- 실제 강의내용의 일부분만 발췌하였습니다.
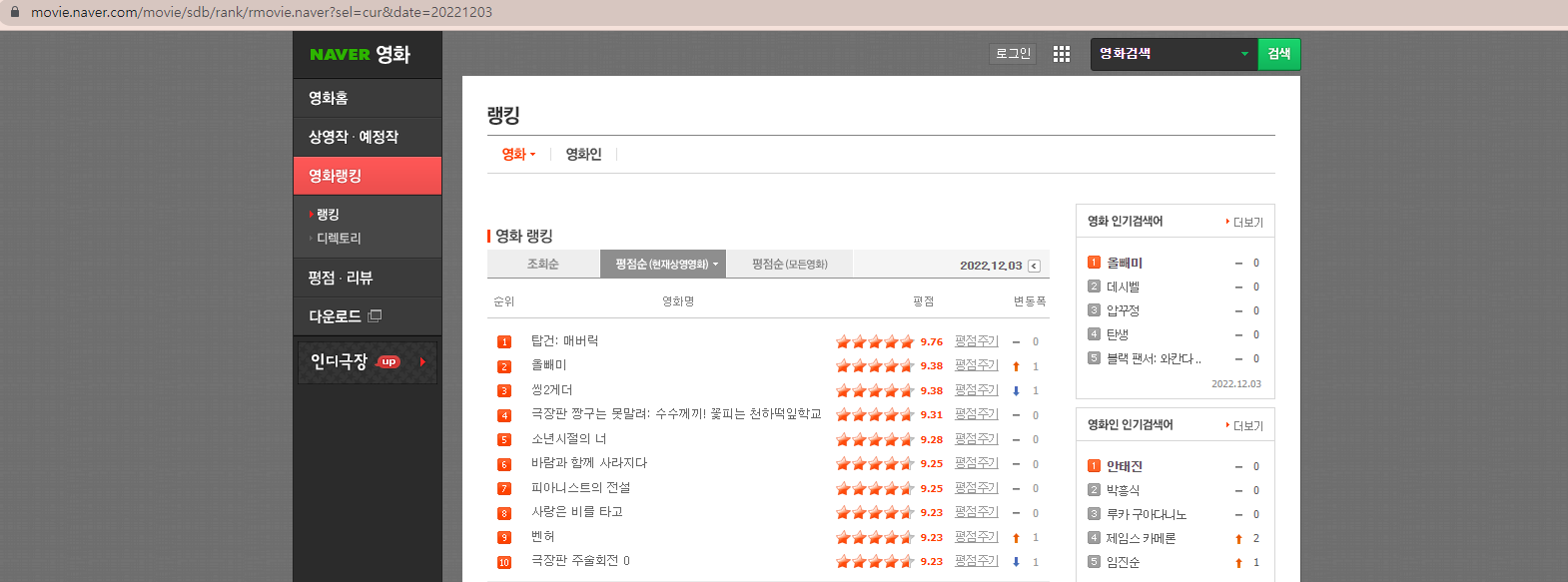
<크롤링하고자 하는 페이지>
<결과 그래프>
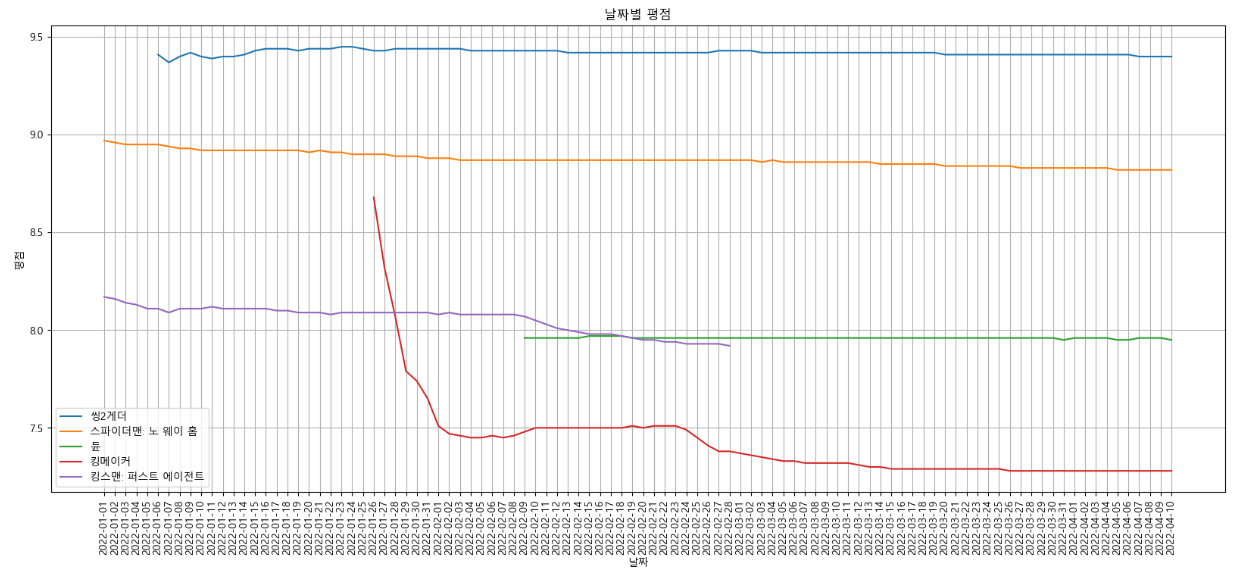
날짜별로 영화 평점을 표현해보자
# requirement
import pandas as pd
import numpy as np
from urllib.request import urlopen
from bs4 import BeautifulSoup
#링크에 표기된 날짜를 바꿔가며 크롤링하기 위해 날짜 범주 리스트 생성
date = pd.date_range("2022.01.01", periods=100, freq = "D")
date
movie_date = []
movie_name = []
movie_point = []
for today in date:
url = "https://movie.naver.com/movie/sdb/rank/rmovie.naver?sel=cur&date={date_}"
# url 스트링 중 {}안의 date_ 변수를 today로 대체
# today 날짜 형식이 2022-01-01인데 20220101로 변환 후 date_에 대입
response = urlopen(url.format(date_=today.strftime("%Y%m%d")))
# url을 여는 창(response)을 html로 읽어내는 역할
soup = BeautifulSoup(response, "html.parser")
# soup에 담긴 html코드 중 "td"와 "point"가 들어간 코드의 개수
end = len(soup.find_all("td","point"))
# 리스트1.extend(리스트2)는 "리스트2"를 item으로 받아들이지 않음
# 리스트1.extend(리스트2)는 리스트1에 "리스트2 item"을 item으로 받아들임
movie_date.extend([today for _ in range(0, end)])
# div class tit5인 태그 내 <a>태그내 text만 뽑아냄 -> 영화제목
movie_name.extend([soup.select("div.tit5")[n].find("a").text \
for n in range(0, end)])
# td, point가 들어간 태그 내 text만 뽑아냄 -> 영화 평점
movie_point.extend([soup.find_all("td","point")[n].string\
for n in range(0, end)])
# 날짜, 영화제목, 영화평점 리스트로 데이터프레임 만들기
# 변수명 = pd.DataFrame({ "콜룸명1" : 리스트명1, "콜룸명2": 리스트명2, ..})
movie = pd.DataFrame({
"Date" : movie_date,
"Title" : movie_name,
"Point" : movie_point
})
movie.tail()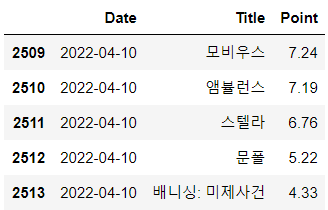
# 데이터프래임 내 특정 컬럼 형변환
# 문자열로 된 콜룸을 그래프를 그리기 위해 실수형으로 변환
movie["Point"] = movie["Point"].astype(float)
# 날짜를 인덱스로 제목을 컬럼으로, 값을 평점으로 피봇테이블 형성
movie_pivot = pd.pivot_table(data=movie, \
index = "Date", columns = "Title", values = "Point")
# 피봇테이블 확인해보기
movie_pivot.loc['2022-03-01':'2022-03-05',\
movie_pivot.columns[40]:movie_pivot.columns[50]]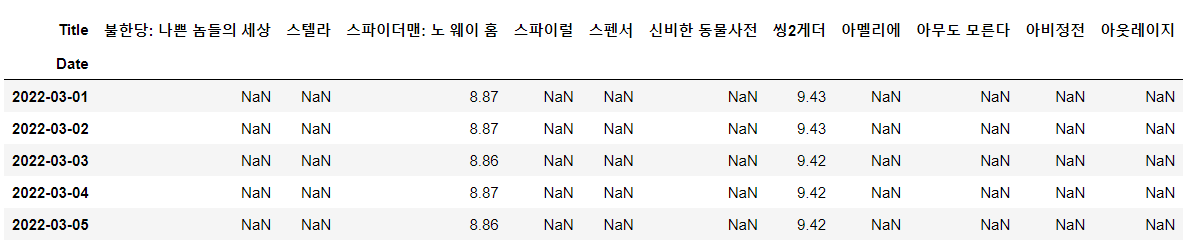
# 시각화하기
import matplotlib.pyplot as plt
import seaborn as sns
from matplotlib import font_manager, rc
font_name = font_manager.FontProperties(fname = path).get_name()
rc("font",family = font_name)
# 날짜별 평점을 확인하고 싶은 영화 목록 지정
target_col =["씽2게더", "스파이더맨: 노 웨이 홈",
"듄","킹메이커","킹스맨: 퍼스트 에이전트"]
plt.figure(figsize = (20, 8))
plt.title("날짜별 평점")
plt.xlabel("날짜")
plt.ylabel("평점")
plt.xticks(rotation = "vertical")
plt.plot(movie_pivot[target_col])
plt.legend(target_col, loc="best")
plt.grid(True)

쉽고 유익하게 널리널리