Accuracy, Precision, Recall
데이터 분석으로 심부전증을 예방할 수 있을까?
참고 논문
Davide Chicco, Giuseppe Jurman: Machine learning can predict survival of patients with heart failure from serum creatinine and ejection fraction alone. BMC Medical Informatics and Decision Making 20, 16 (2020).
https://doi.org/10.1186/s12911-020-1023-5
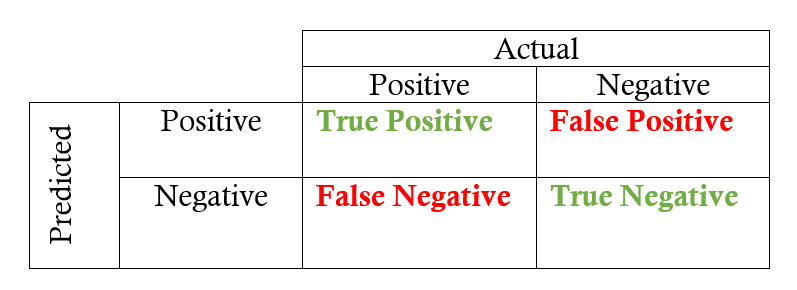
| Prediction\Label | True | False |
|---|---|---|
| True | TP | FP |
| False | FN | TN |
예측이 참이고 실제값도 참일 때 -> True Positive
예측이 참이고 실제값은 거짓일 때 -> True Negative
예측이 거짓이고 실제값은 참일 때 -> False Negative
예측이 거짓이고 실제값도 거짓일 때 -> False Positive
- Accuracy = TP+FP / TP+ TN + FN +FP
- Precision = TP / TP + FP
- Recall = TP/ TP + FN
Accuracy는 말 그대로 정확도, 실제 모델이 정확하게 결과를 맞춘 케이스
Precision은 거짓이라 예측하였으나 참 + 실제 참을 맞힌 경우 중 실제 참인 경우
Recall은 모델이 참이라 에측하였으나 거짓 + 실제 참을 맞힌 경우 중 실제 참인 경우
의료 데이터에서는 Precision과 Recall중 어느 것이 더 중요할까?
recall 이 더 중요하다.
그 이유는 모델이 질병에 양성이라고 판단하였으나 실제로는 음성이라면 다행이지만 모델이 질병에 음성이라고 판단하여 추가 검사를 진행하지 않았는데 실제로는 양성이라면 문제가 되기 때문이다.
하지만 recall을 높이는데 모델을 편중시키는 것은 좋지 않다. 일단 전부 True 라고 판단해 버리면 recall값은 100으로 만들 수 있기 때문.
그렇기 때문에 recall을 최대치로 만드는 와중에 높은 precision을 유지할 필요가 있다.
Library Usage
sklearn.preprocessing StandardScaler
from sklearn.preprocessing import StandardScaler
# 수치형 입력 데이터를 전처리하고 입력 데이터 통합하기
scaler = StandardScaler()
scaler.fit(X_num)
X_scaled = scaler.transform(X_num)
X_scaled = pd.DataFrame(data=X_scaled, index = X_num.index, columns = X_num.columns)
X = pd.concat([X_scaled, X_cat], axis= 1) #axis = 1 을 해줘야 column을 합침 안하면 row 합침DataFrame 객체가 scaler.fit을 통과하면 numpy 객체가 된다.
그렇기 때문에 index와 column 정보가 사라지게 된다.
그래서 scaler.fit을 통해 수치형 입력 데이터를 전처리 해준후에 다시 DataFrame으로 감싸주면서 index와 column 정보를 다시 붙여준다.
예외 상황이 있을 수 있다.
