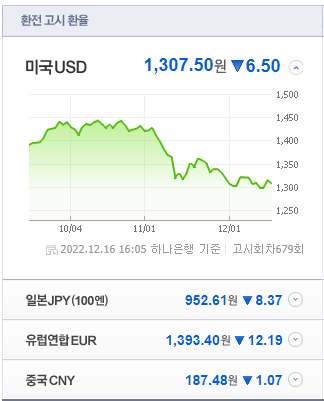
<원본 웹 데이터>
<결과 데이터>

find, find_all과 같은 기능의 메소드인 select_one, select를 활용해서 4개국 환율과 등락, 관련 링크를 크롤링해보자.
import requests
from bs4 import BeautifulSoup
url = "https://finance.naver.com/marketindex/"
response = requests.get(url)
soup = BeautifulSoup(response.text, "html.parser")
# 기능적인 면에서 find = select_one
# 기능적인 면에서 find_all = select
# select, select_one은 복수 파라미터 입력 X
# id는 #, class는 .으로 표기해서 속성값 한번에 이어붙인 파라미터로 입력 O
# id가 exchangeList인 태그 직속 하위에 있는 li 태그 데이터를 리스트로 반환
exchangeList = soup.select("#exchangeList > li")
# 리스트 중 클래스가 h_1st, value, change인 경우
title = exchangeList[0].select_one(".h_lst").text
exchange = exchangeList[0].select_one(".value").text
change = exchangeList[0].select_one(".change").text
print(title," ", exchange," ", change)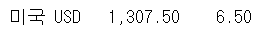
# 클래스 속성 값으로 있는 키워드에 띄워쓰기가 있으면, 속성 값을 분리하여 각각 인식
# 클래스 속성 값이"a b"이면 a와 b, 속성값 2개임.
# 속성값을 이용하여 데이터를 찾을 때 ".a.b"로 입력해줘야함
updown = exchangeList[0].select_one("div.head_info.point_dn>.blind")
print(updown.text)
# 기본 url 뒤에 추가되는 url만 있음. 기본 url을 합쳐줘야함.
link = exchangeList[0].select_one("a").get("href")
baseUrl = "https://finance.naver.com"
baseUrl + exchangeList[0].select_one("a").get("href")
# 4개 데이터 수집
exchange_datas = []
baseUrl = "https://finance.naver.com"
for item in exchangeList:
data = {
"title": item.select_one(".h_lst").text,
"exchange" : item.select_one(".value").text,
"change" : item.select_one(".change").text,
# down에 해당하지 않을 경우 nonetype 반환
# nonetype반환될 경우 up에 있는 데이터 긁어오기
"updown" : item.select_one\
(".head_info.point_dn>.blind").text\
if str(type(item.select_one\
(".head_info.point_dn >.blind"))) != "<class 'NoneType'>" \
else item.select_one(".head_info.point_up >.blind").text,
"link" : baseUrl + item.select_one("a").get("href")
}
# 리스트 각 요소를 분리해서 딕셔너리로 저장
# 각 딕셔너리를 리스트에 item으로 저장
exchange_datas.append(data)
import pandas as pd
# 키값을 공유하는 딕셔너리들을 item으로 갖는 리스트를 데이터프레임으로 변환
df = pd.DataFrame(exchange_datas)
# csv 파일로 데이터프레임 저장
df.to_csv("./naverfinance.csv", encoding = "utf-8")

쉽고 유익하게 널리널리