
개요
본 블로그 포스팅은 수도권 ICT 이노베이션 스퀘어에서 진행하는 AI 핵심 기술 집중 클래스의 자연어처리(NLP) 강좌 내용을 필자가 다시 복기한 내용에 관한 것입니다.
1. 작업개요
이전 포스트 1. NLP-Text 전처리 : Tokenizer Intro (1) - AI 핵심기술 강의 복습와 1. NLP-데이터 처리 외전 : Pandas, 정규표현식 - AI 핵심기술 강의 복습
에서 각각 규칙기반/기계학습 기반의 토크나이저와 Data Preprocessing(데이터 전처리)를 학습했다.
이 과정을 포함하여 Text Preprocessing(텍스트 전처리)과정을 다시 표현하면 아래와 같아지는데
0. Data preprocessing
1. Tokenization (Word & Sentence)
2. Cleaning, Remove Stopword, Normalization
3. Build vocalbulary
4. Integer Encoding (word to index)
5. Sentence Padding (max context length)
6. Vectorization (Embedding)
5번 항목까지 수행하고 작업된 결과물을 바로 모델에 입력가능한 Dataloader로 만들어도 무방하다.
나중에 언급을 할 내용이지만 6. Vectorization (Embedding) 은 모델을 설계할 때 맨 앞 레이어에 해당하는
nn.Embedding의 형식으로 구현하는게 일반적이다.
따라서 이번 포스트에서는 임의의 자연어 데이터셋을 0~5번 항목까지 수행해 텍스트 전처리를 수행하고자 한다.
2. 데이터 전처리
데이터셋 다운로드 & 정보확인
실습에 사용할 파일은 구글 드라이브에 업로드 했기에 아래의 코드를 작성하여 다운로드를 수행한다.
import gdown
# 구글 드라이브에 업로드된 train.csv 파일 ID
file_id = '13gJ7aGItJK3o0oOV9jjP_02EqPOtLIN_'
# 파일 다운로드 링크 생성
url = f'https://drive.google.com/uc?id={file_id}'
# 'train.csv'파일을 다운로드한 뒤 저장할 경로 지정(파일명도 함께)
csv_file = './data/train_data.csv'
# 파일 다운로드
gdown.download(url, csv_file, quiet=True)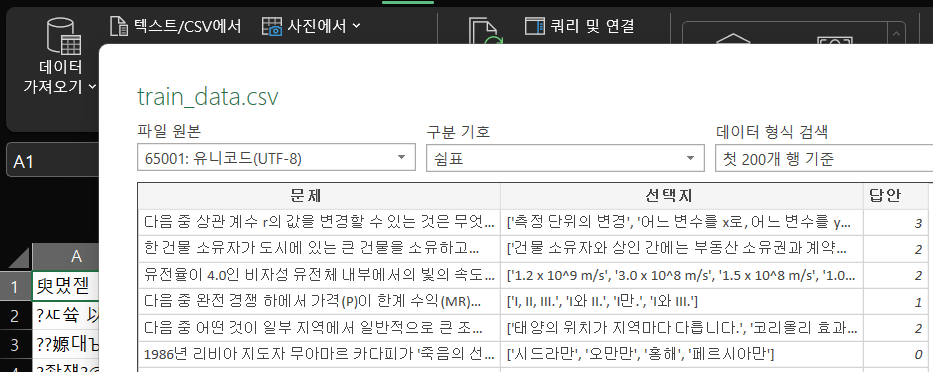
그리고 다운로드 받은 파일을 엑셀 데이터 데이터 가져오기 텍스트/CSV에서 파일을 열고
인코딩 규칙 : 65001-유니코드(UTF-8)
구분기호 : 쉼표(,)로 설정하여 데이터변환을 진행하면
 알아보기 편하게 데이터셋의 구조를 파악할 수 있다.
알아보기 편하게 데이터셋의 구조를 파악할 수 있다.
이제 동일한 작업을 pandas라이브러리를 통해 다시한번 진행하자.
import numpy as np
import pandas as pd
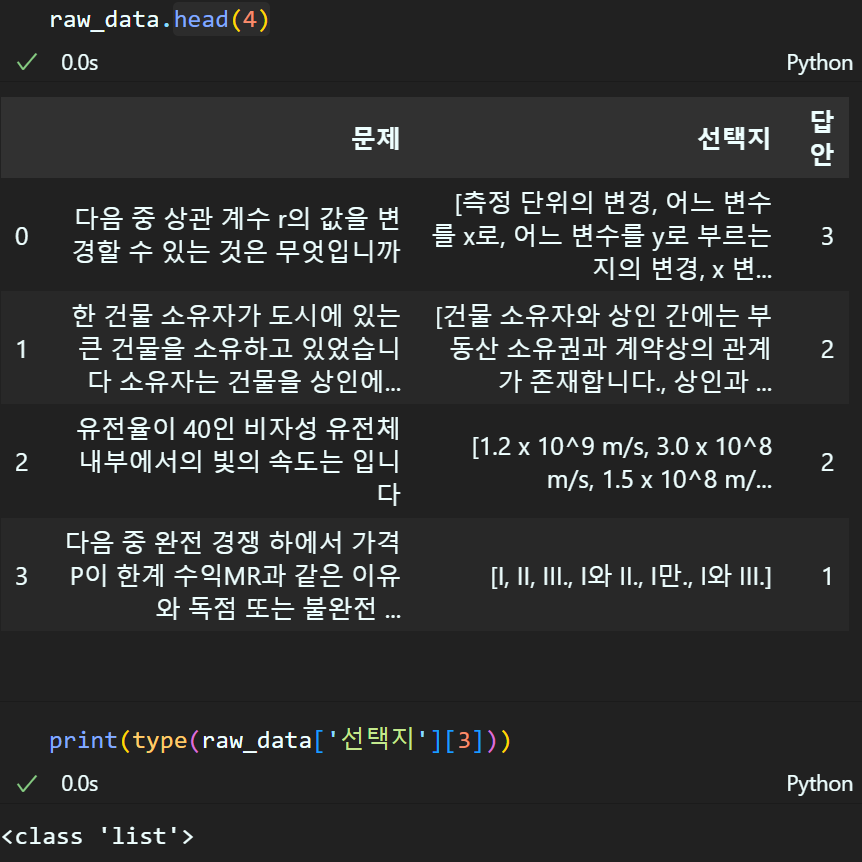
import matplotlib.pyplot as pltraw_data = pd.read_csv(csv_file)raw_data.head(4) #데이터의 일부분 정보 확인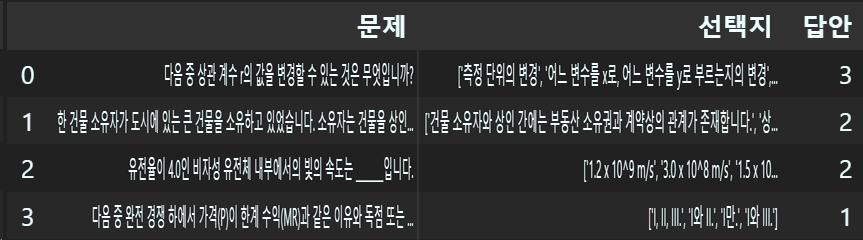
raw_data.info() #데이터셋의 기본 정보 확인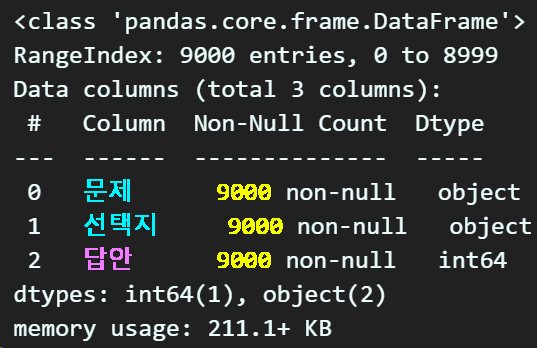
pd.info()를 통해 정보를 확인하면 총 row 데이터는 9000개에 셀은 문제, 선택지, 답안 3개의 컬럼이 있는것을 확인할 수 있다.
이 데이터를
문제, 선택지 x_data
답안 y_label
형식의 지도학습 데이터셋으로 전처리를 수행하는것이 본 포스트의 목적이다.
결측치 & 중복치 제거
# 컬럼별 결측치 cnt값을 모두 더한 값 (정수형 데이터)
missing_data = raw_data.isna().sum().values.sum()
# 결측치 정보가 0이면 결측치가 없으니 아래 함수가 실행안됨
if missing_data != 0:
raw_data.dropna(how='any', inplace=True)
# 중복치 제거
raw_data.drop_duplicates(subset='문제',
keep='first',
inplace=True)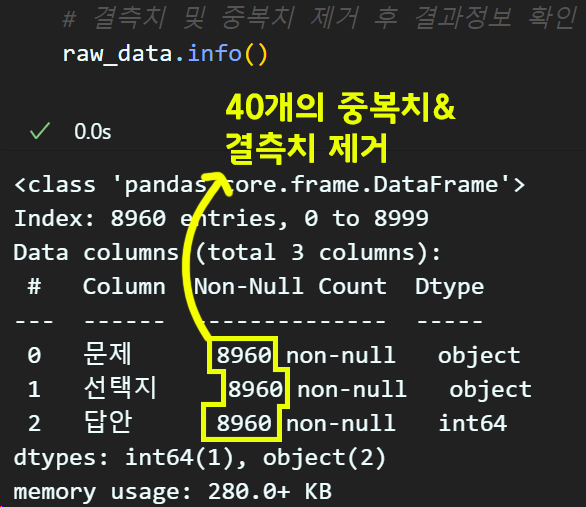
결측치(missing data)는 컬럼별 결측치를 검색한 뒤, 이를 최종 합산하여 모든 셀 데이터의 결측치를 검색합산한다.
이때 결과치가 0이면 모든 셀 데이터에 결측치가 없음을 의미하고, 0이 아니면 결측치가 있다는 뜻이니
.dropna()함수로 결측치를 삭제한다.
그 다음 중복치는 drop_duplicates()함수로 중복치를 제거하며, 이때 중복치를 검색하는 대표 컬럼은 선택지 항목을 기준으로 중복치를 제거한다.
정규표현식으로 데이터 정제
첫번째로 선택지항목에서 영어, 숫자, 한글, 공백 외의 특수문자는 모두 제거하고자 한다.
사용할 정규표현식 : [^ㄱ-ㅎ가-힣a-zA-Z0-9\s], '\n|\s+'
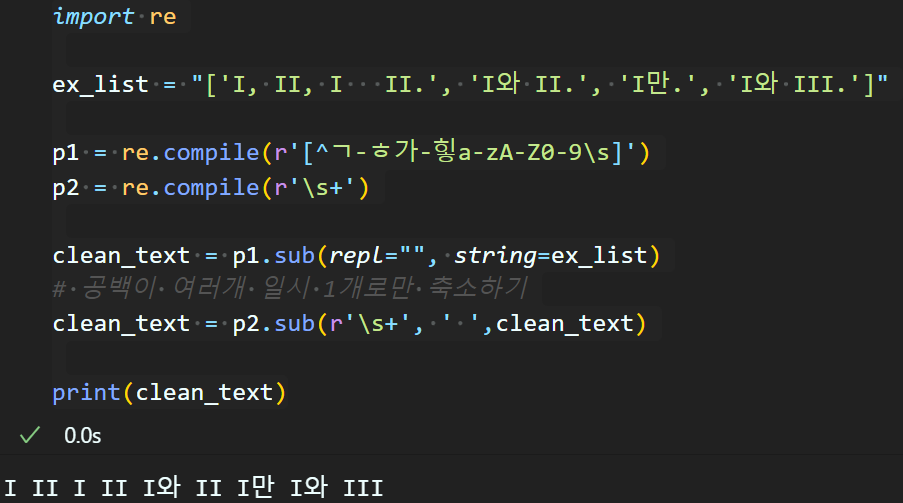
우선 예제 문장을 하나 가져와서 목적대로 정규표현식으로
영어, 숫자, 한글, 공백 이외 특수문자를 삭제하고
공백이 여러 칸 발생하면 이를 1칸으로 줄이는 정규표현식을 각각 적용한다.
추가로 개행문자가 존재해도 해당 개행문자를 1개의 공백문자로 변경한다.
이제 위 정규표현식으로 문자열을 정제하는 과정을 함수화 한뒤 DataFrame 객체인 raw_data에 적용한다.
import re
# 사용할 정규표현식 객체
p1 = re.compile(r'[^ㄱ-ㅎ가-힣a-zA-Z0-9\s]')
p2 = re.compile(r'\n|\s+')
# 정규표현식으로 데이터 정제 함수 설계
def regex_sub(origin_sent):
clean_text = p1.sub(repl="", string=origin_sent)
clean_text = p2.sub(" ", clean_text)
return clean_text# apply함수는 inplace=True(덮어쓰기) 기능이 없음
raw_data['문제'] = raw_data['문제'].apply(regex_sub)다음으로 수행할 항목은 선택지 항목의 데이터를 리스트 데이터로 분리하는 과정이다.

# 문자열을 리스트로 변경하기 위한 정규표현식
p3 = re.compile(r"', '")
def sent2list(origin_text):
# 큰 따옴표는 모두 작은따옴표로 변경
clean_text = re.sub(r"\"", "'", origin_text)
# [' '] 이 구문이 보이면 삭제하기
clean_text = re.sub(r"\[\'|\'\]", "", clean_text)
# ', ' 라는 정규표현식을 기준으로 문자열을 나누고
# 나뉜 문자열은 리스트로 저장
clean_list = p3.split(clean_text)
return clean_list# apply함수는 inplace=True(덮어쓰기) 기능이 없음
raw_data['선택지'] = raw_data['선택지'].apply(sent2list)여기까지 수행하면 대부분의 선택지 항목의 데이터는
리스트 타입의
[ 선택지1, 선택지2, 선택지3, 선택지4 ]
으로 대부분 정리되지만
원소의 개수가 4개 미만이거나, 4개가 넘어가는 항목이 존재한다
4개가 미만인 항목은 임의의 원소를 하나 채우고,
4개가 넘어가면 해당 row를 지우기로 했다(총 2개 지워짐)
# 선택지 컬럼 내 셀 데이터의 리스트 원소 개수 맞추기
def choice_preprocess(row):
if len(row) < 4: # 선택지의 리스트 원소가 4개 미만일 경우
# 4개가 될 때까지 'None' 추가
row.extend(['None'] * (4 - len(row)))
elif len(row) > 4: # 선택지의 리스트 원소가 4개를 초과
return None # 4개 초과인 경우 삭제를 위해 None 반환
return row# 각 row의 선택지 리스트에 대해 처리
raw_data['선택지'] = raw_data['선택지'].apply(choice_preprocess)
# 4개 초과인 row 삭제 (None이 반환된 경우)
raw_data.dropna(subset=['선택지'], inplace=True)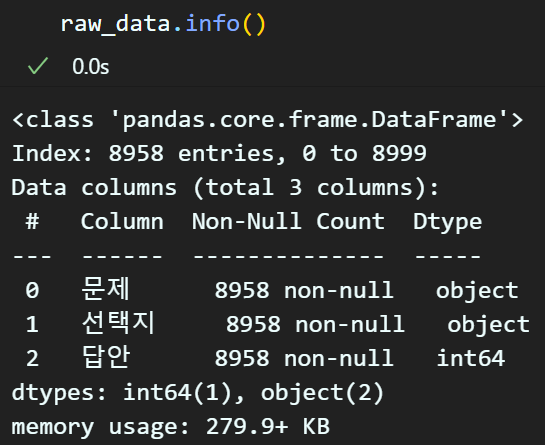
최종 정리된 데이터는 8958개의 데이터가
설계한 데이터 전처리를 완수한 항목이라 볼 수 있다.
3. Tokenize
데이터 전처리과정이 어느정도 완료되었으니 텍스트 전처리의 첫번째 과정인 Tokenize를 수행하고자 한다.
사용할 토크나이저는 한글 단어 토크나어저인 Mecab를 사용한다.
# 데이터프레임의 항목을 분리 후 리스트 타입으로 변경
raw_x_exam = raw_data['문제'].values.tolist()
raw_x_choice = raw_data['선택지'].values.tolist()
raw_y_label = raw_data['답안'].values.tolist()먼저 DataFrame타입의 raw_data 각 columns의 값 항목을 추출한 뒤 이를 list타입의 데이터 형식으로 변경한다.
from mecab import MeCab #한글 단어 토크나이저
from tqdm import tqdm
#mecab 형태소 분석기 인스턴스화
word_tokenizer = MeCab()
# 문제, 선택지 데이터 타입에 맞춰서 워드 토크나이징 수행
def tokenize(x_data, word_tokenizer):
tokenized_sentences = list()
for sent in tqdm(x_data):
# 원소가 'str' -> 문제 컬럼의 데이터인 경우
if isinstance(sent, str):
tokenized_sent = word_tokenizer.morphs(sent)
tokenized_sentences.append(tokenized_sent)
# 원소가 'lsit' -> 선택지 컬럼의 데이터인 경우
elif isinstance(sent, list):
tokenize_sent_ele = []
for sent_ele in sent:
tokenized_sent = word_tokenizer.morphs(sent_ele)
tokenize_sent_ele.append(tokenized_sent)
tokenized_sentences.append(tokenize_sent_ele)
return tokenized_sentences
# 라벨 데이터는 원 핫 인코딩
def one_hot_encoded(y_label):
one_hot_list = list()
for element in tqdm(y_label):
ele_list = [0 for i in range(4)]
int_ele = int(element) #숫자형 데이터를 정수형으로 변환
ele_list[int_ele] = 1 #원 핫 인코딩
one_hot_list.append(ele_list)
return one_hot_list# 문제 항목을 토크나이징 수행
tokenized_x_exam = tokenize(raw_x_exam, word_tokenizer)
# 선택지 항목을 토크나이징
tokenized_x_choice = tokenize(raw_x_choice, word_tokenizer)
# 라벨 데이터를 토크나이징
tokenized_y_label = one_hot_encoded(raw_y_label)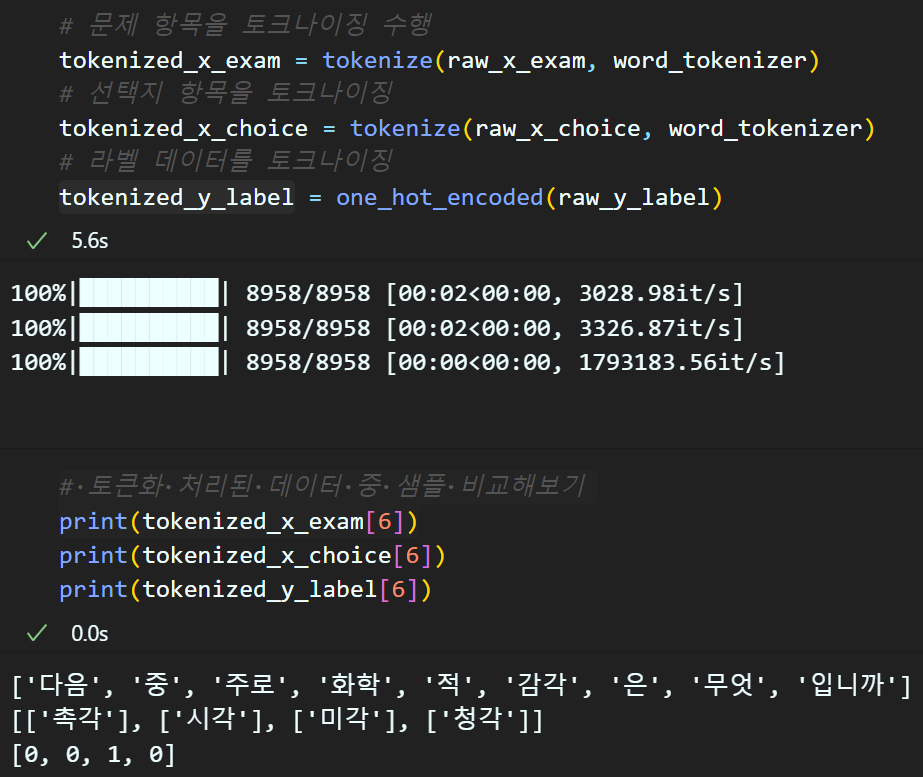
4. Cleaning, Remove Stopword, Normalization
다음으로 수행할 내용은 토큰화된 데이터을 추가로 정제하거나 정규화를 수행하는 과정에 대한 설명이다.
단어가 어렵지만 데이터 전처리과정에서 정규표현식으로 특수문자같은것을 제거하는게 Cleaning에 속하는 항목이고
Normalization도 단어가 어렵지만 영어 대문자+소문자로 혼용된 데이터를 전부 소문자로 처리하는 과정이
정규화에 속한다.

사실상 이번 챕터에서 중요한것은 불용어 제거(Remove Stopword)이다.
불용어는 조사, 접속사, 대명사, 부사, 동사 등등..
문장 내 큰 의미를 갖고 있지 않으나, 문장을 원할하게 구성하기 위한 접착제같은 역할을 하는 단어를 말하며, 통상적으로 텍스트 전처리 과정에서는 주로 제외하는 경향이 있다.
이것을 한글, 영어별로 정리를 하면 아래와 같다.
1) 한글 불용어 리스트
| 항목 | 불용어 예시 |
|---|---|
| 조사 | 이, 가, 을, 를, 에, 에서, 으로, 로, 의, 와, 과, 하고, 고, 및, 은, 는, 도, 만, 까지, 조차, 마저 |
| 접속사 | 그리고, 그러나, 그래서, 그렇지만, 또는, 하지만, 그러므로, 만약, 그렇다면 |
| 대명사 | 나, 너, 그, 그녀, 저, 우리, 너희, 그들 |
| 부사 | 매우, 너무, 조금, 좀, 많이, 약간, 그냥, 즉, 실제로, 대체로, 게다가 |
| 동사 | 이다, 있다, 없다, 하다, 되다, 아니다 |
| 형용사 | 좋은, 나쁜, 큰, 작은, 많은, 적은, 같은 |
| 감탄사 | 아, 어, 예, 네, 아니, 응, 음, 와, 야, 어머 |
| 기타 | 그, 저, 뭐, 어쩌면, 어떻게, 어떤, 어디, 누가, 무엇 |
2) 영어 불용어 리스트
| Category | Stopwords Examples |
|---|---|
| Articles | the, a, an |
| Prepositions | in, on, at, by, for, with, about, against, between, among, during, without, before, after, above, below, to, from, up, down, out, over, under, again, further |
| Conjunctions | and, but, or, yet, so, for, nor, although, because, since, unless, until, while, where, when |
| Pronouns | I, you, he, she, it, we, they, me, him, her, us, them, my, your, his, her, its, our, their, mine, yours, his, hers, ours, theirs |
| Adverbs | very, too, just, only, now, then, here, there, always, never, often, sometimes, usually, really, almost, quite, still, even |
| Auxiliary Verbs | be, is, are, was, were, been, being, do, does, did, have, has, had, can, could, will, would, shall, should, may, might, must |
| Adjectives | good, bad, big, small, many, few, other, new, old, same |
| Interjections | oh, ah, wow, oops, hey, hi, hello, well, um, hmm |
| Others | that, which, who, whom, whose, what, where, when, why, how, than, whether, if, as, all, any, both, each, few, more, most, some, such, no, nor, not, only, own, same, so, than, too, very |
이렇게 불용어를 정리하고 삭제하는 과정을 수행하는 이유는
큰 의미가 없는데 빈도는 높게 출몰하는 경향
이 있기 때문이다.
이는 나중에 단어장을 만들면서 설명할 항목이긴 하지만
단어장을 만들때 해당 단어가 얼마나 빈도 높게 나타나는지?
와 같은 정보도 텍스트 전처리 를 수행하면서 사용되는 항목이어서 이다.
따라서 빈도가 높게 나타나는 경향성이 있는 불용어를 제거함으로써
진짜 유 의미가 있으면서 빈도가 높은 단어을 다시 추려내는 과정이 필요하다.
3) 영문 불용어 제거 예제
영문 불용어는 대체로 정리가 잘 되어있고, 또 Remove Stopword를 수행하는것도 어렵지 않다.
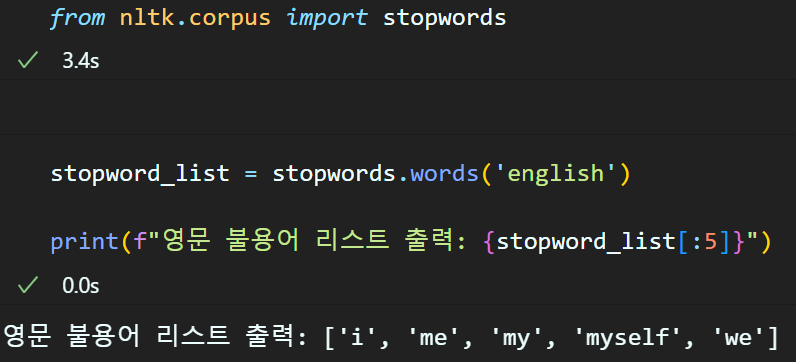
nltk라이브러리의 stopwords 클래스를 불러온 뒤 영문 불용어 항목을 로드하면 리스트 형식으로 정리된
불용어 항목을 저장할 수 있다.
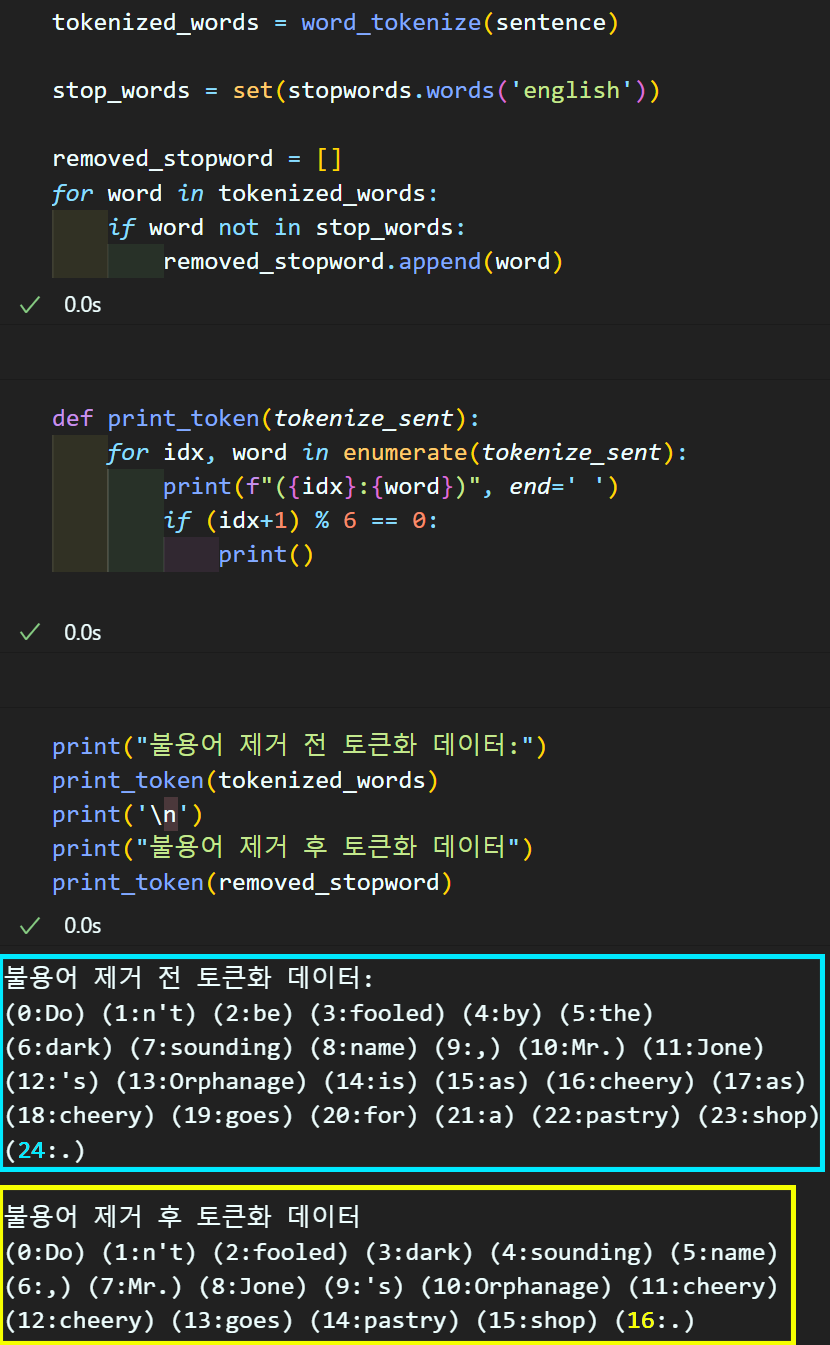
따라서 위 코드처럼 토큰화된 데이터에 불용어제거 과정을 구현하면 빈도수가 높게 나오나 큰 의미가 없는 단어항목이 삭제된 것을 확인할 수 있다.
이렇게 영문 불용어제거는 그렇게 어려운 편이 아니다.
그러나, 한국어의 불용어제거는 별도의 라이브러리가 딱히 제공되는 편은 아니다.
https://www.ranks.nl/stopwords/korean
찾아보니까 위 홈페이지에서 한국어 불용어리스트를 웹페이지에 등록을 해놔서 이를 크롤링 후 텍스트 파일로 저장해서 사용해야 한다.
https://drive.google.com/file/d/1-KtRjx2HBVuqP99kN8tZTiND7oRM6DIO/view?usp=drive_link
이에 kr_stopword_list.txt로 불용어 리스트를 텍스트 파일로 저장한 뒤 이 데이터셋을 활용하여 불용어제거(Remove Stopword)를 수행하고자 한다.
불용어 사전 텍스트 파일 다운로드
# 구글 드라이브에 업로드된 stopword.txt 파일 ID
file_id = '1-KtRjx2HBVuqP99kN8tZTiND7oRM6DIO'
# 파일 다운로드 링크 생성
url = f'https://drive.google.com/uc?id={file_id}'
# 'stopword.txt'파일을 다운로드한 뒤 저장할 경로 지정(파일명도 함께)
stopword = './data/kr_stopword_list.txt'
# 파일 다운로드
gdown.download(url, stopword, quiet=True)# 불용어 단어장 stopword.txt를 열람 후 리스트 변수화
with open(stopword, 'r', encoding='utf-8') as file:
stopword_list = file.read().splitlines()불용어 제거 함수 설계
불용어 제거 함수는 두가지 버전으로 설계를 진행하고자 한다.
# 불용어 제거 함수 설계 -> 가독성 높은 정석버전
def remove_stopword(tokenized_data, stopword):
remove_stopward_tokenized_data = []
for sent in tokenized_data:
f_sent = []
for word in sent:
if word not in stopword:
f_sent.append(word)
remove_stopward_tokenized_data.append(f_sent)
return remove_stopward_tokenized_data# 리스트 컴프리핸션을 적용하여 빠르게 불용어를 제거하는 함수
def Fast_remove_stopword(tokenized_data, stopword):
return [[word for word in sent if word not in stopword]
for sent in tokenized_data]첫번째 함수는 정석대로 가독성 높게 불용어를 제거하는 함수이고
두번째는 list compression를 적용하여
가독성은 조금 포기하지만, 전체적으로 연산의 실행속도가 더 빠르게 구동하는 함수를 설계했다.
두 함수 모두 동일하게 기능하지만,
두번째 함수가 더 빠르게 작동한다.
이 리스트 컴프리핸션 기법은 특히 자연어 천처리 할 때 자주사용될 가능성이 매우매우매우 높으니
숙지를 할 필요성이 있다.
불용어 제거 함수 적용
# 토큰화 처리한 '문제' 데이터셋의 불용어 제거
r_t_x_exam = Fast_remove_stopword(tokenized_x_exam, stopword_list)
# 토큰화 처리한 '선택지' 데이터셋의 불용어 제거
r_t_x_choice = list()
for temp in tokenized_x_choice:
f_temp = Fast_remove_stopword(temp, stopword_list)
r_t_x_choice.append(f_temp)
참고로 이렇게 제거 대상에 속하는 불용어는 대상 데이터셋의 성격에 따라 리스트 내 항목을 제거하거나 추가하는 식으로 조정해서 사용한다.
5. Build vocalbulary
이번 파트에서는 단어장(vocalbulary)을 생성하는데
특이한 규칙이 적용된 단어장을 생성한다.
단어장의 규칙은 아래와 같다.
- 토큰화 불용어 제거 후 정리된 단어를 단어장에 기재
- 단어장에 기재되는 단어는 '빈도가 높은 순'으로
- 등장빈도가 너무 낮은 '희소 단어'는 단어장에 기재하지 않음
Counter 라이브러리로 단어 데이터 정리
from collections import Counter
word_list = []
# 문제 항목의 단어리스트를 추출하기
for sent in r_t_x_exam:
for word in sent:
word_list.append(word)
#선택지 항목의 단어 리스트를 추출 후 더하기
for ele in r_t_x_choice:
for sent in ele:
for word in sent:
word_list.append(word)
# 단어와 해당 단어의 출몰 빈도를 함께 저장하는
# Counter 타입의 변수 생성
word_counts = Counter(word_list)
print(f"총 단어 종류: {len(word_counts)}")총 단어 종류: 23876위 Counter 라이브러리를 통해 단어 목록 / 등장 횟수를 1차적으로 정리한다.
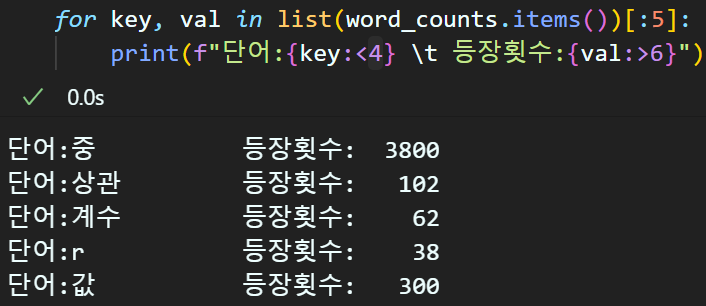
몇개 샘플 데이터를 출력해보면
{ 단어 : 등장횟수 }가 묶여서 dict데이터 타입으로 정리되는 것을 확인할 수 있다.
희소단어 분석 및 단어장 정렬(sort)
total_vocab_cnt = len(word_counts) #전체 단어 종류
rare_vocab_cnt = 0 #등장빈도수가 적은 단어는 몇 종?
total_freq, rare_freq = 0, 0
# 희소단어를 결정하는 하이퍼 파라미터
threshold = 3
for key, value in word_counts.items():
# 전체 단어의 등장빈도를 모두 가산하여 더함
total_freq = total_freq + value
if (value < threshold):
rare_vocab_cnt += 1
rare_freq += value
위 하이퍼 파라미터 threshold값으로 등장빈도가 3개 미만인 단어는 '희소 단어'로 분류하며
이 '희소 단어'의 개수가 대략 전체 단어 종류에서 절반 정도 차지하는 것을 확인할 수 있다.
이 희소단어를 다 포함시켜서 단어장(vocalbulary)을 만들면 매우 비효율적이기에 희소단어를 단어장에 추가시키지 않는것이 일반적이다.
#등장 빈도가 높은 단어 순으로 정렬하기
vocab = sorted(word_counts, key=word_counts.get, reverse=True)
#등장 빈도가 높은 단어만 인덱싱 하기
vocab_size = total_vocab_cnt - rare_vocab_cnt
vocab = vocab[:vocab_size]
이 vocab이 설계한 규칙 0, 1, 2에 의거하여
'빈도가 높은 순' + '희소 단어'는 삭제 하여 단어장을 생성한다.
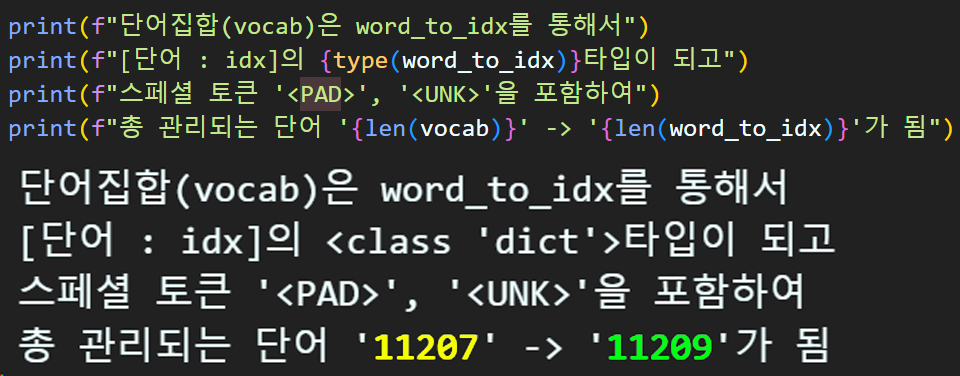
6. Integer Encoding (word to index)
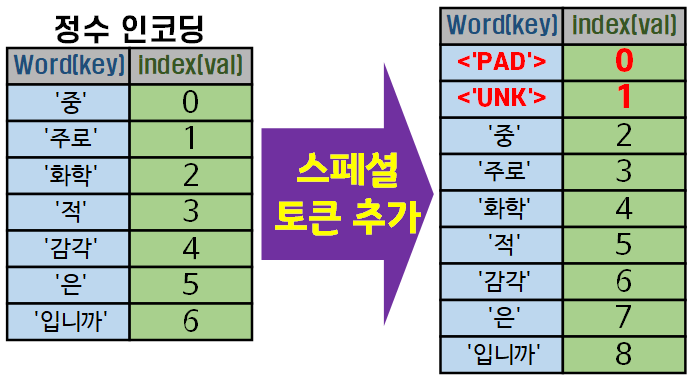
위 사진처럼 리스트 형식의 vocab이 '범주형 데이터' 이기에 이를 '정수형 데이터'로 변환할 수 있도록
word to idx 과정을 수행하는 변수를 생성하고
이때 Special Token을 맨 앞에 추가해준다.
이 Special Token은 텍스트 전처리 과정에서 사용하고자 하는 모델에 따라 종류가 달라지긴 하지만
적어도 위 두개 <PAD>, <UNK>는 거의 공통적으로 포함되는 필수 Special Token으로 볼 수 있다.
# 특수단어를 포함시켜 {단어:인덱스} 딕셔너리 생성하기
# 포함시킬 특수단어는 `<PAD>`, `<UNK>`으로
# <PAD> : 0, <UNK> : 1 순으로 특수단어는 맨 앞에 위치하기
word_to_idx = {'<PAD>' : 0, '<UNK>' : 1}
for idx, word in enumerate(vocab):
word_to_idx[word] = idx + 2위 과정에 대한 코드는 그렇게 어려운 편이 아니다.
딕셔너리 형태의 word_to_idx를 만들고 단어장 항목을 불러오는데 이때 맨 앞에 Special Token만 기입해주면 된다.
word to idx딕셔너리를 바탕으로 정수인코딩 수행
# 단어를 정수 인덱싱 규칙으로 정수 인덱싱 수행하기
def text_to_sequences(tokenized_data, word_to_idx):
encoded_data = [] #리턴해야할 정수 인코딩 결과값
for sent in tokenized_data:
idx_sequence = [] #단어장 리스트에서 idx를 찾아서 여기에 입력
for word in sent:
try: #word_to_idx에서 단어를 찾은 뒤 해당 단어의 인덱스(숫자)를 입력
idx_sequence.append(word_to_idx[word])
except KeyError: # word_to_idx 딕셔너리에 없는 키(단어)등장시 UNK로 인덱싱
idx_sequence.append(word_to_idx['<UNK>'])
#문장 내 단어를 모두 정수로 변환한 후에 이를 리턴값(리스트)에 입력
encoded_data.append(idx_sequence)
return encoded_data# 컬럼 '문제' 항목의 모든 단어를 정수로 인코딩
encoded_x_exam = text_to_sequences(r_t_x_exam, word_to_idx)
# 컬럼 '선택지' 항목의 단어를 정수로 인코딩, 이때 선택지는 데이터 타입=리스트
encoded_x_choice = list()
for choice_list in r_t_x_choice:
temp = text_to_sequences(choice_list, word_to_idx)
encoded_x_choice.append(temp)정수인코딩을 수행한 다음에는 '범주형 데이터' '정수형 데이터' 이 과정이 잘 되었는지 검증을 수행하자.
idx to word딕셔너리를 활용해 정수 인코딩 검증
# 정수인코딩이 잘 되었는지 확인하는
# idx_to_word 딕셔너리 생성
# {Key: val} --> {val:key}로 거울쌍 딕셔너리
idx_to_word = dict()
for key, val in word_to_idx.items():
idx_to_word[val] = key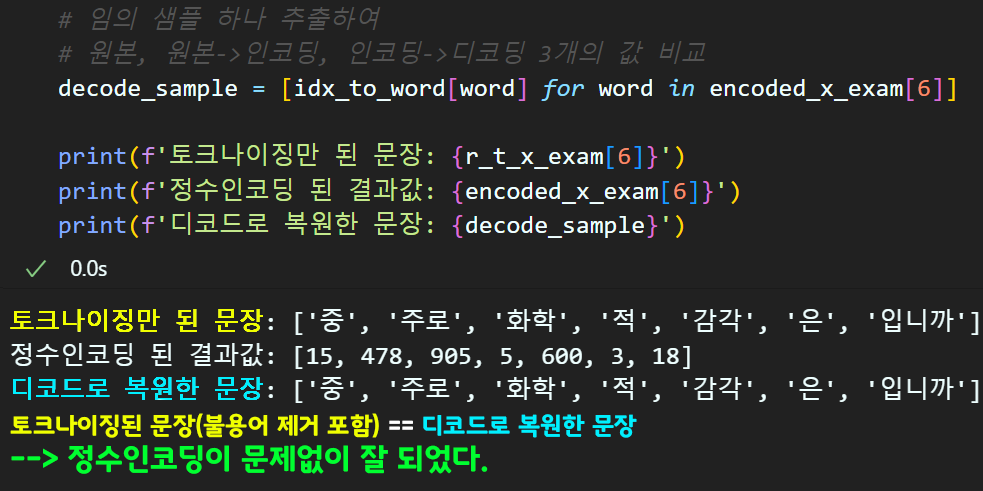
7. Sentence Padding (max context length)
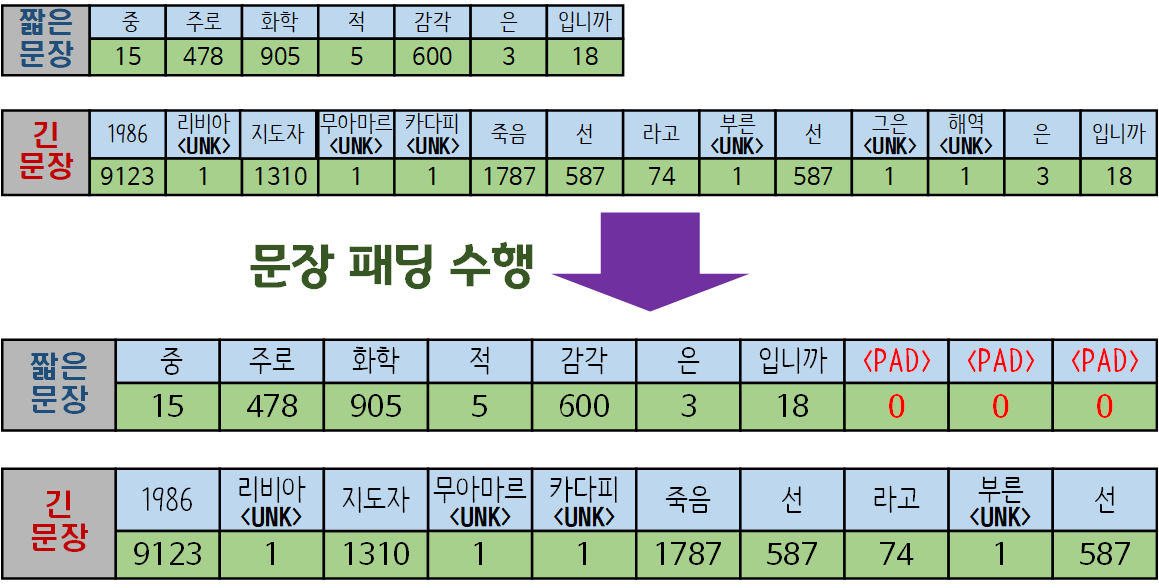 위 그림처럼 문장의 길이가 짧은 것은 뒤에
위 그림처럼 문장의 길이가 짧은 것은 뒤에 <PAD>를 붙이고
길이가 긴 문장은 뒤 부분 문장을 잘라내는 작업
을 수행하는 과정을 말한다.
따라서 모든 문장의 길이가 고정되게 조정하는 것이다.
 이렇게 길고 짧은 문장의 길이를 프로크루스테스 침대로 강제 평준화를 때리는건데
이렇게 길고 짧은 문장의 길이를 프로크루스테스 침대로 강제 평준화를 때리는건데
이게 LLM모델에서 흔히 context length라고 모델에 한번에 입력 가능한 최대 문장 길이를 의미한다.
데이터셋의 문장 길이 분석
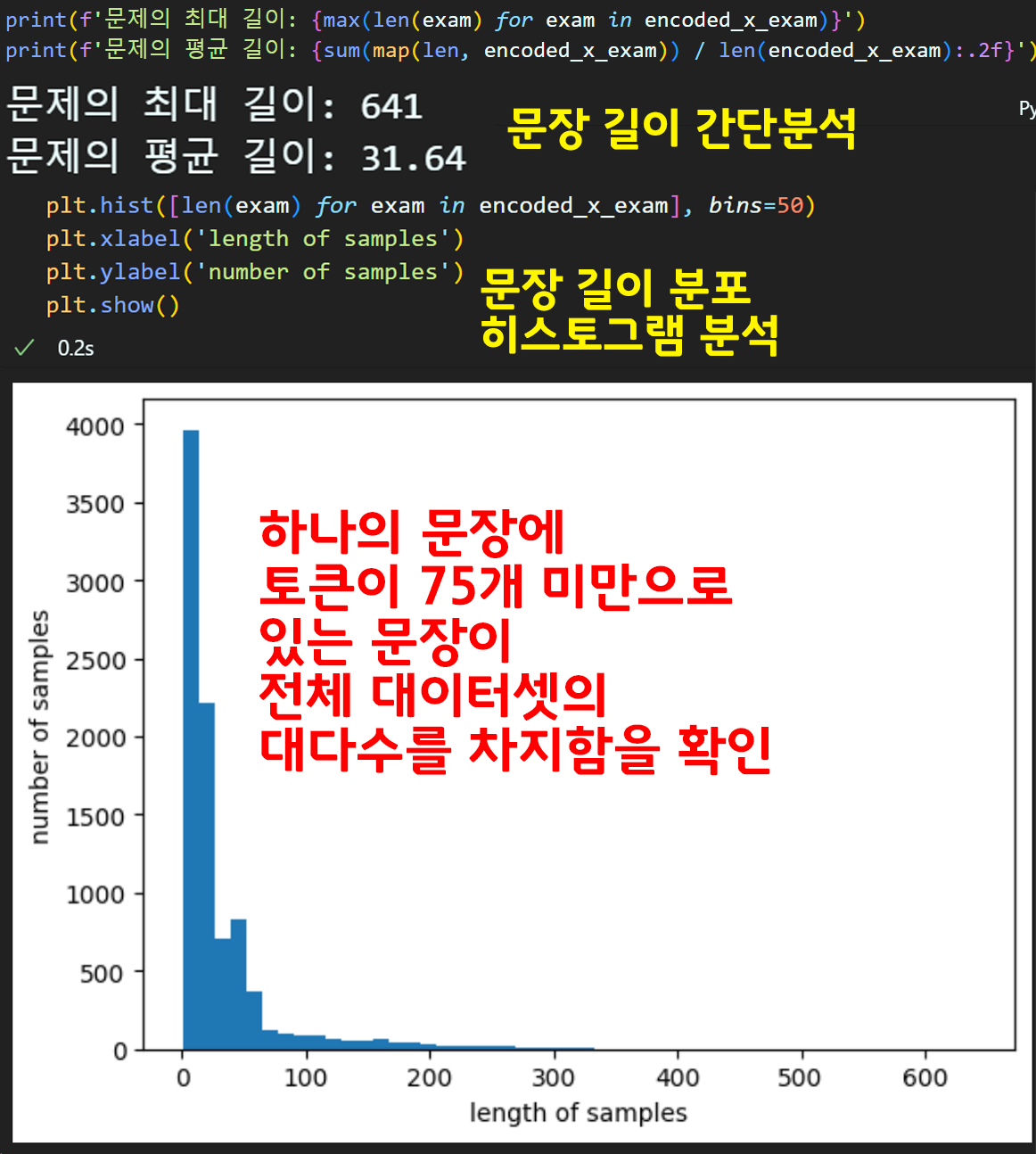
위 코드를 통해 현재 문장들이 평균적으로 몇개의 토큰을 보유하고 있는지 한번 분석을 수행한다
위 정보를 바탕으로 하이퍼 파라미터 : max context length을 설정하는 것이다.
max context length설정
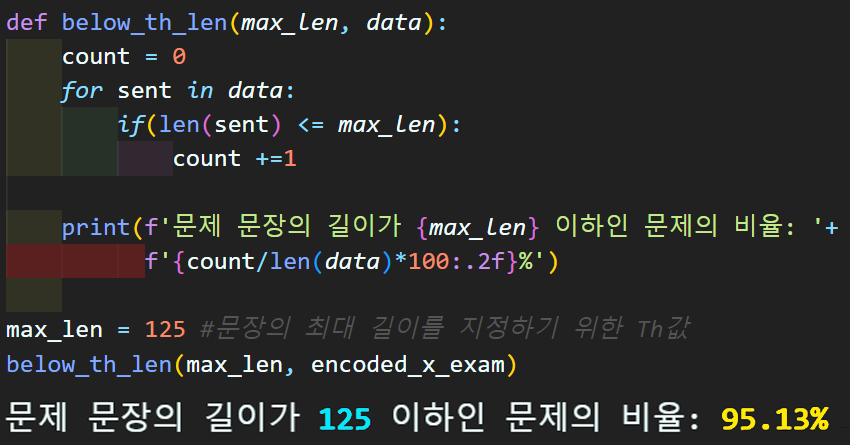
전체 문장 비중에서 max context length같은 하이퍼 파라미터를 설정하는건
당연히 사람마다 자유다
필자는 5% 정도의 긴 문장은 뒤 단어(토큰)이 삭제되도록
max context length를 설정했다.
문장 패딩 수행
max_len = 125 #문장의 최대 길이를 지정하기 위한 Th값
#'문제' 항목에 대한 문장 패딩
def pad_seq_exam(exam, max_len):
features = np.zeros((len(exam), max_len), dtype=int)
for idx, sent in enumerate(exam):
if len(sent) != 0: #예외처리구문
features[idx, :len(sent)] = np.array(sent)[:max_len]
return features
#'선택지' 항목에 대한 문장 패딩
def pad_seq_choice(choice, max_len):
features = np.zeros((len(choice), len(choice[0]), max_len), dtype=int)
for idx, cho_list in enumerate(choice):
for cho_idx, sent in enumerate(cho_list):
if len(sent) != 0:
features[idx, cho_idx, :len(sent)] = np.array(sent)[:max_len]
return features
#'답안'항목은 numpy자료형으로만 변환
def pad_seq_label(label):
features = np.zeros((len(label), len(label[0])), dtype=int)
for idx, one_hot in enumerate(label):
features[idx] = np.array(one_hot)
return features# 각 함수별로 문장 패딩 실행
padded_x_exam = pad_seq_exam(encoded_x_exam, max_len)
padded_x_choice = pad_seq_choice(encoded_x_choice, max_len)
padded_y_label = pad_seq_label(tokenized_y_label)
여기까지 수행했으면 은 텍스트 전처리 과정은 모두 완수했다 볼 수 있다.
numpy에서 제공하는 자료형으로 모든 데이터가 '정수형 데이터'로 변경되었으니 이제 모델에 입력 가능한 데이터 전처리가 완료된 것이다.
8. 데이터로더 생성 및 사후분석
모델에 입력가능한 데이터로더로 변환하기
import torch
from torch.utils.data import TensorDataset, DataLoadertensor_x_exam = torch.tensor(padded_x_exam).to(torch.int64)
tensor_x_choice = torch.tensor(padded_x_choice).to(torch.int64)
tensor_y_label = torch.tensor(padded_y_label).to(torch.int64)
# 텐서 자료형으로 변환된 x_data와 y_label을 TensorDataset 자료형으로 변환
trainset = TensorDataset(tensor_x_exam, tensor_x_choice, tensor_y_label)
# TensorDataset 자료형을 데이터로더로 변환
trainloader = DataLoader(trainset, batch_size=64, shuffle=True)마지막으로 모델에 입력가능한 TensorDataset, DataLoadar 자료형의 생성은 위 코드로 간단하게 해결이 된다.
데이터 사후분석
변환된 데이터의 사후분석은 Special Token인 <UNK>, <PAD> 개수
그리고 OOV(Out Of Vocabulary)으로 인해 <UNK> 처리되어 의미를 잃어버린 단어의 개수를 구하고자 한다.
# 전체 데이터 개수
total_count = tensor_x_exam.numel()
# 0(<PAD>)과 1(<UNK>)로 인코딩된 데이터 개수
spec_data_count = torch.sum((tensor_x_exam == 0) | (tensor_x_exam == 1)).item()
# 0과 1을 제외한 데이터 개수
filtered_count = total_count - spec_data_count
# 의미있는 단어 / 특수단어 비율
ratio = filtered_count / total_count
# <UNK>로 처리된 데이터 개수
unk_data_count = torch.sum((tensor_x_exam == 1)).item()
# 의미를 유실해버린 데이터의 비율 / 의마가 있는 데이터의 비율
lost_ratio = unk_data_count / filtered_count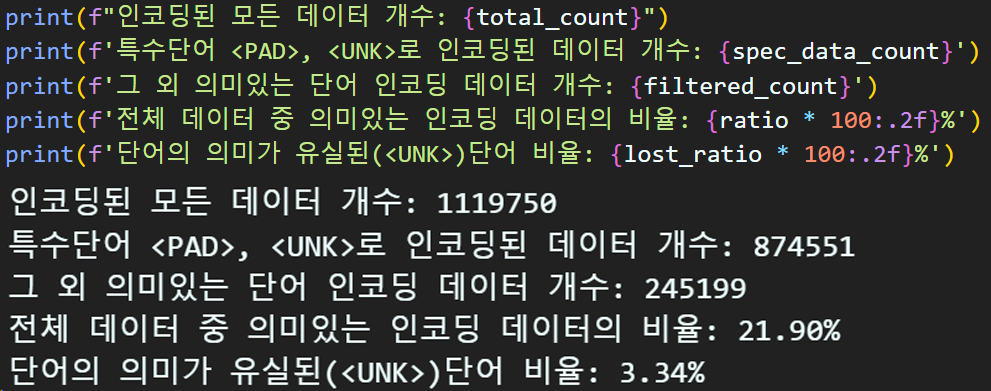
결과물을 본다면 의미가 유실된 <UNK>는 별로 안되고
의미가 없는 단어(토큰) 중 대다수는 <PAD>로 채워진 것을 간접적으로 확인할 수 있다.
텍스트 전처리의 개념 및 절차가 좀 익숙하지 않아서 많이 헤멨는데
이 포스트까지 작성하면서 이제 좀 정립이 된 느낌이다.

NLP의 길은 험난한 것 같다...
