이전 편에서 graph representation learning과 message passing의 일반론을 다뤘다. 이번 챕터는 그 위에서 실제로 두 가지 대표 태스크—node classification과 link prediction—를 어떻게 동일한 framework로 푸는지, 그리고 모델 선택이 어디서 갈리는지를 본다. 본 글의 thesis는 다음과 같다.
Node classification과 link prediction은 입력 형태(homogeneous vs heterogeneous)와 decoder(log_softmax vs dot product)만 다를 뿐, 동일한 encoder–decoder 골격을 공유한다. 그 위에서 SAGE는 두 태스크 모두에서 가장 균형 잡힌 선택지로 드러난다.
1. 두 태스크를 하나의 프레임워크로
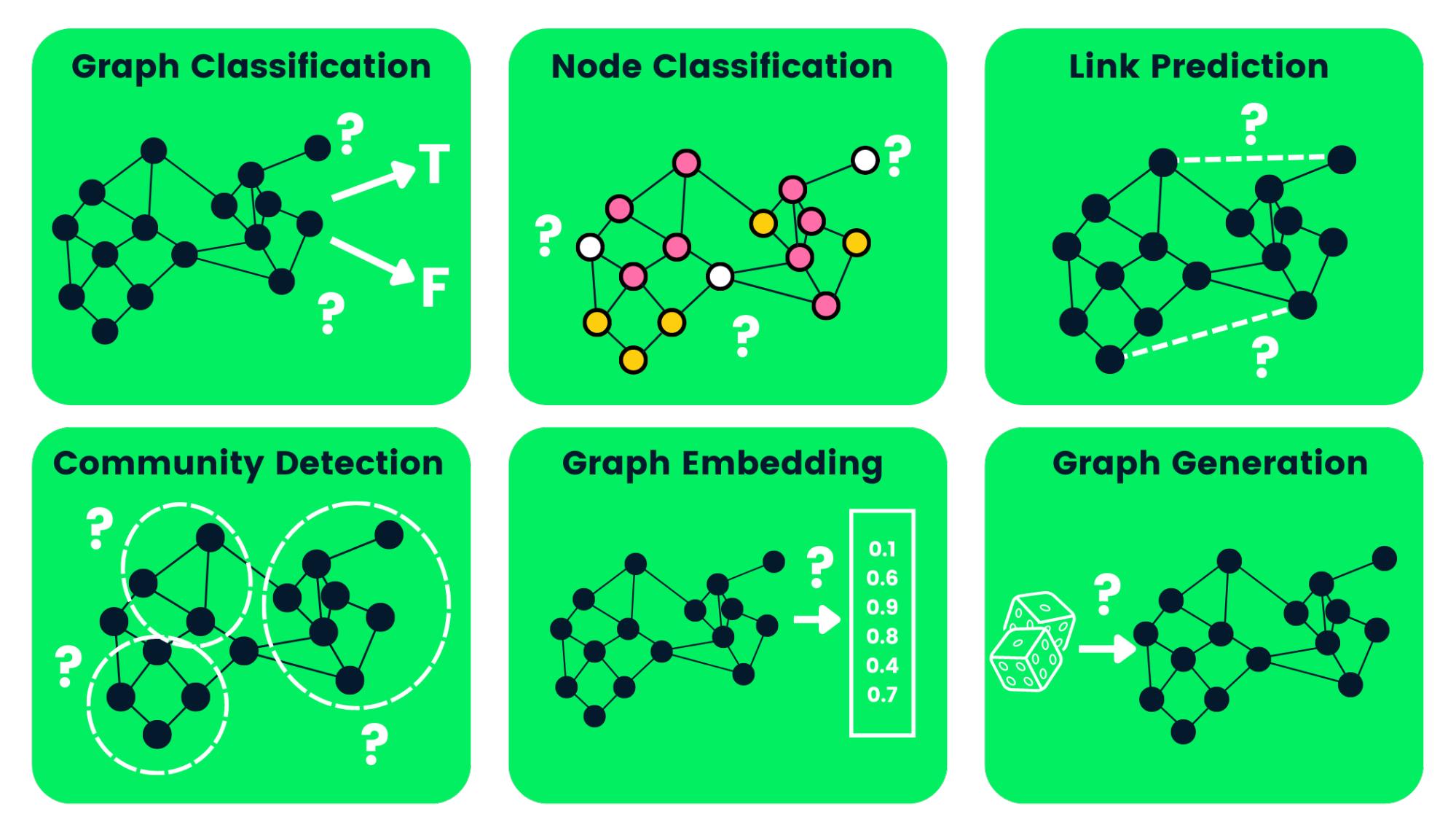
Node classification은 그래프의 각 노드에 라벨을 붙이는 문제다. AML(Anti-Money Laundering) 시나리오에서는 비트코인 거래 네트워크의 각 노드(계정·거래)를 licit(합법)/illicit(불법)로 분류한다. Link prediction은 노드 사이에 존재하지 않은 엣지가 미래에 형성될 가능성을 예측하는 문제다. 영화 추천 시나리오에서는 사용자–영화 쌍이 평점(rating) 관계로 연결될지를 예측한다.
태스크와 도메인이 다르지만, 둘 다 동일한 end-to-end framework로 처리된다.
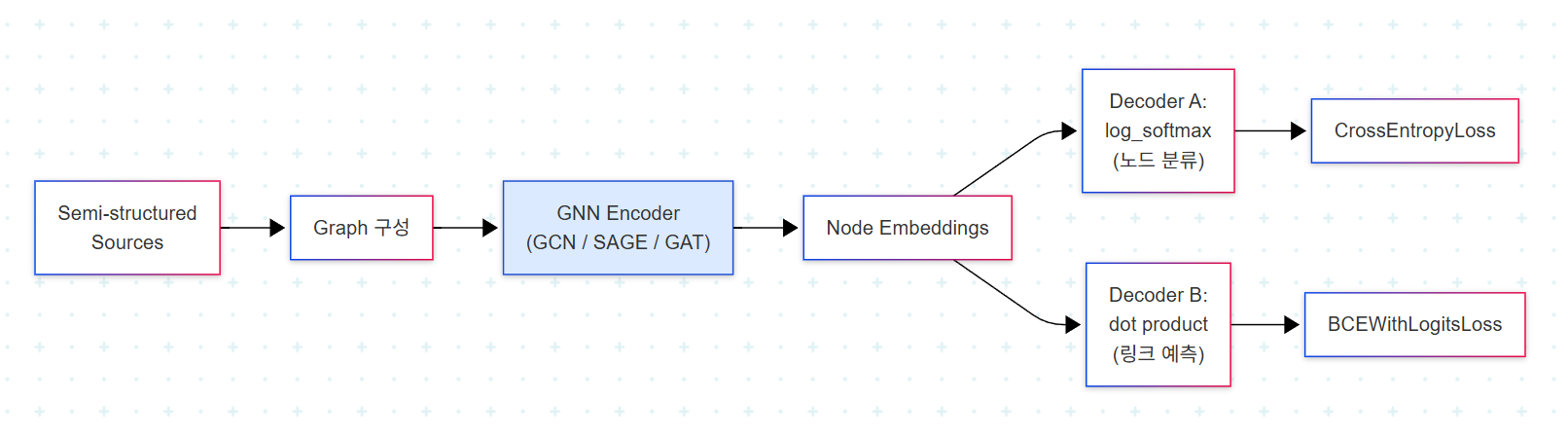
Encoder는 두 태스크 모두 GNN이 담당하고, decoder만 downstream task에 맞춰 교체된다. PyTorch Geometric(PyG)를 기반으로 GCN, GraphSAGE(이하 SAGE), GAT 세 아키텍처를 비교하는 흐름이 챕터 전체를 관통한다.
2. Node Classification: AML 시나리오
2.1 데이터와 문제 설정
Elliptic 데이터셋은 약 20만 개의 비트코인 거래(노드), 23만 4천 개의 directed payment edge, 노드당 166개의 피처를 갖는 time-series 그래프다. 핵심 도전 과제는 심각한 클래스 불균형이다.
| 클래스 | 비율 |
|---|---|
| Unknown | 77.15% |
| Licit | 20.62% |
| Illicit | 2.23% |
Illicit 노드가 전체의 2.23%에 불과하다는 사실이 평가 지표 선택과 loss 설계에 직접 영향을 준다.
2.2 Encoder–Decoder 구성
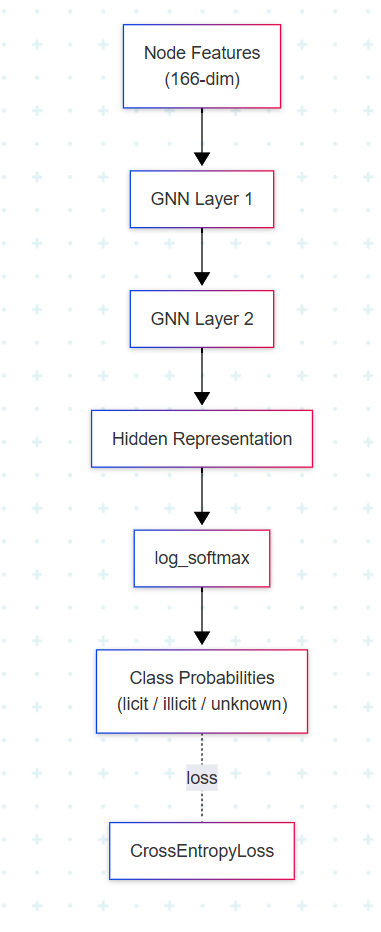
Encoder는 homogeneous GNN이다. 노드 타입과 엣지 타입이 각각 하나뿐인 그래프를 가정한 두 레이어 구조로, PyG가 제공하는 어떤 convolution layer든 끼워 넣을 수 있다.
Decoder는 log_softmax + CrossEntropyLoss 조합이다. 일반 softmax 대신 log_softmax를 쓰는 이유는 수치 안정성이다. Softmax의 분자·분모에서 극단적으로 크거나 작은 값이 등장할 때 log 공간에서 계산을 진행하면 overflow/underflow를 피할 수 있다. CrossEntropyLoss는 내부적으로 log-softmax와 negative log-likelihood를 결합하므로 둘은 자연스럽게 짝을 이룬다.
2.3 모델 비교: 학습 효율
세 모델의 파라미터 수와 학습 시간은 다음과 같다.
| Encoder | Parameters | Training time |
|---|---|---|
| GCN | 2,723 | 19.02s |
| SAGE | 5,427 | 36.71s |
| GAT | 22,025 | 43.45s |
학습 시간은 파라미터 수와 직결된다. GAT는 이웃 엣지마다 learnable attention coefficient를 도입하므로 파라미터가 GCN의 약 8배다. 효율만 보면 GCN이 가장 가볍다.
2.4 평가 지표 해석과 SAGE의 우위
AML 맥락에서 세 지표의 의미는 다음과 같다.
- Precision: 모델이 licit 혹은 illicit이라고 판단했을 때, 그 판단이 맞을 확률
- Recall: 실제 licit·illicit 노드 중 모델이 찾아낸 비율
- F1-score: 위 둘의 조화 평균
심각한 클래스 불균형 때문에 weighted average를 사용해 분포를 반영한 평가가 적합하다. 단순 macro average는 illicit 2.23% 클래스의 변동이 과대 반영되어 모델 선택을 왜곡할 수 있다.
세 모델 중 SAGE가 가장 우수한 성능을 보인다. illicit 노드의 약 83%, licit 노드의 약 99%를 정확히 분류한다. SAGE의 균형 잡힌 정확도와 최소화된 오분류는 illicit 노드 탐지가 결정적인 AML 같은 응용에 가장 적합한 선택지를 만든다.
3. Link Prediction: 영화 추천 시나리오
3.1 문제 설정과 그래프 타입의 전환
추천 시스템은 사용자–아이템 상호작용을 엣지로 모델링하는 link prediction의 대표 응용이다. AML과 달리 사용자와 영화는 본질적으로 다른 타입의 노드이며, 둘 사이의 "rates" 관계는 별개의 엣지 타입이다. 따라서 데이터 구조부터 달라진다.
| 구분 | Node Classification (AML) | Link Prediction (Recommendation) |
|---|---|---|
| Graph type | Homogeneous | Heterogeneous |
| Data class | Data | HeteroData |
| 노드 타입 | 1개 (transaction) | 2개 (user, movie) |
| 엣지 타입 | 1개 | 1개 (rates) + reverse |
HeteroData는 노드 타입별로 피처를 분리하고, edge_index를 특정 관계(여기서는 rates)에 연결한다. 또한 GNN의 message passing이 user→movie와 movie→user 양방향으로 흐르도록 reverse edge를 명시적으로 추가해야 한다.
3.2 Random Link Split의 핵심: Edge Disjoint
Link prediction에서 가장 헷갈리는 부분이자 가장 중요한 디테일은 데이터 분할이다. PyG의 RandomLinkSplit은 일반적인 dataset split과는 다른 두 가지를 고려한다.
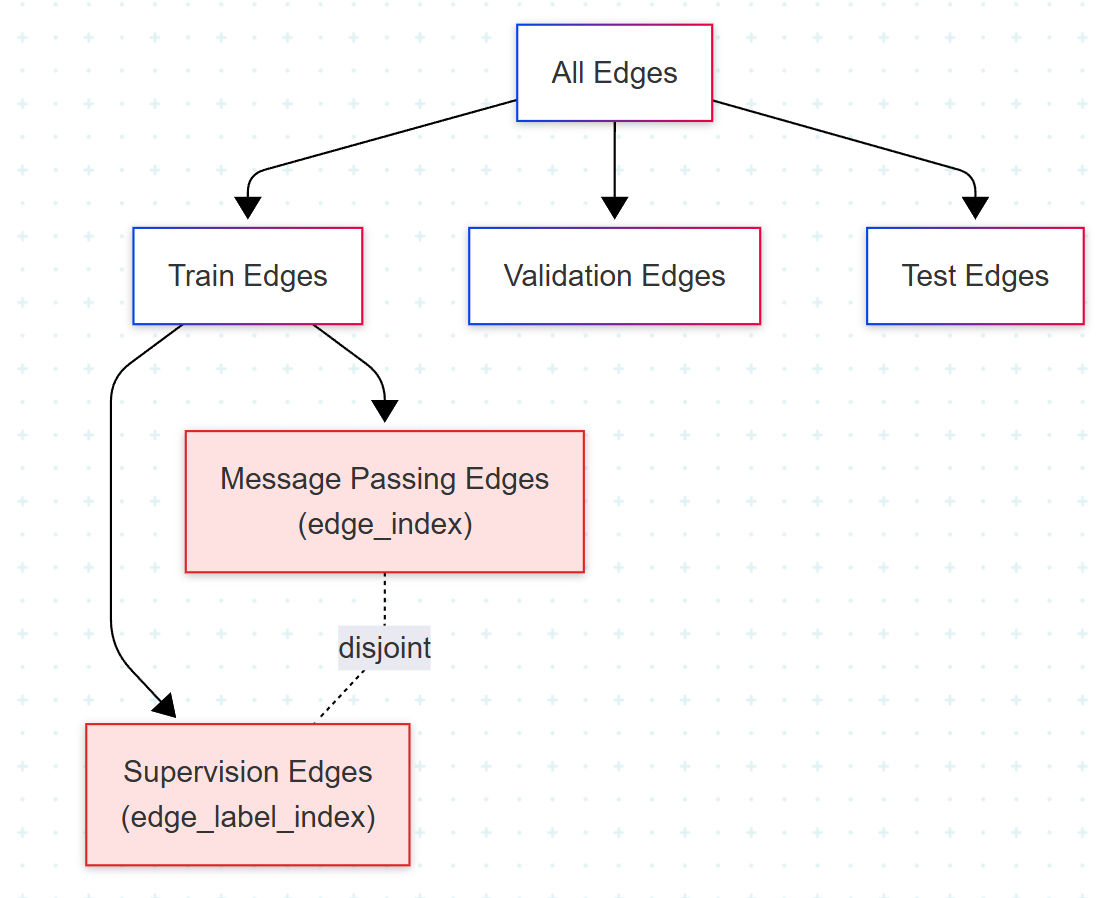
disjoint_train_ratio 파라미터는 training edge를 두 그룹으로 다시 나눈다. 하나는 message passing에 쓰이는 edge_index이고, 다른 하나는 학습 supervision 신호로 쓰이는 edge_label_index다. 두 집합은 반드시 disjoint여야 한다. 동일한 엣지가 message passing과 supervision에 동시에 등장하면 모델은 자신이 이미 본 정답을 그대로 학습 신호로 받게 된다. 이른바 edge leakage다. 한편 reverse edge는 message passing에는 쓰이지만 link prediction 학습에는 쓰이지 않는다.
대규모 그래프에서는 LinkNeighborLoader로 미니배치를 구성한다. 입력 엣지 집합에서 일부를 샘플링하고, 그 엣지에 등장한 노드들로부터 정해진 수의 이웃을 반복적으로 샘플링해 subgraph를 만든다. 작은 그래프에서는 생략 가능하지만, CPU/GPU 메모리를 넘어서는 그래프에서는 필수다.
3.3 User vs Movie: 피처 부재를 다루는 비대칭 임베딩
사용자는 본질 피처(intrinsic feature)가 없는 경우가 많다. 영화는 장르 같은 명시적 피처가 있다. 이 비대칭이 임베딩 전략의 비대칭으로 이어진다.
| 노드 타입 | 임베딩 전략 | 이유 |
|---|---|---|
| User | Single-step: embedding matrix만 사용 | 본질 피처가 없음, 학습 중에 embedding 자체가 학습됨 |
| Movie | Two-step: linear transformation + embedding layer | 20-dim 장르 벡터를 변환한 뒤 embedding과 결합 |
User의 embedding은 학습 데이터에 등장한 user ID에 대해서만 의미가 생긴다. 이 점이 cold-start 문제로 직결된다.
3.4 Decoder: Dot Product + BCEWithLogitsLoss
Link prediction의 decoder는 user embedding과 movie embedding의 dot product다. 값이 클수록 두 노드가 연결될 가능성이 높다고 해석한다. 출력은 binary_cross_entropy_with_logits로 sigmoid 활성화와 BCE loss를 한 번에 처리한다. Sigmoid가 dot product를 확률로 변환하고, BCE가 link 존재 여부와의 차이를 측정한다.
여기서 negative sampling이 필수가 된다. 실제 그래프에는 존재하는 엣지(positive)만 있으므로, "존재하지 않는 엣지"를 만들어내 negative 신호로 공급해야 한다. PyG에서는 neg_sampling_ratio=2 같은 설정으로 positive당 negative 수를 지정한다.
3.5 to_hetero(): Homogeneous 모델의 자동 변환
PyG의 to_hetero() 함수는 homogeneous GNN 모델을 heterogeneous 버전으로 자동 변환한다. HeteroSAGE를 비롯한 모든 heterogeneous 모델은 동일한 homogeneous 모델로부터 파생되며, 변환 결과가 heterogeneous 그래프의 각 엣지 타입에 적용된다. HeteroData 객체의 metadata() 메서드가 노드·엣지 타입 정보를 제공하고, convolution 연산은 이 metadata가 명시한 노드·엣지에 따라 진행된다.
3.6 GCNConv vs GraphConv: 흔히 놓치는 디테일
같은 "GCN"이라는 이름을 써도 PyG에서는 그래프 타입에 따라 다른 operator를 쓴다. Homogeneous 그래프에서는 degree normalization을 포함한 canonical layer인 GCNConv를, heterogeneous 그래프에서는 GraphConv를 쓴다.
| Operator | 대상 그래프 | 핵심 차이 |
|---|---|---|
| GCNConv | Homogeneous | 단일 노드·엣지 타입 가정, degree normalization |
| GraphConv | Heterogeneous | root와 neighbor 변환을 분리, HeteroConv wrapper와 호환 |
GCNConv는 단일 노드·엣지 타입을 가정하므로 heterogeneous 그래프에 직접 적용할 수 없고, GraphConv는 heterogeneous 환경에서 필요한 root·neighbor 분리 변환을 지원한다. 이 차이는 코드를 읽다가 "왜 GCN인데 GCNConv가 아니지"라는 의문이 들 때 정확히 부딪치는 지점이다.
4. Link Prediction 성능 비교: Node Classification과는 다른 결과
학습 효율과 파라미터 수는 다음과 같이 달라진다.
| Encoder | Parameters | Training time |
|---|---|---|
| GCN | 713,408 | 826s |
| SAGE | 713,408 | 777s |
| GAT | 1,066,880 | 956s |
Node classification 대비 파라미터 수가 큰 폭으로 늘었다. 이유는 두 가지다. 첫째, user와 movie의 표현력을 높이기 위해 embedding layer가 추가됐다. 둘째, heterogeneous GNN으로 두 종류의 노드를 모두 처리해야 한다.
이번에는 SAGE가 가장 효율적이고, GAT가 가장 느리며, GCN이 중간이다. Node classification에서는 GCN이 가장 가벼웠는데, link prediction에서는 GCN과 SAGE의 파라미터가 동일함에도 SAGE의 학습 시간이 더 짧다. Encoder 내부 구현 차이가 데이터 통과 비용에 다르게 작용한 결과다.
4.1 비즈니스 함의가 갈리는 지점
추천 맥락에서 지표는 이렇게 읽힌다.
- Precision: 모델이 추천한 영화 중 사용자가 실제로 평가할 비율 → false positive 비용
- Recall: 사용자가 평가할 영화 중 모델이 잡아낸 비율 → 추천 coverage
세 모델의 성능은 다음과 같이 나뉜다.
| 모델 | 강점 | 의미 |
|---|---|---|
| SAGE | 최고 Precision, 최고 F1 | 불필요한 추천 최소화, 균형 |
| GCN | 최고 Recall | 사용자 잠재 관심사 최대 포착 |
| GAT | — | 과추천 경향 |
SAGE는 false positive를 최소화한다. 추천 시스템에서 이는 "쓸데없는 추천이 적다"로 번역된다. GCN은 사용자가 평가할 가능성이 있는 영화를 가장 많이 포착한다. 추천의 포괄성이 중요한 시나리오—예컨대 신규 콘텐츠 노출이 목표인 경우—에서 적합하다. GAT는 평가 가능성이 낮은 영화까지 과도하게 추천하는 경향을 보인다.
F1을 기준으로 하면 SAGE가 정확성과 포괄성 사이에서 가장 좋은 균형을 만든다. 결국 두 챕터의 시나리오 모두에서 SAGE가 최선의 균형점을 차지한다는 일관된 메시지가 나온다.
5. 두 태스크 통합 비교
| 항목 | Node Classification (AML) | Link Prediction (Recommendation) |
|---|---|---|
| Graph type | Homogeneous | Heterogeneous |
| Data structure | Data | HeteroData |
| Decoder | log_softmax | dot product |
| Loss | CrossEntropyLoss | BCEWithLogitsLoss |
| Split 방식 | 수동 node masking | RandomLinkSplit |
| Edge usage 분리 | 불필요 | message passing vs supervision (disjoint) |
| Mini-batching | 불필요 | LinkNeighborLoader 필수 |
| Negative sampling | 불필요 | 필수 (neg_sampling_ratio 지정) |
| Reverse edge | 불필요 | 필수 (T.ToUndirected()) |
| 권장 모델 | SAGE (정밀+균형) | SAGE (F1) / GCN (Recall) |
| 핵심 어려움 | 클래스 불균형 (illicit 2.23%) | edge leakage 방지, 이종 노드 임베딩 설계 |
이 표는 두 태스크가 같은 framework 위에서 어떤 결정점에서 갈라지는지를 한눈에 보여준다. Framework는 같지만 의사결정 지점은 8개 이상 분기한다.
참고 자료
- Knowledge Graphs and LLMs in Action. Manning, 2024 — Chapter Chapter 12 — Node classification and link prediction with GNNs.
