✅ Regularization
: Generalization이 잘 되도록, 학습에 반대되는 쪽으로 규제를 거는 것으로 학습 데이터뿐만 아니라 test set에도 잘 적용되게 만들어주는 것
-
1) ✍️ Early Stopping
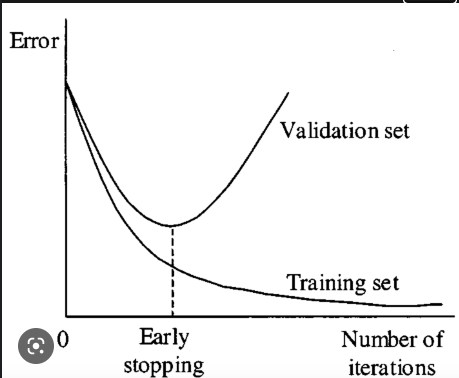 test 데이터는 사용할 수 없으므로, train data와 validation data를 학습시키면서 진행되는 iteration 속에서 error 간격이 벌어지는 시점에 조기 중단
test 데이터는 사용할 수 없으므로, train data와 validation data를 학습시키면서 진행되는 iteration 속에서 error 간격이 벌어지는 시점에 조기 중단 -
2) ✍️ Parameter Norm Penalty
NN 파라미터가 너무 커지지 않도록 해주는 것. (네트워크 내 파라미터 가중치의 크기를 줄여 함수를 부드럽게 보자는 의미)
-
3) ✍️ Data Augmentation
데이터가 많아지고 있는 현재 딥러닝 성능이 가장 좋은 것으로 보여진다. 그러나 사용가능한 데이터는 수가 적기에, 주어진 데이터 한도 내에서 데이터를 증강시키는 방법
ex) 이미지 회전, 확대, 전환 등으로 사용 -
4) ✍️ Noise Robustness
입력 데이터, weight에 Noise를 집어넣어 학습한 모델을 가지고 test 단계에 적용하면 결과가 잘 나오는 케이스도 있음
-
5) ✍️ Label Smoothing
train data의 2개를 뽑아 mix-up / cut-mix 등 진행
ex) 2가지 mix-up해 decision boundary 확인
mix-up : 2개의 이미지를 고르고 label, image를 혼합 // cut-out : 일정 영역 제거
cut-mix : 특정 영역만 mix 진행
특히 mix-up 사용 시 성능 향상에 도움. -
6) ✍️ Dropout
neural network의 weight를 0으로 만들어 일부만 학습되도록 진행
-
7) ✍️ Batch Normalization
적용하고자 하는 layer에 statistic을 정규화시키는 것(mean, variance^2)
layer의 깊이가 긴 쪽에서 성능이 올라가는 경향이 있음
