[1강] mAP
-
mAP가 어떻게 계산될 수 있는 지 완벽하게 이해하고 있는가?
-
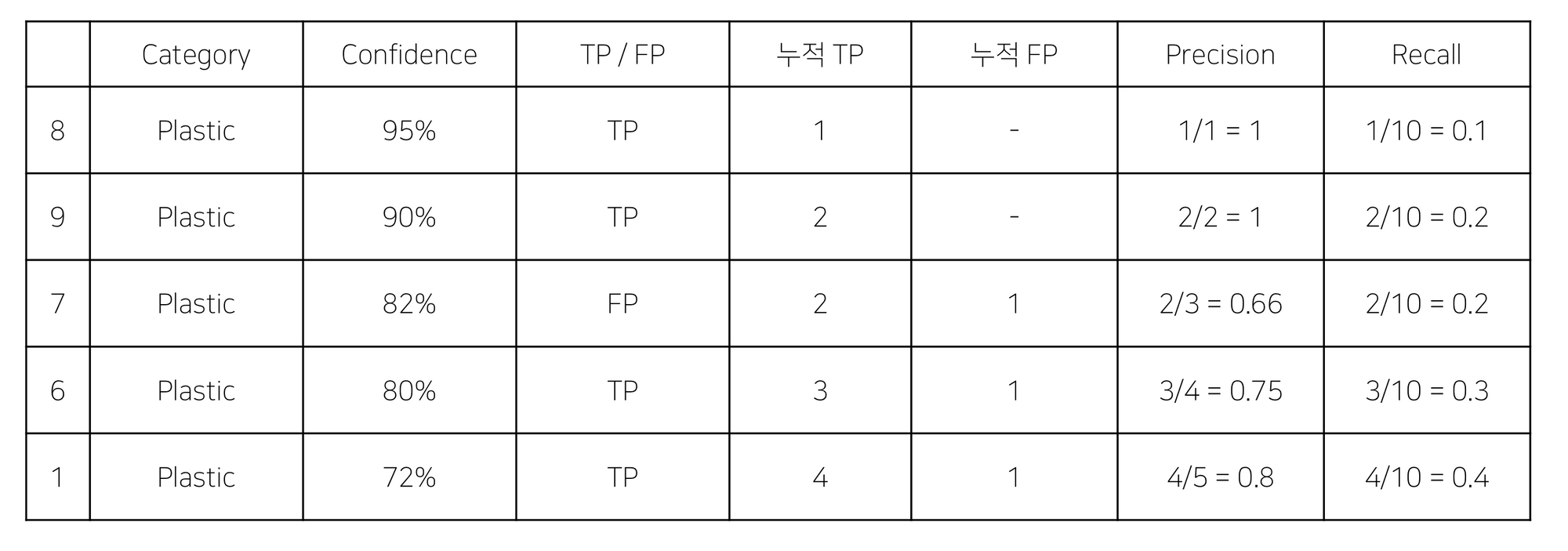
PR curve는 confidence가 높은 순서대로 정렬하고 점수가 높은 순서대로 precision과 recall을 구한다. 여기서 Confidence에 매기는 threshold에 따라 Recall과 precision이 달라질 수 있다는 것을 알아두자
-
이 경우에는 threshold 70
-
그러면 x축은 recall, y축은 confidence로 해서 plot을 찍고 pr curve를 단조적으로 감소하는 그래프로 만든다.
-
그 후에 그래프 밑의 면적을 구하면 AP이다.
-
그 후에 각 클래스별 AP를 구하고 이를 평균내면 mAP이다.
-
[2강] 2 Stage detectors – RCNN, SPP, FastRCNN, FasterRCNN
-
SPP(RoI Pooling)에 대해 완벽하게 이해하고 있는가?
-
roi pooling은 fast rcnn에서 원하는 위치의 feature를 max pooling하기 위한 Layer다→고정된 벡터를 얻고 강제 warping을 하지 않는다.
-

-
-
RoI projection에 대해 완벽하게 이해할 수 있는가?
- 원래 이미지에서 뽑은 region proposal을 feature map에다가 projection하는 것이다.
-
FasterRCNN중 RPN에 대해 완벽하게 이해하고 있는가?
-
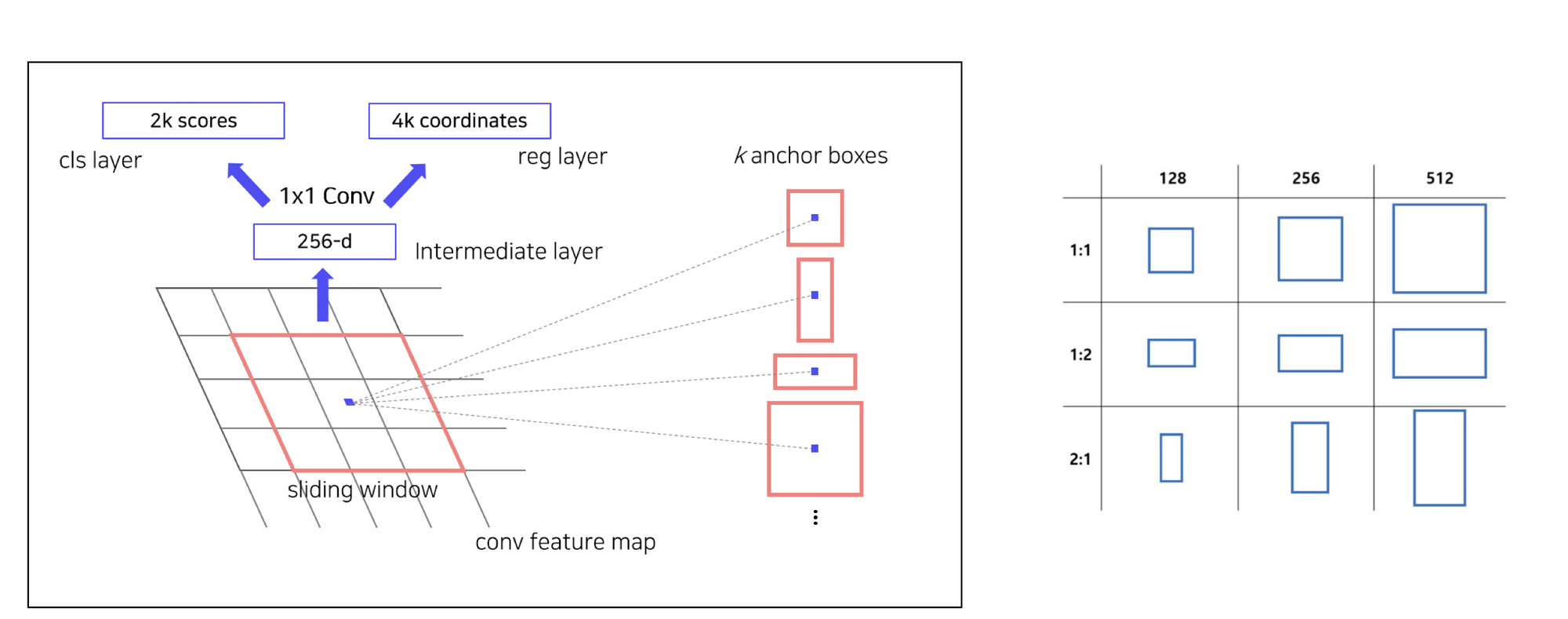
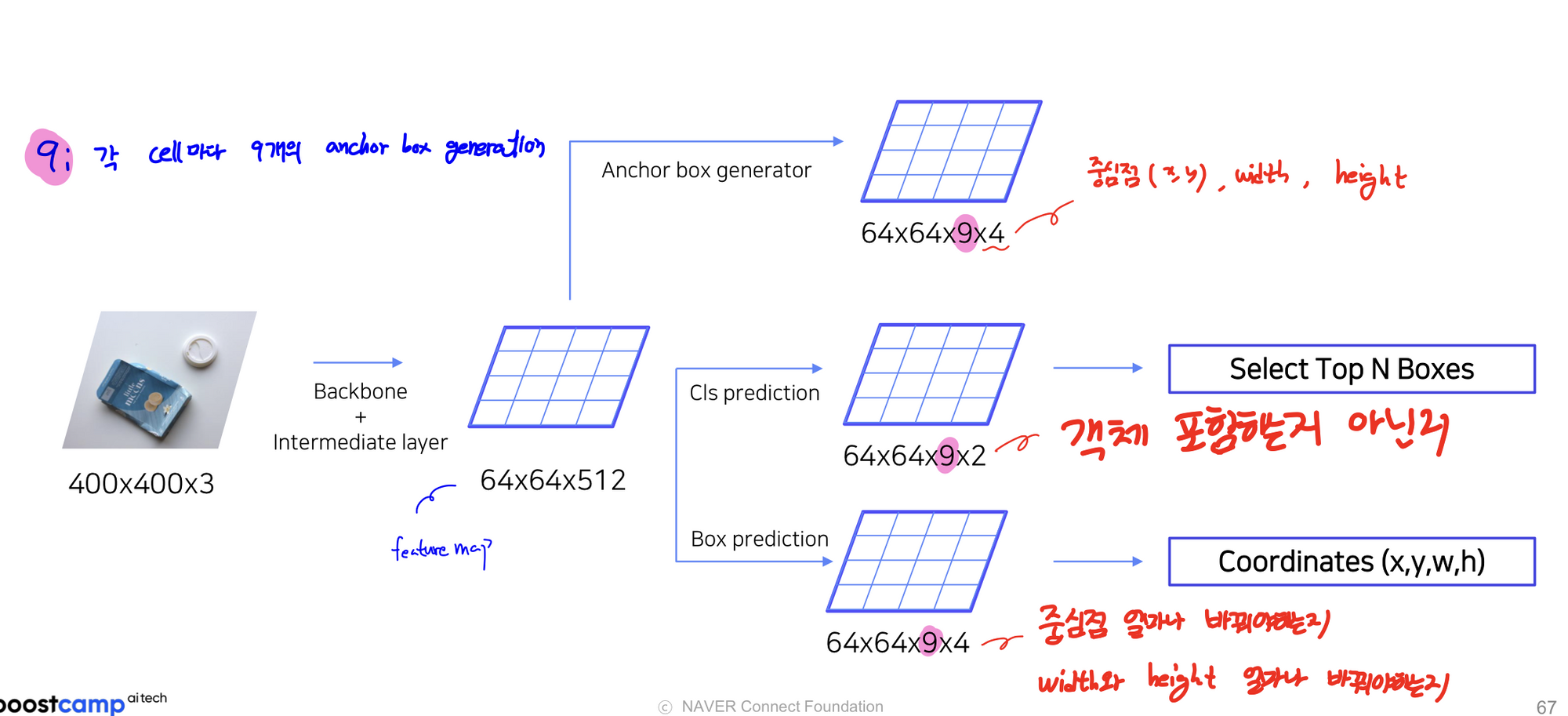
기존에 fast rcnn은 selective search(Cpu연산)로 Region proposal을 했기 때문에 end to end가 아니었다. region proposal하는것도 network로 만들어서 학습시키자해서 나온 개념이다. rpn으로 통해 roi를 계산하고 anchor box개념을 사용한다.
-
hxwx512의 Feture map을 1x1 conv를 통해 binary classification head(hxwx18)와 bbox regression head(hxwx36)로 나눔
-
-
-
Anchorbox에 이해하고 있는가?
- feature map의 한 픽셀에 대해 미리 정해진 크기와 박스를 후보군으로 넣는것
-
RPN의 역할에 대해 이해하고 있는가?
- region proposal을 해준다. 하지만 전과 다르게 박스의 coordinate와 객체인지 아닌지가 학습됨
[3강] MMDetection, Detectron2
MMDetection이든 Detectron2이든 Scratch든 새로운 모델에 대해 코드를 짤 수 있는가?Through Competition !!!
[4강] FPN, PANet, RFP, BiFPN, NasFPN, AugFPN
- Neck의 역할에 대해 완벽하게 이해하고 있는가?
- 다양한 크기를 더 잘 탐지할 수 있고, high level, low lever feature간의 단점을 보완해준다.
- FPN, PANet에 대해 완벽하게 이해하고 있는가?
- FPN: high level에서 low level로 sematic 정보를 전달하기 위해 top down path way를 추가했다. backbone의 정보를 top down과 합치기 위해 lateral connection을 했다. 이 과정에서 top down할 때 upsampling과정이 있음
- PANet: low level의 feature 정보가 high로 전달되지 않아 bottom up path를 추가했다. +
- Adaptive feature pooling: bottom up 올라갈때
[5강] Yolo, SSD, RetinaNet
-
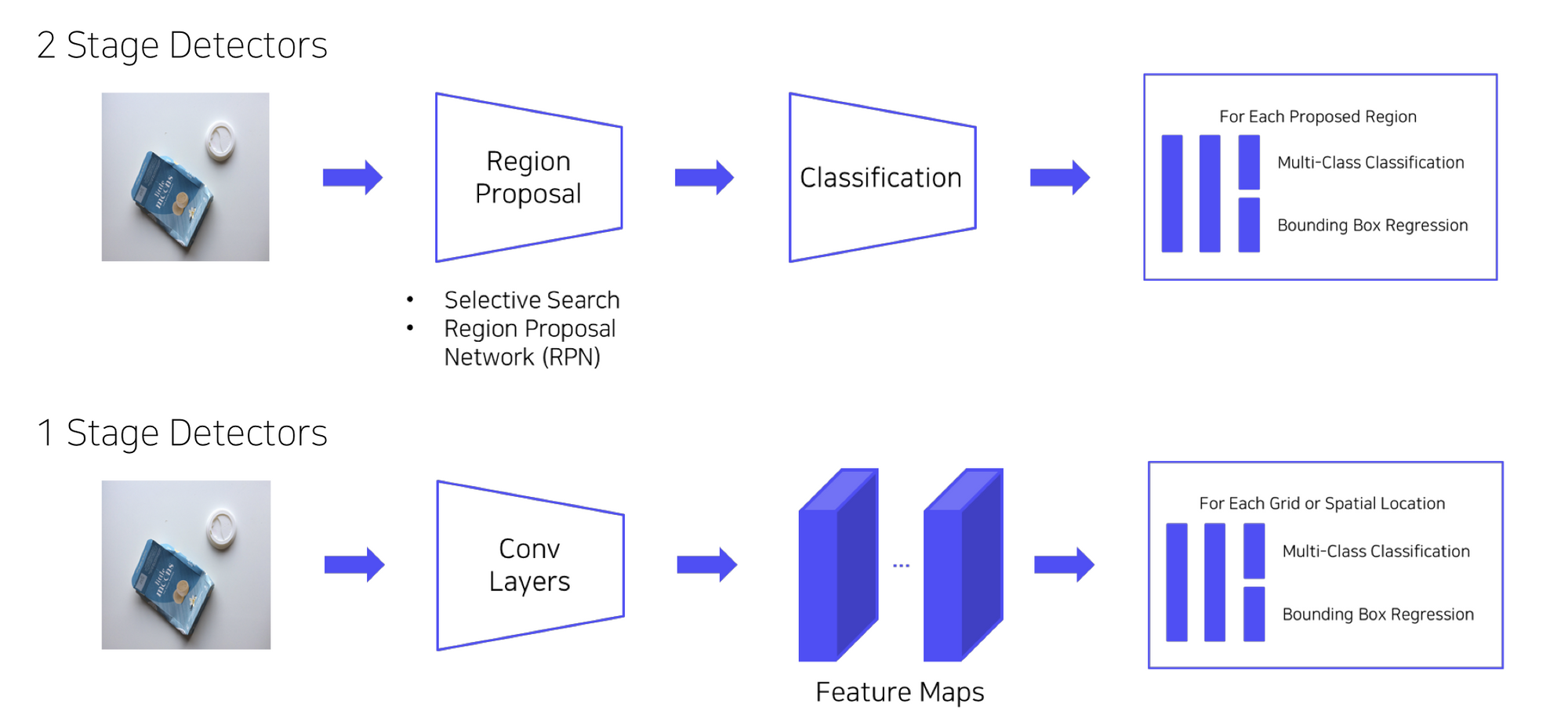
2 stage와는 다르게 RPN이 없는 1 stage에서 어떻게 박스를 예측하는지 이해하고 있는가?
-
-
region proposal을 하지 않고 바로 Localization과 classification이 동시에 진행된다.
-
영역을 추출하지 않고 전체 이미지를 보기 때문에 객체에 대한 맥락적 이해가 높다
-
rpn도 어떻게보면 1stage detector, 하지만 classification 안함
-
-
Yolo v1에 대해 완벽하게 이해하고 있는가?
- SxS grid로 나누고 각 그리드 영역마다 B개(2)의 bounding box와 confidence score 계산
- 각그리드 영역마다 C개의 클래스에 대한 해당 클래스일 확률 계산
- 이를 종합해 final detection→(5(x, y, w, h, score)x2(B:그리드별2개 bbox) + 20(class개수))
-
SSD
-
yolov1은 그리드보다 작은 크기의 물체를 검출할 수 없고, 마지막 feature만 사용해 부정확하고 + Fc layer사용해 느림
→ conv layer에 있는 모든 feature map에 대해 detection, fc layer대신 conv layer, anchor box사용(yolov1는 박스 랜덤)
-
multi scale feature maps: 각 feature map에서 nxnx(#default box x (offset+#class))예측→ 8732 Bbox
-
-
yolo v2
- 데이터 많이사용 + 효율적인 backbone구조
-
Retinanet
- imbalance문제 → focal loss
[6강] EfficientDet
- EfficientDet의 등장 배경 및 Compound scaling의 중요성에 대해 설명할 수 있는가?
- efficientnet
- 배경: 높은 정확도와 효율성을 가지면서 convnet의 크기를 키우는 방법은 없을까?→ efficientnet팀의 연구는 width depth resolution차원에서 균형을 맞춰야한다는 것이 중요하다는 것을 보여주었고 이러한 균형은 일정한 비율로 확장하여 달성했다.
- 결과: 적은 FLops로 높은 mAP를 달성했다.
- width scale: wide모델은 미세한 특징을 잘찾지만 sematic한 특징을 못찾음
- Depth sclae: 풍부하고 복잡한 특징을 찾을 수 있지만 gradient vanishing문제가 있음
- resolution scaling: 높은 해상도의 이미지를 이용하면 미세한 패턴을 잘 잡아낼 수 있음
- → 폭, 깊이, 해상도를 키우면 정확도가 향상되나 큰 모델에 대해 향상 정도는 감소한다.
- EfficientDet
- 자원의 제약이 있는 상태에서 높은 정확도화 효율성을 가진 detection?
- Efficient multi scale feature fusion
- 원래 neck에서는 simpe summation→ feature map을 그냥 단순합하는게 맞나?
- → weight를 줘서 weighted featue fusion방법으로 bifpn학습
- 효율적인 설계를함(자세히는좀..)
- model scaling
- hint-efficientnet
- 기존 연구는 large backbone + image size에 집중
- efficientnet b0~b6를 backbone으로 사용
- bifpn network
- 네트워크의 width와 depth를 compound 계수에 따라 증가시킴
- efficientnet
참고: 부스트캠프 ai tech 9주차 강의 object detection
출처가 명시되지 않은 모든 이미지의 지식재산권은 네이버 커넥트에 귀속됩니다.
