Model(1) - Model with Python
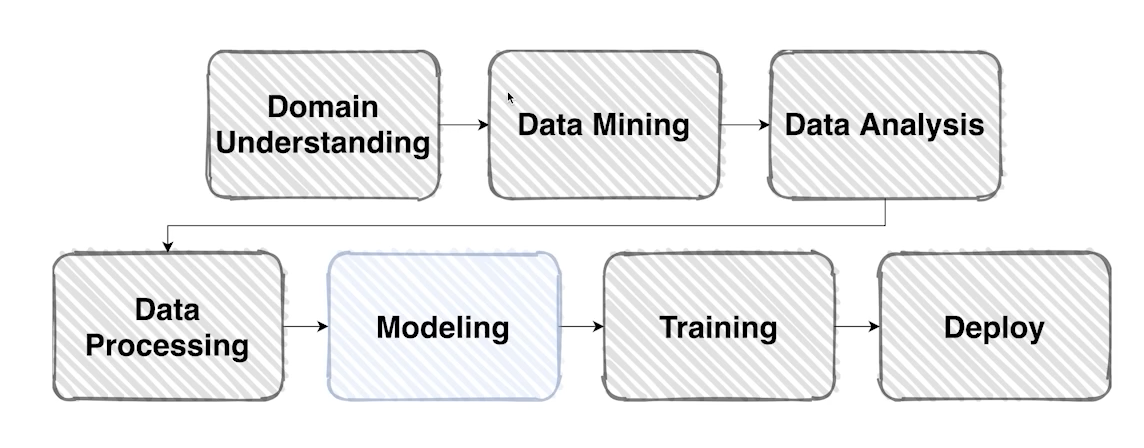
데이터셋을 이용하여 원하는 출력을 만들어줄 모델을 구성할 차례
In general, a model is an informative representation of an object, person or system
system: 시각적인 표현물을 rgb로 표현, 모델을 집어넣었을 때 우리가 원하는 형태의 category
Design Model with Pytorch
- pytorch
연구하기좋은 프레임워크
low-level, pythonic, flexibility

- nn.Module
파이토치 모델의 모든 레이어는 nn.Module클래스를 따른다.
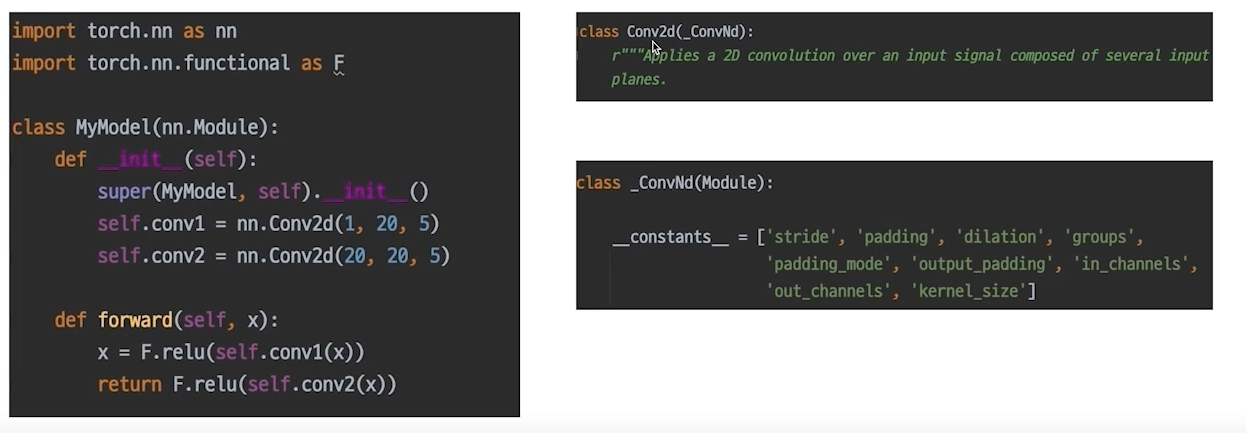
super: initialization 정의해줘야함
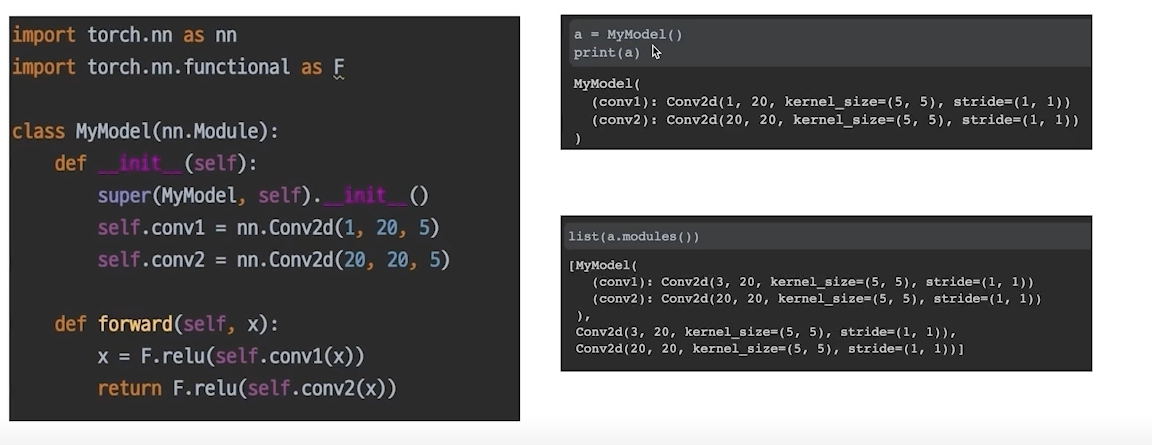
- modules
init에서 정의한 또 다른 nn.Module, 안에있는 모듈까지 다 보여줌
우리는 하나의 모델을 정의하고 거기에 연결된 모듈들(파라미터가 들어있는 모듈들)을 볼 수 있음, 모델을 저장하고 불러오는 것 까지 알 수 있다. 파라미터를 저장하고있는 저장소라보면됨
- forward
이 모델(모듈)이 호출 되었을 때 실행되는 함수
딥러닝 전파 방향대로 구현

- nn.Module Family

모델의 weight parameter를 업데이트 하는 과정은 여기서 발생된 모델의 정의된 modules를 기반으로 만들어짐
모든 nn.Module은 forward()함수를 가진다.
- Parameters
모델에 정의되어 있는 modules가 가지고 있는 계산에 쓰일 Parameter
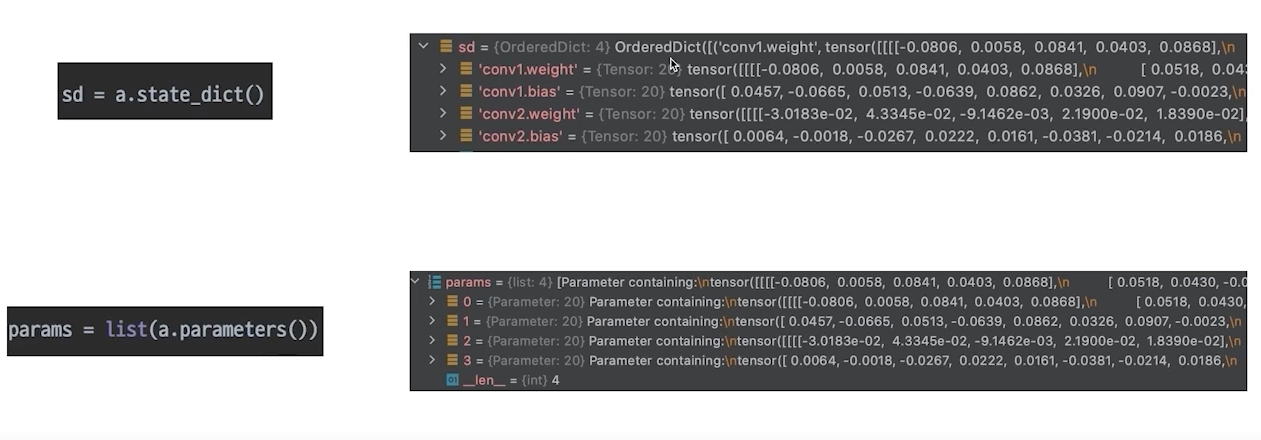
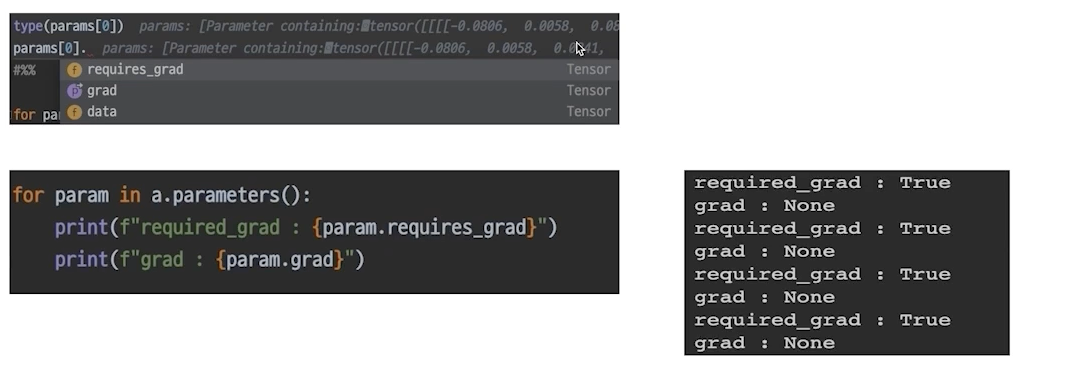
state_dict(): 키값과 같이 텐서가 있음, 어느쪽에 파라미터가 있느지 알 수 있음
parameters(): 그냥 텐서만 있음
각 모델 파라미터는 data, grad(미분값을 저장), requires_grad 변수 등을 가지고 있다.
requires_grad가 false면 업데이트를 하지 않음(freeze)
파라미터는 tensor를 base로 만들어진 클래스임, 파라미터 하나당 중요한 요소는 데이터,
pytorch의 pythonic

load_statedict: 다른 state에 있는 dictionary를 업데이트한다는 것을 알 수 있음
Model(2) - Pretrained Model
좋은 모델을 설계하는것도 좋지만 pretrained모델을 사용하는 것도 좋음!
데이터가 부족한것도 조금은 해결될 수 있음
남의 모델의 구조를 바로 가져와서 쓸 수 있음
computer vision의 발전
computer vision으로 많은 일을 자동화 할 수 있다.
ImageNet(단순 데이터셋)
획기적인 알고리즘 개발과 검증을 위해 높은 품질의 데이터 셋은 필수다.
pretrained model의 배경
모델 일반화를 위해 매번 수많은 이미지를 학습시키는 것을 까다롭고 비효율적
좋은 품질, 대용량의 데이터로 미리 학습한 모델 → 이 모델을 바탕으로 내 목적에 맞게 다듬어서 사용
미리 학습된 좋은 성능이 검증되어 있는 모델을 사용하면 시간적으로 매우 효율적이다.
torchvision.models

Transfer Learning
fc == fully connected layer == classifier
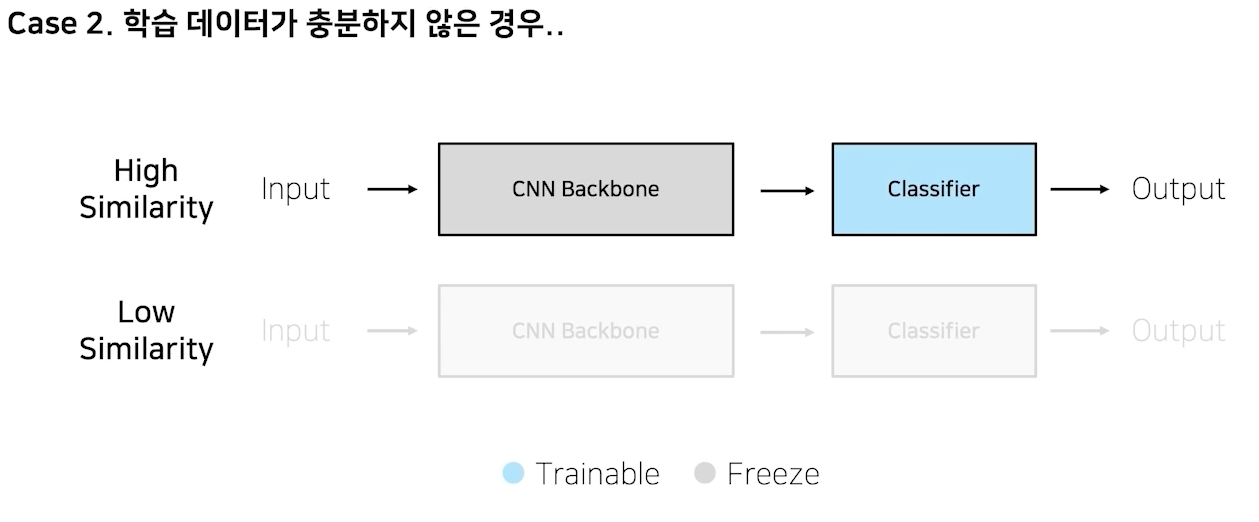
내 데이터, 모델과의 유사성
imagenet pretraining: 실생활에 존재하는 이미지를 1000개의 다른 class로 구분하자라는 목적으로 만들었음
만약 imagenet으로 구름 위성사진 종류 classifier하면? 유사성이 없어서 결과가 안좋을 것임
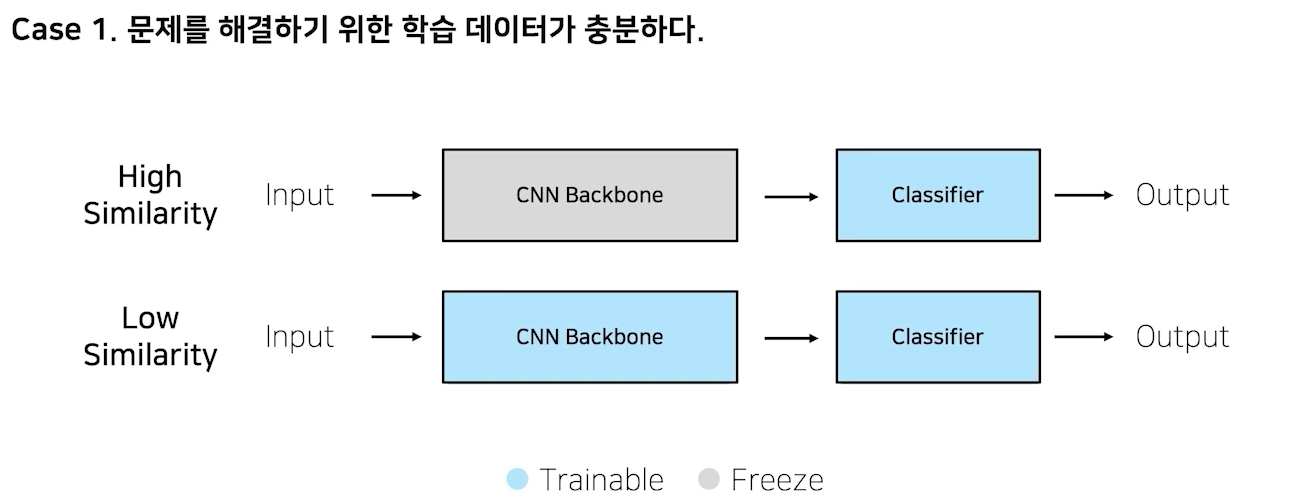
풀고자하는게 비슷하면 freeze하는게 좋음, 하지만 비슷하지 않으면 trainable하게 만드는게 맞음!
feature extraction: cnn백본 사용하고 classifier만 재학습
finetuning: cnn backbone까지 다 학습시키는 것
Training & Inference(1) - Loss, Optimizer, Metric
**본격적으로 모델을 학습해보자!**
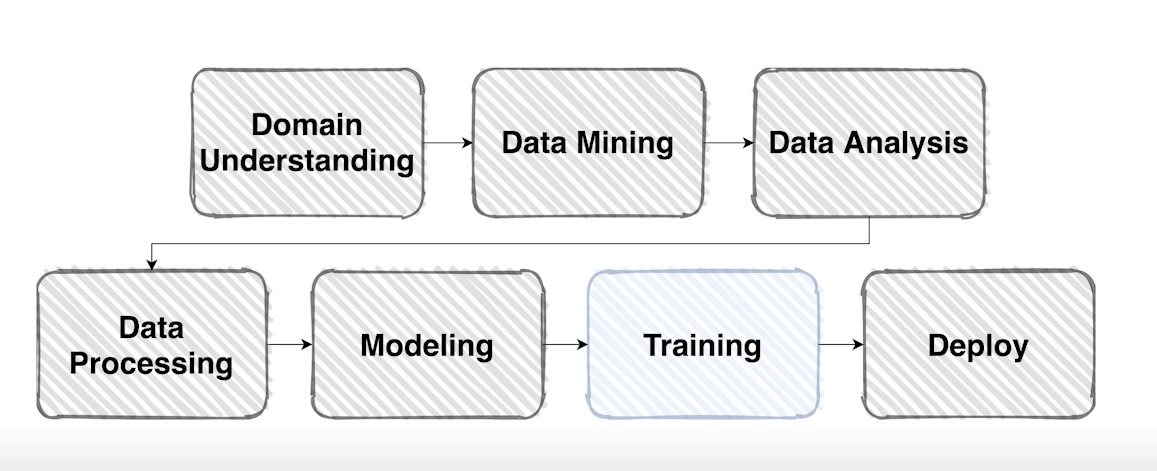
학습 프로세스에 필요한 요소
- Loss
- Optimizer
- Metric
Loss
(오차) 역전파
Loss도 사실 nn.module family
loss.backward()
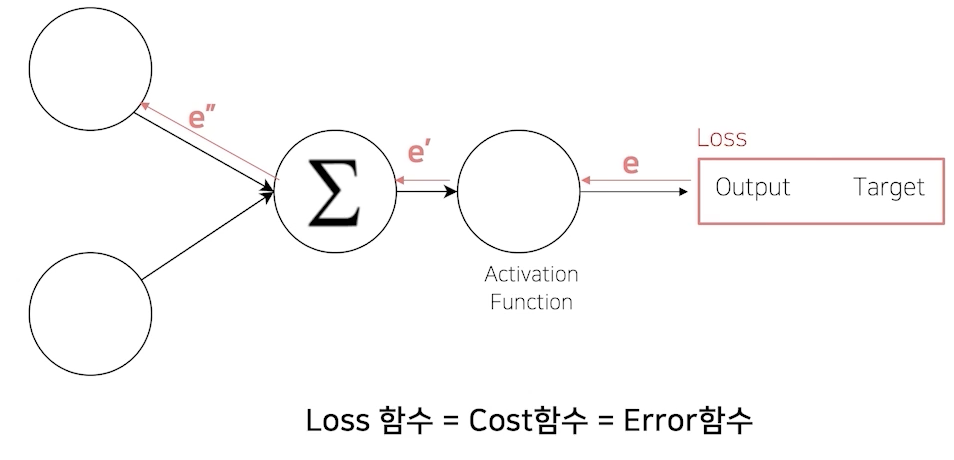
output과 target의 차이는 loss함수가 어떻게 만들어지느냐에 따라 다름(특정 목적에 따라 loss함수가 바뀔 수 있음)

loss도 사실 forward함수가 있음, module과 같은 family임
loss.backward()
input이 들어가면 forward함수로 나오고 그 output과 input의 체인이 만들어짐
모델로 인풋을 만들어진 시작점부터 로스까지 연결된 체인이 생긴다!
required_grad=false일 경우는 backward 안먹음
**조금 특별한 loss**

Optimizer
어느 방향으로 얼마나 움직일지
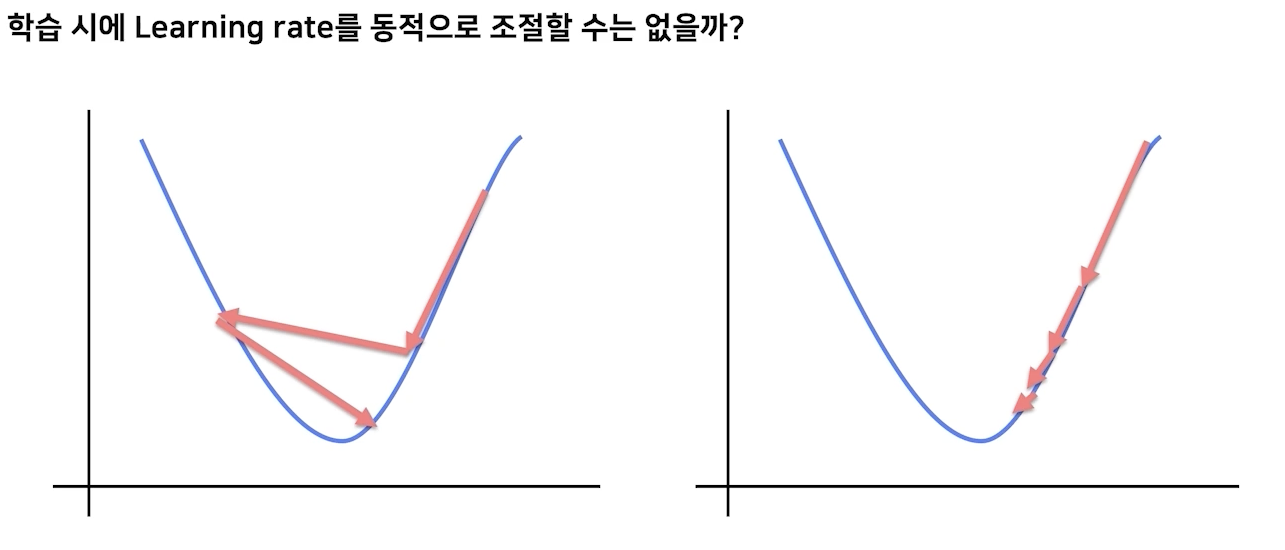
LR Schedualer
영리하게 움직일수록 수렴은 빨라진다.

웨이트에 대한 에러에 대한 변화율에 영향을 받은 웨이트의 변화에 따라 웨이트를 업데이트를 한다. optimizer를 정의했을 때 러닝레이트 만큼
loss값을 update하는 주체가 되는 것은 optimizer임!
LR scheduler
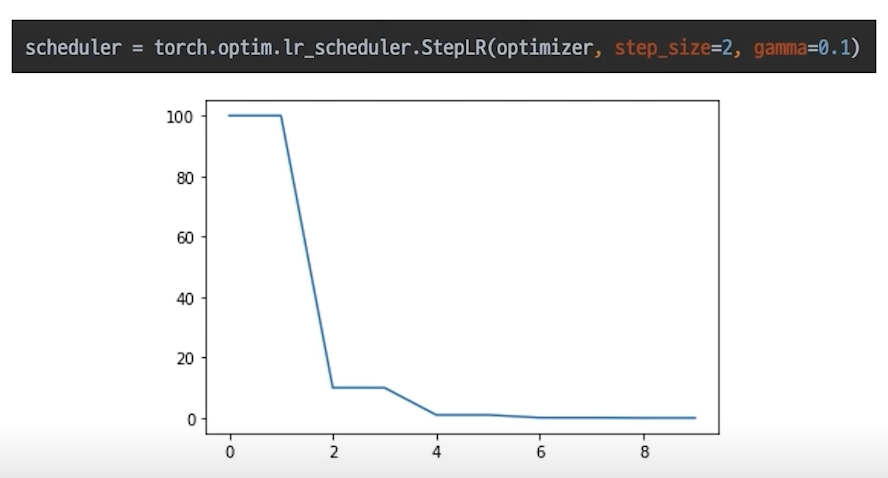
StepLR
특정 step마다 LR감소, 고정적으로 줄인다.
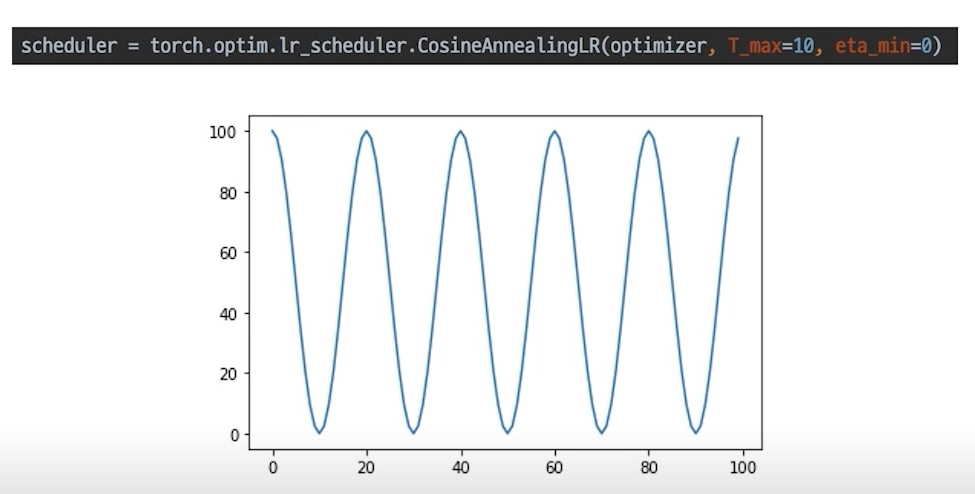
CosineAnnealingLR
cosine함수 형태처럼 LR을 급격히 변경
local minimal에 빠지는 것을 효과적으로 빠르게 탈출할 수 있는 효과가 있다.
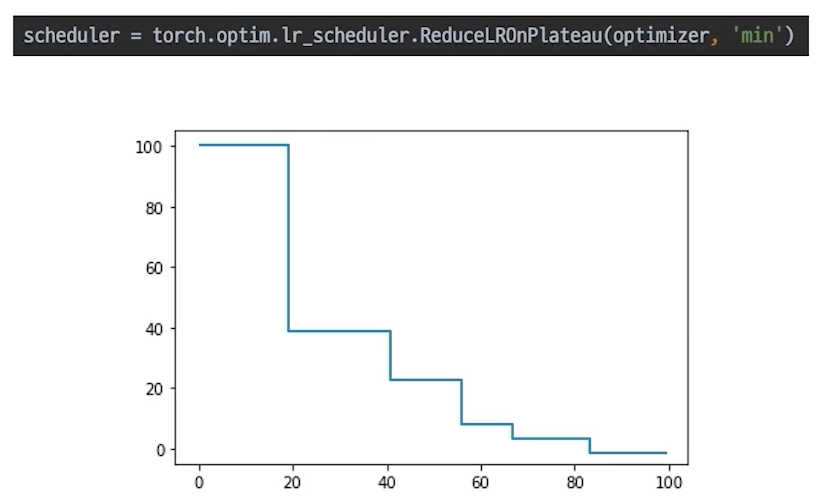
ReducLROnPlateau(가장 많이쓰는거)
더 이상 성능 향상이 없을 때 LR감소
Metric
모델의 평가
score의 허와 실
모델의 평가
학습에 직접적으로 사용되는 것은 아니지만 학습된 모델을 객관적으로 평가할 수 있는 지표가 필요

Training & Inference(2) - Process
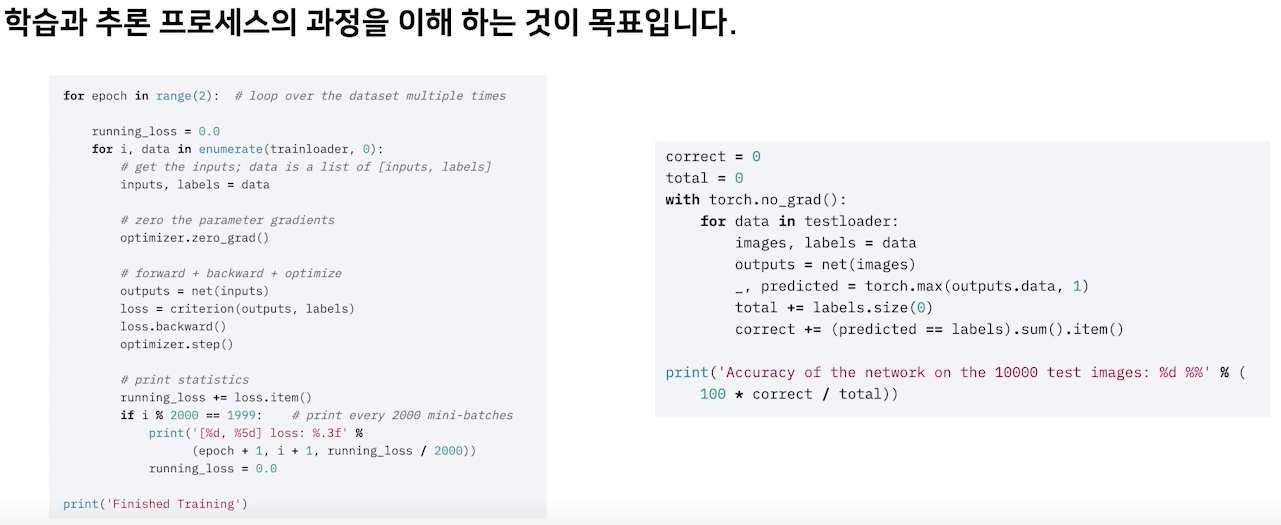
Training Process
training 준비
training process 이해
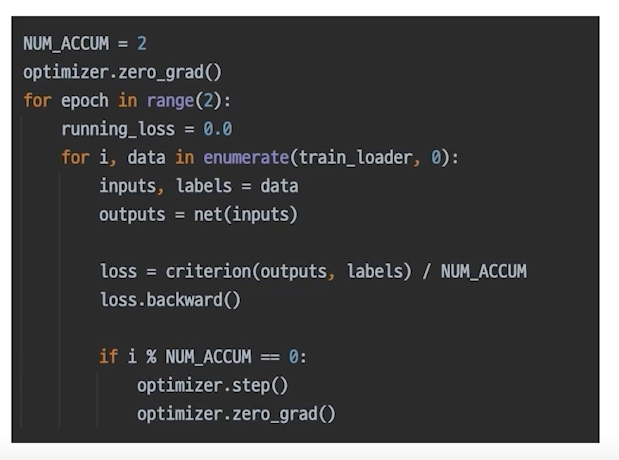
more: gradient accumulation
**지금까지 만든 결과물**
model.train()
모델에 있는 파라미터들을 trainable하게됨
train이랑 eval에 따라 dropout이랑 batchnorm작동이 다르게 되어야됨
→ model train할 때 반드시 들어가야함
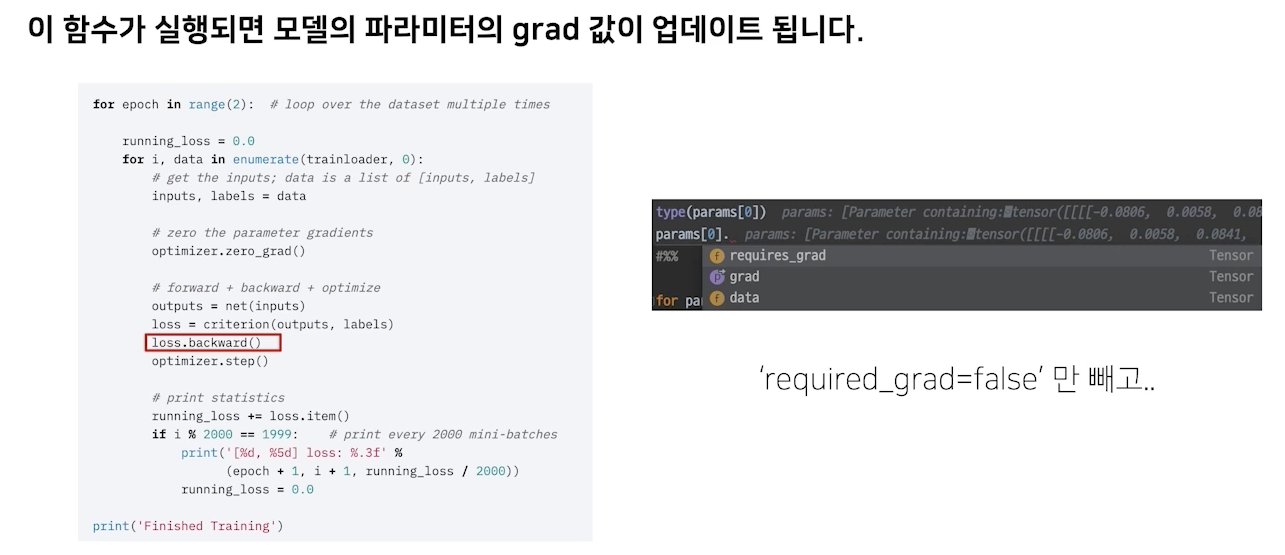
optimizer.zero_grad()
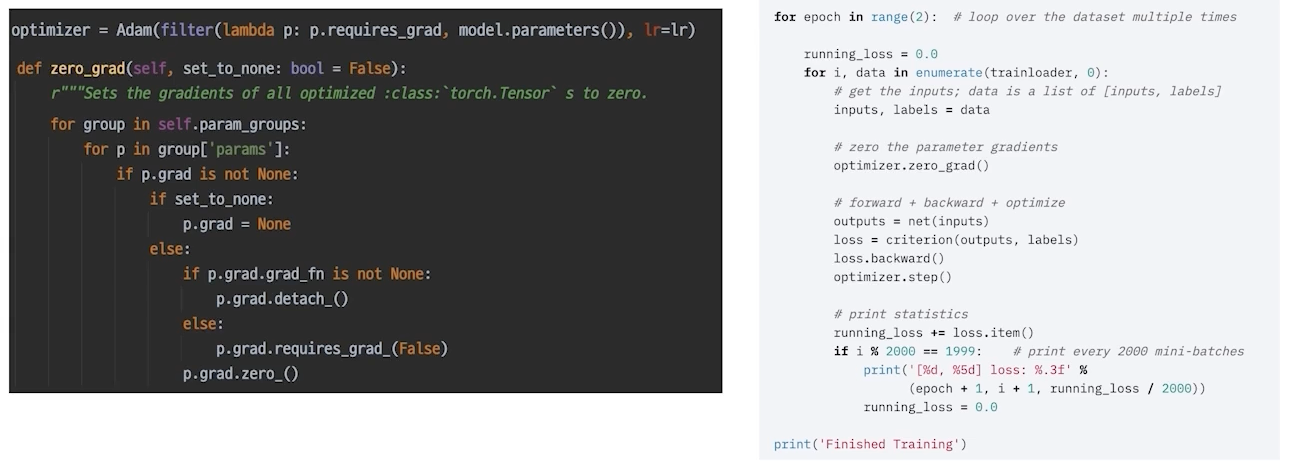
optimizer를 초기화하지 않으면 이전 배치에 있는 grad가 그대로 남아있게됨
옵티마이저는 인풋으로 모델의 파라미터를 가지고 있기 때문에 옵티마이저가 zerograd를 한다는 것은 모델의 파라미터 가지고 컨트롤할 수 있다는 것임
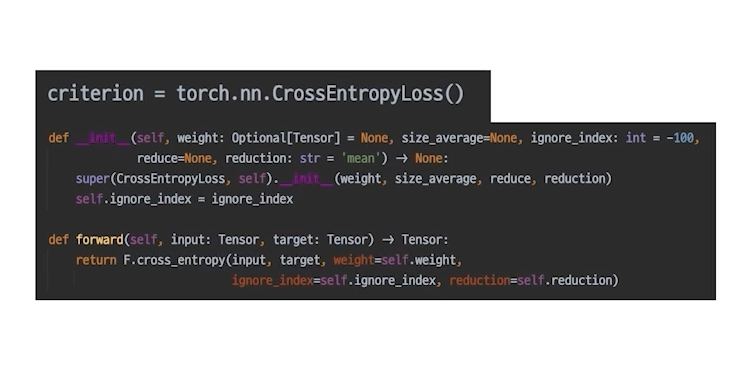
loss = criterion(output, labels)

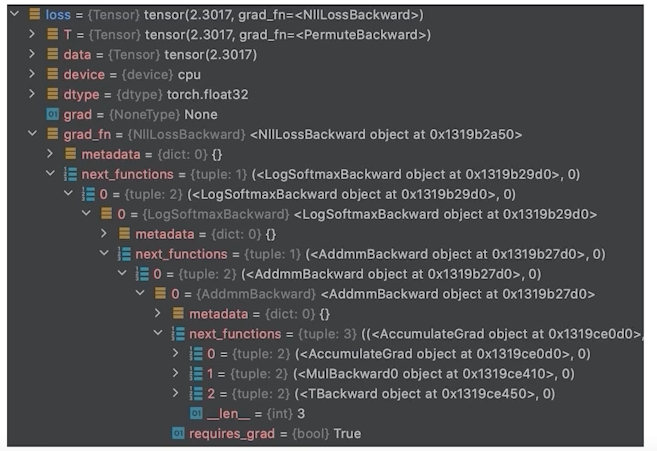
loss의 grad_fn chain → loss.backward()
optimzer.step()
옵티마이저는 옵티마이저를 정의할 때 모델의 파라미터를 인풋으로 넣어 파라미터를 자유자재로 할 수 있음
각각의 파라미터는 grad를 가진채로 파라미터가 업데이트를 갖게 된다.
옵티마이저가 인풋으로 받았던 grad를 바탕으로 적용시킴
응용: gradient accumulation
model.eval()
eval mode에서 사용
단지 검증하고 test하는 것뿐!
파라미터가 업데이트되면 문제가 될 수 있음

Validation 확인
추론 과정에 validation set이 들어가면 그게 검증이다.
checkpoint
직접 짤 수 있다.

최종 output, submisssion형태로 변환
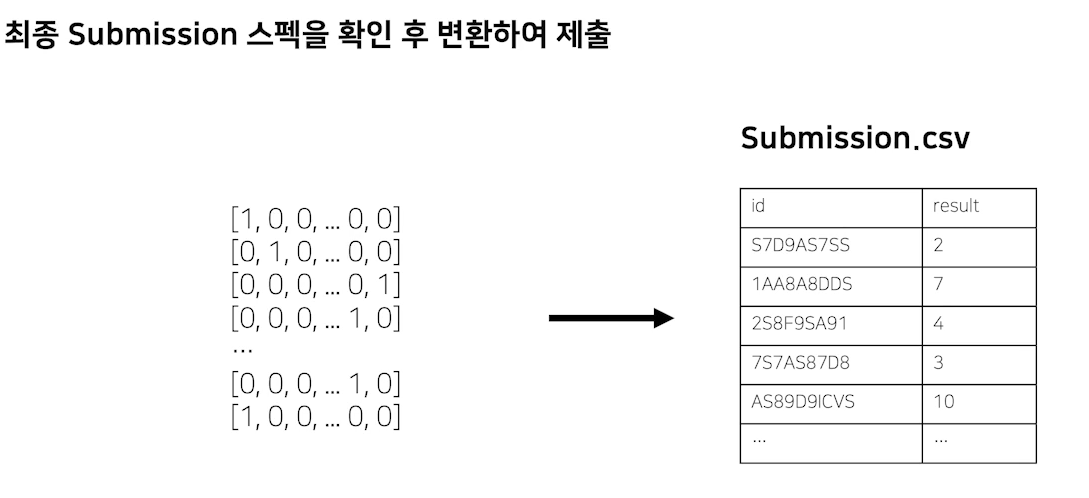
최종적인 아웃풋으로 변환해야한다.
참고: boostcamp aitech 4기 6주차 김태진 마스터님 강의
