One-hot vector, Multicollinearity
우리 애는 머리는 좋은데, 공부를 안해서 그래요
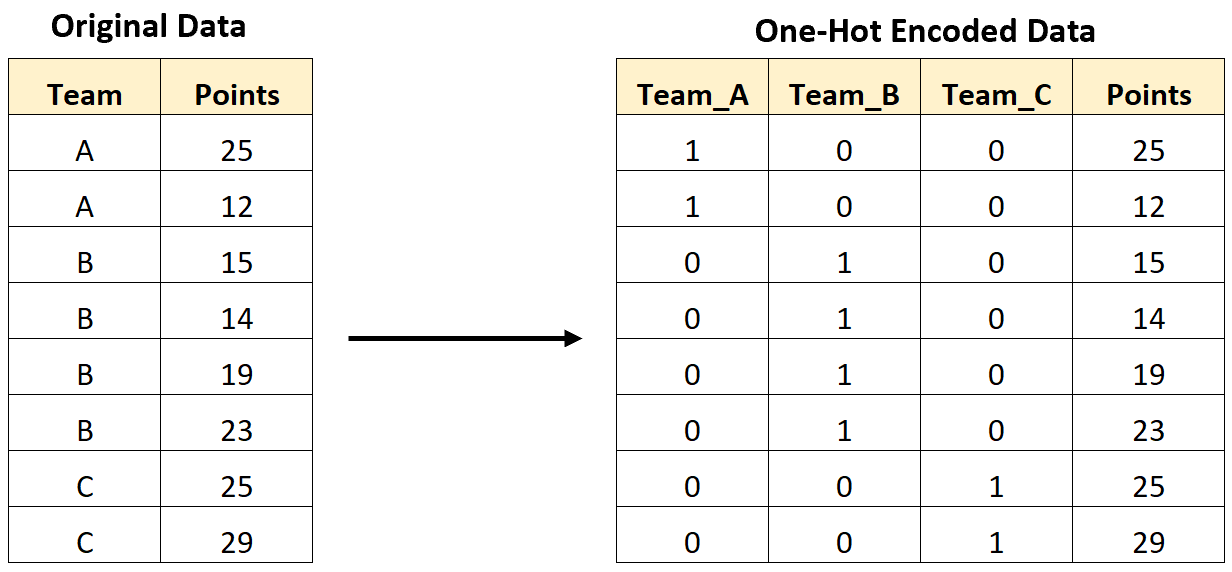
pandas의 get_dummies()를 이용하여 범주형 데이터를 one-hot 벡터로 변환한다.
import pandas as pd
# pd.get_dummies()를 이용해 범주형 데이터를 one-hot 벡터로 변환하기
# Hint) Multicollinearity를 피하기 위해 drop_first=True로 설정
X = pd.get_dummies(df.drop(['ParentschoolSatisfaction', 'Class', 'Class_value'], axis=1), columns=['gender', 'NationalITy', 'PlaceofBirth', 'StageID', 'GradeID',
'SectionID', 'Topic', 'Semester', 'Relation',
'ParentAnsweringSurvey','StudentAbsenceDays'],
drop_first=True)
y = df['Class']One-hot vector란?
One-hot encoding/vector는 데이터를 쉽게 중복 없이 표현할 때 사용하는 형식이다.
과정:
1. 각 단어에 고유한 인덱스 부여
2. 표현하고 싶은 단어의 인덱스에 1을 나머지에는 0을 입력.
예시)
선호 색상이 빨강 파랑 초록 중 하나일 때
선호색 = '빨강'
보다 [빨강, 파랑, 초록] 의 인덱스를 제공하고
빨강 선호 -> [1,0,0]
초록 선호 -> [0,0,1]
이런 식으로 표현 해 주는게 컴퓨터에게 더 편하다.
하지만 단어의 속성이 벡터에 반영되지 않고 아이템이 많을 때 size가 크게 늘어난다는 단점이 존재함.
Multicollinearity란?
우리말로는 다중공선성문제라고도 함
독립변수들 간에 강한 상관관계가 나타나는 문제
범주형 데이터들은 서로 collinear하기 때문에 Multicollinearity를 야기할 수 있음.
그렇기 때문에 첫번째 index를 drop함으로써 원래 데이터의 대칭성을 깨뜨릴 수 있고, 이를 통해 linear classification이나 linear regression 모델의 편중을 유도한다.
