컴퓨터 비전과 딥러닝
3차원 기하와 캘리브레이션
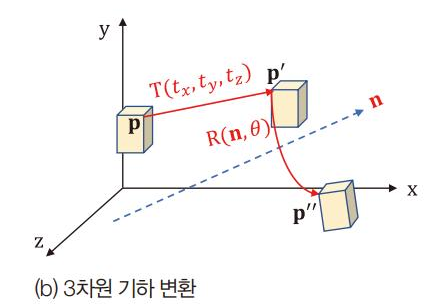
3차원 기하 변환
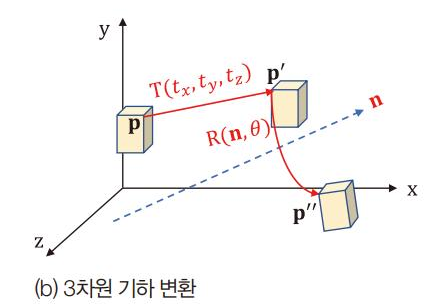
3차원 회전 행렬 방법 2가지
- 회전축과 각도 이용 R(n, )
아래
- 쿼터니언 방식
영상 생성 기하
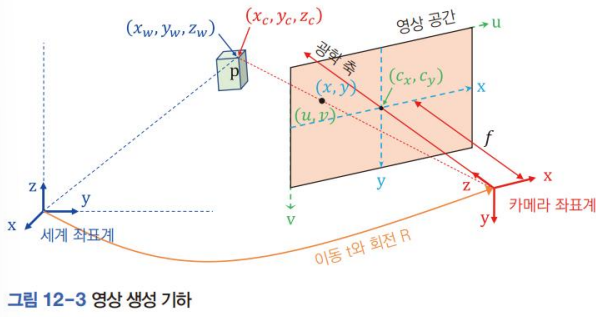
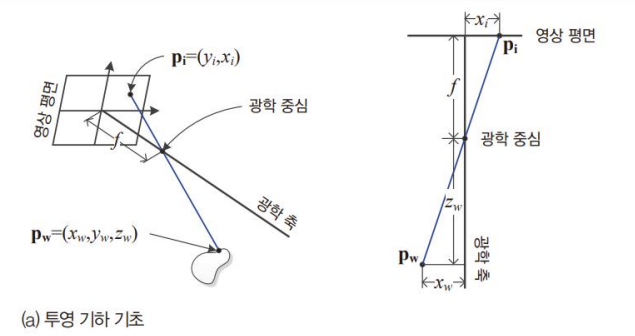
3차원 점 P가 2차원 영상 평면의 점으로 변환되는 지 나타냄.
- 세계 좌표계
- (
- 방의 구석점이라고 상상
- 카메라 좌표계
- (
- u-v 좌표계(오른쪽 위가 원점), x-y좌표계(광학축이 지나가는 점이 원점)
- 영상 공간은 원래 카메라 뒤쪽에 맺히지만, 편의를 위해 앞에 위치
- 초점거리(focal length)
- 카메라 좌표계에서 영상 평면까지 거리
- 카메라에 따라(정사각형 화소가 아닌 경우?) x,y 방향 길이가 다를 수 있다.

세계좌표계를 영상공간의 동차 좌표로 변환하는 행렬식
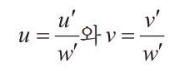
다음을 통해 (u,v) 좌표를 도출한다.
- x,y축이 약간 기울어진 것을 반영
- 내부 행렬
- 카메라의 내부동작 표현
- 카메라 좌표계 기준 물체를 어떻게 영상 공간에 맺히게 하는지 말해주는 행렬
- 외부행렬
- 외부세계와 상호작용하는 기하 관계 표현
- 세계 좌표 → 카메라 좌표
카메라 캘리브래이션
카메라가 외부 세계와 어떤 기하하적 관계를 가지는 지 알아내는 것.
⇒ 내부행렬, 외부행렬 구하기
zhang 방법(격자 패턴)
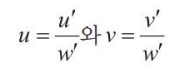
- 격자 패턴을 프린트해 벽이나 칠판같이 평평한 곳에 붙인다. 격자를 구성하는 칸의 길이는 정확히 알아야 한다. 종이 위에 세계좌표계가 있다고 가정하고 3차원 점을 수집한다.
- 카메라 | 철판을 이동하면서 여러 장의 영상을 획득한다.
- 영상에서 교차점을 검출하여, 단계 1에서 수집한 3차원 점과의 2차원 대응점을 수집한다. 교차점 보정작업 한다.
- 최대 우도 추정으로 직선 왜곡현상 보정
- CalibrateCamera 함수로 내부행렬 5개의 매개변수와 외부 행렬의 6개 매개변수를 구한다.
손눈 캘리브레이션(hand-eye Calibration)
로봇 좌표계가 해당 물체를 향해 다가가야 하기 때문에 거꾸로 카메라 좌표계(c)로부터 로봇 좌표계(w)를 알아내자.
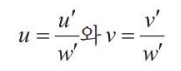
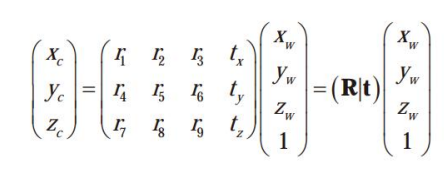
이때, 깊이 카메라(RGB-D)를 사용해 컬러 영상 RGB와 깊이 영상 D를 동시에 제공한다.
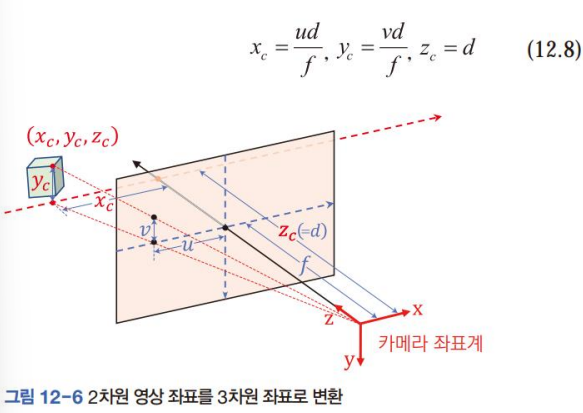
RGB영상을 분석해 (u,v)를 알아내고, 깊이 영상 D에서 거리 d를 읽는다.
비례식을 활용해 (를 확정할 수 있다.
깊이 추정
컴퓨터 비전에서 카메라에서 물체까지의 거리를 depth라고 한다.
스테레오 카메라
영상 평면의 좌표 와 초점거리 f는 알 수 있지만 2차원 영상만 가지고는 3차원 점의 좌표인 는 알 수가 없다.
⇒ 파란색 선분 위에 있는 모든 점이 에 투영될 수 있으므로
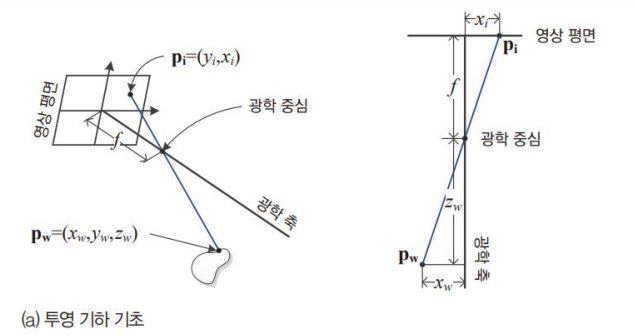
카메라 두대 사용해서 b를 알면 비례로 그냥 찾을 수 있다.

(disparity, 변위)
대응점 찾기와 에피폴라 기하
대응점은 5.4절의 SIFT 특징을 이용해 찾을 수 있다.
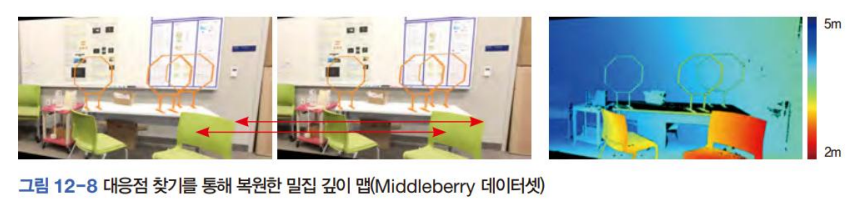
스테레오 카메라는 오른쪽과 같이 모든 화소가 값을 가지는 밀집 깊이 영상(dense depth map)을 생성해야 한다.
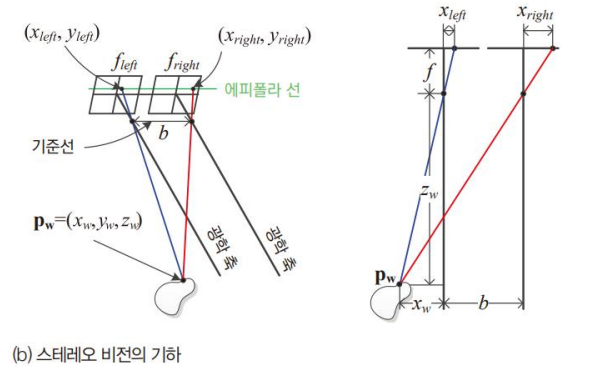
에피폴라 기하
스테레오 비전에서 대응점 찾을 때, 왼쪽 점의 대응점(오른쪽 점)이 에피폴라 선분 위에 있을 것이라는 것.
보통 x축과 수직하지 않는 경우가 많기에, 임의의 방향을 가진 에피포라 선분을 따라 대응점을 탐색한다.


3번에서 대응점 I_right을 찾을 때, 왼쪽 오른쪽 영상에서 어떤 점 P, q에 대해서 그 점을 중심으로 하는 패치 P_n, q_n에 대해서 SSD를 시행해 가장 값이 작은 q를 대응점으로 채택하는 방식이 있다.
근데 순진한 방법이라 한다.
영상의 깊이는 물체 경계를 빼고 매끄럽게 변하는 특성이 있다. 이 방법을 이용해 이웃 화소와 정보를 교환하면서 깊이 영상을 만드는 최적화 전략을 쓴다.
SGM(semi-global matching)

⇒ 스테레오 카메라에 대해서 쓰이는 것 같아서 일단 pass
딥러닝을 사용한 스테레오 비전
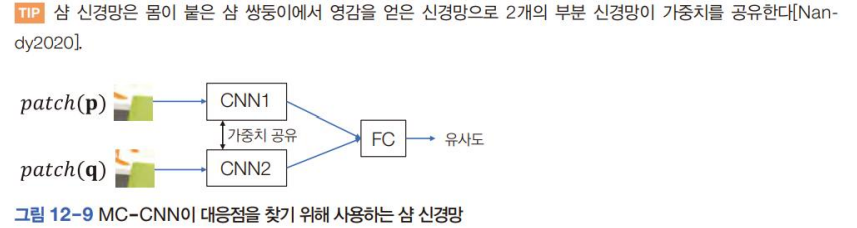
위에서 설명한 것과 같이 패치에서 유사도를 계산하는 대신 Convolution NN이 추출한 특징에서 유사도를 계산하는 전략사용 ⇒ MC-CNN이라는 모델 [Zbontar, 2016년 논문]
siamese network를 사용해 특징을 추출하고 FC layer 또는 1X1 convolution layer를 사용해 [0,1] 범위의 유사도를 출력
컨볼루션 신경망은 의미 분할을 잘한다
FCN, DeCovNet, U-net 등의 분할 모델은 물체 영역에 고유 번호를 부여한 밀집 맵을 레이블로 활용해 학습
레이블을 분할 맵에서 깊이 맵으로 바꾸어 학습하면 깊이 영상을 출력하는 신경망을 통째 학습(end to end learning)으로 구현 가능.
DISPNet-C 가 이를 최초로 성공한 논문, 깊이 정보뿐만 아니라 광류까지 추정하여, 비디오에 적용해 장면 흐름까지 추정한다.
깊이정보를 레이블링하는 일이 매우 어려워서 충분히 많은 데이터를 확보하는 일은 여전히 어렵다.
⇒ 비지도 학습으로 깊이를 추정하는 신경망 제안
⇒ https://arxiv.org/pdf/2004.08566
Monocular depth estimation (단안 깊이 추정)
한 장의 컬러 영상만 보고 깊이 영상을 출력하는 신경망 모델?
CNN 사용한 초기 연구
Depth Map Prediction from a Single Image using a Multi-Scale Deep Network
자율 학습 이용한 연구
서베이 논문
Monocular Depth Estimation: A Survey
Monocular Depth Estimation Based On Deep Learning: An Overview
transformer 사용
Vision Transformers for Dense Prediction
BinsFormer: Revisiting Adaptive Bins for Monocular Depth Estimation

https://huggingface.co/docs/transformers/main/en/tasks/monocular_depth_estimation
능동센서
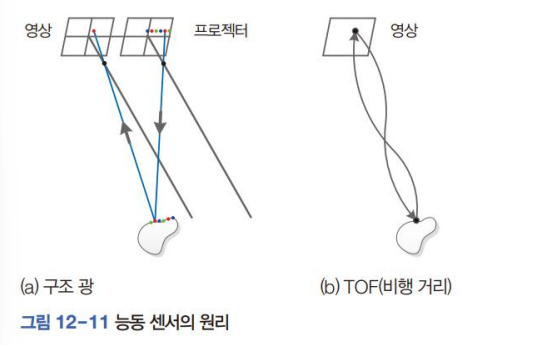
무엇을 쏘는지에 따라 structured light vs Time of Flight 방식으로 구별할 수 있다.

잘 구조화된 무늬로 대응점 쉽게 찾기
TOF
빛 또는 소리가 물체에서 반사되어 돌아오는 시간 계산
상용 깊이 카메라

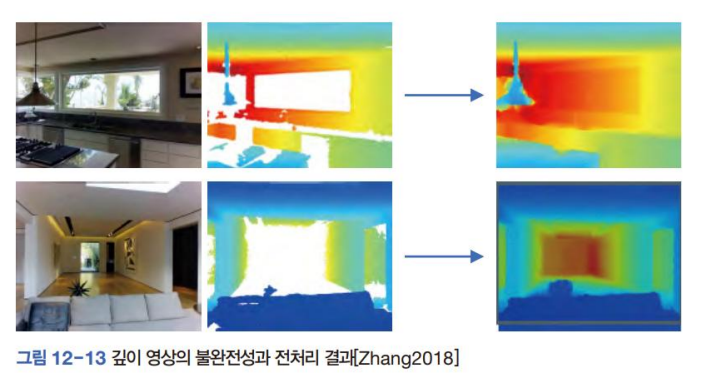
D 채널은 잡음 심한 편이다.
너무 가깝거나 먼 물체
표면에 하이라이트가 발생한 물체
너무 얇은 물체
ex) 창문
이를 위한 전처리 알고리즘이 있다.
RGB-D 영상 인식
AlexNet이 발표된 후로(왜 언급했지) 빠른 속도로 발전한 딥러닝은 RGB로만 사람의 자세와 행동을 인식했다.
D는 RGB와 융합해 인식 성능을 높이고, 로봇 주행(3차원 공간 정보를 바탕으로 자신의 위치를 실시간 갱신할 수 있는 SLAM)에 사용된다.
RGB는 물체 외관appearance에 대한 정보를 가졌고, D는 물체 형상(shape)에 대한 정보를 가졌기 때문에 상호 약점을 보완할 수 있다. 이런 이유로 RGB-D의 융합은 분류 검출 자세 추정 등에 널리 활용된다.
D 데이터의 불완정성 때문에 RGB 채널과 D 채널을 별도의 신경망에 넣어 특징 맵을 추출한 다음 적절한 순간에 융합한다. (의미 분할에서)
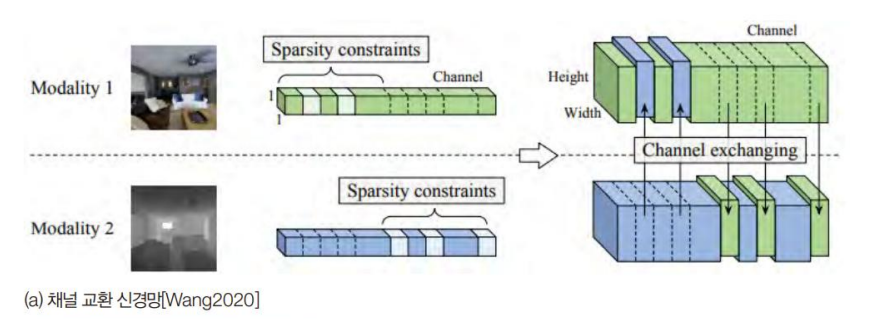

사람 행동을 인식하는 데 RGB-D를 적용한 연구
https://www.sciencedirect.com/science/article/abs/pii/S0031320319301955?via%3Dihub
