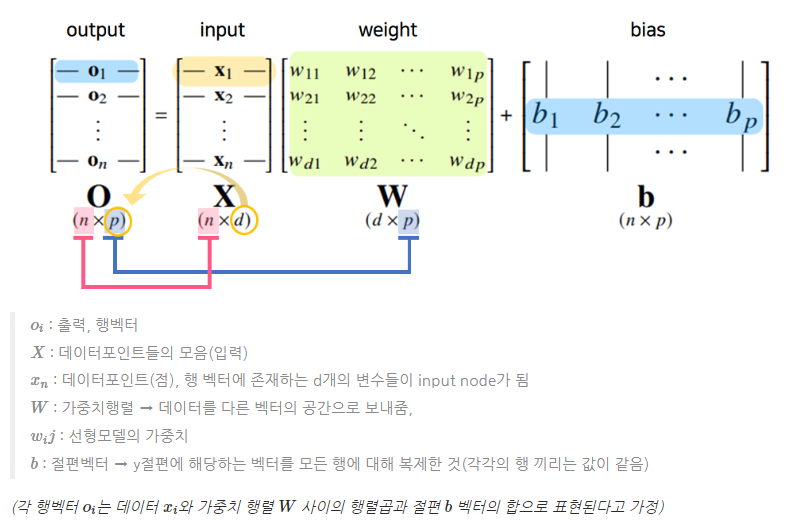
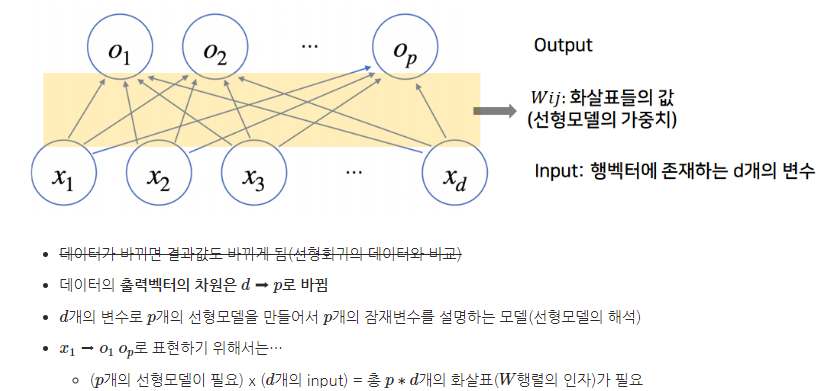
Neural Network
단순 선형 회귀 분석과 같이 선형모델은 복잡한 패턴을 지닌 분류나 회귀문제를 해결할 수 없는 문제가 발생한다. 이를 보완하고자 한 것이 선형모델 + 비선형함수를 가진 비선형모델 즉, 신경망이다.
위 구조를 해석한다면, output vector O에 softmax 함수를 합성하면 확률벡터로 변환되므로 output 내 특정 클래스 k에 속할 확률을 구할 수 있다.
- 그렇다면, softmax를 사용하여 합성하는 이유는 ?
바로 앞서말한 확률벡터로 만들 수 있다는 점이다. 즉, 특정 클래스에 속할 확률 계산을 위해서 사용한다.
softmax
분류문제를 해결하기 위해 반드시 필요한 연산자. 모델의 출력 결과를 확률로 해석할 수 있게 변환해주는 연산.분류문제를 풀 때에는 이 softmax 함수와 선형모델을 결합하여 해결한다. 수식은 다음과 같이 표현할 수 있다.
연산을 이해해보면, 분모에 해당하는 것은 각 출력벡터들의 값에 지수함수를 씌운 값들의 합이고 분자는 각 출력값 성분에 해당하는 값에 지수함수를 씌운 것이다. softmax 함수의 출력값은 원 핫 벡터로 0 또는 1의 출력값만을 가지는 추론문제를 해결하는 데에는 사용하지 않는다.
이를 코드로 구현하면 다음과 같다.
def softmax(vec): # np.max: 오버플로우 방지 denumerator = np.exp(vec - np.max(vec, axis=-1, keepdims=True)) numerator = np.sum(denumerator, axis=-1, keepdims=True) val = denumerator / numerator vec = np.array([[1, 2, 0],[-1, 0, 1],[-10, 0, 10]]) softmax(vec)
- 즉 신경망은 선형모델에 활성함수(비선형함수)를 합성한 함수이다.
Activation function
입력 신호의 총합을 출력신호로 변환해주는 함수
- sigmoid (using for outputlayer)
출력값의 범위는 [0,1]을 가지며 이진분류(Logistic Regression)에 주로 사용된다.
그러나, 입력값이 너무 크거나 작은 경우, 학습이 잘 이루어지지 않고 grdient vanish 문제가 발생하고, zero-centered 문제도 있어 layer가 많을수록 학습이 느려질 수 있는 문제 존재.
- tanh (Hyperbolic tangent function)
출력값의 범위는 [-1, 1]을 가지며 sigmoid가 갖는 zero-centered문제도 해결해준다. 그러나 gradient vanish 문제는 해결하지 못함.
- softmax (using for outputlayer)
input값을 [0,1] 사이의 값으로 모두 정규화하여 출력하며, 출력값들의 총합은 항상 1이 되는 특성을 가진 함수이다. 다중분류(multi-class classification) 문제에서 사용.
- ReLU (Rectified Linear unit function)
Sparsity : 0이하는 0으로 처리해 연산량 줄여주고, gradient vanish 문제 해결, gradient descent 시 타 활성함수에 비해 속도가 매우 빠른 편
- LeakyReLU
기존 ReLU의 입력값이 음수인 경우 뉴런이 죽는 현상을 방지해주는 활성함수
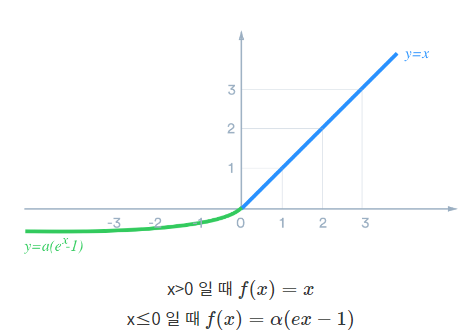
- Exponential Linear Unit(ELU)
비용을 0으로 더 빨리 수렴하고 보다 정확한 결과를 도출해줌. 타 활성함수와 달리 ELU에는 양수여야 하는 상수가 존재. 마이너스 값의 입력을 제외하고 ReLU와 매우 유사
NN 학습 구조
1. 학습할 신경망 구조 선택
2. 모델 제작 및 weight, bias 등 parameter 랜덤 초기화
3. 모델에 input 값 넣어 여러 layer를 거쳐 output 계산
4. forward propagation으로 cost-function 계산 (target - output)
5. weight update 진행 (back propagation을 통해 편미분값 계산 + gradient descent 로 cost-function 최소화)
6. 중지 기준 충족 혹은 비용함수 최소화할 때 까지 3~5단계 반복 단계 한번 진행하는 것을 iteration or epoch라고 함.참고
loss function : 데이터 1개의 error값
cost function : 데이터 전체의 loss의 합
- Back Propogation
원리 : 합성함수의 미분법인 연쇄법칙 기반으로 미분 계산 진행.
각 뉴런에 해당하는 값을 tensor라 부르고 각 tensor는 메모리에 저장되어야만 back propogation 동작 가능하고 순전파보다 메모리 용량 사용 多
신경망을 여러층 쌓으면 MLP, MLP(Multi-Layer Perceptron)를 사용하여 학습하는 것이 Deep-Learning
- 층을 여러 개 쌓는 이유 ?
- 층이 깊을수록 목적함수를 근사하는데 필요한 뉴런 숫자가 훨씬 빠르게 줄어들어 효율적인 학습 가능.
- 층이 깊으면 적은 파라미터로 훨씬 복잡한 함수 표현 가능
- 층이 깊어져 최적화에 더 많은 노력(학습, 계산 비용 등) 必
최종 목적
딥러닝 학습 시 각 weight matrix에 대한 gradient vector를 SGD(Stochastic Gradinet Descent)사용해 각 parameter들을 mini-batch로 번갈아가며 학습
--> 신경망 학습의 최종목적은 cost를 0에 근사시키는 parameter (weight, bias)를 찾는 것
