
✅ Spark-Streaming
- 실시간 데이터 스트림 처리를 위한 Spark API
- kafka, kinesis, flume, TCP 소켓 등의 다양한 소스에서 발생하는 데이터 처리 가능
- JOIN, MAP, REDUCE, WINDOW와 같은 고급 함수 사용 가능
동작 방식은 다음과 같다.
- 데이터 : micro batch 처리로 읽기 (해당 과정 loop)
- 읽어온 데이터를 앞서 읽은 데이터와 병합
- batch마다 데이터 인덱스 관리 (start, end)
- Fault Tolerance와 데이터 재처리 관리
구체적으로 내부동작을 이야기하면 다음과 같다.
-> 실시간 입력 데이터 스트림을 micro batch로 나눈 후 spark engine에서 처리해 최종 결과 스트림을 일괄적으로 생성 (data stream, structured streaming 2 종류 존재)
🎈 source (Input)
kafka, amazon kinesis, apache flume, TCP/IP 소켓, HDFS, File 등 spark structured streaming에서 처리할 수 있도록 함.
- spark dataframe으로 변환. (kafka에서 spark structured streaming으로 데이터를 수집하는 경우, kafka source를 사용해 kafka 클러스터에서 하나 이상의 토픽에서 데이터를 가져와 DF로 변환!)
lines_df = spark.readStream \ .format("socket") \ .option("host", "localhost") \ .option("port", "9999") \ .load()🎈 sink (Output)
- sss에서 처리된 데이터를 외부 시스템, storage로 출력되도록 함.
- 변환되거나 집계된 데이터를 어떻게 쓰이거나 소비되는지 정의 (kafka sink를 사용해 sss에서 처리된 데이터를 topic으로 쓰는 것이 가능)
- OutputMode : 현재 micro batch 결과가 sink에 어떻게 쓰일지 결정.
word_count_query = counts_df.writeStream \ .format("console") \ .outputMode("complete") \ .option("checkpointLocation", "chk-point-dir") \ .start()🎈 micro batch trigger option
하나의 batch 이후 다음 batch가 자동적으로 읽어내기 위해선, 다음과 같은 트리거 옵션 설정 必
- unspecified 디폴트 모드 : 현재 micro batch 끝나면 다음 batch 시작
- time interval : 고정된 시간마다 micro batch 시작 (읽을 데이터 X -> 시작 X)
- one time : available-now (지금있는 데이터 모두 처리 후 중단)
- continuous : 새로운 저지연 연속 처리 모드에서 실행 (아직 베타)
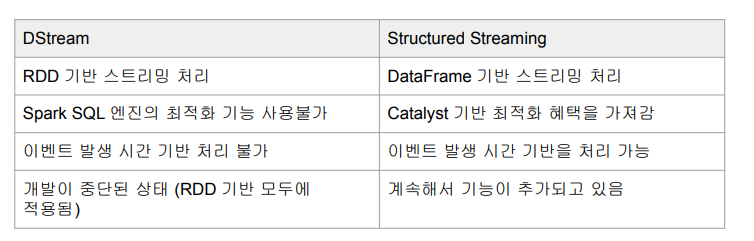
✅ reminder
🎈 local standalone spark
- spark cluster manager로 local[*] 지정 (컴퓨터 내 cpu 수만큼 쓰레드 생성)
- 주로 개발이나 간단한 테스트 용도
- 하나의 JVM에서 모든 프로세스 실행 (하나의 driver, 하나의 executor가 실행)
- executor 안에 생성되는 쓰레드 수
-> JDK8/11 필요.

To be a DataScientist