
개요
본 블로그 포스팅은 수도권 ICT 이노베이션 스퀘어에서 진행하는 AI 핵심 기술 집중 클래스의 자연어처리(NLP) 강좌 내용을 필자가 다시 복기한 내용에 관한 것입니다.
1. 모듈화
그간의 포스팅을 통해 자연어 처리(NLP, Natural Language Processing)를 수행하는데 있어 언어모델에 데이터를 입력하려면
Text Preprocessing(텍스트 전처리), Data Preprocessing(데이터 전처리)를 수행해야함을 확인할 수 있으며,
특히 전처리 부분에 있어 사용하는 데이터의 foramat이 정말 자유롭기에 모듈화 하기 어려운 부분이 있다.
그래도 최대한 나름대로 모듈화 해서 사용하는것이 편하기에 이를 https://github.com/tbvjvsladla/ASH_NLP_lacture 에 업로드 하였다.
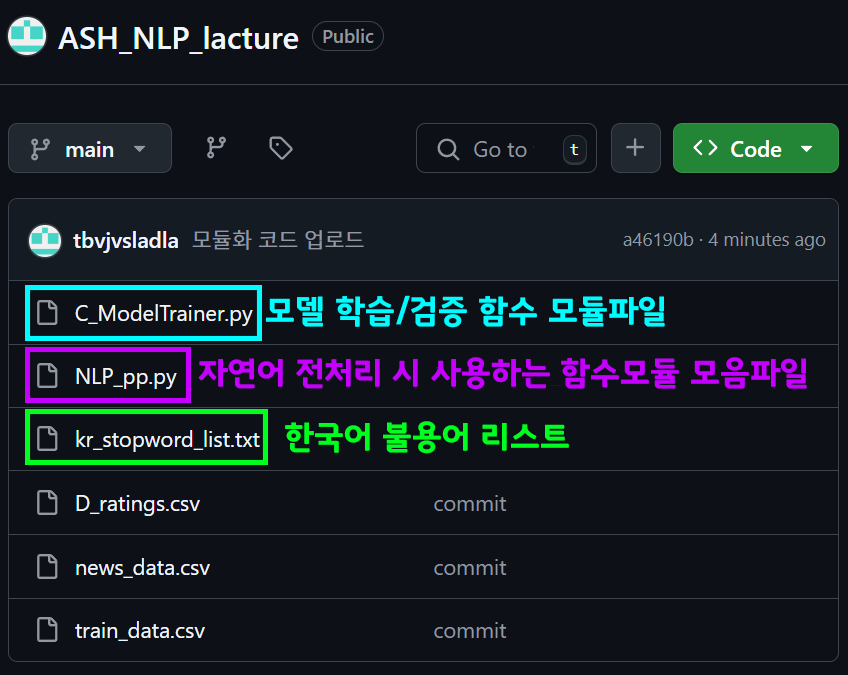
업로드한 파일 중 NLP_pp.py은 텍스트 및 데이터 전처리에 사용되는 함수를 모은 것으로
함수 중에 val_~~으로 시작하는 함수군이 있다.
이 함수군은 딱히 텍스트 및 데이터 전처리 과정에 직접적으로 개입하는 함수는 아니고
여러가지 결과물을 중간에 확인하기 위한 함수이다.

예를 들어 위 사진처럼 print구문만 존재하는 함수라 보면 된다.
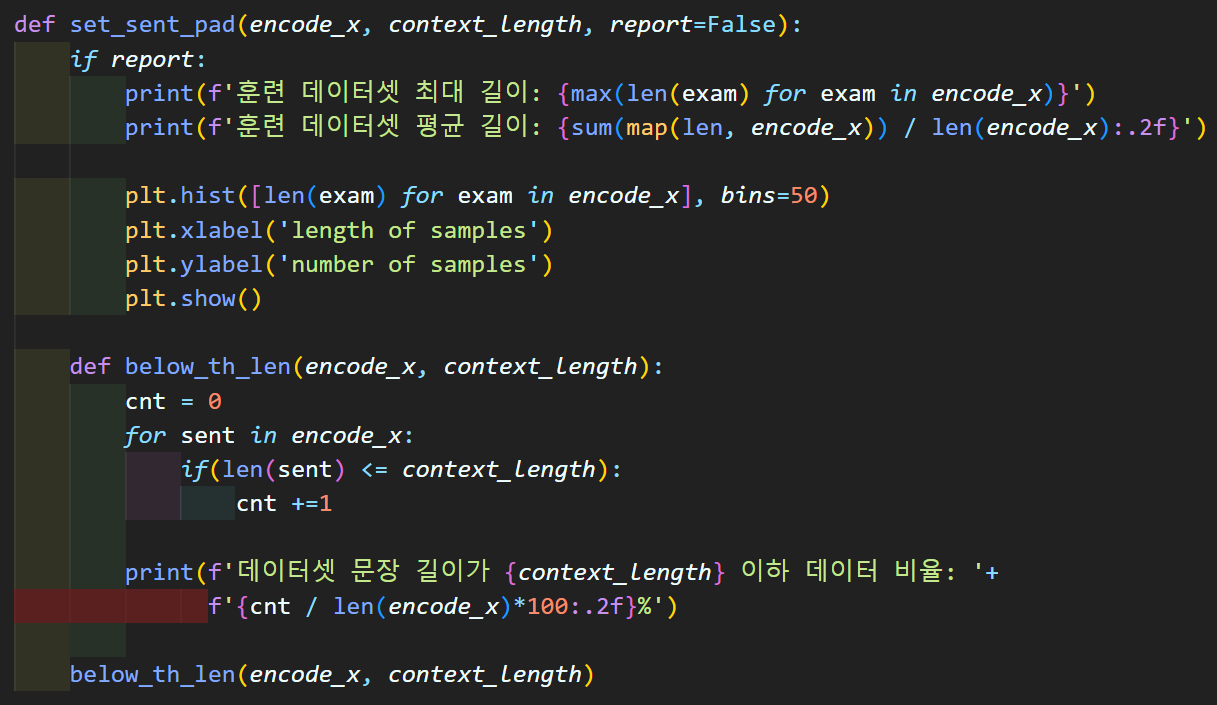
그 다음으로 set_~~으로 시작하는 함수군이 있다.
이 함수군은 텍스트&데이터 전처리 과정에 필수적으로 사용되는 함수인데
report옵션이 있어서 전처리 결과물 확인 유/무를 선택할 수 있는 함수이다.
예들들어
위 함수를 실행할 때 report의 기본옵션은 False이지만 이를 True로 바꾸면 결과물을 출력하는데 필요한 정보를 추가로 확인할 수 있다.
2. 모듈화 코드 실습
위 설계한 NLP_pp.py 코드를 바탕으로 실제 실습을 진행하도록 하겠다.
2.1 예제 데이터셋
코드 실습에 사용한 데이터셋은 spam_SNS.csv로
https://github.com/tbvjvsladla/ASH_NLP_lacture/blob/main/spam_SNS.csv
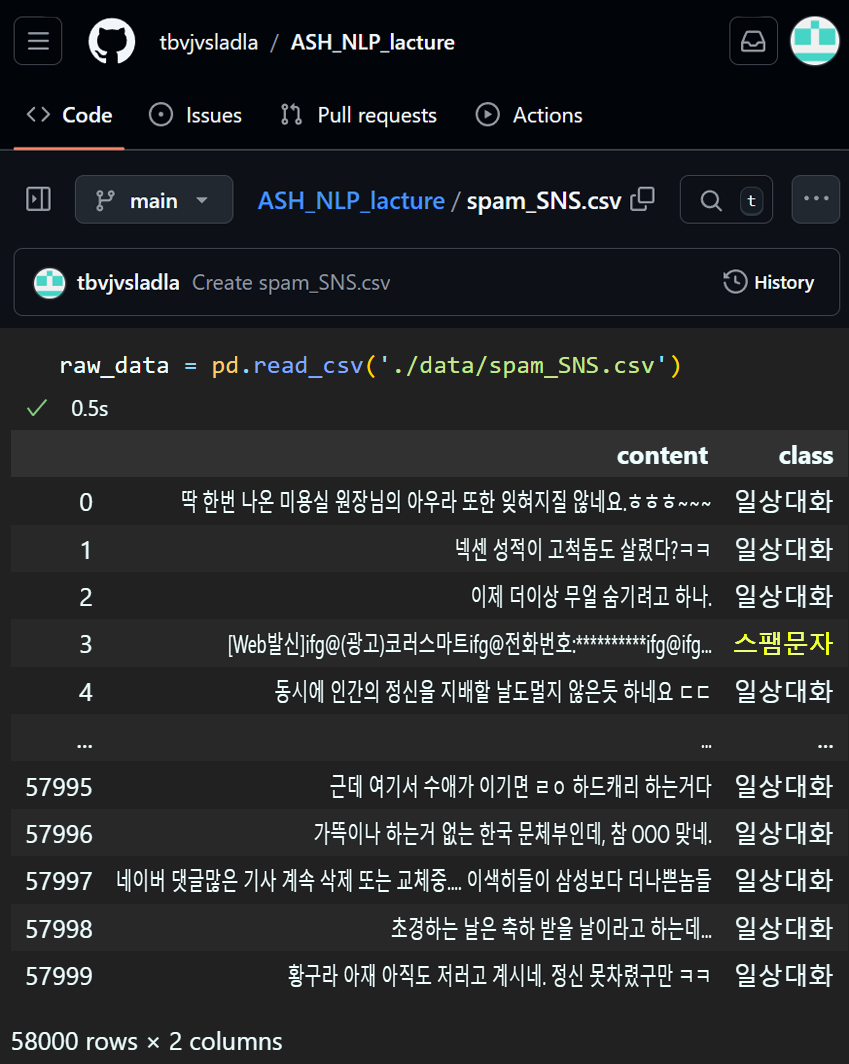
데이터셋의 구조는 총 58,000개의 데이터가 존재하고 이 중 스팸문자 / 일상대화(문자)가 각각 반반씩 섞여있는 데이터셋이다.
해당 데이터셋은 한글 버전의 Spam Detector를 개발할 때 사용하려 제작한 파일이다.

spam_SNS.csv는 인터넷에서 구할 예제 - 스팸 메일 분류의 데이터셋이 영문버전이어서 한글버전에 데이터가 더 많이 포함된 버전이라 보면 된다.
라이브러리 import
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt# 텍스트 및 데이터 전처리 함수모음 import
from NLP_pp import *설계한 NLP_pp.py 모듈파일은 클래스 없이 def로 선언한 함수파일만 다 있기에 아에 전체 불러오기 옵션인 *로 import한다.
데이터 전처리 함수
# 데이터에 결측치 혹은 중복치가 있을 때 이를 제거하는 전처리
raw_data = df_cleaning(raw_data, 'content')NLP_pp.py에 모듈화한 첫번째 함수는 df_cleaning로 입력한 column에 대하여 결측치 및 중복치가 있으면 해당 row를 모두 삭제하는 함수이다.
import re
# 한글, 영어(소문자, 대문자), 숫자
p1 = re.compile(r'[^가-힣a-zA-Z0-9\s]')
# 한글 자모 데이터
p2 = re.compile(r'[ㄱ-ㅎㅏ-ㅣ]+')
# 개행문자 + 하나 이상의 공백문자
p3 = re.compile(r'\n|\s+')
def regex_sub(origin_sent):
clean_text = p1.sub(repl=" ", string=origin_sent)
clean_text = p2.sub("", clean_text)
clean_text = p3.sub(" ", clean_text)
return clean_text그 다음으로 특수문자나 공백같은 것을 정리하는 함수의 경우
일반화 하기 어려운 부분에 속하기에 NLP_pp.py에는 포함시키지 않았다.
regex_sub는 별도로 설계해야 하는 함수이다.
텍스트 전처리 - 토크나이저 + 불용어 제거
from mecab import MeCab #한글 단어 토크나이저
#mecab 형태소 분석기 인스턴스화
word_tokenizer = MeCab()
# 토큰화 수행
tokenized_x_data = tokenize(raw_x_data, word_tokenizer)word_tokenizer는 다양한 라이브러리가 존재하기에 토크나이저를 인스턴스화 하면 이를
NLP_pp.py에 함수화한 tokenize를 사용하여 문서를 단어단위로 토큰화 처리한다.
# 깃허브에 있는 stopwordlist.txt파일 다운
url = 'https://raw.githubusercontent.com/tbvjvsladla/ASH_NLP_lacture/main/kr_stopword_list.txt'
# 불용어 데이터셋 다운로드
stopword_list = download_stopword_list(url)
# 토큰화 처리한 '기사 본문' 데이터셋의 불용어 제거
r_t_x_data = remove_stopword(tokenized_x_data, stopword_list)불용어 제거는 영어 버전의 불용어 제거는 nltk라이브러리로 제거를 하지만
한글버전은 앞서 https://github.com/tbvjvsladla/ASH_NLP_lacture 에 업로드한 한글 불용어 리스트인 kr_stopword_list.txt을 URL로 다운받고
일르 불용어 처리하는 코드를 수행한다.
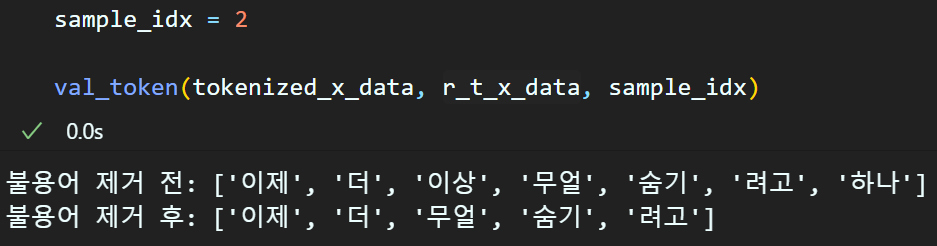
수행결과는 val_token 검증함수로 확인 할 수 있다.
텍스트 전처리 - 한글 자모 분리
# 불용어 제거된 데이터를 자모 데이터로 분리
jamo_x_data = decompose_jamo(r_t_x_data)한글 데이터셋은 FastText 기반으로 워드임베딩을 수행할 시 한글단어 한글 자모 분해 및 복원과정이 필히 요구되기에
word_to_jamo, jamo_to_word와 이 함수를 콜백하여 사용하는 decompose_jamo를 NLP_pp.py에 포함시켯다.
텍스트 전처리 - 희소단어 제거 함수
rare_th = 3 #희소단어의 등장 빈도를 결정하는 파라미터
tot_vocab_cnt, rare_vocab_cnt = set_rare_vocab(word_counts, rare_th, report=True)단어장 생성 후 희소단어 단어장 배제
과정을 수행하는 함수는 set_rare_vocab으로
해당 함수는 report 옵션을 True로 설정하면

단어장에 포함된 희소단어 총 개수 및 해당 희소단어가 등장하는 빈도 등의 정보를 출력한다.
텍스트 전처리 - 단어장 생성 및 검증 함수
생성한 단어장을 정수인코딩을 하려면 먼저
스페셜 토큰을 단어장에 추가해줘야 한다.
spec_token = ['<PAD>', '<UNK>']위 설정한 스페셜 토큰을 바탕으로
word_to_idx, idx_to_word = set_word_to_idx(spec_token, vocab, report=True) NLP_pp.py 에 포함한 set_word_to_idx 함수를 구동하면
{단어장 : 단어장의 인덱스} 딕셔너리 데이터인
word_to_idx와 이것의 거울쌍 딕셔너리인 idx_to_word를 생성한다
이때 report=True 옵션을 사용하면

위와 같이 스페셜 토큰을 포함하여 총 관리되는 단어의 정보를 확인할 수 있다.
텍스트 전처리 - 정수인코딩 및 인코딩 검증
# 데이터셋의 정수 인코딩 수행
e_x_train = text_to_sequences(x_train, word_to_idx)
e_x_val = text_to_sequences(x_val, word_to_idx)
e_x_test = text_to_sequences(x_test, word_to_idx)데이터셋의 정수인코딩은 text_to_sequences함수를 통해 수행하며
수행결과를 확인하려면 val_encode_decode함수를 구동한다.
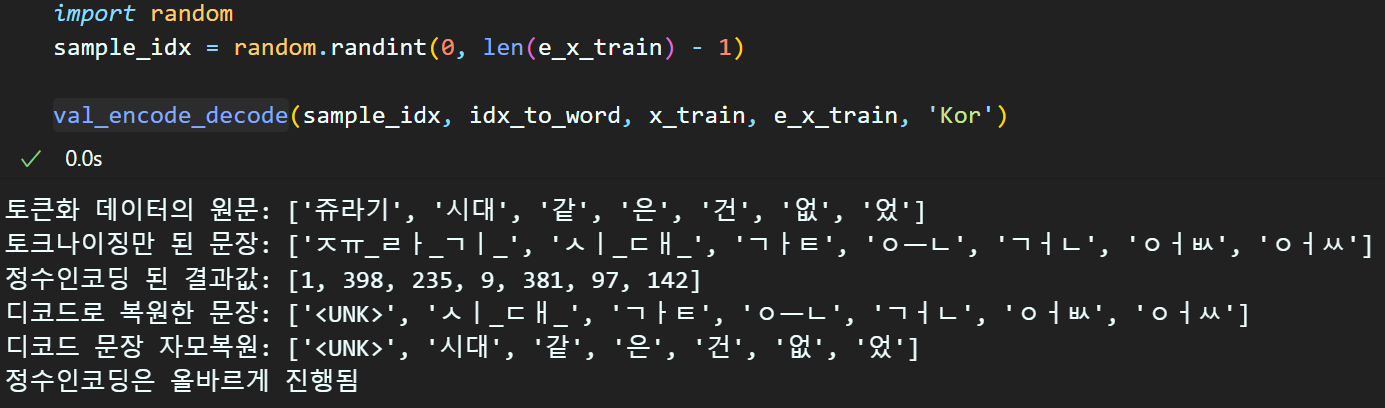
단어장에 배제된 희소단어는 UNK로 매핑되며,
만약 단어장이 자모단위로 분해되어 있을 시 Kor옵션을 활성화하면
분해된 자모를 단어로 복원하여 중간 결과물에 대한 가독성을 높였다.
그리고 마지막으로 희소단어 스페셜 토큰처리
범주형 데이터 정수형 데이터의
인코딩, 디코딩 과정이 잘 수행되는지 확인되는 결과물도 디스플레이한다.
텍스트 전처리 - 문장 패딩 분석함수 및 패딩 실행 함수
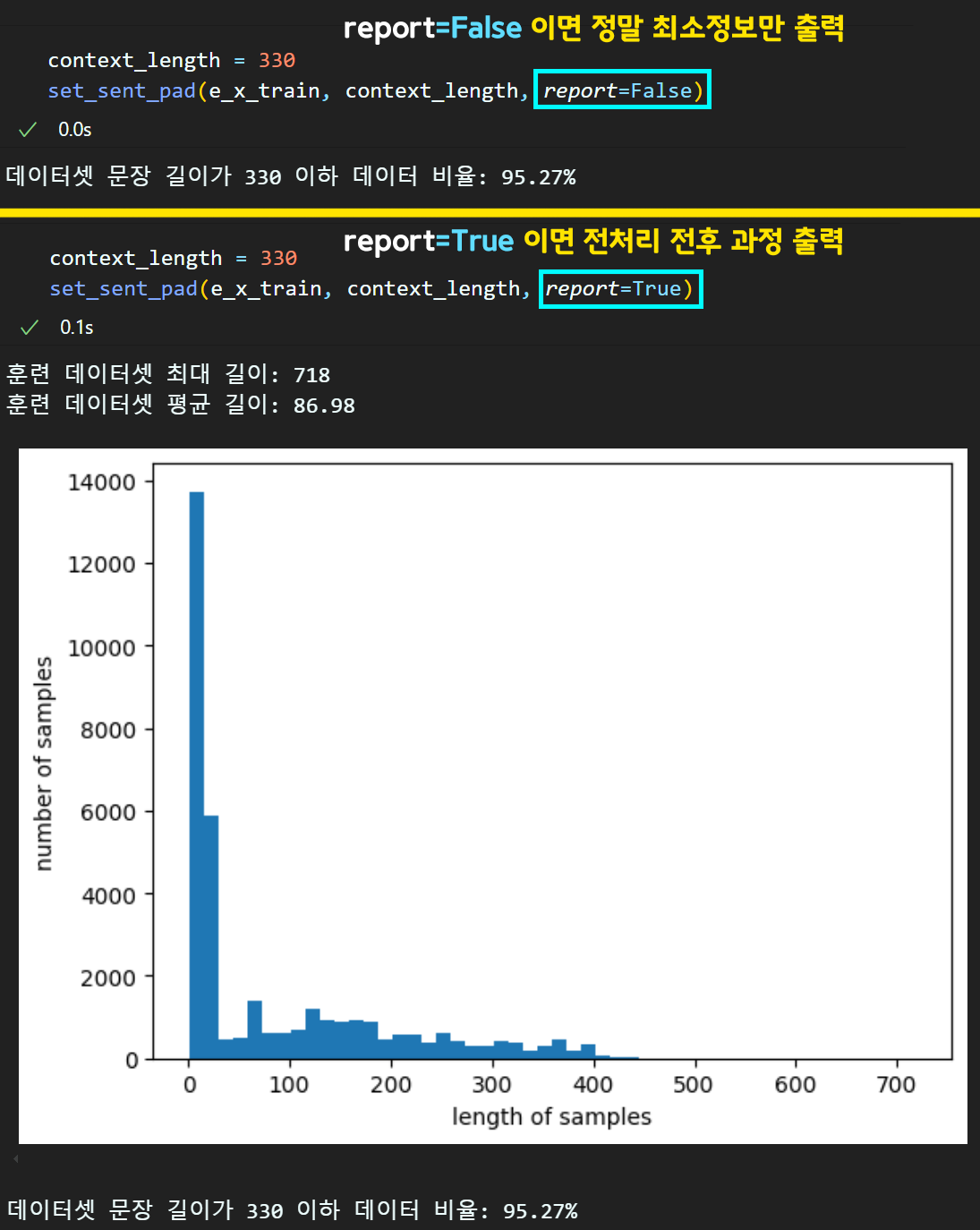
# 문장 패딩을 위한 하이퍼 파라미터 설정
context_length = 330
# 설정한 하이퍼 파라미터에 대한 분석 함수 수행
set_sent_pad(e_x_train, context_length, report=True)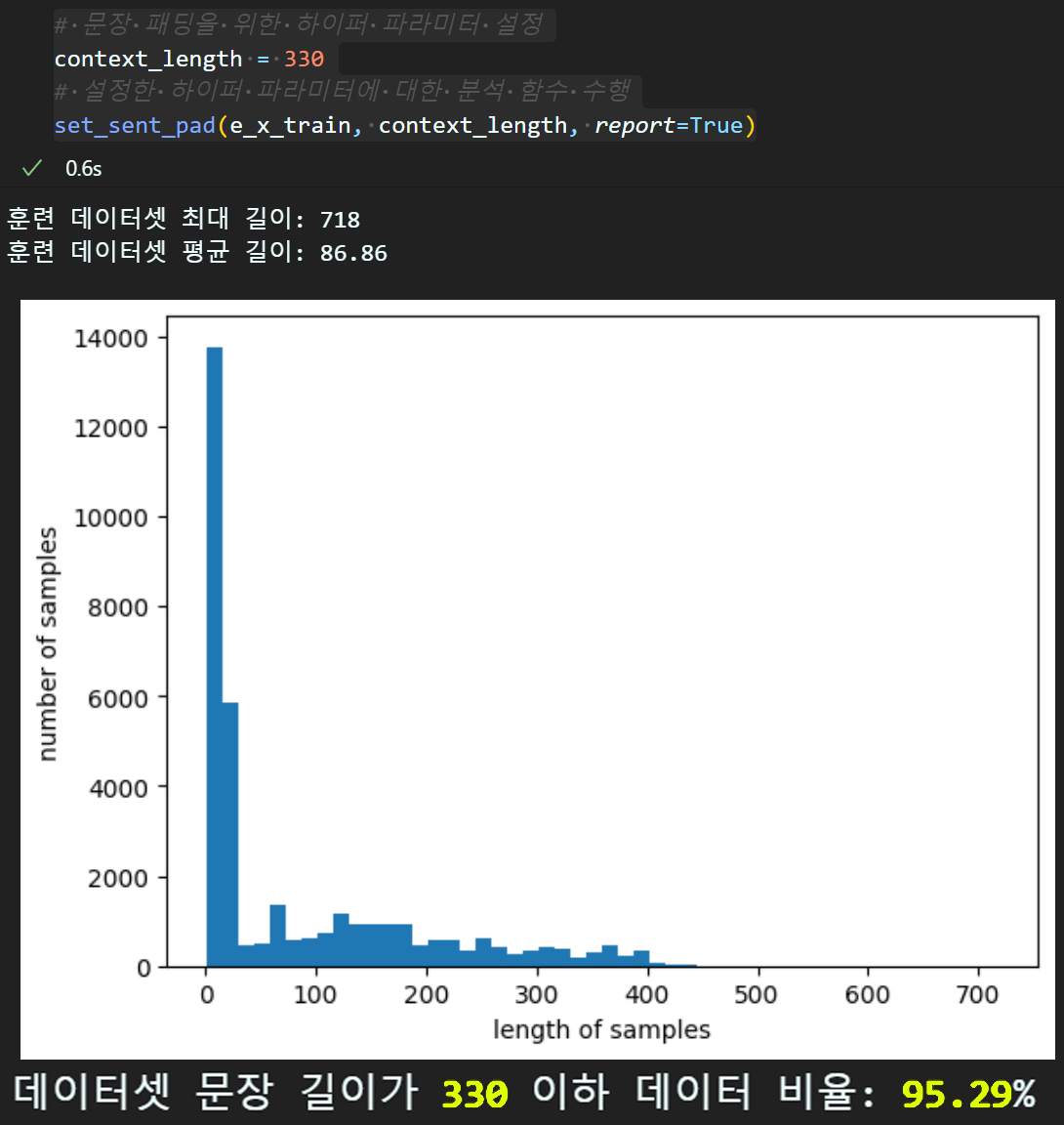
문장 패딩을 할 때는 주요 설계 하이퍼 파라미터인 context_length를 지정해야 하고, 해당 context_length을 넘어가지 않는 길이가 짧은 문장이 전체 데이터에서 몇 퍼센트인지 확인하는 분석함수인
set_sent_pad 함수를 구동한다.
위 분석결과가 타당하면
val_pad_shape(padded_x_train, "훈련")
val_pad_shape(padded_x_val, "검증")
val_pad_shape(padded_x_test, "평가")val_pad_shape로 문장패딩을 수행하여 텍스트 전처리를 완료한다.
데이터로더 생성
마지막으로 문장패딩까지 완료한 정수(원핫)인코딩 데이터는
언어모델에 입력하여 학습/검증/평가를 수행하기 위해서는
Tensor데이터 형식으로 변경해야 하기에
이를 set_dataloader 함수로 수행한다.
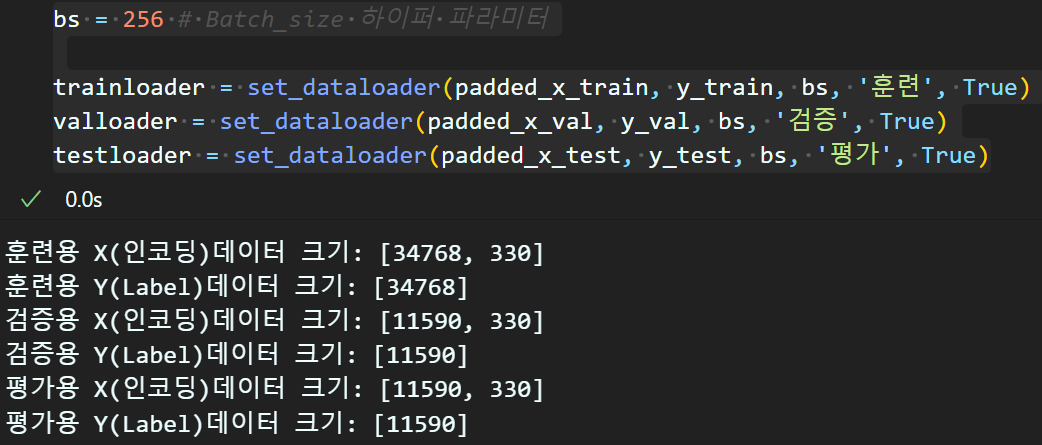
여기까지 NLP_pp.py에 대한 설명과 예제를 첨부했다.
NLP 전처리과정은 매번 코드를 전체 포함하여 설명함녀 포스트가 한없이 길어지기에
모듈화 및 코드 재사용성을 높여서 수행하는게 올바르다

츄라이 츄라이
