
데이터 분석
마진율 분석
연도별 평균 마진율 계산
adidas.groupby('year').agg({'Operating Margin':'mean'})
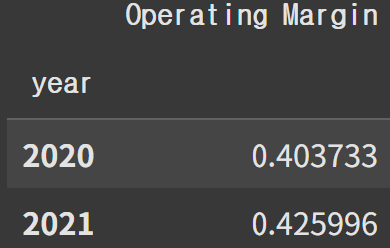
연도, 월별 평균 마진율 시각화
adidas.pivot_table(index=['year', 'month'], values='Operating Margin', aggfunc='mean').plot(kind='line')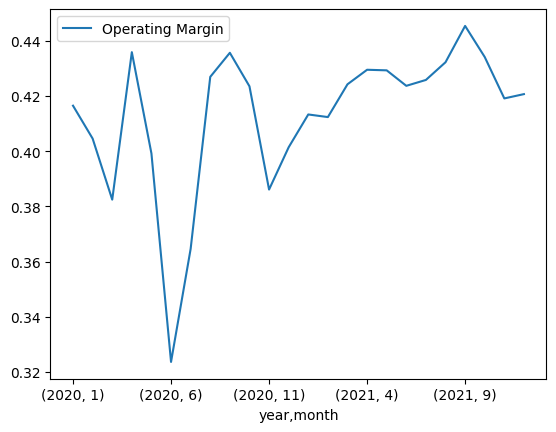
소매점 별 연도, 월 평균 마진율 시각화
adidas.pivot_table(index=['year', 'month'], columns='Retailer', values='Operating Margin', aggfunc='mean').plot(kind='line', figsize=(15,6))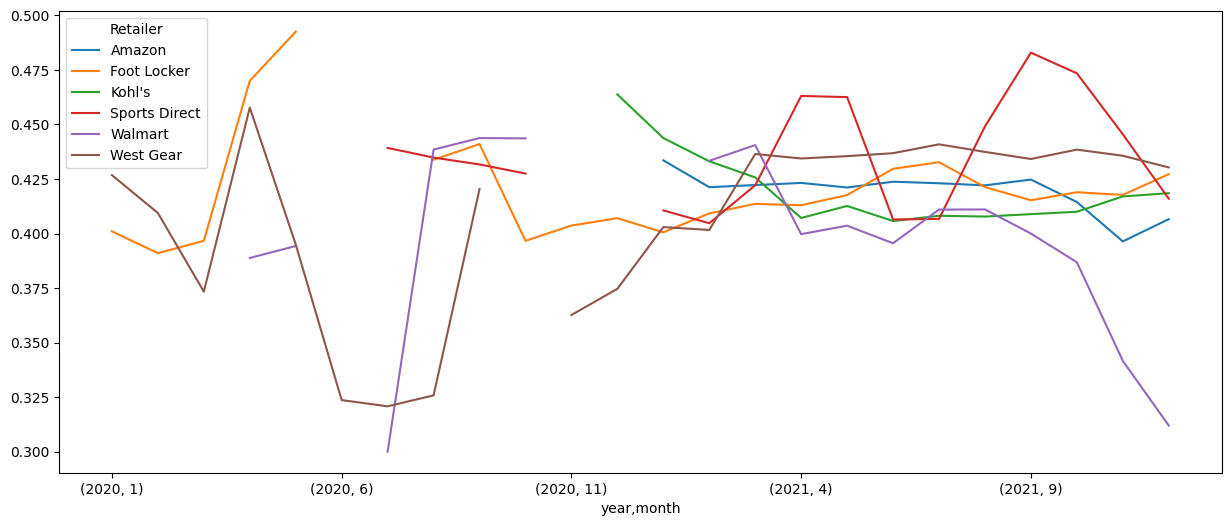
판매방법에 따른 마진율/판매단가
adidas.pivot_table(index = ['year', 'month'],columns = 'Sales Method', values = 'Operating_Margin_rate', aggfunc='mean').plot(kind = 'bar',figsize = (15,7))
adidas.pivot_table(index = ['year', 'month'],columns = 'Sales Method', values = 'Price per Unit', aggfunc='mean').plot(kind = 'line',figsize = (15,7))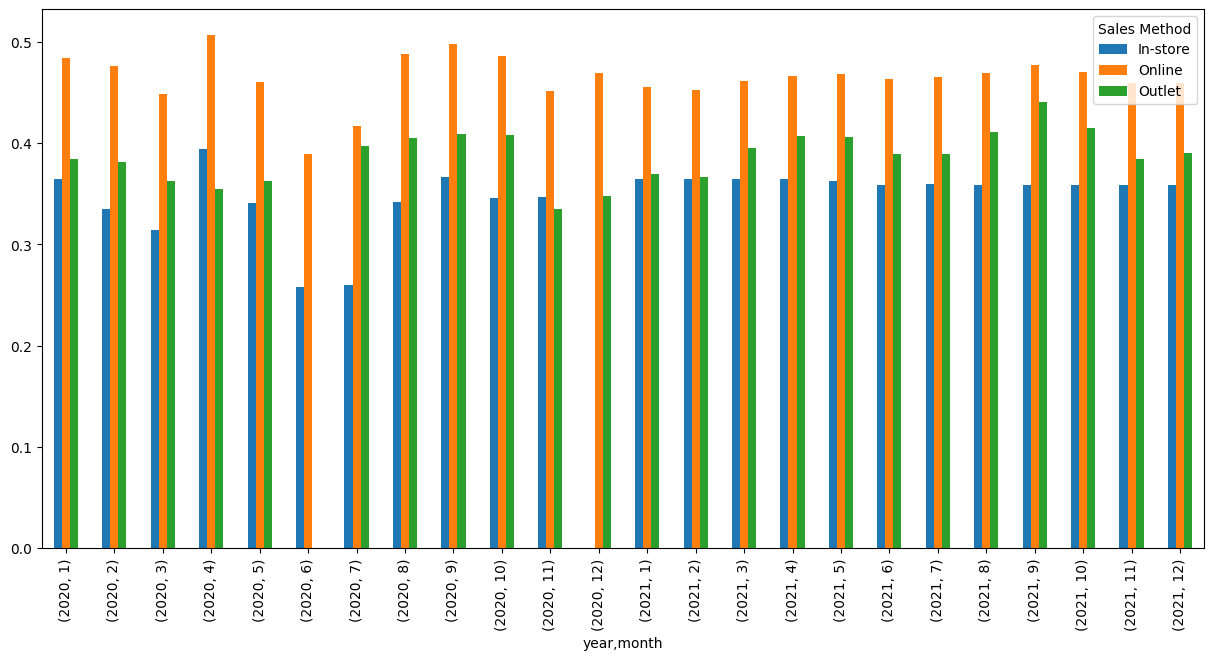
판매방법에 따라 판매성과에 차이가 있을까? -> 분산 분석
일원배치 분산분석(ANOVA)을 이용한 통계적 검증 -> 여러 집단(2개보다 큰)세개 이상의 집단이 하나의 변수로 인해 차이가 나는지 검증하는 분석방법
최소자승법(OLS)를 이용하여 검증할 수 있음
boxplot 시각화
판매방법에 따른 판매 단가
adidas[['Sales Method', 'Price per Unit']].boxplot(by='Sales Method') # Sales Method 그룹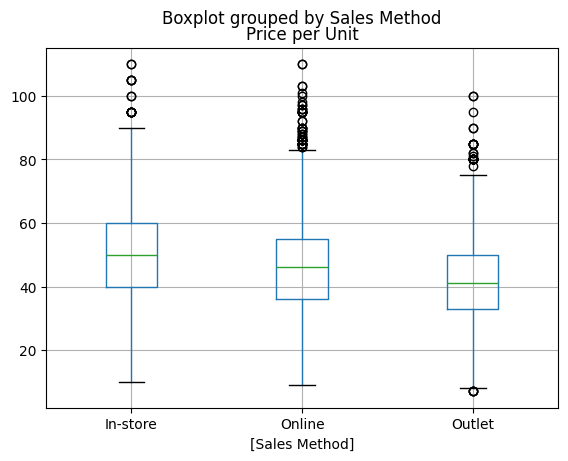
판매방법에 따른 마진율
adidas[['Sales Method', 'Operating Margin']].boxplot(by='Sales Method') # Sales Method 그룹ANOVA 함수
from statsmodels.formula.api import ols
from statsmodels.stats.anova import anova_lmx='Sales Method'
y='Operating Margin'x : 비교그룹(매장, 온라인, 아울렛) -> Sales Method
y : 비교할 변수 -> 영업이익, 단가
df=adidas[[x,y]]
df
띄어쓰기 있는 경우 statsmodels의 ols 함수가 인식을 못한다 -> 띄어쓰기를 _로 바꾼다
x=x.replace(' ','_')
y=y.replace(' ','_')
print('바뀐 이름: '+x,',',y)
바뀐 이름: Sales_Method , Operating_Margin
df.columns=[x,y]
df.columns
Index(['Sales_Method', 'Operating_Margin'], dtype='object')# the "C" indicates categorical data
model=ols(f'{y} ~ C({x})', df).fit()anova_table=anova_lm(model)
print(anova_table)if anova_table.iloc[0,4]<0.05:
print('판매 방법에 따른 {}가 차이가 있다'.format(y))
else:
print('판매 방법에 따른 {}가 차이가 없다'.format(y))판매 방법에 따른 Operating_Margin가 차이가 있다
모듈화
def anova_analysis(x,y):
df=adidas[[x,y]]
x=x.replace(' ','_')
y=y.replace(' ','_')
print('바뀐 이름:', x, ',',y)
df.columns=[x,y]
model=ols(f'{y} ~ C({x})', df).fit()
anova_table=anova_lm(model)
print(anova_table)
if anova_table.iloc[0,4]<0.05:
print('판매 방법에 따른 {}가 차이가 있다'.format(y))
else:
print('판매 방법에 따른 {}가 차이가 없다'.format(y))print('판매가격의 차이 검증')
anova_analysis('Sales Method', 'Price per Unit')
print('\r\n\r\n')
print("======================================================")
print('\r\n\r\n')
print('마진율의 차이 검증')
anova_analysis('Sales Method', 'Operating Margin')판매가격의 차이 검증
바뀐 이름: Sales_Method , Price_per_Unit
df sum_sq mean_sq F PR(>F)
C(Sales_Method) 2.0 5.550261e+04 27751.304281 131.810754 3.339384e-57
Residual 9645.0 2.030649e+06 210.538999 NaN NaN
판매 방법에 따른 Price_per_Unit가 차이가 있다
======================================================
마진율의 차이 검증
바뀐 이름: Sales_Method , Operating_Margin
df sum_sq mean_sq F PR(>F)
C(Sales_Method) 2.0 18.450217 9.225109 1224.079115 0.0
Residual 9645.0 72.688254 0.007536 NaN NaN
판매 방법에 따른 Operating_Margin가 차이가 있다분석 결과
온라인: 단가 낮은 상품이 많이 팔리고, 마진울은 높은
매장: 단가 높은 상품 많이 팔리고, 마진율 낮은
인사이트
판매방법에 따라 단가 차이가 있다. In-Store > On_line > Outlet 순서
매장 방법 손님의 객단가가 가장 높고, 다음으로 온라인, 아웃렛 순서
아울렛은 매장, 온라인에서 판매되지 않는 상품이 판매되기 때문에 인사이트 분석을 위한 비교대상으로 보기는 어렵다
판매 방법에 따라 마진율 차이 존재. On-line > Outlet> In-Store 순서
