Attention
Attention: 문맥에 따라 집중할 단어를 결정하는 방식
Encoder: input data를 입력으로 받아 context vector로 변환, 출력
Decoder: context vector를 입력 받아 output data를 출력context vector를 사용하면 연산량은 줄어들지만 정보 손실이 발생 -> Attention으로 해결
encoder는 모든 RNN 셀의 은닉층들을 사용하지만, decoder는 현재 RNN셀의 은닉층만 사용
Transformer
Transformer: Attention만으로 이루어진 Encoder-Decoder 구조의 seq2seq모델
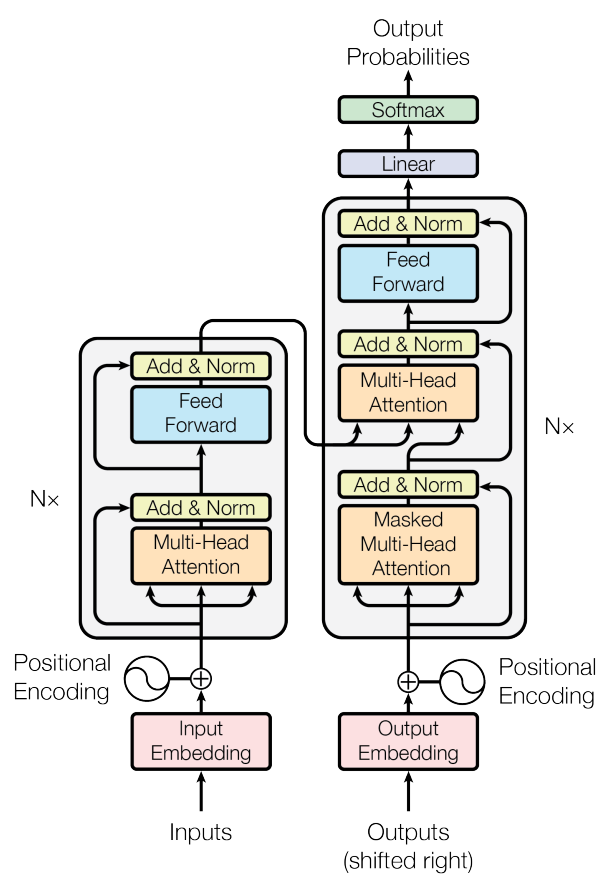
RNN, LSTM <- 직렬, 네트워크를 계속 순환(성능, 학습 속도 떨어진다)
Transformer <- 병렬, RNN사용x (성능, 학습 속도 좋음)
Positional Encoding
RNN은 특성으로 인해 각 단어의 위치 정보를 가질 수 있다
Transformer는단어 입력을 순차적으로 입력 받는 방식이 아니라 단어의 위치 정보를 알려줄 필요가 있다.
Positional Encoding
각 단어의 임베딩 벡터에 위치 정보들을 더해 모델의 입력으로 사용

Positional Encoding Vector: 위치 개념을 가진다
Embedding Vector: 단어의 의미를 가지고 있다
Embedding Vector가 인코더의 입력으로 사용되기 전 Positional Encoding의 값이 더해지는 과정
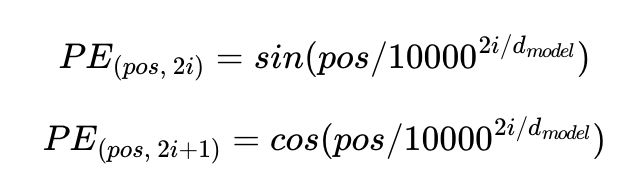
삼각함수를 사용하는 이유: 범위가 -1~1로 안정적이며, 주기함수로 input data의 크기에 상관x
주기함수는 y값이 주기적으로 반복돼, 정보가 겹친다 -> 이를 해결하기 위해 cos, sin 함수를 번갈아가며 사용. embedding차원이 짝수이면 sin함수, 홀수이면 cos함수 사용
pos: Position of Word(단어의 위치)
i: 임베딩 벡터 차원의 인덱스
: size of embedding vector(정규화역할)
Self Attention
Self Attention
문장에서의 단어들의 연관성을 알기위해서 Attention을 자기 자신한테 행한다ex) "The animal didn't cross the street because it was too tired"라는 문장이 있을 때, "it"이 가리키는 단어를 컴퓨터가 파악하기 어렵다.
이때 Self Attention 사용
Self Attention은 Query, Key, Value라는 변수 존재
Query, Key, Value의 시작 값은 동일하다
이를 구하는 공식
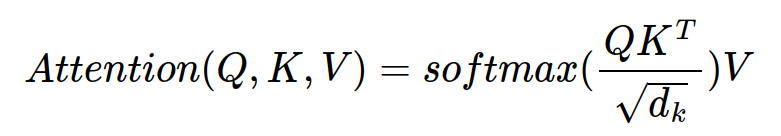
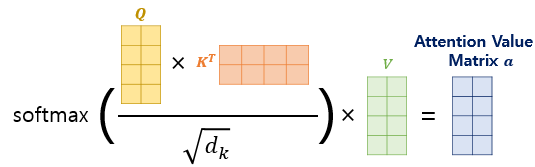
Query와 Key를 내적: Query와 Key의 연관성을 계산한다. 내적하면 스칼라 값이 나오는데 그럴 Attention Score라고 부른다
의 루트적용해 나누어 주어 Query, Key의 차원이 커지면 더 Attention 되는걸 방지한다(정규화 역할)
그 다음, softmax를 적용하고 Value 행렬을 내적해 최종적인 Attention 행렬을 얻을 수 있다
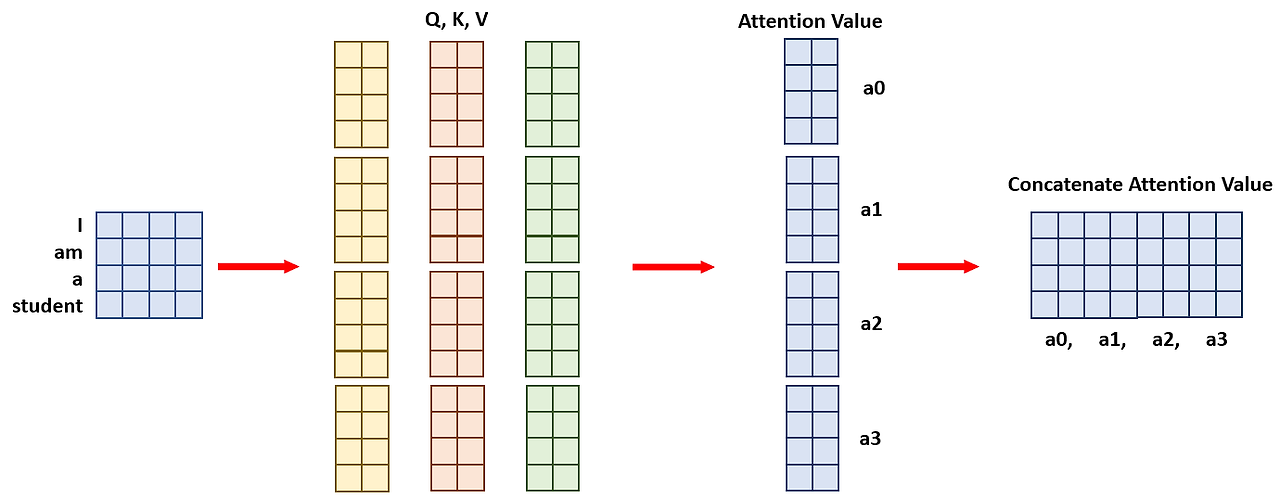
Multi-head Attention
head의 수만큼 Attention을 각각 병렬로 나누어 계산을 한고, 각각 나온 Attention Value들은 마지막에 concatenate를 통해 하나로 합친다
Masked Multi-head Attention
마스크를 추가해 특정 위치의 정보를 가리는 방식으로 미래정보를 참조하지 못하도록 한다
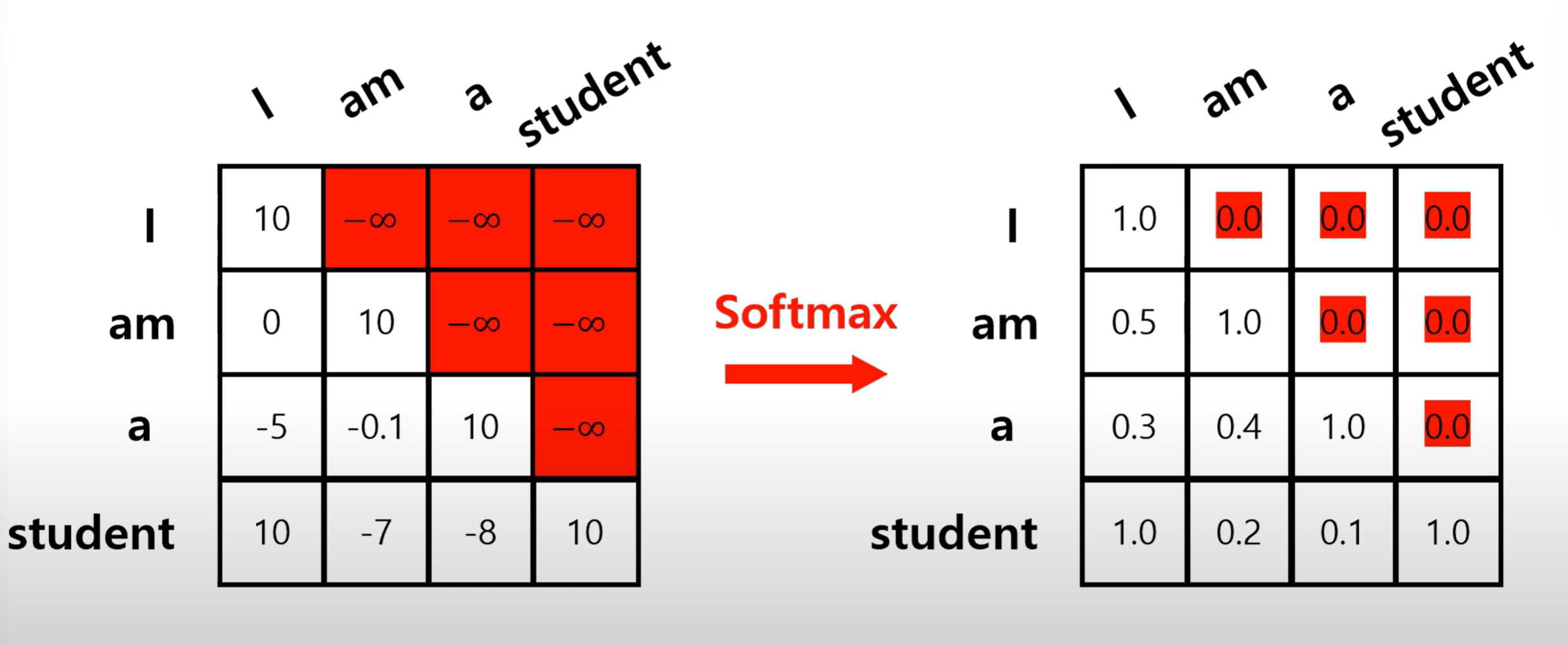
그림과 같이 엄청 큰 음수를 넣고 softmax를 적용하여 0으로 만든다
