Sharding
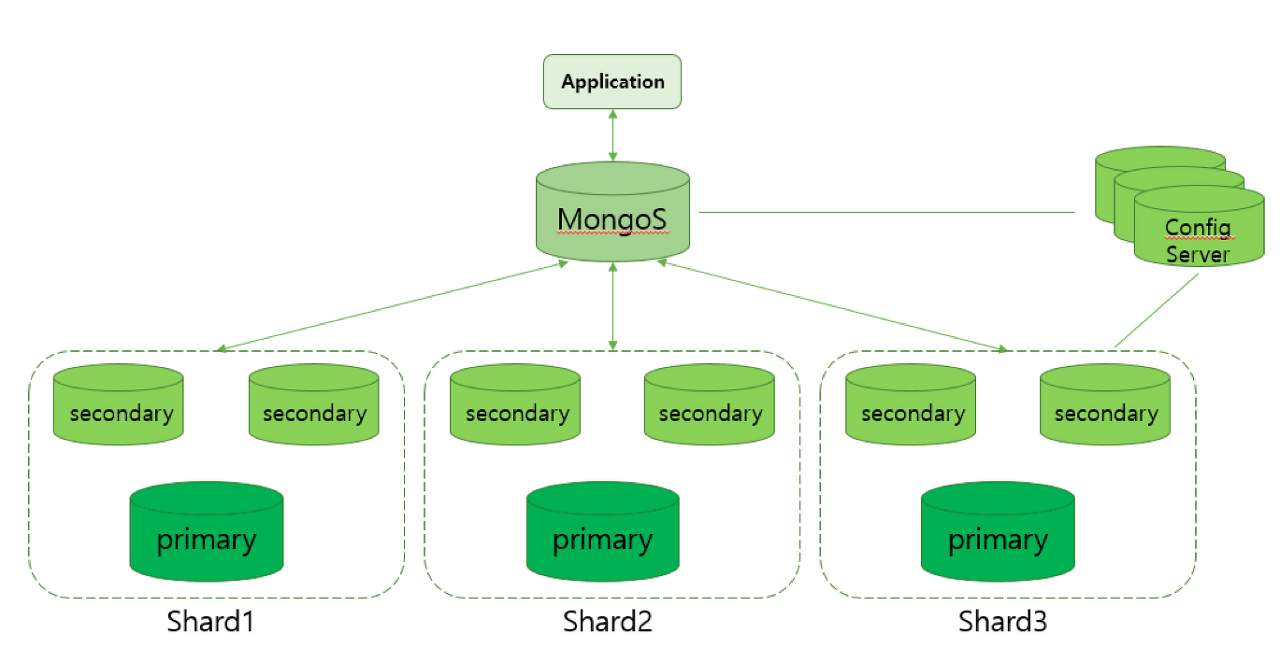
샤딩은 데이터를 여러 서버에 분산해서 저장하고 처리할 수 있는 기술을 말합니다.
1. Shared Cluster
-
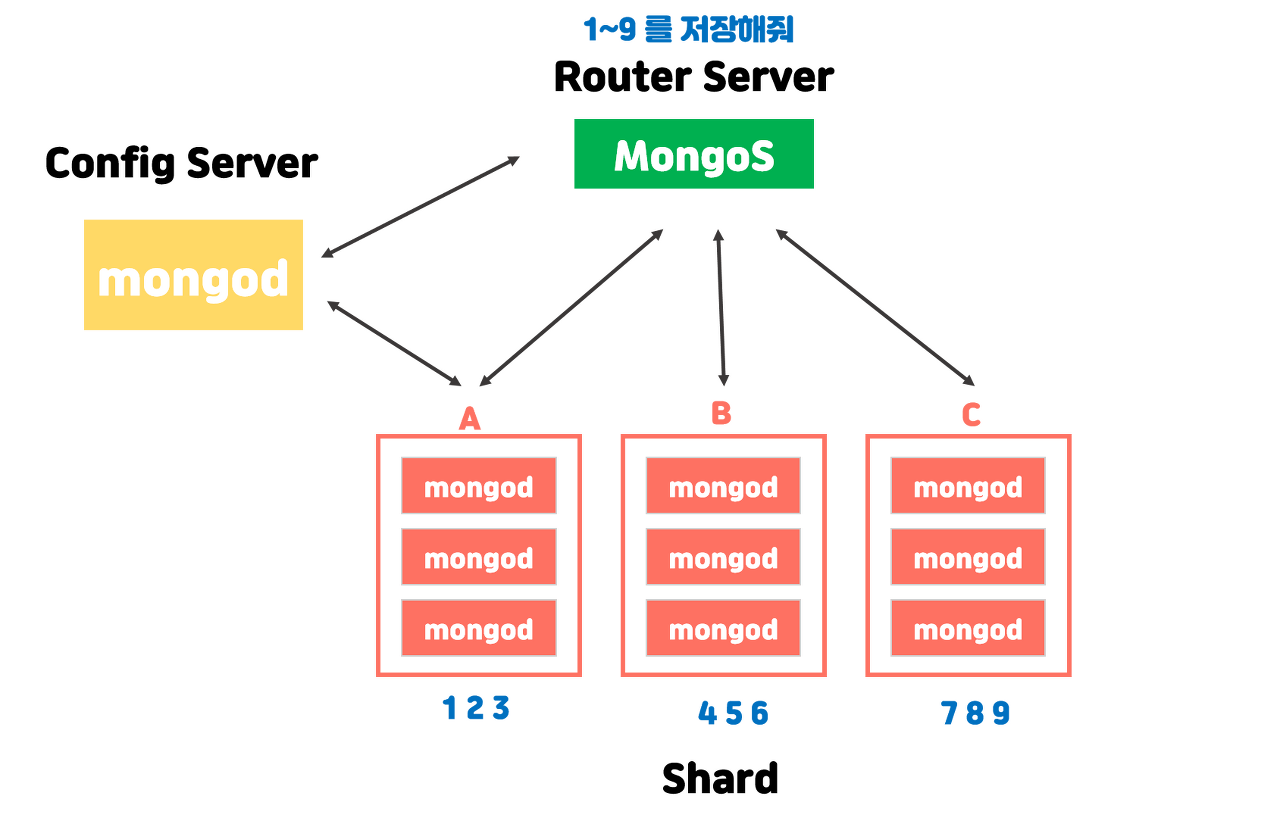
Shard : 샤드 데이터의 집합, 샤드는 Replica set으로 구성되어 있습니다.
-
Mongos : 몽고스는 쿼리 라우터와 같은 역할로 애플리케이션과 샤드 클러스터 간의 인터페이스를 제공합니다. 쉽게 말하면 client에서 전달된 질의를 분석해서 적절한 샤드로 보냅니다.
-
Config server : 각 샤드 서버에 어떤 데이터가 어떤 식으로 분산 저장되어있는지에 대한 meta 데이터가 저장되어 있습니다.
shared는 데이터를 나누어 저장해놓은 곳이고, config server는 이 데이터를 찾기 위해 어디로 가야하는지 mongos에게 알려줍니다.
2. Replica
서버에 문제가 생겼을 경우, 시스템전체에 문제가 생기기 때문에 복사본을 만듭니다. 이를 '레플리카'라고 합니다.
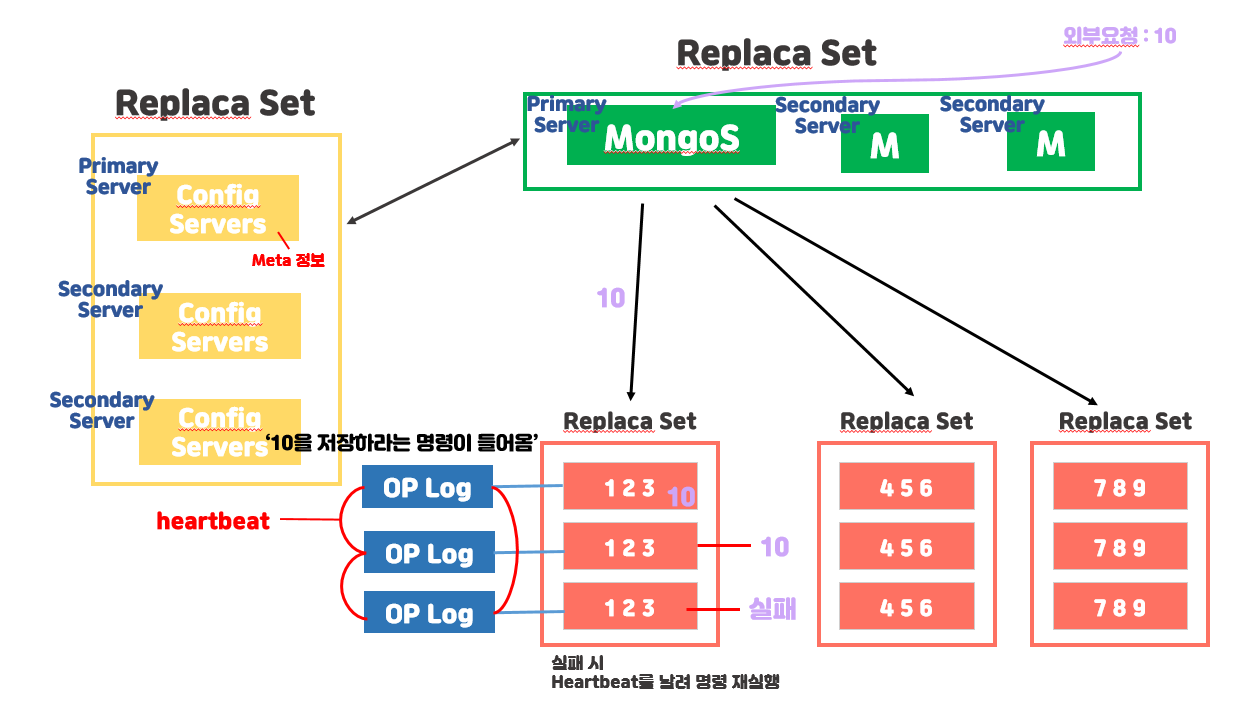
- 레플리카 셋(SET) : 레플리카를 만들 때는 3개를 한 쌍으로 만듭니다.
RAID : 레플리카처럼 여러개의 디스크를 묶어 하나의 디스크처럼 사용하는 것을 RAID(Redundant Array of Independent Disk)라고 합니다.
레플리카 셋에는 primary server와 secondary 서버가 있습니다. primary는 write
operation을 수행하고 이러한 operation 을 oplog에 기록합니다. secondary는 이 oplog를 복제하고 각자의 데이터셋에 operation을 비동기방식으로 적용합니다.
oplog
명령어를 저장합니다. 10이라는 정보가 들어왔다면, 10을 저장해야되! 라는 명령 자체를 저장하는 곳입니다.
HeartBeat
primary에서 secondary에 이 oplog를 서로 주고받는 과정을 heartbeat라고 합니다. 이를 통해 동기화할 수 있습니다.
또 primary는 2초 단위로 secondary 서버 상태를 체크하고 heartbeat를 시도합니다.
Polling
이 2초 단위로 체크하는 것을 polling이라고 합니다. 폴링은 하나의 장치가 충돌 회피 또는 동기화 처리 등을 목적으로 다른 장치의 상태를 주기적으로 검서하여 일정한 조건을 만족할 떄 송수신 등의 자료처리를 하는 방식을 말합니다.
secondary에 문제가 생기더라도 primary에 oplog가 저장되어있기 때문에 secondary가 복구된 뒤에 이 oplog도 동기화할 수 있습니다.
만약에 primary에 문제가 생긴다면, secondary서버가 primary서버로 바뀝니다.
과정
- 10이라는 정보가 들어왔다면, Primary Server에 Mogos가 10을 저장하라는 요청을 받습니다.
- Primary Server가 Config Server에게 어디에 작업할지를 요청합니다.
- Config Server가 Primary Server의 Mongos에게 A Server(123)으로 가라고 응답합니다.
- 바로 저장하는 것이 아니라 OPLog(저장 영역)으로 갑니다. OPLog는 10을 저장해야하는 명령을 저장합니다.(명령 자체를 저장)
- Primary와 Secondary에 연결된 OPLog끼리 서로 통신을 보냅니다.(복제하기 위해서 동기화하는 것입니다.)
- 동기화가 되면서 데이터가 복사본이 만들어집니다.
출처
https://kslee7746.tistory.com/entry/MongoDB-Sharding%EC%83%A4%EB%94%A9
https://junghwanta.tistory.com/41
https://ryu-e.tistory.com/2?category=784319
https://eunsour.tistory.com/73
https://dev-cini.tistory.com/36
