작업 레포지토리 : https://github.com/fnzksxl/word-puzzle
지난 번에 정제했던 데이터를 데이터베이스에 삽입해보도록 하겠습니다.
프론트엔드까지 구현해볼지는 모르겠지만 백엔드 서비스 형태로
게임을 제공해보기 위해서 FastAPI 프레임워크를 사용하기로 했습니다.
MySQL이 설치가 되어있다는 전제하에 진행해보겠습니다.
# 프로젝트 구조
ROOT FOLDER
ㄴ app
ㄴ main.py
ㄴ config.py
ㄴ database.py
ㄴ models.py
ㄴ word-data
ㄴ json files... 로우 데이터 JSON 파일들
ㄴ extract_word.py 데이터 정제 스크립트
ㄴ runserver.py 서버 실행 스크립트초기 서버 설정
실행환경 구성
# 실행환경 구성
python -m venv venv 가상환경 설정
pip install uvicorn[standard] fastapi sqlalchemy pymysql# .env
# 각자의 환경에 맞게 .env 파일을 설정해주면 됩니다.
DB_USERNAME={USERNAME}
DB_PASSWORD={PASSWORD}
DB_HOST={HOST}
DB_PORT={PORT}
DB_NAME={NAME}
# config.py
from dotenv import load_dotenv
from functools import lru_cache
import os
load_dotenv()
class Settings:
# DB Settings
DB_USERNAME = os.getenv("DB_USERNAME")
DB_HOST = os.getenv("DB_HOST")
DB_PASSWORD = os.getenv("DB_PASSWORD")
DB_NAME = os.getenv("DB_NAME")
DB_PORT = os.getenv("DB_PORT")
@lru_cache
def get_settings():
return Settings()
settings = get_settings()코드 전역에서 사용할 서버 세팅을 관리해주는 파일입니다.
lru_cache를 사용해 settings를 사용할 때 추가연산을 하지 않도록 했습니다.
# database.py
from sqlalchemy import create_engine
from sqlalchemy.ext.declarative import declarative_base
from sqlalchemy.orm import sessionmaker
from app.config import settings
engine = create_engine(
"mysql+pymysql://{username}:{password}@{host}:{port}/{name}".format(
username=settings.DB_USERNAME,
password=settings.DB_PASSWORD,
host=settings.DB_HOST,
port=settings.DB_PORT,
name=settings.DB_NAME,
)
)
SessionLocal = sessionmaker(
bind=engine,
autocommit=False,
autoflush=False,
)
Base = declarative_base()
def get_db():
db = SessionLocal()
try:
yield db
finally:
db.close()서버와 MySQL 서버를 연결해주는 세션을 생성하는 파일입니다.
API에서 사용할 때 get_db 함수를 Depends 해줄 수 있게 미리 선언했습니다.
# main.py
from contextlib import asynccontextmanager
from fastapi import FastAPI
@asynccontextmanager
async def lifespan(app: FastAPI):
from app import models
from app.database import engine
models.Base.metadata.create_all(bind=engine)
yield
pass
app = FastAPI(lifespan=lifespan)
# runserver.py
import uvicorn
if __name__ == "__main__":
uvicorn.run("app.main:app", host="0.0.0.0", port=8000, reload=True)서버 실행과 관련된 파일입니다. 서버 실행 시에 데이터베이스와 연결되도록 lifespan으로 관리해줍니다.
이전에는 on_event를 사용해서 서버 시작, 종료 시 이벤트를 관리했는데
이는 사장될 문법이므로 지양하는게 좋습니다.
DB 테이블 생성
# models.py
from sqlalchemy import Column, Integer, VARCHAR
from app.database import Base
class BaseMin:
id = Column(Integer, primary_key=True, index=True)
class WordInfo(BaseMin, Base):
__tablename__ = "wordinfo"
# 단어 이름
word = Column(VARCHAR(7), nullable=False)
# 단어 설명
desc = Column(VARCHAR(200), nullable=False)
# 단어 길이
len = Column(Integer, nullable=False)
# 단어 품사
pos = Column(VARCHAR(7), nullable=False)BaseMin 클래스를 선언해서 이후 테이블에서 id를 Primary Key로 반복 선언하지 않게 따로 빼줬습니다.
데이터 DB 삽입
# extract_word.py
from sqlalchemy import create_engine
from sqlalchemy.orm import sessionmaker
from app.models import WordInfo
import re
import os
import json
from app.config import settings
DIR = os.getcwd()
DATA_DIR = DIR + "/word-data"
json_list = os.listdir(DATA_DIR)
def process_word(word):
"""
자음이 포함된 단어 제거, 단어에 한글을 제외한 문자 및 공백 제거, 지정 길이를 벗어나는 단어 제거
위 세 가지 일을 한 뒤 단어와 그 길이를 반환합니다
Args:
word (str): 정제할 단어
Returns:
dict: {단어, 단어의 길이}
"""
word = word.strip()
consonant_mixed = re.search(r'[ㄱ-ㅎ]', word)
if consonant_mixed:
return None
result = re.sub(r'[^가-힣]', '', word)
length = len(result)
if length > 7 or length < 2:
return None
return {"word": result, "length": length}
def process_senseinfo(senseinfo):
"""
단어의 품사가 없거나 '품사 없음'일 시 제거, 방언 및 북한어 제거, 설명에 특이점이 있으면 제거
위 세 가지 일을 한 뒤 설명과 단어의 품사를 반환합니다
Args:
senseinfo (dict): 품사, 설명 데이터가 들어있는 딕셔너리
Returns:
dict: {설명, 품사}
"""
definition = senseinfo["definition"].strip()
word_type = senseinfo["type"].strip()
pos = senseinfo.get("pos", None)
if pos is None or pos == "품사 없음":
return None
if word_type == "방언" or word_type == "북한어":
return None
if len(definition) > 200 or "&" in definition or "img" in definition or "<FL>" in definition or "규범 표기" in definition or "준말" in definition or "옛말" in definition or "-" in definition:
return None
return {"definition": definition, "pos": pos}
if __name__ == "__main__":
"""
JSON 파일로부터 단어 로우 데이터를 읽어들이고, 정제한 뒤 WordInfo 테이블에 추가합니다.
"""
engine = create_engine(
"mysql+pymysql://{username}:{password}@{host}:{port}/{name}".format(
username=settings.DB_USERNAME,
password=settings.DB_PASSWORD,
host=settings.DB_HOST,
port=settings.DB_PORT,
name=settings.DB_NAME,
)
)
Session = sessionmaker(bind=engine)
db = Session()
word_list = []
for i, _json in enumerate(json_list):
print(f"{len(json_list)}/{i+1}번 째 파일, 파일명 : {_json}")
with open(DATA_DIR+"/"+_json, encoding="utf-8") as f:
json_data = json.load(f)
for word_data in json_data["channel"]["item"]:
processed_word = process_word(word_data["wordinfo"]["word"])
processed_senseinfo = process_senseinfo(word_data["senseinfo"])
if processed_word and processed_senseinfo:
word_list.append({
"word": processed_word["word"],
"desc": processed_senseinfo["definition"],
"pos": processed_senseinfo["pos"],
"len": processed_word["length"]
})
else:
continue
print(f"현재 단어 수 : {len(word_list)}")
db.bulk_insert_mappings(WordInfo, word_list)
db.commit()
db.close()글 최상단의 프로젝트 구조대로 구성하고 위 스크립트를 실행하면
로그가 위와 같이 나오며 실행됩니다.
50만개가 넘는 row를 한 번에 삽입하는 경우에는 개별적으로 add하는게 아니라
bulk_insert 기능을 활용하는게 성능적으로 훨씬 우수합니다.
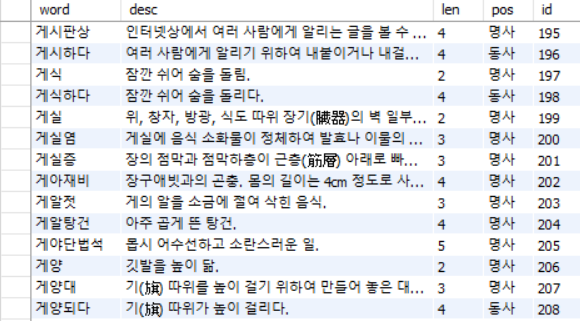
MySQL WorkBench에서 확인해본 결과입니다. 잘 들어가있죠?
다음 포스트에서는 십자말풀이 퍼즐 생성을 다뤄보겠습니다.
읽어주셔서 감사합니다.
