- 실제 강의 내용의 일부분만 발췌했습니다.
<2차가공 데이터(직전 포스팅 결과 데이터)>
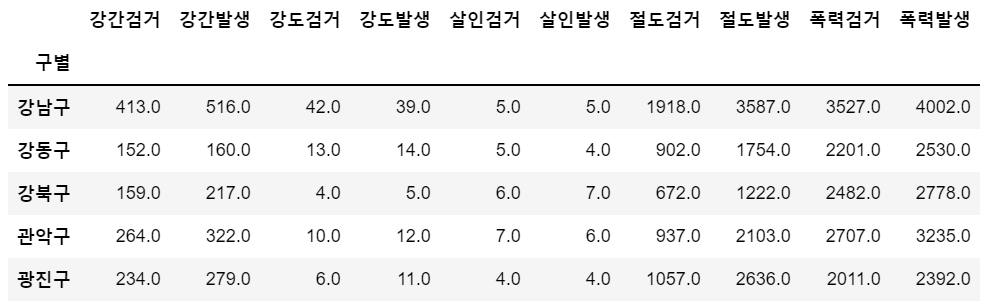
<3차가공 데이터>
# 검거율 도출: 다수의 컬럼을 다수의 컬럼으로 각각 나누기
num = ["강간검거","강도검거","살인검거","절도검거","폭력검거"]
den = ["강간발생","강도발생","살인발생","절도발생","폭력발생"]
target = ["강간검거율","강도검거율","살인검거율","절도검거율","폭력검거율"]
crime_anal_gu[target] = crime_anal_gu[num].div(crime_anal_gu[den].values)*100
crime_anal_gu.head()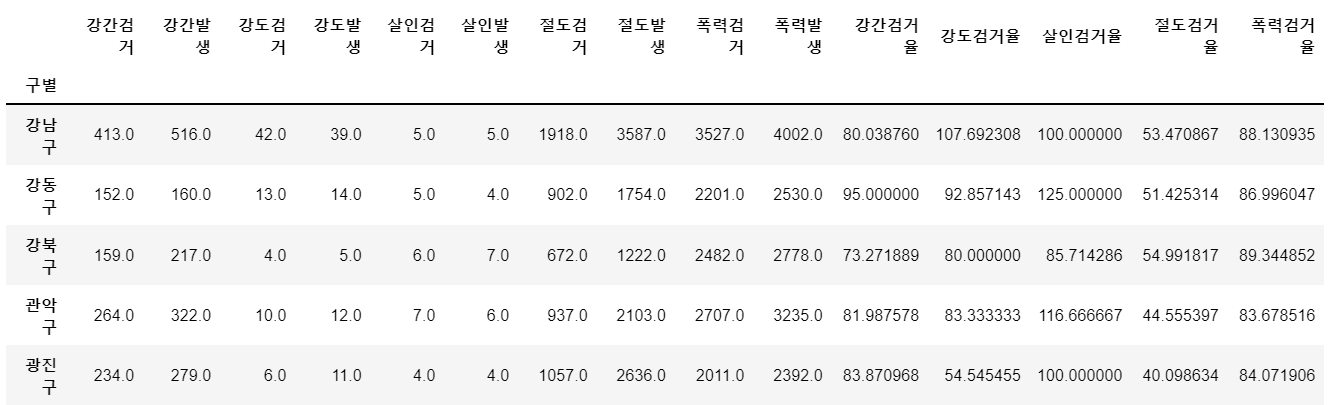
# 범죄검거(~~검거) 컬럼 제거
crime_anal_gu.drop(num, axis = 1, inplace = True)
crime_anal_gu.head()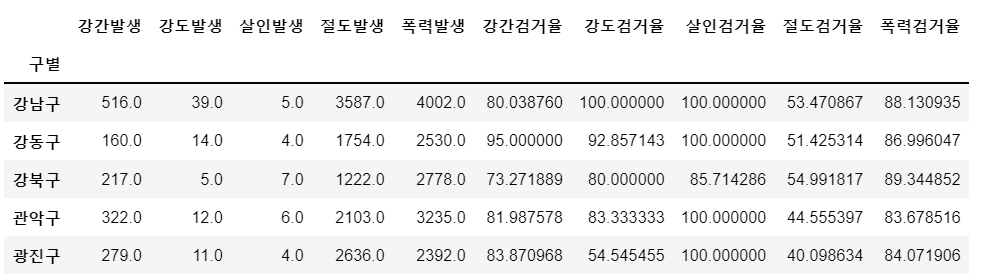
# 발생은 1개년 대상으로, 검거율은 다년간 누적 범죄에 대한 집계
# 검거율 100을 넘는 경우 有
# 검거율 100보다 큰 숫자 찾아서 바꾸기 for drawing heatmap
crime_anal_gu[crime_anal_gu[target]> 100] = 100
# 컬럼 이름 변경
crime_anal_gu.rename(columns = {
"강간발생":"강간","강도발생":"강도",
"살인발생":"살인","절도발생":"절도","
폭력발생":"폭력"}, inplace = True)
crime_anal_gu.head()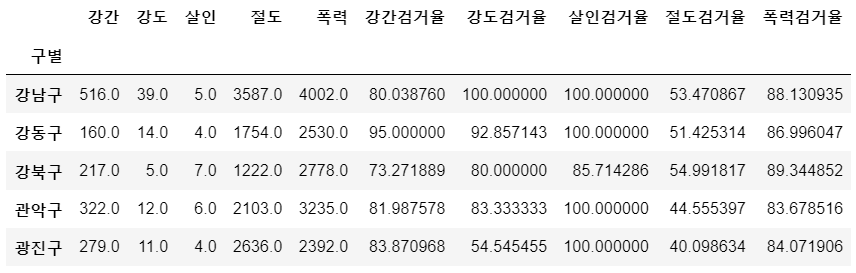
import matplotlib.pyplot as plt
import seaborn as sns
from matplotlib import rc
#마이너스 부호로 한글 깨지지 않게 하는 설정
plt.rcParams["axes.unicode_minus"]= False
rc("font", family = "Malgun Gothic")
get_ipython().run_line_magic("matplotlib","inline")
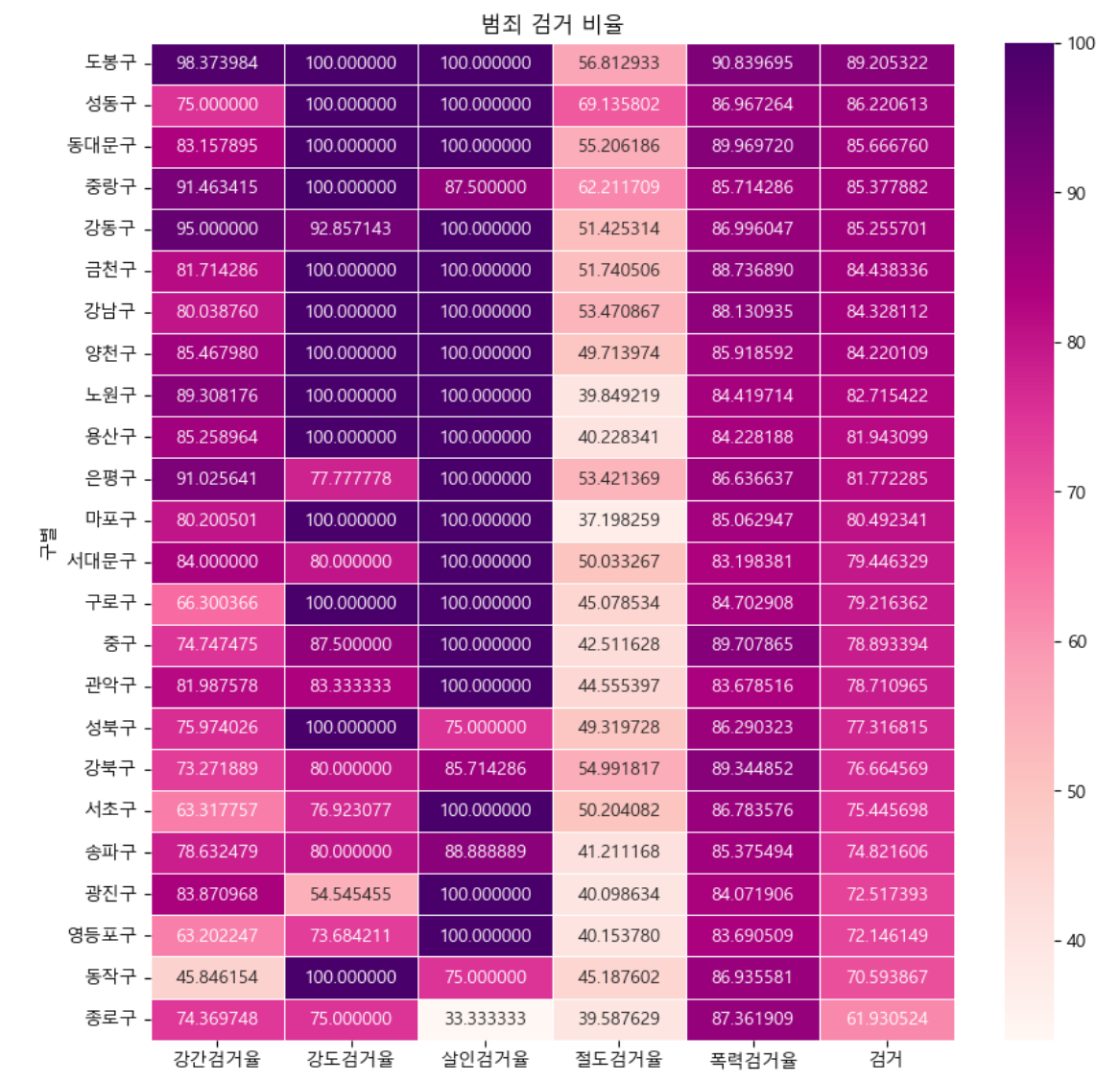
# 서울특별시 구별 검거율 heatmap을 생성해보자.
# 검거율의 평균을 값으로 갖는 "검거" 컬럼 생성
crime_anal_gu["검거"] = np.mean(crime_anal_gu[target], axis = 1)
def drawGraph():
#데이터 프레임 생성
target_col = [
"강간검거율","강도검거율","살인검거율",
"절도검거율","폭력검거율","검거"]
crime_anal_gu_sort = crime_anal_gu.sort_values(
by = "검거",
ascending = False) #내림차순
# 그래프 설정
plt.figure(figsize = (10,10)) # 그래프 크기
sns.heatmap(
data= crime_anal_gu_sort[target_col],
annot= True, # 데이터값 표기: True, 색만 표기:False
fmt = "f", # d: 정수, f: 실수
linewidths = 0.5 ,# 간격 설정
cmap = "RdPu" #색상 설정
)
plt.title("범죄 검거 비율")
plt.show()
drawGraph()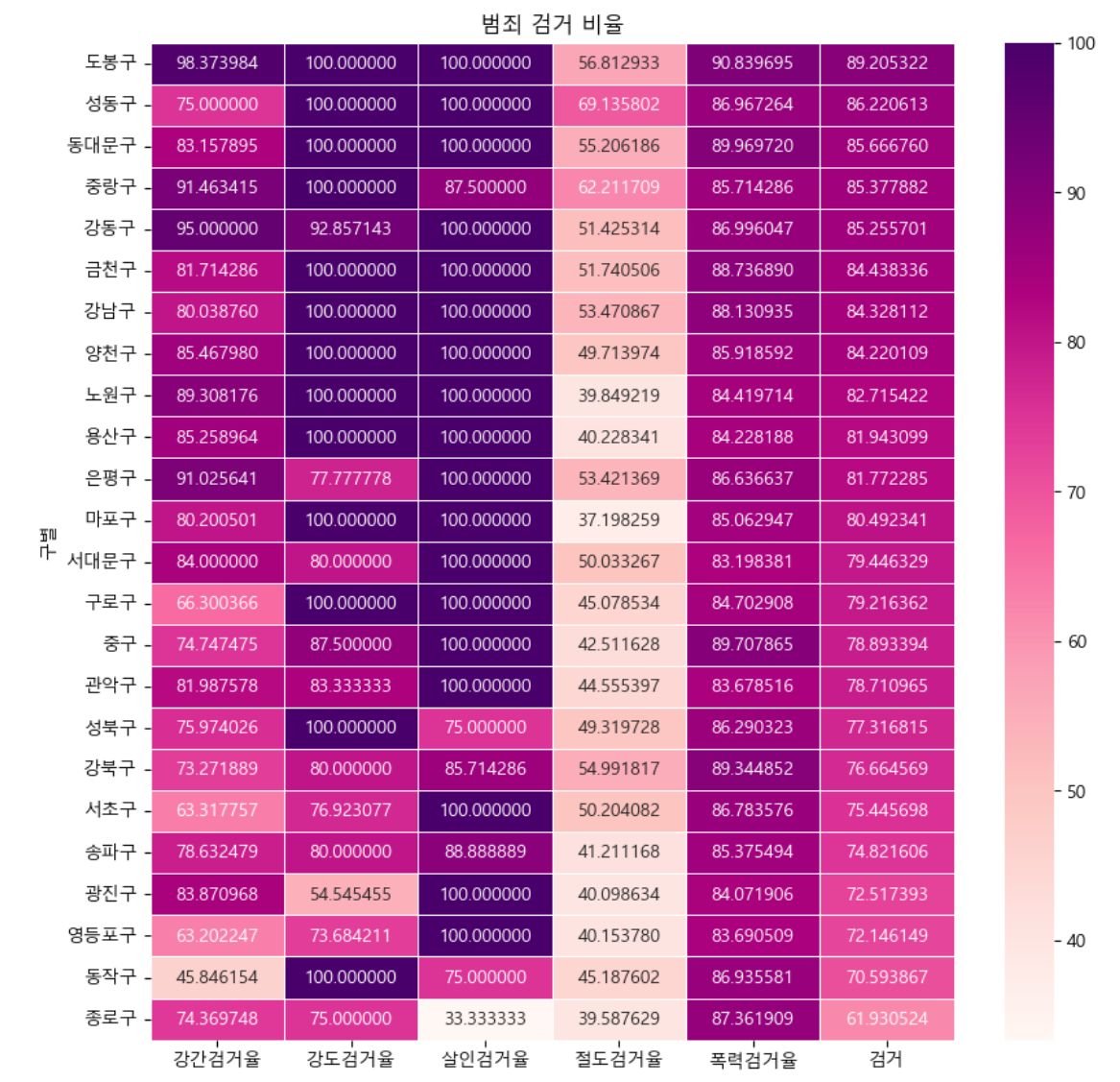

쉽고 유익하게 널리널리