- 선수지식
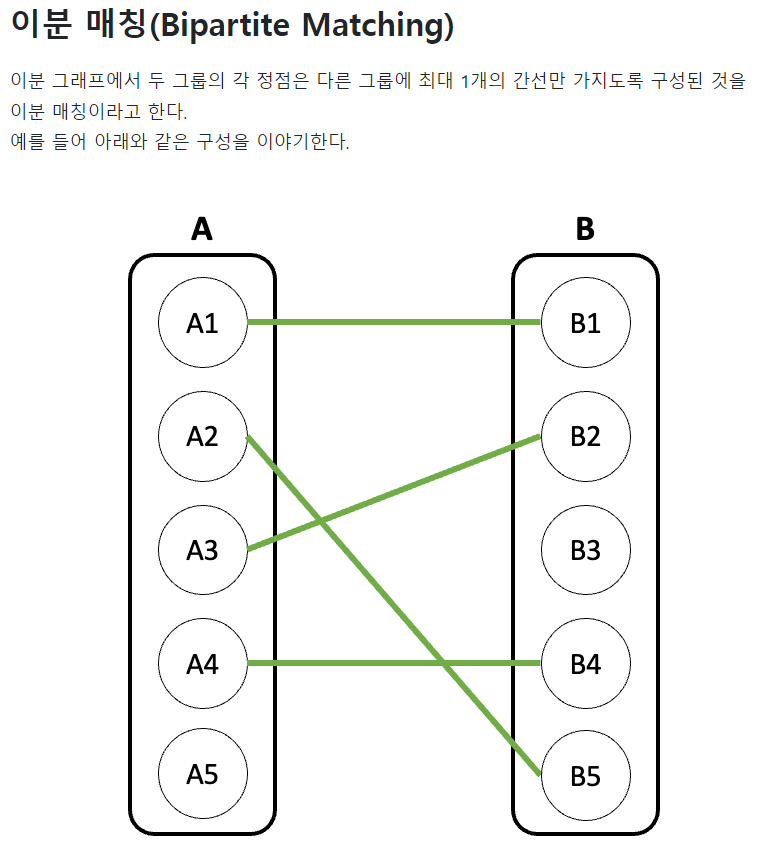
- 이분매칭
- 이분매칭
- Abstract
- DETR은 set-based global loss와 bipartite matching 알고리즘을 사용.
- 이 때문에 object bounding box를 엄청 많이 예측해두고 그 안에서 최종 예측을 하는 기존 방식과는 차별
- Prior knowledge (NMS, anchor genetration)를 사용하지 않아 detection pipeline을 간소화
- Introduction 기존에는 해당 집합들을 예측하기 위해서 indirect한 방법을 주로 사용(proposals, anchor, window centers 등등) DETR은 direct set prediction approach
ResNet-50을 사용하여 CNN backbone을 구성 (입력 이미지에서 **feature map을 추출하는 역할)**
본 논문의 모델은 **transformer 기반의 encoder-decoder 구조**를 채택
전반적인 인스턴스간의 상호작용을 잘 파악
픽셀별 연관성 정보도 제공하는 **self-attention mechanism**을 활용
결론적으로 Set prediction에서 필요했던 **중복 예측 제거** 기능을 수행
DETR은 Object와 Ground truth object 간의 이분매칭을 통해 set loss function을 사용해 end-to-end한 학습을 함 → spatial anchors나 NMS같은 것들이 필요하지 않다.
**DETR**의 가장 큰 특징 두 가지는 **Partite matching (이분매칭)**과 병렬처리가 가능한 **Transformer** 구조-
Related work
- Set Prediction multilabel classification으로는 객체 감지가 힘듦. 그래서 NMS 같은 방법을 썼고 이것들은 일명 후처리 = Postprocessing 작업을 필수적으로 해야했음. 측면에서 중복을 피하기 위해 모든 예측된 요소들간의 상관관계를 모델링 하는global inference가 필요하게 되었고, 이를 위해 auto-regressive sequence 모델과 같은 RNN 계열 모델들이 사용. 그래서 Hungarial algorithm 기반으로 loss function을 구성하여 이분매칭 가능해짐.
- Transformers and Parallel Decoding Transformer는 self-attention layers를 사용합니다. 이를 통해 whole sequence에 대한 정보로 업데이트
트랜스포머는 long sequence의 정보를 처리하는 데에 용이하고 병렬적인 학습이 가능해서 computing resource를 크게 절약할 수 있기에 본 논문에서 채택
- Object detection Object Detection 분야에서 많은 모델이 있지만 Proposals을 만드는데 Two-stage와 Single-stage가 있음. Region proposal하는데 있어서 어떤 방식을 쓰는가가 성능을 좌우 anchor 대신 input image에 관련해서 absolute box prediction 으로 직접적으로 set을 detection 사용.
- Set-based loss 이 논문에서 가만 핵심은 이분매칭 + 사전처리(anchor, NMS)를 안쓴다는 것인데, 일부 논문들은 ConV.나 FC layer로 모델링 되어있고 수작업으로 NMS를 쓰면서 후처리를 함. 수작업 안돼!
- Recurrent detectors
- Set Prediction multilabel classification으로는 객체 감지가 힘듦. 그래서 NMS 같은 방법을 썼고 이것들은 일명 후처리 = Postprocessing 작업을 필수적으로 해야했음. 측면에서 중복을 피하기 위해 모든 예측된 요소들간의 상관관계를 모델링 하는global inference가 필요하게 되었고, 이를 위해 auto-regressive sequence 모델과 같은 RNN 계열 모델들이 사용. 그래서 Hungarial algorithm 기반으로 loss function을 구성하여 이분매칭 가능해짐.
-
The DETR model
DETR 모델은 direct set predictions을 하기 위해서 두가지 정도의 방법을 사용.
(1) Predicted된 box와 Ground truth box 간의 unique한 matching을 하기 위한 set prediction loss를 사용
(2) set of objects을 예측하고 그들의 관계를 모델링 하는 architecture 사용
-
Object detection set prediction loss
DETR은 디코더의 single pass로 고정된 크기 N개의 예측을 하는데, 이때 N은 실제 이미지에 있는 일반적인 object 개수보다 훨씬 크게 설정된다. 학습 과정 중 어려운 점은 예측된 object(class, position, size)를 ground truth에 비교하여 점수를 매기는 것이다. 우리의 loss는 예측된 값과 gt값의 최적 bipartite matching을 구하고 object-specific loss를 구한다.
최적의 이분매칭을 위해 쓰는 것은 Hungarian algorithm (추가 공부 필요)
-
Hungarian algorithm 수식
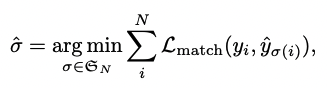
- y : ground truth set of object
- y^ : set of N prediction
- N : 이미지 내의 object의 개수보다 크며, y는 object가 없다는 뜻인 ∅으로 pad되어 있음
- Lmatch : pair-wise matching cost
-
Bounding box loss
많은 detector들이 초기 guess에 대한 차이로 bounding box를 예측하는 것과 달리, DETR은 바로 box를 예측한다. 이러한 접근법이 implementation을 간단하게 만들었지만, loss에 대한 상대적인 scaling이 이슈가 될 수 있다.
-
-
DETR architecture
아키텍쳐는 3가지 요소를 가지고 있다.
1) 피쳐를 뽑기 위한 CNN backbone
2) encoder-decoder transformer
3) 최종 디텍션 예측을 하기 위한 simple feed forward network(FFN).
Transformer Encoder
1x1 convolution으로 차원 C를 더 작은 차원 d로 바꿔주어 새로운 feature map으로 만든다.
Transformer Decoder
원래 트랜스포머는 output sequence를 하나하나 넣어주는 방식으로 autoregressive하게 진행했지만, 우리의 모델은 한번에 N개의 obejct를 병렬로 예측
Prediction FFN
3개의 perceptron과 ReLU, linea projection으로 이루어진다. FFN은 상대적인 중앙값을 예측하고, 이후 linear layer는 softmax를 통해 class를 예측한다.
-
