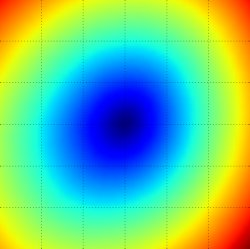
Loss Function의 시각화
고차원 데이터의 손실 함수를 시각화 하기위해 1차원 직선이나 2차원 평면으로 잘라서 본다.
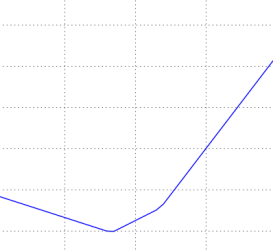
여러 a값에 따른 1차원 손실(loss) 곡선
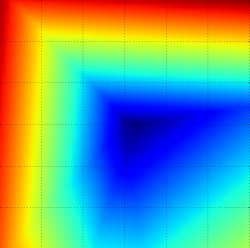
2차원 손실(loss) 평면, 파란색(낮은손실)
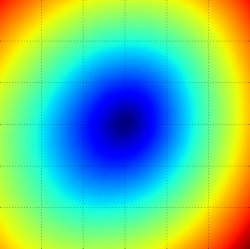
손실의 평균, 밥그릇을 뒤집어 놓은 모양이 특징이다.
부분적으로 선형(piecewise linear)은 손실함수(Loss function)의 구조를 수식을 통해 설명할 수 있다.
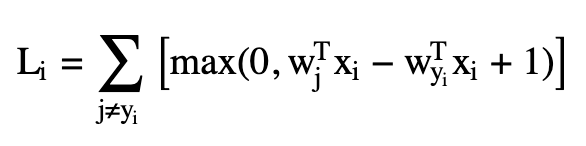
미분이 불가능한 손실함수(loss functions). 기술적인 설명을 덧붙이자면, max(0,−)함수 때문에 손실함수(loss functionn)에 꺾임이 생기는데, 이 때문에 손실함수(loss functions)는 미분이 불가능해진다.
최적화
최적화는 손실함수의 손실을 최소화 시키는 w를 찾는 방법인데 이 함수는 미분이 불가능하기 때문에 새로운 방법이 필요하다.
1. Random search
bestloss = float("inf") # Python assigns the highest possible float value
for num in xrange(1000):
W = np.random.randn(10, 3073) * 0.0001 # generate random parameters
loss = L(X_train, Y_train, W) # get the loss over the entire training set
if loss < bestloss: # keep track of the best solution
bestloss = loss
bestW = W
print 'in attempt %d the loss was %f, best %f' % (num, loss, bestloss)# X_test은 크기가 [3073 x 10000]인 행렬, Y_test는 크기가 [10000 x 1]인 어레이라고 하자.
scores = Wbest.dot(Xte_cols) # 모든 테스트데이터 예제(1만개)에 대한 각 클라스(10개)별 점수를 모아놓은 크기 10 x 10000짜리인 행렬
# 각 열(column)에서 가장 높은 점수에 해당하는 클래스를 찾자. (즉, 예측 클래스)
Yte_predict = np.argmax(scores, axis = 0)
# 그리고 정확도를 계산하자. (예측 성공률)
np.mean(Yte_predict == Yte)
# 정확도 값이 0.1555라고 한다.정확도가 15.5%가 나온다. 이는 좋은 방법이 아니다.
2. Random Local Search
완전 무작위로 탐색하는게 아닌 시작점에서 무작위로 방향을 정해서 발을 살짝 뻗어서 더듬어보고 그게 내리막길길을 때만 한발짝 내딛는 것이다.
W = np.random.randn(10, 3073) * 0.001 # 임의의 시작 파라미터를 랜덤하게 고른다.
bestloss = float("inf")
for i in xrange(1000):
step_size = 0.0001
Wtry = W + np.random.randn(10, 3073) * step_size
loss = L(Xtr_cols, Ytr, Wtry)
if loss < bestloss:
W = Wtry
bestloss = loss
print 'iter %d loss is %f' % (i, bestloss)정확도가 21.4%로 아직도 부정확하다.
3. gradient 따라가기

차이를 이용해서 수치적으로 gradient계산하기
def eval_numerical_gradient(f, x):
"""
함수 f의 x에서의 그라디언트를 매우 단순하게 구현하기.
- f 는 입력값 1개를 받는 함수여야한다.
- x는 numpy 어레이(array)로서그라디언트를 계산할 지점 (역자 주: 그라디언트는 당연하게도 어디서 계산하느냐에 따라 달라지므로, 함수 f 뿐 아니라 x도 정해줘야함).
"""
fx = f(x) # 원래 지점 x에서 함수값 구하기.
grad = np.zeros(x.shape)
h = 0.00001
# x의 모든 인덱스를 다 돌면서 계산하기.
it = np.nditer(x, flags=['multi_index'], op_flags=['readwrite'])
while not it.finished:
# 함수 값을 x+h에서 계산하기.
ix = it.multi_index
old_value = x[ix]
x[ix] = old_value + h # 변화랑h
fxh = f(x) # evalute f(x + h)
x[ix] = old_value # 이전 값을 다시 가져온다. (매우 중요!)
# 편미분 계산
grad[ix] = (fxh - fx) / h # 기울기
it.iternext() # 다음 단계로 가서 반복.
return grad모든 차원을 하나씩 돌아가면서 그 방향으로 작은 변화 h를 줬을 때, 손실함수(loss function)의 값이 얼마나 변하는지를 구해서, 그 방향의 편미분 값을 계산한다. 변수 grad에 전체 그라디언트(gradient) 값이 최종적으로 저장된다.
# 위의 범용코드를 쓰려면 함수가 입력값 하나(이 경우 파라미터)를 받아야함.
# 따라서X_train와 Y_train은 입력값으로 안 치고 W 하나만 입력값으로 받도록 함수 다시 정의.
def CIFAR10_loss_fun(W):
return L(X_train, Y_train, W)
W = np.random.rand(10, 3073) * 0.001 # 랜덤 파라미터 벡터.
df = eval_numerical_gradient(CIFAR10_loss_fun, W) # 그라디언트를 구했다.loss_original = CIFAR10_loss_fun(W) # 기존 손실값
print 'original loss: %f' % (loss_original, )
# 스텝크기가 주는 영향에 대해 알아보자.
for step_size_log in [-10, -9, -8, -7, -6, -5,-4,-3,-2,-1]:
step_size = 10 ** step_size_log
W_new = W - step_size * df # 파라미터(parameter/weight) 공간 상의 새 파라미터 값
loss_new = CIFAR10_loss_fun(W_new)
print 'for step size %f new loss: %f' % (step_size, loss_new)
# prints:
# original loss: 2.200718
# for step size 1.000000e-10 new loss: 2.200652
# for step size 1.000000e-09 new loss: 2.200057
# for step size 1.000000e-08 new loss: 2.194116
# for step size 1.000000e-07 new loss: 2.135493
# for step size 1.000000e-06 new loss: 1.647802
# for step size 1.000000e-05 new loss: 2.844355
# for step size 1.000000e-04 new loss: 25.558142
# for step size 1.000000e-03 new loss: 254.086573
# for step size 1.000000e-02 new loss: 2539.370888
# for step size 1.000000e-01 new loss: 25392.214036새로운 파라미터 W_new로 업데이트할 때, 그라디언트(gradient) df의 반대방향으로 움직인 것을 주목하자. 왜냐하면 우리가 원하는 것은 손실함수(loss function)의 증가가 아니라 감소하는 것이기 때문이다.
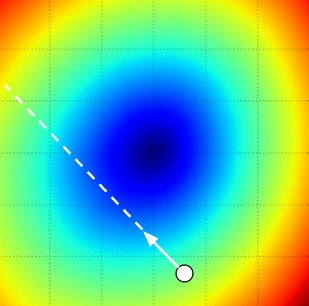
작은 변화값(step)이 주는 영향을 시각적으로 보여주는 그림. 특정 지검 W에서 시작해서 그라디언트(혹은 거기에 -1을 곱한 값)를 계산한다. 이 그라디언트에 -1을 곱한 방향, 즉 하얀 화살표 방향이 손실함수(loss function)이 가장 빠르게 감소하는 방향이다. 그 방향으로 조금 가는 것은 일관되지만 느리게 최적화를 진행시킨다. 반면에, 그 방향으로 너무 많이 가면, 더 많이 감소시키지만 위험성도 크다. 스텝 크기가 점점 커지면, 결국에는 최소값을 지나쳐서 손실값이 더 커지는 지점까지 가게될 것이다.
이는 효율이 매우 안좋다.
미적분을 이용하여 해석적으로 그라디언트(gradient)를 계산하기
# 단순한 경사하강(gradient descent)
while True:
weights_grad = evaluate_gradient(loss_fun, data, weights)
weights += - step_size * weights_grad # 파라미터 업데이트(parameter update)미니배치(mini-batch)에서 그라디언트(gradient)를 구해서 더 자주자주 파라미터(parameter/weight)을 업데이트하면 실제로 더 빠른 수렴하게 된다.
# 단순한 미니배치 (minibatch) 그라디언트(gradient) 업데이트
while True:
data_batch = sample_training_data(data, 256) # 예제 256개짜리 미니배치(mini-batch)
weights_grad = evaluate_gradient(loss_fun, data_batch, weights)
weights += - step_size * weights_grad # 파라미터 업데이트(parameter update)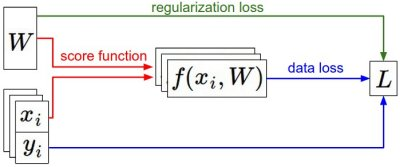
정보 흐름 요약.
(x,y)라는 고정된 데이터 쌍이 주어져 있다. 처음에는 무작위로 뽑은 파라미터(parameter/weight)값으로 시작해서 바꿔나간다. 왼쪽에서 오른쪽으로 가면서, 스코어함수(score function)가 각 클래스의 점수를 계산하고 그 값이 f 벡터에 저장된다. 손실함수(loss function)는 두 부분으로 나뉘어 있다. 첫째, 데이터 손실(data loss)은 파라미터(parameter/weight)만으로 계산하는 함수이다. 그라디언트 하강(Gradient Descent) 과정에서, 파라미터(parameter/weight)로 미분한 (혹은 원한다면 데이터 값으로 추가로 미분한. 그라디언트(gradient)를 계산하고, 이것을 이용해서 파라미터(parameter/weight)값을 업데이트한다.

학생입니다.