
데이터 로드 및 라이브러리 입력
import pickle
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import re
import urllib.request
from konlpy.tag import Okt
from tqdm import tqdm
from tensorflow.keras.preprocessing.text import Tokenizer
from tensorflow.keras.preprocessing.sequence import pad_sequences
urllib.request.urlretrieve("https://raw.githubusercontent.com/e9t/nsmc/master/ratings_train.txt", filename="ratings_train.txt")
urllib.request.urlretrieve("https://raw.githubusercontent.com/e9t/nsmc/master/ratings_test.txt", filename="ratings_test.txt")
train_data=pd.read_table('ratings_train.txt')
test_data=pd.read_table('ratings_test.txt')데이터 구조
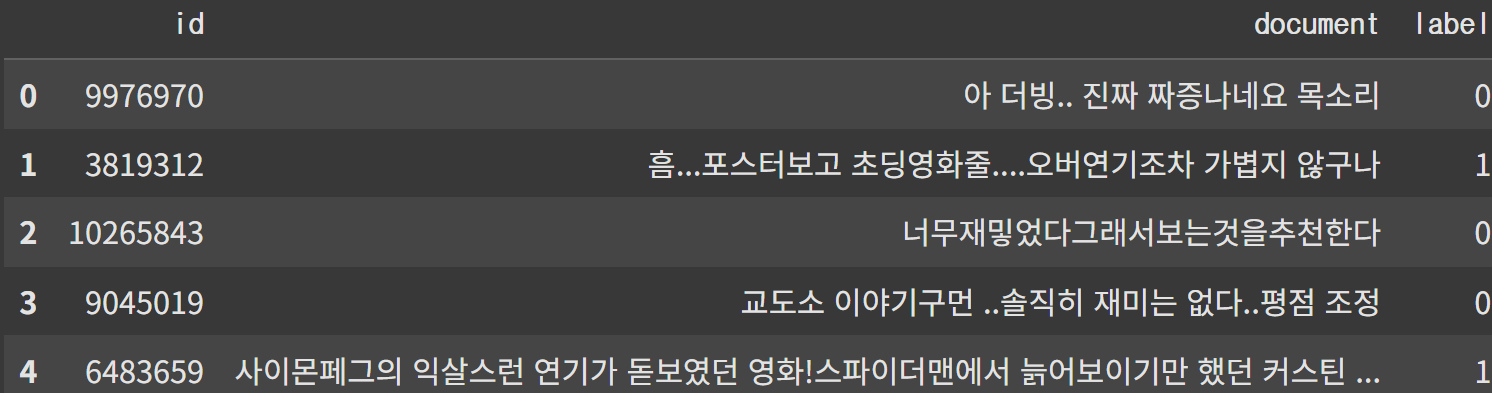
id: 개인 고유 번호
document: 작업할 데이터
label: 부정(0), 긍정(1)
총 150,000개의 데이터
데이터 전처리
# 중복된 데이터 확인
train_data['document'].nunique(), train_data['label'].nunique()
# 중복 제거
train_data.drop_duplicates(subset=['document'], inplace=True)긍정, 부정 개수 확인
train_data['label'].value_counts().plot(kind='bar')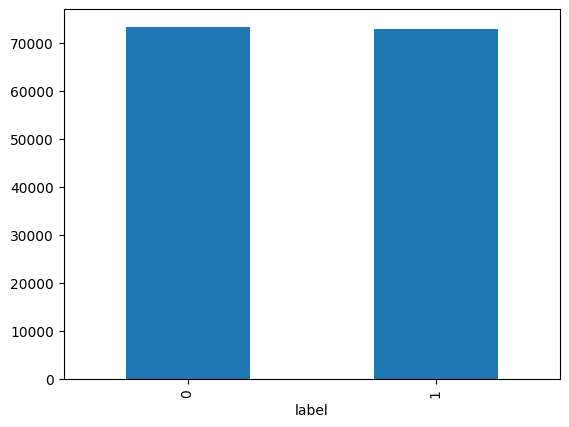
print(train_data.groupby('label').size().reset_index(name = 'count'))
label count
0 0 73342
1 1 72841텍스트 전처리
정규표현식 사용하여 한글, 공백만 남기기
# 한글과 공백을 제외하고 모두 제거
train_data['document'] = train_data['document'].str.replace("[^ㄱ-ㅎㅏ-ㅣ가-힣 ]","", regex=True)
train_data['document'] = train_data['document'].str.replace('^ +', "", regex=True) # white space 데이터를 empty value로 변경
train_data['document'].replace('', np.nan, inplace=True)
train_data = train_data.dropna(how = 'any')
print(len(train_data))텍스트 데이터에도 앞과 같은 작업
test_data.drop_duplicates(subset = ['document'], inplace=True) # document 열에서 중복인 내용이 있다면 중복 제거
test_data['document'] = test_data['document'].str.replace("[^ㄱ-ㅎㅏ-ㅣ가-힣 ]","", regex=True) # 정규 표현식 수행
test_data['document'] = test_data['document'].str.replace('^ +', "", regex=True) # 공백은 empty 값으로 변경
test_data['document'].replace('', np.nan, inplace=True) # 공백은 Null 값으로 변경
test_data = test_data.dropna(how='any') # Null 값 제거
print('전처리 후 테스트용 샘플의 개수 :',len(test_data))
전처리 후 테스트용 샘플의 개수 : 48852불용어제거
stopwords=['의','가','이','은','들','는','좀','잘','걍','과','도','를','으로','자','에','와','한','하다']
okt=Okt()
okt.morphs('와 이런 것도 영화라고 차라리 뮤직비디오를 만드는 게 나을 뻔', stem=True)
X_train=[]
for sentence in tqdm(train_data['document']):
tokenized_sentence=okt.morphs(sentence, stem=True)
stopwords_removed_sentence=[word for word in tokenized_sentence if word not in stopwords]
X_train.append(stopwords_removed_sentence)불용어 제거된 문장 3개 확인
X_train[:3]
[['아', '더빙', '진짜', '짜증나다', '목소리'],
['흠', '포스터', '보고', '초딩', '영화', '줄', '오버', '연기', '조차', '가볍다', '않다'],
['너', '무재', '밓었', '다그', '래서', '보다', '추천', '다']]테스트 데이터에도 토큰화 한 후 불용어제거
X_test = []
for sentence in tqdm(test_data['document']):
tokenized_sentence = okt.morphs(sentence, stem=True) # 토큰화
stopwords_removed_sentence = [word for word in tokenized_sentence if not word in stopwords] # 불용어 제거
X_test.append(stopwords_removed_sentence)워드 인덱싱
각 단어별로 고유한 정수 부여
tokenizer=Tokenizer()
tokenizer.fit_on_texts(X_train)단어 빈도가 적은 단어의 비율 확인
threshold=3
total_cnt=len(tokenizer.word_index)
rare_cnt=0
total_freq=0
rare_freq=0
for key, value in tokenizer.word_counts.items():
total_freq+=value
if value<threshold:
rare_cnt+=1
rare_freq+=value
print('단어 집합(vocabulary)의 크기 :',total_cnt)
print('등장 빈도가 %s번 이하인 희귀 단어의 수: %s'%(threshold - 1, rare_cnt))
print("단어 집합에서 희귀 단어의 비율:", (rare_cnt / total_cnt)*100)
print("전체 등장 빈도에서 희귀 단어 등장 빈도 비율:", (rare_freq / total_freq)*100)단어 집합(vocabulary)의 크기 : 43752
등장 빈도가 2번 이하인 희귀 단어의 수: 24337
단어 집합에서 희귀 단어의 비율: 55.62488571950996
전체 등장 빈도에서 희귀 단어 등장 빈도 비율: 1.8715872104872904
단어크기 정의(희귀단어 제거)
vocab_size=total_cnt-rare_cnt+1
vocab_size
19416단어 인덱싱
tokenizer=Tokenizer(vocab_size)
tokenizer.fit_on_texts(X_train)
X_train=tokenizer.texts_to_sequences(X_train)
X_test=tokenizer.texts_to_sequences(X_test)
X_train[:4]
[[50, 454, 16, 260, 659],
[933, 457, 41, 602, 1, 214, 1449, 24, 961, 675, 19],
[386, 2444, 2315, 5671, 2, 222, 9],
[6492, 105, 8118, 218, 56, 4, 26, 3603]]레이블 정의
y_train=np.array(train_data['label'])
y_test=np.array(test_data['label'])데이터에서 길이가 0인 문장 제거
drop_train = [index for index, sentence in enumerate(X_train) if len(sentence) < 1]
drop_test = [index for index, sentence in enumerate(X_test) if len(sentence) < 1]
X_train=[x for i, x in enumerate(X_train) if i not in set(drop_train)]
y_train=[x for i, x in enumerate(y_train) if i not in set(drop_train)]문장 길이 시각화
print(max(len(review) for review in X_train))
print(sum(map(len, X_train))/len(X_train))
plt.hist([len(review) for review in X_train], bins=50)
plt.xlabel('length of samples')
plt.ylabel('number of samples')
plt.show()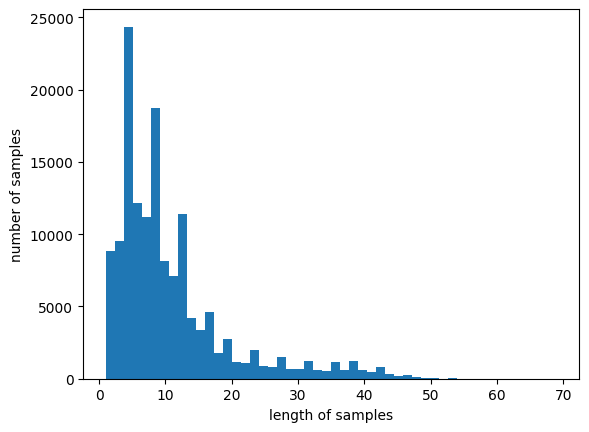
문장 패딩
패딩을 위해 길이를 정하는 과정
def below_threshold_len(max_len, nested_list):
count = 0
for sentence in nested_list:
if(len(sentence) <= max_len):
count = count + 1
print('전체 샘플 중 길이가 %s 이하인 샘플의 비율: %s'%(max_len, (count / len(nested_list))*100))
max_len=30
below_threshold_len(max_len, X_train)
전체 샘플 중 길이가 30 이하인 샘플의 비율: 94.31944999380003패딩
X_train=pad_sequences(X_train, maxlen=max_len)
X_test=pad_sequences(X_test, maxlen=max_len)LSTM 모델 설계
from tensorflow.keras.layers import Embedding, Dense, LSTM
from tensorflow.keras.models import Sequential
from tensorflow.keras.models import load_model
from tensorflow.keras.callbacks import EarlyStopping, ModelCheckpoint
embedding_dim = 100
hidden_units = 128
model = Sequential()
model.add(Embedding(vocab_size, embedding_dim))
model.add(LSTM(hidden_units))
model.add(Dense(1, activation='sigmoid'))
es = EarlyStopping(monitor='val_loss', mode='min', verbose=1, patience=4)
mc = ModelCheckpoint('best_model.keras', monitor='val_acc', mode='max', verbose=1, save_best_only=True)
model.compile(optimizer='rmsprop', loss='binary_crossentropy', metrics=['acc'])
history = model.fit(X_train, y_train, epochs=15, callbacks=[es, mc], batch_size=64, validation_split=0.2)모델 평가
loaded_model=load_model('best_model.keras')
loaded_model.evaluate(X_test, y_test)
[0.3488772511482239, 0.853639543056488]모델 모듈화
def sentiment_predict(new_sentence):
new_sentence=re.sub(r'[^ㄱ-ㅎㅏ-ㅣ가-힣 ]','', new_sentence)
new_sentence=okt.morphs(new_sentence, stem=True)
new_sentence=[word for word in new_sentence if not word in stopwords]
encoded=tokenizer.texts_to_sequences([new_sentence])
pad_new=pad_sequences(encoded, maxlen=max_len)
score=float(loaded_model.predict(pad_new))
if score>0.5:
print('{:.2f}%확률로 긍정 리뷰입니다.\n'.format(score*100))
else:
print('{:.2f}%확률로 부정 리뷰입니다.\n'.format((1 - score) * 100))sentiment_predict('이 영화 개꿀잼 ㅋㅋㅋ')
85.46%확률로 긍정 리뷰입니다.sentiment_predict('이 영화 핵노잼 ㅠㅠ')
97.23%확률로 부정 리뷰입니다.sentiment_predict('이딴게 영화냐 ㅉㅉ')
99.75%확률로 부정 리뷰입니다.CNN 모델
from tensorflow.keras.models import Sequential, Model
from tensorflow.keras.layers import Embedding, Dropout, Conv1D, GlobalMaxPooling1D, Dense, Input, Flatten, Concatenate
from tensorflow.keras.callbacks import EarlyStopping, ModelCheckpoint
from tensorflow.keras.models import load_model
embedding_dim = 128
dropout_ratio = (0.5, 0.8)
num_filters = 128
hidden_units = 128
model_input=Input(shape=(max_len, ))
z=Embedding(vocab_size, embedding_dim, input_length=max_len, name='embedding')(model_input)
z=Dropout(dropout_ratio[0])(z)
conv_blocks = []
for sz in [3, 4, 5]:
conv = Conv1D(filters = num_filters,
kernel_size = sz,
padding = "valid",
activation = "relu",
strides = 1)(z)
conv = GlobalMaxPooling1D()(conv)
conv_blocks.append(conv)
z=Concatenate()(conv_blocks) if len(conv_blocks) > 1 else conv_blocks[0]
z=Dropout(dropout_ratio[1])(z)
z=Dense(hidden_units, activation='relu')(z)
model_output=Dense(1, activation='sigmoid')(z)
model=Model(model_input, model_output)
model.compile(loss='binary_crossentropy', optimizer='adam', metrics=['acc'])
es = EarlyStopping(monitor='val_loss', mode='min', verbose=1, patience=4)
mc = ModelCheckpoint('CNN_model.keras', monitor='val_acc', mode='max', verbose=1, save_best_only=True)
model.fit(X_train, y_train, batch_size=64, epochs=10, validation_split=0.2, verbose=2, callbacks=[es, mc]) 모델 정확도
loaded_model=load_model('CNN_model.keras')
loaded_model.evaluate(X_test, y_test)
[0.3623010814189911, 0.8408458232879639]모델 예측
sentiment_predict('이 영화 개꿀잼 ㅋㅋㅋ')
88.16%확률로 긍정 리뷰입니다.sentiment_predict('이 영화 핵노잼 ㅠㅠ')
97.25%확률로 부정 리뷰입니다.sentiment_predict('이딴게 영화냐 ㅉㅉ')
97.43%확률로 부정 리뷰입니다.