- 실제 강의 내용의 일부분만 발췌했습니다.
<원본데이터>
<결과데이터>

import urllib
from urllib.request import urlopen, Request
from bs4 import BeautifulSoup
html = "http://ko.wikipedia.org/wiki/{search_words}"
#https://ko.wikopedia.org/wiki/재벌집_막내아들
#글자를 url로 인코딩
req = Request(html.format(search_words = urllib.parse.quote("재벌집_막내아들")))
response= urlopen(req)
response.status200
soup = BeautifulSoup(response, "html.parser")
n = 0
for each in soup.find_all("ul"):
print(str(n)+"="*30)
print(each.text)
n += 1
soup.find_all("ul")[38].text
soup.find_all("ul")[38].text.replace("\xa0", " ")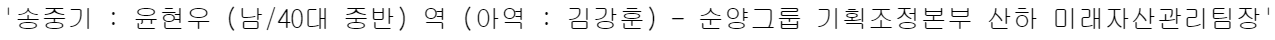
for i in range(38, 62):
print(soup.find_all("ul")[i].text.replace("\xa0"," "))

쉽고 유익하게 널리널리