
작업 레포지토리 : https://github.com/fnzksxl/word-puzzle
지난 번 포스트에서 단어 데이터 추출 후 데이터베이스 삽입까지 했습니다.
이번 포스트에서는 단어 데이터들을 데이터베이스에서 선택해 십자말풀이 퍼즐을
만들어보도록 하겠습니다.
모델 변경점
class WordInfo(BaseMin, Base):
__tablename__ = "wordinfo"
word = Column(VARCHAR(5), nullable=False)
desc = Column(VARCHAR(200), nullable=False)
len = Column(Integer, nullable=False)
pos = Column(VARCHAR(7), nullable=False)
시작하기에 앞서 지난 번 모델에서 단어 의 최대 길이가 5로 감소했습니다.
퍼즐 데이터 형식
- 퍼즐의 크기는 정사각형이다
- 단어는 위->아래, 왼->오 방향으로만 추가된다.
- 연결된 단어를 제외하고 단어끼리는 상,하,좌,우로 접하지 않는다.
위 세가지를 기본 전제로 퍼즐을 구성하기로 했습니다.

위 그림은 (7x7) 형태의 제가 생각하는 퍼즐의 최종 모습을 메모장으로 작성해본 샘플입니다.
이러한 데이터를 구성하기 위해서 어떤 데이터 형식을 취해볼까요?
저는 퍼즐의 각 단어 배치를 2차원 배열로 처리하기로 했습니다.
(7x7) 형태의 정수 0으로 이루어진 리스트를 생성하고, 단어가 추가될 때마다
숫자가 +1 되면서 마킹하기로 말이죠.
그리고 각 단어에 대해 {번호, 설명}, {번호, 단어} 자료형을 가지는 리스트로 관리해보겠습니다.
퍼즐 생성
Phase1: 첫 단어 배치
각 함수들이 의존성 주입 형태로 배치되어있기 때문에,
가장 아래 함수부터 매개변수를 거슬러올라가며 보는 게 읽기 쉬울 겁니다.
import random
from collections import deque
from fastapi import Depends
from sqlalchemy.orm.session import Session
from typing import List, Tuple, Deque, Dict
from app.models import WordInfo
from app.database import get_db
async def append_letter_into_queue(
start_point: Tuple[int, int], length: int, word: str, queue: deque, dir: bool
) -> Deque:
"""
시작점, 길이, 단어, 방향을 토대로 큐에 다음 단어 추가에 대한 힌트를 큐에 삽입 후 반환한다.
Args:
start_point (Tuple): 단어 첫 음절이 위치하는 곳
length (int): 단어의 길이
word (str): 단어
queue (deque): 큐
dir (bool): 단어 방향 가로, 세로 여부
Returns:
Deque: 다음 단어의 시작점, 시작 음절, 방향이 추가된 큐
"""
def add_to_queue(coord: Tuple[int, int], letter: str, dir: bool) -> None:
if 0 <= coord[0] < 11 and 0 <= coord[1] < 11:
queue.append(((coord[0], coord[1]), letter, not (dir)))
if dir:
add_to_queue((start_point[0], start_point[1] + length - 1), word[-1], dir)
else:
add_to_queue((start_point[0] + length - 1, start_point[1]), word[-1], dir)
if length > 2:
if length >= 5:
if dir:
add_to_queue((start_point[0], start_point[1] + 2), word[2], dir)
else:
add_to_queue((start_point[0] + 2, start_point[1]), word[2], dir)
add_to_queue(start_point, word[0], dir)
return queue
async def create_map() -> List[str]:
"""
0으로 초기화 된 맵을 생성해 반환한다.
Args:
None
Returns:
List[str]
"""
map = [[0 for _ in range(11)] for _ in range(11)]
return map
async def find_first_word_info(db: Session = Depends(get_db)) -> WordInfo:
"""
DB에서 랜덤으로 하나의 단어를 찾아 반환한다.
Args:
db (Session): 커넥션
Returns:
WordInfo: 랜덤으로 가져온 WordInfo Row 객체
"""
random_idx = random.randint(1, 494047)
return db.query(WordInfo).filter(WordInfo.id == random_idx).first()
async def create_puzzle_phase1(
word: WordInfo = Depends(find_first_word_info), map: List[str] = Depends(create_map)
) -> Dict:
"""
0으로 초기화 된 맵에 첫 단어를 추가,
이 후 추가될 단어와 그 위치에 대한 힌트를 큐에 삽입,
첫 단어 설명 추가 후 반환한다.
Args:
word (WordInfo): 단어 정보
map (List[str]): 0으로 초기화 된 맵
Returns:
Dict: {map(List[str]), queue(deque), desc(dict)}
"""
start_y, start_x = 0, 0
queue = deque()
desc = []
words = []
for i in range(word.len):
map[start_y][start_x + i] = 1
words.append({"num": 1, "word": word.word})
desc.append({"num": 1, "desc": word.desc})
queue = await append_letter_into_queue((start_y, start_x), word.len, word.word, queue, True)
return {"map": map, "queue": queue, "desc": desc, "words": words}위 함수들을 간단하게 요약하자면, 10x10 퍼즐에 (0,0), 최좌상단에서 가로 방향으로 단어를 하나 배치하고, 단어의 길이에 따라 큐에 다음 단어의 시작점 좌표를 추가해줬다는 겁니다.
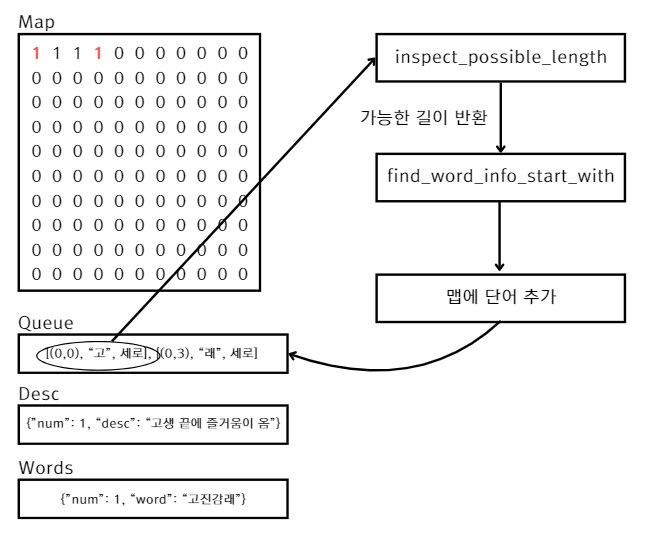
단어 배치 시 0으로 초기화 된 맵에 단어 위치에 해당하는 좌표를 1로 바꿨습니다.
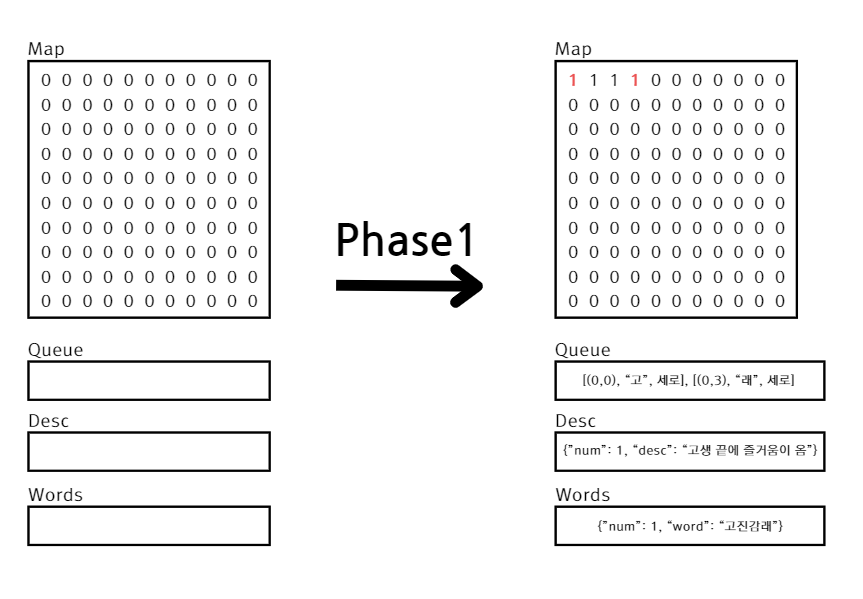
위 상황을 그림으로 표현해봤습니다. 오른쪽 그림의 빨간 좌표가 현재 큐에 들어가있는 좌표입니다. 세로로 표기된 것은 편의상 배치한 것이고, 실제 코드 상에서는 세로는 False, 가로는 True 입니다.
Phase2: 첫 단어에서 이어지는 단어들 배치
Phase1의 첫 단어 배치가 끝나면 이제 첫 단어에서 이어지도록 단어를 계속 배치해야합니다.
위 그림을 예시로 들면 "고"와"래"로 시작하는 단어가 되겠네요.
async def find_word_info_start_with(start_word: str, db: Session) -> WordInfo:
"""
DB에서 {start_word}로 시작하는 단어를 찾아 반환한다.
Args:
db (Session): 커넥션
start_word (str): 시작 어절
Returns:
WordInfo: {start_word}로 시작하는 WordInfo Row 객체
"""
return (
db.query(WordInfo)
.filter(WordInfo.word.like(f"{start_word}%"))
.order_by(func.rand())
.first()
)위 함수는 DB에서 {start_word}로 시작하는 단어를 검색해서 랜덤 추출합니다.
async def create_puzzle_phase2(
db: Session = Depends(get_db), map_queue_desc: Dict = Depends(create_puzzle_phase1)
) -> Dict:
"""
단어 하나가 삽입된 상태에서, 시작 어절이 같은 단어를 찾아 추가한다.
단, 진행방향의 삼면에 이미 다른 단어의 어절이 없어야 한다.
이 함수는 두 번째 페이즈로, 처음 추가된 단어와 이어지는 경우에만 단어를 추가한다.
Args:
db (Session): 커넥션
map_queue_desc (Dict): 맵, 큐, 설명 및 단어가 들어있는 사전형 자료
Returns:
Dict: 맵, 큐, 설명 및 단어가 들어있는 사전형 자료
"""
map = map_queue_desc.get("map")
queue = map_queue_desc.get("queue")
desc = map_queue_desc.get("desc")
words = map_queue_desc.get("words")
num = 2
while queue:
point, start_word, dir = queue.popleft()
next_word = await find_word_info_start_with(start_word, db)
if not next_word:
continue
if (next_word) and (
(dir and point[1] + next_word.len < 11) or (not dir and point[0] + next_word.len < 11)
):
if point[1] >= 1:
if dir and map[point[0]][point[1] - 1] != 0:
continue
if point[0] >= 1:
if not dir and map[point[0] - 1][point[1]] != 0:
continue
original_value = map[point[0]][point[1]]
for i in range(next_word.len):
if dir:
if i and map[point[0]][point[1] + i] != 0:
for j in range(i):
map[point[0]][point[1] + j] = original_value
break
if i and (
(point[1] + i + 1 < 11 and map[point[0]][point[1] + i + 1] != 0)
or (point[0] - 1 >= 0 and map[point[0] - 1][point[1] + i] != 0)
or (point[0] + 1 < 11 and map[point[0] + 1][point[1] + i] != 0)
):
for j in range(1, i):
map[point[0]][point[1] + j] = 0
map[point[0]][point[1]] = original_value
break
map[point[0]][point[1] + i] = num
else:
if i and map[point[0] + i][point[1]] != 0:
for j in range(i):
map[point[0] + j][point[1]] = original_value
break
if i and (
(point[1] - 1 >= 0 and map[point[0] + i][point[1] - 1] != 0)
or (point[1] + 1 < 11 and map[point[0] + i][point[1] + 1] != 0)
or (point[0] + i + 1 < 11 and map[point[0] + i + 1][point[1]] != 0)
):
for j in range(1, i):
map[point[0] + j][point[1]] = 0
map[point[0]][point[1]] = original_value
break
map[point[0] + i][point[1]] = num
else:
words.append({"num": num, "word": next_word.word})
desc.append({"num": num, "desc": next_word.desc})
num += 1
queue = await append_letter_into_queue(
point, next_word.len, next_word.word, queue, dir
)
return {"map": map, "desc": desc, "words": words}이 함수에서 검색하는 조건은 Docstring에 적혀있는 바와 동일합니다.
어차피 갈아엎을 함수이니 자세히 읽진 않아도 됩니다.
왜 갈아엎어야 할까요? 조건식이 너무 복잡해보여서?
그것도 맞지만 이 로직에는 커다란 문제점이 하나 있습니다.
조건식이 아닌 부분에서 잠시 생각해보시길 바랍니다.
......
불필요한 DB 호출
create_puzzle_phase2 함수에서 DB호출하는 부분을 한 번 확인해보시길 바랍니다.
- 큐에서 꺼내 단어를 DB에서 가져온다.
- 현재 퍼즐에 단어를 넣을 수 있는지 조건을 검사한다.
위의 로직은 DB에서 단어 데이터를 불러온 뒤에 그 단어가 퍼즐에 추가할 수 있는지 조건을 검사하고 있습니다.
하지만 순서를 바꿔 큐에서 꺼낸 좌표에서 가능한 단어의 길이를 먼저 계산한 후에 DB에서 해당 단어를 가져오는 로직이라면 성능적으로 이득을 볼 수 있다고 판단이 됩니다.
조건 계산 로직을 분리하고 변경된 로직에 맞게 코드를 수정해보죠.
async def find_word_info_start_with(start_word: str, limit: int, db: Session) -> WordInfo:
"""
DB에서 {start_word}로 시작하면서 길이가 limit 이하인 단어를 찾아 반환한다.
Args:
start_word (str): 시작 어절
limit (int): 가능한 최대 길이
Returns:
WordInfo: {start_word}로 시작하면서 길이가 limit 이하인 WordInfo Row 객체
"""
return (
db.query(WordInfo)
.filter(WordInfo.word.like(f"{start_word}%"))
.filter(WordInfo.len <= limit)
.order_by(func.rand())
.first()
)
async def inspect_possible_length(map: List[int], point: Tuple[int, int], dir: bool) -> int:
"""
추가할 수 있는 단어의 길이를 반환해주는 함수
Args:
map (List[int]): 퍼즐 맵 정보
point (Tuple[int, int]): 새로운 단어의 시작 지점
dir (bool): 가로,세로 여부
Returns:
Int: 추가할 수 있는 단어의 길이
"""
if point[1] >= 1:
if dir and map[point[0]][point[1] - 1] != 0:
return 0
if point[0] >= 1:
if not dir and map[point[0] - 1][point[1]] != 0:
return 0
if dir:
for i in range(1, 5):
if (
(point[0] - 1 >= 0 and map[point[0] - 1][point[1] + i] != 0)
or (point[0] + 1 < len(map) and map[point[0] + 1][point[1] + i] != 0)
or (point[1] + i < len(map[0]) - 1 and map[point[0]][point[1] + i + 1] != 0)
or (point[1] + i == len(map[0]) - 1)
):
return i
else:
for i in range(1, 5):
if (
(point[1] - 1 >= 0 and map[point[0] + i][point[1] - 1] != 0)
or (point[1] + 1 < len(map[0]) and map[point[0] + i][point[1] + 1] != 0)
or (point[0] + i < len(map) - 1 and map[point[0] + i + 1][point[1]] != 0)
or (point[0] + i == len(map) - 1)
):
return i
return 5
async def create_puzzle_phase2(db: Session = Depends(get_db), map_queue_desc: Dict = Depends(create_puzzle_phase1)) -> Dict:
"""
단어 하나가 삽입된 상태에서, 시작 어절이 같은 단어를 찾아 추가한다.
단, 진행방향의 삼면에 이미 다른 단어의 어절이 없어야 한다.
이 함수는 두 번째 페이즈로, 처음 추가된 단어와 이어지는 경우에만 단어를 추가한다.
Args:
db (Session): 커넥션
map_queue_desc (Dict): 맵, 큐, 설명 및 단어가 들어있는 사전형 자료
Returns:
Dict: 맵, 큐, 설명 및 단어가 들어있는 사전형 자료
"""
map = map_queue_desc.get("map")
queue = map_queue_desc.get("queue")
desc = map_queue_desc.get("desc")
words = map_queue_desc.get("words")
num = 2
while queue:
point, start_word, dir = queue.popleft()
limit = await inspect_possible_length(map, point, dir)
if limit <= 1:
continue
next_word = await find_word_info_start_with(start_word, limit, db)
if not next_word:
continue
for i in range(next_word.len):
if dir:
map[point[0]][point[1] + i] = num
else:
map[point[0] + i][point[1]] = num
words.append({"num": num, "word": next_word.word})
desc.append({"num": num, "desc": next_word.desc})
num += 1
queue = await append_letter_into_queue(point, next_word.len, next_word.word, queue, dir)
return {"map": map, "desc": desc, "words": words}이렇게 바꾸는게 성능적으로 실제로 이득이 있는지 확인해보겠습니다.
from fastapi import APIRouter, status, Depends
from typing import Dict
from app.utils.puzzle import create_puzzle_phase2
router = APIRouter(tags=["PuzzleV1"], prefix="/puzzle")
@router.get("", status_code=status.HTTP_200_OK)
async def create_puzzle(puzzle: Dict = Depends(create_puzzle_phase2)):
return await puzzle엔드포인트 하나 만들어주고,
# main.py
from contextlib import asynccontextmanager
from fastapi import FastAPI, Request
import time
from app.api import router
@asynccontextmanager
async def lifespan(app: FastAPI):
from app import models
from app.database import engine
models.Base.metadata.create_all(bind=engine)
yield
pass
app = FastAPI(lifespan=lifespan)
app.include_router(router)
@app.middleware("http")
async def log_request_time(request: Request, call_next):
start_time = time.time()
response = await call_next(request)
process_time = time.time() - start_time
response.headers["X-Process-Time"] = str(process_time)
return responsemain.py에 response time을 측정할 수 있도록 미들웨어를 하나 달아주겠습니다.
FastAPI에서 자동으로 생성해주는 Swagger 문서에서 시간 차이를 보겠습니다.
변경 전 로직
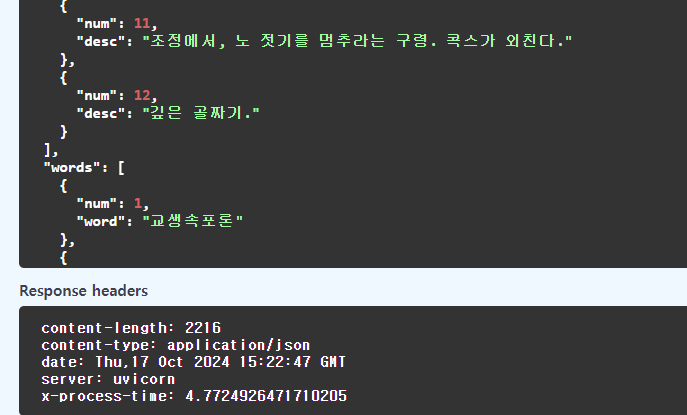
단어 12개 배치에 약 4.8초 정도 걸렸네요.
변경 후 로직
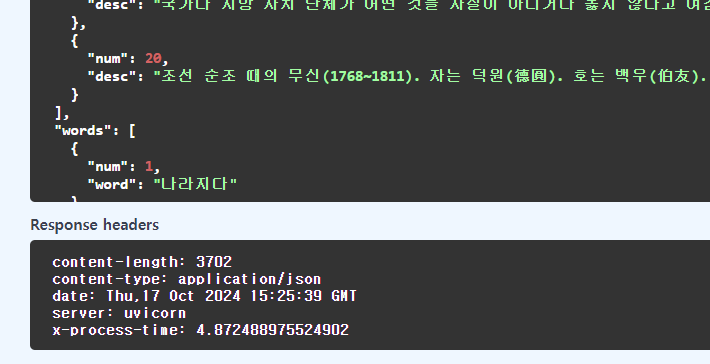
단어 20개 배치에 약 4.9초 정도 걸렸습니다.
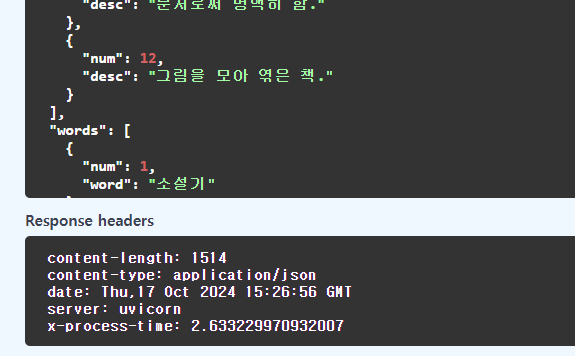
같은 단어 수인 12개를 배치할 때 약 2.6초 정도 걸려, 45% 정도의 향상률을 보여줍니다.
로직을 이해하기 쉽도록 그림으로 표현해봤습니다.
참고) 함수형 -> 클래스로 변경
클래스의 생성자도 Depends로 종속성 주입이 가능합니다.
PuzzleCreateService 생성자에 Optional[int] = None을 선언해
Query 파라미터로 퍼즐의 크기를 입력받을 수 있게 했습니다.
class PuzzleCreateService:
def __init__(self, size: Optional[int] = None, db: Session = Depends(get_db)):
"""
퍼즐의 크기를 받아 맵을 생성한다. 기본 값은 7x7
Args:
size (int or None): 퍼즐의 크기 + 1
"""
self.db = db
self.map_size = size + 1 if size is not None else 8
self.map = self.create_map()
self.queue = deque()
self.desc = []
self.words = []
self.num = 2
self.word_size = 494047
def create_map(self) -> List[str]:
"""
0으로 초기화 된 맵을 생성해 반환한다.
"""
return [[0 for _ in range(self.map_size)] for _ in range(self.map_size)]
async def append_letter_into_queue(
self, start_point: Tuple[int, int], length: int, word: str, dir: bool
) -> Deque:
"""
시작점, 길이, 단어, 방향을 토대로 큐에 다음 단어 추가에 대한 힌트를 큐에 삽입 후 반환한다.
Args:
start_point (Tuple): 단어 첫 음절이 위치하는 곳
length (int): 단어의 길이
word (str): 단어
dir (bool): 단어 방향 가로, 세로 여부
Returns:
Deque: 다음 단어의 시작점, 시작 음절, 방향이 추가된 큐
"""
def add_to_queue(coord: Tuple[int, int], letter: str, dir: bool) -> None:
if 0 <= coord[0] < self.map_size and 0 <= coord[1] < self.map_size:
self.queue.append(((coord[0], coord[1]), letter, not (dir)))
if dir:
add_to_queue((start_point[0], start_point[1] + length - 1), word[-1], dir)
else:
add_to_queue((start_point[0] + length - 1, start_point[1]), word[-1], dir)
if length > 2:
if length >= 5:
if dir:
add_to_queue((start_point[0], start_point[1] + 2), word[2], dir)
else:
add_to_queue((start_point[0] + 2, start_point[1]), word[2], dir)
add_to_queue(start_point, word[0], dir)
return self.queue
async def find_first_word_info(self) -> WordInfo:
"""
DB에서 랜덤으로 하나의 단어를 찾아 반환한다.
Returns:
WordInfo: 랜덤으로 가져온 WordInfo Row 객체
"""
random_idx = random.randint(1, self.word_size)
return self.db.query(WordInfo).filter(WordInfo.id == random_idx).first()
async def find_word_info_start_with(self, start_word: str, limit: int) -> WordInfo:
"""
DB에서 {start_word}로 시작하면서 길이가 limit 이하인 단어를 찾아 반환한다.
Args:
start_word (str): 시작 어절
limit (int): 가능한 최대 길이
Returns:
WordInfo: {start_word}로 시작하면서 길이가 limit 이하인 WordInfo Row 객체
"""
return (
self.db.query(WordInfo)
.filter(WordInfo.word.like(f"{start_word}%"))
.filter(WordInfo.len <= limit)
.order_by(func.rand())
.first()
)
async def create_puzzle_phase1(self) -> None:
"""
0으로 초기화 된 맵에 첫 단어를 추가,
이 후 추가될 단어와 그 위치에 대한 힌트를 큐에 삽입,
첫 단어 설명 추가
"""
word = await self.find_first_word_info()
start_y, start_x = 0, 0
for i in range(word.len):
self.map[start_y][start_x + i] = 1
self.words.append({"num": 1, "word": word.word})
self.desc.append({"num": 1, "desc": word.desc})
self.queue = await self.append_letter_into_queue(
(start_y, start_x), word.len, word.word, True
)
async def inspect_possible_length(self, point: Tuple[int, int], dir: bool) -> int:
"""
단어의 시작 좌표와 방향으로 가능한 단어의 최대 길이를 반환한다.
Args:
point (Tuple[int,int]): 단어가 시작될 좌표
dir (bool): 단어의 가로, 세로 여부
Returns:
int: 가능한 단어의 길이
"""
y, x = point
if x >= 1:
if dir and self.map[y][x - 1] != 0:
return 0
if y >= 1:
if not dir and self.map[y - 1][x] != 0:
return 0
if dir:
for i in range(1, 5):
if (
(y - 1 >= 0 and self.map[y - 1][x + i] != 0)
or (y + 1 < self.map_size and self.map[y + 1][x + i] != 0)
or (x + i < self.map_size - 1 and self.map[y][x + i + 1] != 0)
or (x + i == self.map_size - 1)
):
return i
else:
for i in range(1, 5):
if (
(x - 1 >= 0 and self.map[y + i][x - 1] != 0)
or (x + 1 < self.map_size and self.map[y + i][x + 1] != 0)
or (y + i < self.map_size - 1 and self.map[y + i + 1][x] != 0)
or (y + i == self.map_size - 1)
):
return i
return 5
async def create_puzzle_phase2(self) -> Dict:
"""
단어 하나가 삽입된 상태에서, 시작 어절이 같은 단어를 찾아 추가한다.
단, 진행방향의 삼면에 이미 다른 단어의 어절이 없어야 한다.
이 함수는 두 번째 페이즈로, 처음 추가된 단어와 이어지는 경우에만 단어를 추가한다.
Args:
db (Session): 커넥션
map_queue_desc (Dict): 맵, 큐, 설명 및 단어가 들어있는 사전형 자료
Returns:
Dict: 맵, 큐, 설명 및 단어가 들어있는 사전형 자료
"""
await self.create_puzzle_phase1()
while self.queue:
point, start_word, dir = self.queue.popleft()
limit = await self.inspect_possible_length(point, dir)
if limit <= 1:
continue
next_word = await self.find_word_info_start_with(start_word, limit)
if not next_word:
continue
for i in range(next_word.len):
if dir:
self.map[point[0]][point[1] + i] = self.num
else:
self.map[point[0] + i][point[1]] = self.num
self.words.append({"num": self.num, "word": next_word.word})
self.desc.append({"num": self.num, "desc": next_word.desc})
self.num += 1
self.queue = await self.append_letter_into_queue(
point, next_word.len, next_word.word, dir
)
return {"map": self.map, "desc": self.desc, "words": self.words}Phase3: 남은 공간 채우기
남은 공간을 최대한 채우기 위해 퍼즐을 순회하며 아직 0인 좌표에 대해서 단어를 추가할 수 있는지 검증한 뒤 Phase2처럼 가능한 이어서 붙이기로 했습니다.
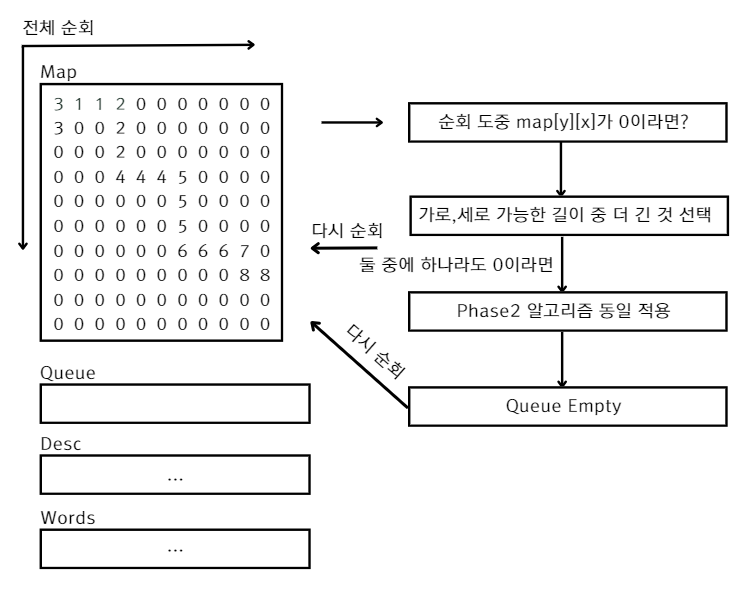
# 가능한 단어 길이 검사 함수 로직 추가
async def inspect_possible_length(
self, point: Tuple[int, int], dir: bool, phase: int = 2
) -> int:
"""
단어의 시작 좌표와 방향으로 가능한 단어의 최대 길이를 반환한다.
Args:
point (Tuple[int,int]): 단어가 시작될 좌표
dir (bool): 단어의 가로, 세로 여부
phase (int): 퍼즐 생성 단계
Returns:
int: 가능한 단어의 길이
"""
y, x = point
if phase == 3:
if y > 0 and self.map[y - 1][x] != 0:
return 0
if y < self.map_size - 1 and self.map[y + 1][x] != 0:
return 0
if x > 0 and self.map[y][x - 1] != 0:
return 0
if x < self.map_size - 1 and self.map[y][x + 1] != 0:
return 0
if x >= 1:
if dir and self.map[y][x - 1] != 0:
return 0
if y >= 1:
if not dir and self.map[y - 1][x] != 0:
return 0Phase3에서는 단어 시작하는 곳에서도 상하좌우를 확인해야합니다.
async def fill_puzzle_until_queue_empty(self) -> None:
"""
큐가 빌 때까지 퍼즐에 단어를 추가시킨다.
"""
while self.queue:
point, start_word, dir = self.queue.popleft()
limit = await self.inspect_possible_length(point, dir)
if limit <= 1:
continue
next_word = await self.find_word_info_start_with(start_word, limit)
if not next_word:
continue
for i in range(next_word.len):
if dir:
self.map[point[0]][point[1] + i] = self.num
else:
self.map[point[0] + i][point[1]] = self.num
self.words.append({"num": self.num, "word": next_word.word})
self.desc.append({"num": self.num, "desc": next_word.desc})
self.num += 1
self.queue = await self.append_letter_into_queue(
point, next_word.len, next_word.word, dir
)
async def create_puzzle_phase2(self) -> None:
"""
단어 하나가 삽입된 상태에서, 시작 어절이 같은 단어를 찾아 추가한다.
단, 진행방향의 삼면에 이미 다른 단어의 어절이 없어야 한다.
이 함수는 두 번째 페이즈로, 처음 추가된 단어와 이어지는 경우에만 단어를 추가한다.
"""
await self.create_puzzle_phase1()
await self.fill_puzzle_until_queue_empty()Phase2에서 큐가 빌 때까지 단어 추가해주던 로직을 추출했고,
async def create_puzzle_phase3(self) -> Dict:
"""
퍼즐의 비어있는 공간에 단어를 추가한다.
Returns:
Returns:
Dict: 맵, 설명 및 단어가 들어있는 사전형 자료
"""
await self.create_puzzle_phase2()
for i in range(self.map_size - 1):
for j in range(self.map_size - 1):
if self.map[i][j] == 0:
hor = await self.inspect_possible_length((i, j), True, phase=3)
ver = await self.inspect_possible_length((i, j), False, phase=3)
dir = True if hor > ver else False
if not (hor and ver):
continue
else:
word = await self.find_word_info_start_with("", hor if hor > ver else ver)
if not word:
continue
for k in range(word.len):
if dir:
self.map[i][j + k] = self.num
else:
self.map[i + k][j] = self.num
self.words.append({"num": self.num, "word": word.word})
self.desc.append({"num": self.num, "desc": word.desc})
self.num += 1
self.queue = await self.append_letter_into_queue(
(i, j), word.len, word.word, dir
)
await self.fill_puzzle_until_queue_empty()
return {"map": self.map, "desc": self.desc, "words": self.words}추출한 로직을 Phase3에서도 사용하도록 구성했습니다.
저는 이전에 Class형태로 의존성을 주입하도록 코드를 리팩토링 했기 때문에
엔드포인트도 수정이 필요합니다.
from fastapi import APIRouter, status, Depends
from app.utils.puzzle import PuzzleCreateService
router = APIRouter(tags=["PuzzleV1"], prefix="/puzzle")
@router.get("", status_code=status.HTTP_200_OK)
async def create_puzzle(puzzle: PuzzleCreateService = Depends(PuzzleCreateService)):
return await puzzle.create_puzzle_phase3()추가적인 성능 개선
Phase3까지 모두 돌아갔을 때 어느정도 시간이 걸리는지 확인해볼까요?
위의 시간 테스트에서 맵 크기를 10x10으로 했기 때문에 동일하게 하겠습니다. 직접 해보실 분들은 Swagger 문서에서 size 파라미터에 10 적고 해보시면 됩니다.
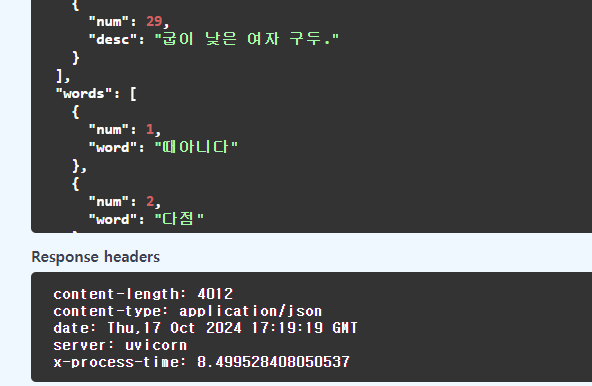
단어가 총 29개나 들어가있네요. 단어 수가 많기도 하지만 게임판을 생성하는데에 약 8.5초나 걸리는건 꽤나 아쉽습니다.
성능을 한 번 더 개선해봅시다.
EXPLAIN SELECT * FROM wordinfo
WHERE word LIKE '마%'
AND len <= 5
ORDER BY RAND()
LIMIT 1;"마"로 시작하면서 길이가 5 이하인 단어를 찾을 때,
SQLAlchemy ORM을 통해 생성될 SQL ROW Query의 실행 계획을 확인해봅시다.

확인해봐야할 row가 47만개가 넘어가면서, 탐색해야할 범위가 큰 것을 알 수 있습니다. 실제로 저 SQL문을 실행하면 약 0.25초가 걸립니다.
탐색 범위를 좁히기 위해 인덱스를 테이블에 걸어주는 방법이 있습니다.
우리는 word와 len에 조건을 걸어서 탐색하고 있습니다.
그런데 인덱스는 카디널리티가 클 수록 성능이 좋아지는 경향이 있습니다.
len은 2~5까지의 범위뿐이라 카디널리티가 매우 작습니다.
따라서, word에 인덱스를 걸어보도록 하죠.
class WordInfo(BaseMin, Base):
__tablename__ = "wordinfo"
word = Column(VARCHAR(5), nullable=False, index=True)
desc = Column(VARCHAR(200), nullable=False)
len = Column(Integer, nullable=False)
pos = Column(VARCHAR(7), nullable=False)모델을 수정하고 alembic으로 마이그레이션하는 방법이 있고,
CREATE INDEX ix_wordinfo_word ON wordinfo(word);MySQL에서 직접 인덱스를 생성하는 방법도 있습니다.
인덱스 생성 후에 실행 계획을 다시 살펴보겠습니다.

탐색해야 할 row가 현저히 줄어들었습니다. 위에서는 null 값이었던 key에 저희가 생성해준 인덱스도 들어있는 것을 확인할 수 있습니다.

실제로 조회 성능이 0.25초에서 0.015초로 무려 약 94%나 향상됐네요.
다시 한 번 퍼즐을 생성해봅시다.
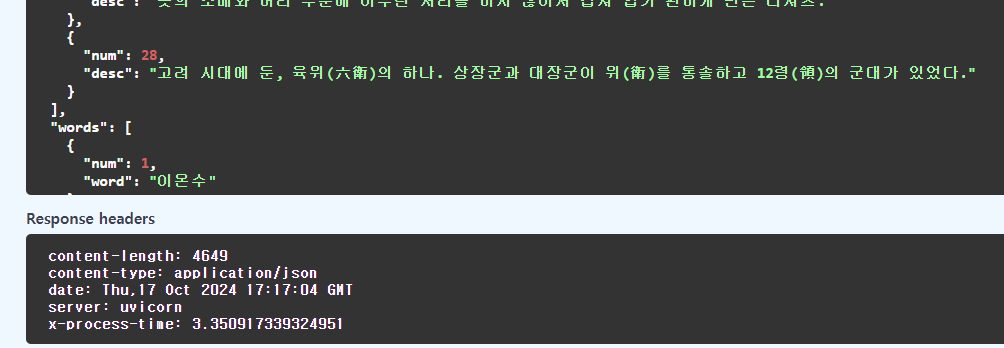
단어 수가 1개 적은 28개이긴 하지만, 약 3.4초 정도로 나왔습니다.
인덱스를 생성 이전 8.5초에서 생성 후 3.4초로 약 60%의 향상률을 보였습니다.
다음 포스트에서는 결과적으로 생성된 데이터의 형태를 알아보고
데이터베이스에 추가하는 작업을 해보겠습니다.
읽어주셔서 감사합니다.
