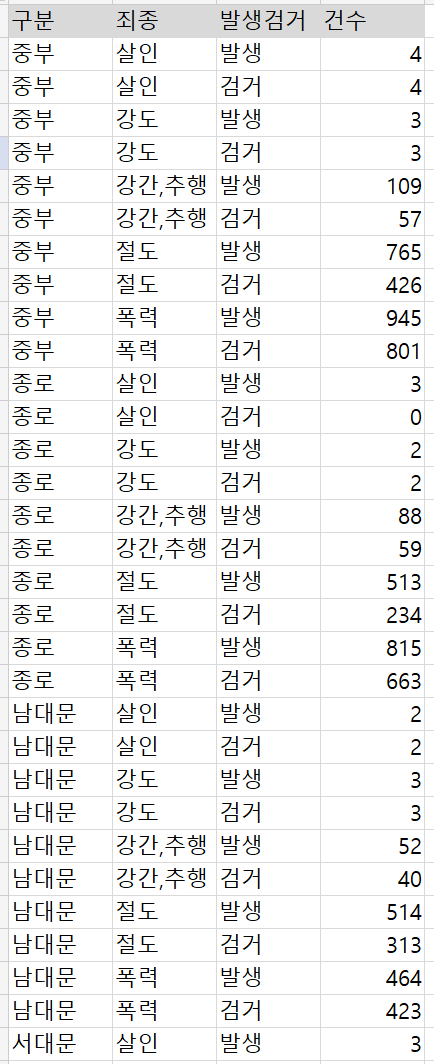
<원본데이터>
경찰서별 5대 범죄 발생 검거 현황
<가공 후 데이터 형태>
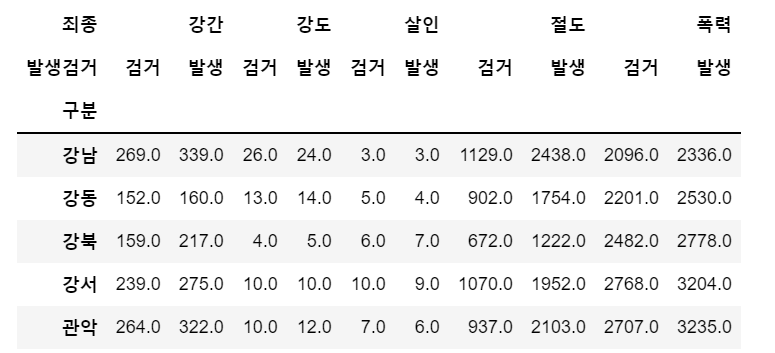
pandas pivot table 기능을 활용하여 서울시 경찰소별 5대 범죄 현황 데이터를 가공해보자
import numpy as np
import pandas as pd
# 다운로드 받은 파일 읽어오기
crime_raw_data = pd.read_csv(
"../data/02. crime_in_Seoul.csv",
thousands = ",", # 숫자사이 콤마를 seperator로 인식하지 말 것
encoding = "euc-kr" #한글 파일이라서 추가로 encoding
)
# 읽어온 데이터 정보 개요 확인
crime_raw_data.info()
데이터는 65,534개인데 그중 실제로 정보가 담겨져 있는 데이터는 310개이고 나머지는 null값이 기입되어 있음을 알 수 있다. 불필요한 데이터는 배제하고 분석하기 위해 null값이 기입되어있는 데이터는 삭제한다.
# NaN으로 이루어진 데이터 row들 삭제
crime_raw_data = crime_raw_data[crime_raw_data["죄종"].notnull()]
crime_raw_data.info()
# pivot_table 만들기
crime_station= crime_raw_data.pivot_table(
index="구분", # 행기준데이터
columns = ["죄종", "발생검거"], #열기준데이터
aggfunc=[np.sum]) # 표기할 데이터 연산(default는 평균)
crime_station.head()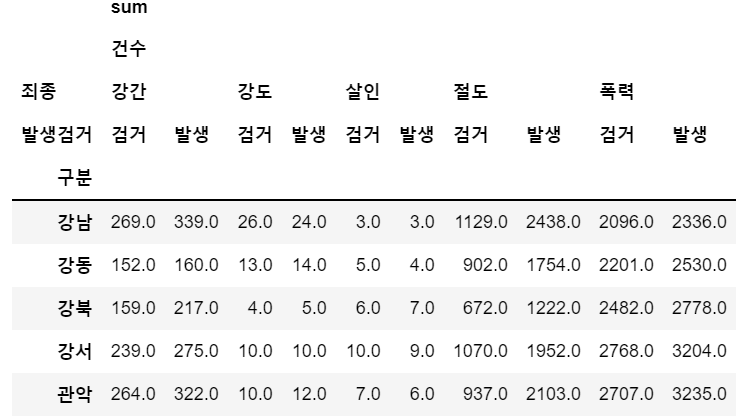
# 다중 컬럼에서 특정 컬럼(sum, 건수) 제거
crime_station.columns = crime_station.columns.droplevel([0,1])
crime_station.head()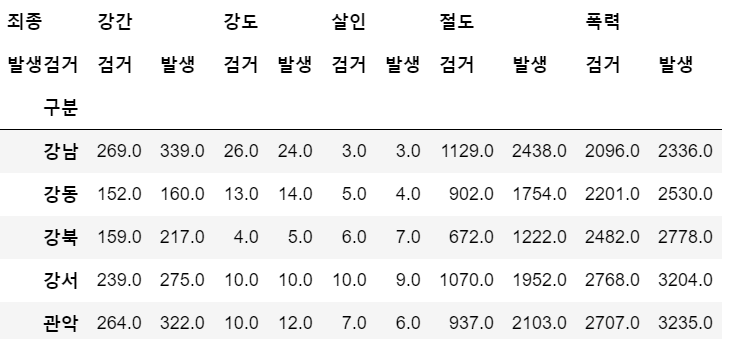
기타 pandas pivot table
#기본데이터
df = pd.read_csv("../data/02. sales-funnel.csv")
df.head()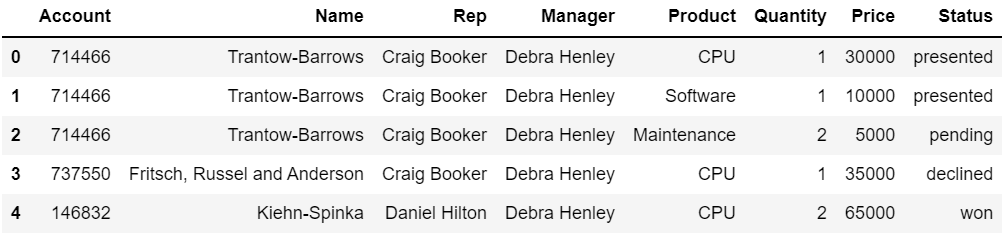
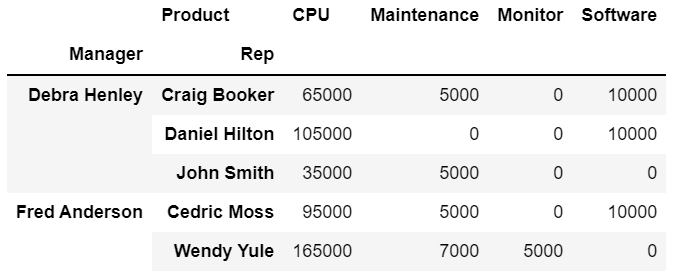
# 판다스 데이터 프레임 df에 대하여 피봇테이블 형성
df.pivot_table(
index = ["Manager","Rep"], #행기준 데이터
values="Price", # 행기준X열기준에 표기될 값
columns="Product", #열기준 데이터
aggfunc = np.sum, #표기될 값의 연산 형태
fill_value = 0 #NaN값이 있을 경우 대체해서 표기할 값
)
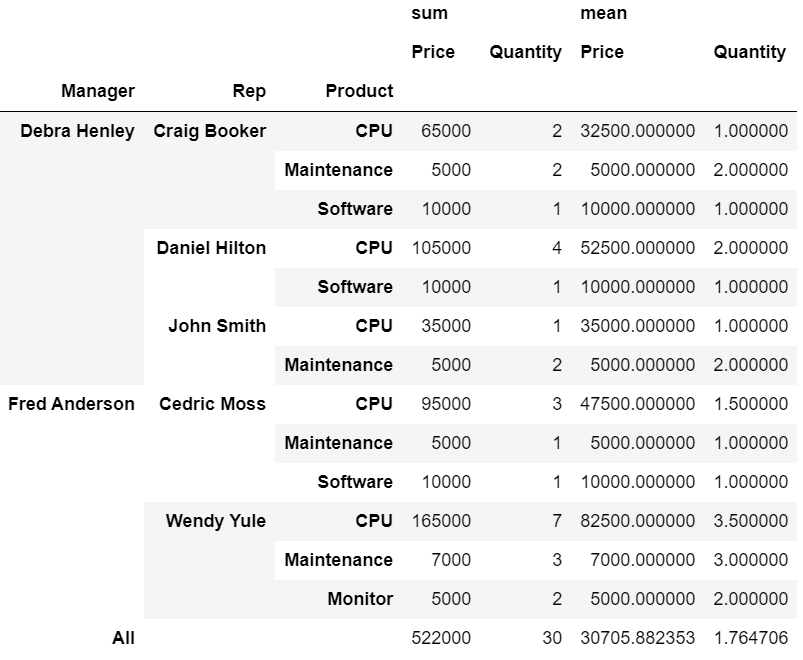
# 2개 이상의 values, 2개 이상의 arrfunc 설정시
df.pivot_table(
index = ["Manager","Rep","Product"],
values = ["Price","Quantity"],
aggfunc = [np.sum, np.mean],
fill_value = 0,
margins = True #총계(all) 추가
)

쉽고 유익하게 널리널리