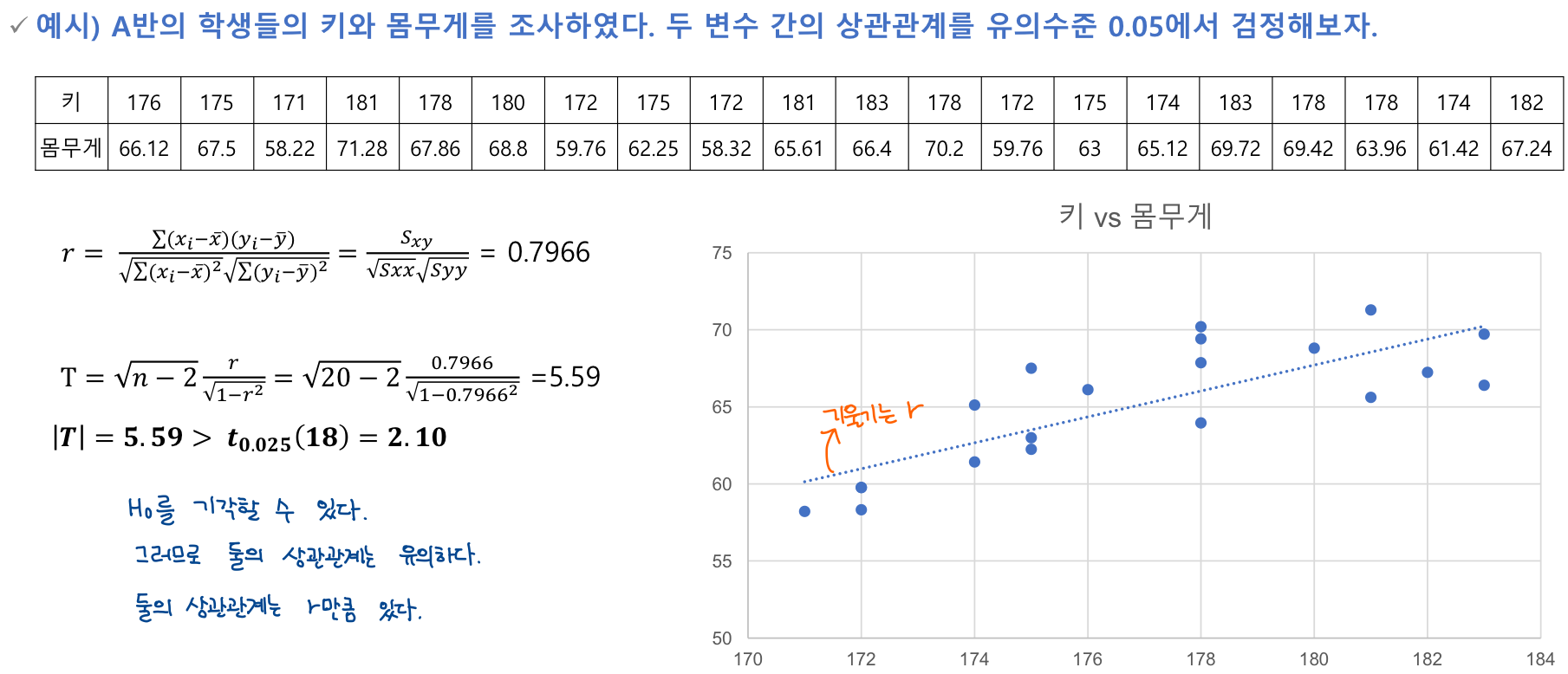
상관분석
🔰 상관관계 계수
Correlation Coefficient
두 변수간의 함수 관계가 선형적인 관계가 있는지 파악할 수 있는 측도가 상관계수이다.

표본상관계수
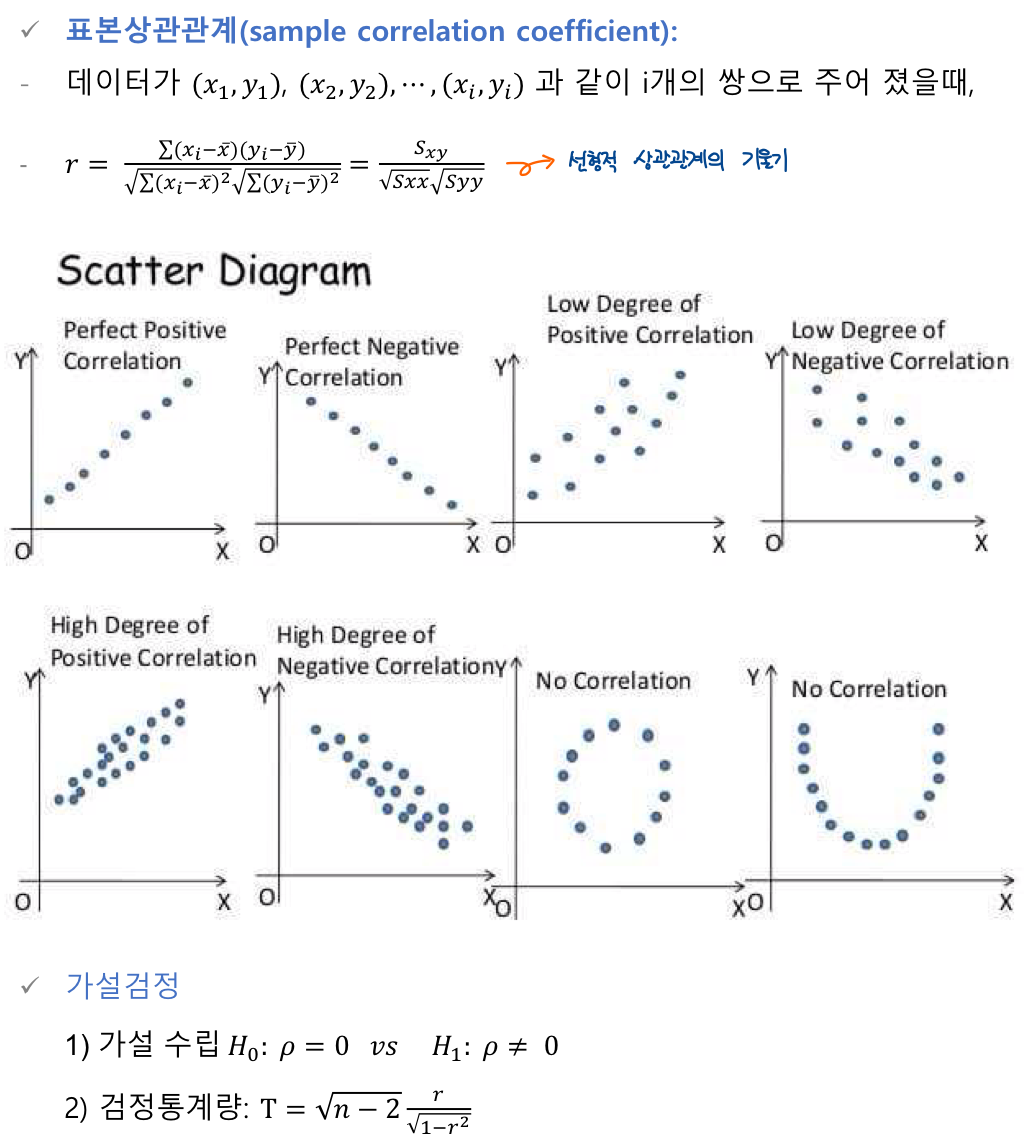
가설검정
-
가설수립
-
검정통계량
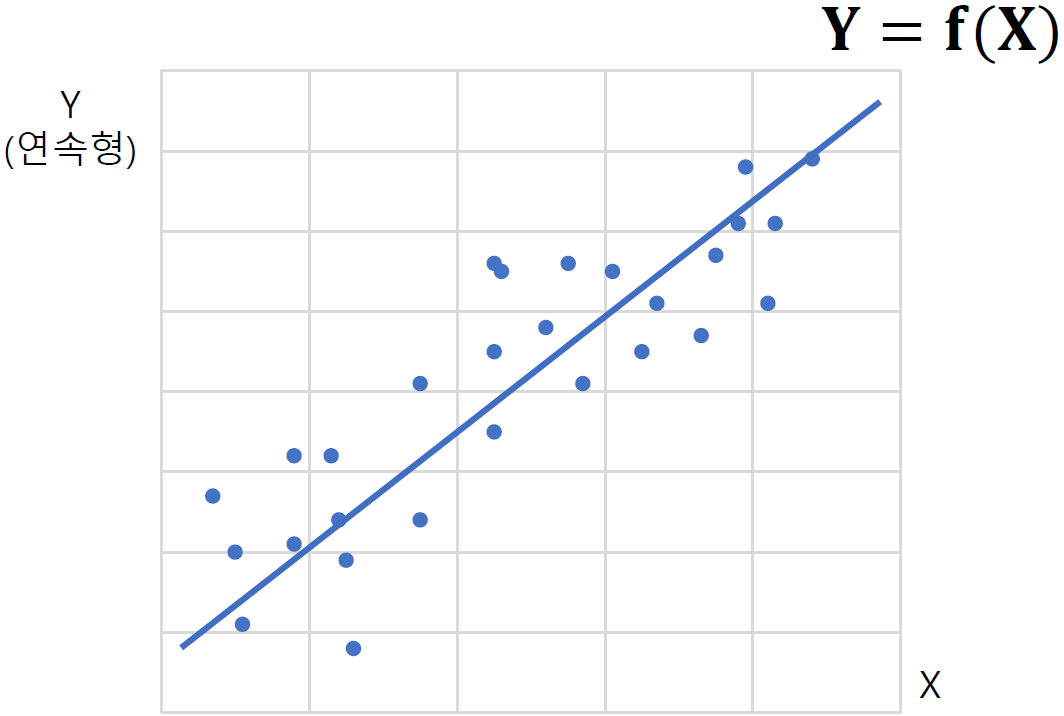
회귀분석
Regression Analysis
변수들 간의 함수적 관계를 선형으로 추론하는 통계적 분석 방법으로 독립변수를 통해 종속변수를 예측하는 방법이다.
-
비선형인 함수적 관계일 경우 비선형회귀(nonlinear regression)를 사용해야 한다.
-
ex. 마케팅 비용에 따른 매출액을 예측
-
종속 변수(dependent variable)
다른 변수의 영향을 받는 변수로 반응변수라 표현 하기도 하며,
예측을 하고자 하는 변수이다.- ex:) 매출액, 수율, 불량율 등
-
독립 변수(independent variable)
종속변수에 영향을 주는 변수로 설명변수라 표현 하기도 하며,
예측 하는 값을 설명해주는 변수이다.
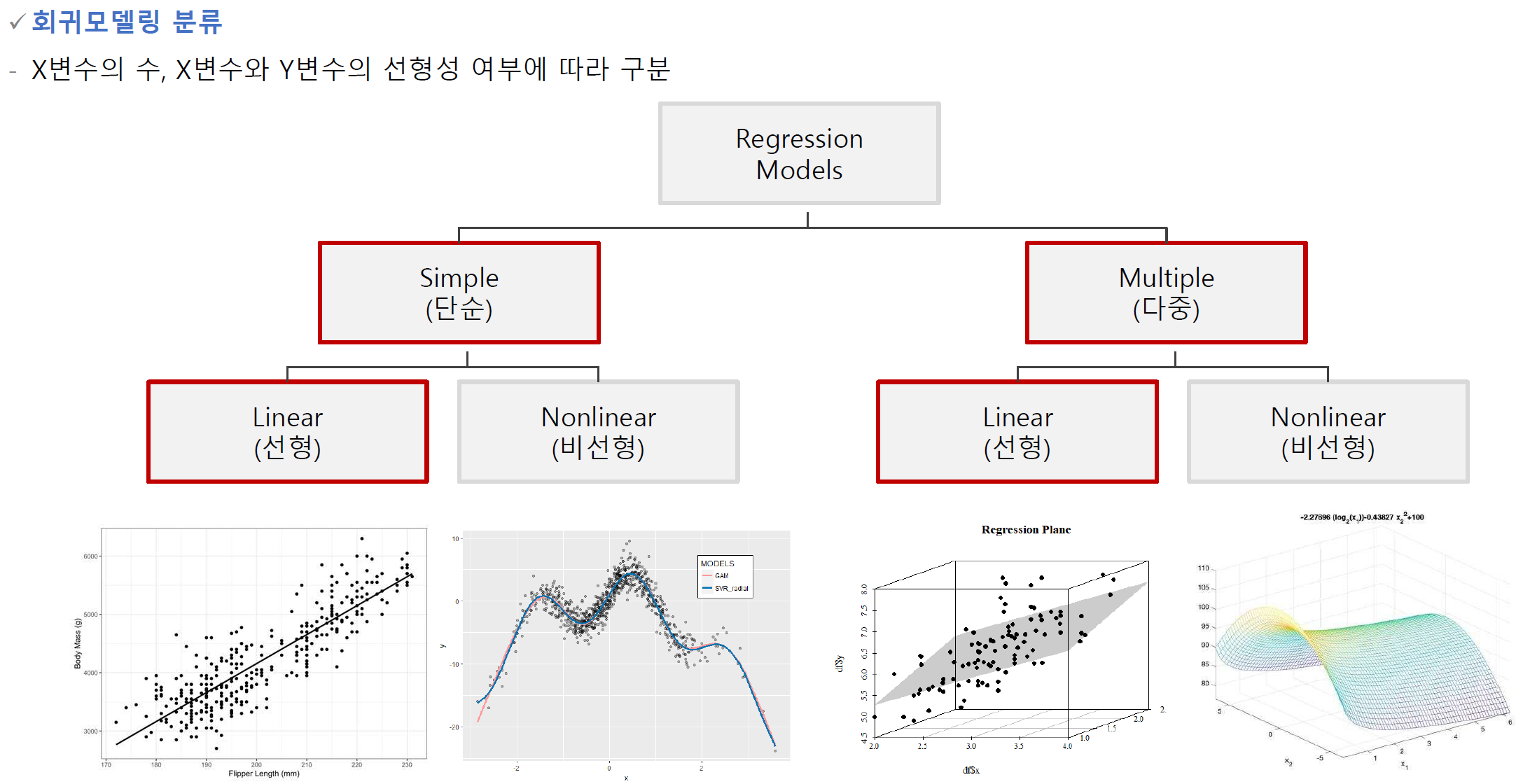
🔰 단순 회귀분석
simple regression analysis
하나의 독립변수로 종속변수를 예측하는 회귀 모형을 만드는 방법을 단순 회귀분석이라고 한다.
⏺ 회귀선
-
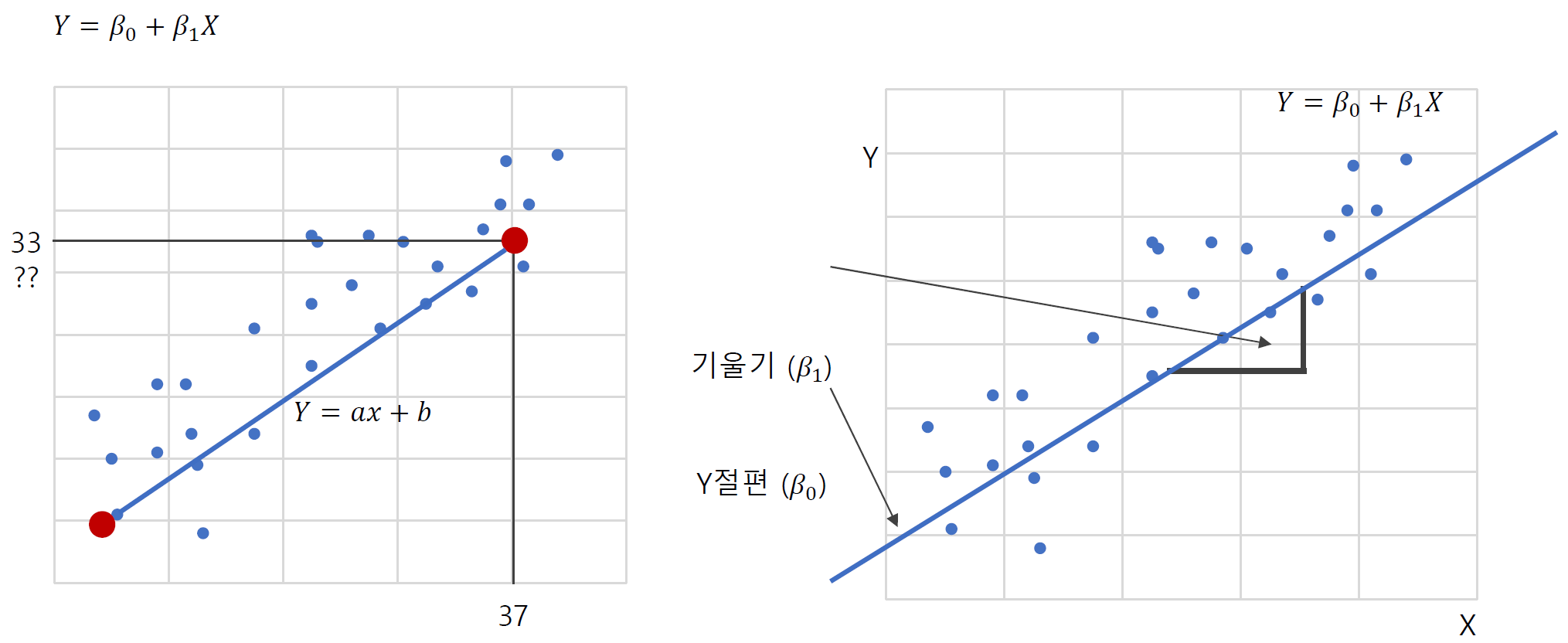
-
회귀선으로부터 각 관측치의 오차를 최소로하는 선을 찾는 것이 핵심이다.
-
오차 를 최소로 하여 을 추정하는 방법을 최소제곱법이라 한다.
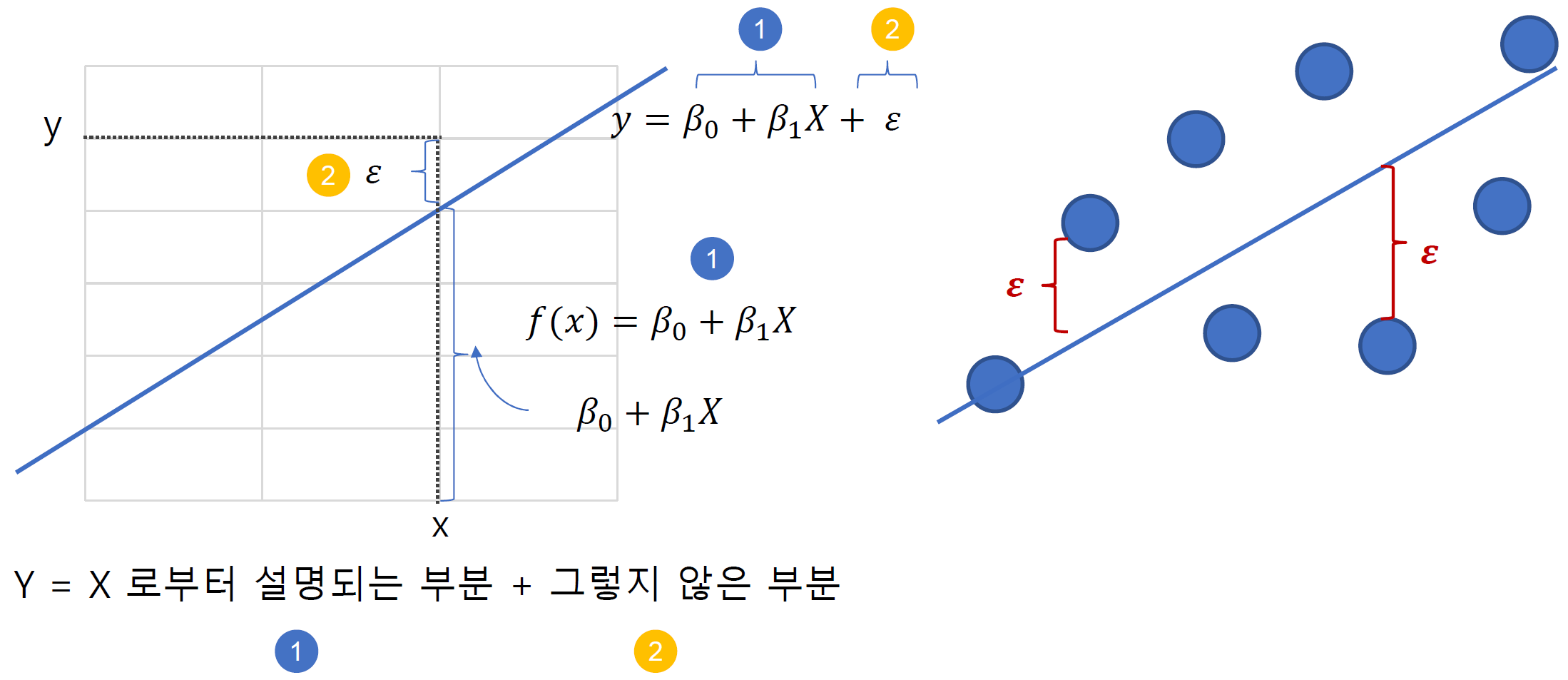
⏺ 최소제곱법(method of least squares)
-
회귀 모형의 모수 을 추정하는 방법중 하나를 최소 제곱법이라고 하며, 이 때 회귀 모형의 모수를 회귀 계수라고 한다.
-
최소 제곱법을 통해 구한 추정량을 최소제곱추정량(LSE)라고 한다.
-
OLS(Ordinary Least Square)은 최소제곱법을 통해 회귀모형의 모수를 추정하는 것이다.
-
회귀 모형 오차에 대하여 기본 가정이 있다.
1) 정규성 가정: 오차항은 평균이 0인 정규 분포를 따른다.
2) 등분산성 가정: 오차항의 분산은 모든 관측값 에 상관없이 일정하다.
3) 독립성 가정: 모든 오차항은 서로 독립이다.
🔰 다중 회귀분석
multiple regression analysis
2개 이상의 독립변수로 종속 변수를 예측하는 회귀 모형을 만드는 방법을 다중 회귀분석이라고 한다.
-
-
여기서 는 종속 변수, 은 독립 변수, 는 절편, 은 각 독립 변수의 계수, 은 오차 항이다.
-
변수선택법
-
전진선택법(forward selection):
독립변수를 1개부터 시작하여 가장 유의한 변수들부터 하나씩 추가하면서 모형의 유의성을 판단하는 방법 -
후진 제거법(backward selection):
모든 독립변수를 넣고 모형을 생성한 후, 하나씩 제거하면서 판단하는 방법 -
단계접 방법(stepwise selection):
위의 두가지 방법을 모두 사용하여 변수를 넣고 빼면서 판단하는 방법
-
분산분석
ANOVA(Analysis of Variance)는 셋 이상의 모집단의 평균 차이를 검정
셋 이상의 모집단으로부터 추출한 양적 데이터를 비교하는 통계적 분석 방법
- 두 개의 모집단의 평균 차이를 검정하는 t-test가 유용하지 않을 때 분산분석을 활용한다.

⏺ 실험계획법(experimental design):
모집단의 특성에 대하여 추론하기 위해 특별한 목적성을 가지고 데이터를 수집하기 위한 실험 설계를 실험계획법이라고 한다.
- 반응변수: 관심의 대상이 되는 변수
- 요인/인자(Factor): 실험 환경 또는 조건을 구분하는 변수로 실험에 영향을 주는 변수
- 인자수준: 인자가 취하는 개별 값(처리:treatment)
⏺ 분산분석의 기본 가정
- 각 모집단은 정규 분포를 따른다.
- 각 모집단은 동일한 분산을 갖는다.
- 각 표본은 독립적으로 추출되었다.
⏺ 분산분석의 가설
- : 각 집단의 평균은 동일하다.
- : 각 집단의 평균에 차이가 있다.
⏺ 실험의 가정
- 반복의 원리: 실험을 반복해서 실행해야 한다.
- 랜덤화의 원리: 각 실험의 순서는 무작위이다.
- 블록화의 원리: 제어해야 할 변수가 있다면 인자에 영향을 받지 않도록 조건을 묶어서 실험해야 한다.
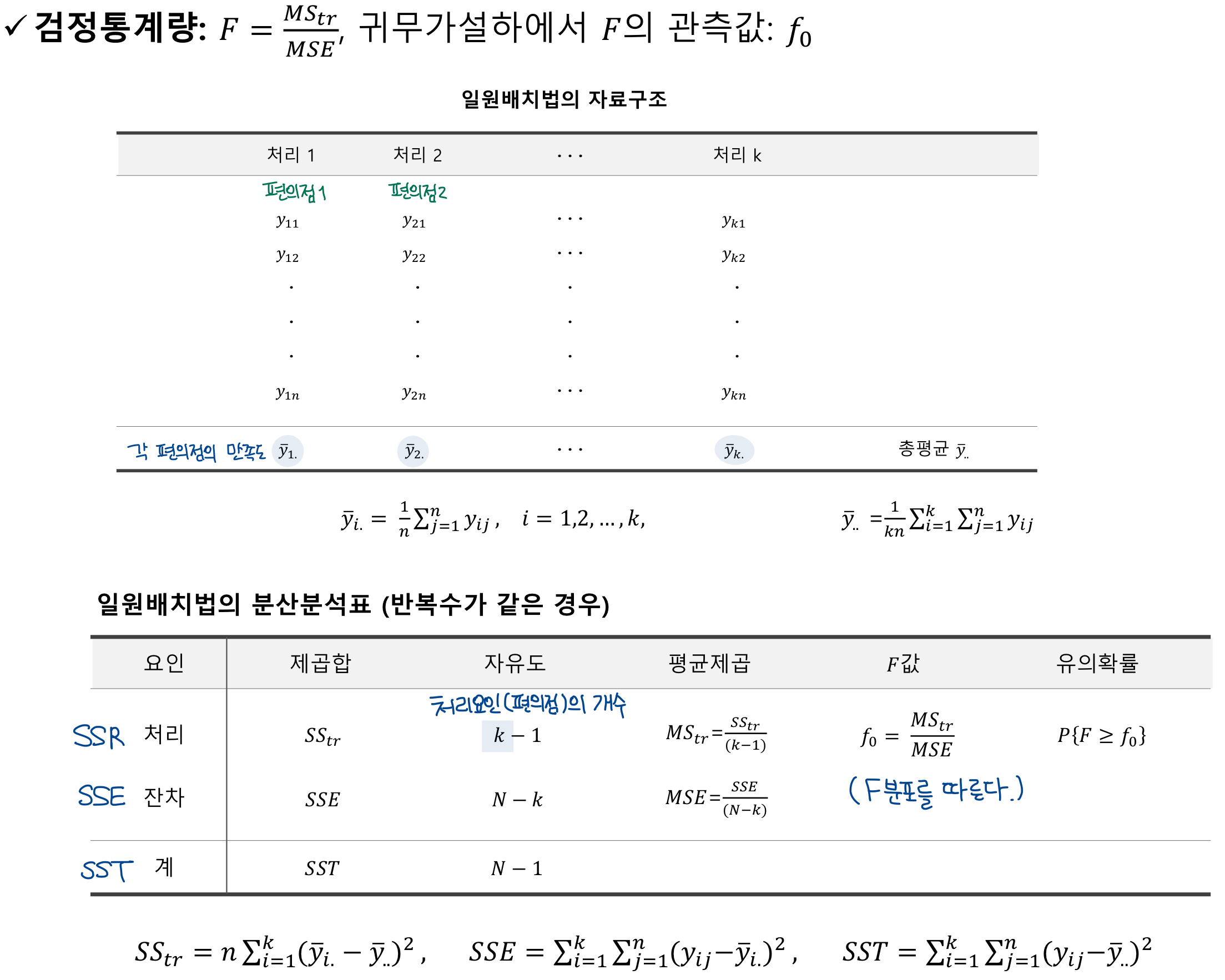
🔰 일원 ANOVA
One-way ANOVA
한가지 요인을 기준으로 집단간의 차이를 조사하는 것
세 개 이상의 독립적인 그룹 간의 평균 차이가 통계적으로 유의한지를 검정하기 위해 사용된다.
-
한 개의 반응 변수와 한 개의 독립 인자
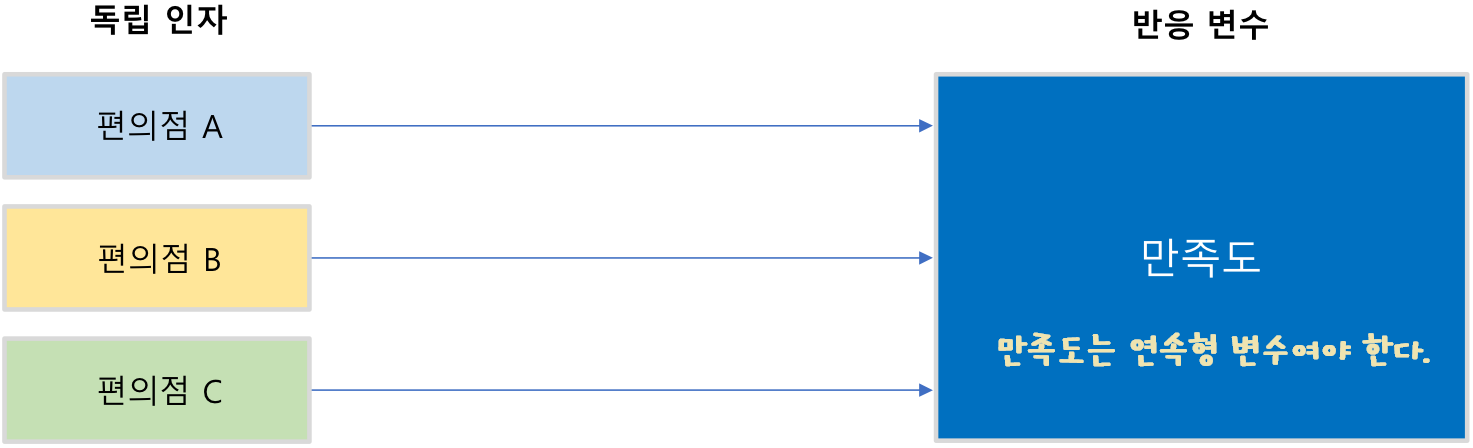
- 반응 변수: 연속형 변수만 가능
- 독립 인자(변수): 이산형 또는 범주형 변수만 가능
-
ex.
- A,B.C 3개의 편의점에서 만족도를 조사한 결과 만족도의 차이가 있는가?
- 생산라인 A, B, C에서 생산되는 웨이퍼의 불량률은 차이가 있는가?
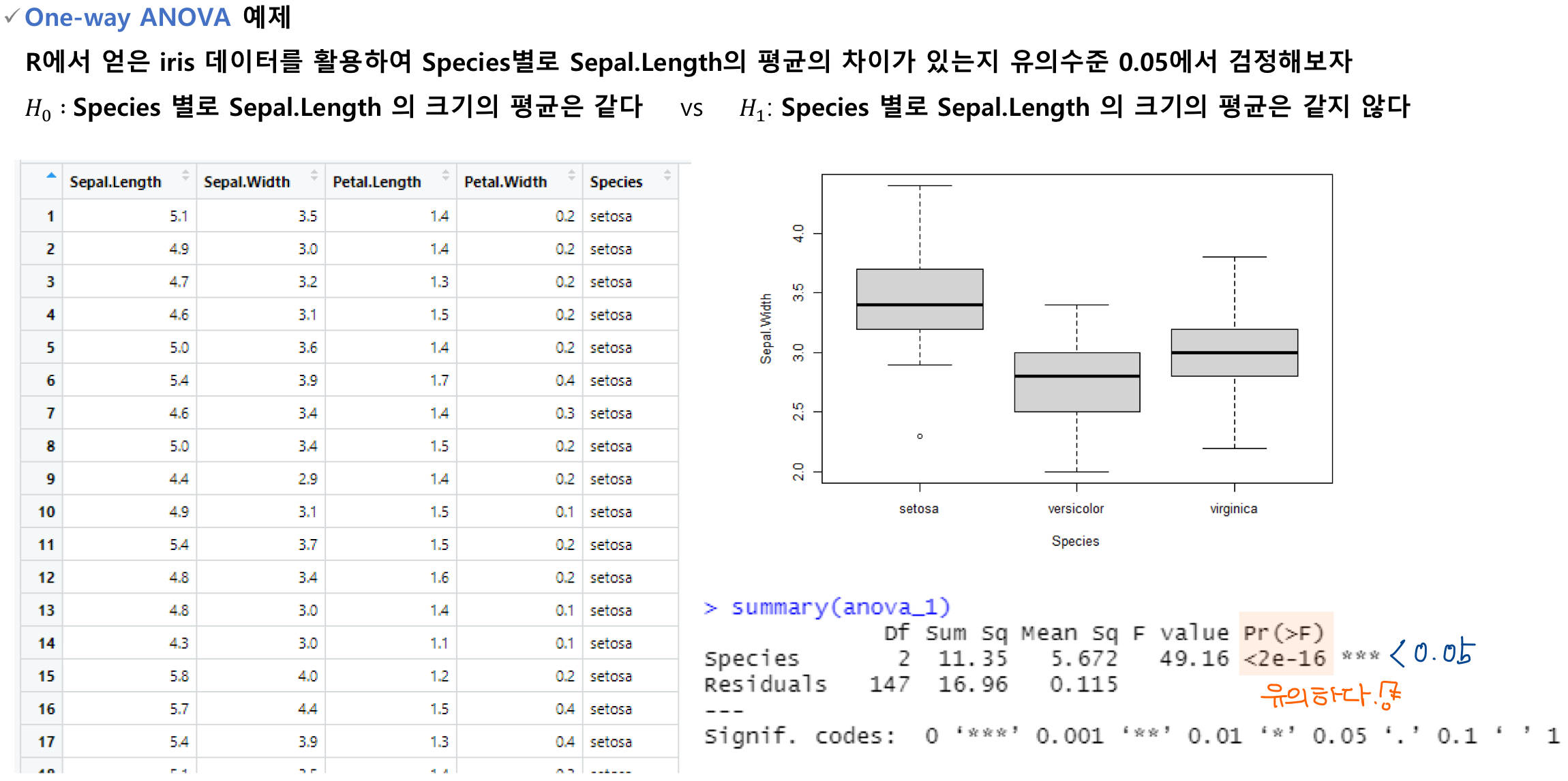
⏺ 일원 분산분석 가설검정
-
가설수립
- 적어도 하나 이상의 평균이 같지 않다.
-
유의수준 기각역
- 이면 를 기각한다.
-
유의확률, p-value
- 일 때, -value = 이다.
- 값이 보다 작으면 를 기각한다.
-
검정통계량
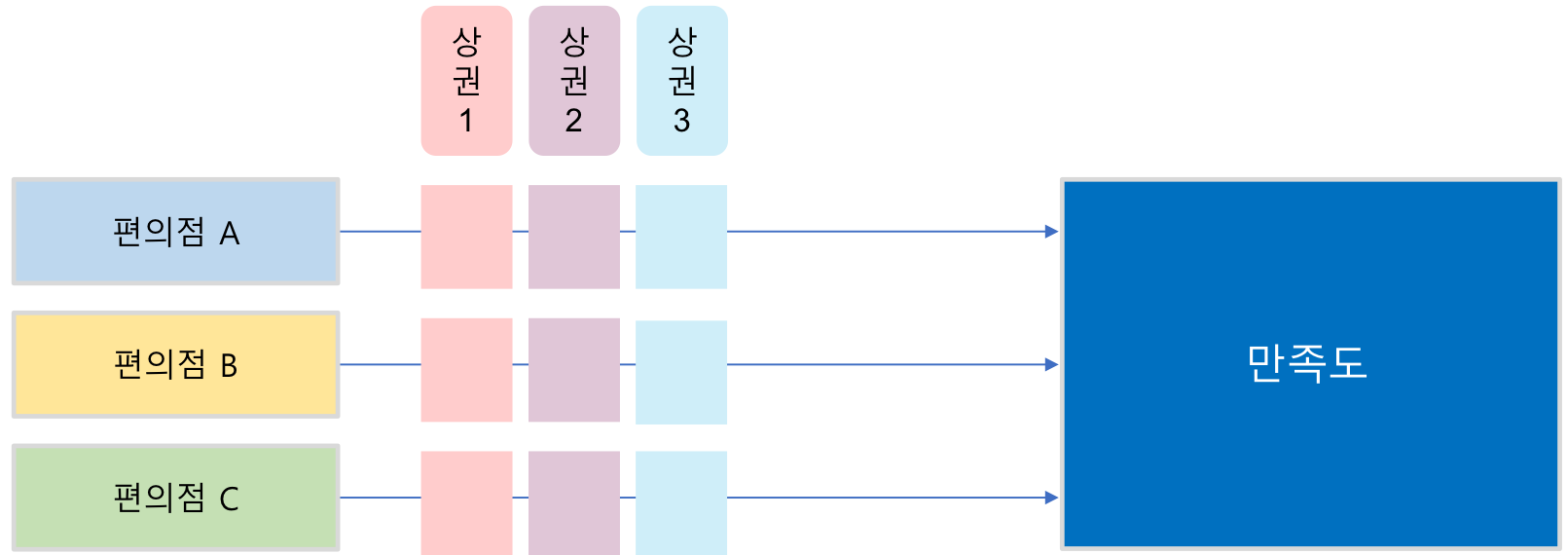
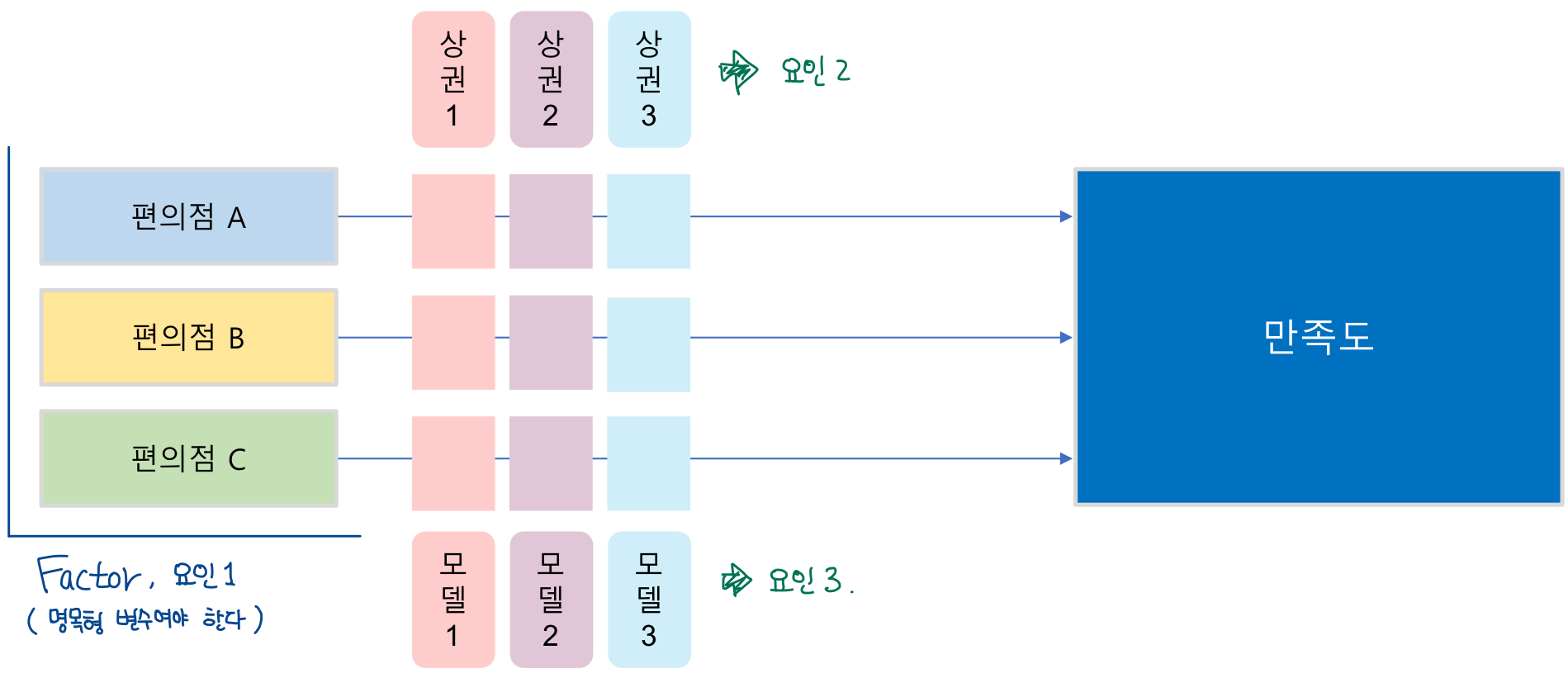
🔰 이원 ANOVA
Two-way ANOVA
두 가지 요인을 기준으로 집단 간의 차이를 조사하는 것
-
한 개의 반응 변수와 두 개의 독립 인자로 분석하는 방법
- 독립인자는 one-way와 마찬가지로 이산형 또는 범주형 변수만 가능
-
ex.
만족도에 영향을 주는 인자가 편의점 브랜드와 상권이라고 할 때, 편의점 브랜드별로 상권을 변경하면서 만족도가 다른지 측정하고 분석하는 방법 -
두 개의 범주형 독립변수가 연속형 종속변수에 미치는 효과와 두 독립변수의 상호작용 효과를 분석한다.
상호작용(Interaction Effect)
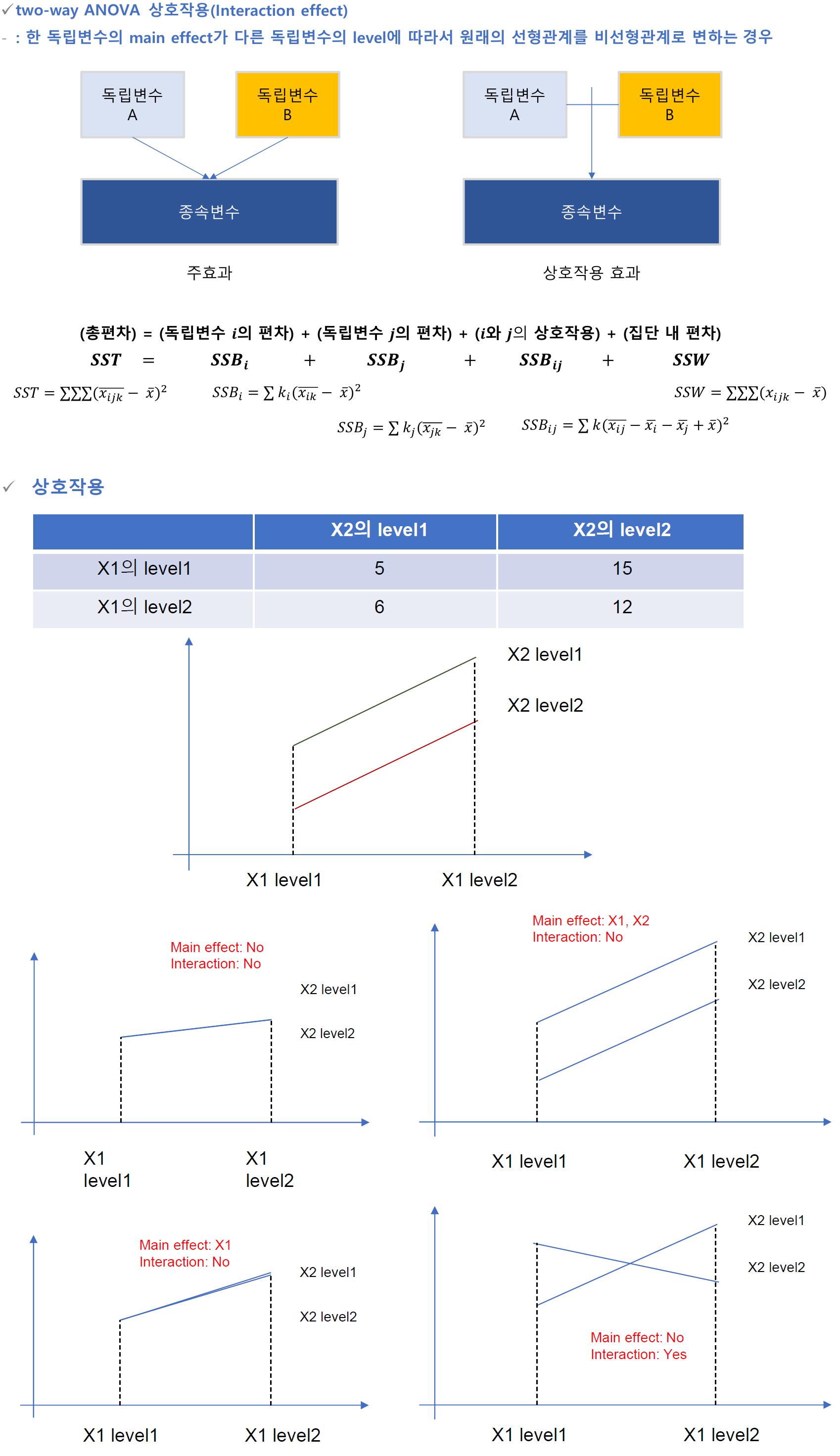
⏺ 이원 분산분석 가설 검정
-
첫 번째 main effect 가설
적어도 하나 이상의 평균이 같지 않다.
- k는 그룹의 갯수
-
두 번째 main effect 가설
적어도 하나 이상의 평균이 같지 않다.
-
상호작용에 대한 가설
∶ 교호작용이 없다. vs. : 교호 작용이 있다.
🔰 다원 ANOVA
세 가지 이상의 요인을 기준으로 집단 간의 차이를 조사하는 것
시계열 분석
Time Series Analysis
시간의 흐름에 따라서 관측된 자료를 통계적으로 분석하는 방법
시계열(시간의 흐름에 따라 기록된 것) 자료(data)를 분석하고 여러 변수들간의 인과관계를 분석하는 방법
⏺ 시계열분석의 목적
-
예측: 금융시장 예측, 수요 예측 등 미래의 특정 시점에 대한 관심의 대상(종속,반응변수)를 예측하는 데 활용
-
시계열 특성 파악: 경향(Trend), 주기, 계절성, 변동성(패턴) 등을 파악하는 데 활용
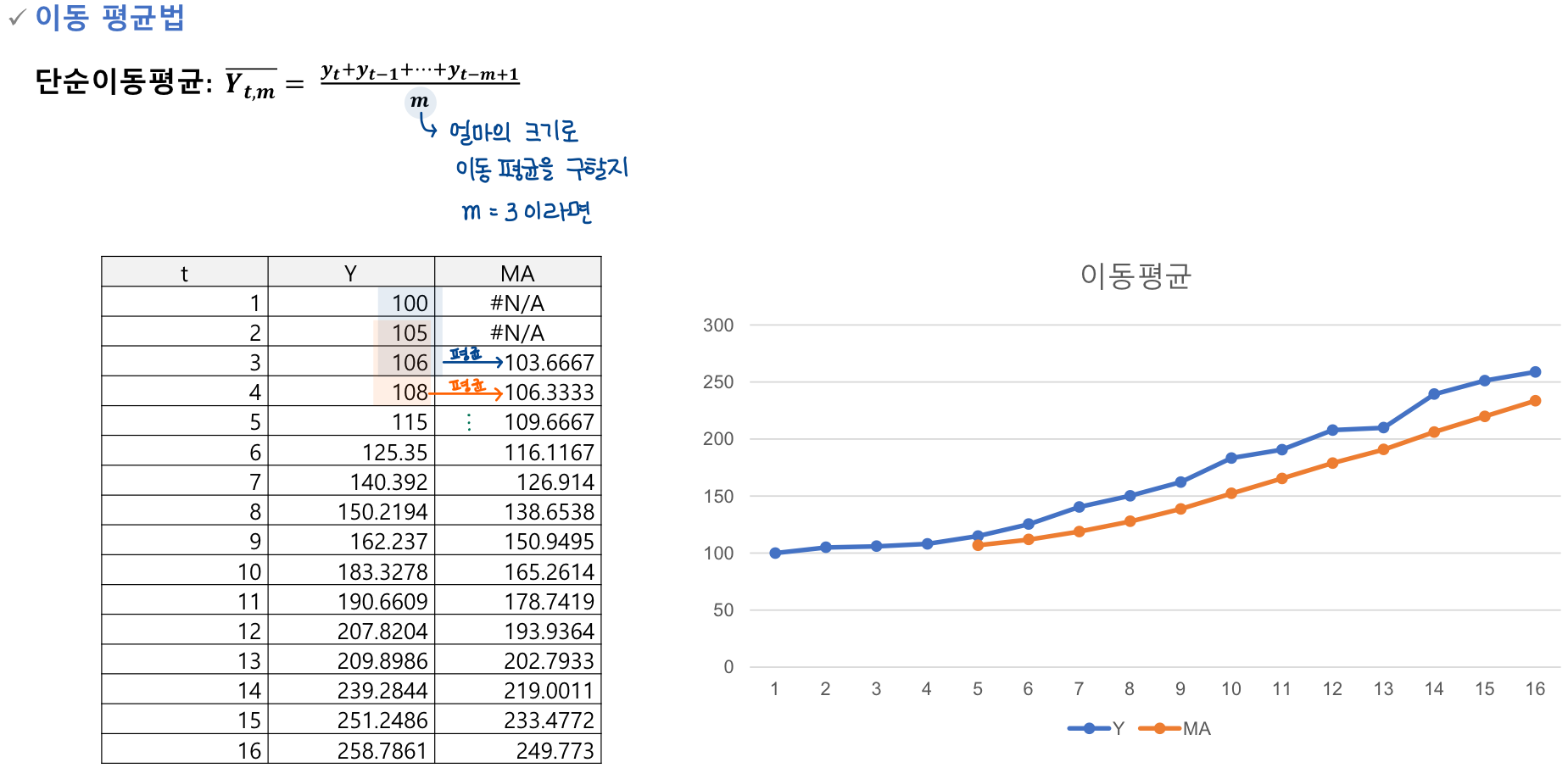
🔰 이동 평균법
-
Moving Average, MA
-
이동평균은 시계열 데이터의 단기적인 변동을 부드럽게 하고 장기적인 추세를 보여주기 위해 사용되는 통계적 방법이다.
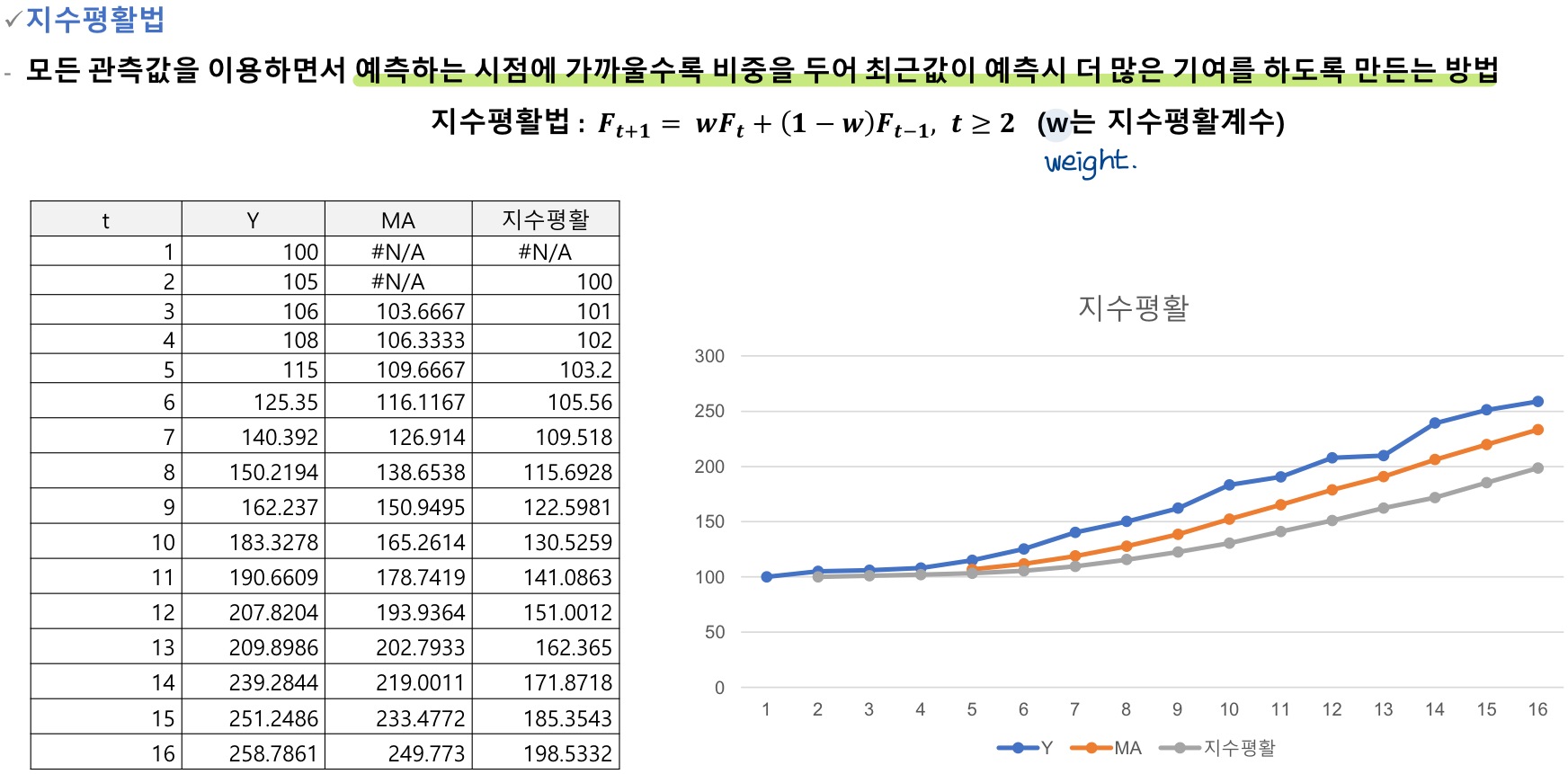
🔰 지수평활법
-
Exponential Smoothing
-
지수평활법은 시계열 데이터에서 단기적인 변동을 줄이면서도 데이터의 추세와 계절성을 반영할 수 있는 방법이다.
-
지수평활은 과거 데이터에 지수적으로 감소하는 가중치를 부여하는 방식으로 이루어진다. 이러한 가중치의 적용으로 최근의 관측치에 더 많은 비중을 두고, 오래된 데이터에는 점점 더 적은 가중치를 부여하게 된다.