10.1 모션 분석
- 비디오를 구성하는 영상 한 장 = 프레임(2차원)
- 비디오는 시간 축이 추가되어 3차원 시공간 . 컬러영상은 채널이세장이므로 mXnx3 텐서이고 T장의 프레임을 담은 비디오는mXDX3XT의4차원 구조텐서
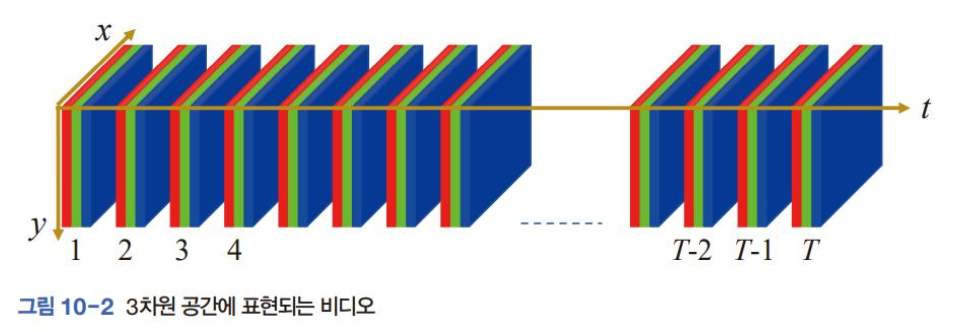
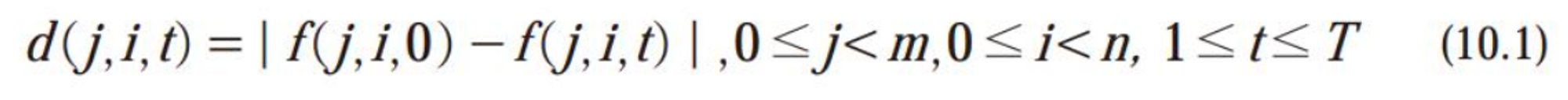
- 배경이 고정된 상황에서 차영상 (difference image)을 분석했었음.
- f(j,i,t) ⇒ t 순간 프레임의 (j,i) 화소값.
- f(,,0)⇒ 배경만 두고 획득한 영상을 기준 프레임 역할을 한다
- 초기에는 광류 → 딥러닝 시대로 전환
10.1.1 모션벡터와 광류
- 움직이는 물체는 연속 프레임에서 명암 변화를 일으킴. 따라서 명암변화를 분석하면 역으로 물체의 정보를 알아낼 수 있다. 화소별로 모션 벡터를 추정해 기록한 맵을 광류라고 함.
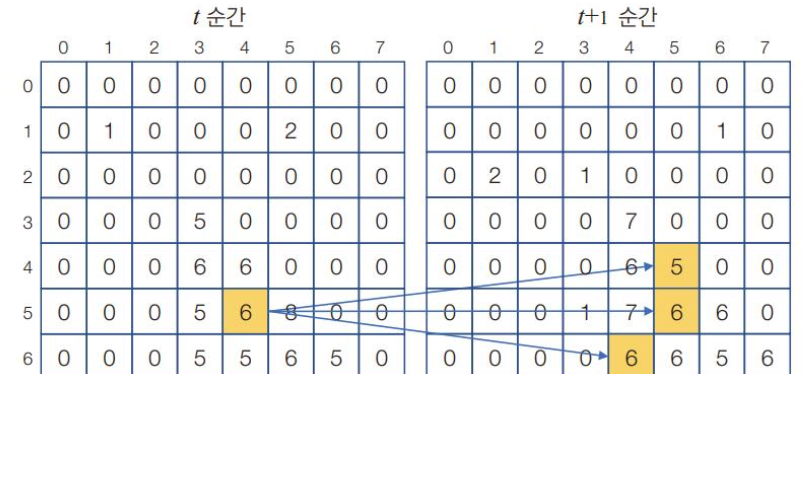
- 모션 벡터 추정 알고리즘 애매함: 노란색 화소가 다음 순간애 어디로 이동했는지 확정짓지 어려움 → 밝기 향상성 조건을 가정 (연속한 두 영상에서 같은 물체는 같은 명암으로 나타난다)
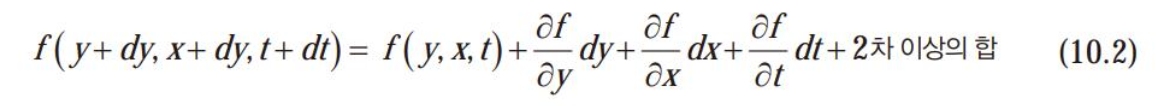
- dt= 두영상의 사간 차이. 작다는 가정하에 2차 이상을 무시
- dt동안 (dy,dx)만큼 이동하여 형성된 f(y+dy, x+dx,t+dt)=f(y,x,t)
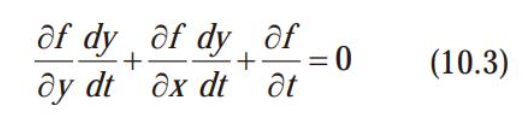

그래서 나온 조건 광류식,
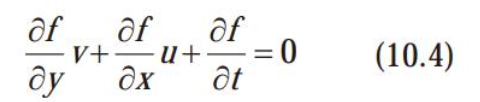
- af/ay, af/ax는 y,x 방향의 명암 변화
위의 예시

- 모션벡터 V=(v,u)를 만족해야 한다는 조건식을 얻음. 그러나, 영상을 아주 많은 화소로 구성되기 때문에 이웃화소와 관계를 고려하면 상당히 정확한 해를 구할 수 있음.
- Lucas-Kanade 알고리즘, Horn Schunck 알고리즘, Farneback 알고리즘
- 희소 광류 추정을 이용한 KLT 추적
10.1.2 딥러닝 기반 광류 추청
- FlowNet: 광류 추정에 컨벌루션 신경망을 적용한 최초 논문 . 9장의 DeConvNet과 같은 신경망을 광류에 적용
- 딥러닝으로 인해 영상 분할 알고리즘의 성능이 높아지자 분할 결과 활용하여 광류 추정의 성능을 개선하려는 시도들이 이루어짐

- RAFT에서 비용볼륨은 t 순간 특징 맵의 화소 각각이 t+1 순간 영상의 어느곳에 주목해야하는지를 나타냄
- 주목 (attention): 특징 사이의 관련성을 분석하여 성능을 향상할 목적으로 컴퓨터 비전에서 애용 → 트랜스포머를 이용한 컴퓨터 비전은 11장에서…
- 광류추정에 트랜스포머를 적용한 최초논문은 2021년에발표됨
- 물체가 영상밖으로 나가거나 다른 물체에 잠시 가렸다가 나타나도 사람은 물체의 움직임을 정확히 예측한다⇒ 가림이 발생한부분의 모션벡터를 안정적으로 알아냄.
- FlowFormer는 RAFT가 사용했던 비용볼륨을 트랜스포머에적용하여 추가적인 성능향상을 얻음. 컨볼루션 신경망이 사용해온 비용볼륨을 트랜스포머와 결합한 점이 FlowFormer 가 높은 성능을 얻은 비결
10.2 추척
- KLT: 고전 추적 알고리즘의 표준 노릇
- 지역특징을 추적하기 때문에 뚜렷하게 특징점이 나타나지않는물체를 추적하지못함
- 지역특징이 어떤물체에 속하는지에 대한 정보가 전혀없어 추적하는 물체가 무엇인지 알지 못함
딥러닝 ⇒ 검출/분할 결과를 잘 활용하면 박스나 영역 단위로 물체를 추적할 수 있으며, 추적 대상이 어떤 물체인지 정확히 알 수 있다.
10.2.1 문제의 이해
- 추적에서는 물체가 사라졌다 다시 나타나는 상황이 종종 발생
- 여러 카메라가 있을 경우, 카메라 시야를 벗어났다가 다시 나타나는 경우
- 끊긴 추적을 매칭하여 같은 물체로 이어주는 과정이 필요 = 재식별 re-identification
- 추적할 물체의 갯수에 따라
- VOT: visual objectTracking(시각물체추적)
- 첫프레임에서 물체 하나를 지정하면 이후 프레임에서 그 물체를 추적하는 문제
- MOT: MultipleObjectTracking(다중물체추적)
- 여러 물체를 찾아야 하는데 첫프레임에서 물체위치를 지정해주지않고 추적할 물체의 부류는 지정
- ⇒ VOT, MOT 대회는 한 대의 카메라에서 입력된 비디오로 한정. 또 다른 문제는 다중 카메라 추적= Multi-Camera Tracking
- 수초 내지 수분이 지난 후 다른 카메라에 나타나는 동일물체를 찾아 이어주는 장기재식별이 중요
- 매장과 같이 비교적 좁은 영역에 설치된 여러대의 카메라를 다루는 경우
- 도로망처럼 넓은 지역에 설치된 여러 카메라를 분석하는 경우
- VOT: visual objectTracking(시각물체추적)
- 추적 문제
- 배치방식
- t 순간을 처리할 때 미래에 해당하는 t+1, t+2 ,•••T 순간의 프레임을 활용.
- 이미 녹화된 경기를 분석해 선수의 장단점을 파악
- 온라인 방식
- 지난 순간의 프레임만 활용
- 실시간 감시 시스템에서는 온라인방식만 활용
- 배치방식
10.2.2 MOT의 성능 척도
- (단일 카메라로 수집한 비디오에서 여러 물체 검출)
- 프레임 간의 연관성까지 고려해야 하므로 검출이나 분할보다 복잡
- 여러 물체를 추적하는 경우 중간에 다른물체로 교환되는 오류까지 고려해야
- MOT Accuracy

- 모든 프레임에서 FN, FP, IDSW를 세야함.
- 매칭 알고리즘에 따라서 정해짐. 9장에서의 IoU 임곗값을 넘기면 매칭되었다고 판정
- 이전 프레임의 박스를 현재 프레임의 박스에 할당하는 문제가 발생 ⇒ 헝가리안 알고리즘으로 해결

- MOTA는 쌍맺기 성공률이 낮더라도 검출 성공률이 높으면 좋은 점수를 부여
⇒ 단점을 지적하고 쌍맺기와 검출 성능을 균형있게 고려한 HOTAHigher OrderTrackingAccuracy
10.2.3 딥러닝 기반 추적
- 보통 딥러닝 기반 추적 알고리즘은 딥러닝 모델로 물체를 검출한 다음 이웃한 프레임에서 검출된 물체 집합을 매칭하여 쌍을 맺는 방식으로 동작
- 일반적인 처리 절차
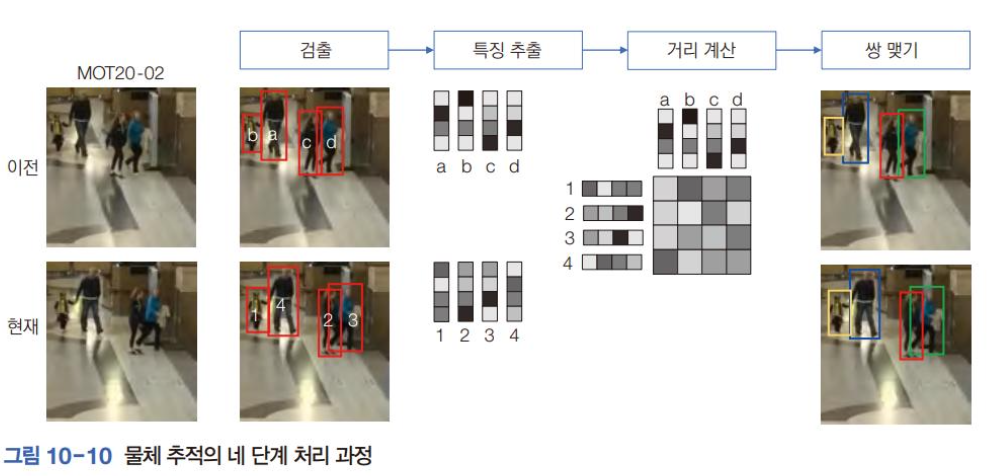
- 1) 현재 프레임에 물체 검출 알고리즘을 적용해 박스를 찾는다.
- 이때 검출 성능이 전체 추적 성능을 좌우⇒ 보통 높은 성능이 입증된
RCNN 계열, YOLO 계열 방법을 활용
- 이때 검출 성능이 전체 추적 성능을 좌우⇒ 보통 높은 성능이 입증된
- 2) 박스에서 특징을 추출
- 단순히 박스의 위치 정보를 특징으로 쓰는 경우
- 컨볼루션 신경망으로 특징을 추출하는 경우
- 3) 이전 프레임의 박스와 현재 프레임박스의 거리행렬을 구한다.
- 박스위치를 특징으로 사용하는 경우는 박스의 IoU 를 계산하고 1- IoU를 거리로 사용
- 컨볼루션 신경망으로 특징을 추출한 경우는 특징 벡터 사이의 거리를 사용
- 4) 거리 행렬을 분석해 이전 프레임의 박스와 현재 프레임의 박스를 쌍으로 맺어 물체의 이동궤적을 구성
- 쌍을 맺는 일은 주로 헝가리안 알고리즘으로 해결
- 위 과정에 더해 다양한 변형이 일어남
- 대부분의 알고리즘이 이전 추적에서 쌓은 이력 정보를 활용하여 성능을 향상하는 전략 사용.
- 물체가 사라졌다 다시 나타나는 상황을 추가로 다룸
단순한 연산을 활용하여 비교적 높은 정확률과 빠른 추적시간을 달성한 SORT 알고리즘과 이를 개선한 DeepSORT 알고리즘
SORT
- 1) 물체검출: 9.3.3항에서 소개한 faster RCNN으로 해결
- 현재 순간 t 의프레임에 faster RCNN을 적용하여 물체를 검출
- 추적 대상 물체를 사람으로 국한하기 때문에 사람에 해당하는 박스만 남기고 나머지는 모두 버림 ⇒ 이렇게 구한 박스를 B(detection)에 담는다.
- 2) 특징 추출: 이전순간 t- 1에서 결정해 놓은 목표물의 위치 정보와 이동 이력정보를 사용
- x,y: 목표물의 중심위치, s: 크기, r: 높이와 너비의 비율, 고정된 값.
- .x, .s, .y: 목표물이 이전에 이동했던 정보를 누적한 이력 정보
- 이런 t-1 순간의 목표물 정보로 t순간을 예측.
- SORT는 이동량을 나타내는 .x,.y,.s를 각각 x,y,s에 더하는 단순한 방법으로 t 순간의 박스를 예측⇒ 예측한 박스를 B predict에 담는다
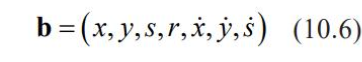
- 3) B detection에 있는 박스와 B predict에 있는 박스의 IoU를 계산, 1-IoU= 거리 변환. 이렇게 얻은 거리를 거리 행렬에 채움
- 4) 거리 행렬을 이용하여 최적의 매칭쌍을 찾는다.(헝가리안알고리즘 적용)

- SORT는 네 단계를 마친 다음 후처리를 수행하고 다음 프레임으로 넘어감
- SORT는 IDSW 오류가 많은 편
- 후처리: B predict에 있는 목표물의 식 정보를 갱신.
- 매칭이 일어난 목표물과 매칭에 실패한 목표물을 구별해서 처리.
- 매칭이 일어난 목표물은 쌍이 된 박스 정보로 x,y,s,r을 대치.
- 이동 이력 정보에 해당하는 .x,.y,.s는 칼만 필터를 사용하여 갱신
- 칼만 필터는 잡음과 변형이 심한 시계열 데이터에서 이전 샘플의 분포를 감안해 현재 측정치를 보완하는 기법.
- 매칭에 실패한 목표물은 .x,.y,.s를 각각 x,y,s에 더하여 x,y,s를 갱신.
- B detection에 있는 박스 중 매칭에 실패한 것은 새로 등장한 목표물로 간주하여 식 정보를 생성
- 이동 정보가 없기 때문에 x,.y,.s 는 0으로 설정. 이렇게 생성한 박스는 B predict에 추가
- 거리행렬을 구할때 박스의 IoU만 사용한 탓이 큰 것으로 분석
- 이듬해 발표된 DeepSORT는 박스의 IoU와 컨볼루션 신경망으로 구한 특징을 같이 사용하여 성능을 향상
- 후처리: B predict에 있는 목표물의 식 정보를 갱신.
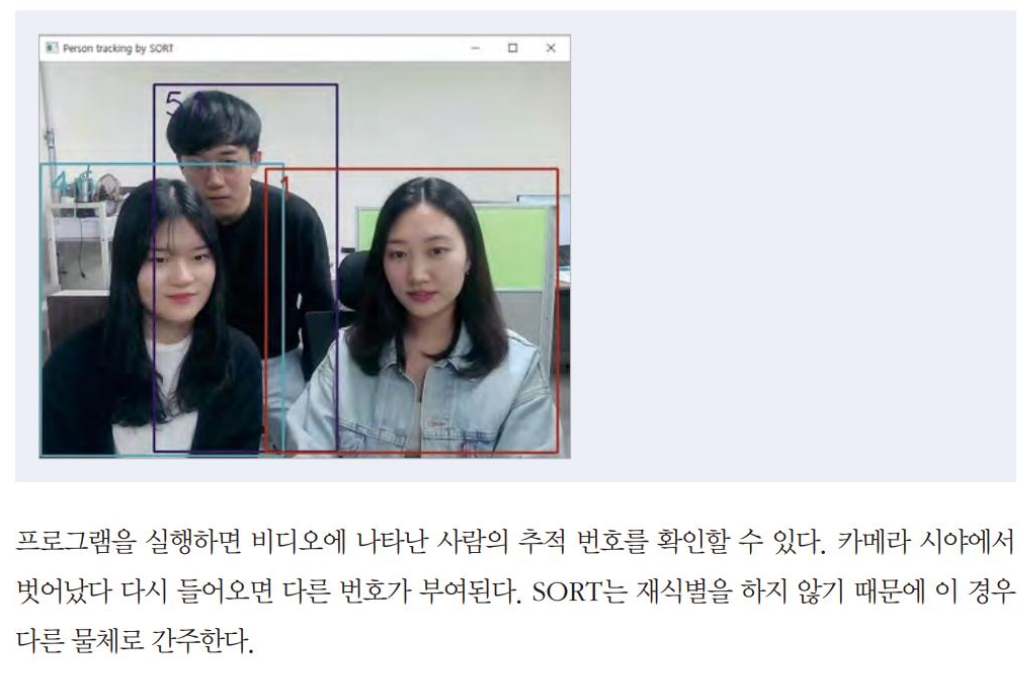
10.3 MediaPipe를 이용해 비디오에서 사람인식(X)
10.3.1 얼굴 검출
- 원리
- BlazeFace로 얼굴 검출
- 비디오에서 얼굴 검출
- 얼굴을 장식하는 증강 현실
10.3.2 얼굴 그물망 검출
- 원리
- FaceMesh로 얼굴 그물망 검출
10.3.3 손 랜드마크 검출
10.4 자세 추정과 행동 분류
10.4.1 자세 추정
- 자세추정 pose estimation은 정지 영상 또는 비디오를 분석해 전신에 있는 관절 위치를 받아내는 일
- 관절을 랜드마크, 키포인트라고 부름
- 인체모델
- 골격 표현
- 랜드마크의 연결관계를 그래프로표현
- 골격표현은 랜드마크를 2차원좌표와 3차원좌표로 표현하는 경우로 구분
- 부피 표현
- 기본적으로 3차원 좌표 사용
- SMPL - 인체를 3차원 랜드마크와 3차원 부피로 표현
- 골격 표현
- ⇒ 책에서는 2차원 골격 표현법으로 한정해 설명

- 정지 영상에서 자세 추정
- Deep Pose: 딥러닝을 자세 추정에 처음 적용한 모델
-
입력: 2202203 영상.
-
컨볼루션 층 5개 ⇒ 1313192 특징 맵으로 변환. 2개의 완전연결층을 거쳐 2k개의 실수를 출력
-
k= 랜드마크 개수, 랜드마크 (x,y)좌표로 표현.
-
전체 영상을 보고 좌표를 예측하기 때문에 가림이 발생한 관절의 위치까지 예측
- 하지만 정확률이 떨어지기 때문에 추정한 관절 위치에서 패치를 잘라내 세밀하게 위치를 조정하는 후처리 단계를 밟음
-
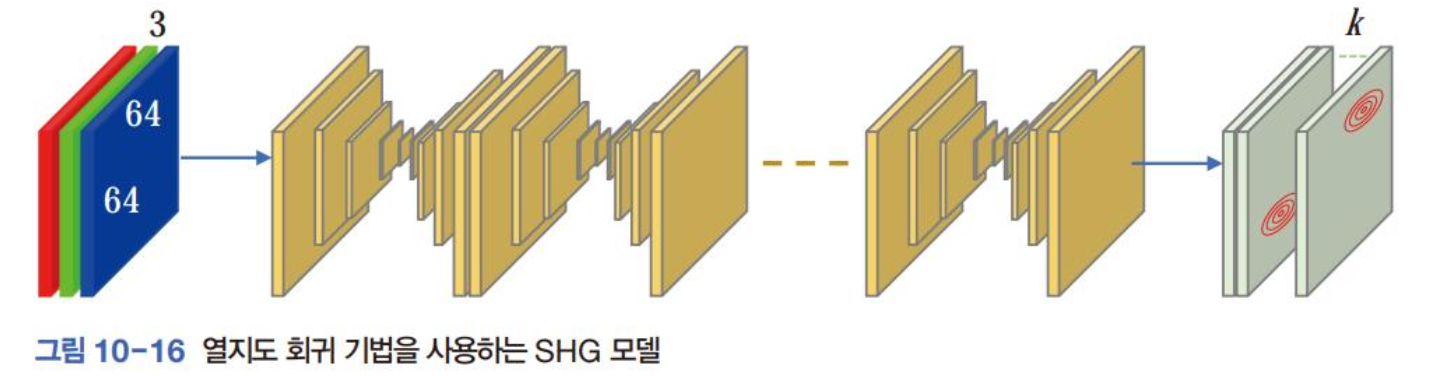
랜드마크를 검출하는 또 다른 방법: 열지도 회귀 heatmap regression
- DeepPose는 i번째 랜드마크를 (xi, yi)로 표현하고 신경망이 좌푯값 자체를 예측
- 열지도에서는 (xi. yi) 위치에 가우시안을 씌운 맵을 예측.
- 좌푯값을 예측하는 좌표 회귀에서는 출력층 2k개의 실수를출력하는데, 열지도 회귀에서는 k개의 2차원맵을 출력
- 대표적인 신경망: SHG Stacked HourGlass
- 모래 시계 모양의 신경망을 여러 개 쌓아 만드는 것으로 모래 시계 하나는 인코더와 디코더를 붙여만든 신경망과 비슷한 구조
-
다수의 사람을 대상으로 자세를 추정하는 접근 방법
- 하향식
- faster RCNN과 같은 모델을 사용해 사람을 검출 ⇒ 사람부분 패치로 잘라냄 ⇒ 각각 패치에 같은 모델 적용하여 자세추정
- 상향식
- 랜드마크를 모두 검출 ⇒ 랜드마크를 결합하여 사람별로 자세를 추정
- 하향식
-
비디오에서 자세추정
- 이웃 프레임 접근 고려
- 광류를 사용하는 방법
- 순환 신경망 방법
- 자세 추적 pose tracking은 하나의 프레임에서 여러 명을 구분 ⇒ 개개인의 자세를 추정 ⇒ 이후 프레임에서 자세 단위로 사람을 추적
- 이웃 프레임 접근 고려
-
데이터셋과 성능 척도
- 자세추정 성능 척도: 현재는 랜드마크별로 제대로 찾았는지 측정하는 척도를 주로 사용 PCP@0.5
- OKS object keypoint similarity 사용: 예측 랜드마크와 참값 랜드마크 사이의 OKS를 계산. 임곗값을 변화시키며 정밀도, 재현률 구성 ⇒ AP 측정 (average precision). 관절별로 AP 계산 ⇒ 모든 관절의 AP를 평균 ⇒ mAP
10.4.2 BlazePose를 이용한 자세추정
10.4.3 행동 분류
- 컴퓨터 비전은 아직 행동 이해까지는 못감. ⇒ 행동 분류, 예측에 집중
- 데이터셋: Kinectics, HAA500 (레이블링 된 비디오)
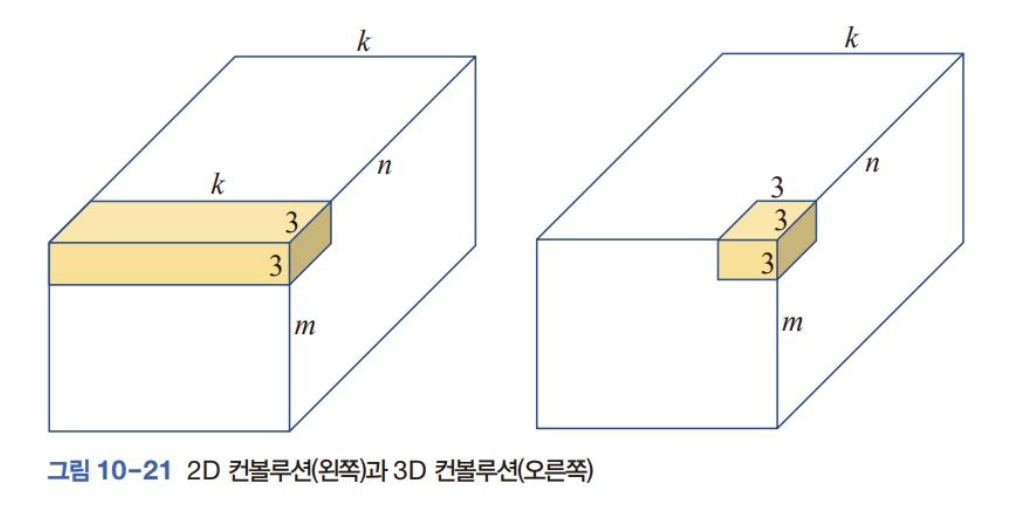
- 비디오 + 시간축 ⇒ 3차원 공간= spatio temporal 공간
- 3 차원 필터를 사용하여 3차원 컨볼루션 수행.
- 왼: k라고 표시된 깊이 방향으로 필터가 움직이지 않기 때문에 2차원 컨볼류션
- 오: 333 필터가 세 방향으로 이동
- 비디오 특징
- 한 장의 프레임에서 추출한 특징 맵
- 여러 프레임에서 추출한 광류
- Simonyan: 두 흐름으로부터 부류 확률 벡터를 추정 ⇒ 두 확률 벡터를 결합해 최종 부류 결정
- 첫번째 흐름: 현재 프레임 처리, 두번째 흐름: 광류
- 두 흐름을 어느 시점에서 어떤 방식으로 결합해야 좋은 성능을 얻을 수 있는지 연구 ⇒ 마지막 컨볼루션 층에서 결합해야.
- Carrerira: 두 흐름의 접근 방법에 3차원 컨볼루션을 적용하는 아이디어 제안
- Wang: 비디오를 몇개 구간으로 나눈 다음, 각 구간에서 두 흐름의 컨볼루션 수행. 각 구간에서 얻은 맵을 최대 풀링같은 단순한 연산으로 결합
- 행동 예측은 행동 분류보다 어려움 [Kong2022]에서 확인가능

ML Engineer 🧠 | AI 모델 개발과 최적화 경험을 기록하며 성장하는 개발자 🚀 The light that burns twice as bright burns half as long ✨