11.1 주목
고전 주목 알고리즘
- 특징 선택(feature selection) : 쓸모가 많은 특징은 남기고 나머지는 제거하는 작업 → 분별력 높은 특징에 주목, 0(선택 안 함), 1(선택함)
- 돌출 맵 : 컬러 대비, 명암 대비, 방향 대비 맵 결합해 돌출 맵 구성. 주목해야 할 정도를 실수로 표현. 사람이 설계하고 수작업 특징 적용
딥러닝의 주목

- 영상의 중요한 부분에 더 큰 가중치를 줘서 성능을 개선하는 아이디어
- 자기 주목 : 영상을 구성하는 요소 상호 간에 주목을 결정
- Non-local Net(2017)
- Transformer(2017) : ViT(분류), DETR(검출), SETR(분할), MOTR(추적), Swin(분류, 검출, 분할, 추적)
11.2 순환 신경망과 주목
11.2.1 순환 신경망 기초
구조와 동작
- 순환 신경망(RNN) : 은닉 노드끼리 에지를 가진다.
- 가중치 집합 :
- 순간 에서 와 가 입력 → 가 생성 → 가 출력 (중간에 활성함수 있음)
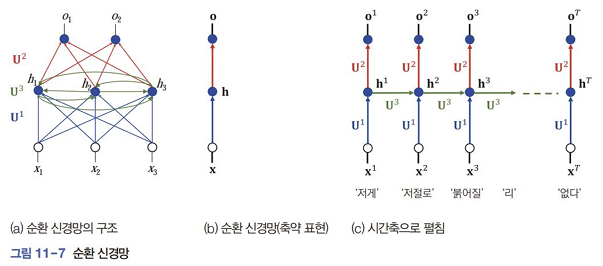
- 임베딩 벡터(embedding vector)로 단어를 표현. 단어의 의미를 반영함
장거리 의존과 LSTM
- 길이가 긴 샘플에서 한계
- 장거리 의존 : 앞쪽 단어와 멀리 뒤에 있는 단어가 밀접하게 상호작용해야하는 것
- LSTM : 순환 신경망 개조 → 장거리 의존을 처리 : 신경망 곳곳에 입력과 출력을 열거나 막을 수 있는 게이트를 두어 선별적으로 기억하는 기능 확보. 실제로는 실숫값을 사용해 여닫는 정도를 조절
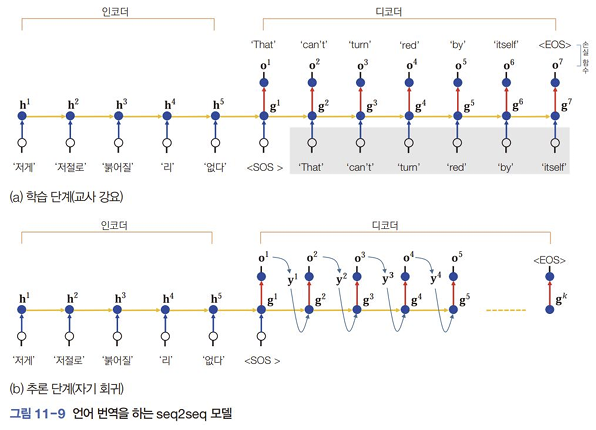
서츠케버의 seq2seq모델
- seq2seq가 가지는 혁신성 : 가변 길이의 문장을 가변 길이의 문장으로 변환할 수 있다는 사실
- 교사 강요(teacher forcing) : 정답에 해당하는 출력을 알려줌(학습)
- 자기 회귀(auto-regressive) : 추론(예측) 단계. 이전 순간에 출력된 단어를 보고 현재 단어를 출력하는 일 반복. 가 발생하면 멈춤
- 한계
- 인코더의 마지막 은닉 상태만 디코더를 전달. 따라서 인코더는 마지막 은닉 상태에 모든 정보를 압축해야 하는 부담이 있다.
- 디코더는 풍부한 정보가 인코더의 모든 순간에 있음에도 불구하고 마지막 상태만 보고 문장을 생성해야 하는 부담이 있다.
11.2.2 query-key-value로 계산하는 주목
query가 key와 유사한 정도를 측정하고 유사성 정보를 가중치로 사용해 value를 가중하여 합하는 방법.
non-local 신경망이 사용했던 식도 비슷한 방식. query와 가장 유사한 것(self attention)
주목 벡터 : query와 key 사이의 벡터
문맥 벡터 : value의 가중 합
벡터의 차원을 라 하면 는 행렬, 는 행렬이디. 은 key와 value가 가진 벡터의 개수다.
11.2.3 주목을 반영한 seq2seq 모델
바다나우 주목
- 디코더가 인코더의 모든 상태에 접근할 수 있게 허용함으로써 성능을 향상함
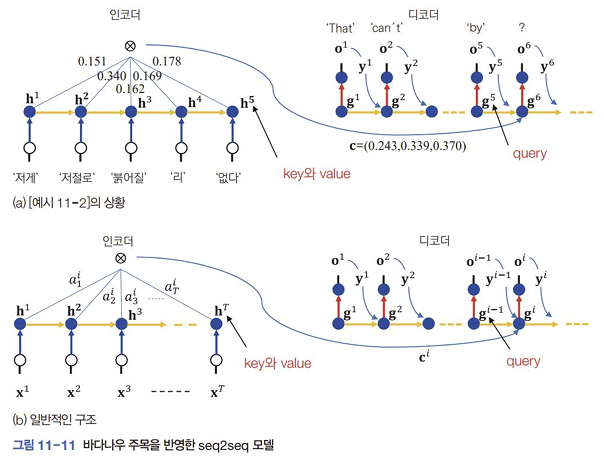
- 디코더의 순간 에서의 입력
- 이전 순간의 상태
- 이전 순간에 디코더가 출력한
- 순간 를 위한 문맥 벡터
- 주목을 적용하는 신경망 모델을 을 위해 라는 가중치를 추가로 사용
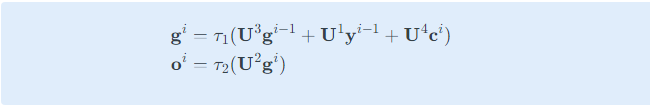
11.3 트랜스포머
구글 : Attention is all you need → 트랜스포머 : 순환 신경망과 컨볼루션 신경망의 구성요소를 모두 없애고 주목만으로 신경망을 구현
11.3.1 기본 구조
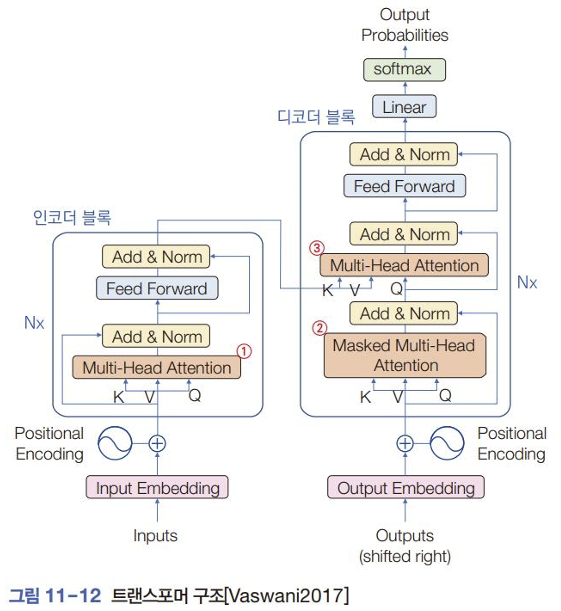
- 모든 단어를 한꺼번에 입력 → 자기 주목 가능하게 함, 병렬 처리 가능
- 단어 : 단어 임베딩을 통해 차원의 임베딩 벡터로 표현
- 단어의 위치 정보 보완 : 위치 인코딩positional encoding
- MHA
- ① : 인코더에 배치, 입력 문장을 구성하는 단어 사이의 주목 처리. 같은 문장을 구성하는 단어끼리 주목한다 → self-attention
- ② : 디코더에 배치 Masked MHA : 출력 문장을 구성하는 단어끼리 주목을 처리하는 자기 주목. 언어 번역을 학습할 때 출력 문장을 처리하는 디코더는 순간 i에서 1,2,…i-1만 관찰해야 하므로 마스크를 사용해 i+1, i+2, … 순간을 감추어야 한다.
- ③ : 인코더가 처리한 입력 문장과 디코더가 처리하고 있는 출력 문장 사이의 주목을 다루기 때문에 자기 주목이 아니다. 이때 인코더의 상태 벡터는 key와 value가 되고 디코더의 상태는 query로 작용한다. 여기서 인코더와 디코더는 정보를 교환한다.
- 위치 정보를 추가한 단어들을 한꺼번에 처리하기 때문에 병렬 처리 가능
- 자기 주목은 모델이 문장을 이해하는 데 매우 효과적이다. 자기 주목은 트랜스포머의 핵심 아이디어다.
11.3.2 인코더의 동작
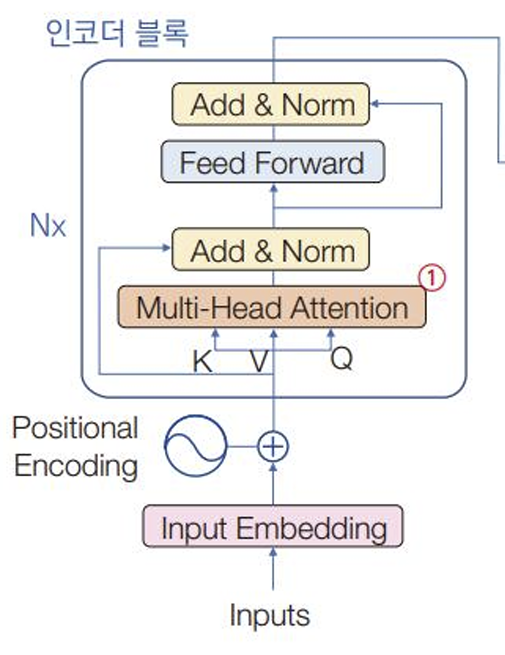
단어 임베딩과 위치 인코딩
- 단어 행렬 :
- : 단어 임베딩 차원
- : 단어의 개수
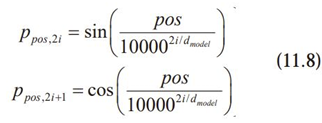
- : 위치 인코딩 : 위치 정보, :
- 위치 행렬 : sin, cos함수 사용해서 만듦. 홀수 위치 : sin , 짝수 위치 : cos
자기 주목
- : 자기 주목의 기반이 되는 식
- 자기 주목은 입력 문장이 자기 자신에 주목하는 과정 → query, key, value 모두 입력 문장을 표현한 행렬이다.
- 이때 query의 확장이 필요 → 자기 주목에서는 query가 T개의 행을 가진 행렬 가 된다.
- : 주목 행렬
- : 문맥 행렬
- , , , : 크기의 행렬
- Self attention을 구현하는 가장 단순한 방법은 Q, K, V를 모두 X로 설정하는 것.
- 트랜스포머 ⇒ 각각의 가중치 행렬로 를 변환하여 사용
- :
- :
- : ⇒ : , :
- 논문 기준,
- 가중치 행렬 은 학습으로 알아낸다.
softmax행렬은 행마다 attention 벡터를 담고 있다. 행렬의 i번째 행은 i번째 단어가 다른 단어에 주목할 정보를 제공.
Multi-head 주목
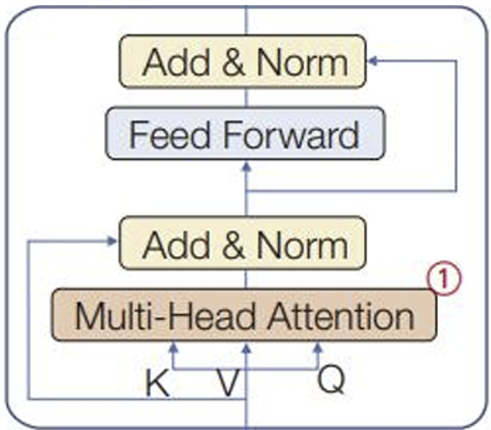
①의 MHA의 각 헤드(h개)는 고유한 변환 행렬을 가지고 자기 주목을 독립적으로 수행해 상호 보완한다.
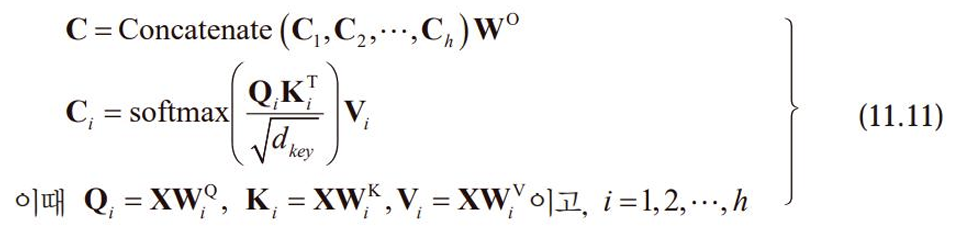
: 를 행으로 이어 붙여 행렬 만든다. ( : )
입력 가 ⇒ 출력 가 : 같은 크기의 행렬을 유지한다!
Add&Norm
- Add : 지름길 연결 : MHA층의 출력 특징 맵 와 층에 입력되었던 특징 맵 를 더해주는 연산
- Norm : 층 정규화 : 미니 배치를 구성하는 샘플별로 특징 맵의 평균이 0, 표준편자가 1이 되도록 정규화한다.
위치별 FF층
:
트랜스포머 : 신경망을 흐르는 텐서의 모양을 유지 → 행렬 연산이 원활히 이루어지도록 설계됨
- : 첫 번째 완전연결층의 연산
- 신경망이 문장을 처리한다면 단어별로 처리하는 셈 → 위치별 FF층
학습이 알아내야 할 가중치
매우 많다!
11.3.3 디코더의 동작
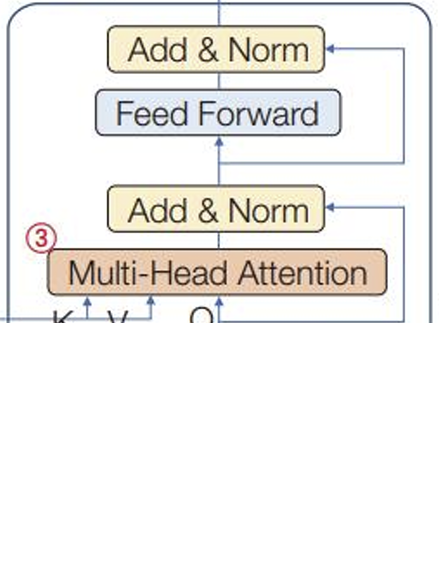
Masked MHA층
- ②Masked MHA층 : 행렬 일부를 마스크로 가린다는 점 제외하면 인코더의 MHA층과 같다.
- 예측 단계에서는 입력 문장은 알고 있지만 출력 문장은 모른 채 동작해야 한다.
- 예측하는 일을 재귀적으로 수행하는 자기 회귀 방식을 적용
- 학습 : 교사 강요(teacher forcing) / 추론 : 자기 회귀
- 행렬 얻음. 개 단어가 각각 다른 단어에 주목해야 할 정보 담음
인코더와 연결된 MHA층
- ③MHA층 : 인코더와 디코더가 상호작용
- ①MHA : 입력 문장 내의 단어끼리 주목을 처리
- ②MaskedMHA : 출력 문장 내의 단어끼리 주목을 처리하는 자기 주목
- ③MHA : 디코더로 입력된 문장의 단어가 인코더로 입력된 문장의 단어에 주목할 정보를 처리한다. (이외에 연산은 같음)
- 이후에 Add&Norm층, 완전연결층, Add&Norm층 거쳐 만들어진 행렬 → Linear, softmax로 구성된 출력층으로 전달
학습이 알아내야 할 가중치
이것도 많음
11.3.4 전체 동작
N개의 인코더 블록과 N개의 디코더 블록으로 구성된 트랜스포머
인코더 블록을 모두 거친 후 1~N번 디코더에 모두 입력
softmax를 통과한 확률 벡터는 단어로 변환되어 최종 출력
11.4 비전 트랜스포머
컴퓨터 비전에 적용된 트랜스포머 모델 ⇒ 비전 트랜스포머
11.4.1 분류를 위한 트랜스포머
영상 분류 : 영상이 주어지면 어떤 부류에 속하는지 맞히는 문제
ViT
- 원래 트랜스포머 구조를 최대한 그대로 따라한 실험
- 문장 : 1차원 / 영상 : 2차원 → 구조 변경 필요
- 입력 : 영상 → 출력 : 부류 확률 벡터 ⇒ 인코더
- 영상을 어떻게 인코더에 입력하는가
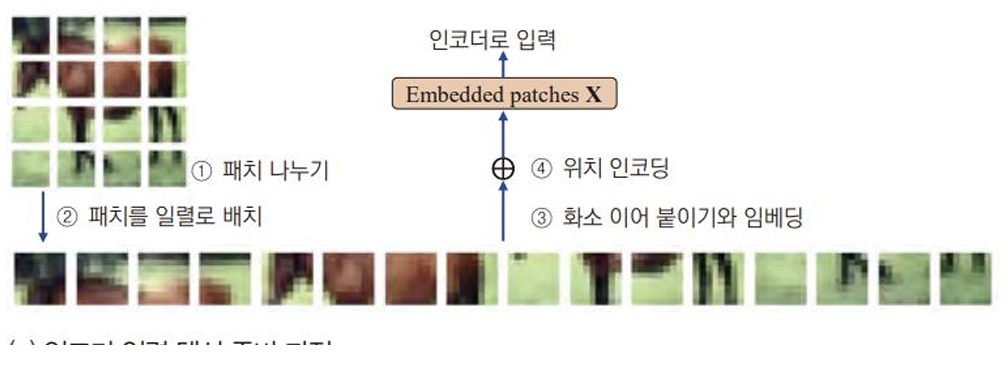
① 패치 나누기
② 패치를 일렬로 배치
③ 화소 이어붙이기와 임베딩
④ 위치 인코딩
⇒ 행렬 $\bold{X}$ : $T \times d_{model}$ : T개의 패치가 행을 이룬다. 패치끼리 자기 주목을 계산- 인코더만 있는 구조
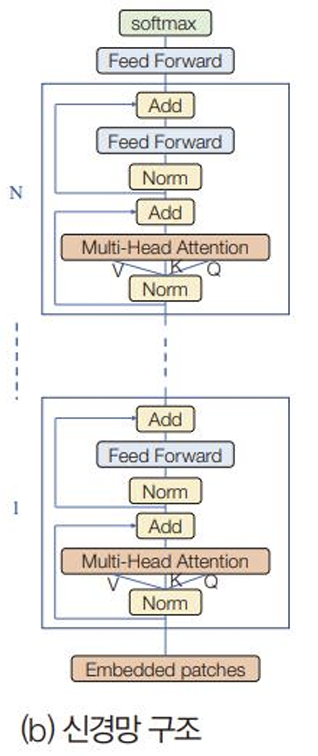
- [층 정규화 결과(Norm)
→ MHA
→ 지름길 연결(Add)] * N
→ Feed Forward 완전연결층
→ softmax
→ 출력 : 부류 확률 벡터11.4.2 검출과 분할을 위한 트랜스포머
발상
- 영상에서 물체를 검출하는 신경망 : 여러 개의 박스를 예측 → 집합 예측 모델
- 모델의 예측과 정답에 해당하는 레이블이 모두 박스 집합이기 때문에 헝가리안 알고리즘으로 최적의 매칭 쌍을 알아내 손실 함수를 계산
- 트랜스포머는 컨볼루션 신경망에 비해 구조를 개조할 수 있는 여지가 적다. 따라서 원래 구조를 유지하면서 박스 집합을 예측할 수 있게 개조해야 한다.
- 입력 : 영상 → 출력 : 박스 집합 ⇒ 인코더와 디코더를 모두 사용
DETR
- 트랜스포머를 이용해 바로 집합 예측
- 후보 영역 생성하는 단계 없음
- 비최대 억제라는 후처리 단계 없음
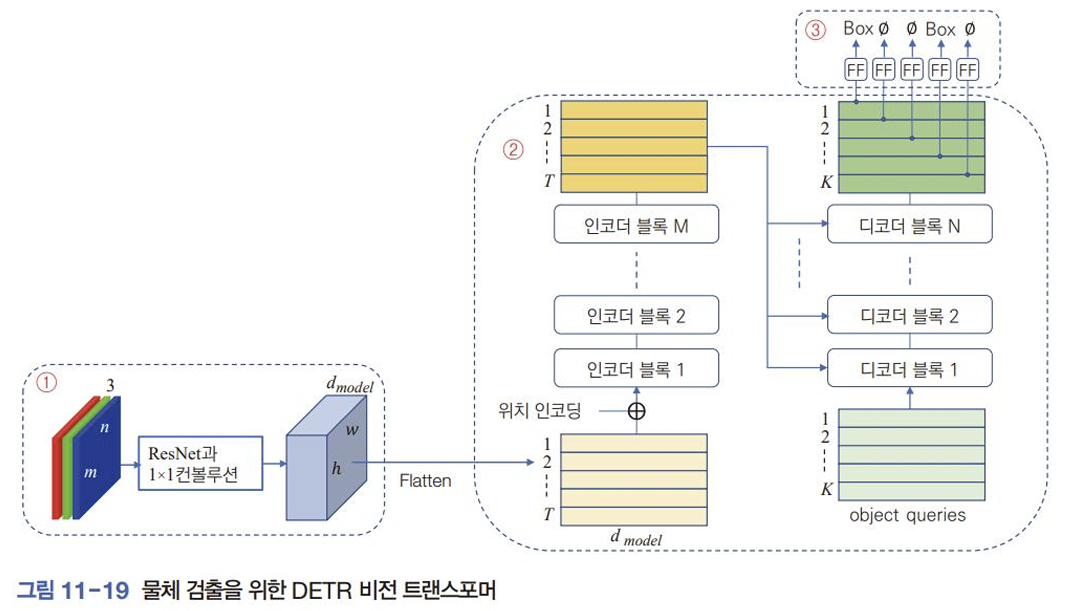
① 컨볼루션 신경망으로 특징 추출
② 인코더와 디코더로 구성된 트랜스포머
- 디코더에 자기 회귀 적용할 수 없다. 물체 박스는 순서가 없어 집합으로 표현해야 한다.
- Object queries : K 개의 검출 가능한 물체의 최대 개수 미리 설정( 가능), 박스에 대한 정보 없어서 학습을 통해 알아낸 위치 인코딩 정보 사용함
③ 완전연결층(FF) 통과하여 박스 정보로 변환
- 부류를 맞혔는지, 물체의 위치를 얼마나 정확하게 맞혔는지
분할을 위한 비전 트랜스포머
- DETR의 모듈 ③의 검출 헤드를 떼내고 분할 헤드를 붙인다.
- 분할 헤드는 축소된 해상도를 원래 해상도로 복구하려고 업 샘플링을 위한 컨볼루션층을 포함한다.
- SETR : 인코더는 트랜스포머 사용, 디코더는 컨볼루션 신경망을 사용
11.4.3 백본 트랜스포머
- 스윈 트랜스포머 : 분류, 검출, 분할, 추적 등에 두루 사용할 수 있는 백본 비전 트랜스포머를 목표로 설계됨
- 백본이 되려면 영상의 특성을 충분히 반영한 구조를 설계하는 일이 핵심
계층적 특징 맵과 이동 윈도우

- 계층적 특징 맵 : 물체의 스케일 변화에 대응(다중 해상도)
- 작은 패치부터 큰 패치로 → 여러 크기의 물체를 분류, 검출, 분할
- 계산 효율
- 이동 윈도우 : 윈도우끼리 연결성 강화되어 성능 향상
- 윈도우를 절반 크기만큼 수평과 수직 방향으로 이동해 나눔
스윈 트랜스포머의 구조
- 계층적 특징 맵과 이동 윈도우 적용
- 분류, 검출, 분할 헤드 → 백본 모델로 작용할 수 있는 스윈 트랜스포머
11.4.4 자율지도 학습
- 트랜스포머의 확장성scalability : 모델의 크기와 데이터셋의 크기가 커져도 원만하게 학습이 이루어지고 성능이 향상되는 특성을 뜻함.
자연어 처리를 위한 MLM
Masked Language Model
자율지도 학습, 다음 문장 예측
컴퓨터 비전을 위한 MIM
Masked Image Modeling : 영상의 일부를 가린 다음 모델이 알아내도록 학습하는 기법
11.5 비전 트랜스포머 프로그래밍 실습
- 11.5.3 CLIP 프로그래밍 실습 : 멀티 모달 트랜스포머는 멀티 모달 데이터를 모델링하는 능력이 뛰어나다. CLIP은 이런 강점을 활용해 사전 학습된 모델이다.
11.6 트랜스포머의 특성
장거리 의존
- 컨볼루션 신경망 : 컨볼루션 연산으로 이웃 화소와 정보를 교환. 멀리 떨어져 있는 물체끼리 상호 작용하려면 층이 깊어야 함 → 층이 깊어짐에 따라 중요 정보 흐릿해짐
- 순환 신경망 : 시간축을 따라 상호작용. 깊은 층을 통해 상호작용 → 층이 깊어짐에 따라 중요 정보 흐릿해짐
- 트랜스포머 : 자기 주목을 통해 장거리 의존을 처리한다. 전역 정보 명시적으로 표현하고 처리, 지역 정보 추출에도 능숙
확장성
- 트랜스포머 : 모델의 크기와 데이터셋의 크기 측면에서 확장성이 뛰어나다.
- 트랜스포머의 확장성scalability : 모델의 크기와 데이터셋의 크기가 커져도 원만하게 학습이 이루어지고 성능이 향상되는 특성을 뜻함.
설명 가능
- 트랜스포머 : 영상을 구성하는 요소끼리 자기 주목을 명시적으로 표현하기 때문에 설명 가능을 구현하기에 훨씬 유리하다.
멀티 모달
- 귀납 편향 : 기계학습 모델이 학습 단계에서 보지 않았던 새로운 샘플을 옳게 추론하기 위해 사용하는 가정 ex. 지역성, 이동 등변
- 컨볼루션 : 귀납 편향 강한 편 / 순환 신경망 : 시간축 관련 강한 귀납 편향 가짐
- 트랜스포머 : 귀납 편향 약한 편 → 여러 가지 입력 형태(멀티 모달 데이터)에 적용할 여지
토대 모델
- 토대 모델 : 그 자체로 응용이 완성되지 않았지만 전이 학습을 통해 컴퓨터 비전과 자연어 처리, 음성 분석 등 넓은 범주의 다양한 과업을 지원할 수 있는 모델. 기초가 튼튼하고 다양한 응용 헤드를 붙일 수 있는 유연함을 갖추어야 한다.
- 트랜스포머 : 귀납 편향 약해 멀티 모달 데이터에 적용, 확장성과 성능 우월
