
1. 비정형 데이터에서 KG로: 두 개의 축
이전 챕터까지 다룬 KG는 테이블·관계형 DB·기존 knowledge base 같은 구조화된 데이터를 전제로 했다. 그러나 실무에서 마주하는 도메인 지식 대부분은 논문·보고서·아카이브 문서 같은 비정형 텍스트에 잠겨 있다. 이 챕터의 thesis는 다음과 같다. 비정형 데이터에서 KG를 만드는 작업은 "지식 표현(knowledge representation)"과 "지식 학습(knowledge learning)"이라는 두 축의 결합이며, LLM은 후자의 비용 구조를 근본적으로 바꾼다.
- Knowledge representation: 정보를 컴퓨터와 사람이 모두 자율적으로 접근 가능한 형태로 모델링하는 방법. 분산되고 고립된 정보를 정렬되고 연결된 형태로 만드는 것이 KG의 본질이다.
- Knowledge learning: NLP·LLM 같은 프레임워크와 기술의 조합으로 비정형 문서에서 insight를 채굴하는 과정이다.
전체 파이프라인은 digitization → NER → RE → custom knowledge extraction의 순서로 흐른다.

NER과 RE 단계에 전통적 NLP 모델 또는 LLM이 투입된다. 강조된 두 노드가 이 챕터의 핵심 결정 지점이다.
2. NER과 RE: KG 구축의 최소 단위
2.1 Named Entity Recognition
NER은 raw text에서 named entity의 mention을 식별하고 사전 정의된 카테고리로 분류하는 ML classification system으로 정의된다. 다수의 open source NLP 라이브러리는 Person, Location, Organization 같은 generic 카테고리를 즉시 제공하지만, 실제 도메인 작업에서는 거의 충분하지 않다.
예를 들어 화학 연구 아카이브에서 "Professor of Chemistry"라는 직위, 특정 연구 분야명, 화학 물질명을 식별해야 한다면 generic NER 모델로는 부족하다. 단순한 dictionary 기반 시스템도 도메인 어휘 커버리지가 낮다. 따라서 custom entity-extraction system이 필요하며, 이는 custom NER 모델 학습 또는 LLM 활용 두 경로로 해결된다.
2.2 Relation Extraction
RE는 텍스트 내 entity pair 사이의 semantic relation을 식별하는 작업이다. 다음 문장을 보자.
"Jane Austen, Victorian era writer, is currently employed by Google."
이 문장은 PERSON("Jane Austen")과 ORGANIZATION("Google")이라는 두 named entity를 포함하며, 둘은 employment 관계로 묶인다. 이 relatedness를 포착하는 것이 진짜 KG를 만드는 작업이다. 단순히 entity 목록만 추출하면 그래프가 아니라 리스트일 뿐이다.
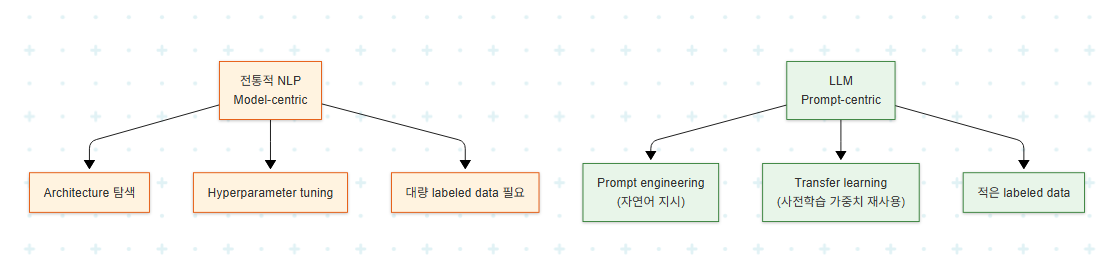
3. 전통적 NLP에서 LLM으로: 패러다임 전환
3.1 모델 중심에서 데이터 중심으로
전통적 NLP는 task-specific training dataset 구축, 최적 model architecture 탐색, hyperparameter fine-tuning 같은 model-centric 접근을 취해왔다. 이 접근의 극단적 형태는 데이터 품질 문제를 무시하는데, faulty data를 넣으면 faulty prediction이 나온다는 단순한 사실을 간과한다.
시간이 지나면서 data-centric paradigm이 주목받기 시작했다. 고복잡도 ML 모델을 학습시키기 위한 데이터의 품질과 양을 개선하는 데이터 엔지니어링이 핵심으로 자리 잡았다.
3.2 LLM의 등장이 바꾼 것
2022년 말 OpenAI의 GPT-3.5 시리즈와 ChatGPT 공개 이후, Transformer 아키텍처 기반 generative model이 NLP 작업의 표준 옵션이 되었다. LLM의 핵심 가치는 다음 두 가지다.
- Transfer learning: 방대한 데이터셋으로 학습된 weight를 재사용하므로, 동일한 정확도를 더 적은 human-labeled data로 달성한다. 모델을 from scratch로 학습할 필요가 없다.
- Prompt engineering으로 충분: 자연어로 task를 기술(prompt engineering)하면 모델이 답을 생성한다. Model engineering이 필요 없다.
3.3 LLM의 한계: hallucination
LLM의 강력함에도 시스템 설계 시 반드시 고려할 한계가 있다. 가장 중요한 것은 hallucination, 즉 학습 데이터에 근거가 없는 경우에도 "사실"을 만들어내고 잘못된 추론을 수행하는 경향이다. 이 때문에 LLM을 KG 구축 도구로 사용할 때는 LLM이 직접 사실을 단정하게 하기보다, 고품질의 named entity·관계·속성을 추출하도록 유도하는 방식이 권장된다.
4. LLM 기반 KG 구축 워크플로우
LLM을 활용한 KG 구축은 prompt-based inference로 즉시 시작하거나, 도메인 특화 정확도를 위해 fine-tuning으로 확장할 수 있다.
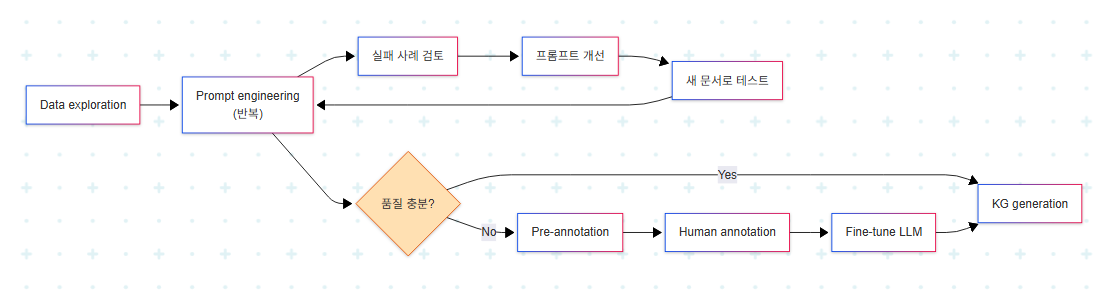
각 단계의 역할은 다음과 같다.
- Data exploration: 도메인의 복잡도와 합리적 기대치를 파악하는 초기 단계. 데이터 이해 없이는 의미 있는 prompt를 작성할 수 없다.
- Prompt engineering: 가장 효과적인 prompt를 찾기 위한 반복 과정. 단어 몇 개를 바꾸는 것만으로도 성능에 큰 차이가 발생한다.
- Pre-annotation + Fine-tuning: prompt-based 접근이 한계에 부딪히면 진입한다. 비용과 시간이 들지만, 도메인에 specialized된 더 안정적이고 정확한 모델을 얻는다.
5. Prompt Engineering의 실제: 세 번의 반복
generic prompt("모든 entity와 관계를 식별하라")만으로 KG를 만들면 다음과 같은 문제가 드러난다.
- 공지칭 해결과 약어 복원의 자연스러운 처리: LLM의 generative 특성 덕분에 coreference resolution이 implicit하게 수행된다. 예를 들어 "Prof. Chem."이나 "Assoc. in Chem." 같은 축약 직위가 "Professor of Chemistry", "Associate in Chemistry"로 복원된다. 전통적 NER 모델이 할 수 없는 작업이다.
- 과도한 관계 세분화: specializes in, is measuring, is interested in, demonstrates처럼 모두 정확하지만 KG 관점에서 같은 개념을 표현하는 관계들이 분리된다.
- 비일관된 노드 라벨: 같은 단락의 네 가지 연구 주제에 field, research, theory 세 가지 다른 라벨이 부여된다.
- 예측 불안정성: 동일한 prompt를 동일 텍스트에 반복 실행해도 결과가 달라진다.
이러한 문제는 prompt를 점진적으로 정교화하면서 해결된다.
| 버전 | 전략 | 결과 |
|---|---|---|
| v1: 일반 지시 | "모든 entity와 관계를 식별하라" | 공지칭/약어 처리는 우수, 라벨 비일관·과도 세분화·불안정 |
| v2: 목록 추가 | entity class 목록과 relation type 목록을 prompt에 포함, 성능이 낮은 관계 유형에 설명 추가, 도메인 노트 2개 추가 (이니셜로 사람을 지칭하는 관행, 대학·학과명 별칭) | 정규화 향상, 일부 안정성 확보 |
| v3: 풍부한 예시 | 예시를 확장해 명확한 가이드라인 제공 | entity·relation class 부여의 높은 안정성, 관심 관계 모두 정확히 식별 |
세 번째 버전에서 원하는 모든 결과를 달성한다. 핵심 교훈은 모델 자체의 선택보다 근본 원리, 즉 task 명확성·도메인 노트·다양한 예시가 더 결정적이라는 점이다. 이 챕터의 prompt는 ChatGPT 계열 모델용으로 설계되어 GPT-4o mini에서 테스트되었으나, 새로운 모델이 등장해도 동일한 원칙이 적용된다.
Prompt 설계 일반 원칙
| 원칙 | 설명 |
|---|---|
| Task description | 모호성을 제거할 만큼 정확하게 task를 기술. 모델이 답을 "지나치게 창의적으로" 만들 여지를 줄임 |
| Naming entity/relation classes | 관심 있는 entity·relation class 목록을 prompt에 포함. 작업을 명료화하고 정규화된 출력 유도 |
| Complex representative examples | 입력과 기대 출력 예시를 prompt에 포함. 실제 텍스트의 압축본에 중요한 entity·relation을 담는 형태 |
| LLM configuration | temperature는 낮을수록 deterministic, 높을수록 variation·hallucination 증가 |
| Prediction stability | LLM은 generative이므로 동일 prompt에서도 결과가 다를 수 있음. 모호하지 않은 prompt + 낮은 temperature로 통제 |
| Unit-testing | prompt 업데이트마다 텍스트와 기대 출력을 테스트 리스트에 추가. 주기적으로 일괄 실행해 성공률 측정 |
| Eyeballing a mini-KG | prompt milestone마다 수십 페이지 분량으로 KG를 만들어 직접 탐색. 정성적 검증 단계 |
| Evaluation | 만족스러운 prompt에 도달하면 정량 평가. QA 담당자가 correct/incorrect/missing으로 라벨링 |
6. 전통적 NLP vs LLM: 선택의 기준
LLM이 모든 상황에서 우월한 것은 아니다. 도메인·비용·운영 제약에 따라 선택이 달라진다.
| 기준 | 전통적 NLP | LLM |
|---|---|---|
| 예측 속도 | 빠름 (CPU 가능) | 느림 (GPU 필수) |
| 인프라 비용 | 단순·저렴 | 복잡·고비용 |
| 예측 단위 비용 | 매우 낮음 | 데이터셋 규모에 따라 가변 |
| 보안·on-premise | 격리 배포 용이 | GPU cluster 자체 운영 부담 |
| 초기 도메인 커스터마이징 | 높은 초기 투자 (전문 인력, annotation) | Prompt engineering으로 빠른 진입 |
| 학습 곡선 | 가파름 (data scientist 필수) | 완만 (최소 기술로 prompt engineering 가능) |
| 파이프라인 | NER · RE · coreference · entity resolution 등 다단계 체이닝 | One-pass 처리 |
| 출력 품질 | 후처리 (cleansing, normalization) 필요량 많음 | 생성적 특성으로 후처리 부담 적음 |
| Fine-tuning 비용 | 해당 없음 (모델별 학습) | prompt로 부족할 때 추가 비용 발생 (OpenAI 기준 custom 모델 추론은 약 10배) |
선택은 이분법적이지 않다. 두 접근은 공존 가능하며, LLM을 활용해 전통적 NLP 모델 학습용 데이터를 빠르게 pre-annotation하는 하이브리드 전략도 유효하다.
7. 한계와 트레이드오프
LLM 기반 KG 구축이 실무에서 직면하는 한계는 다음 세 가지로 정리된다.
- Hallucination 리스크: LLM이 근거 없는 entity나 관계를 생성할 수 있다. KG는 downstream 추론에 사용되므로, 잘못된 사실 하나가 multi-hop traversal을 통해 확산될 위험이 있다. 따라서 LLM 출력을 그대로 신뢰하기보다 high-quality entity·relation·property 추출에 활용하고, 사실 단정은 원본 문서나 신뢰 가능한 source로 우회하는 설계가 안전하다.
- 출력 안정성과 정규화 비용의 trade-off: temperature를 낮추면 안정성은 확보되지만, 미묘한 도메인 변형에 대한 적응력이 떨어진다. 반대로 prompt를 정교화해 entity/relation class를 강하게 명시하면 안정성은 높아지나 prompt 자체가 길어져 token 비용과 유지보수 부담이 늘어난다. 제3의 옵션인 fine-tuning은 이 trade-off를 우회하지만 초기 비용을 다시 부과한다.
- 대규모 데이터셋에서의 비용 역전: 소~중규모 데이터셋에서는 LLM이 전통적 NLP 파이프라인 대비 초기 투자가 적어 유리하지만, 데이터 규모가 커질수록 GPU 추론 비용이 누적되어 경제성이 역전될 수 있다. streaming 시나리오나 실시간 추론 요구가 있는 환경에서는 더욱 그렇다.
8. 실무 적용 시 고려사항
LLM으로 KG를 구축할 때 production 단계에서 자주 간과되는 지점이 있다. 첫째, prompt engineering은 코드와 동일하게 버전 관리되어야 한다. 단어 하나의 변경이 출력 품질에 비대칭적 영향을 미치므로, prompt와 기대 출력을 unit test 형태로 묶고 회귀 테스트를 자동화하는 것이 안전하다. 둘째, eyeballing a mini-KG 단계를 생략하지 않아야 한다. 정량 지표만으로는 잡히지 않는 노드 라벨 비일관성·관계 세분화 문제가 그래프 시각화에서 즉시 드러난다. KG는 결국 그래프로 사용되므로, 그래프 형태로 점검하지 않으면 downstream에서야 문제가 발견된다.
셋째, 보안 요구가 강한 도메인이라면 LLM 직접 사용 대신 LLM을 데이터 어노테이션 가속기로 활용하는 우회 경로를 검토한다. LLM으로 pre-annotation한 데이터를 사람이 검수해 전통적 NLP 모델 학습에 사용하면, on-premise 배포 가능한 모델과 LLM의 transfer learning 이점을 동시에 얻을 수 있다. Hyperscaler(AWS, Azure, GCP)를 통한 LLM 호출이 가능한 환경이라면 일부 인프라 부담이 완화된다.
결론: 비정형 텍스트에서 KG를 구축하는 작업의 본질은 모델 선택이 아니라 task 정의의 명확성이다. LLM은 진입 비용을 낮췄지만, 도메인 클래스 목록·정밀한 task 기술·대표 예시라는 세 축은 여전히 사람의 몫으로 남는다.
참고 자료
- Knowledge Graphs and LLMs in Action. Manning, 2024 —
Chapter 5: Extracting domain-specific knowledge from unstructured data
