Abstract
객체 탐지를 위한 Fast Region-based Convolutional Network method (Fast R-CNN) 에 대한 논문!
이전의 것들과 비교해서, Fast R-CNN는 훈련 및 테스트 속도를 향상 시키고 동시에 탐지 정확도를 높인다!!
Fast R-CNN는 R-CNN보다 VGG16 네트워크를 훈련하는 데 9배 빠르고, 테스트 시간에는 213배 더 빠르며, PASCAL VOC 2012에서 더 높은 mAP(Mean Average Precision)를 달성합니다.
깃 허브 주소: https://github.com/rbgirshick/fast-rcnn
참고) VGG-16 모델은 ImageNet Challenge에서 Top-5 테스트 정확도를 92.7% 달성하면서 2014년 컴퓨터 비전을 위한 딥 러닝 관련 대표적 연구 중 하나로 자리매김하였다.
PASCAL VOC challenge은 Object detection 분야에서 가장 보편적인 데이터 셋 입니다. 그 중에서도 PASCAL VOC 2012라는 데이터 셋은 R-CNN 모델에서부터 YOLO v3 모델 까지 학습 데이터 셋으로 사용되었습니다.
Mean Average Precision: 평균 정밀도 지표를 나타내며, 컴퓨터 비전에서 객체 감지 알고리즘의 성능을 평가하는 데 자주 사용됩니다. 이는 정밀도와 재현율을 결합하여 이미지 내 객체를 얼마나 정확하게 식별하는 지를 평가하는 지표입니다.
1. Introduction
- 깊은 합성곱 신경망(ConvNets)은 이미지 분류와 물체 검출 정확도를 향상시킴
- 이 논문에서는 단일 단계 훈련 알고리즘을 제안하여 훈련 과정을 간소화하고, 결과적으로 VGG16을 R-CNN보다 9배, SPPnet보다 3배 빠르게 훈련하며, PASCAL VOC 2012에서 66%의 mAP를 달성함.
- 물체 검출이 정확한 물체의 위치를 찾아야 하기 때문에 발생하는 복잡성과 이에 따른 주요 문제들이 있습니다. 첫째로, 많은 후보 물체 위치를 처리해야 합니다. 둘째로, 이러한 후보들은 정교한 지역화를 위해 보정되어야 하는 대략적인 위치 정보만을 제공합니다. 이 문제들에 대한 해결책은 종종 속도, 정확도 또는 단순함을 희생해야 할 수 있습니다.
- 이 논문에서는 최첨단 ConvNet 기반의 객체 탐지를 위한 훈련 과정을 간소화합니다. 우리는 단일 단계 훈련 알고리즘을 제안하여, 객체 제안을 분류하고 공간적 위치를 정교하게 보정하는 것을 동시에 학습합니다.
1.1. R-CNN and SPPnet
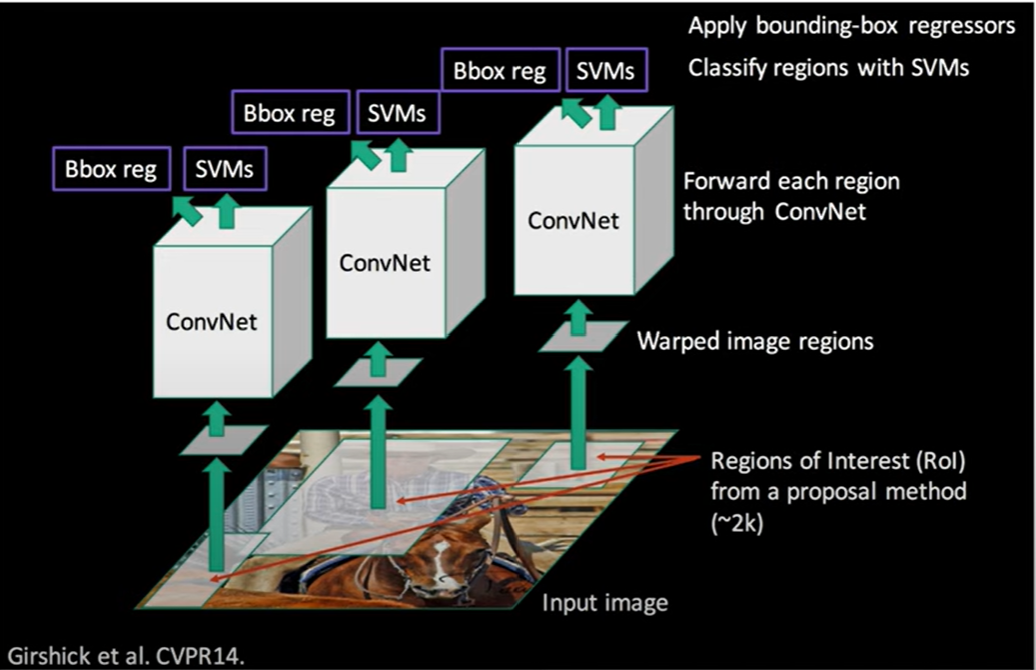
<R-CNN의 구조>
- The Region-based Convolutional Network method (R-CNN)은 뛰어난 객체 탐지 정확도를 보여주지만 몇 가지 단점이 존재한다.
- 첫 번째는 다단계 파이프라인 입니다. ⇒ 복잡한 과정
- 첫 번째로, ConvNet은 객체 제안에 대해 미세 조정됩니다. 즉, ConvNet이 이미지에서 제안된 객체를 잘 식별할 수 있도록 학습됩니다.
- 두 번째로, ConvNet의 특징을 사용하여 SVM(Support Vector Machine)을 학습시킵니다. 이 SVM은 객체를 탐지하는데 사용됩니다. 이것은 이전에 미세 조정된 ConvNet에서 배운 softmax 분류기를 대체합니다.
- 세 번째로, 바운딩 박스 회귀자를 학습시킵니다. 이 회귀자는 객체의 정확한 위치를 찾는 데 도움이 됩니다.
- 이러한 다단계 훈련 프로세스는 훈련 시간이 오래 걸리고 복잡하며, 메모리와 계산 비용이 많이 드는 단점을 가지고 있습니다. 이것이 R-CNN의 주요한 단점 중 하나 입니다.
- 두 번째는 훈련 과정에서 필요한 계산과 시간이 매우 많이 든다는 점입니다. ⇒ 많은 비용
- 각 이미지의 각 객체 제안에서 특징을 추출하고 디스크에 저장하는 과정이 필요합니다. 따라서 이것은 훈련을 비용이 많이 들게 만들고, 대규모 데이터 셋을 처리할 때 더욱 어렵게 만듭니다.
- 세 번째는 객체 탐지가 느리다는 점입니다. ⇒ 느린 속도
- VGG16을 사용한 물체 검출은 각 이미지 당 47초가 소요됩니다(그래픽 처리 장치(GPU)를 사용한 경우). 이는 검출 과정이 매우 시간이 많이 소요되는 것을 의미하며, 실시간 물체 검출을 어렵게 만듭니다. ⇒ R-CNN은 쓰지 말자!!!!!!!
- 이 물체검출을 2000여개의 영역마다 진행해야 하기 때문에 학습 시간이 길다
- Spatial pyramid pooling networks (SPPnets)은 R-CNN을 가속화하기 위해 제안 되었습니다. SPPnet은 테스트 시에 R-CNN을 10배에서 100배 가속화합니다.
- 하지만 SPPnet도 R-CNN과 마찬가지로 다단계 파이프라인이다.
<보충> Region Proposal Network(RPN)
RPN은 feature map을 input으로, RP(Region Proposal)를 output으로 하는 네트워크라고 할 수 있고, selective search의 역할을 온전히 대체한다.
- 다양한 사이즈의 이미지를 입력 값으로 object score과 object proposal을 출력한다.
- Fast r-cnn과 합성 신경망을 공유한다.
- feature map의 마지막 conv 층을 작은 네트워크가 sliding하여 저차원으로 매핑한다.
- Regression과 classification을 수행한다.
- 구성
RPN의 input 값은 이전 CNN 모델에서 뽑아낸 feature map이다. Region proposal을 생성하기 위해 feature map위에 nxn window를 sliding window시킨다.
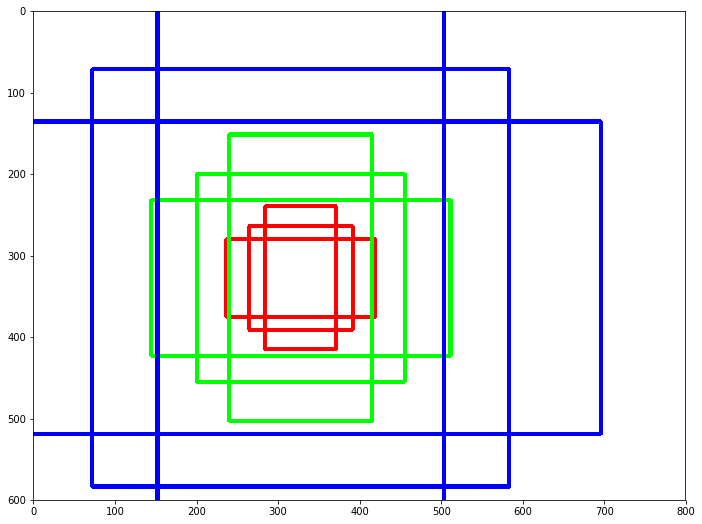
1-1. 기본 Anchor Box
(앵커 박스 : 미리 정의된 형태를 가진 경계박스 수)
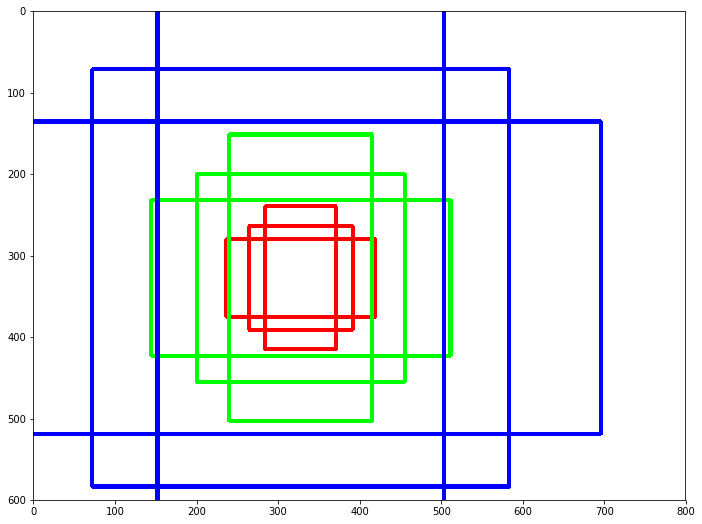
Fast R-CNN에서는 3개의 스케일과 3개의 비율을 사용하여 k=9개의 앵커를 사용하였다.
1-2. Delta
기본 Anchor의 크기와 위치를 조정하기 위한 값들이다.
모델을 통해 학습된다. Anchor하나에 Delta가 하나씩 대응한다. Anchor하나의 값의 구성은 (Y1,X1,Y2,X2)처럼 Bounding Box형식의 구조를 갖고, Delta하나의 값의 구성은 (deltaCenterY, deltaCenterX, deltaHeight, deltaWidth) 로 구성된다.
1-3. Probability
각 Anchor 내부에 객체가 존재할 확률이다.
RPN의 output 값은 객체가 존재할 것이라는 확률이 높고, 중복이 제거된 Bounding Box들이다.(ROI라고 함)
- RPN 내부에서 이루어지는 동작
- 입력단계
위 3가지의 정보를 입력
- Bounding Box 계산
Anchor는 Delta와 결합해서 값들을 조정해야 한다. Delta값이 Deep Network을 통해 산출된 값이므로, 이 조정 과정을 거쳐야 실제 객체의 위치를 정확하게 표현하게 된다.
- Sort단계
입력으로 설정된 Anchor Box는 갯수도 너무 많고 확률이 0에 부분도 Bounding Box정보를 가지고 있다. 따라서 계산과정은 확률이 높은 객체에 대해서만 작업을 진행할 필요가 있다. 그래서 2번에서 산출된 Bounding Box들 중에서 확률이 높은 객체를 사용한다.
- Non Maximum Suppression (NMS)
- 동일한 클래스에 대해 높은-낮은 confidence 순서로 정렬한다.
- 가장 confidence가 높은 boundingbox와 IOU가 일정 이상인 boundingbox는 동일한 물체를 detect했다고 판단하여 지운다.
아래의 첫번째 이미지는 NMS를 시행하기 전, 두번째 이미지는 이를 실행한 후 결과이다.


- Merge
NMS의 결과는 메모리 상에서 구멍이 뚫린 형태가 된다.연속된 형태로 모아 주어야 다음에 이어지는 Convolution과 같은 표준화된 절차를 진행할 수 있다.
이후 이 과정을 통해 ROI를 구할 수 있다.
1.2. Contributions
- R-CNN과 SPPnet의 단점을 수정하면서 그들의 속도와 정확도를 향상 시키는 새로운 훈련 알고리즘을 제안 ⇒ Fast R-CNN
- R-CNN, SPPnet보다 높은 검출 품질 (mAP)
- 다중 작업 손실을 사용하는 단일 단계입니다.
- 훈련은 모든 네트워크 계층을 업데이트할 수 있습니다.
- 특징 캐싱을 위한 디스크 저장 공간이 필요하지 않습니다.
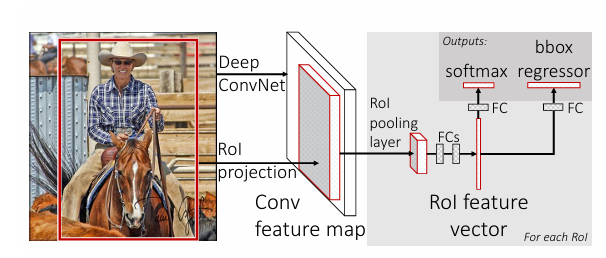
2. Fast R-CNN architecture and training
Fast R-CNN 아키텍처의 동작 절차는 다음과 같습니다
- 전체 이미지와 객체 제안 세트를 입력으로 받습니다. ⇒ Deep ConvNet & RoI projection
- 전체 이미지를 합성곱(conv) 및 최대 풀링 레이어를 통해 처리하여 conv 특징 맵을 생성합니다. ⇒ Conv feature map
- 각 객체 제안에 대해 관심 영역(RoI) 풀링 레이어를 적용하여 특징 맵에서 고정된 길이의 특징 벡터를 추출합니다 ⇒ RoI feture vector
- 추출된 특징 벡터는 전체 연결(fc) 레이어의 일련의 레이어로 입력되어 처리됩니다.
- 이러한 처리 과정을 거쳐서 두 개의 동료 출력 레이어로 분기됩니다:
-
첫 번째 레이어는 K개의 객체 클래스에 대한 소프트맥스 확률 추정을 생성합니다. 여기서 K는 물체 클래스의 수이며, 하나는 "배경" 클래스를 포함합니다. ⇒ softmax
-
두 번째 레이어는 각 K개의 객체 클래스에 대해 네 개의 실수 값을 출력합니다. 각각의 4개의 값은 해당 클래스에 대한 보정된 바운딩 박스의 위치를 인코딩합니다.
⇒ bbox regressor
-
2.1. The RoI pooling layer
- 먼저, 전체 이미지를 컴퓨터가 이해할 수 있는 형태로 변환(Conv feature map)합니다. 이를 위해 여러 합성곱(conv) 및 최대 풀링 레이어를 사용합니다. 이러한 작업을 통해 이미지에서 중요한 기능을 추출할 수 있습니다.
- 그런 다음, 컴퓨터가 주의를 기울일 만한 물체가 될 가능성이 있는 지역을 선택합니다. 이것을 "객체 제안(Object Proposal)"이라고 합니다. ⇒ 관심 영역 (ROI, region of interest)
- 선택된 객체들로부터, 해당 지역에서 중요한 특징을 추출합니다. 이를 통해 컴퓨터는 물체를 더 잘 이해할 수 있게 됩니다. ⇒ feature vector ⇒ 이를 통해 회귀자 및 소프트맥스를 추출
- 추출된 특징들은 각각의 물체에 대한 정보로 사용됩니다. 컴퓨터는 이 정보를 사용하여 물체가 무엇인지 식별하고 그 위치를 파악합니다.
- 소프트맥스(Softmax): 소프트맥스는 여러 개의 클래스 중에서 하나를 선택하는 데 사용됩니다. 주어진 입력에 대한 각 클래스의 확률을 출력합니다. 예를 들어, 이미지 내에 각각의 물체에 대한 클래스를 예측하는 데 사용됩니다. 가장 높은 확률을 가진 클래스가 해당 객체의 예측된 클래스입니다. 이러한 방식으로 소프트맥스는 이미지 내의 물체를 식별하는 데 사용됩니다.
- 회귀자 바운딩 박스(Regressor Bounding Box): 회귀자 바운딩 박스는 객체의 위치를 보정하는 데 사용됩니다. 각 클래스마다 네 개의 실수 값을 출력합니다. 이 네 개의 값은 해당 클래스에 대한 보정된 바운딩 박스의 위치를 나타냅니다. 따라서 회귀자는 객체의 정확한 위치를 파악하는 데 도움이 됩니다. 예를 들어, 객체 제안에서 추출된 특징을 기반으로 하여 객체의 정확한 위치를 조정합니다.
- 이를 통해 Fast R-CNN이 이미지 내의 물체를 식별하고 위치를 파악하는 것이다!!
참고) ROI max pooling이란 무엇인가?
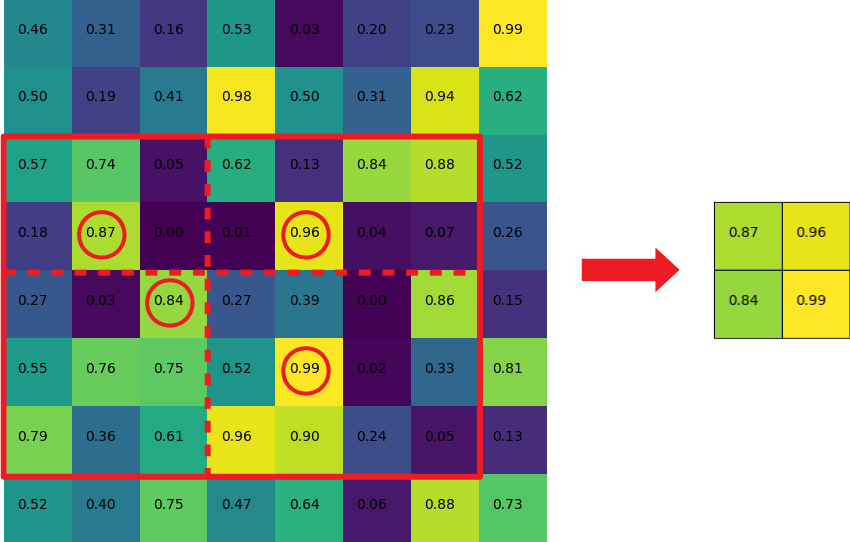
- RoI(Region of Interest) max pooling은 특정 관심 영역(ROI) 내에서 가장 중요한 정보를 추출하는 방법입니다.
- 먼저, ROI 창을 일정한 크기의 그리드로 나눕니다. 이 그리드는 대략적인 크기가 되도록 조정됩니다.
- 그런 다음, 각 그리드 셀 내에서 최대 값을 선택하여 해당 셀에 출력합니다.
- 이렇게 하면 각 셀이 ROI 내의 특정 영역에 대한 가장 중요한 정보를 포함하게 됩니다.
- 이 과정은 ROI 내에서 특정 영역의 중요한 특징을 추출하는 데 사용됩니다. 이를 통해 Fast R-CNN은 객체 제안 내에서 중요한 정보를 추출하고, 이를 이용하여 물체를 식별하고 위치를 파악합니다.
2.2. Initializing from pre-trained networks
- 사전훈련된 ImageNet Network 3개(각각 5개의 max pooling layer를 가지고 5~13개의 conv layers 사이에 있는)로 실험 진행
- 미리 학습된 네트워크가 Fat R-CNN Network를 초기화 할 때 세가지 변환.
- 마지막 max pooling layer가 ROI pooling layer로 교체
- 네트워크의 첫 번째 FC layer와 호환되도롣 H, W 설정
- network 마지막 FC layer와 Softmax가 2개의 sibling layers로 교체된다.
- 네트워크가 두 가지 입력 데이터(이미지 리스트, 이미지의 ROI들)를 받을 수 있도록 바뀐다.
- 마지막 max pooling layer가 ROI pooling layer로 교체
2.3. Fine-tuning for detection
https://bkshin.tistory.com/entry/논문-리뷰-Fast-R-CNN-톺아보기
역전파로 네트워크의 모든 가중치를 훈련할 수 있다는 점은 Fast R-CNN의 큰 장점이다.
기존 기법 R-CNN 과 SPP-Net은 ROI가 입력이미지에서 굉장히 큰 영역을 갖기 때문에 입력 이미지 전체를 훈련하게 되어버린다.
이에 더 나은 방법을 제기하는데, 훈련하는 동안 feature를 공유하는 방식이다. Fast R-CNN 훈련에서는 SGD 미니 배치가 샘플링된다.
먼저 N개의 이미지를 샘플링하고
이어서 R/N개 ROI를 샘플링한다. 중요한 점은 같은 이미지에서 뽑은 ROI는 순전파와 역전파를 하면서 연산 결과와 메모리를 공유한다는 것이다.
N이 작을수록 미니 배치 연산은 줄어듭니다. 예를 들어, N = 2, R = 128이라고 해봅시다. 그러면 서로 다른 128개의 이미지에서 RoI 한 개를 뽑을 때보다 64배나 빠릅니다.
2개(=N)의 이미지를 샘플링하여 각 이미지마다 RoI 64개(=R/N=128/2)를 샘플링하기 때문입니다. 128개를 샘플링하는 경우와 2개를 샘플링하는 경우의 속도 차이는 64배가 나겠죠. 2개의 이미지에서 64개의 RoI를 샘플링할 때는 RoI가 연산과 메모리를 공유하기 때문에 손실이 발생하지 않습니다.
게다가 Fast R-CNN은 소프트맥스 분류기, 경계 박스 회귀(Bounding box regression)를 동시에 최적화하도록 한번에 파인 튜닝을 합니다(one-stage). R-CNN은 소프트맥스 분류기, SVM, 경계 박스 회귀를 따로따로 처리했다(multi-stage).
Multi-task loss
Fast R-CNN은 두 가지 출력 계층을 갖는다.
- ROI마다 (K+1)개의 확률값을 출력.
- K = 클래스 개수, +1은 배경까지
- 경계 박스 좌표 출력.
- (좌상단 x좌표, 좌상단 y좌표, 너비, 높이)
p = 예측 클래스 값
u = 실제 클래스 값
t = 예측 경계 박스 좌표
v = 실제 경계 박스 좌표

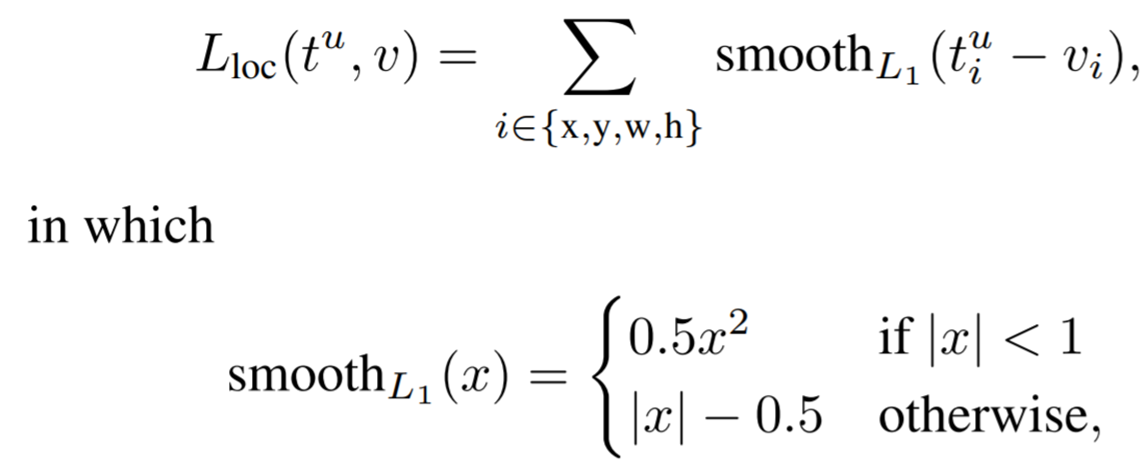
⇒ 이를 이용해 분류와 위치 회귀라는 두 작업을 한 가지 모델로 처리하면, 역전파로 두가지 작업에 대해 한번에 파인튜닝을 할 수 있게 되는 것이다.
Mini-batch sampling.
파인 튜닝하는 동안 각 SGD 미니 배치는 N=2가 되게 이미지를 샘플링합니다. R=128이므로, 각 이미지마다 RoI를 64개 뽑습니다. 후보 영역에서 실제 경계 박스와 IoU 0.5 이상인 RoI를 25% 뽑습니다. 이 RoI를 positive 샘플로 간주합니다. 즉, u=1이라는 말입니다. 후보 영역에서 뽑은 나머지 RoI 중 실제 경계 박스와 IoU가 0.1 이상 0.5 미만인 RoI는 배경으로 간주합니다. negative 샘플로 간주한다는 뜻이죠. u=0입니다. 데이터 증강을 위해 훈련하는 동안 50% 확률로 좌우 대칭을 합니다. 이외에 다른 데이터 증강은 하지 않았습니다.
- 2.3. 첨부- SGD, SVD SGD

**SVD(Singular Value Decomposition)**
- 고유값 분해(eigen decomposition)
- 어떤 행렬을 고유값 행렬과 고유벡터 행렬로 분해해서 나타내는 것.
- 행과 열의 크기가 같은 행렬에 대해서만 가능(Square matrix)

- A^D는 A 행렬의 대각화 행렬
- 특이값 분해
- **m * n 크기의 행렬 A(square 아니어도 된다)**를 다음과 같이 분해하는 것
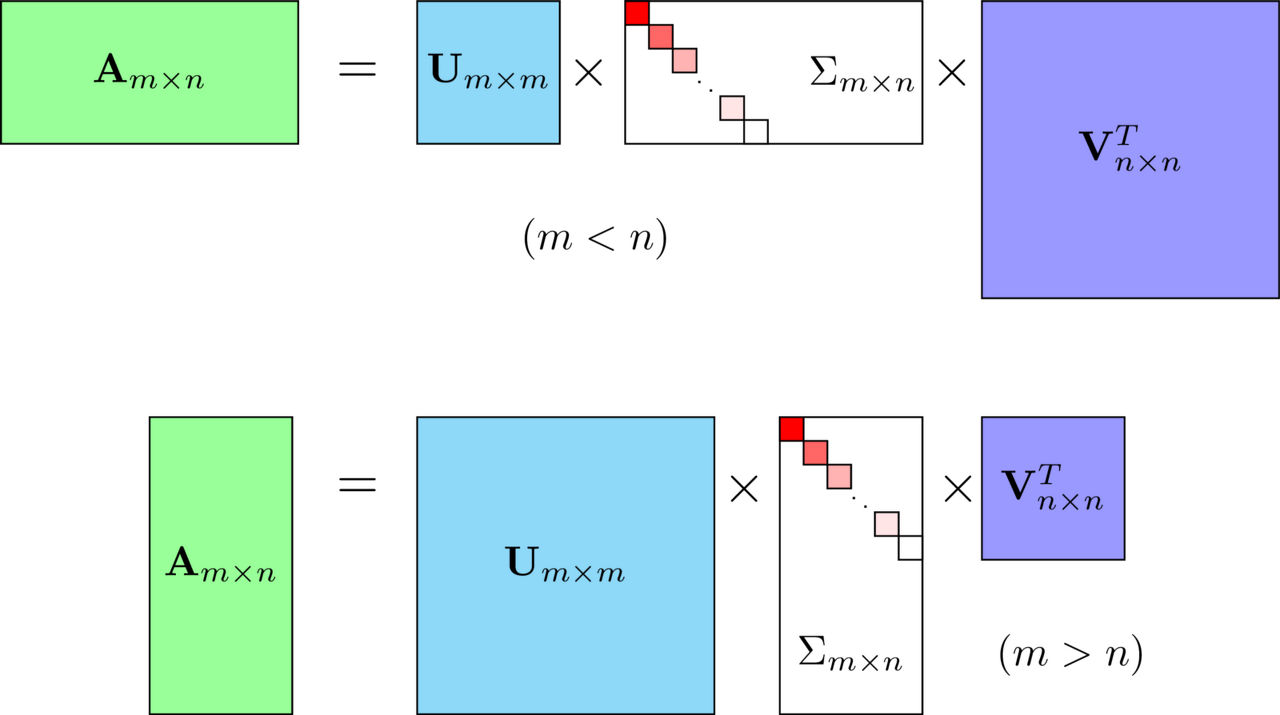
U, V를 특이 벡터(singular vector)라고 하며, 모든 특이 벡터는 서로 직교한다. 시그마는 대각 행렬
U: AA^T를 고유값 분해해서 얻은 직교 행렬, left singular vector
V: A^TA를 고유값 분해해서 얻은 직교 행렬, right singular vector
- **특이값 분해의 의미**
- 행렬을 대각화하는 한 방법
- 기하학적 의미는 A로 직교하는 벡터를 선형 변환시 여전히 직교하는 벡터 U, ㅍ를 찾아내는 것. ⇒ **데이터의 특성을 가장 잘 표현하는 축들을 찾는 것, PCA와도 연관된다.**
- **Truncated SVD**
- 시그마의 비대각 부분을 제거하고 그에 대응되는 U와 V의 원소도 함께 제거
- 대각 원소 중 특이값(singular value)가 0인 부분을 모두 제거
- 시그마의 대각 원소 중 상위 몇 개만 추출하여 차원을 줄임.
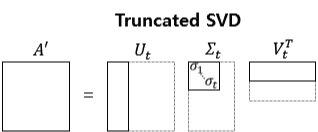
- **원본 훼손, 복구 불과.**- 2.4. Scale invariance 스케일이 변하지 않는 객체 탐지를 위해서 1)brute-force 방식(훈련과 테스트 모두 각 이미지를 사전에 정의된 픽셀 크기로 처리)과 2) 이미지 피라미드 방식(여러 이미지 크기를 학습)을 사용했다.
-
Image pyramid
- 이미지의 스케일과 해상도를 조절하여 동일한 이미지를 여러 크기로 조절하여 작업할 필요가 있을 때 사용.
-
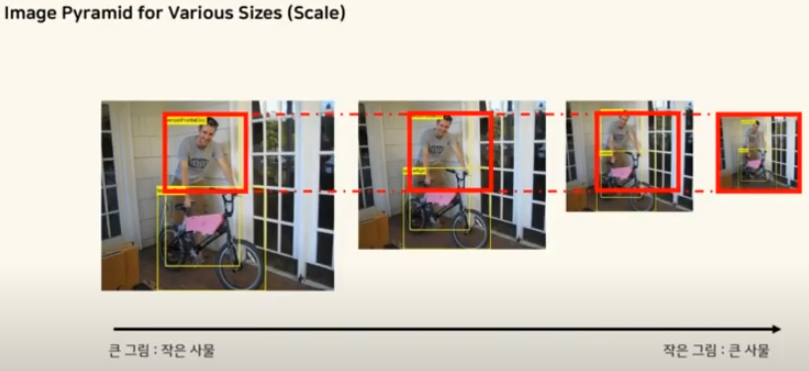
큰 그림은 작은 사물을 detection할 때, 작은 그림은 큰 사물을 detection할 때 사용함.3. Fast R-CNN detection
- 3.1. Truncated SVD for faster detection 이미지 분류 시 순전파를 할 때, 전결합 계층에서 소요하는 시간이 합성곱 계층에서 소요하는 시간 대비 상대적으로 짧다. 객체 탐지는 처리해야 할 ROI가 많아 전결합 계층에서 소요하는 시간이 거의 절반을 차지한다. Truncated SVD(특이값 분해)를 적용하면 전결합 계층에서 소요하는 시간을 줄일 수 있다.
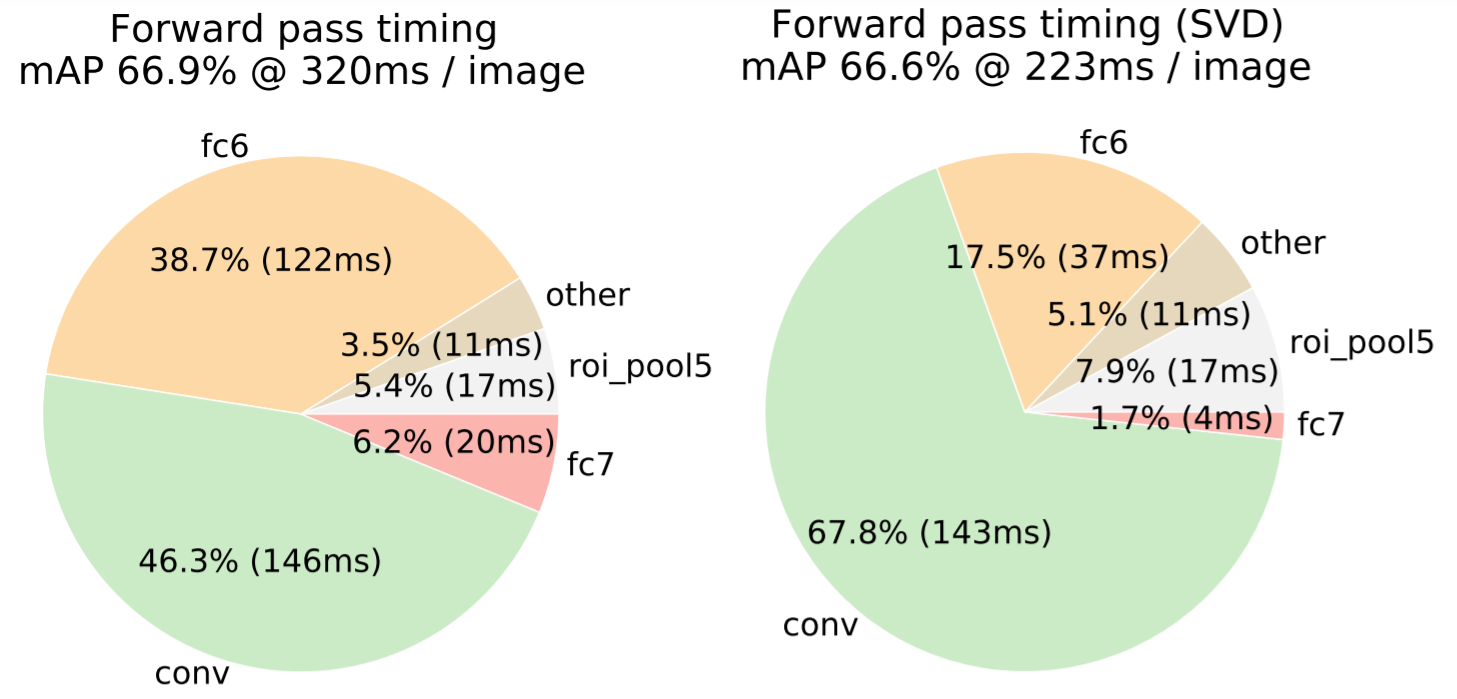
4. Design evaluation

Fast R-CNN과 R-CNN 및 SPPnet의 비교 ⇒ PASCAL VOC 2007 데이터셋을 가지고 실험하였습니다.
4.1. Does multi-task training help?
- 물체 검출 정확도를 향상시키기 위해 다음 절차를 따르며 Fast R-CNN의 다중 작업 훈련을 평가했습니다.
- 기준 네트워크 훈련: 분류 손실만 사용하여 기본 네트워크를 훈련합니다. 이때, 바운딩 박스 회귀가 비활성화됩니다.
- 다중 작업 훈련: 다중 작업 손실을 사용하여 네트워크를 훈련하되, 테스트 시 바운딩 박스 회귀를 비활성화합니다.
- 분류 정확도 비교: 다중 작업 훈련과 단일 작업 훈련의 결과를 비교하여 분류 정확도를 확인합니다. 다중 작업 훈련은 분류 정확도를 향상시킵니다.
- 바운딩 박스 회귀 추가: 기준 모델에 바운딩 박스 회귀 레이어를 추가하고, 바운딩 박스 회귀를 사용하여 네트워크를 훈련합니다.
- 성능 평가: 단계별 훈련과 다중 작업 훈련의 성능을 비교하여 mAP를 평가합니다. 다중 작업 훈련이 단계별 훈련보다 성능이 우수합니다.
결론!!!!! ⇒ Fast R-CNN의 다중 작업 훈련이 물체 검출 정확도를 향상 시킬 수 있음을 확인하였습니다.
4.2. Scale invariance: to brute force or finesse?
scale-invariant object detection : 물체의 크기가 달라져도 동일한 정확도로 물체를 감지하는 것.
이를 위한 두 가지 방법을 제안
⇒ brute-force learning (single scale) and image pyramids (multi-scale)
먼저, 물체를 감지할 이미지를 가져온다. 이 이미지는 여러 물체를 포함할 수 있고, 이 물체들의 크기가 다양할 수 있다.
- 이미지 스케일링: 이미지의 크기를 정합니다. 일반적으로 가장 짧은 변의 길이를 기준으로 이미지를 크기 조정. 예를 들어, 모든 이미지의 가장 짧은 변의 길이를 600 픽셀로 만들 수 있다. 이렇게 함으로써 이미지를 표준화하고, 처리 속도를 높이고, 메모리 사용량을 줄일 수 있다.
- ConvNet 통과: Convolutional Neural Network (ConvNet)을 사용하여 이미지를 처리. ConvNet은 이미지의 특징을 추출하는 데 사용되는 여러 계층으로 구성.
- 물체 제안 생성: 이미지에서 물체가 있을 것으로 예상되는 위치를 제안. 이를 위해 각 위치에서 물체가 있을 확률을 계산하는 방법을 사용.
- Region of Interest (RoI) 풀링: 물체 제안 영역에서 고정 길이의 특징 벡터를 추출. 이를 위해 RoI 풀링 레이어를 사용해요. 각 물체 제안 영역을 일정한 크기로 조정하고, 해당 영역에서 가장 중요한 특징을 추출.
- Fully Connected (FC) 레이어 통과: 추출된 특징 벡터는 Fully Connected 레이어를 통과. 이 레이어는 각 물체 제안에 대한 정보를 가지고 있고, 다음 단계에서 사용될 준비.
- 출력 계산: FC 레이어에서 계산된 결과를 사용하여, 물체가 속할 클래스와 물체의 위치를 예측. 클래스 예측에는 softmax를 사용하고, 물체 위치 예측에는 bounding box regressor를 사용.
- 출력 평가: 예측된 결과를 평가하여, 각 물체 제안이 실제 물체와 얼마나 일치하는지를 확인. 이를 통해 정확도를 평가.
참고) single scale 과 multi scale의 차이
- 단일 스케일(Single Scale):
- 단일 스케일 감지 방법은 이미지를 일정한 크기로 고정하고, 이 크기에서 물체를 감지합니다. 예를 들어, 모든 이미지를 600x600 픽셀로 크기 조정하여 처리할 수 있습니다.
- 이 방법은 각 이미지를 하나의 크기로 표준화하여 처리 속도를 높이고 메모리 사용량을 줄일 수 있습니다.
- 단일 스케일은 물체 크기가 일정한 경우에 적합하며, 처리 속도가 빠르고 구현이 간단합니다.
- 다중 스케일(Multi Scale):
- 다중 스케일 감지 방법은 이미지를 여러 다른 크기로 조정하여 물체를 감지합니다. 즉, 다양한 크기의 이미지에서 각기 다른 크기의 물체를 감지할 수 있습니다.
- 이 방법은 다양한 크기의 물체를 감지해야 하는 경우에 유용합니다. 예를 들어, 작은 물체와 큰 물체가 함께 있는 이미지를 처리할 때 유용합니다.
- 다중 스케일은 보다 다양한 물체를 감지할 수 있지만, 처리 속도가 느리고 구현이 복잡할 수 있습니다.
요약하면, 단일 스케일은 간단하고 빠르지만, 물체의 크기가 다양한 경우에는 다중 스케일이 더 적합할 수 있습니다. 다중 스케일은 다양한 크기의 물체를 감지할 수 있지만, 처리 속도가 느리고 구현이 복잡할 수 있습니다.
4.3. Do we need more training data?
A good object detector should improve when supplied with more training data.
⇒ 좋은 object detector 는 훈련 데이터가 많아짐에 따라 성능이 점점 더 좋아져야 한다.
⇒ VOC10과 2012의 경우, 각각 mAP가 66.1%에서 68.8%, 65.7%에서 68.4%로 향상되는 것을 확인!
4.4. Do SVMs outperform softmax?
Fast R-CNN은 이미지 안에 있는 물체를 찾기 위해 사용되는데, 이때 분류를 위해 SVM(Support Vector Machine) 대신에 소프트맥스(softmax) 분류기를 사용합니다. 이것은 이전에 사용된 방법들과 비교하여 더 효과적인 것으로 나타났습니다. 예를 들어, SVM 대신에 소프트맥스를 사용하면 약간 더 좋은 결과를 얻을 수 있습니다. 이것은 물체를 정확하게 식별하는 데 도움이 됩니다.
4.5. Are more proposals always better?
object detectors에는 두 가지 타입이 존재한다.
- sparse set ⇒ selective search : 이미지 내에서 물체의 가능성 있는 위치를 추정하는 데 사용
- dense set ⇒ DPM : 이미지 내에서 보다 밀집하게 분포된 물체 위치를 제안하는 세트를 의미
물체를 찾는 방법은 크게 두 가지 유형이 있다. 하나는 물체를 찾을 때 제안된 위치가 적은 경우이고, 다른 하나는 위치가 많은 경우입니다. 제안된 위치가 적은 경우에는 그 중 일부를 선택해서 실제 물체가 있는지 판단하고, 위치가 많은 경우에는 모든 위치에서 물체를 찾습니다.
이 두 가지 방법을 비교하기 위해 우리는 모델 M을 사용하여 이미지마다 제안된 위치의 수를 조절하고 그때마다 테스트를 해봤다. 그 결과, 제안된 위치의 수가 많아져도 정확도가 조금 올라가다가 다시 조금 내려가는 것을 발견했어요. 이 실험을 통해 물체를 찾을 때 제안된 위치가 많다고 해서 정확도가 더 올라가는 것은 아니라는 것을 알 수 있었습니다. 그리고 이러한 실험을 통해 Fast R-CNN을 사용하는 경우, 제안된 위치를 밀도가 높은 위치로 대체했을 때 정확도가 조금만 낮아지는 것을 발견했습니다. 그러나 밀도가 높은 위치를 추가하면 정확도가 더 많이 낮아지는 것을 알 수 있었습니다.
마지막으로, 밀도가 높은 위치만 사용하여 훈련하고 테스트할 때 SVM을 사용하는 것이 더 나쁜 결과를 가져온다는 것도 알 수 있었습니다. ⇒ 소프트 맥스 사용해야하는 이유
5. Conclusion
- Sparse Object Proposal이 detector의 품질을 향상시켰다.
- Dense box들이 sparse proposal 만큼 성능이 나오게 하는 기술이 있을지도 모른다. 만약 있다면 object detection이 가속화될 것이다.
