
개요
본 블로그 포스팅은 수도권 ICT 이노베이션 스퀘어에서 진행하는 AI 핵심 기술 집중 클래스의 자연어처리(NLP) 강좌 내용을 필자가 다시 복기한 내용에 관한 것입니다.
1. RNN 개요
RNN(Recurrent Neural Network)은 자연어 처리(NLP, Natural Language Processing) 계열에 있어서는 가장 기본적인 언어모델로
입력과 출력을 시퀀스 단위로 처리하는 시퀀스(Sequence)모델 이라 정의하고 있다.
이 시퀀스(Sequence)가 이전 포스트 NLP 전처리 시리즈에서 줄창 수행했던 문장패딩 후 마지막 결과물
이라고 보면 된다.
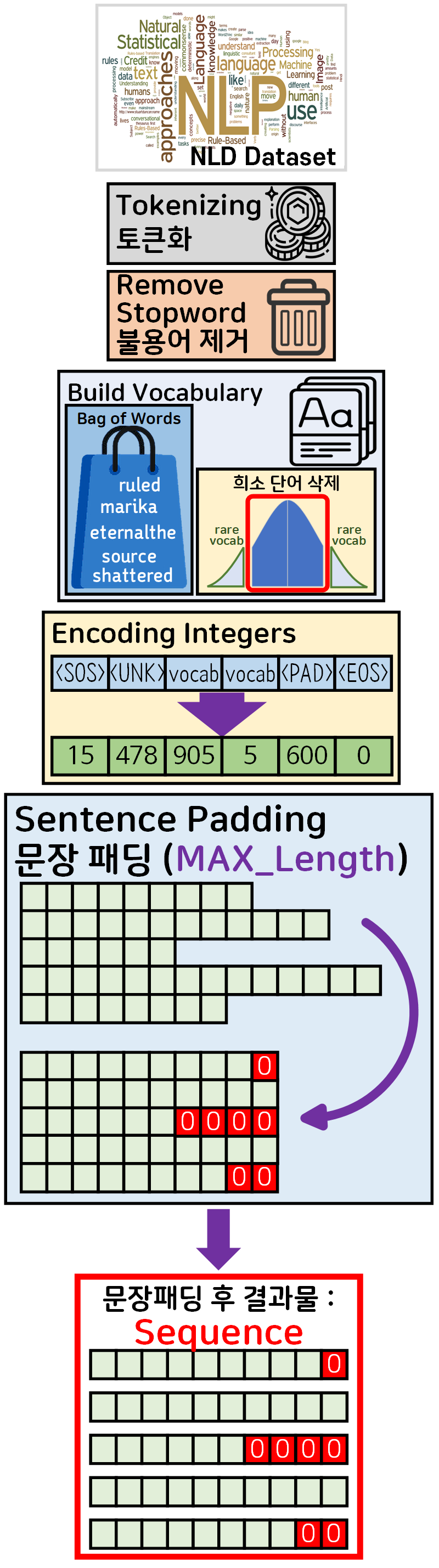
텍스트 전처리과정을 다시한번 복기하자면 위 단계을 다 수행하고 나온 최종 결과물이 Sequence 이다.
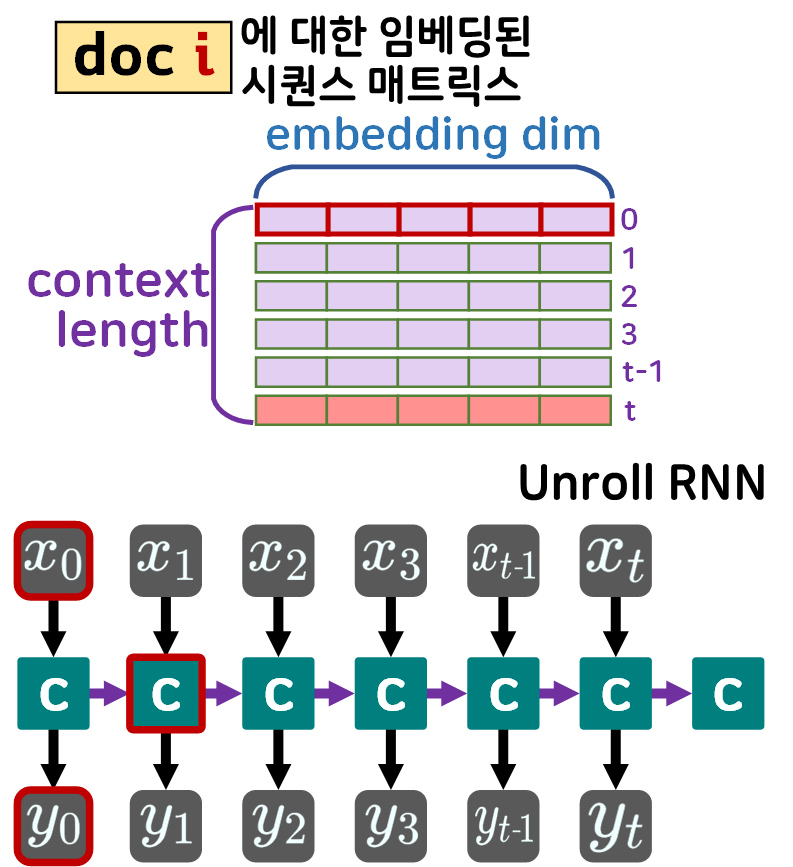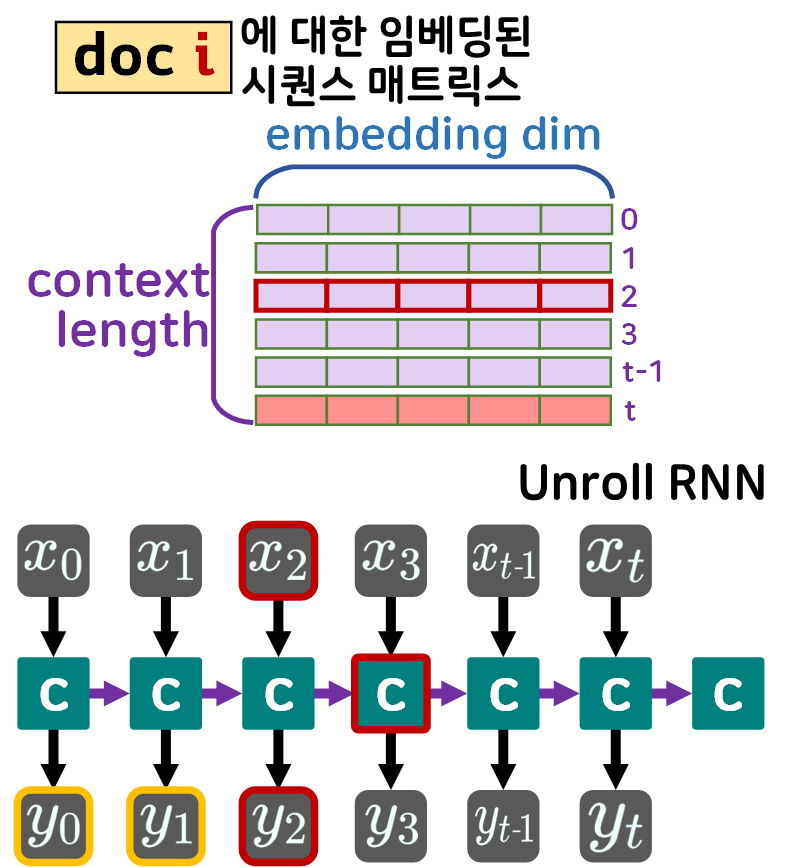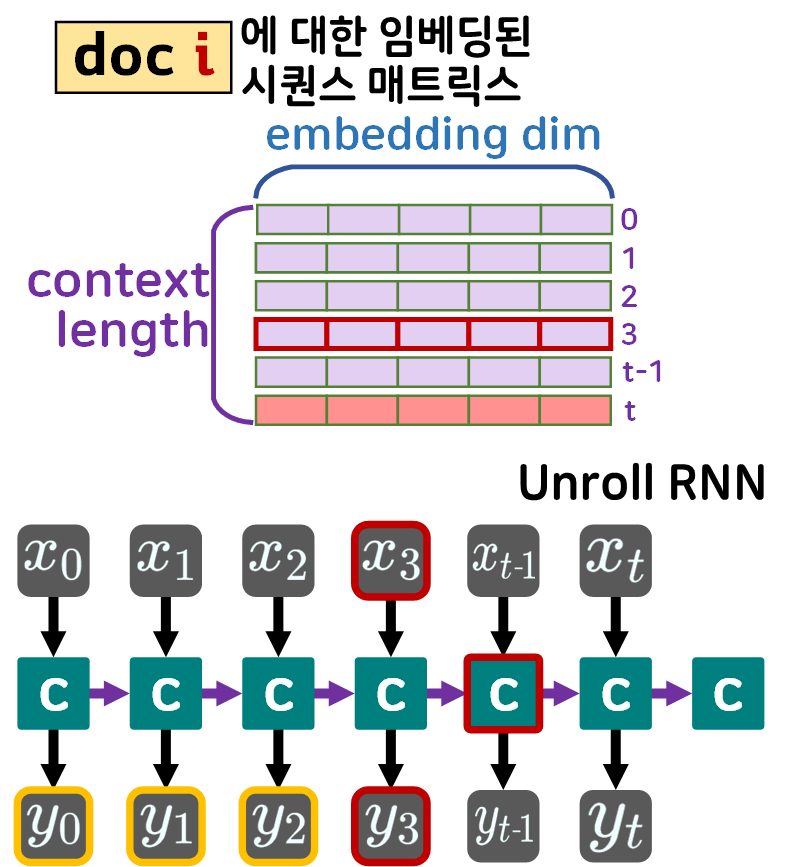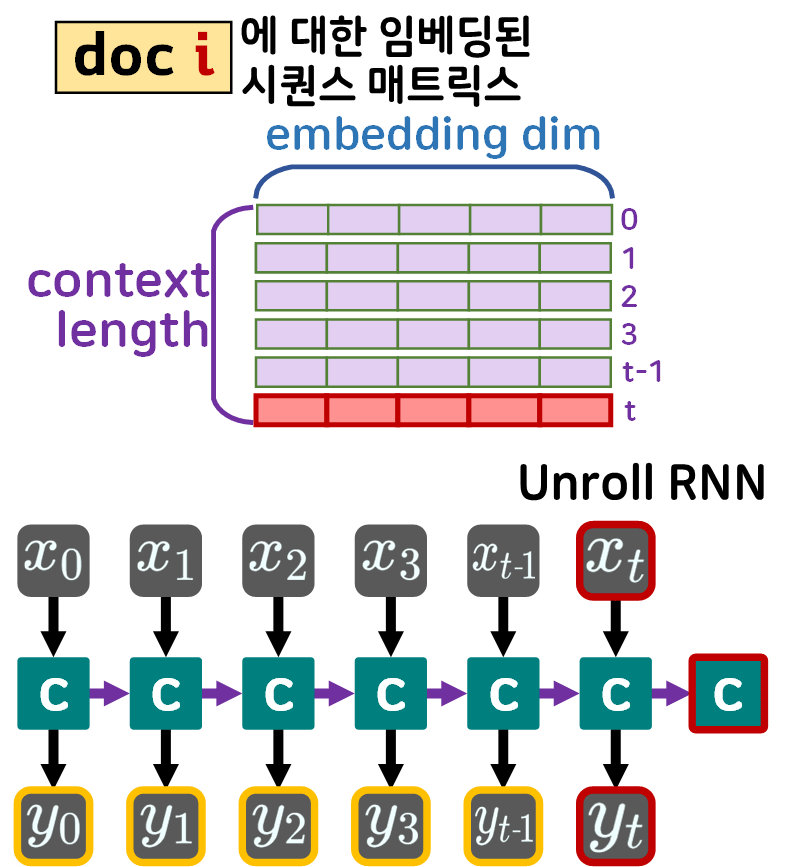
이 시퀀스단위로 언어모델이 정보를 처리하는 과정을 도식화 하면 아래와 같다.
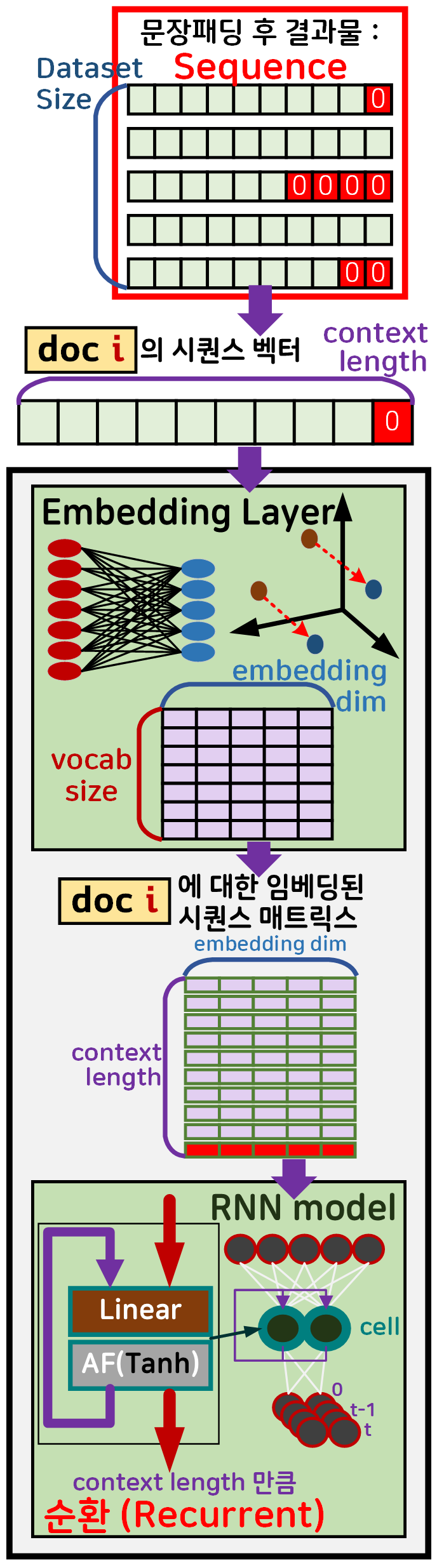
위 도식으로 RNN모델이 하나의 시퀀스를 처리하는 과정을 글로 표현하면 아래와 같다.
1) 문장패딩이 끝난 결과물은 (dataset_size, context_length)으로
하나의 document 시퀀스는 (1, context_length)이 된다
2) 이 document 시퀀스(1, context_length)를 언어모델의 임베딩 레이어에 입력하면
임베딩된 document 시퀀스가 되며 (context_length, embedding_dim)으로 시퀀스 내 단어가 단어간 유사도 정보를 갖춘 벡터로 확장됨
3) 임베딩된 document 시퀀스가 RNN에 입력되면 시퀀스 내 하나의 단어(임베딩된 단어벡터) (1, embedding_dim) 단위로 정보를 입력받아
hid Cell이 context_length 만큼 다음 단어를 입력 받으면서 동시에 순환(Recurrent)해
두가지 출력물 :
Output(context_length, hid_dim),
hid Cell(hid_dim)
을 발생시킨다
여기서 문제는 이 순환(Recurrent)이라는 요소가
GPU의 병렬처리로 반복되는 항목이 아닌
단순 for문 처럼 시간(t)단위로 반복되는 항목이기에
흔히 RNN에 대해 설명을 할때 시퀀스의 구성요소인 임베딩된 단어벡터를 time_stamp 단위로 입력 받는 형식으로 도식화 하여
아래의 unrolled Recurrent Neural Network로 RNN을 표현하는게 일반적이다.
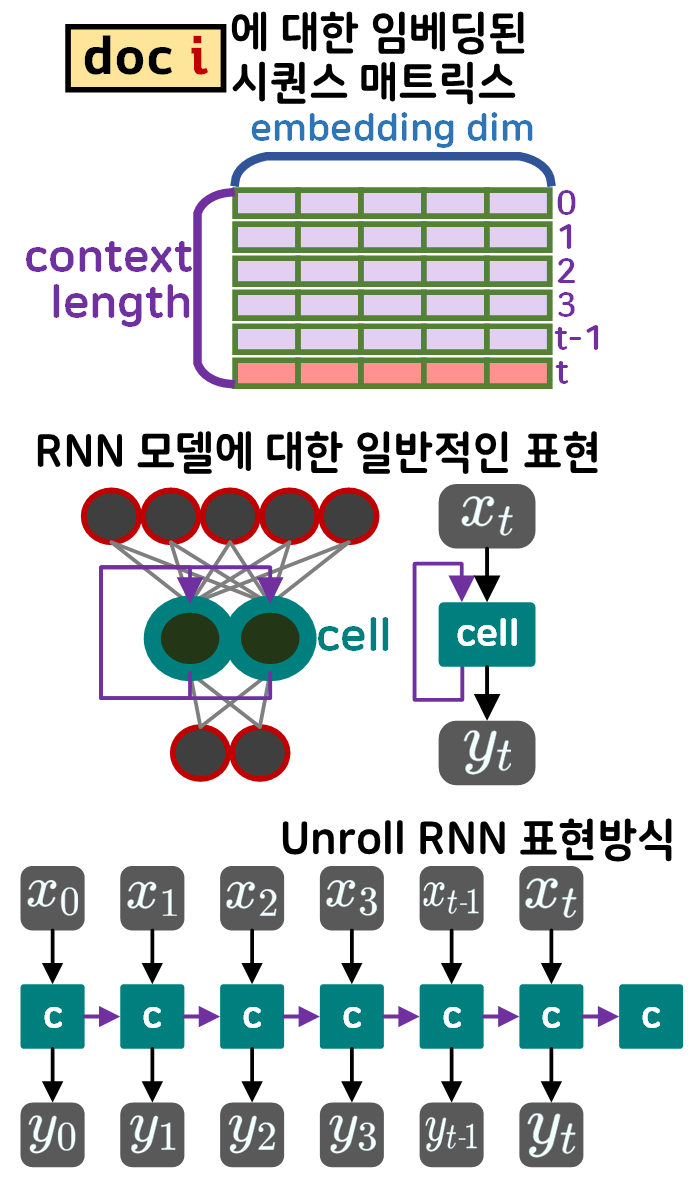
이 time_stamp라는 단위가 존재하니 RNN이 동작하는 방식을 gif로 표현한다면 아래와 같아진다.
time_stamp라는 개념으로 모델이 어떻게 동작하는지 이해했으니
이를 응용한 여러가지 잡기술용 RNN을 설계할 수 있다.
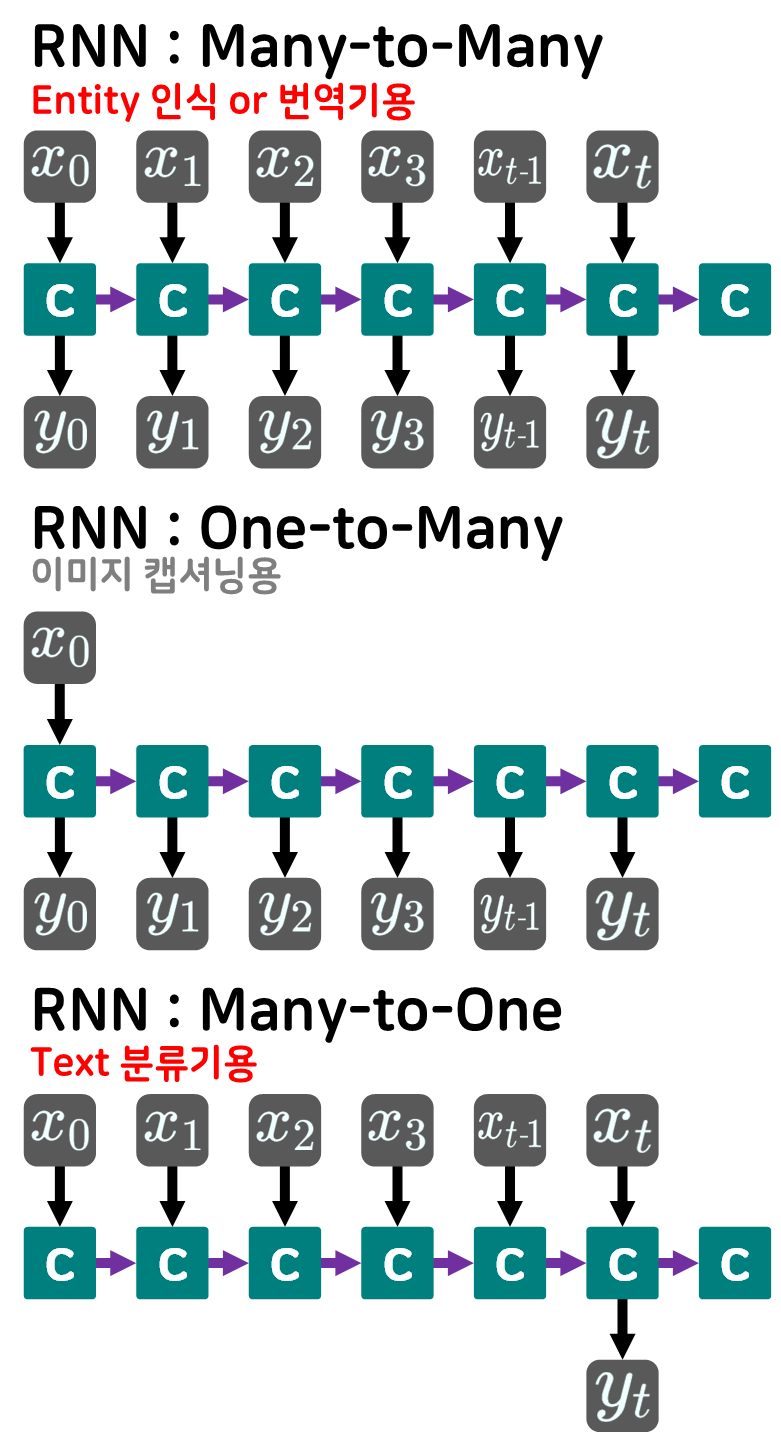
1) 매 time_stamp마다 입력()를 받으면서 동시에 출력()와 hid_cell을 출력함 : Many-to-Many
RNN : Many-to-Many옵션으로 동작할 때는 개체명(Entity)인식 혹은 번역기로 주로 사용되며
이때 RNN모델을 번역기로 사용할 때는 성능이 그다지 좋지 않기에 다른 언어모델(Seq-to-Seq, Transformer)을 주로 사용한다.
2) 맨 처음 time_stamp에서만 입력()를 받고, 매 time_stamp에서 출력()을 수행 : One-to-Many
RNN : One-to-Many는 이미지 캡셔닝용으로 사용되는데 그냥 이런게 있다.. 라고만 알아두면 된다.
3) 매 time_stamp 입력()를 받고 가장 마지막 time_stamp에서 출력()을 수행 : Many-to-One
RNN : Many-to-One은 텍스트 분류기로 사용되며, 이번 포스팅의 목적이자 RNN계열의 모델 만 구현해서 사용한다면 대체로 텍스트 분류기로 이용한다.
1.1 RNN의 출력 : Output, Hidden
이제 여기서 이해하기 어려운 부분인 RNN의 두개 출력
Output, Hidden이 어떤 데이터 구조를 가지고 출력되는지를 이해해야 한다.
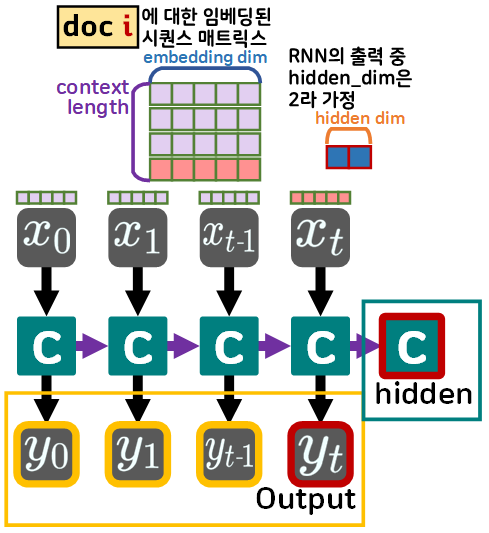
우선 첫번째로 출력 는 이전 time_stamp의 출력인 를 모두 가져오는 특성이 있다.
이를 그림으로 표현하면
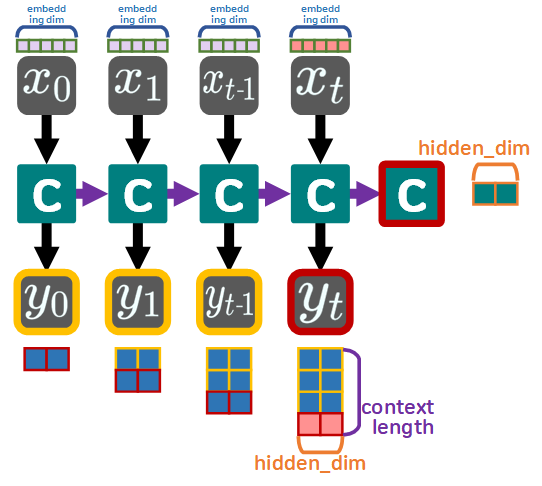
위 사진처럼 입력되는 는 임베딩된 시퀀스를 단어벡터 단위로 쪼개서 입력받기에
하나의 는 (embedding_dim) 1차원 벡터가 입력되고
이에 는 이전 시점(time_stamp)의 out을 누적해서 업데이트 되기에 가장 마지막 출력인
는 (context_length, hid_dim)가 된다.
그리고 또다른 출력물인 Hidden은 1차원 벡터인 (hid_dim)의 형태로 출력된다
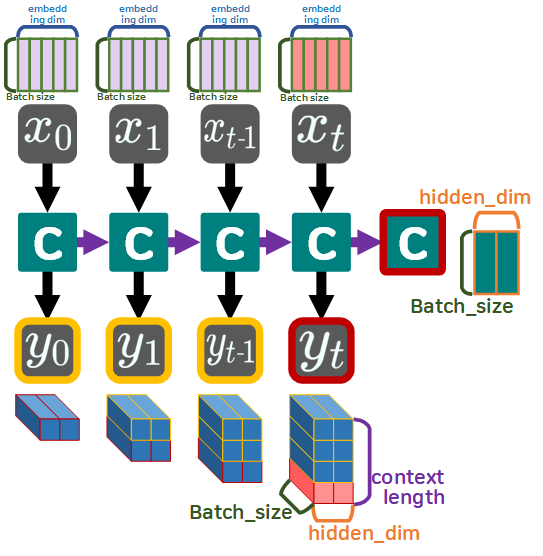
이제 여기서 Batch_size라는 개념이 도입된다.
모든 딥러닝 모델은 Batch_size라는 개념이 도입되어 병렬처리가 수행되니 이 정보가 포함된 출력물이 생성되어야 한다.
이제 여기서 num_layers라는 옵션이 하나 더 포함된다.
이것은 Hidden cell이 지금까지는 1층의 그림으로 표현했지만
실제로는 n개의 층으로 설계가 가능하다
(통상 1층이지만 아무튼 n개의 층으로 설계가 가능하다)
그래서 num_layers 옵션까지 고려하여 최종 출력물의 차원에 대해 다시 설정해야 한다.
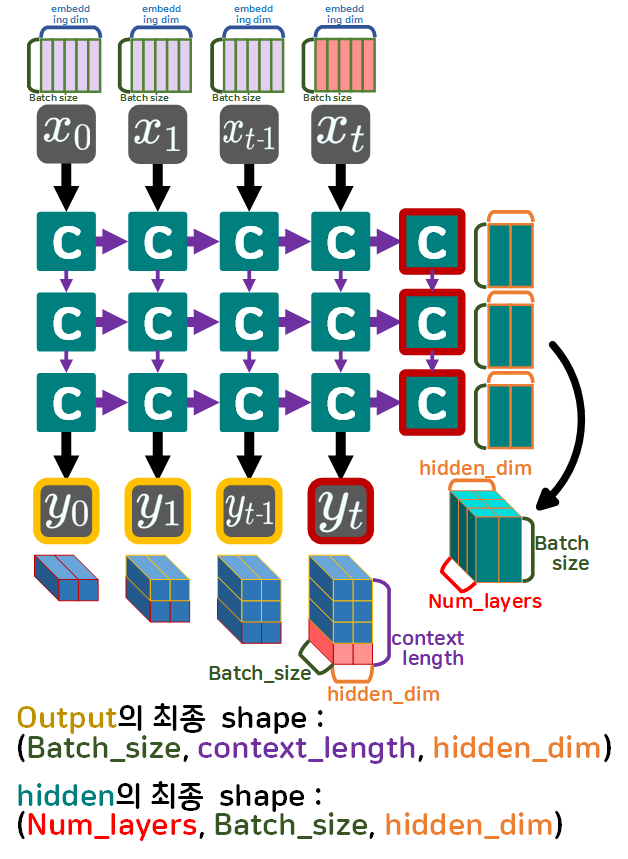
따라서
입력 의 차원 : (Batch_size, context_length, embedding_dim)
출력 차원 : (Batch_size, context_length, hid_dim)
hidden 차원 : (num_layers, Batch_size, hid_dim)
이렇게 입/출력 차원을 정리할 수 있다.
1.2 nn.RNN
이제 코드로 RNN을 사용해보려면 Pytorch 라이브러리의
nn.RNN이 어떤 인자값을 받아들이는지 확인해야 한다.
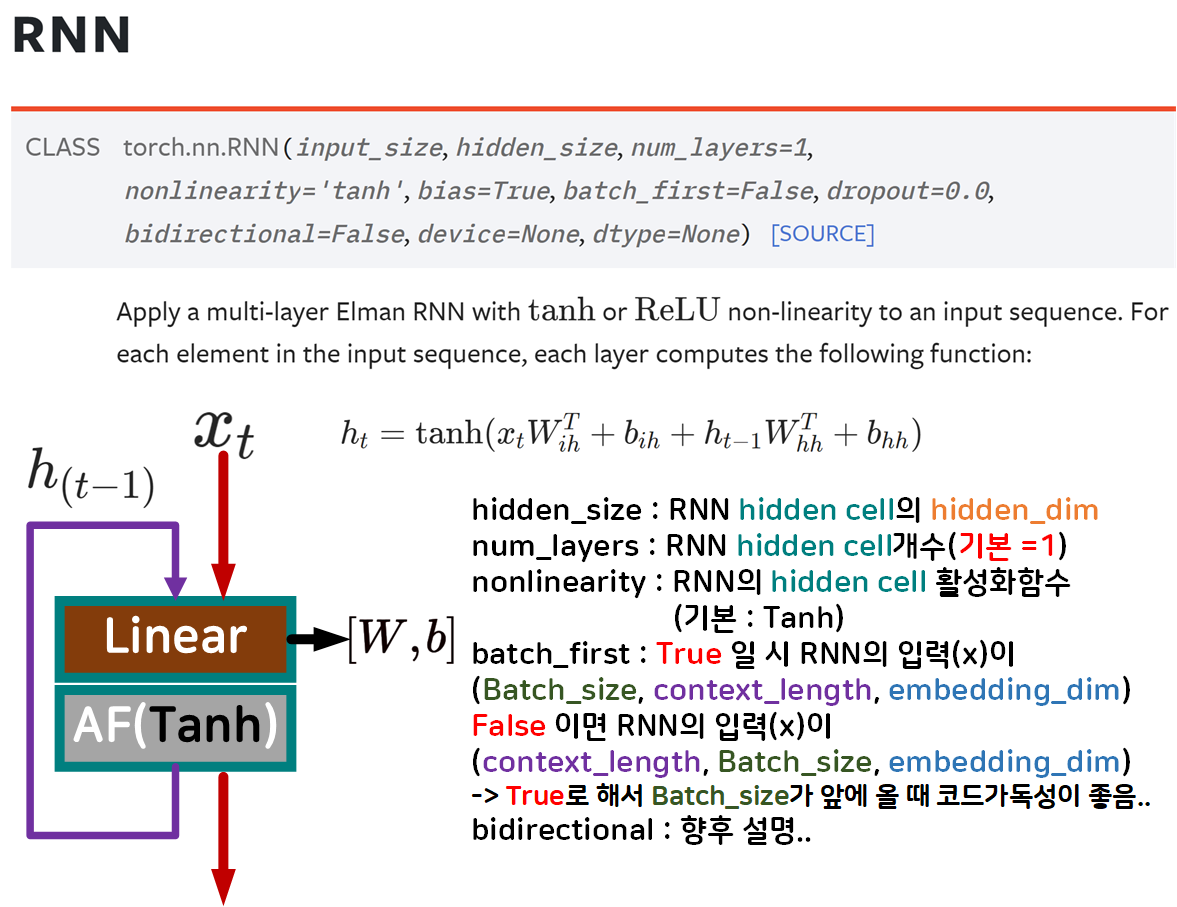
nn.RNN에서 중요하게 다룰만한 인자는 총 6개로
input_size, hidden_size 이거는 모든 레이어에 공통으로 사용되는 인자값이고
나머지 num_layers, nonlinearity, batch_first, bidirectional이 있는데
num_layers는 앞서 hidden, output의 차원을 설명하면서 지정하는 옵션임을 설명했다.
batch_first는 default는 False이지만 되도록이면 True로 설정해서
input()와 output()의 차원 순서를 Batch_size를 맨앞에 두는게 코드가독성에 이점이 많다
nonlinearity는 RNN의 레이어 구성에 사용되는
Activation Function을 지정할 수 있는데
초기에는 sigmod를 사용했고, nn.RNN에서는
ReLU, Tanh 둘 중 하나만 선택할 수 있게 옵션이 바뀌었는데
통상적으로 RNN계열 모델(LSTM, GRU)는 대체로
Tanh를 사용한다.
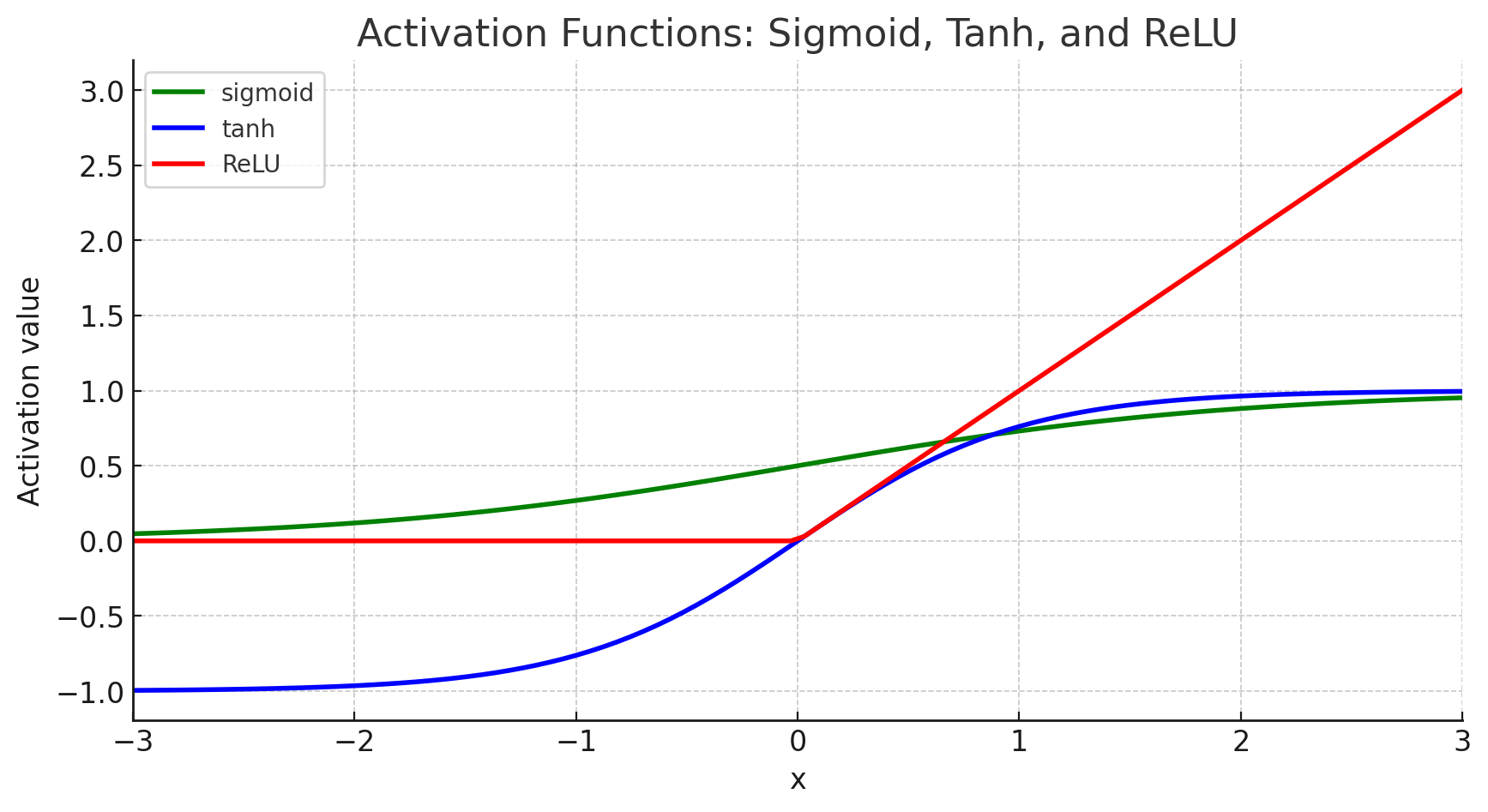
이는 3개의 활성화 함수 sigmoid, tanh, ReLU를 비교해보면서 설명하는 것이 편한데
sigmoid는 대체로 레이어와 레이어 사이의 활성화 함수로는 이제 더이상 사용되지 않으며(기울기 소실문제가 크게 발생함)
ReLU는 지속적으로 재귀하여 이전값을 사용하는 RNN에는 기울기 폭주문제가 자주 발생하게 된다
따라서 이전 값의 상한 하한을 사이로 nomalize 하는 Tanh가 주로 사용된다.
마지막으로 bidirectional은
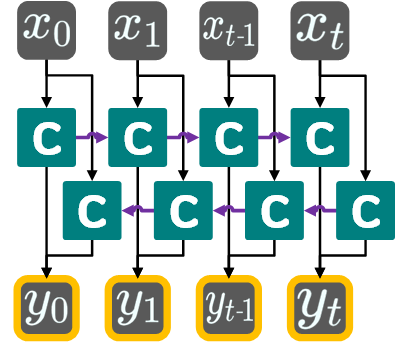
위 그림처럼 입력되는 시퀀스을 앞뒤의 정방향이 아닌
뒤앞의 역방향으로도 재귀연산을 수행하는 RNN을 사용할 때 설정하는 옵션이다.
해당 옵션으로 RNN을 설계할 때는 아래 그림처럼 빈칸채우기 문제를 풀이할 때 성능이 꽤 잘 나오는 편이다.

2. RNN 실습
대략 이 정도면 어느정도 RNN의 개념과 사용처에 대해 정리가 된 듯 하니 실습을 진행하도록 하자
실습 데이터셋은 https://github.com/tbvjvsladla/ASH_NLP_lacture/blob/main/spam_SNS.csv 에 업로드한 '스팸문자', '일상문자' 두개로 라벨링된 데이터를 학습하여
스팸 분류기(Spam detector)을 설계하고자 한다.
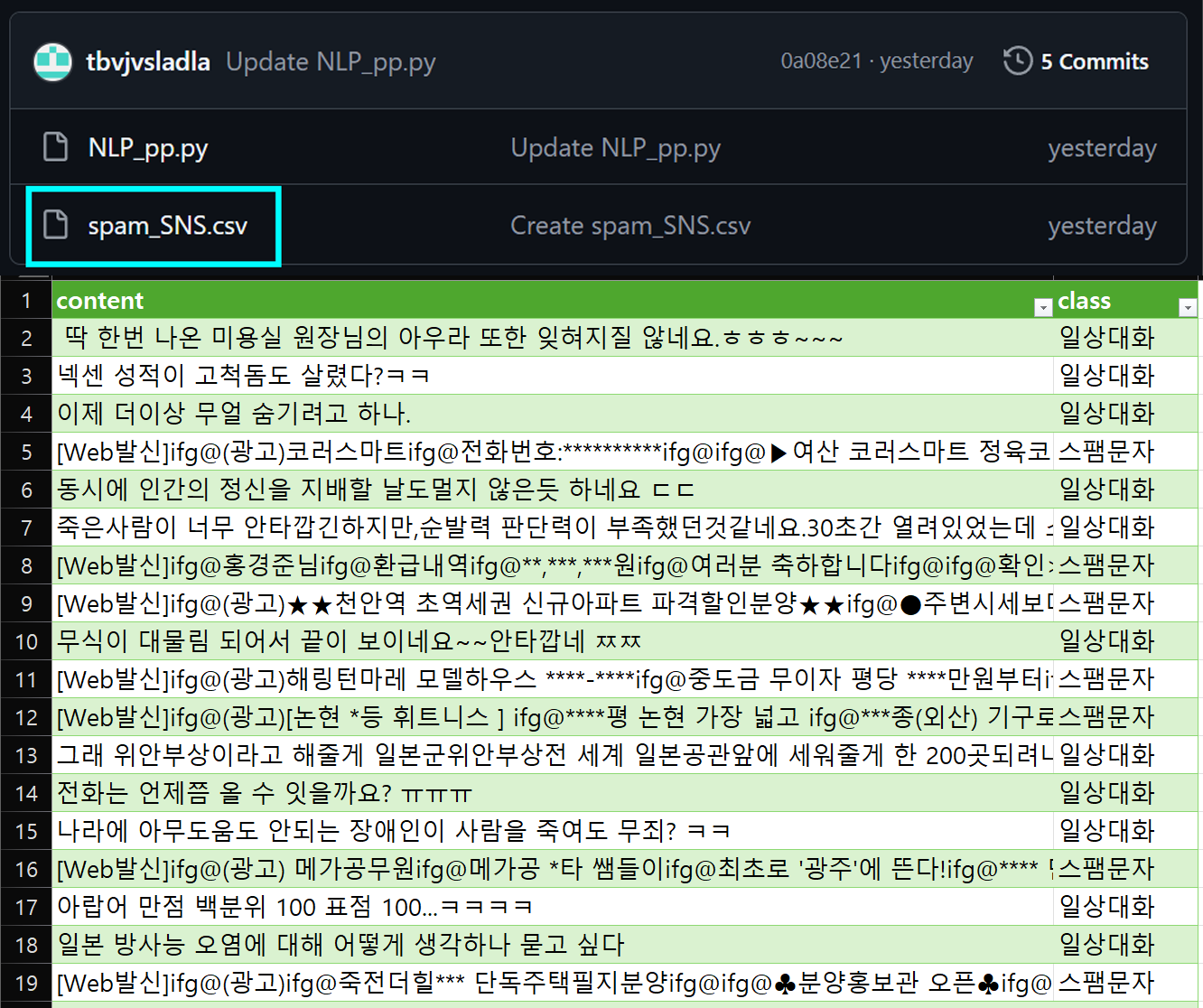
데이터&텍스트 전처리에는 이전 포스트 1. NLP-Text 전처리 마침 : 모듈화에서 설명하고 있는
데이터&텍스트 전처리 함수 모음 NLP_pp.py를 사용한다.
데이터 전처리
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
# 데이터 및 텍스트 전처리 함수를 모듈화 시킨 파일
from NLP_pp import *import urllib.request
url = 'https://raw.githubusercontent.com/tbvjvsladla/ASH_NLP_lacture/main/spam_SNS.csv'
path = './data/spam_SNS.csv'
# 깃허브에 있는 파일 다운로드
urllib.request.urlretrieve(url=url, filename=path)# 다운로드 받은 파일 불러오기
raw_data = pd.read_csv(path)# 데이터셋읜 결측치 & 중복치 제거 함수 실행
raw_data = df_cleaning(raw_data, 'content')import re
# 한글, 영어(소문자, 대문자), 숫자
p1 = re.compile(r'[^가-힣a-zA-Z0-9\s]')
# 한글 자모 데이터
p2 = re.compile(r'[ㄱ-ㅎㅏ-ㅣ]+')
# 개행문자 + 하나 이상의 공백문자
p3 = re.compile(r'\n|\s+')
def regex_sub(origin_sent):
clean_text = p1.sub(repl=" ", string=origin_sent)
clean_text = p2.sub("", clean_text)
clean_text = p3.sub(" ", clean_text)
return clean_text# 설계한 정규표현식기반 특수문자 삭제 함수 적용
# apply함수는 inplace=True(덮어쓰기) 기능이 없음
raw_data['content'] = raw_data['content'].apply(regex_sub)
# '일상대화'는 0으로, '스팸문자'는 1로 변환
raw_data['class'] = raw_data['class'].map({'일상대화': 0, '스팸문자': 1})텍스트 전처리
# 데이터프레임의 항목을 분리 후 리스트 타입으로 변경
raw_x_data = raw_data['content'].values.tolist()
raw_y_label = raw_data['class'].values.tolist()from mecab import MeCab #한글 단어 토크나이저
from tqdm import tqdm
#mecab 형태소 분석기 인스턴스화
word_tokenizer = MeCab()# 토큰화 수행
tokenized_x_data = tokenize(raw_x_data, word_tokenizer)# 깃허브에 있는 stopwordlist.txt파일 다운
stop_url = 'https://raw.githubusercontent.com/tbvjvsladla/ASH_NLP_lacture/main/kr_stopword_list.txt'# 불용어 데이터셋 다운로드
stopword_list = download_stopword_list(stop_url)
# 토큰화 처리한 '기사 본문' 데이터셋의 불용어 제거
r_t_x_data = remove_stopword(tokenized_x_data, stopword_list)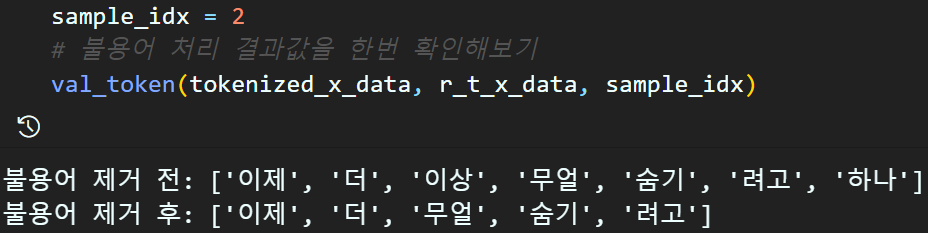
# 불용어 제거된 데이터를 자모 데이터로 분리
jamo_x_data = decompose_jamo(r_t_x_data)from sklearn.model_selection import train_test_split
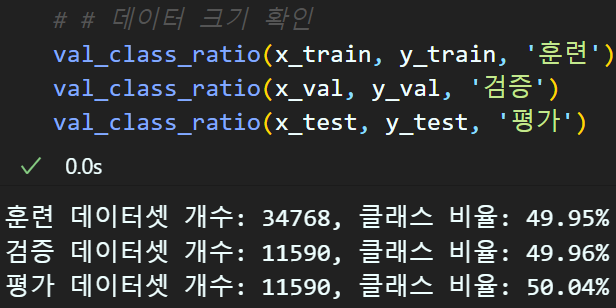
# 훈련데이터셋(60%) 그 외 데이터셋(40)로 나누는 작업 수행
# random_state -> 데이터셋을 내누는데 '재현성' 유지를 위해 넣음 -> 안넣어도 됨
# stratify -> Y_label의 클래스 비율을 유지하면서 데이터 나눌때 옵션
x_train, x_etc, y_train, y_etc = train_test_split(
jamo_x_data, raw_y_label, test_size=0.4, stratify=raw_y_label
)
# 그 외 데이터셋을 반반으로 Val, Test로 나눔
x_val, x_test, y_val, y_test = train_test_split(
x_etc, y_etc, test_size=0.5, stratify=y_etc
)
from collections import Counter
word_list = []
# train항목을 워드 리스트에 입력
for sent in x_train:
for word in sent:
word_list.append(word)
# val항목을 워드 리스트에 입력
for sent in x_val:
for word in sent:
word_list.append(word)
# 단어와 해당 단어의 출몰 빈도를 함께 저장하는
# Counter 타입의 변수 생성
word_counts = Counter(word_list)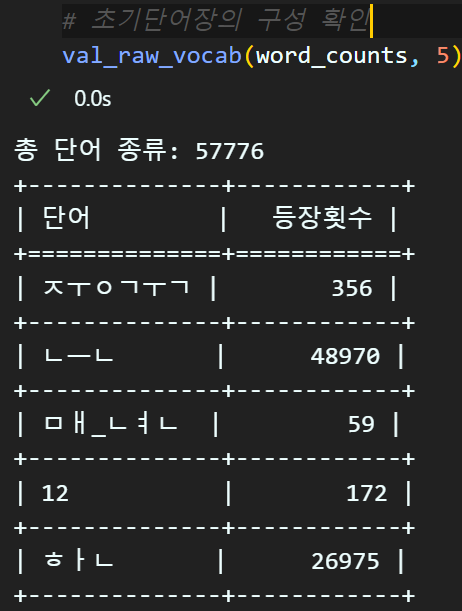
rare_th = 3 #희소단어의 등장 빈도를 결정하는 파라미터
# 희소단어 등장 빈도를 바탕으로 희소 단어를 배제하기 위해 준비 함수
tot_vocab_cnt, rare_vocab_cnt = set_rare_vocab(word_counts, rare_th)#등장 빈도가 높은 단어 순으로 정렬하기
vocab = sorted(word_counts, key=word_counts.get, reverse=True)
#등장 빈도가 높은 단어만 인덱싱 하기
vocab_size = tot_vocab_cnt - rare_vocab_cnt
vocab = vocab[:vocab_size]# 스페셜 토큰 선언
spec_token = ['<PAD>', '<UNK>']
# 스페셜 토큰을 포함한 {단어:단어idx}의 딕셔너리 생성
word_to_idx, idx_to_word = set_word_to_idx(spec_token, vocab)# 데이터셋의 정수 인코딩 수행
e_x_train = text_to_sequences(x_train, word_to_idx)
e_x_val = text_to_sequences(x_val, word_to_idx)
e_x_test = text_to_sequences(x_test, word_to_idx)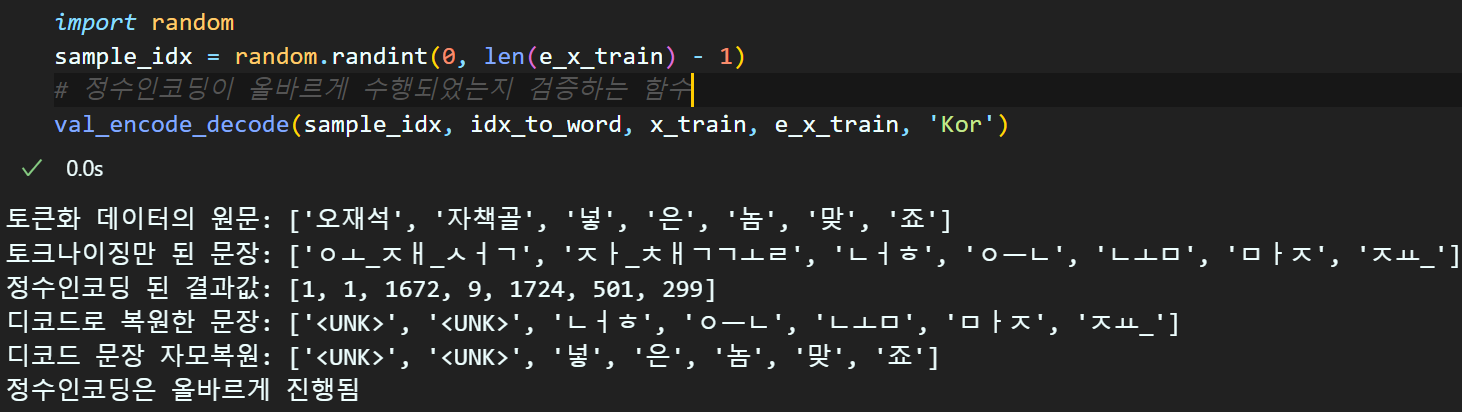
context_length = 330
set_sent_pad(e_x_train, context_length, report=False)# 데이터셋의 문장 패딩(정수인코딩의 완료)
padded_x_train = pad_seq_x(e_x_train, context_length)
padded_x_val = pad_seq_x(e_x_val, context_length)
padded_x_test = pad_seq_x(e_x_test, context_length)
import torch
bs = 256 # Batch_size 하이퍼 파라미터
# 정수(원핫)인코딩 데이터를 데이터로더로 변환
trainloader = set_dataloader(padded_x_train, y_train, bs, '훈련')
valloader = set_dataloader(padded_x_val, y_val, bs, '검증')
testloader = set_dataloader(padded_x_test, y_test, bs, '평가')2.1 FastText로 임베딩레이어 학습
한글 데이터셋이니 FastText로 임베딩레이어를 학습시킨 사전 임베딩 레이어 파라미터를 생성한다.
# Word2Vec 및 FastText 학습에 사용할 데이터:
# 원본 데이터셋의 토큰화 후 불용어 제거를 수행한 데이터터
# 에다가 단어 -> 자모 분리를 수행한 데이터
word2vec_doc = jamo_x_datafrom gensim.models import FastText
FT_model = FastText(
sentences=word2vec_doc,
vector_size = 100, # 임베딩 차원은 100으로 설정
window = 5, # 논문의 최대 관심가질 주변단어 사이즈인 5~20
min_count = rare_th, # (3) 단어장에서 배제할 희소단어 빈도 기준
workers= -1, # 학습에 참여할 프로세스 개수 (최대로 설정)
sg = 1, # Skip-gram 방식으로 학습 수행
# FastText의 N-gram 범위 설정(3~6)
min_n=3, max_n=6
)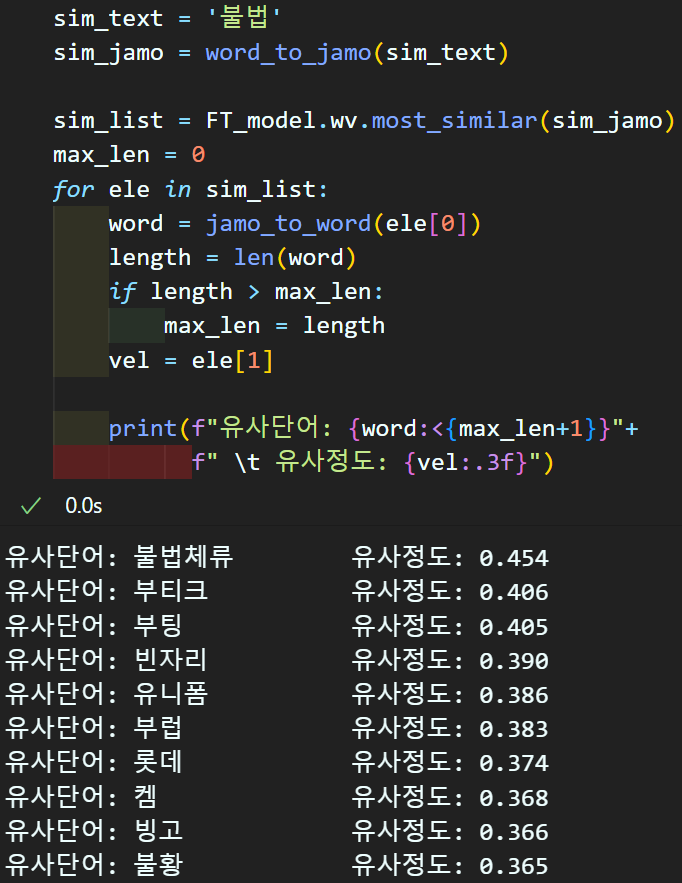
FastText로 단어학습이 잘 완료된 듯 하니
학습된 임베딩 레이어를 조정한다
# 단어장 크기 : 26824
vocab_size = len(word_to_idx)
# 임베딩 차원 크기 : 100
embedding_dim = FT_model.wv.vector_sizedef build_my_embed(word2idx, vocab_vector):
vocab_size = len(word2idx)
emb_dim = vocab_vector.vector_size
embedding_matrix = np.zeros((vocab_size, emb_dim))
for word, idx in word2idx.items():
# word2idx의 단어를 학습된 임베딩레이어가
# 포함된 단어벡터에서 찾아냄
if word in vocab_vector:
embedding_vector = vocab_vector[word]
embedding_matrix[idx] = embedding_vector
# 스페셜 토큰별로 처리하기
elif word == '<PAD>':
# '<PAD>' 토큰의 임베딩 벡터는 0으로 유지
embedding_matrix[idx] = np.zeros(emb_dim)
else: # 단어벡터에 없는 단어 발생 -> '<UNK>' 처리
# '<UNK>'는 랜덤 초기화 해버린다
embedding_matrix[idx] = np.random.normal(size=(emb_dim,))
return embedding_matrix# FastText 방식으로 학습된 임베딩 레이어 조정
my_FT_embedding = build_my_embed(word_to_idx, FT_model.wv)2.2 Text 분류(스팸분류기)
먼저 모델을 설계하기 전 주요 하이퍼 파라미터를 정리하자
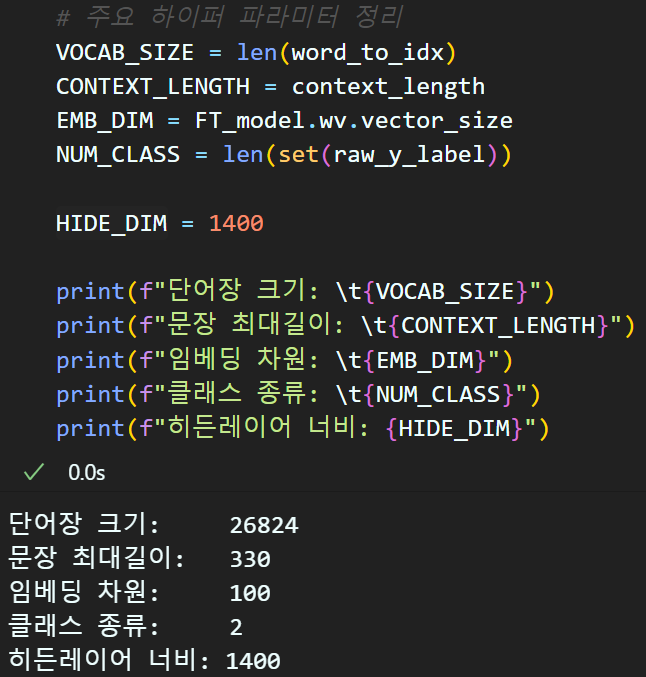
NLP계열 실습은 항상 설정해야 하는 인자값이 CV계열 실습 대비 종류가 많음을 인지해야 하며,
정리를 잘 해둬야 한다.
import torch.nn as nn
class SimpleRNN(nn.Module):
def __init__(self, vocab_size, embed_dim, num_classes,
hid_dim, emb_matirx=None):
super(SimpleRNN, self).__init__()
self.embed = nn.Embedding(vocab_size, embed_dim)
if emb_matirx is not None:
# 사전 훈련된 임베딩 매트릭스를 붙여넣음
self.embed.weight = nn.Parameter(
torch.tensor(emb_matirx, dtype=torch.float32))
# 붙여넣은 Pretrained 임베드 레이어만 Freeze하고 싶을때는 False
self.embed.weight.requires_grad = True
# RNN은 반복횟수가 context_length으로 자동으로 지정됨
self.rnn = nn.RNN(input_size=embed_dim, #RNN에 입력되는 차원
hidden_size=hid_dim, #RNN의 내부 cell의 차원
num_layers=1, #내부 은닉 셀이 몇층인지?
batch_first=True, #입력 텐서의 첫번째가 Batch임
nonlinearity='tanh') #RNN활성화 함수 어떤것?
# hidden_dim은 임베딩 차원 * context_length로 설정한다.
self.classifier = nn.Sequential(
nn.Linear(hid_dim, num_classes),
)
def forward(self, x):
emb = self.embed(x)
# RNN에 입력하고, 최종 출력과 마지막 은닉 상태를 가져옴
# output: 전체 시퀀스에 대한 RNN의 출력 (batch_size, seq_length, hidden_size)
# hidden: 마지막 타임스텝의 은닉 상태 (num_layers, batch_size, hidden_size)
output, hidden = self.rnn(emb)
# 마지막 은닉 상태를 사용하여 분류
# (num_layers, batch_size, hidden_dim)
# 으로 나오므로 num_layers차원을 제거
out = hidden.squeeze(0)
out = self.classifier(out)
return out여기서 중요한 것은
nn.rnn의 출력인 Output, Hidden 중
Hidden을 classifier의 입력으로 사용하는 것이다.
Output 차원 : (Batch_size, context_length, hid_dim)
Hidden 차원 : (1, Batch_size, hid_dim)
위 두개의 차원을 확인 했을 때 어차피 classifier에 입력되는 데이터는 Batch_size를 제외하고 나머지 차원이 1차원인 Feature가 입력되어야 하니 Hidden을 쓰는게 더 편하다
억지로 Output을 classifier에 입력하려면
avg_pool = torch.mean(output, dim=1)이렇게 차원축소를 해줘야 하니 이게 더 비효율적이고
또 문맥의 학습정보가 뭉게지는 불상사가 발생한다.
2.3 RNN 모델 학습하기
위 챕터를 통해 FastText 사전훈련 임베딩 레이어
RNN계열 모델 설계까지 완료했다.
이제 학습을 진행해보자
# 모델의 조건을 구분하기 위한 키
model_key = ['사전훈련', '랜덤초기화']RNN_model_raninit = SimpleRNN(VOCAB_SIZE, EMB_DIM,
NUM_CLASS, HIDE_DIM)
RNN_model_pre_emb = SimpleRNN(VOCAB_SIZE, EMB_DIM,
NUM_CLASS, HIDE_DIM, my_FT_embedding)모델은 사전 훈련 임베딩 레이어의 사용 유/무에 따라 두가지 조건이 있으니 이에 맞춰 초기화를 수행한다.
# GPU사용 가능 유/무 확인
device = torch.device("cuda" if torch.cuda.is_available() else 'cpu')
models = {} # 딕셔너리
models[model_key[0]] = RNN_model_raninit.to(device)
models[model_key[1]] = RNN_model_pre_emb.to(device)import torch.optim as optim
# 로스함수 및 옵티마이저 설계
criterion = nn.CrossEntropyLoss()
LR = 0.001 # 러닝레이트는 통일
optimizers = {}
optimizers[model_key[0]] = optim.Adam(RNN_model_raninit.parameters(), lr=LR)
optimizers[model_key[1]] = optim.Adam(RNN_model_pre_emb.parameters(), lr=LR)# 사전에 모듈화 한 학습/검증용 라이브러리 import
from C_ModelTrainer import ModelTrainer
num_epoch = 8 #총 훈련/검증 epoch값
ES = 2 # 디스플레이용 에포크 스텝
# BC_mode = True(이진), False(다중)
# aux = 보조분류기 유/무
# wandb = 완디비에 연결 안하면 None
# iter = 훈련시 iteration의 acc및 loss 정보 추출
trainer = ModelTrainer(epoch_step=ES, device=device,
BC_mode=False, aux=False, iter=False)# 학습/검증 정보 저장
metrics_key = ['Loss', '정확도']
history = {mk: {metrics_key[0]: [],
metrics_key[1]: []}
for mk in model_key}학습 코드
for mk in model_key: #모델의 조건 - 임베딩레이어의 Pretrain유/무
# 모델 훈련/검증 코드
for epoch in range(num_epoch):
# 훈련모드의 손실&성과 지표
train_loss, train_acc = trainer.model_train(
models[mk], trainloader,
criterion, optimizers[mk], epoch)
# 검증모드의 손실&성과 지표
val_loss, val_acc = trainer.model_evaluate(
models[mk], valloader,
criterion, epoch)
# 손실 및 성과 지표를 history에 저장
history[mk]['Loss'].append((train_loss, val_loss))
history[mk]['정확도'].append((train_acc, val_acc))
# Epoch_step(ES)일 때마다 print수행
if (epoch+1) % ES == 0 or epoch == 0:
if epoch == 0:
print(f"현재 훈련중인 조건: [{[mk]}]")
print(f"epoch {epoch+1:03d}," + "\t" +
f"훈련 [Loss: {train_loss:.3f}, " +
f"Acc: {train_acc*100:.2f}%]")
print(f"epoch {epoch+1:03d}," + "\t" +
f"검증 [Loss: {val_loss:.3f}, " +
f"Acc: {val_acc*100:.2f}%]")
print(f"\n----조건[{[mk]}] 훈련 종료----\n")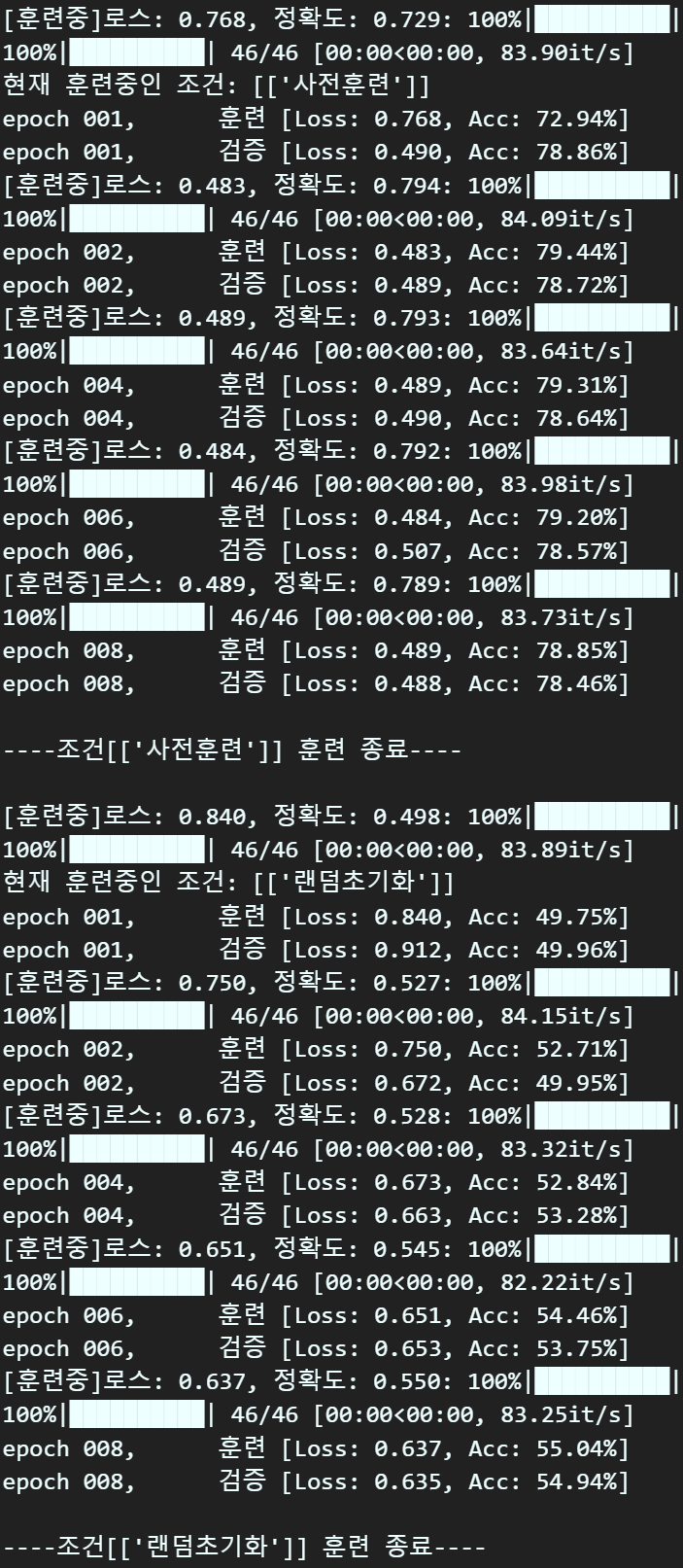
여기까지 수행하면 조건별로 훈련/검증 결과를 출력할 수 있다.
훈련 결과 분석
import matplotlib.pyplot as plt
# 한글 사용을 위한 폰트 포함
plt.rcParams['font.family'] = 'Malgun Gothic'
plt.rcParams['axes.unicode_minus'] = False
# 모델 목록과 메트릭 목록
# model_key = ['사전훈련', '랜덤초기화']
# metrics_key = ['Loss', '정확도']
# 데이터 추출을 위한 딕셔너리 초기화
extracted_data = {}
for model in model_key:
extracted_data[model] = {}
for metric in metrics_key:
# 각 모델의 메트릭 데이터 추출
metric_data = history[model][metric]
# 훈련 및 검증 값 분리
train_values = [tup[0] for tup in metric_data]
val_values = [tup[1] for tup in metric_data]
extracted_data[model][f'훈련_{metric}'] = train_values
extracted_data[model][f'검증_{metric}'] = val_values# 손실 및 정확도 그래프 그리기 그래프 생성
fig, axes = plt.subplots(2, 2, figsize=(12, 12))
axes = axes.flatten() # 2차원 배열을 1차원으로 변환하여 인덱싱 쉽게 함
# 손실 그래프 그리기
for idx, model in enumerate(models):
ax = axes[idx*2] #손실 그래프는 0, 2번째에 위치
ax.plot(extracted_data[model]['훈련_Loss'], label='훈련 로스')
ax.plot(extracted_data[model]['검증_Loss'], label='검증 로스')
ax.set_title(f'RNN 모드-{model} 텍스트 분류기 Loss')
ax.set_xlabel('Epoch')
ax.set_ylabel('Loss')
ax.legend()
# 정확도 그래프 그리기
for idx, model in enumerate(models):
ax = axes[idx*2 + 1] #정확도 그래프는 1, 3번째에 위치
ax.plot(extracted_data[model]['훈련_정확도'], label='훈련 정확도')
ax.plot(extracted_data[model]['검증_정확도'], label='검증 정확도')
ax.set_title(f'RNN 모드-{model} 텍스트 분류기 정확도')
ax.set_xlabel('Epoch')
ax.set_ylabel('정확도')
ax.legend()
plt.tight_layout()
plt.show()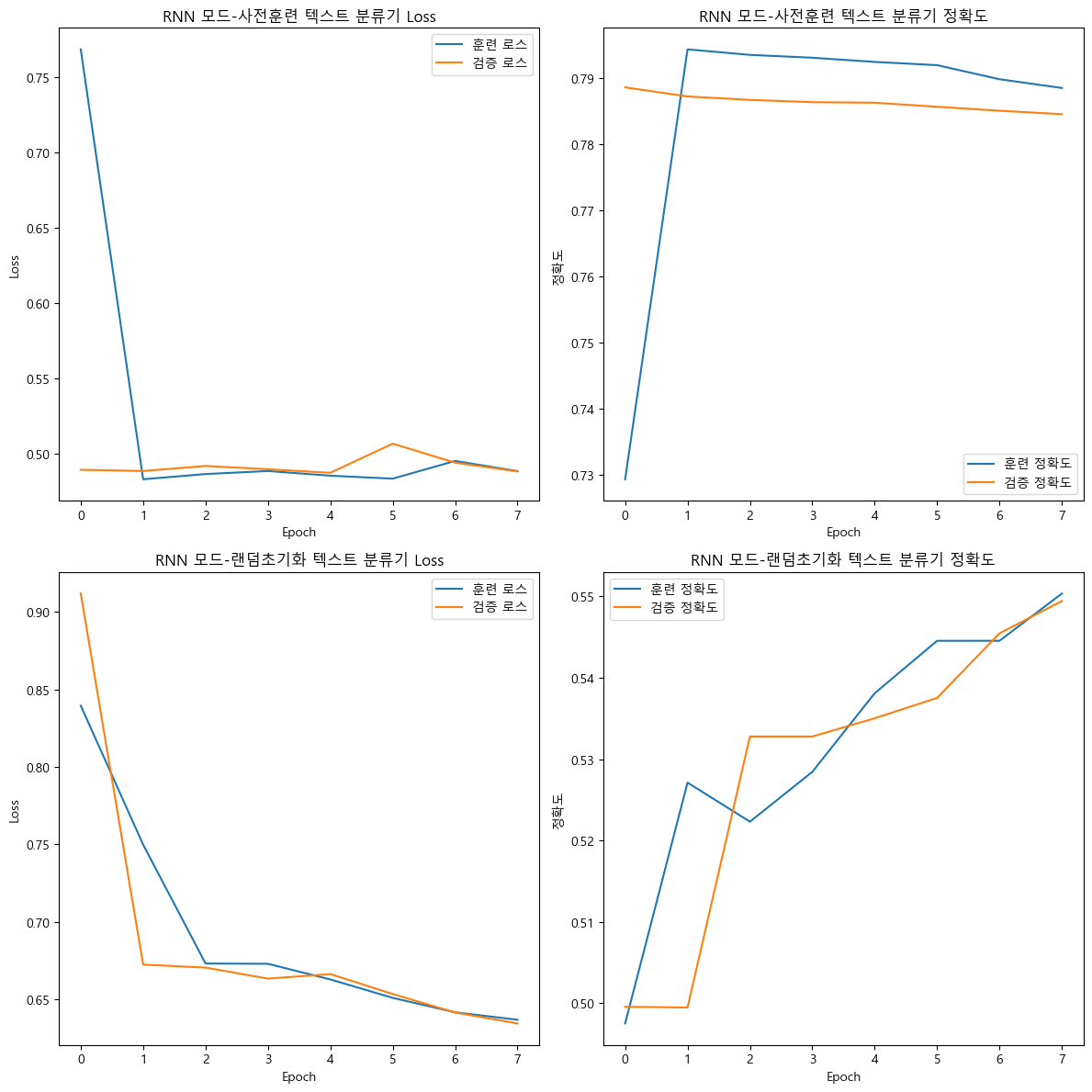
# 모든 모델의 손실과 정확도를 비교하는 그래프 생성
fig, axes = plt.subplots(2, 1, figsize=(10, 18))
# 모든 모델의 손실 그래프
ax = axes[0]
for model in models:
ax.plot(extracted_data[model]['훈련_Loss'], label=f'RNN모드-{model} 훈련 로스')
ax.plot(extracted_data[model]['검증_Loss'], label=f'RNN모드-{model} 검증 로스', linestyle='--')
ax.set_title('모든 조건별 모델의 훈련/검증 Loss')
ax.set_xlabel('Epoch')
ax.set_ylabel('Loss')
ax.legend()
# 모든 모델의 정확도 그래프
ax = axes[1]
for model in models:
ax.plot(extracted_data[model]['훈련_정확도'], label=f'RNN모드-{model} 훈련 정확도')
ax.plot(extracted_data[model]['검증_정확도'], label=f'RNN모드-{model} 검증 정확도', linestyle='--')
ax.set_title('모든 조건별 모델의 훈련/검증 정확도')
ax.set_xlabel('Epoch')
ax.set_ylabel('정확도')
ax.legend()
plt.tight_layout()
plt.show()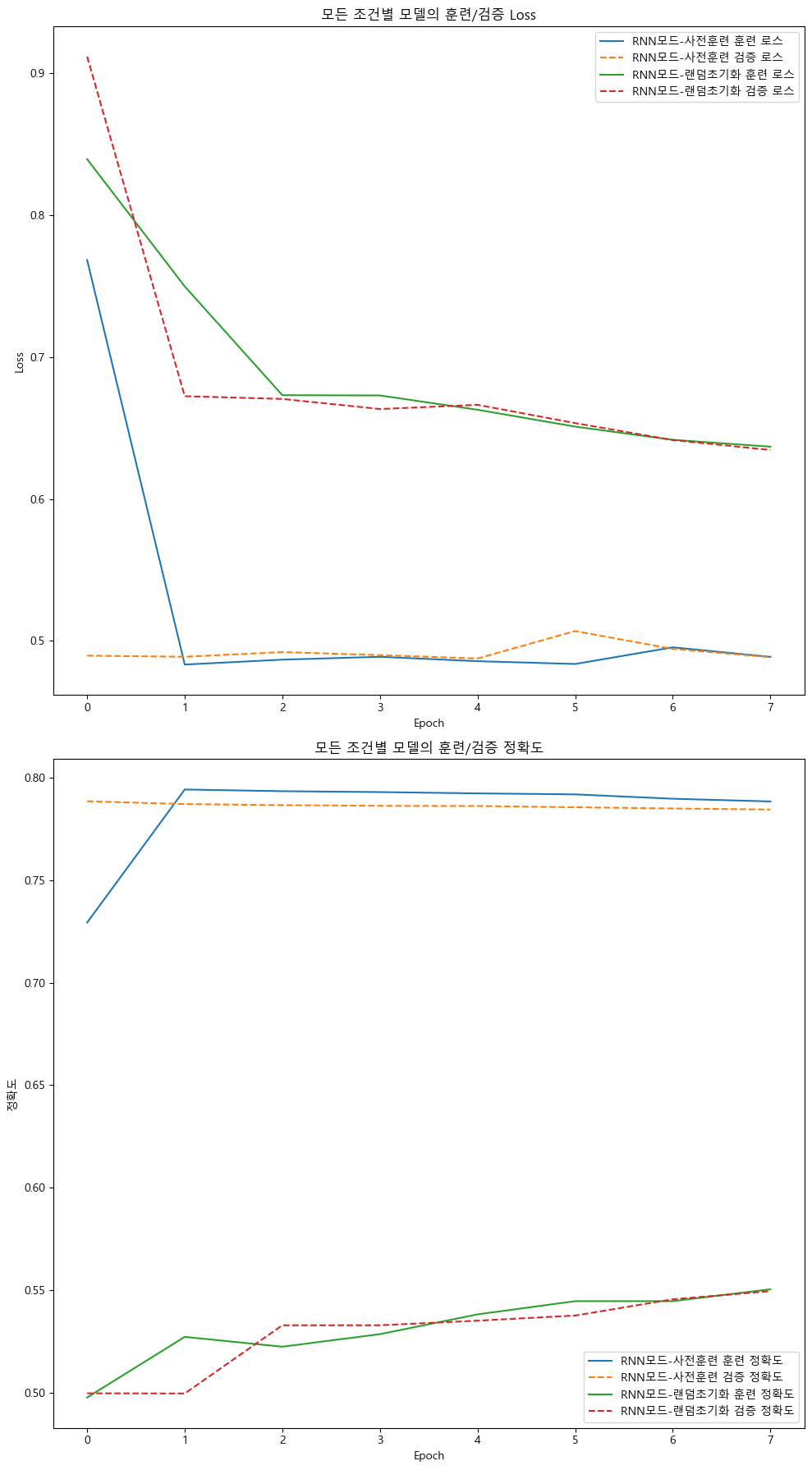
성능을 보면 알겠지만...
RNN모델의 랜덤 초기화 버전은 이건 뭐 의미가 없어보이고
FastText 사전 훈련 임베딩 레이어를 입력한 RNN모델도 그렇게 썩 좋은 성능은 나고 있지 않은것을 확인할 수 있다.
왜 그런지는 '장기 의존성' 문제라 생각되며
이는 다음 포스트에서 후술하겠다.
여담
참고로 지금의 스팸 분류기는 모델의 훈련 데이터셋도 적은 편이어서
import torch.nn as nn
class SimpleNet(nn.Module):
def __init__(self, vocab_size, embed_dim, num_classes,
context_length, hid_dim, emb_matirx=None):
super(SimpleNet, self).__init__()
self.embed = nn.Embedding(vocab_size, embed_dim)
if emb_matirx is not None:
# 사전 훈련된 임베딩 매트릭스를 붙여넣음
self.embed.weight = nn.Parameter(
torch.tensor(emb_matirx, dtype=torch.float32))
# 붙여넣은 Pretrained 임베드 레이어만 Freeze하고 싶을때는 False
self.embed.weight.requires_grad = True
self.flatten = nn.Flatten()
# hidden_dim은 임베딩 차원 * context_length로 설정한다.
self.classifier = nn.Sequential(
nn.Linear(embed_dim * context_length, hid_dim),
nn.ReLU(),
nn.Linear(hid_dim, num_classes),
)
def forward(self, x):
emb = self.embed(x)
emb = self.flatten(emb)
out = self.classifier(emb)
return out위 MLP(다층 퍼셉트론) 기반의 SimpleNet가 훨씬 성능이 더 잘나온다
데이터셋 개수가 적어도 20만개는 넘어가줘야
고전 머신러닝, MLP 계열의 모델보다 더 좋은 성능이 나온다
물론... NLP에 적합한 좋은 자연어 데이터셋
그것도 한글버전을 구하는게 참 녹록치 않다..
