
1. 하이퍼파라미터 튜닝
- 모델에서 사람이 설정해주어야 하는 옵션을 하이퍼파라미터라고하며, 모델 성능을 최적화하는 하이퍼파라미터를 찾는 과정을 튜닝이라고 한다.
- 하이퍼파라미터 튜닝 수행 방법에는 그리드서치, 랜덤서치, 베이지안 최적화, 수동 튜닝이 있다.
2. GridSearchCV란
- 그리드서치(GridSearch)는 각 파라미터에 대하여 경우의 수를 지정해주면 모든 경우의 수에 대하여 모델의 성능을 평가해보는 것이다.
- 데이터 세트가 작을 때 유리하다.
- CV는 cross-validation(교차검증)의 약어로 원본 데이터셋을 훈련용과 테스트용으로 분리한 후, 다시 훈련용 데이터를 학습용, 검증용 데이터로 분리하여 모델성능을 재차 평가하는 구조로 모델 성능을 교차 검증하는 것을 의미한다.
- GridSearchCV는 교차검증을 통해 그리드서치를 수행하는 모듈이다.
3. GridSearchCV 모듈 활용하기
데이터 불러오기
import pandas as pd
red_url = 'https://raw.githubusercontent.com/PinkWink/\
ML_tutorial/master/dataset/winequality-red.csv'
white_url = 'https://raw.githubusercontent.com/PinkWink/\
ML_tutorial/master/dataset/winequality-white.csv'
red_wine = pd.read_csv(red_url, sep = ';')
white_wine = pd.read_csv(white_url, sep = ';')
red_wine['color'] =1
white_wine['color']=0
wine = pd.concat([red_wine, white_wine])
X = wine.drop(['color'], axis = 1)
y = wine['color']
wine['taste'] = [ 1 if grade > 5 else 0 for grade in X['quality']]
X= wine.drop(['taste','quality'], axis = 1)
y = wine['taste']
from sklearn.model_selection import train_test_split4가지 값에 대하여 5번 교차검증
- 학습, 예측, 성능평가가 4 X 5 = 20번 수행된다.
from sklearn.model_selection import GridSearchCV
from sklearn.tree import DecisionTreeClassifier
from sklearn.metrics import accuracy_score
from sklearn.pipeline import Pipeline
from sklearn.tree import DecisionTreeClassifier
from sklearn.preprocessing import StandardScaler
estimators = [
('scaler', StandardScaler()),
('clf', DecisionTreeClassifier())
]
pipe = Pipeline(estimators)
# 하이퍼파라미터 값 4가지 지정
params = {'max_depth': [2,4,7,10]}
wine_tree = DecisionTreeClassifier(max_depth = 2, random_state = 13)
# cv = 5이므로 5번 교차검증
gridsearch = GridSearchCV(estimator = wine_tree, param_grid= params, cv = 5)'
gridsearch.fit(X, y)
import pprint
pp = pprint.PrettyPrinter(indent = 4)
pp.pprint(gridsearch.cv_results_)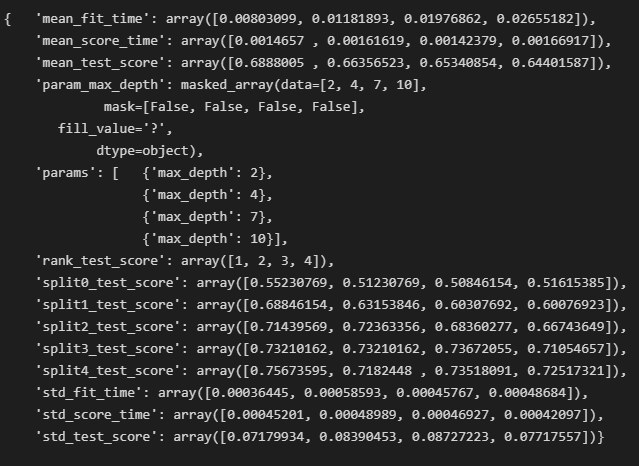
best_estimator 호출
gridsearch.best_estimator_
best_score 호출
- GridSearchCV에 scoring을 지정을 별도로 안할 경우 기본적으로 accuracy로 평가한다.
GridSearch.best_score_
4. 수동으로 코드 구현하기
- 경우에 따라서는 GridSearchCV, cross_val_score 모듈을 사용할 수 없을 때가 있다.
- 수동으로 교차검증을 구현해보자.(특정 clf에 대하여 교차검증 수행 후 성능 평가 지표 평균 값을 구해본다)
from sklearn.model_selection import KFold
kfold = KFold(n_splits = 5)
wine_tree_cv = DecisionTreeClassifier(max_depth = 2, random_state = 13)
from sklearn.model_selection import StratifiedKFold
skfold = StratifiedKFold(n_splits = 5)
wine_tree_cv = DecisionTreeClassifier(max_depth = 2, random_state = 13)
cv_accuracy = []
for train_idx, test_idx in skfold.split(X, y):
X_train, X_test = X.iloc[train_idx], X.iloc[test_idx]
y_train, y_test = y.iloc[train_idx], y.iloc[test_idx]
wine_tree_cv.fit(X_train, y_train)
pred = wine_tree_cv.predict(X_test)
cv_accuracy.append(accuracy_score(y_test, pred))
np.mean(cv_accuracy)

쉽고 유익하게 널리널리