MongoDB
NoSQL
MongoDB는 NoSQL 데이터베이스 입니다. 그중에서도 NoSQL 도큐먼트 데이터베이스 입니다.
Atlas Cloud
MongoDB에서는 아틀라스로 클라우드에 데이터베이스를 설정합니다.
아틀라스 사용자는 클러스터를 배포할 수 있습니다.
인스턴스들의 모임을 클러스터라고 하며 하나의 시스템으로 작동합니다.
단일 클러스터에서 각각의 인스턴스는 동일한 복제본을 가지고있으며 이를 레플리카 세트라고 합니다.
클러스터를 이용하여 배포할 경우 자동으로 레플리카 세트를 생성합니다.
-
인스턴스 로껄 또는 클라우드에서 특정 소프트웨어를 실행하는 단일 머신, MongoDB에서 데이터베이스
-
레플리카 동일하 ㄴ데이터를 저장하는 소수의 연결된 머신
-
클러스터 데이터를 저장하는 서버 그룹으로 여러 대의 컴퓨터를 네트워크를 통해 연결하여 하나의 단일 컴퓨터처럼 동작하도록 제작한 컴퓨터를 뜻함
MongoDB Document

Document는 객체와 같이 데이터를 필드:값 쌍으로 저장하고 구성합니다.
Documnet에서 필드는 데이터의 고유한 식별자, 값은 주어진 식별자와 관련된 데이터를 뜻합니다.
컬렉션 MongoDB 도큐먼트로 구성된 저장소,
1. 작성법
도큐먼트느느 JSON 형식으로 출력됨
- {} 중괄호로 도큐먼트가 시작하고, 끝나야함
- 필드와 같이 콜론(:) 으로 분리되어야하며, 필드와 값을 포함하는 쌍은 쉼표(,)로 구분
- 문자열인 필드도 쌍따옴표("")로 감싸야함
JSON은 텍스트 형식이기 때문에 읽기 쉽지만, 파싱이 느리고 메모리 사용이 비효율적
기본 데이터 타입만 지원하기 떄문에 데이터 타입에 제약이 있습니다.
이러한 문제를 해결하기위해 BSON(Binary JSON) 형식 도입
JSON & BSON 타입
데이터를 가져오거나, 내보내는 경우에 따른 효율적 데이터 형식이 존재
MongoDB의 데이터는 BSON 형태로 저장되고, 보통 읽기 쉬운 JSON 형태로 출력 두 형식의 특징이 다르기 때문
JSON - mongoimport, mongoexport
BSON - mongorestore, mongodump
(1) Export
- mongodump (BSON 형식)
mongodump --url "<Atlas Cluster URI>"- mongoexport (JSON 형식)
mongoexport --url "<Atlas Cluster URI>"
--collection=<collection name>
--out=<filename>.json(2) Import
- mongorestore (BSON 형식)
mongorestore --url "<Atlas Cluster URI>"
--drop dump- mongoimport (JSON 형식)
mongoimport --url "<Atlas Cluster URI>"
--drop=<filename>.json2. CRUD
(1) CREATE
A.INSERT
- insert : 단일 또는 다수의 Document를 입력할 때 사용
- insertOne: 한 개의 document 생성
- insertMany : lisft of documnet 생성
insertOne, insertMany는 몽고버젼 3.2 이후에 추가된 명령입니다. 3.2버전 이후에는 insertOne(), insertMany() 명령 사용을 권장합니다.
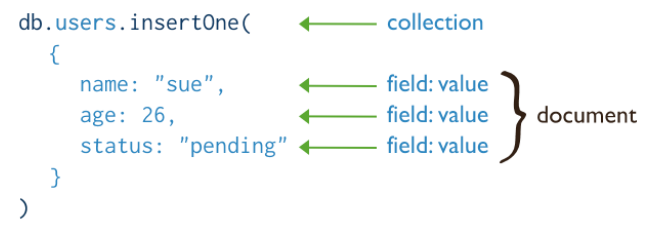
- 각 도큐먼트는 고유한 _id 값을 가지고 있어야합니다.
- 도큐먼트를 추가할 때, _id 값을 설정하지않았으면 자동적으로 _id 필드가 생성되고 값에 ObjectId 타입이 할당되어집니다.
INSERT 명령을 실행하면, 주어진 도큐먼트 배열의 인덱스 순서로 작업이 실행됩니다. 혹시나 오류가 발생하면 작업은 중단되어집니다.
그러나 ordered를 추가하면, 순서에 상관없이 고유한_id를 가진 도큐먼트는 모두 컬렉션에 삽입됩니다.
B.SAVE
같은 데이터가 있으면 덮어쓰고 없다면 INSERT한다
(2) READ

- find(query, projection) : 컬렉션 내의 모든 다큐먼트를 조회합니다.
finde({}) : {}중괄호 안에 필드와 해당값을 넣는다면 조건문으로 사용할 수 있습니다.
projection : query 결과 값을 보여줄 때 표시할 필드를 지정하는 것입니다.
- findOne
(3) UPDATE
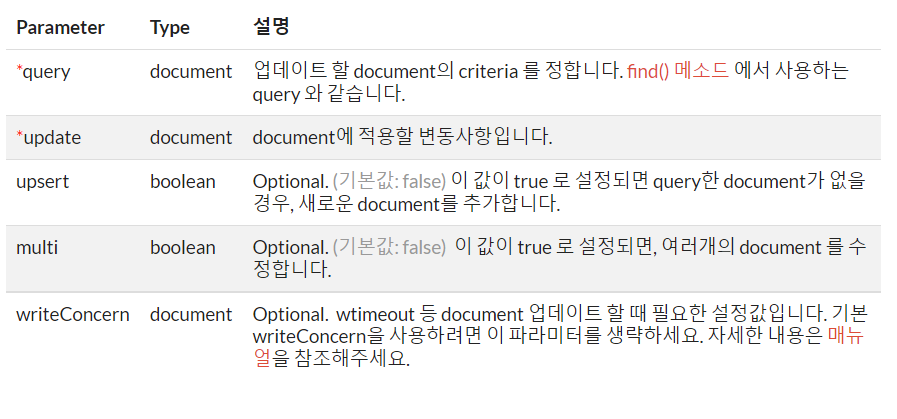
db.user.update({
query,
update,
{
upsert: <boolean>,
multi: <boolean>,
writeConcern: <document>
}
})
- updateOne : 주어진 기준에 맞는 다수의 도큐먼트 중 첫 번째 도큐먼트 하나만 업데이트
- updateMany : 쿼리문과 일치하는 모든 도큐먼트 업데이트
- 값 바꾸기
db.user.update({'바꿀필드':'바꿀값'}, {'바꿀필드':'바꿔진값'})update 첫 번째 인자에는 update하고 싶은 필드와 값을 입력하고 두 번째 인자에는 해당 필드에 바꿀 값을 입력한다
- 특정 필드의 값 변경
db.user.update({'바꿀필드':'바꿀값'}, {$set: {'다른필드': '다른값'}})바꿀필드에 바꿀 값이 있는지 검색하고, 해당 문서에 다른필드가 있다면 다른값으로 바꾼다. 만약에 다른 필드가 없다면 해당 필드를 추가하게 된다
- 특정 필드 삭제
db.user.update({'바꿀필드':'바꿀값'}, {$unset: {'삭제할필드': '삭제할 값'}})(4) DELETE

-
deleteOne
주어진 기준에 맞는 다수의 도큐먼트 중 첫 번째도큐먼트 하나를 삭제 -
deleteMany
쿼리문과 일치하는 모든 도큐먼트 삭제 -
drop
컬렉션 삭제하기위해 drop 이라는 명령어 사용
3. 비교 연산자
{<field>:{<operator>:<value>}}
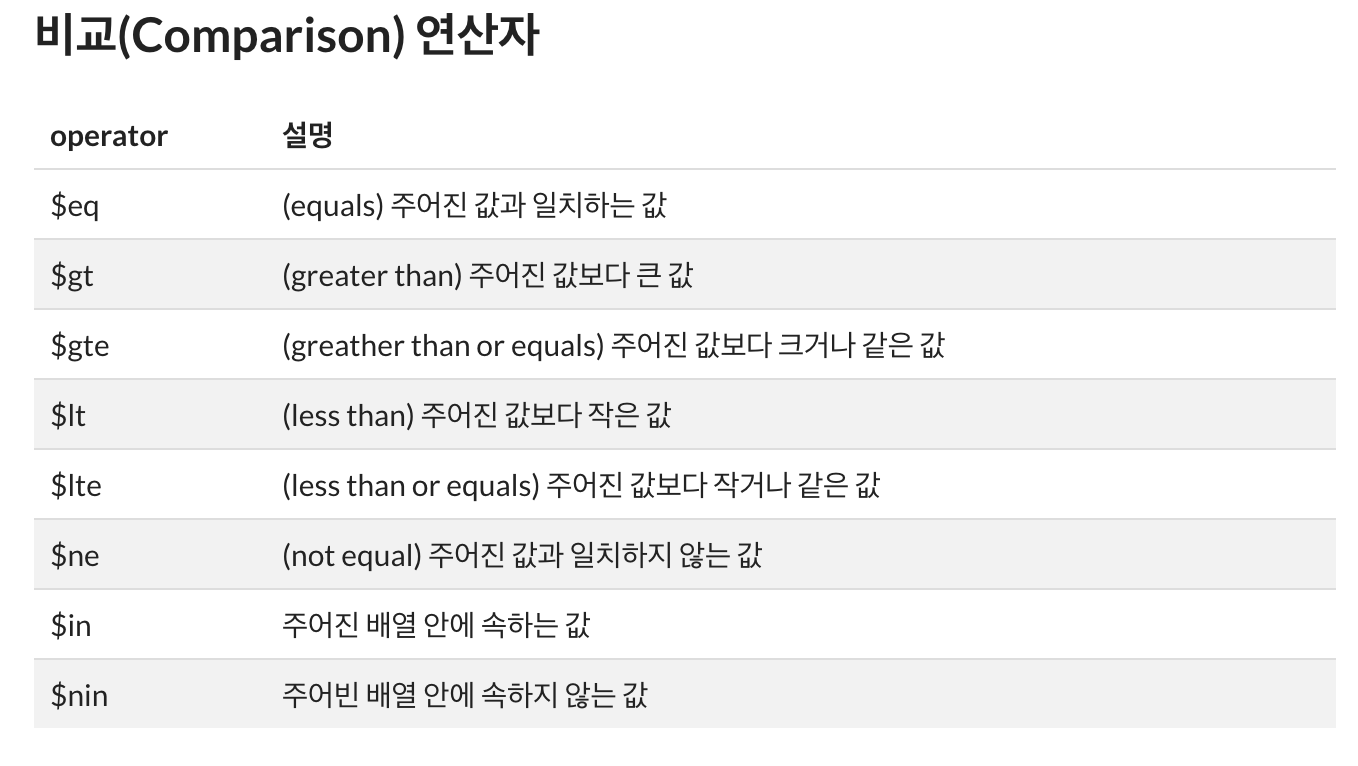
4. 논리 연산자
{"$operator":[{<clause1>}, {<clause2>},...]}$and는 연산자가 지정되어있지않은 경우에 기본 연산자로 사용됩니다.

5. 표현 연산자
$expr을 사용하여 쿼리 내에서 집계 표현식을 사용할 수 있습니다.- 이를 사용해 변수와 조건문을 사용할 수 있습니다.
- 같은 도큐먼트 내의 필드들을 서로 비교할 수 있습니다

6. 배열 연산자
(A)push
- 배열의 마지막 위치에 엘리먼트에 넣습니다.
- 배열이 아닌 필드에 사용했을 경우, 필드의 타입을 배열로 바꿉니다.
(B)all
{<array field>:{"$all":<array>}}- 지정된 배열 필드의 배열 순서와 관계없이 지정된 모든 요소가 포함된 모든 도큐먼트들이 있는 커서를 반환합니다.
(C)size
{<array field>:{"$size":<number>}}- 지정된 배열 필드가 주어진 길이와 정확히 일치하는 모든 도큐먼트들이 있는 커서를 반환합니다.
출처
https://www.fun-coding.org/mongodb_basic4.html
http://semantics.kr/%EB%AA%BD%EA%B3%A0db%EC%9D%98-%EB%8D%B0%EC%9D%B4%ED%84%B0-%EC%88%98%EC%A0%95%ED%95%98%EA%B8%B0-update-documents-in-mongodb/
https://jdm.kr/blog/18
