
기초 ML 학습에 있어 어제는 선형대수, 금일 학습 내용은 확률이다.
데브코스 이전 그동안은 데이터 분석 관련 학습들을 쭉 진행해왔기에 기본적인 통계적 유의성, 통계적 가설검정은 물론 확률 이론도 기초는 갖춘 상황.
이전과 마찬가지로 remind & 추가 학습 내용에 대해서만 정리할 계획.
✅ Probability
확률의 개념 부터 살펴보면, 집합 S의 부분집합(사건)을 실수값에 대응시키는 함수를 의미.
이때 집합 S는 발생할 수 있는 모든 사건의 경우의 수를 뜻하게 된다.이때 확률변수 X는 집합 S 내 원소들을 의미하게 된다.
누적분포함수 F(x)를 가진 확률변수 X에 대해 다음을 만족하는 f(x)가 존재한다면 X를 연속확률 변수라 부르고 f(x)를 X의 확률밀도함수 라고 부른다.
이외에도 이산확률분포도 존재하는데 뭐 적분하냐 안하냐 이 차이라 생략. (연속이냐 아니냐)
Covariance : 2개의 확률변수 사이의 선형관계를 표현. (공분산이 0보다 큰 지 작은 지에 따라 두 변수가 양, 음의 선형관계를 나타낸다고 판단할 수 있다.) 만일 cov(x, y) = 0인 경우 두 변수 사이의 상관관계가 없다고 확인할 수 있지만, 독립이라고는 판단할 순 없다. (ex. y = x^2)
따라서 공분산은 변수 간 서로 얼마나 의존하는가 즉, X가 평균으로부터 증가, 감소하는 경향이 있을 때 타 변수가 얼마나 이를 따라가는가를 수치화한 지표이다.
🎈 Bayesian
알아야 하는 기본적인 확률로는 베이즈 확률이 존재한다.
posterior(사후확률) = likelihood(가능도) * prior(사전확률) / normalization(X의 경계확률)
-> 각 변수를 자세히 살펴보면 다음과 같다.
- posterior : 특정 결과(B)가 발생했다는 조건 하의 원인(A)이 발생한 확률
- likelihood : 원인(A) 발생 하에 결과(B)가 발생할 확률
- normalization : 결과가 발생할 확률
- prior : 원인(A) 발생할 확률
-> 사실 간단히 얘기하면, P(A|B)를 의미하는 것으로, B라는 결과가 나오기에 A라는 원인의 발생 확률을 구하는 것과 동일하다.이러한 베이지안 관점의 장점으로는 prior를 모델에 포함시킴으로써 극단적인 확률을 회피할 수 있게 된다. (데이터 크기가 커짐에 따라 평균으로 회귀하는 특성을 갖게 됌.)
이와 반대되는 개념이 이제 MLE라고 볼 수 있다.
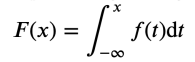
✅ Probability Distribution
확률분포란, 확률변수 X가 특정 값을 가질 확률을 나타낸 함수를 의미한다.
확률분포 종류로는 베르누이, 이항, 베타, 다항, 디리클레, 가우시안 등등 상당히 많은데 이러한 확률분포 등을 통해 모델링이 가능하고, test data 들에 대해 예측을 할 수 있게 된다.
확률분포는 크게 이산확률분포, 연속확률분포로 나뉜다.
- 이산확률분포 : 확률 질량 함수로 분포 표현이 가능하며 예시로 푸아송, 베르누이, 기하, 이항, 다항이 있다.
- 연속확률분포 : 확률 밀도 함수로 분포 표현이 가능하며 정규분포, 카이제곱, 감마가 있다.
각 분포에 대해 기본적인 개념을 살펴보면 다음과 같다.
- 베르누이 분포 : 이항분포의 확장 버전으로 총 n번 중 특정 사건이 i번 일어날 확률을 의미
- 초기하 분포 : 이항분포는 시행횟수와 관계 없이 확률이 일정하지만, 기하분포는 줄어드는 모집단의 크기를 적용하여 분포로 표현한 방법.
- 포아송 분포 : 일정 조건 내 발생확률이 아주 낮은 확률변수가 갖는 분포로 발생하지 않은 사건에 대해 알 수 없을 때 유용하다.
- 지수분포 : 포아송분포에서 한 사건이 일어난 후 다음 사건 일어날 때까지 필요한 시간이 따르는 분포.
- 감마분포 : 지수분포에서 파생된 것으로, r번째 발생할 때까지 필요한 시간이 따르는 분포를 의미.
가우시안 분포 : 정보이론 내 엔트로피를 최대화시키는 확률 분포로 중심극한정리를 따른다.우도함수 : x값을 N번 관찰한 결과에서 각 x가 p(x|u)에서 뽑혀지면,
위와 같이 표기
디리클레 분포는 다항분포를 확장한 버전으로 토픽 모델링인 LDA내 모수 추정에 사용되는 분포.
이렇게 보면, 강의 내용을 기반으로 작성을 하긴 했으나 확률 이론이든, 선형 대수든 가장 중요한 것은 주어진 이론만 보고 넘어가는 것이 아닌 이해를 통해 '아 이래서 이러한 성질을 갖는구나'를 알고 넘어가는 것이 오래 기억에 남고 결국 자신에게 무기가 될 수 있다.

항상 좋은 글 감사합니다.