
이번 주차 학습 내용은 머신러닝 ML
이쪽 분야는 기존에 DA 프로젝트들과 학부 강의를 통해 상대적으로 DE에 비해 좀 더 빠삭하긴 하다.
따라서 학습하면서 이론적인 내용보다는 알아두면 좋은 점, Remind할 부분 등을 작성할 계획.
✅ ML
모델링 이전, 전처리 과정은 다음과 같다.
- 데이터 수집 이후 전처리 과정에서 분포 확인, 결측치 확인, 데이터 타입 확인 필요.
-> 이 과정을 통해 인사이트 발견 가능. (outlier 탐지도 가능)- seed42로 train/test split 진행 (stratified sampling 통해 skew 해결)
- 훈련데이터 EDA를 통해 인사이트 도출 (상관관계, 파생변수 생성 등)
- 범주형, 문자형 데이터 -> 인코딩 처리 or CATBoost 모델링
- 이후 스케일링 처리 후 pipeline 구축
모델링 이전, 데이터로부터 인사이트를 도출해 feature engineering을 실시함으로써 모델 성능을 개선할 수 있다.
모델링 과정은 다음과 같다.
- 모델 학습 후 cross-validation으로 검증
- gridsearchCV 활용해 최적의 hyperparameter 탐색
- 테스트 셋 예측 후 평가
-> 상용환경에 배포하기 위해 데이터 전처리와 모델의 예측이 포함된 파이프라인 생성하여 저장🎈 why ML need probablity?
- 확률이론 : 예측값의 불확실성을 정량화시켜 표현할 수 있는 수학적인 프레임워크 제공
- 결정이론 : 확률적 표현을 바탕으로 최적의 예측을 수행할 수 있는 방법론 제공
정규화를 통해 overfitting, underfitting 문제 해결 必
✅ predict delivery time
음식 배달 시간을 정확히 예측하되 동시에 under-prediction을 최소화하는 것이 목표
배달 시간에 영향 주는 요소
- 주문시간, 지역, 식당 속성, 주문 속성(음식 수)
column 특성
- market_id : 배달 이루어지는 지역 ID
- created_at : 주문 생성 시간 ts
- actual_delivery_time : 주문자가 배달 받은 시간의 ts
- store_id : 식당 ID
- store_primary_category : 식당 카테고리
- order_protocol : 주문 받을 수 있는 방식을 나타낸 ID
- total_onshift : 주문 생성 시 가게로부터 10마일 이내 있는 배달원 수
- total_busy : 위 배달원 중 주문에 관여하고 있는 사람 수
- total_outstanding_orders : 주문한 가게로부터 10마일 이내 타 주문 수
- estimated_order_place_duration : 식당이 주문 받을 때까지 걸릴 것으로 예상되는 시간
- estimated_store_to_consumer_driving_duration : 식당에서 출발해 주문지에 도착할 때까지 걸릴 것으로 예측되는 시간.
✍️ best-practice
🎈 Data Insight
- make a target for prediction : real_delivery_time = actual_delivery_time - create_at (by seconds)
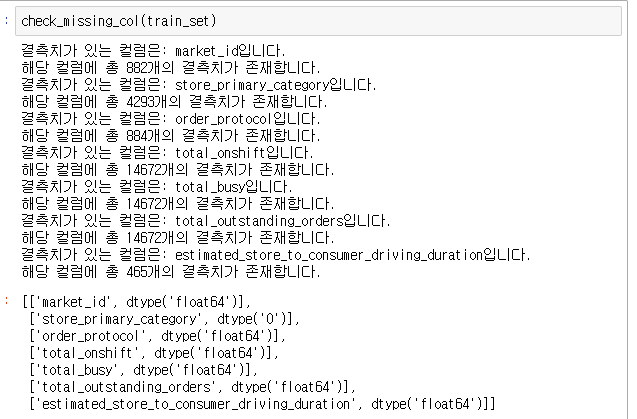
- To check for missing values using the code below
def check_missing_values(df): missing_col = [] counted_missing_col = 0 for i, col in enumerate(df.columns): missing_values = sum(df[col].isna()) is_missing = True if missing_values >= 1 else False if is_missing: counted_missing_col += 1 print(f"결측치가 있는 컬럼은: {col}입니다.") print(f"해당 컬럼에 총 {missing_values}개의 결측치가 존재합니다.") missing_col.append([col, df[col],dtype]) if counted_missing_col == 0: print("결측치가 존재하지 않습니다.") return missing_col
✍️ How to fill the missing values ?
- Fill in missing values by making predictions. However, this operation is difficult to apply to categorical variables.
- If columns fill in missing values by mean or median, the prediction may not be accurate.
-> So, I will try prediction missing values in numeric columns after removing all rows that only categorical columns with missing values.
-> It may be not exactly analytics....-> My Methods : Try EDA of train data set to fill missing values in numeric columns.ㄴ
- target variable : I just said before, real_delivery_time
- I need to minimize two evaluation metrics (RMSE, ratio of under-prediction : # of under-prediction / len of test data)
-> under-prediction : actual delivery time takes longer than predicted.
Get ✨ Insights from EDA
The result of taking EDA only for columns with missing values is as follows.
- market_id : 437s are missing values and discrete variables -> delete
- order_protocol : 431s are missing values and discrete variables -> delete
- total_# : 14182s are missing values and continuous variables -> delete
-> Because These columns can be related to target.

To be a DataScientist

잘봤습니다. 좋은 글 감사합니다.