9.1 인식이란
1) 인식의 세부 문제
컴퓨터 비전은 인식 문제를 분류,검출,분할,추적,행동 분류의 세부 문제로 구분한다
-
분류 : 물체의 부류 정보를 알아내는 문제
- 사례 분류: 특정한 물체를 알아낸다
- 범주 분류: 물체 부류를 알아낸다
- 미리 정해진 물체 부류에 대해 부류 확률 벡터 출력
-
검출: 영상에서 물체를 찾아 바운딩 박스로 위치 표현하고 신뢰도 같이 출력
-
분할 : 화소 집합 지정, 신뢰도 같이 출력
- 의미 분할: 화소 각각에 대해 물체 부류 지정
- 사례 분할: 같은 부류에 속하는 물체가 여러 개면 서로 다른 번호 부여
-
추적 : 영상에 나타난 물체의 이동 궤적을 표시하는 문제
- 시각 물체 추적: 첫 프레임에서 지정한 물체
- 다중 추적: 여러 물체를 모두 추적
-
행동 분류: 물체가 수행하는 행동의 종류 알아내는 문제
2) 데이터셋
- PASCAL
- ImageNet
- COCO 데이터셋
- Open Image
- 특정분야 거냥: Deep Fashion/Food-101/CheXpert
- 대회는 공정하게 한다…
- 영상 레이블링
- 많은 노동력 필요
- 분류는 부류만 지정 but 검출은 물체 위치까지 지정해야 된당
- 많은 노동력 필요

---3) 사람 vs 컴퓨터 인식 과정
- 사람
- 검출 따로 수행 안하고 바로 분할 수행(동시)
- 의도에 따라 선택적 집중 발휘
- 문맥 이용 능숙
- 컴퓨터
- 인식 나누고 독립적으로 해결
- 목적이 의도 대신
- 자율적으로 선택적 주의집중 할 수 없음
9.2 분류
1) 고전적인 방법( 현대적 해법은 7장,8장 공부하삼)
-
사례 분류: 모양과 텍스처가 고정된 물체
- ex) 표지판 인식 →
-
범주 분류: 모양이 변하는 물체까지 포함해서 일반 부류에 속하는 물체 알아내는 문제
- 두발 자전거, 세발 자전거, 누워 있는 코끼리, 걷는 코끼리
\
2) 딥러닝 방법
- 범주 분류에 집중
- 부류가 적은 범주 분류 대회에서 고전적인 방법이 좋았지만 부류가 늘어나면서 컨볼루션 신경망이 주류 이룸
- 미세 분류: EX) 개, 새 품종 알아내는 문제
- 부류 내 변환, 부류 간 변환
- 딥러닝 성능 좋지만 분류 결과에 대한 이유 설명 못한다 이를 위해 CAM,GradCAM 등장
- CAM: 모델이 어떤 곳을 보고 어떤 클래스임을 짐작하고 있는지 확인할 수 있는 지도
- 단점: 마지막 convolution layer를 통과해 나온 feature map에 대해서만 CAM을 통해 Heat map 추출이 가능함

- GradCAM: CAM의 한계 극복해 다양한 신경망 구조에 적용 가능
- 적대적 공격
- 영상을 조작하여 모델 속여서 원하는 부류로 분류하게 만들 수 있다
- 나쁜 목적으로 이용되면 위험하다!
- 이에 대응하기 위한 방어 전략 연구되고 있다.9.3 검출
1) 성능 척도
- mAP로 측정
- 각 class 별 AP의 평균을 나타낸 값
- AP
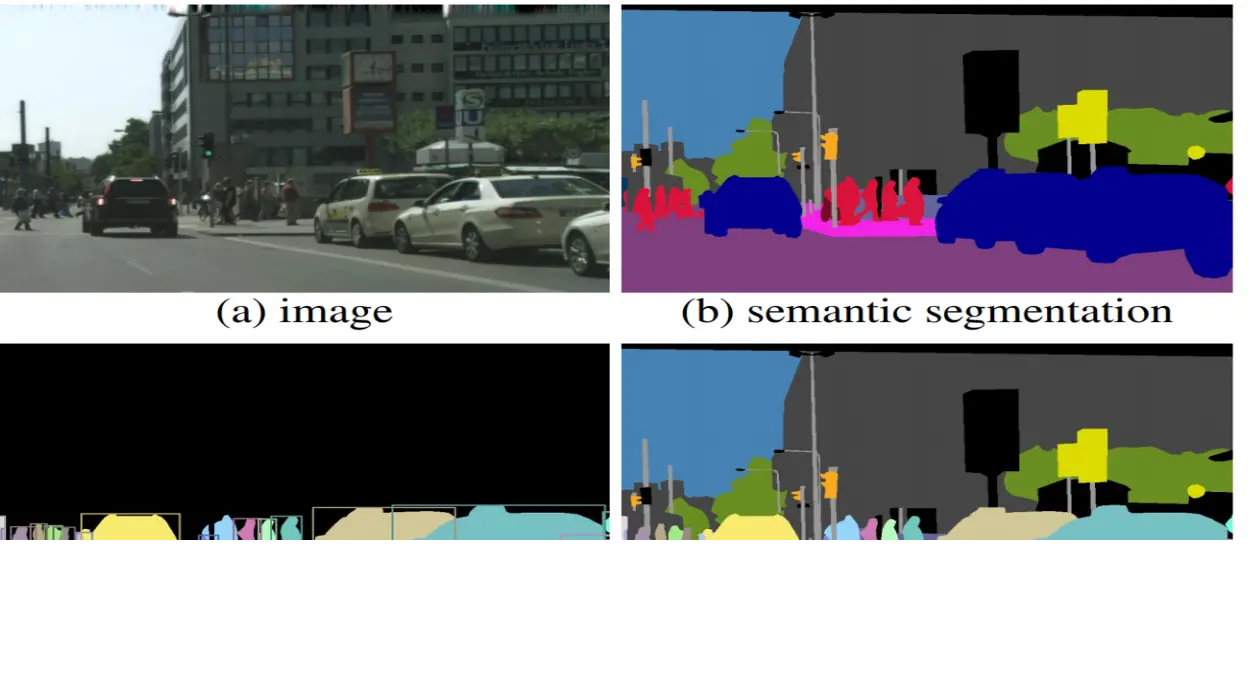
- IoU기반 계산
- IoU기반 계산
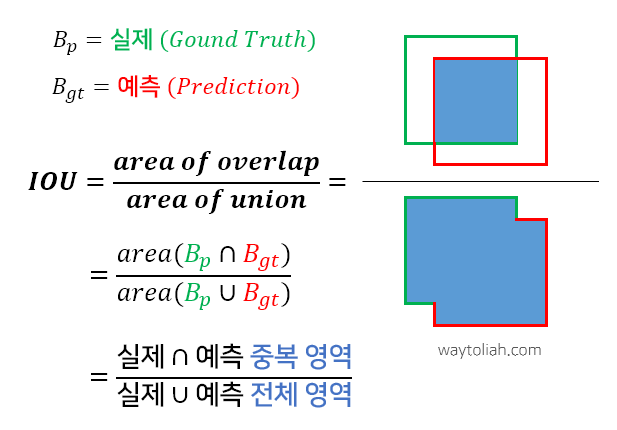

- EX) 합집합 면적 70화소, 교집합 면적이 30화소 ⇒ IoU= 30/70= 0.4286
- 신뢰도 임게값 , IoU 임게값 설정
- AP알고리즘
-
2) 고전 방법
-
초기 연구는 사람에 국한 → 점점 확장
-
검출은 물체의 위치를 찾는 일과 부류 알아내는 일 같이 해결
-
가능성 있어 보이는 후보 영역 많이 생성 → 후보 영역을 분류 알고리즘으로 걸러내기
-
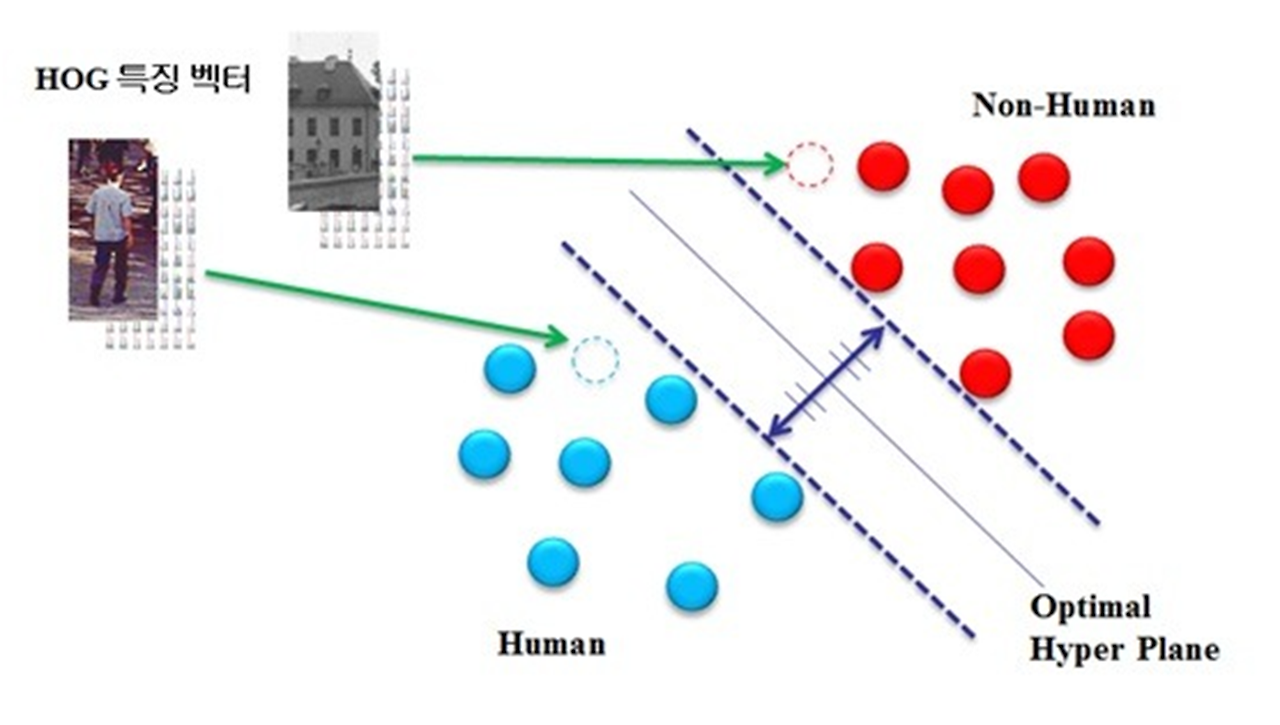
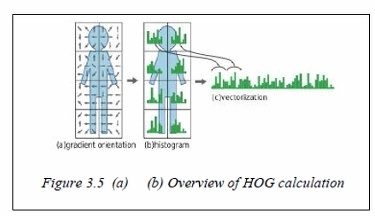
HOG 특징: (계산하는 법 공부하고 싶으면 4장을 보세용 p122)
- 방향에 따른 gradient 값의 히스토그램으로 표현
- SVM은 HOG특징 분류해서 사람일 확률 출력
- 후보 영역 생성할 때는 **슬라이딩 윈도우** 방법 활용
• Windows를 왼쪽 상단에서 오른쪽 하단까지 이동시키면서 detect하는 방식
고전의 검출방식
물체의 위치와 부류를 알아내는 일을 같이 해결해야함. → 가능성이 있어 보이는 후보 영역을 많이 생성한 후 후보 영역을 분류 알고리즘으로 걸러내곤했다. (Viola 알고리즘이 얼굴검출로 유명함)
Viola는 HOG 특징을 추출하는 과정을 쓰는데,
후보영역을 128X64로 만들고 16X8개의 타일 만든 후 그레이디언트 방향을 계산해 9개 구간으로 양자화한다. 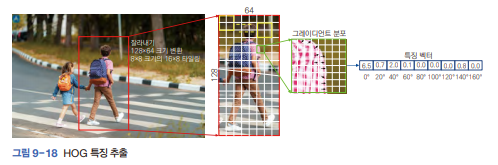
**DPM**
- 부품 이용해 물체 모델링
- 바운딩 박스에 있는 feature가 사람이 갖고 있는 특징 포함하고 있다고 판단하면 사람으로 detection한다
3) RCNN 계열 (논문 스터디 했던 거 보기 )
-
R CNN
- 영역 제안과 영역 분류 2단계
- 선택적 탐색으로 후보 영역 생성
- 생성된 영역을 227x227 크기로 정규화하고 conv layer로 특징 벡터 추출
- SVM으로 특징 벡터 분류해서 물체 부류 알아낸다
- 영역마다 독립적으로 분류 수행헤서 속도 느리다
-
FAST R CNN
- 선택적 탐색 이용
- 영역 분류는 SVM 대신 신경망 이용
- ROI투영 : conv 측징 맵에서 후보 영역 해당하는 곳 ROI로 지정
- ROI 특징 벡터 추출
- 회귀→ 부류별 박스 정보 /분류→ 부류 확률 벡터
- 영역 제안 단계에서 선택적 알고리즘 사용→ 실시간 처리 방해
-
FASTER R CNN
- 영역 제안을 RPN이라는 신경망이 한다
- 사전 학습된 VGG16으로 H x W 크기의 특징 맵 추출
- 특징 맵에 1 x1 컨볼루션 적용해서 앵커 생성
- 앵커를 후보영역으로 간주하고 Fast RCNN으로 입력
4) YOLO 계열
- RCNN 계열 보다 정확도는 떨이지지만 속도는 짱 빠르다
- 물체 위치와 부류 정보를 한꺼번에 알아내는 ONE STAGE 방식
- RCNN 계열 보다 단순하다
- 컨볼루션 24, MAX컨볼루션 4개 , 완전연결층 2개로 구설
- YOLO v1은 작은 물체 놓치는 경우 많았음
- YOLO v3은 여러 스케일 표현해서 다양한 크기의 물체 검출하는능력이 향상됨
9.4 분할
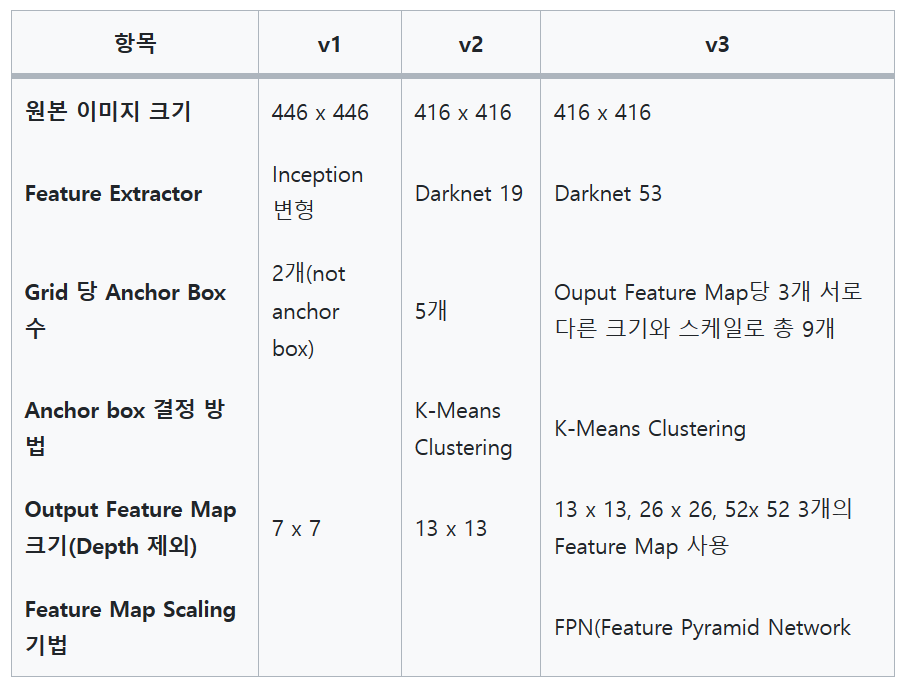
딥러닝 이용한 영상 분할
- 물체
- 셀 수 있는 물체( thing)/ 셀 수 없느 물체 (stuff)
- 의미 분할
- 모든 화소에 thing,stuff 물체 부류 할당
- 같은 부류의 thing 물체가 여러 개인 경우 구분하지 않고 같은 번호 할당
- 사례 분할
- thing만 분할
- 같은 부류의 물체가 여러 개면 고유한 번호 할당해서 구분
- 총괄 분할
- 모든 화소에 thing,stuff 물체 부류 할당
- thing 물체에는 고유번호까지 할당
1) 성능 척도와 데이터셋
- 분류: 영상에 대해 하나의 부류 확률 벡터 출력
- 분할: 화소별로 부류를 지정 ⇒ 밀집분류라고도 함
-
PA:
맞힌 화소 수 / 전체 화소 수
-
MPA:
부류별로 PA 계산하고 평균낸 거
-
IoU
-
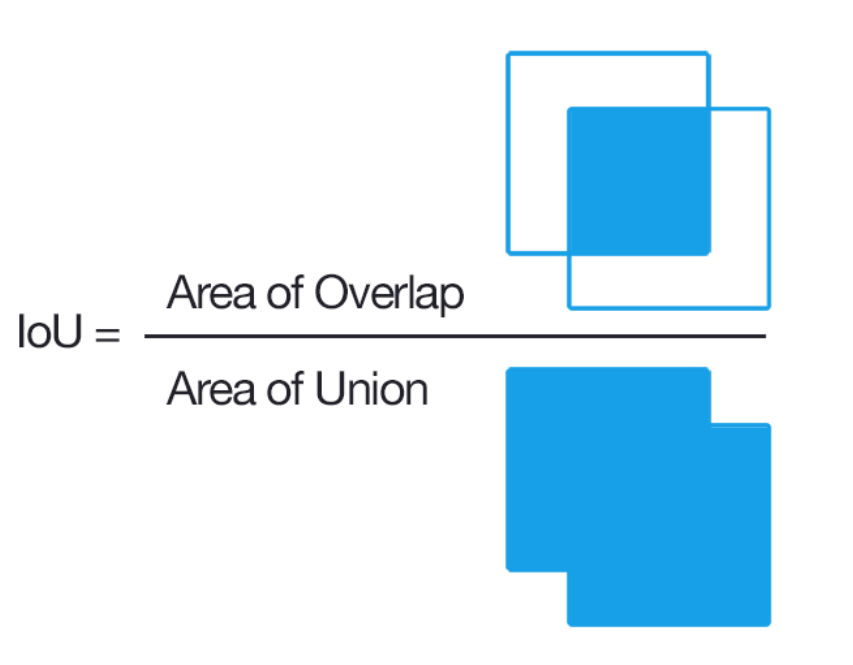
- Dice: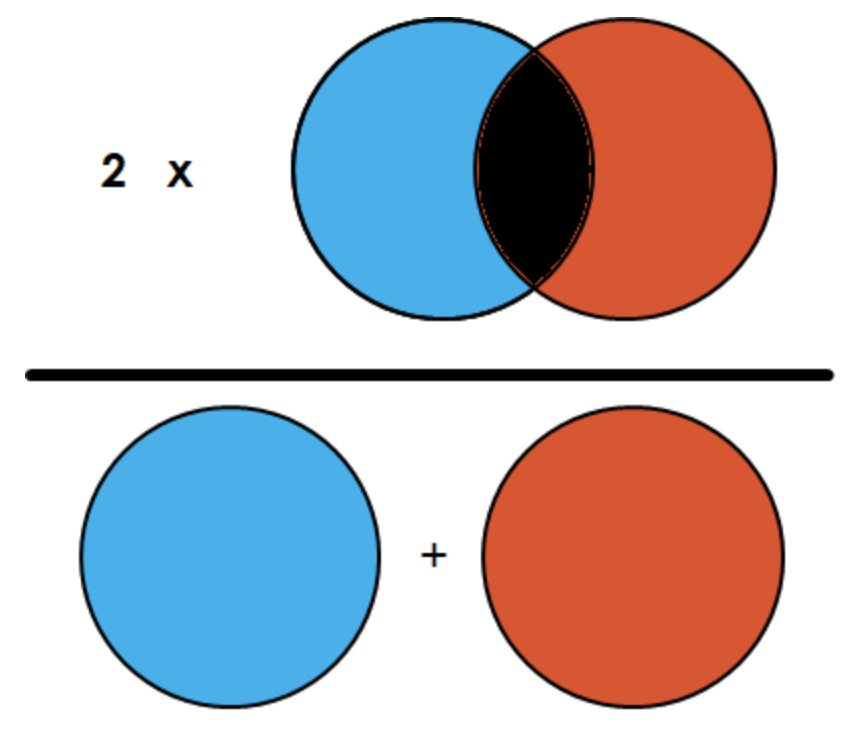
- 데이터셋
- 분할 위한 레아블 포함하고 있는 데이터셋 (PASCAL VOC ,ImageNet ,COCO, OpenImage)..
- 특수목적 데이터셋( 도로 분할,유튜브 비디오 분할, 자율주행..)
2) 의미 분할을 위한 FCN
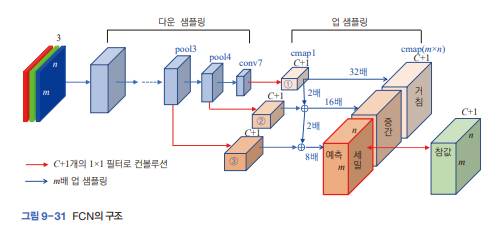
- FCN의 구조와 동작
- 기존 CNN에서 완전 연결층 제거하고 컨볼루션층과 풀링층으로만 구성
- 이미지 크기: m xn , 부류 개수 : C
- 입력: m x n x 3 (rgb)
- 출력: m x n (C+1) : 배경 더해줌
- 참값도 예측 첸서와 동일하게 m x n (C+1)로 표현
- 예측텐서와 참값 텐서의 차이를 줄이는 방향으로 가중치 갱신
- 업 샘플링ㅜㅜ
- 양선형 보간법(고전)
- FCN은 전치 컬볼루션으로 업 샘플링
- m x m 특징 맵을 h x h 필터로 컨볼루션하여 m’ x m’ 특징 맵을 출력
- m’ = (m+2q-h)/s +1
- m으로 복원 : (m’-1)s-2q+h
- 전치 컨볼루션은 맵의 크기를 복원하지만 값을 복원하지는 않는다
- 앞쪽의 특징 맵: 세밀함은 좋지만 전역 정보 부족
- 뒤쪽의 특징 맵: 전역정보 갖지만 세밀함 부족
3) FCN 개선한 신경망
- FCN은 사람이 개입해서 업 샘플링 과정 설계했기 때문에 구조 복잡하고 어색
- DeConvNet: 오토인코더와 FCN 결합한 구조
- 대칭 구조의 표준 오토인코더를 사용해서 신경망 구조와 학습이 세련되고 성능도 우월
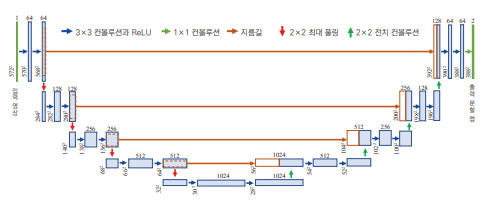
- U-Net:
- 의료 영상 분할 목적으로 개발됨
- 다운 샘플링과 업 샘플링을 축소 경로, 확대 경로라고 부른다
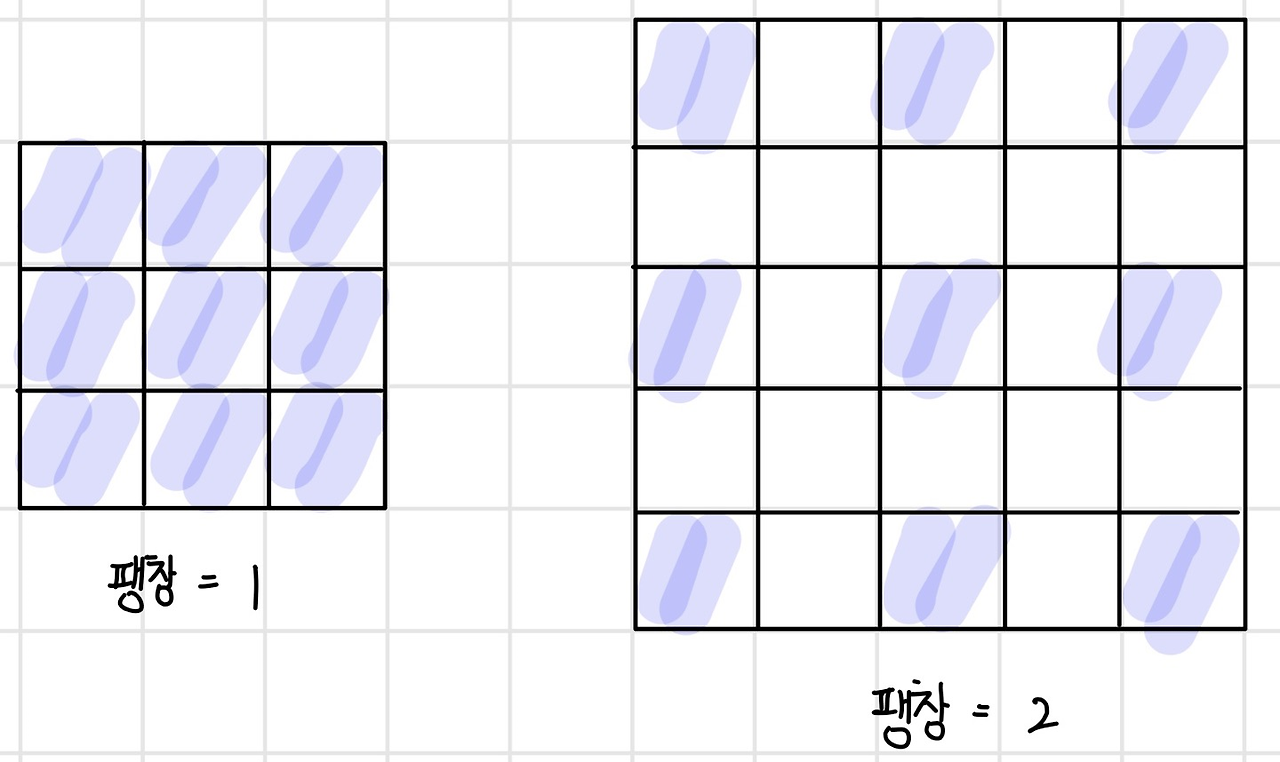
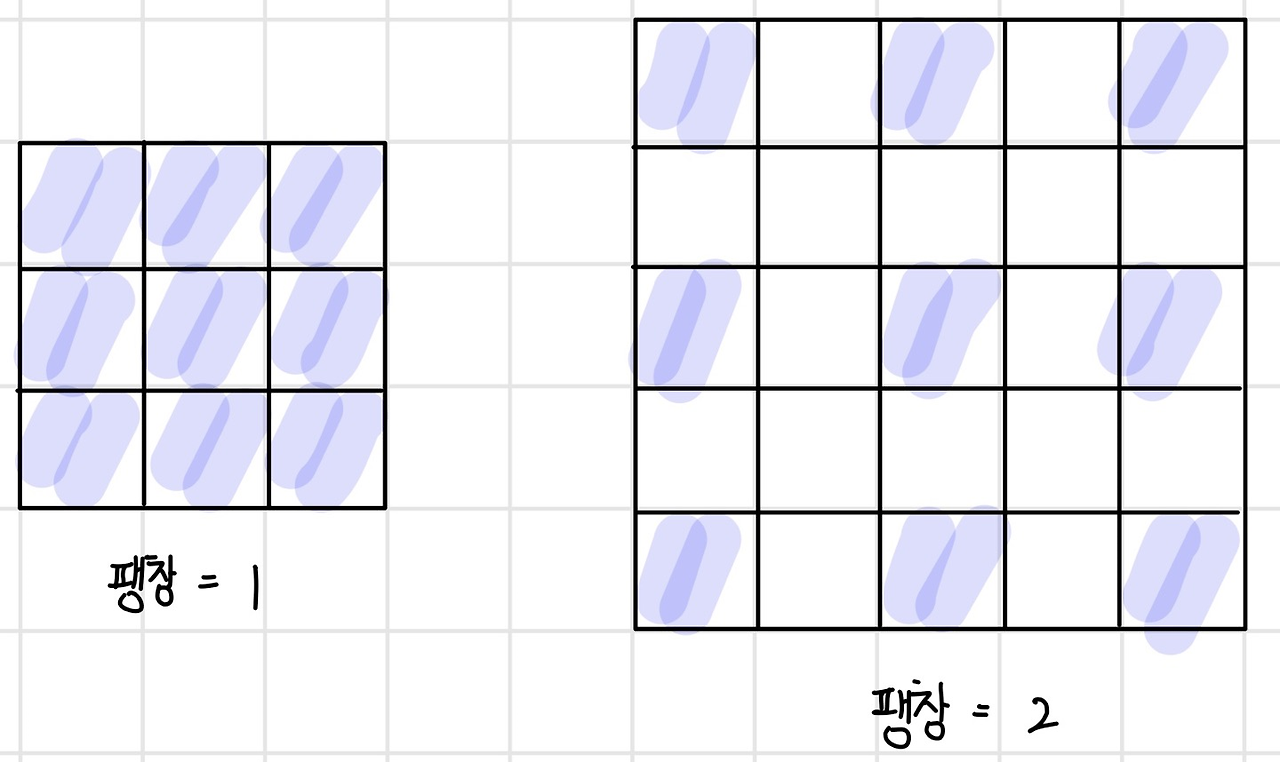
- DeepLabv3+:
- 기존 FCN이 영상 너무 축소해서 상세 내용 잃어버릴 수 있다
- 팽창 컨볼루션 도입
- 측징 맵의 해상도 유지된다
9.6 사람 인식
생체인식: 사람의 생리학적 도는 행동학적 특성을 측정하고 유용한 응용한 응용에 활용하는 분야
- 컴퓨터 비전 이용은 형광펜*
- 생리학적: 얼굴,지문,손금, 홍채
- 행동학적: 음성,서명,걸음걸이,타자
얼굴 인식
-
고유 얼굴기법 : 주성분 분석→ 매칭 알고리즘 → 얼굴 인식 수행
-
얼굴 인식은 단순히 분류 알고리즘X . 제로샷 학습에 해당함
-
특징 추출 + 매칭 단계로 해결
-
얼굴 확인: 두 장의 얼굴 영상이 입력되면 동일인인지 확인하는 문제
- 신분증 검사.. 대조하는 검사
-
얼굴 식별: 입력 영상을 등록된 얼굴 영상과 매칭하여 누구인지 알아내는 문제
-
매칭 알고리즘: 두 영상의 유사도 계산
- 얼굴 확인) 유사도가 임계치 넘으면 동일인으로 판정
- 얼굴 식별) 유사도가 가장 큰 부류로 분류
-
특징 추출
- 사전 학습된 컨볼루션 신경망을 백본을 사용 전이 학습
- 사람 얼굴은 미세 분류에 해당
- 사람은 눈,코,입 배열 일정
- 기본 전략: 같은 부류에 속하는 얼굴 영상 유사도 높게, 다른 부류는 유사도 낮게 유지
- 사람은 눈,코,입 배열 일정
-
얼굴 검출: 알고리즘으로 얼굴 영역 오려낸다
-
얼굴 정렬: 눈, 코,입,귀 등의 위치 알아낸다
얼굴영상 생성 방법
- 일대다 증강: 사진 하나를 다양한 방향으로 변환 (1→n)
- 다대일 정규화: 여러 방향 영상을 한 장의 표준 영상으로( n→1)
성별과 나이 추정
- 성별과 나이 추정 데이터 셋
- MORPH II : 나이 16~77세 사람 얼굴 영상 55134장
- 나이 들면서 찍은 영상 있어서 나이에 따른 변화 분석하는데 활용 가능
- IMDB-WIKI :연예인 사진,(성별,나이) 50만장
- AFAD: 아시아인 얼굴 여상 (성별,나이) 16만장
- UTKface: 0~116세 23708장( 나이,성별,인종)
- MORPH II : 나이 16~77세 사람 얼굴 영상 55134장
나이
-
나이 추정은 분류보다는 회귀 알고리즘으로 해결
-
나이 추정 초기
- 컨볼루션층 3개와 완전연결층 2개 연결한 간단한 구조 사용
- 출력층에 softmax 활성함수 사용
- softmax 함수는 input값을 [0,1] 사이의 값으로 모두 정규화하여 출력하며, 출력값들의 총합은 항상 1이 되는 특성을 가진 함수이다.
- 다중분류(multi-class classification) 문제에서 사용한다
- 나이 추정을 분류 문제로 해결함
-
초기 이후
- 순서형 회귀 문제로 취급
- 이진 분류기 여러 개 만들었다
- 나이 범위 초기 추정 → 정제 → 새로운 범위 설정→ 다시 정제 : 반복
-
나이 추정 성능 측정 척도
-
평균 절댓값 오차 (MAE) : 예측값과 참값의 절댓값 차이를 평균
-
누적 점수 (CS): 예측값과 참값의 절댓값 차이가 오류 포용값 이하면 맞혔다고 간주하는 정확률
성별
-
명확한 분류 문제
-
성별 인식은 단순한 이진 분류라서 다른 거랑 같이 수행하는 경우 많다
-
