십자말풀이 게임을 한 번 토이프로젝트로 진행해보고자 합니다.
게임을 진행하려고 할 때마다 새로운 게임판을 생성해주는 형식을 취해보기 위해
단어 데이터들을 수집해서 데이터베이스에 넣어두려합니다.
작업 레포지토리 : https://github.com/fnzksxl/word-puzzle
정제 전 데이터 소스
국립국어원의 우리말샘의 사전 데이터를 로우 데이터로 삼았습니다.
그 중 JSON 형태로 제공되는 파일의 일부를 살펴보겠습니다.
channel 아래 item 배열에 단어 데이터들이 들어있는 형태네요.
{
"channel": {
"total": 50000,
"title": "사전 검색",
"description": "사전 검색 결과",
"item": [
{
"wordinfo": {
"conju_info": [
{
"conjugation_info": {
"pronunciation_info": {
"pronunciation": "걷치레싱만"
},
"conjugation": "겉치레식만"
}
}
],
"pronunciation_info": [
{
"pronunciation": "걷치레식"
}
],
"word_unit": "어휘",
"word": "겉치레-식",
"original_language_info": [
{
"original_language": "겉치레",
"language_type": "고유어"
},
{
"original_language": "式",
"language_type": "한자"
}
],
"word_type": "혼종어"
},
"group_order": 1,
"group_code": 46174,
"link": "http://opendict.korean.go.kr/dictionary/view?sense_no=643318",
"target_code": 643318,
"senseinfo": {
"definition": "겉으로 보기에만 좋게 꾸미어 드러내는 방식.",
"sense_no": "001",
"type": "일반어",
"example_info": [
{
"source": "노컷뉴스 2009년 7월",
"example": "그러나 주변에서 일상적으로 듣는 {겉치레식} 격려는 아무런 힘을 발휘할 수 없다."
},
{
"source": "서울신문 2013년 3월",
"example": "“통과의례, {겉치레식의} 인사 청문회 제도에 대한 개선이 필요하다.”라는 지적도 나온다."
}
],
"definition_original": "겉으로 보기에만 좋게 꾸미어 드러내는 방식.",
"pos": "명사"
}
},데이터 정제
1. 단순 데이터 추출
# 단어 이름, 설명, 품사 추출하는 스크립트
import json
import os
DIR = os.getcwd()
DATA_DIR = DIR + "/word-data"
json_list = os.listdir(DATA_DIR)
for i, _json in enumerate(json_list):
print(f"{len(json_list)}/{i+1}번 째 파일, 파일명 : {_json}")
with open(DATA_DIR+"/"+_json, encoding="utf-8") as f:
json_data = json.load(f)
for word_data in json_data["channel"]["item"]:
word = word_data["wordinfo"]["word"]
senseinfo = word_data["senseinfo"]
pos = senseinfo["pos"]
definition = senseinfo["definition"]위 데이터 중 단어의 이름인 ["wordinfo"]["word"],
단어의 설명인 ["senseinfo"]["definition"],
단어의 품사인 ["senseinfo"]["pos"] 이렇게 세 개를 가져오기로 했습니다.
2. 데이터 확인
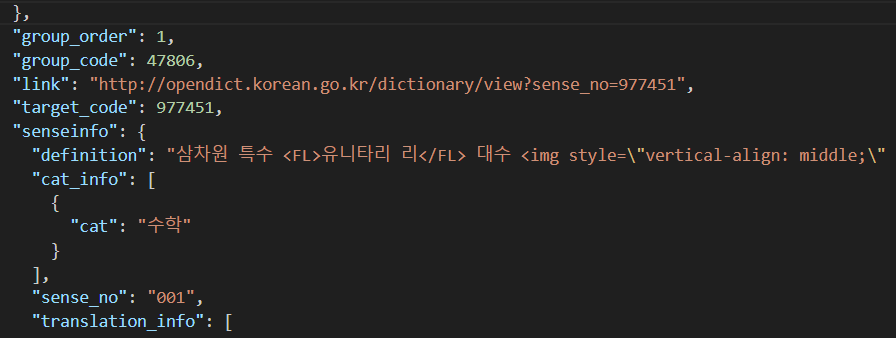
단어 설명에 img 나 FL 태그가 들어있는 경우도 있었고,
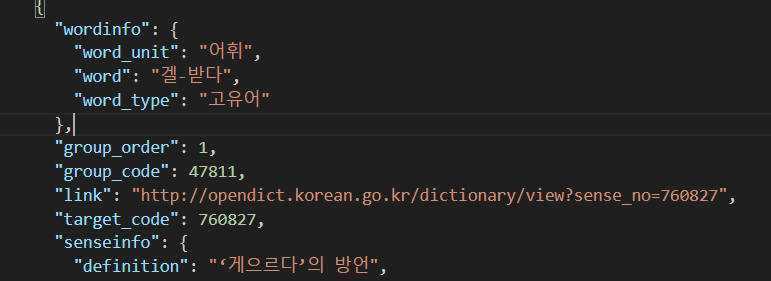
어휘에 특수문자가 들어가거나,
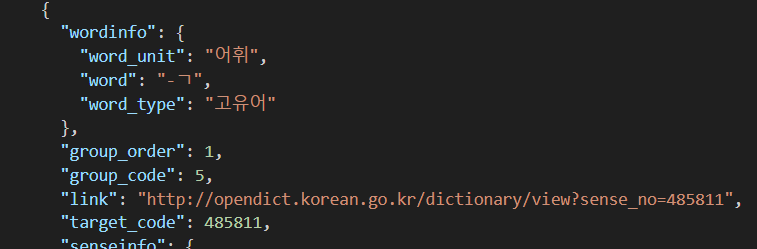
자음만 존재하는 등 십자말풀이에서 쓰지 못할 데이터가 존재합니다.
이외에도 설명에 %lt %gt 같은 용어, 너무 긴 단어나 설명이 존재하기도 했습니다.
3. 데이터 정제
위에서 확인해본 데이터를 배제함과 동시에 십자말풀이에 쓸 수 있도록
데이터를 정제해보겠습니다.
단어
- 2 <= 단어의 길이 <= 7 인 경우만 추출할 것
- 단어에 자음만 존재하거나 한글을 제외한 다른 문자가 있으면 스킵할 것
- 단어에 띄워쓰기는 제거할 것
위 조건을 만족하도록 단어를 정제하는 함수를 정규표현식을 이용해 작성해봅시다.
# 원하는 조건으로 단어를 정제하는 함수
def process_word(word):
word = word.strip()
consonant_mixed = re.search(r'[ㄱ-ㅎ]', word)
if consonant_mixed:
return None
result = re.sub(r'[^가-힣]', '', word)
length = len(result)
if length > 7 or length < 2:
return None
return {"word": result, "length": length}- re.search(pattern, string) 함수는 패턴과 문자열이 일치하는 부분이 없으면 None, 있으면 그 부분을 반환해줍니다.
- re.sub(pattern, replacement, string) 함수는 패턴과 문자열이 일치하는 모든 부분을 replacement로 치환해줍니다. r'[^가-힣]'의 패턴의 경우 한글을 제외한 모든 문자를 의미합니다. ^ 기호는 차집합의 의미로 생각하면 이해가 쉽습니다.
다른 메타 문자나 정규표현식의 더 많은 함수는 파이썬에서 제공해주는 문서에서 자세히 확인해볼 수 있습니다.
# EXAMPLE
word_list = ["ㄱ-", "게", "게임", "게이밍 모니터"]
processed_word_list = []
for word in word_list:
processed_word_list.append(process_word(word))
print(processed_word_list)# 출력 결과
[None, None, {'word': '게임', 'length': 2}, {'word': '게이밍모니터', 'length': 6}]설명 및 품사
- 품사는 반드시 있어야 할 것
- 방언과 북한어는 제외할 것
- 설명의 길이 > 200 이거나 태그가 들어있으면 제외할 것
- 규범 표기, 옛말, 준말 등의 설명이 있으면 제외할 것
- -가 들어가는 경우는 제외할 것
5번의 경우는 설명에서 이상한 부분이 있었지만 따로 캡쳐하지 못했습니다.
위 조건을 만족하도록 설명과 품사를 전제하는 함수를 만들어 봅시다.
# 원하는 조건으로 설명을 정제하는 함수
def process_senseinfo(senseinfo):
definition = senseinfo["definition"].strip()
word_type = senseinfo["type"].strip()
pos = senseinfo.get("pos", None)
if pos is None or pos == "품사 없음":
return None
pos = pos.strip()
if word_type == "방언" or word_type == "북한어":
return None
if len(definition) > 200 or "&" in definition or "img" in definition or "<FL>" in definition or "규범 표기" in definition or "준말" in definition or "옛말" in definition or "-" in definition:
return None
return {"definition": definition, "pos": pos}# EXAMPLE
senseinfo_list = [{"definition": "&&안녕하세요", "type": "고유어", "pos": "명사"},
{"definition": "안녕하세요", "type": "북한어", "pos": "명사"},
{"definition": "안녕하세요", "type": "고유어", "pos": "명사"},
{"definition": "안녕하세요", "type": "고유어", "pos": "품사 없음"},
{"definition": "안녕하세요 <img", "type": "고유어", "pos": "명사"}]
processed_senseinfo_list = []
for senseinfo in senseinfo_list:
processed_senseinfo_list.append(process_senseinfo(senseinfo))
print(processed_senseinfo_list)# 출력 결과
[None, None, {'definition': '안녕하세요', 'pos': '명사'}, None, None]다음 포스트에서는 정제한 단어 데이터들을 데이터베이스에 삽입해보겠습니다.
읽어주셔서 감사합니다.
