단일 출처 그래프는 정보를 저장하지만, 다중 소스 통합 KG는 정보를 연결한다.
1. 챕터의 위치와 thesis
이전까지의 논의가 단일 도메인·단일 출처에서 knowledge graph(KG)를 구축하는 방법에 머물렀다면, 이 챕터는 이질적인 데이터셋을 하나의 동질 그래프(homogeneous graph)로 통합하고, 그 위에서 LLM 기반 intelligent advisor system(IAS)을 운용하기 위한 분석 기법을 다룬다. 핵심 thesis는 다음과 같다. 다중 소스 KG의 가치는 그래프를 키우는 데 있지 않고, 서로 다른 출처의 entity와 relationship을 일관된 의미 단위로 정렬(align)하는 데 있다.
이전 편에서 vector retrieval이 chunk 간 유사도에 머무는 한계를 보였다면, multisource KG는 출처 간 cross-reference를 명시적 edge로 보존한다는 점에서 본질적으로 다르다. 즉, retrieval의 단위가 "비슷한 텍스트"에서 "검증된 관계"로 옮겨간다.
2. 다중 소스 통합 파이프라인
구조화·반구조화 데이터를 하나의 그래프로 합치는 과정은 단순 merge가 아니라 다단계 파이프라인이다. 이 파이프라인의 각 단계는 직렬로 의존하므로, 어느 한 단계의 품질 저하가 후속 분석 전체로 전파된다.

각 단계의 역할은 다음과 같이 정리된다.
| 단계 | 입력 | 핵심 작업 | 실패 시 영향 |
|---|---|---|---|
| Schema alignment | 이질적 스키마 | 속성·타입·관계 명명 일치화 | 동일 개념이 별도 노드로 분리 |
| Entity resolution | 정렬된 레코드 | 동일 실체 식별·식별자 매칭 | 중복 entity, 단절된 subgraph |
| Quality validation | 병합 후보 | 결측·충돌·일관성 검증 | 잘못된 edge가 분석 결과 왜곡 |
| Post-processing | 검증 통과 그래프 | entity/relationship 병합 | 그래프 밀도·지표 신뢰도 저하 |
entity resolution은 단순 문자열 매칭을 넘어 식별자(identifier) 수준의 reconciliation을 요구한다. 같은 단백질이 데이터셋마다 다른 ID로 등록되어 있는 경우, ID 매핑 테이블 없이는 두 노드가 별개로 남는다.
3. 분석 기법: 클러스터링과 subgraph 지표
통합된 KG의 품질은 시각 점검만으로 판단되지 않는다. 정량적 분석 지표가 그래프의 구조와 완성도를 평가하는 도구가 된다.
3.1 클러스터링 알고리즘
전역 구조와 커뮤니티 조직을 파악하기 위해 두 가지 알고리즘이 사용된다.
| 알고리즘 | 목적 | 산출물 | 해석 |
|---|---|---|---|
| Weakly Connected Components (WCC) | 연결 컴포넌트 식별 | 분리된 subgraph 집합 | 통합 누락·고립 영역 탐지 |
| Louvain | 모듈성 기반 community detection | 밀집 군집 분할 | 도메인 내 기능 그룹화 발견 |
WCC는 "그래프가 얼마나 연결되어 있는가"라는 거시적 질문에, Louvain은 "연결된 그래프 내부에 어떤 응집 구조가 있는가"라는 미시적 질문에 답한다. 두 결과는 상호보완적이며, 다중 소스 통합의 성공 여부를 판단하는 1차 지표 역할을 한다.
3.2 Subgraph 품질 지표
def evaluate_subgraph(G, subgraph_nodes):
sub = G.subgraph(subgraph_nodes)
n = sub.number_of_nodes()
m = sub.number_of_edges()
# density: 밀도
density = (2 * m) / (n * (n - 1)) if n > 1 else 0
# conductance: 외부와의 연결 비율
boundary_edges = sum(
1 for u, v in G.edges()
if (u in subgraph_nodes) ^ (v in subgraph_nodes)
)
internal_edges = m
conductance = boundary_edges / (2 * internal_edges + boundary_edges) \
if (internal_edges + boundary_edges) > 0 else 0
# 최대 연결 컴포넌트의 상대 크기
largest_cc = max(nx.connected_components(sub), key=len, default=set())
relative_lcc = len(largest_cc) / n if n > 0 else 0
return density, conductance, relative_lcc- density: subgraph 내부 연결의 조밀함. 너무 낮으면 entity resolution 누락 가능성을 시사한다.
- conductance: subgraph가 외부와 얼마나 연결되어 있는지. 낮을수록 자기 완결적 community다.
- largest connected component의 상대 크기: 1에 가까울수록 단일 거대 연결 구조. 이 값이 작으면 그래프가 파편화되어 있다.
3.3 경로 기반 고급 지표: DWPC
Degree-Weighted Path Count(DWPC)는 단순 경로 개수 계산의 한계를 보완한다. 단순 path counting은 hub 노드(연결이 매우 많은 노드)를 거치는 경로를 과대평가한다. DWPC는 경로상의 각 노드 degree에 가중치를 부여해 hub 효과를 감쇠시킨다.
def dwpc(paths, degrees, w=0.4):
# w: damping exponent. 일반적으로 0.3~0.5
score = 0.0
for path in paths:
path_weight = 1.0
for node in path[1:-1]: # 중간 노드만 가중
path_weight *= degrees[node] ** (-w)
score += path_weight
return scorew 값이 클수록 hub 페널티가 강해진다. 이 지표는 entity 간 관련성(relevance)을 평가할 때 단순 도달 가능성보다 훨씬 풍부한 신호를 제공한다.
4. 대표 KG 사례
다중 소스 통합 기법의 실증 사례로 다음 KG들이 testbed 역할을 한다.
| KG | 도메인 | 통합 출처 성격 |
|---|---|---|
| Hetionet | 생의학 (질병·약물·유전자) | 29개 공개 데이터베이스 통합 |
| PPI network | 단백질 상호작용 | 실험·문헌 기반 상호작용 |
| Clinical Knowledge Graph (CKG) | 임상·프로테오믹스 | 환자 데이터·문헌·온톨로지 |
이들 KG는 entity resolution, schema alignment, 분석 지표 적용을 모두 요구하는 복잡도를 가지므로 통합 기법의 검증 대상으로 적합하다.
5. LLM 기반 결과 해석
KG 분석은 정량 지표를 산출하지만, 그 자체로는 도메인 의미가 뚜렷하지 않다. density 0.12, conductance 0.31 같은 숫자가 어떤 임상적·연구적 함의를 갖는지는 별도의 해석 단계가 필요하다.
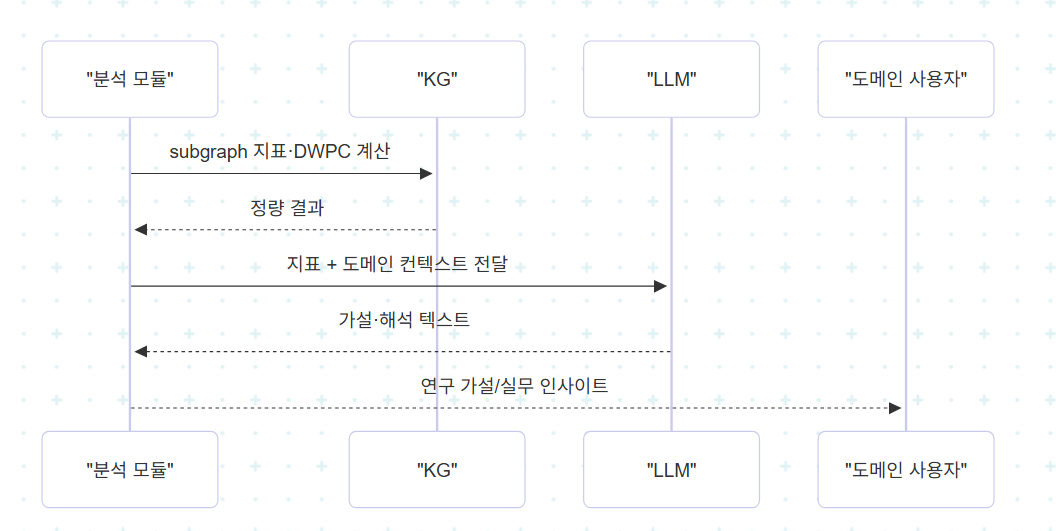
LLM은 이 단계에서 정량 지표를 도메인 가설로 번역하는 역할을 한다. "이 community는 평균 대비 density가 높고 특정 단백질 cluster를 공유한다"는 분석 결과를 "공통 신호 경로의 후보군"이라는 연구 가설로 변환하는 식이다.
6. 한계와 트레이드오프
다중 소스 통합 KG는 표현력 측면에서 강력하지만, 다음 한계가 따른다.
-
Entity resolution의 정확도 천장: 동일 실체를 식별하는 작업은 본질적으로 휴리스틱·확률적 추론에 의존한다. 식별자가 없는 경우 문자열·맥락 기반 매칭이 사용되며, false merge(다른 실체를 합치는 오류)와 false split(같은 실체를 분리하는 오류)이 동시에 발생한다. 두 오류는 trade-off 관계에 있어 한쪽을 줄이면 다른 쪽이 늘어난다.
-
지표의 도메인 의존성: density·conductance·DWPC 같은 지표는 그래프 구조의 통계적 속성일 뿐, 도메인 의미를 보장하지 않는다. 같은 density 값이 임상 KG와 소셜 네트워크에서 전혀 다른 의미를 갖는다. 지표 임계값을 일반화하려는 시도는 실패하기 쉽다.
-
확장성 비용: 출처가 늘어날수록 schema alignment·entity resolution의 조합 폭발이 발생한다. n개 출처 통합 시 매핑 작업은 단순히 n에 비례하지 않고, 출처 간 페어와이즈 충돌 해소를 포함하면 빠르게 가중된다. 또한 후처리 병합 단계의 재계산 비용이 그래프 크기에 비선형적으로 증가한다.
7. 실무 적용 시 고려사항
실제 시스템에서 다중 소스 KG를 운용할 때 가장 먼저 결정해야 할 것은 entity resolution의 신뢰 임계값이다. 자동 병합 임계를 높게 잡으면 분리된 중복 entity가 남고, 낮게 잡으면 의미가 다른 노드가 합쳐져 분석 결과를 오염시킨다. 도메인 전문가의 검증 루프를 단계적으로 삽입하는 hybrid 방식이 안정적이다.
또한 KG는 일회성 산출물이 아니라 유지보수 대상이다. 출처 데이터의 스키마 변경, 신규 출처 추가, 기존 매핑 규칙의 수정이 누적되면서 그래프 일관성이 흔들린다. WCC·Louvain 결과를 정기적으로 비교해 구조적 drift를 감지하는 모니터링 체계가 필요하다. LLM 기반 해석 모듈을 운용할 경우, 정량 지표와 도메인 어휘 사이의 매핑 규칙을 명시적으로 두지 않으면 해석이 hallucination에 취약해진다.
결론: 다중 소스 KG의 품질은 그래프 크기가 아니라 entity resolution과 정량 지표 검증 루프의 정밀도로 결정된다.
참고 자료
- Knowledge Graphs and LLMs in Action. Manning, 2024 — Chapter 4: From simple networks to multisource integration
