
개요
본 블로그 포스팅은 수도권 ICT 이노베이션 스퀘어에서 진행하는 AI 핵심 기술 집중 클래스의 자연어처리(NLP) 강좌 내용을 필자가 다시 복기한 내용에 관한 것입니다.
1. 벡터화기초 - Bag of Words
이전 포스트 1. NLP-Text 전처리 : 한번 전처리 실습 - AI 핵심기술 강의 복습에서
0. Data preprocessing
1. Tokenization (Word & Sentence)
2. Cleaning, Remove Stopword, Normalization
3. Build vocalbulary
4. Integer Encoding (word to index)
5. Sentence Padding (max context length)
6. Vectorization (Embedding)
0~5번 항목까지 실습을 진행했고 6. Vectorization에 대해서는 진행하지 않았다.
하지만 아에 Vectorization을 안 했다고는 보기는 어려운게
이전 포스트에서 Counter라이브러리를 사용하여
{ 단어 : 등장횟수(빈도) }의 딕셔너리로 묶고
등장빈도가 너무 낮은 '희소 단어'는 단어장을 생성하는데 배제하는 과정을 수행했다.
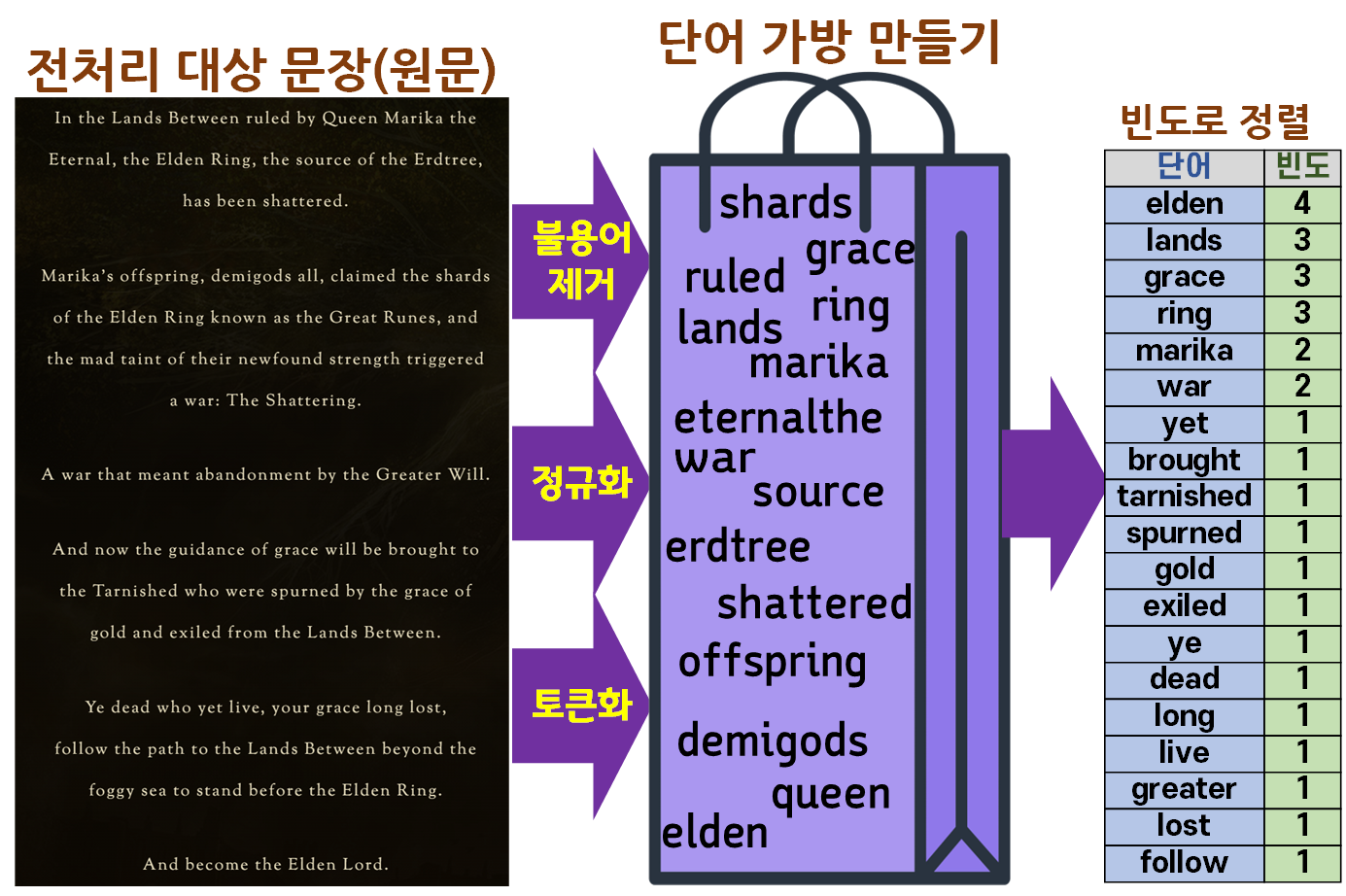
위 이미지에서 설명하는 과정 중 단어가방, 그리고 이것을 빈도 단위로 분류한 것이
1. NLP-Text 전처리 : 한번 전처리 실습 - AI 핵심기술 강의 복습 - 5. Build vocalbulary
Counter 라이브러리로 단어 데이터 정리
희소단어 분석 및 단어장 정렬(sort)
에서 수행했던 내용과 동일한 과정이다.
따라서 위 이미지의 과정을 실습을 통해 무의식적으로 진행을 했고
이게 가장 기초적인 Vectorization 방법인 Bag of Words라 부른다.
2. 고전 벡터화 : DTM, TF-IDF
고전 벡터화 방법론은 1. NLP-Text 전처리 : 한번 전처리 실습 - AI 핵심기술 강의 복습에서
6. Integer Encoding 이후에 적용하는 가장 기초적인 방법론이다.
우선 이전 포스트에서 수행한 작업 내용을 그림으로 도식화 하여 머리에 각인하자.
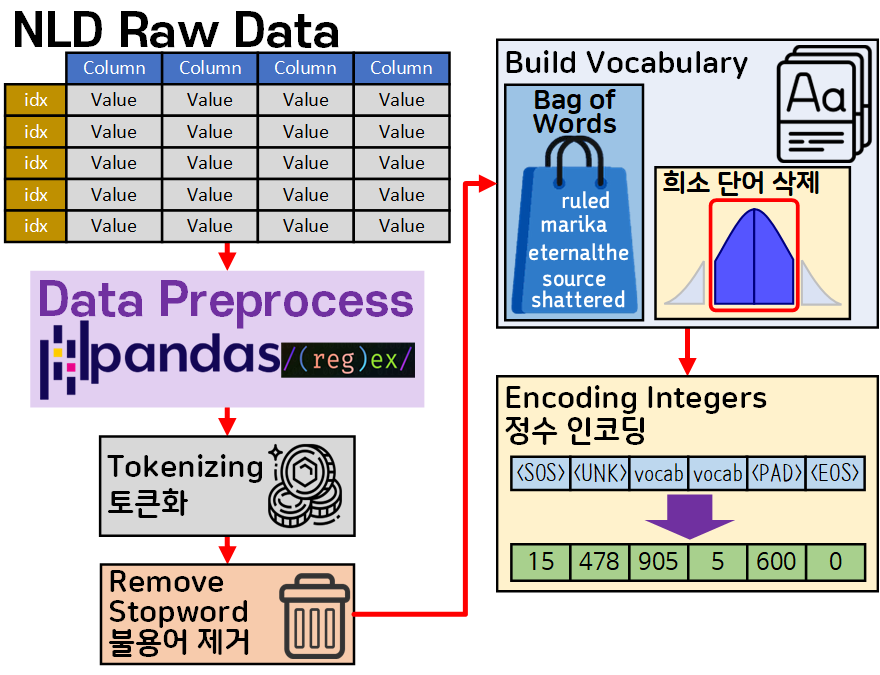
문장패딩을 일단 제외하고 데이터 전처리 및 텍스트 전처리 과정을 도식화 하면 위 사진처럼 표현할 수 있다.
여기까지 수행된 정수 인코딩 결과값은 1차원 데이터라 볼 수 있다.
이제 이 결과값을 본격적으로 Vectorization을 적용하는데 간단하게
1차원 데이터 2차원 데이터로 변경하는것을 말한다.
이때 신경망(딥러닝) 방법론을 적용하지 않고 고전적으로 벡터화을 수행하는 방법론이 One-Hot Encoding, DTM(Document Term Matrix), TF-IDF(Term Frequency Inverse - Inverse Document Frequency)
3가지가 존재한다.
물론 그 결과값은 아래 그림처럼 매트릭스가 생성될 때
매트릭스 내 원소가 대부분 0으로 채워져 있는
희소 벡터(Sparse Vector)로 벡터화 된다.
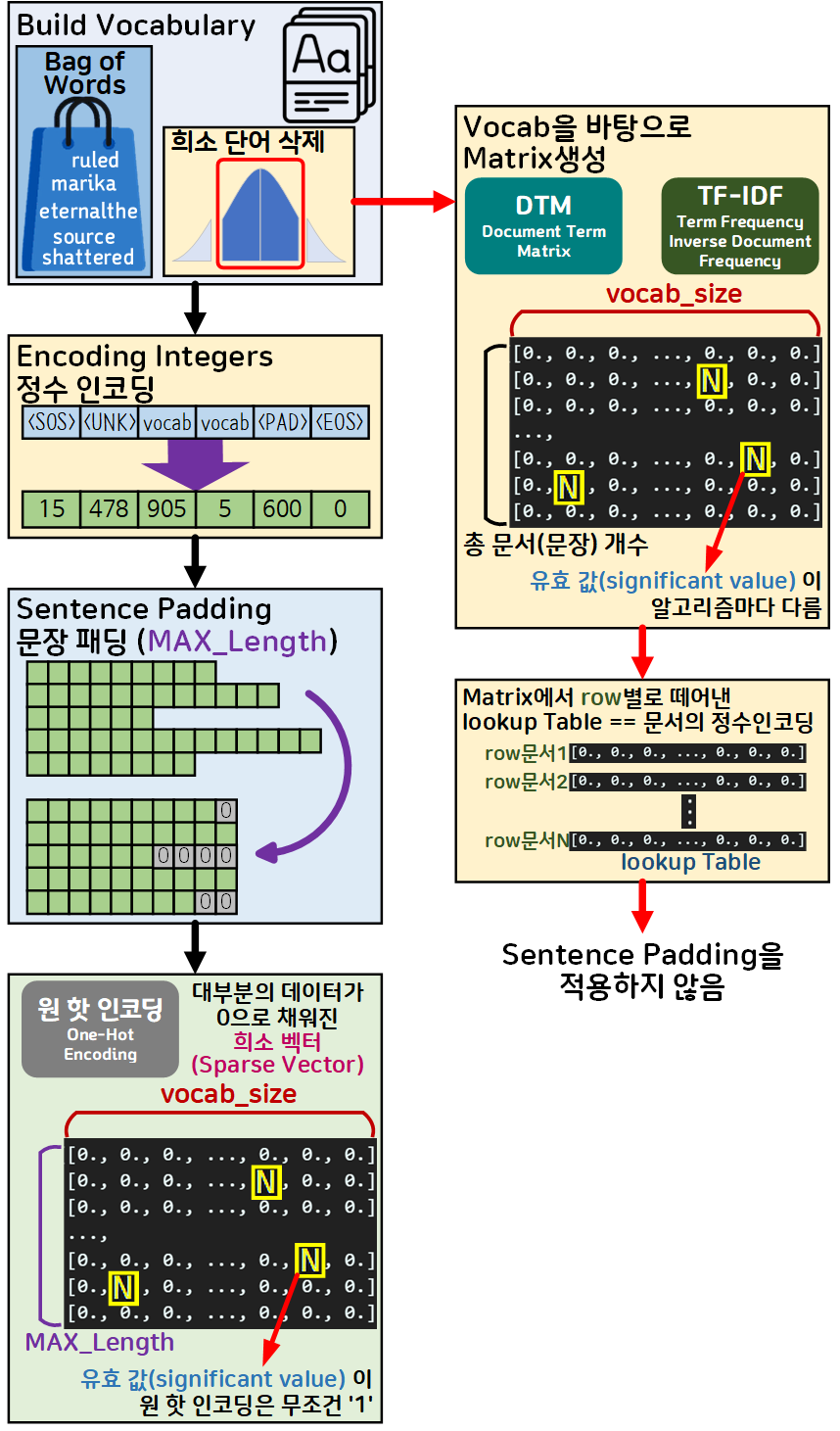
이를 그림으로 표현하면 위 사진과 같으며, One-Hot Encoding, DTM, TF-IDF 셋 다 희소 벡터(Sparse Vector)를 만들지만,
이 희소 벡터(Sparse Vector)를 One-Hot Encoding는 문장패딩 까지 수행한 최종 결과물에 대해서 벡터화를 진행하고
DTM, TF-IDF는 Build vocab단계의 희소단어를 삭제한 후 생성하는 단어장(vocabulary)에 대하여 희소 벡터(Sparse Vector)를 생성한다.
따라서 One-Hot Encoding와 DTM, TF-IDF는 희소 벡터(Sparse Vector)를 생성하는 단계가 다르고, 벡터 내 의미가 있는 유효 값(significant value)에 대하여 정의하는 방식이 또 다르다.
유효 값(significant value)의 정의 방식을 각 벡터화 방법론으로 정리하면 아래와 같다.
1) One-Hot Encoding : 무조건 1
2) DTM : 문서(문장)내 단어의 빈도 정보도 고려
위 결과를 아래의 임의 문장이나 문서를 바탕으로 One-Hot Encoding, DTM의 수행결과를 보면 아래와 같다.
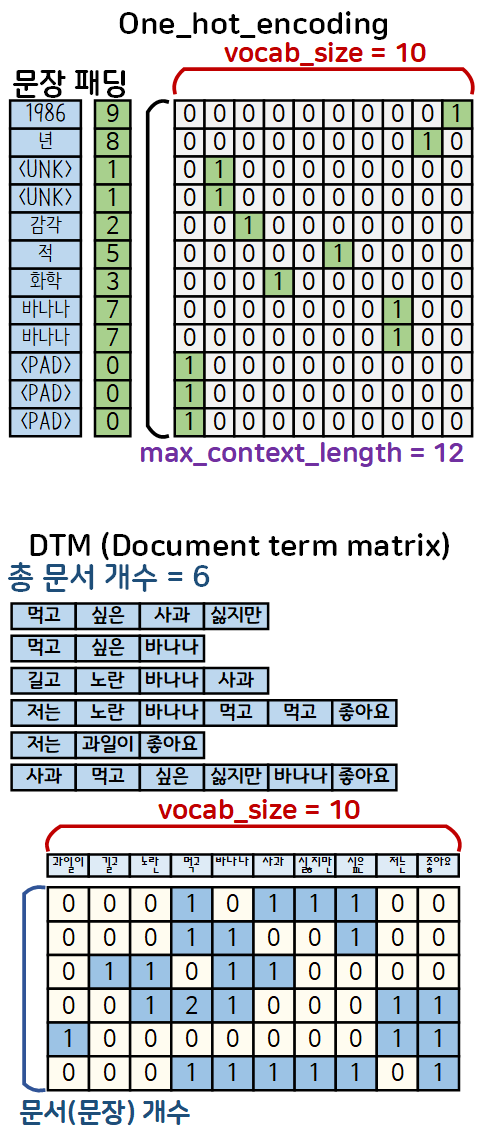
임의의 문장을 정수인코딩 + 문장패딩까지 수행했고 그 결과물에 대해 원핫 인코딩 결과물인 희소 벡터값을 보면
단어와 매칭되어 있는 정수의 idx에 해당하는 배열의 원소값만 1로 유효 값(significant value)이 변경되지만
DTM의 경우 해당 Bag of words 수행으로 문서-빈도 매트릭스를 생성하는 것이며, 빈도가 높은 값일 수록 했을 시, 유효 값(significant value)을 빈도(중복)한 값으로 원소값을 인코딩한다는 뜻이다.
결국 DTM은 One-Hot Encoding에서 빈도정보를 더 추가한 희소 벡터(Sparse Vector)를 생성하는 것이라 보면 된다.
이제 TF-IDF에 대한 설명인데

유효 값(significant value)을 결정하는 방법론이 좀 더 복잡한 수식을 쓰고, 그 결과가 정수값이 아닌 실수값을 갖게 된다.
아무튼 수식이 두개를 섞어서 살짝 어려워 보이는데
결국 가중치를 곱하는 것이고
가중치의 규칙이
1) 모든 문서(문장)에서 공통적으로 많이 등장하는 단어 불용어처럼 큰 의미가 없는 단어일 가능성이 높을 것이다
2) 특정 문서(문장)에서 반복적으로 많이 등장함 중요도가 높은 의미 있는 단어라 판단하자
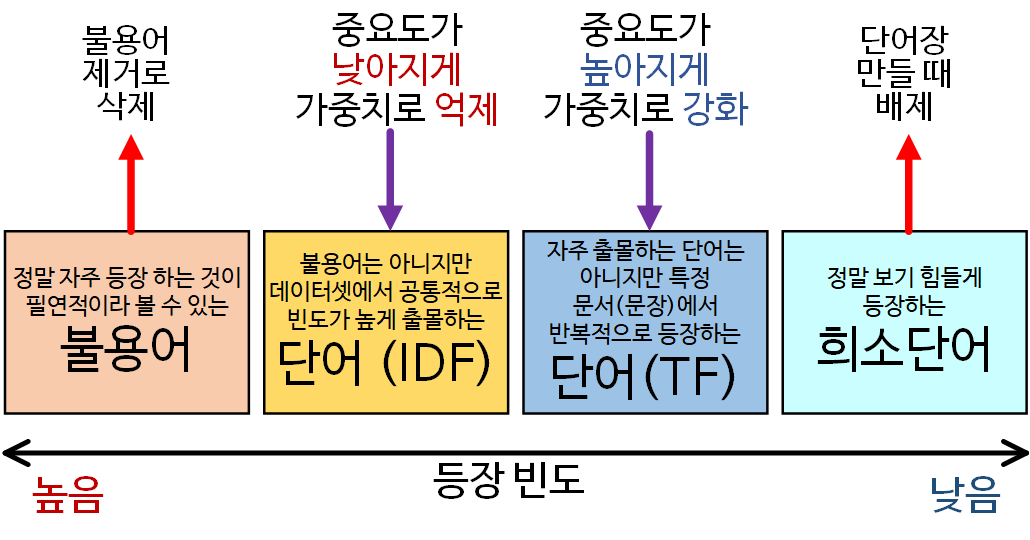
따라서 단어의 빈도수 별로 4개의 카테고리를 나누어 본다면
TF-IDF는 의미 있는 단어를 좀 더 집중해서 볼 수 있도록 가중치를 부여한다 볼 수 있다.
2.1 TF-IDF 실습 준비
TF-IDF는 고전 벡터화 방법론 중에서는 그래도 가장 실무에서 많이 사용되는 항목이기에 실습 을 진행하도록 하겠다.
2.1.1. 데이터셋 다운로드

데이터셋은 토닥토닥 sklearn - 텍스트를 위한 머신러닝 교재에 실린
한국 네이버 뉴스 카테고리 데이터셋을 활용하여 데이터 전처리 후 뉴스기사 분류 추론작업까지 수행해 보고자 한다.
먼저 위 업로드된 웹페이지에서 데이터셋을 다운로드 받으면 폴더별로 뉴스 기사가 다 텍스트로 담겨져 있기에
이를 필자가 정리 + 셔플을 수행한 *.csv 파일로 한번 전처리 하여 이를 구글 드라이브에 업로드 했다.
https://drive.google.com/file/d/1-LF9_aqZoF78JZS5excKwfBtqONYfYmG/view?usp=drive_link
위 파일을 다운로드 받는 코드를 먼저 작성하자
import gdown
# 구글 드라이브에 업로드된 train.csv 파일 ID
file_id = '1-LF9_aqZoF78JZS5excKwfBtqONYfYmG'
# 파일 다운로드 링크 생성
url = f'https://drive.google.com/uc?id={file_id}'
# 'train.csv'파일을 다운로드한 뒤 저장할 경로 지정(파일명도 함께)
csv_file = './data/news_data.csv'
# 파일 다운로드
gdown.download(url, csv_file, quiet=True)
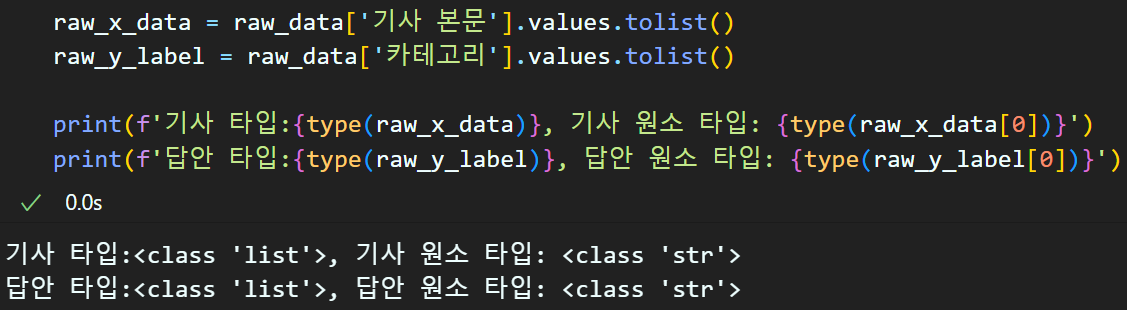
다운로드한 엑셀 파일을 열람하면 기사 본문, 카테고리 두개의 컬럼에 데이터가 담겨있음을 확인할 수 있다.
import numpy as np
import pandas as pd
import matplotlib.pyplot as pltraw_data = pd.read_csv(csv_file)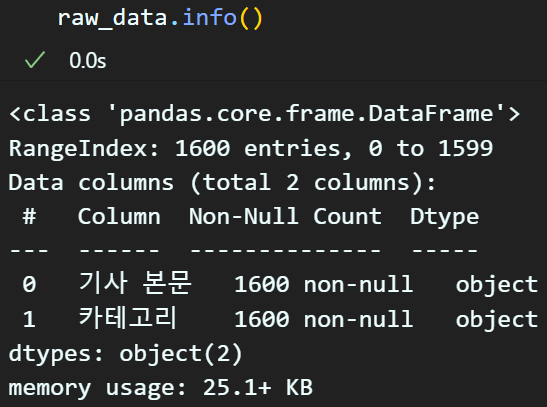
다운로드 받은 데이터셋은 이전 실습처럼 pandas - DataFrame 로 변환 후 기본 정보를 확인하도록 하자.
2.1.2 데이터 전처리
결측치 및 중복치 제거
# 컬럼별 결측치 cnt값을 모두 더한 값 (정수형 데이터)
missing_data = raw_data.isna().sum().values.sum()
# 결측치 정보가 0이면 결측치가 없으니 아래 함수가 실행안됨
if missing_data != 0:
raw_data.dropna(how='any', inplace=True)
# 중복치 제거
raw_data.drop_duplicates(subset='기사 본문',
keep='first',
inplace=True)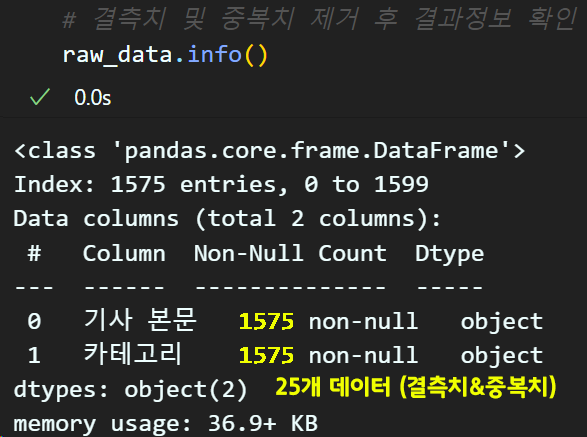
정규표현식
import re
# 사용할 정규표현식 객체
# 한글, 영어(소문자, 대문자), 숫자
p1 = re.compile(r'[^ㄱ-ㅎ가-힣a-zA-Z0-9\s]')
# 개행문자 + 하나 이상의 공백문자
p2 = re.compile(r'\n|\s+')
def regex_sub(origin_sent):
clean_text = p1.sub(repl=" ", string=origin_sent)
clean_text = p2.sub(" ", clean_text)
return clean_text# 설계한 정규표현식기반 특수문자 삭제 함수 적용
# apply함수는 inplace=True(덮어쓰기) 기능이 없음
raw_data['기사 본문'] = raw_data['기사 본문'].apply(regex_sub)
기타 데이터 처리
label_category = set(raw_data['카테고리'].values)라벨 데이터 항목은 범주형 데이터이니 따로 추출해서 저장한다.

2.1.3 토큰화 수행
from mecab import MeCab #한글 단어 토크나이저
from tqdm import tqdm
# 범주형 데이터 -> 정수형 데이터로 전환하기 위한 라이브러리
from sklearn.preprocessing import LabelEncoder
#mecab 형태소 분석기 인스턴스화
word_tokenizer = MeCab()
# 문제, 선택지 데이터 타입에 맞춰서 워드 토크나이징 수행
def tokenize(x_data, word_tokenizer):
tokenized_sentences = list()
for sent in tqdm(x_data):
tokenized_sent = word_tokenizer.morphs(sent)
tokenized_sentences.append(tokenized_sent)
return tokenized_sentences
# 라벨 데이터는 범주형데이터 -> 정수형 데이터로 전환
e = LabelEncoder()
e.fit(raw_y_label)# 기사 본문 항목을 토큰화 수행행
tokenized_x_exam = tokenize(raw_x_data, word_tokenizer)
tokenized_y_label = e.transform(raw_y_label)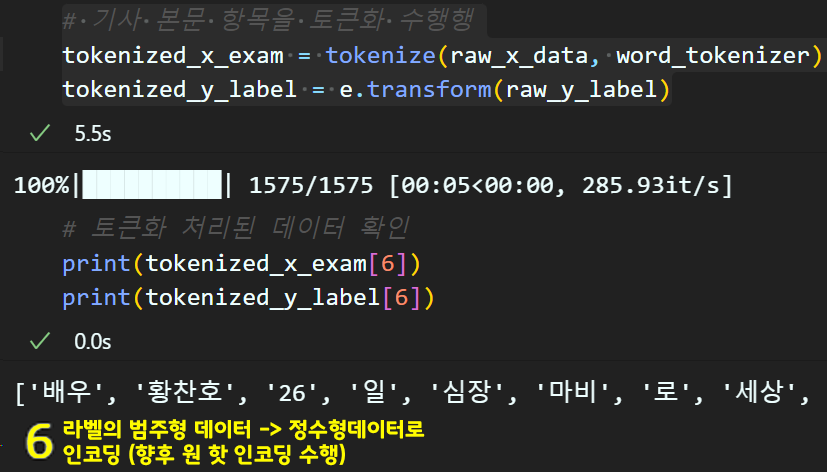
2.1.4 불용어 제거
# 구글 드라이브에 업로드된 stopword.txt 파일 ID
file_id = '1-KtRjx2HBVuqP99kN8tZTiND7oRM6DIO'
# 파일 다운로드 링크 생성
url = f'https://drive.google.com/uc?id={file_id}'
# 'stopword.txt'파일을 다운로드한 뒤 저장할 경로 지정(파일명도 함께)
stopword = './data/kr_stopword_list.txt'
# 파일 다운로드
gdown.download(url, stopword, quiet=True)# 불용어 단어장 stopword.txt를 열람 후 리스트 변수화
with open(stopword, 'r', encoding='utf-8') as file:
stopword_list = file.read().splitlines()# 리스트 컴프리핸션을 적용하여 빠르게 불용어를 제거하는 함수
def Fast_remove_stopword(tokenized_data, stopword):
return [[word for word in sent if word not in stopword]
for sent in tokenized_data]# 토큰화 처리한 '기사 본문' 데이터셋의 불용어 제거
r_t_x_exam = Fast_remove_stopword(tokenized_x_exam, stopword_list)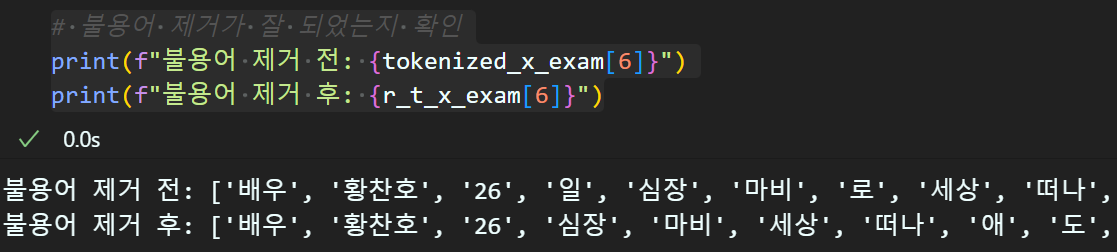
2.1.5 단어장 만들기(희소단어 제거)
from collections import Counter
word_list = []
# 문제 항목의 단어리스트를 추출하기
for sent in r_t_x_exam:
for word in sent:
word_list.append(word)
# 단어와 해당 단어의 출몰 빈도를 함께 저장하는
# Counter 타입의 변수 생성
word_counts = Counter(word_list)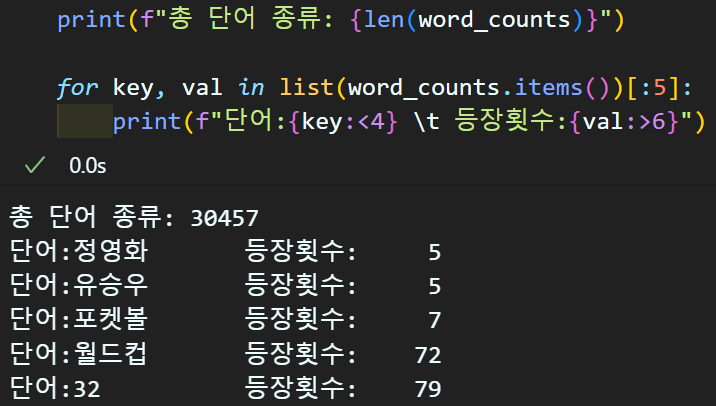
total_vocab_cnt = len(word_counts) #전체 단어 종류
rare_vocab_cnt = 0 #등장빈도수가 적은 단어는 몇 종?
total_freq, rare_freq = 0, 0
# 희소단어를 결정하는 하이퍼 파라미터
threshold = 3
for key, value in word_counts.items():
# 전체 단어의 등장빈도를 모두 가산하여 더함
total_freq = total_freq + value
if (value < threshold):
rare_vocab_cnt += 1
rare_freq += value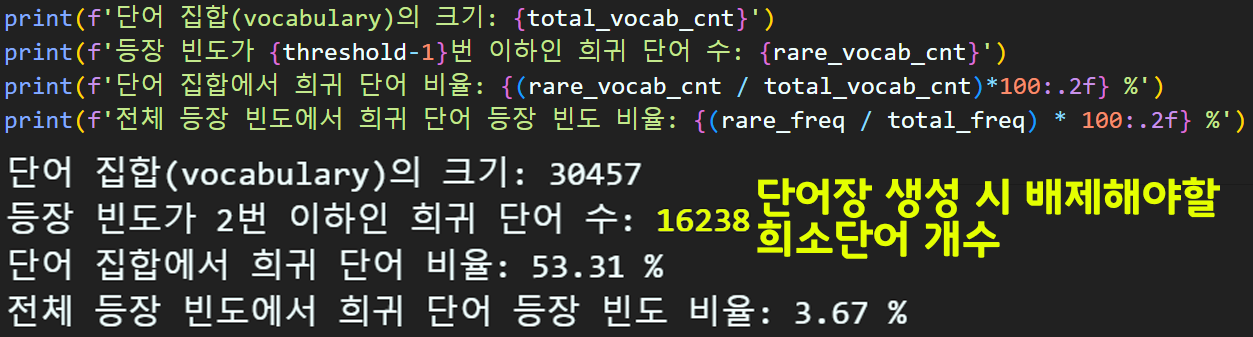
#등장 빈도가 높은 단어 순으로 정렬하기
vocab = sorted(word_counts, key=word_counts.get, reverse=True)
#등장 빈도가 높은 단어만 인덱싱 하기
vocab_size = total_vocab_cnt - rare_vocab_cnt
vocab = vocab[:vocab_size]
2.1.6 스페셜 토큰 추가
# 특수단어를 포함시켜 {단어:인덱스} 딕셔너리 생성하기
# 포함시킬 특수단어는 `<PAD>`, `<UNK>`으로
# <PAD> : 0, <UNK> : 1 순으로 특수단어는 맨 앞에 위치하기
word_to_idx = {'<PAD>' : 0, '<UNK>' : 1}
for idx, word in enumerate(vocab):
word_to_idx[word] = idx + 2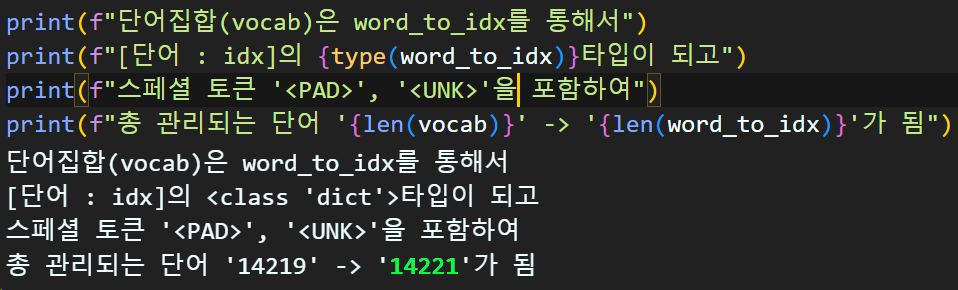
여기까지 수행했다면 이제 DTM, TF-IDF를 생성하기 위한 준비작업은 모두 마친 것이라 보면 된다.
2.2 TF-IDF 생성 실습
2.2.1 DTM 만들기
첫번째로 수행할 항목은 DTM을 만드는 작업이다.
이 DTM을 생성한 뒤 적절한 가중치를 계산 후 적용하는 것이 TF-IDF이니 DTM을 먼저 만들어야 한다.
# 단어 : 빈도가 함께 포함되는 DTM 생성하기
def create_dtm(x_data, word_to_idx):
# row = x_data의 개수(문서 개수), col = 생성한 단어장 내 단어 개수
dtm = np.zeros((len(x_data), len(word_to_idx)), dtype=int)
for i, sent in enumerate(x_data):
for word in sent:
#word_to_idx에서 단어를 찾은 뒤 해당 단어의 인덱스(숫자)를 입력
try:
word_idx = word_to_idx[word]
# word_to_idx 딕셔너리에 없는 키(단어)등장시 UNK로 인덱싱
except KeyError:
word_idx = word_to_idx['<UNK>']
#(문서 인덱스, 찾은 단어 인덱스) 항목에 +1 가산
dtm[i, word_idx] +=1
return dtmdtm_matrix = create_dtm(r_t_x_exam, word_to_idx)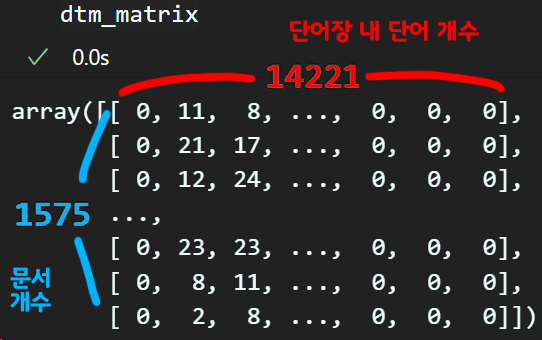
2.2.2 TF-IDF 만들기
위 생성한 DTM에서 각 축별로 합산한 값을 적절하게 사용하면
TF-IDF의 수식을 적용한 가중치를 생성할 수 있다.
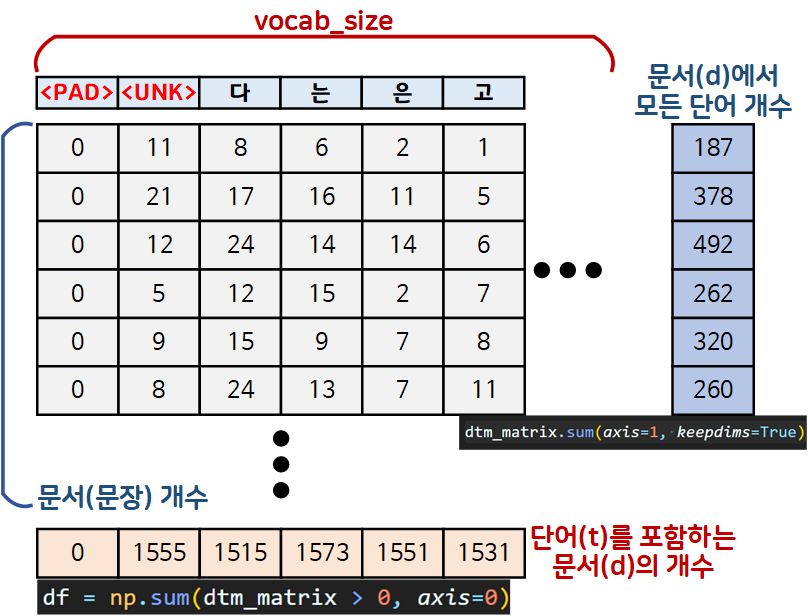
이 각 축별로 합산한 값이 아래 수식에서 TF의 분모, IDF의 분모로 사용됨을 잊지 말자

def create_tf_idf(dtm):
# TF 계산 : 문서(d)에서 단어(t)가 등장횟수 / 문서(d)에서 모든 단어 개수
# keepdims=True는 축 별로 더한 sum의 결과 차원정보 유지
tf = np.array(dtm / dtm.sum(axis=1, keepdims=True))
# 문서의 총 개수
num_docs = dtm.shape[0] #row열의 개수
# IDF 계산 : log(총 문서 개수 / 단어(t)를 포함하는 문서(d)의 개수)
df = np.sum(dtm > 0, axis=0) #단어 별 문서 등장 횟수
# 기존 수식의 분자, 분모, 그리고 총 결과값에 +1을 더해서
# 안정적인 idf를 산출 (smoothing)
idf = np.log((num_docs + 1) / (df + 1)) + 1
tf_idf =tf * idf
return tf_idftf_idf_matrix = create_tf_idf(dtm_matrix)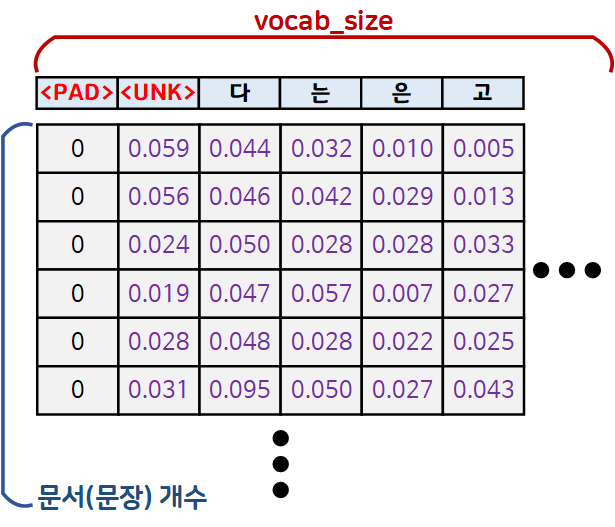
TF-IDF의 가중치가 적용된 매트릭스의 맨 앞단 부분의 원소값을 확인하면 위 사진과 같다. 대체로 큰 의미가 없으나 빈도가 높게 출현하는 단어를 앞단에 오게끔 정렬을 수행했기에
해당 단어들의 가중치가 대체로 0에 가까운 값을 가짐을 확인 할 수 있다.
이렇게 DTM, TF-IDF를 수행하여 데이터셋을 인코딩하면
해당 데이터셋 내 문서의 단어 순서정보는 보존되지 않는다.
하지만 위 인코딩 결과만으로 모델을 학습하여 결과를 산출할 수 있다.
3. TF-IDF기반 모델 학습
3.1 데이터 로더 만들기
import torch
# x_data는 float32 자료형으로 변환
tensor_x_data = torch.tensor(tf_idf_matrix, dtype=torch.float32)
# y_label은 int64 자료형으로 변환
tensor_y_label = torch.tensor(tokenized_y_label, dtype=torch.int64)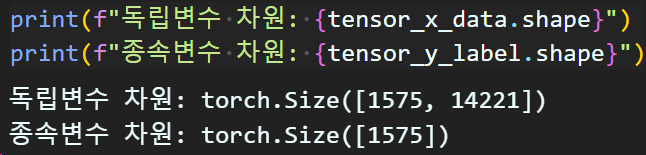
from torch.utils.data import TensorDataset, DataLoader
trainset = TensorDataset(tensor_x_data, tensor_y_label)
trainloader = DataLoader(trainset, shuffle=True, batch_size=64)y_label데이터는 원-핫 인코딩을 수행하지 않아도 모델에 입력 가능하니 그대로 텐서 자료형으로 변경하고
x_data는 TF-IDF의 인코딩 결과값을 사용하면 된다.
3.2 Simple Net 기반 기사(카데고리)분류
정말 간단한 Simple Net를 만들고 학습시켜서 loss값을 확인해보자
import torch.nn as nn
# 간단한 simplenet 생성
class simpleNet(nn.Module):
def __init__(self, tfidf_size, num_label):
super(simpleNet, self).__init__()
self.fcn1 = nn.Linear(tfidf_size, 1400)
self.relu = nn.ReLU()
self.fcn2 = nn.Linear(1400, num_label)
def forward(self, x):
x = self.fcn1(x)
x = self.relu(x)
x = self.fcn2(x)
return xdevice = torch.device("cuda" if torch.cuda.is_available() else 'cpu')
model = simpleNet(tf_idf_matrix.shape[0], len(label_category))
model.to(device)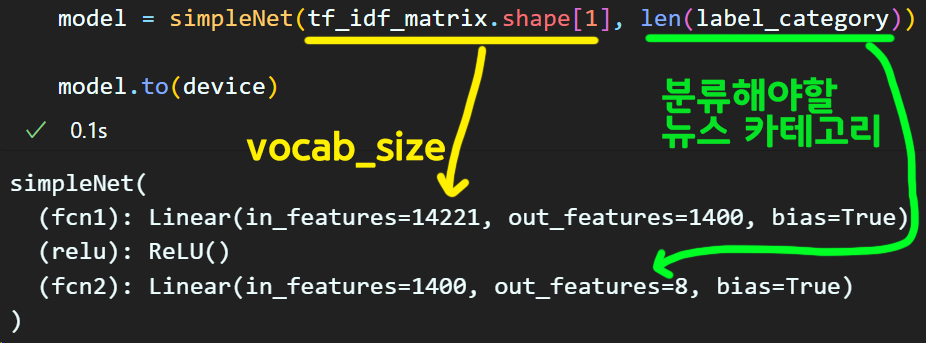
3.3 하이퍼 파라미터 설정
import torch.optim as optim
# 로스함수 및 옵티마이저 설계
criterion = nn.CrossEntropyLoss()
optimizer = optim.Adam(model.parameters(), lr=0.001)3.4 모델 훈련
#모델 훈련시키기
model.train(True)
optimizer.zero_grad()
for epoch in range(10):
epoch_loss = 0
for batch in trainloader:
# batch >> (train_dataset, label)
batch = tuple(t.to(device) for t in batch)
y_pred = model(batch[0])
labels = batch[1]
loss = criterion(y_pred, labels) #loss를 구하기
epoch_loss += loss.item()
loss.backward()
optimizer.step()
optimizer.zero_grad()
print(f"훈련횟수: {epoch}, 현재로스: {epoch_loss:.4f}")
model.train(False)
위와 같은 방식으로
TF-IDF 알고리즘으로 독립변수인 X_data를 정수인코딩+벡터화를 수행한 후
독립변수인 뉴스 카테고리(Y_label)을
가장 간단한 SimpleNet을 설계하여 뉴스 카테고리 분류를 진행할 수 있다.
