1. Multi-Cycle Implementation
-
The disadvantages of Single-Cycle implementation
- Longest delay determines clock period.
-> Inefficient hardware utilization (load instruction) - 하나의 Cycle안에서 squential 하게 Datapath가 진행되어야 한다.
-> ALU, Instruction memory, Data memory 등을 동시에 공유해서 사용할 수 없다
- Longest delay determines clock period.
-
Multi-Cycle implementation
- 하나의 명령어가 여러개의 cycle로 나누어진다.
- Example
- R-format instruction (4 cycle) : Instruction fetch → Instruction decode / Register fetch → ALU operation → Register write
- Load instruction (5 cycle) : Instruction fetch → Instruction decode / Register fetch → address computation → memory read → Register write
-
CPI of the Multi-cycle Implementation
- Single-cycle implementation : CPI ↓, clock cycle time ↑
-> CPI : 하나의 Instruction을 수행하는데 필요한 cycle 갯수
-> clock cycle time : 하나의 cycle을 수행하는데 필요한 시간 - Multi-cycle implementation : CPI ↑, clock cycle time ↓
- Example
- Number of clock cycles

- Instruction mix
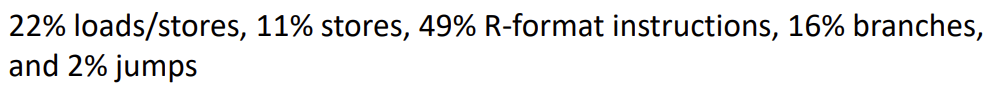
-> CPI : 5 x 0.22 + 4 x 0.11 + 4 x 0.49 + 3 x 0.16 + 3 x 0.02 = 4.04
- Number of clock cycles
- Single-cycle implementation : CPI ↓, clock cycle time ↑
2. Pipelining
-
Definition : Multi-cycle implementation을 사용하지만 여러 단계로 나누어진 명령어들을 중첩하여 실행될 수 있게 병렬화 해줌으로써 CPI을 1로 만들어준다.
-> 하나의 cycle마다 instruction이 수행되는 것처럼 겉으로 보이게 한다.
-> 동시에 수행할 수 있는것들은 가능한 동시에 수행을 하자! -
Example
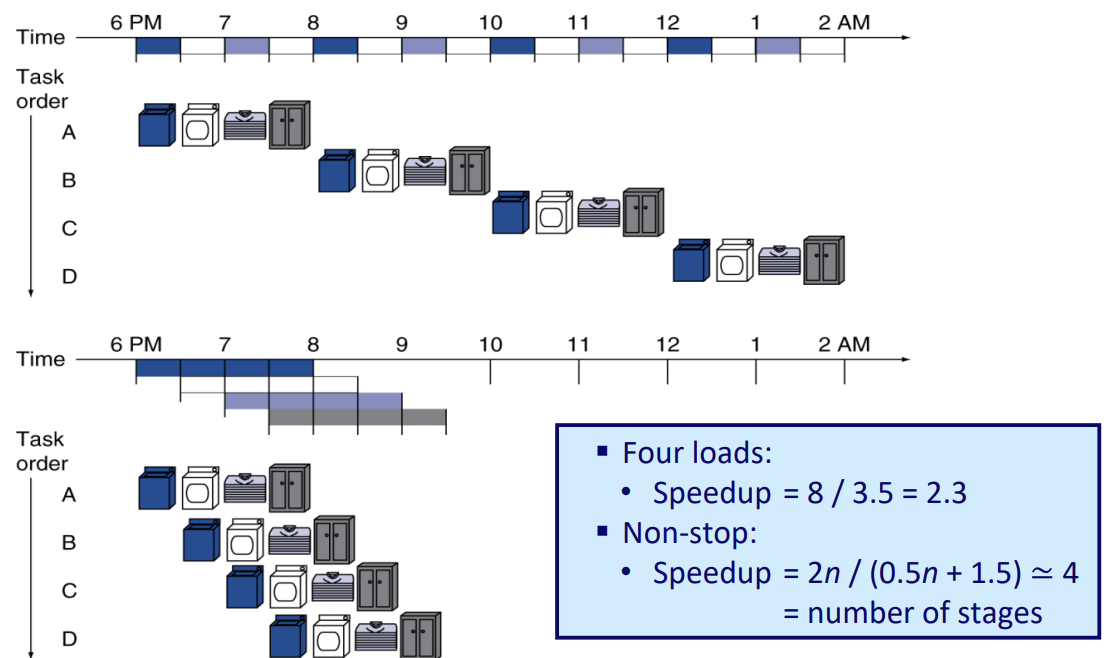
- 하나의 instruction을 독립된 execution unit으로 나눔 -> Multi-cycle implementation!
- Pipelining 사용 이전
- 세탁기에 옷을 넣는다.
- 세탁기 작동이 끝나면 젖은 옷을 건조기에 넣는다.
- 건조기 작동이 끝나면 건조된 옷을 탁자 위에 놓고 접는다.
- 접는 일이 끝나면 옷을 장롱에 넣는다.
- Pipelining 사용 이후
- 첫번째 빨래가 다 돌아가면 건조기에 빨래를 넣고 다시 세탁기에 옷을 집어 넣는다.
- 건조기와 세탁기가 다 돌아가면 건조된 옷을 접고 세탁이 된 빨래를 건조기에 넣고 새로운 빨래를 세탁기에 넣는다.
- 옷을 다 접었으면 옷을 장롱에 넣고 빨래를 개고 건조기에 세탁이 된 옷을 넣고 새로운 빨래를 세탁기에 넣는다.
- 결과 : 매 시간마다 빨래가 완료된 옷들이 장롱에 넣어진다 → 매 cycle마다 instruction이 수행
-> CPI : 1
-> 특정 시간 unit에 4개의 서로 다른 자원을 4개의 operation이 공유해서 실행한다. - stage : 4
-> 하나의 시간 unit에 동시에 수행할 수 있는 execution unit 갯수
-> Power wall로 인해 무한하게 증가시킬 수 없다.
-
Basic Steps Of Execution : 5 stages

-
Pipelined Instruction Execution
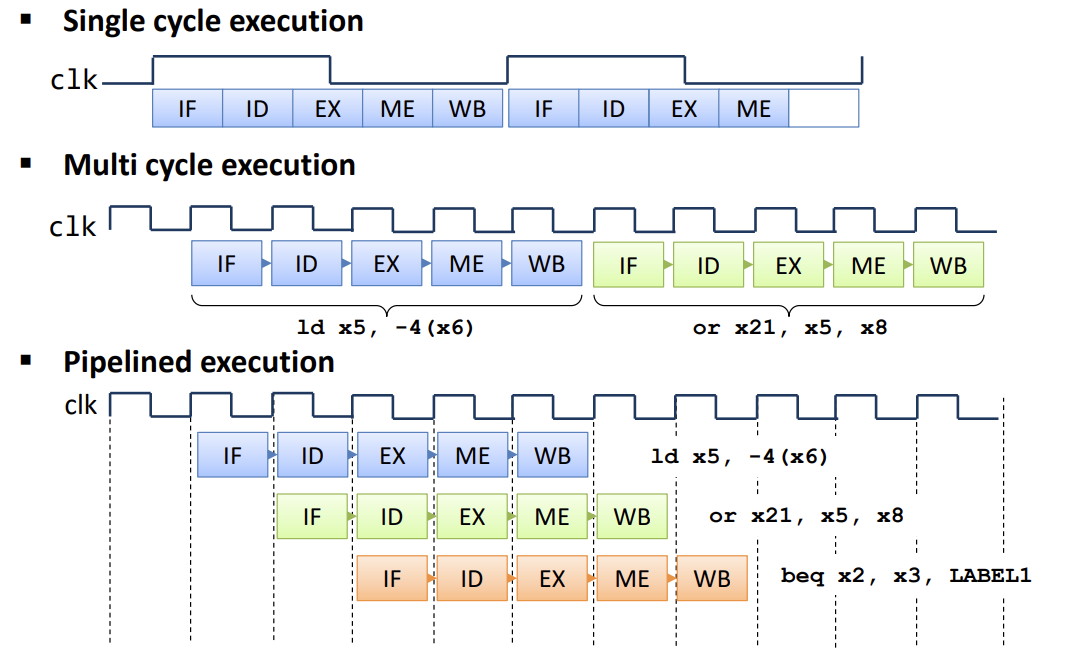
-
Pipeline Performance
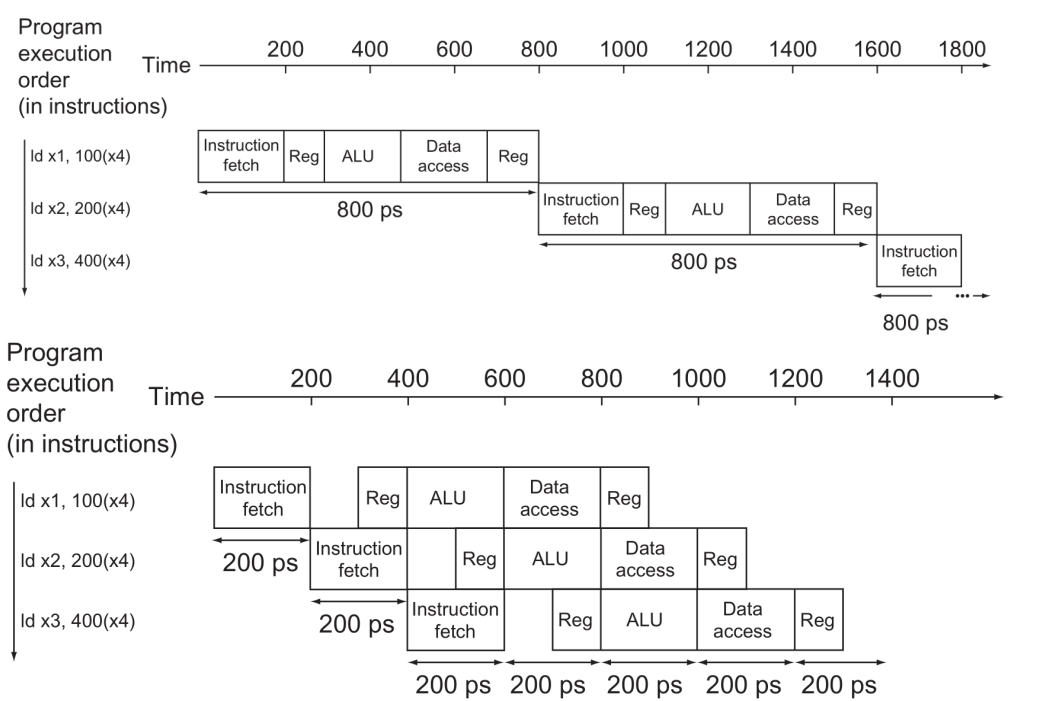
-
Pipeline SpeedUp
- 하나의 Instruction을 수행하는 시간이 줄어드는 것이 아닌 특정 time interval 안에 수행되는 instruction의 갯수가 늘어나는 것이다.
-> Throughput ↑ - All stages are balanced.
-> Pipelining을 효과적으로 수행하기 위해서는 각 Execution unit의 수행 시간을 동일하게 해줌으로써 정확하게 하나의 cycle 안에서 overlapping 할 수 있다.
- 하나의 Instruction을 수행하는 시간이 줄어드는 것이 아닌 특정 time interval 안에 수행되는 instruction의 갯수가 늘어나는 것이다.
-
Pipelining and ISA Design : RISC는 개별 Instruction의 format이 동일하기때문에 Pipelining에 더 유리하다.
-> step을 나누기가 더 쉽다.
3. Computational Example
-
Combinational logic : Computation time
-
Reg : to save result in register
-
Single-cycle implementation
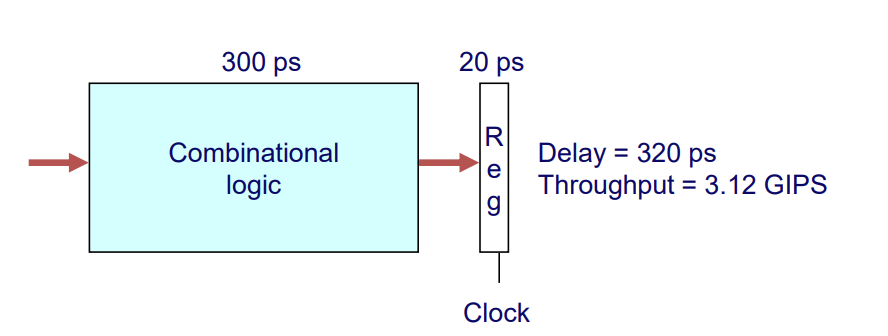
- Delay : 320 ps
- Throughput : 3.12 GIPS
- The percentage of clock cycle spent loading register : 6%
-
3-Way Pipelined Version
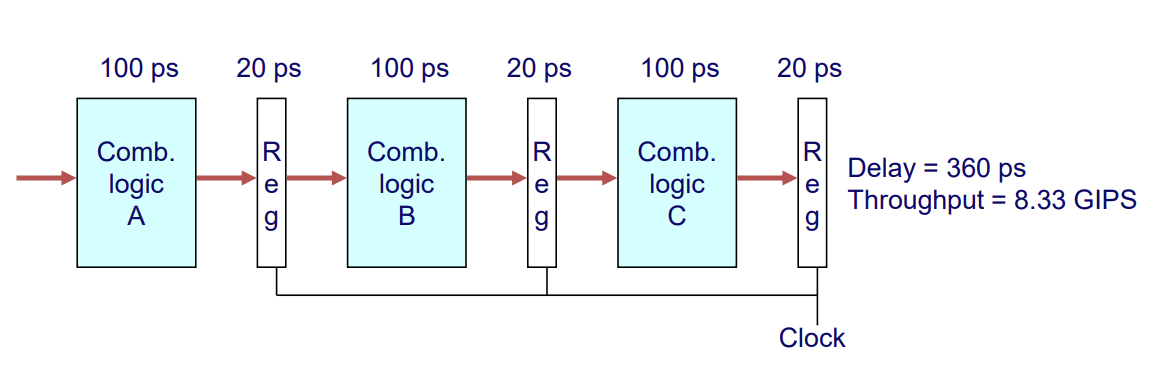
- Delay : 360 ps
-> Overal latency자체는 더 증가했다. - Throughput : 8.33 GIPS
-> 처리율이 더 좋아졌다. - The percentage of clock cycle spent loading register : 16%
- Delay : 360 ps
-
Nonuniform Delays : Stages are unbalanced.
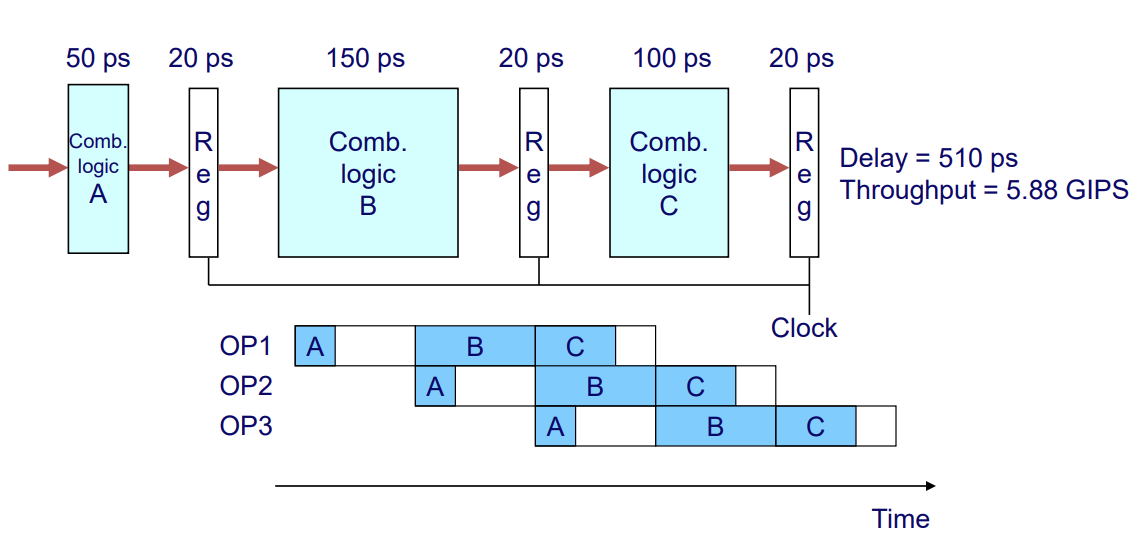
- Delay : 510 ps
-> 가장 큰 stage 시간 기준으로 계산해야 함 - Throughput : 5.88 GIPS
- Delay : 510 ps
-
6-Way Pipelined Version
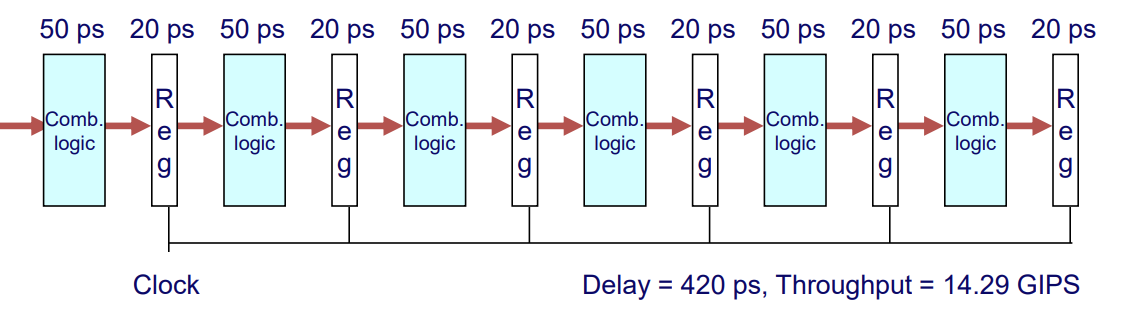
- Delay : 420 ps
- Throughput : 14.29 GIPS
- The percentage of clock cycle spent loading register : 29%
4. Major Hurdles of Pipelining
-
Hazards : 정상적인 pipelining을 방해하는 상황으로 다음 cycle의 다음 명령어가 시작이 불가능한 경우를 말한다.
-> Reduce ideal speedup (CPI = 1)- Structural hazards
- Data hazards
- Control hazards
-
Structural hazards
: 같은 cycle내에서 Hardware resource에 대한 사용 요구를 서로다른 instruction에서 동시에 하는 경우 (Resource conflicts)
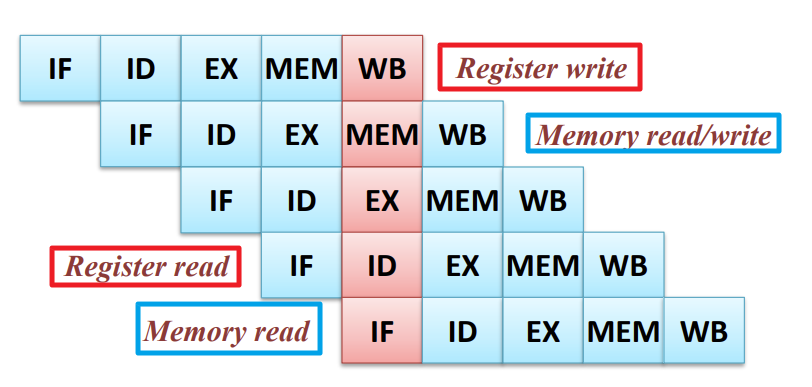
- Solution I : stall (bubble)을 통해 해결할 수 있지만 cpi가 증가함에따라 pipelining 효율↓ -> resource duplication
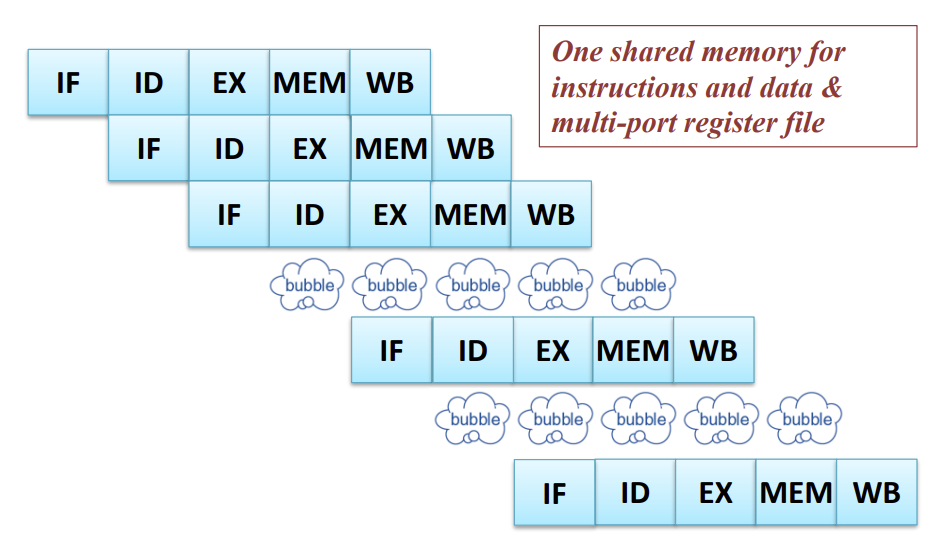
- Solution II : Resource duplication
- Seperate Instruction memory and Data memory
- Time-multiplexed (multi-port register file → read register / write register)
-> 하나의 cycle을 여러개의 sub-cycle로 나누어 서로다른 동작을 하도록 설계!
- Solution I : stall (bubble)을 통해 해결할 수 있지만 cpi가 증가함에따라 pipelining 효율↓ -> resource duplication
-
Data hazards
: 현재 명령어 연산에 필요한 앞선 명령어의 결과가 아직 반환되지 못한 상황
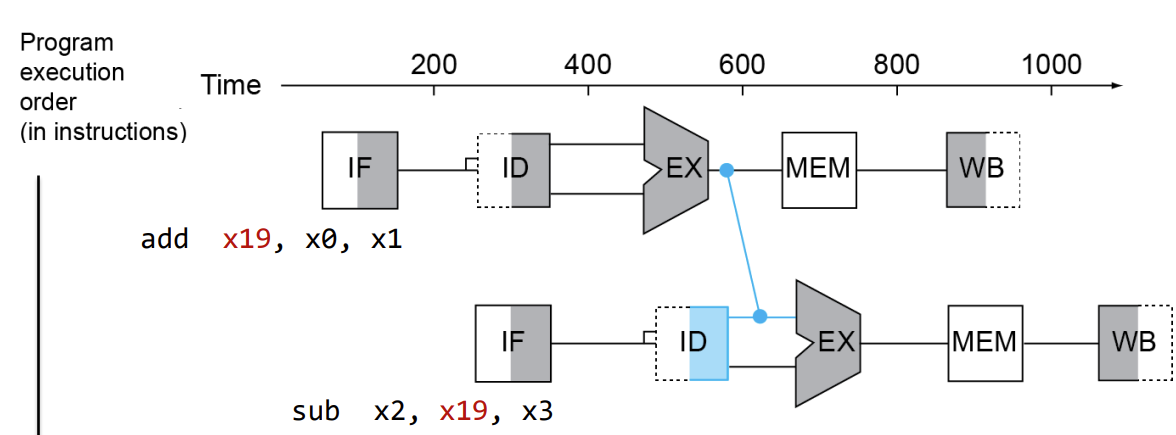
-> ex) add x19, x0, x1 / sub x2, x19, x3 : add에서 x19에 WB 이후에 sub에서 ID를 통해 x19의 값을 read 해야한다.
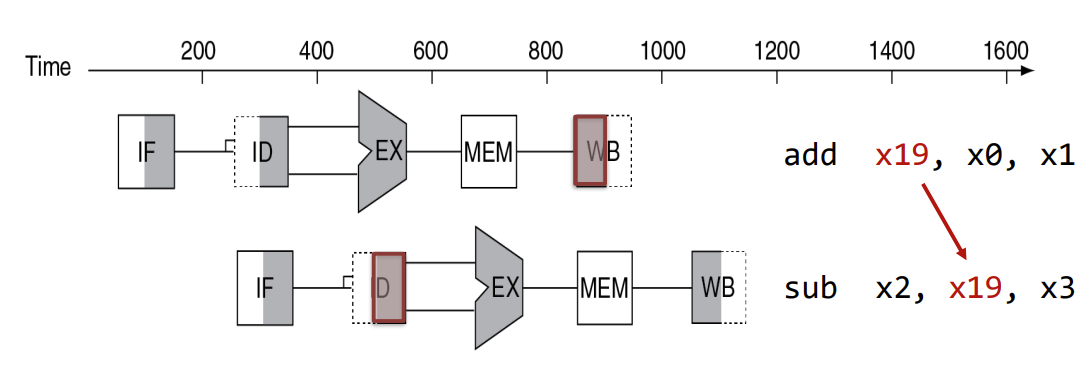
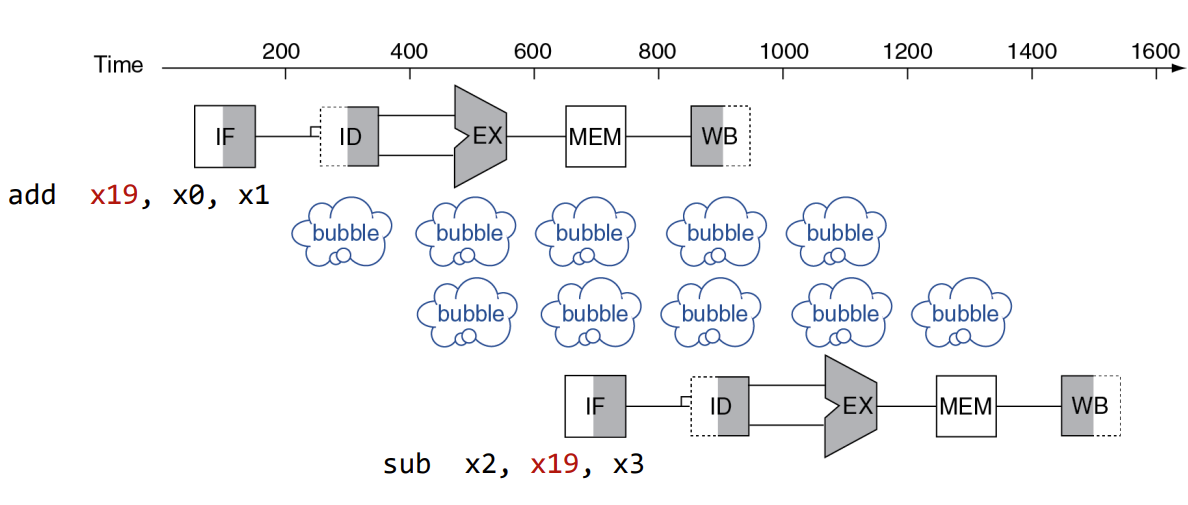
- Solution I : Freezing the pipeline
-> stall을 통해 이전 명령어의 data read/write가 완료될 때까지 기다린다.
- Solution II : Forwarding (Bypassing)
- Register에 값이 write 될 때까지 기다리는 것이 아니라 ALU operation으로부터 값을 가지고와서 stall 없이 data hazard를 해결할 수 있다.
-> 추가적인 하드웨어가 필요하다.
- 하지만 load 명령어 같은 경우에는 Memory로부터 값을 읽어와야 한다.
-> EX : ALU operation의 결과값은 target memory의 주소 값
-> MEM의 결과값을 next instruction의 값으로 사용해야 한다.
-> 결과적으로 1 stall 필요!
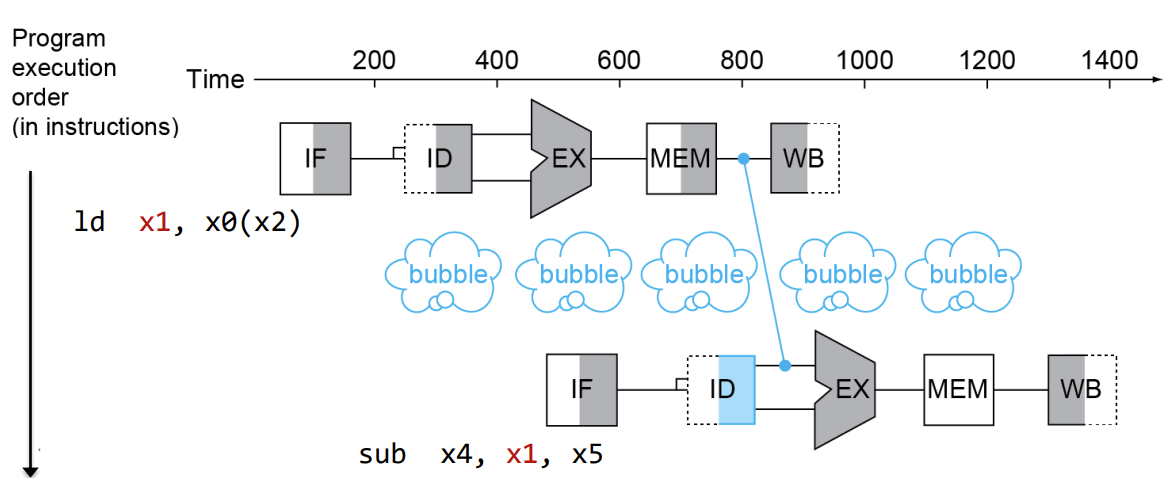
-> Forwarding을 사용하더라도 추가적인 stall을 피할 수 없다.
- Register에 값이 write 될 때까지 기다리는 것이 아니라 ALU operation으로부터 값을 가지고와서 stall 없이 data hazard를 해결할 수 있다.
- Solution III : Compiler Scheduling
- 코드의 reorder를 통해 load의 사용을 피함으로써 전체적인 cycle을 감소시킬 수 있다.

- 코드의 reorder를 통해 load의 사용을 피함으로써 전체적인 cycle을 감소시킬 수 있다.
- Solution I : Freezing the pipeline
-> Bypassing or Compiler scheduling을 통해 얼마의 cycle을 줄일 수 있을까?
-> Data Hazard classification in in-order pipelining
- RAW (read after write) : in-order pipelining에서 발생하는 문제
- WAW (write after write) : 순서대로 pipelining을 하는 in-order pipelining에서는 발생하지 않는다.
- WAR (write after read) : 순서대로 pipelining을 하는 in-order pipelining에서는 발생하지 않는다.
- RAR (read after read) : no hazard
Control hazards
: Next instruction 값이 필요하지만 branch와 같은 이 전 단계에서 target memory 주소에 대한 계산 결과 값이 필요한 경우 next instruction을 알 수 없어서 생기는 hazard.
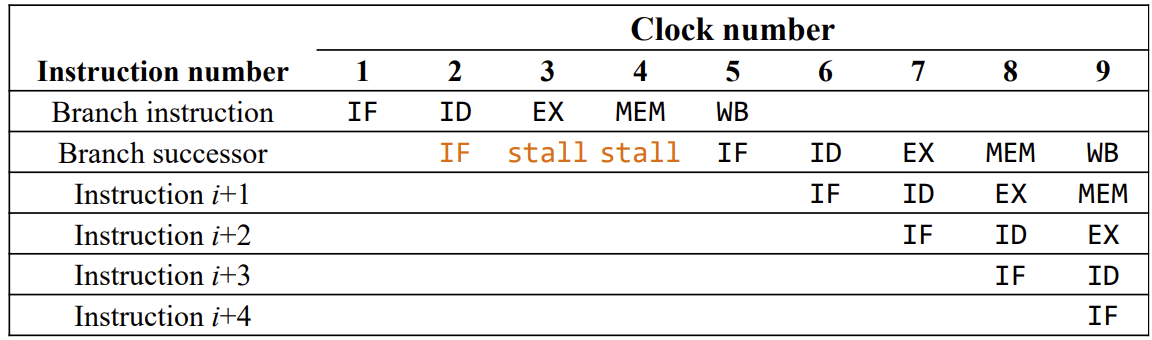
-> 3 stall needed
- Solution I : Optimized Branch Processing
-> 미리 브랜치의 결과값과 target memory address를 알고 싶다.- Find out branch taken or untaken
-> ALU의 zero flag값을 통해 알 수 있다. - Compute branch target address early
-> Extra H/W를 통해 ID (register file) 단계에서 계산을 한다. - 결과적으로 2 stalls를 줄일 수 있다.
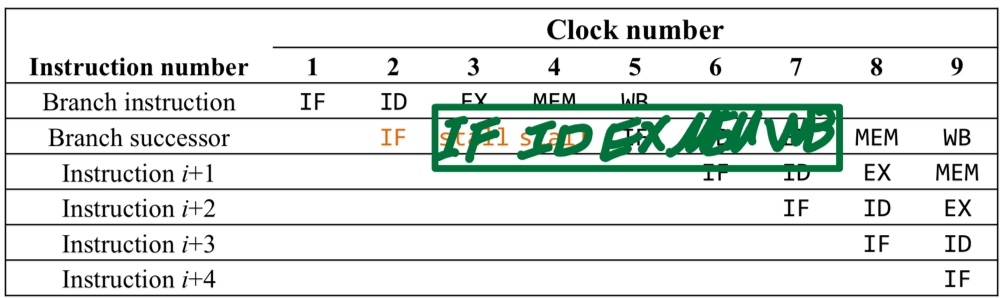
- Find out branch taken or untaken
- Solution II : Branch Prediction
- branch가 untaken이라고 가정한다.
-> Stall은 prediction이 틀렸을 경우에만 발생하게 된다.
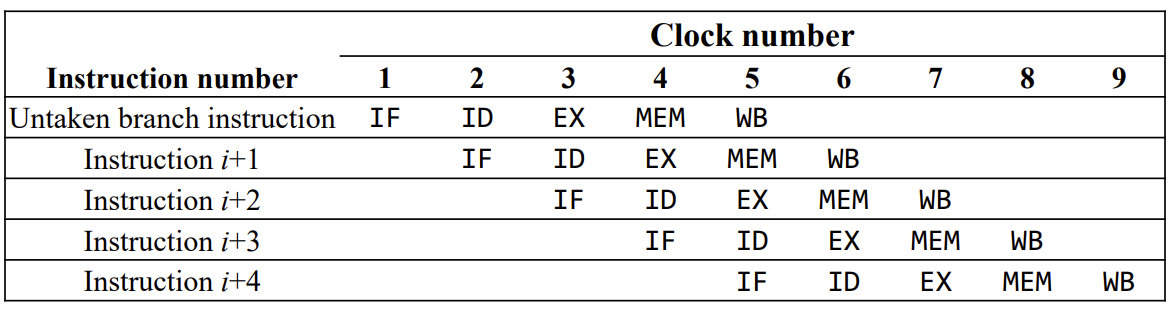
- Static branch prediction : 이전 실행으로부터 얻어진 정보를 바탕으로 prediction
- Dynamic branch prediction : runtime에 정보를 얻어 prediction
- branch가 untaken이라고 가정한다.
- Solution I : Optimized Branch Processing
