- 실제 강의 내용의 일부분만 발췌했습니다.
<크롤링하고자 하는 페이지 html 중 body>
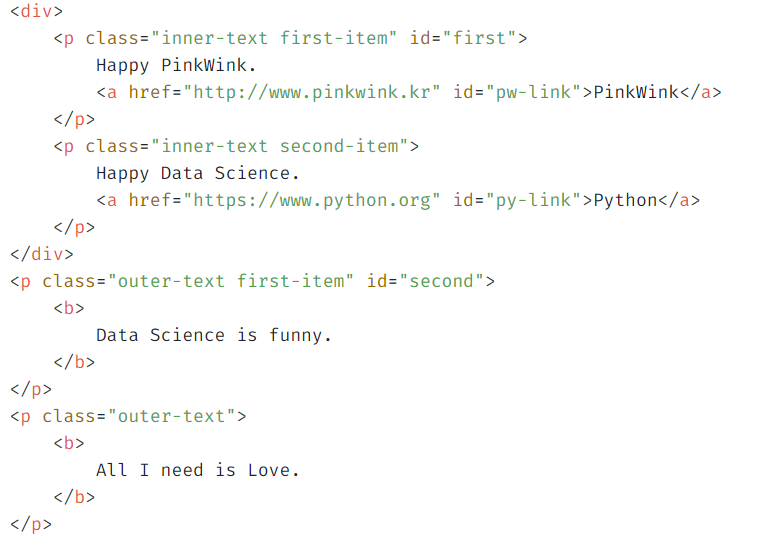
<결과 데이터>

p태그에 있는 텍스트를 출력해보자
#BeautifulSoup 사용하기 위한 선언
from bs4 import BeautifulSoup
# 같은 폴더에 저장되어 있으므로 html 파일명만 "r"모드로 open후 read() 메소드 호출
page = open("03. zerobase.html","r").read()
# page에 대한 BeautifulSoup 객체 형성
soup = BeautifulSoup(page, "html.parser")
# head 태그 확인
soup.head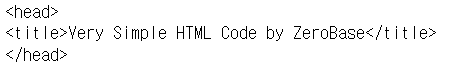
# body 태그 확인은 soup.body
# 특정태그(여기서는 p) 확인하는 방법
# 1. soup.p - 처음 발견되는 p태그 하나만 찾아줌
# 2. soup.find("p") - 처음 발견되는 p태그 하나만 찾아줌
# 3. soup.find_all("p") -p태그가 있는 모든 태그를 리스트 형태로 반환
soup.find_all("p")
# 태그 안에 속성값까지 설정해서 검색하기
# id의 경우 유일무이한 값이므로 검색하기 용이한 값이라고 할 수 있다.
soup.find("p", {"class":"inner-text first-item", "id":"first"})
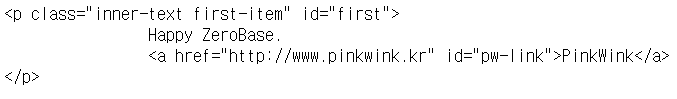
# 찾는 태그안에 문자를 추출하는 3가지 방법
print(soup.find_all("p")[0].text)
print(soup.find_all("p")[1].string)
print(soup.find_all("p")[2].get_text())
#p태그 리스트에서 텍스트 속성만 출력
for each_tag in soup.find_all("p"):
print("="*40)
print(each_tag.text)

쉽고 유익하게 널리널리