
개요
본 블로그 포스팅은 수도권 ICT 이노베이션 스퀘어에서 진행하는 AI 핵심 기술 집중 클래스의 자연어처리(NLP) 강좌 내용을 필자가 다시 복기한 내용에 관한 것입니다.
1. 임베딩레이어와 LM
이전 포스트 : 1. NLP-Text 전처리 : 현대 벡터화(Word Embedding) (2) - AI 핵심기술 강의 복습
에서 Embedding layer란 고 차원의 희소 벡터를 저 차원의 밀집 벡터로 정보를 응축하면서
동시에 응축된 정보(단어)가 데이터셋에 포함된 다른 정보(단어)와 유사한 의미를 가진 정도를 포함하게끔 설계한 벡터화 방법론 이라 정리했다.
이 Embedding layer는 현대의 언어모델을 설계할 때는 거의 맨 앞단에 항상 위치하는 Head(Stem) Layer 라 볼 수 있는데 학습 가능한 가중치 매트릭스(Weighted Matrix)를 포함하고, 언어모델과 함께 학습이 되다 보니
이 Embedding layer이 포함된 언어모델을 크게 3가지로 분류할 수 있다.
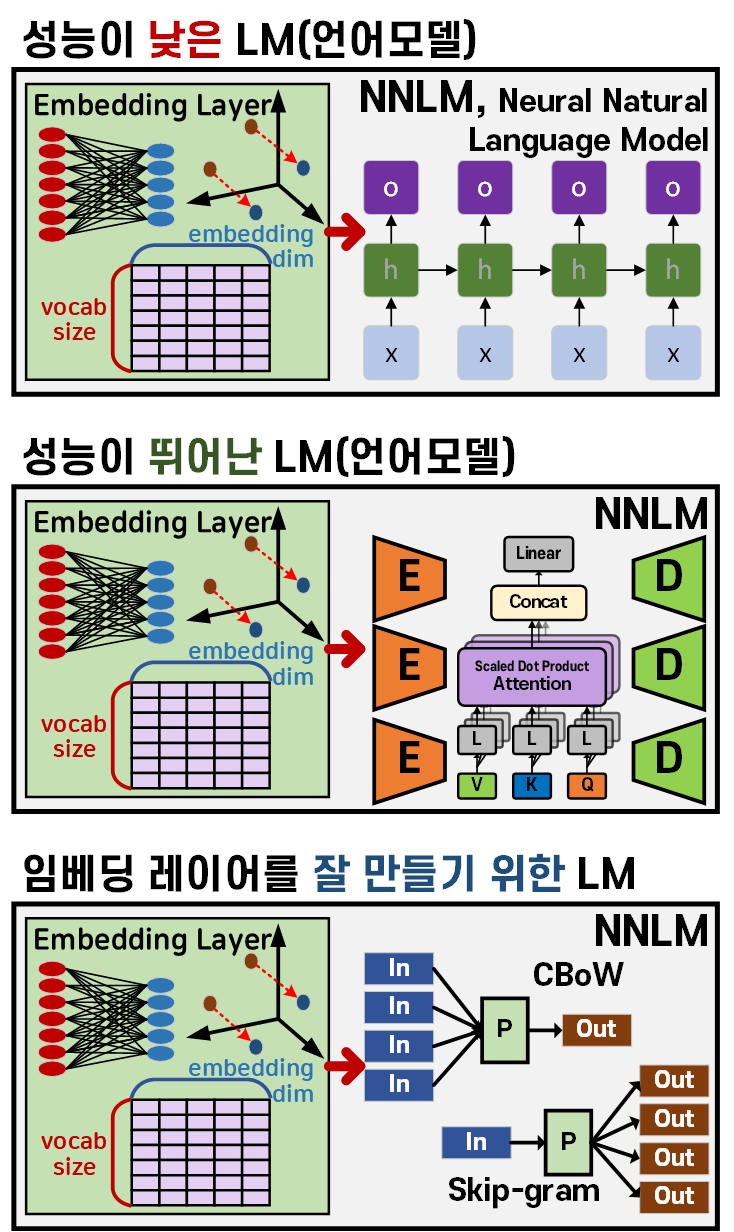
1) 성능이 낮은 언어모델과 임베딩 레이어 : 초기에 설계된 언어모델 (RNN, LSTM, GRU 등...)은 NLP작업을 수행하는데 있어 한계점을 드러냈었고, 이와 함께 사용된 Embedding layer 또한 정보의 응축이나, 데이터셋 내 구성요소간의 유사도를 제대로 표현하지 못하는 경우가 종종 있음
2) 성능이 우수한 언어모델과 임베딩 레이어 : Attention 기법과 Transformer 모델 기반의 언어모델이 개발되고 이것이 대규모 언어모델(LLM, Large Language Model)로 발전하였고, 이에 따라 다양하고 높은 수준의 NLP를 수행하는 것이 가능해졌다. 이때 해당 모델의 앞단에 장착된 Embedding layer도 수많은 단어 간의 유사성을 옳게 표현하면서, 많은 정보를 효율적으로 응축해 성능이 우수한 경우가 많다.
3) 임베딩 레이어를 잘 만들기 위한 언어모델 : 아직 2)와 같은 성능이 우수한 언어모델이 개발되기 전 Embedding layer가 단어의 유사성 및 많은 정보를 응축하기 위한 목적으로 개발된 언어모델이 존재하며,
해당 언어모델로 학습이 완료된 Embedding layer를 배포
이를 Pre-trained Word Embedding이라 부른다.
따라서 이번 포스트에서는 임베딩 레이어를 잘 학습시키기 위한 언어모델인
Word2Vec, FastText, GloVe의 개념에 대해 학습하고,
각 모델로 학습시킨 Pre-trained Word Embedding 파라미터를 배포처에서 취득하여 이를 통해 기존의 랜덤으로 초기화된 Embedding layer와 비교하여
얼마나 성능이 향상되는지를 확인해보고자 한다.
2. Word2Vec 개요
Word2Vec는
3) 임베딩 레이어를 잘 만들기 위한 언어모델 중 하나로
임베딩 레이어의 목적이
밀집 벡터 생성을 통한 차원축소(정보응축)
정보(단어) 간 의미 유사성 생성
이니 이 목적을 잘 달성할 수 있도록 대규모 언어 데이터셋으로 Embedding layer를 학습시키고
이를 Pre-trained Word Embedding로 배포하고 있다.. 이렇게 보면 된다.
그래서 User 입장에서는 이 Word2Vec를 어떻게 이해하면 되는가?
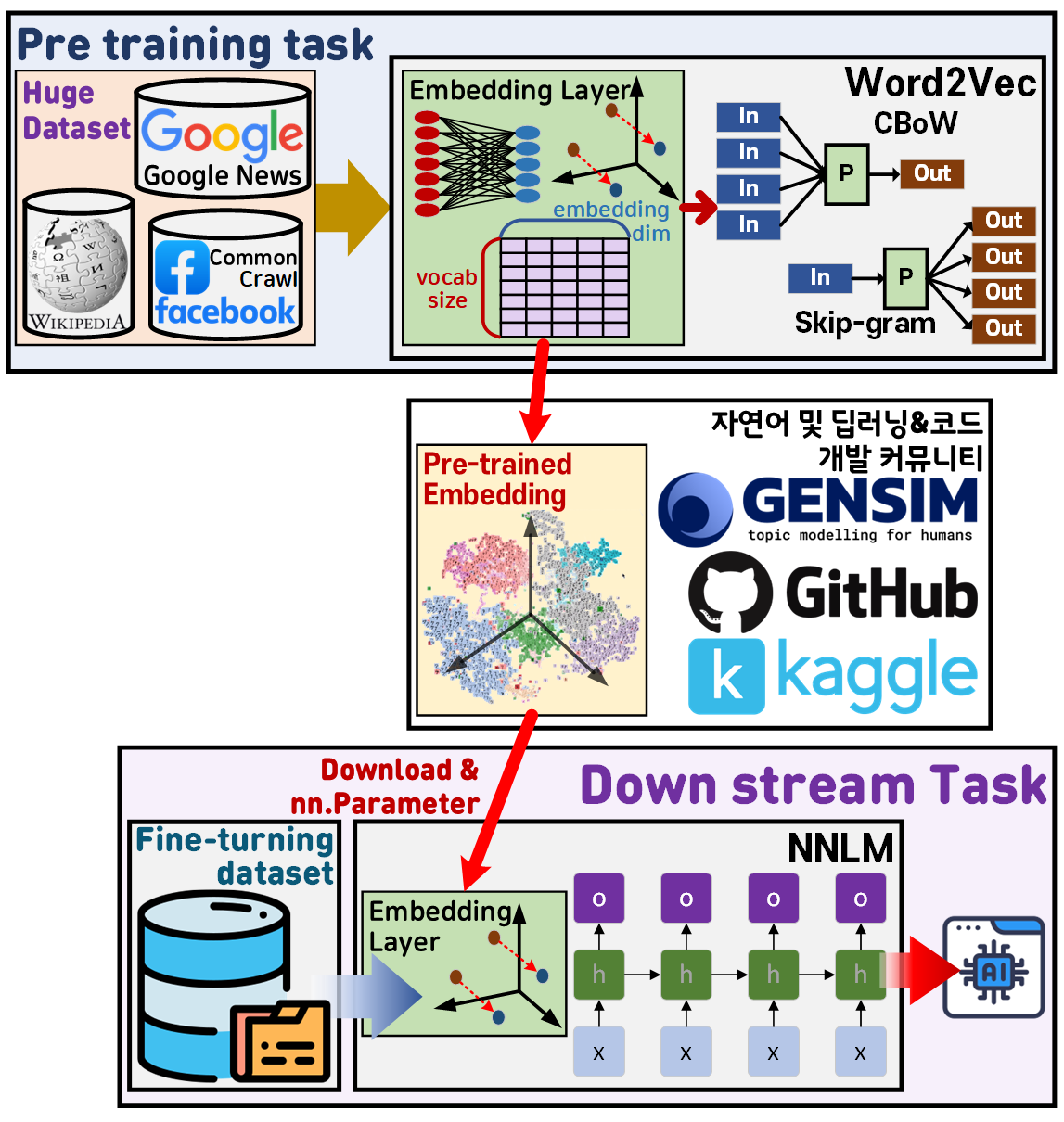
1) 서비스 제공자가 대용량의 데이터 셋(Huge Dataset)을 Word2Vec, FastText, GloVe와 같은 임베딩 레이어를 잘 만들기 위한 언어모델로 학습시키는
Pre Training Task를 수행한다.
2) 서비스 제공자가 자연어 및 딥러닝 그리고 개발자 커뮤니티(클라우드 플랫폼)에 학습이 완료된 임베딩(Pre-trained Embedding) 레이어 파라미터를 업로드 한다.
3) 이를 사용자가 다운로드 한 뒤
(Pre-trained Embedding)
이를 사용자가 수행하고자 하는 작업(Task)에 적합한 언어모델(Tarrget model)의 Embedding layer에 붙여넣는 Downstream Task작업을 수행한다.
즉, 모델 전체에 대한 훈련된 weighted parameter을 다 가져오는 Downstream Task 작업이 아닌
Embedding layer 딱 1층의 weighted parameter만을 가져오는 부분적인 Downstream Task라고 볼 수 있다.
그런데 이 Embedding layer를 훈련시키기 위한 언어모델이 다들 판이한 설계 방향성으로
Embedding layer를 학습시켰기에 설계 방향성을 알아둘 필요가 있다.
아무튼 Word2Vec에 대해 설명을 하자면
학습된 결과물은(임베딩 레이어 파라미터) 단어 벡터간 유의미한 유사도 정보를 잘 표현하고 있다.
이때 Embedding layer의 차원 정보가 (vocab_size, embedding_dim)으로 된 embedding matrix가 출력되는데
이 embedding_dim을 3차원으로 다시 Projection하면
아래의 gif처럼 단어의 유사도 정보를 디스플레이 할 수 있다.
https://projector.tensorflow.org/
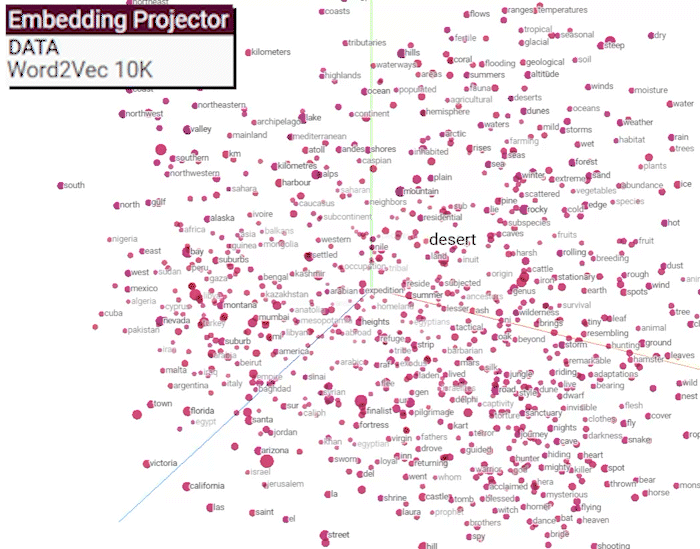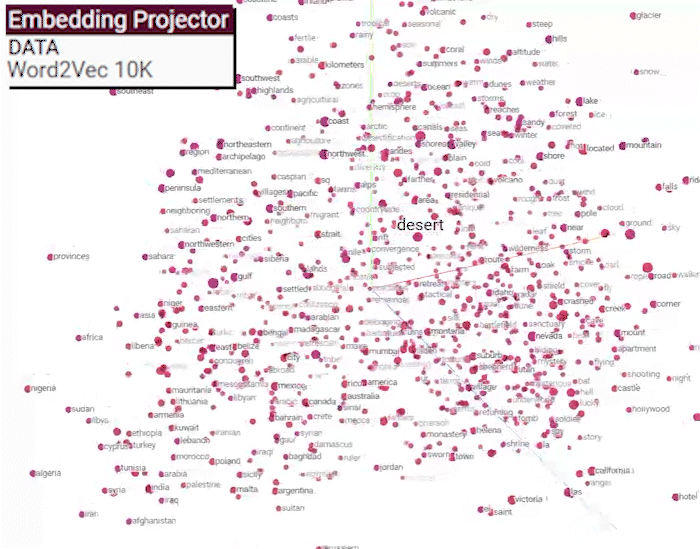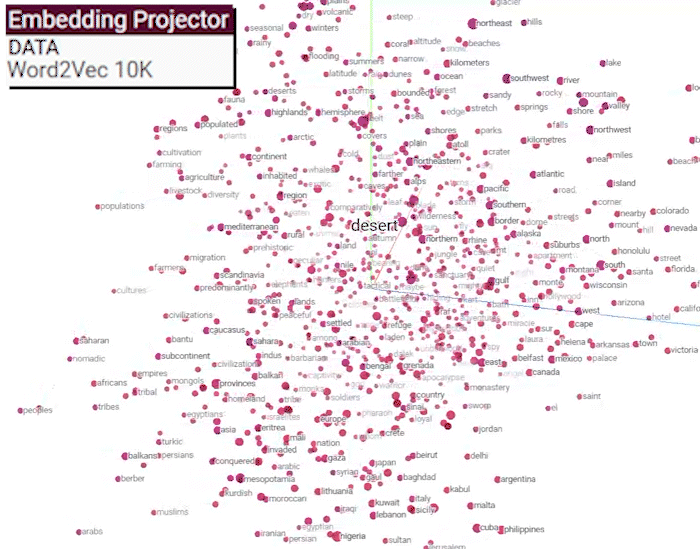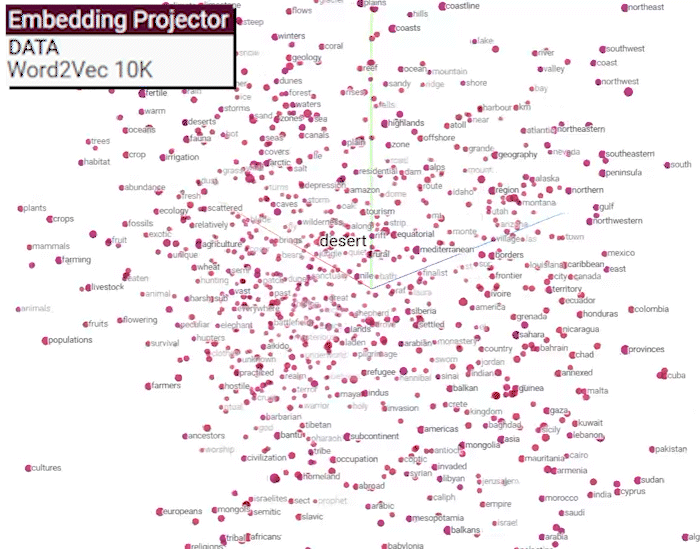
아무튼 Word2Vec은 위 gif 처럼 단어간 유의미한 유사도 정보를 잘표현하도록 임베딩 레이어를 학습시킬 수 있기에
1) Word2Vec방식으로 학습된
Pre-trained Embedding를 인터넷에서 구해서 이를 활용
2) Word2Vec방식으로 설계된 언어모델을 만든 뒤 데이터셋을 직접 학습시켜서
Pre-trained Embedding를 생성 이를 목표 작업을 수행하기 위한 주 작업 언어모델의 임베딩 레이어에 전이(Transfer)
이렇게 두가지 방식으로 Word2Vec를 활용할 수 있다.
2.1 Word2Vec : CBoW
Word2Vec는 임베딩 레이어를 학습시키는데 두가지 세부 방법론이 존재하는데 각각
CBoW(Continuous Bag of Words), Skip-gram이 존재한다.
이 세부 방법론에 따라 입력되는 데이터셋의 전처리, 모델의 작동 구조가 살짝 달라진다.
CBoW에 대해 요약을 하자면

빈칸에 알맞는 단어를 고르는 문제
Word2Vec : CBoW방식으로 설계된 언어모델은 입력된 데이터셋을 바탕으로
끊임없이 위 빈칸에 들어갈 단어를 맞추는 문제풀이를 수행한다.
여기서 총 3가지 개념이 발생하는데
맞춰야(예측해야) 하는 단어 : 중심 단어(Center word)
맞춤(예측)을 수행하는데 필요한(입력) 단어 : 주변단어(context word), 주변단어의 범위(windows)
이 3가지 개념을 하나의 문서를 기준으로
Word2Vec : CBoW이 어떻게 동작하는지 이해해 보도록 하자
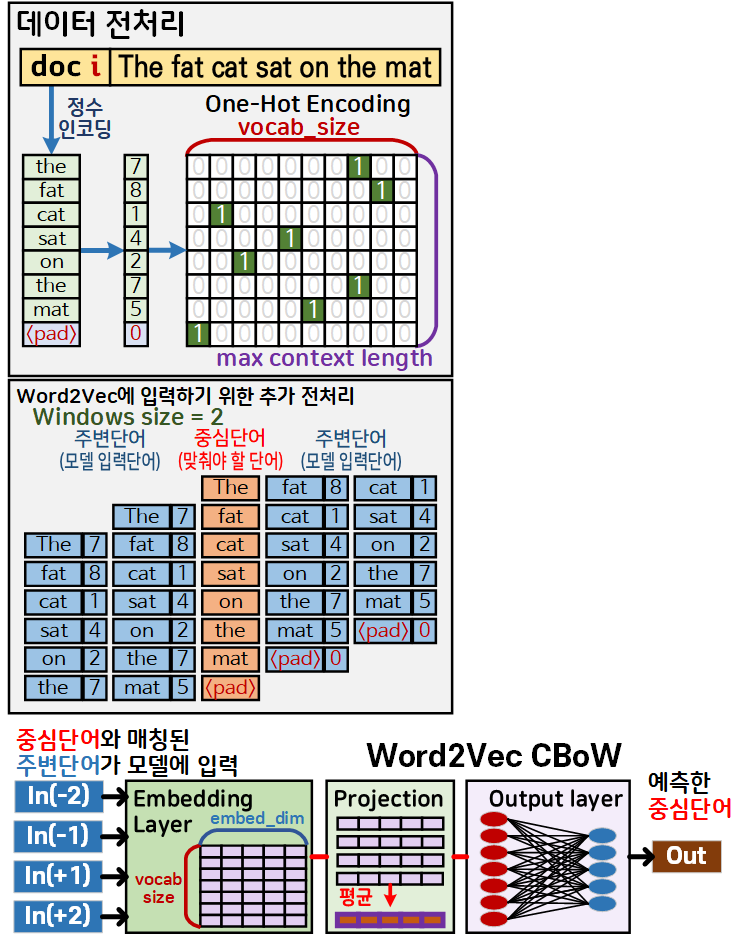
1) 데이터 전처리 : 일반적인 정수인코딩
One-Hot Encoding을 수행한다.
이전 포스트 1. NLP-Text 전처리 : 현대 벡터화(Word Embedding) (2) - AI 핵심기술 강의 복습에서
정수인코딩 == One-Hot Encoding인 것을 설명했으니 다음 과정은 정수인코딩 과정으로 설명하도록 하겠다.
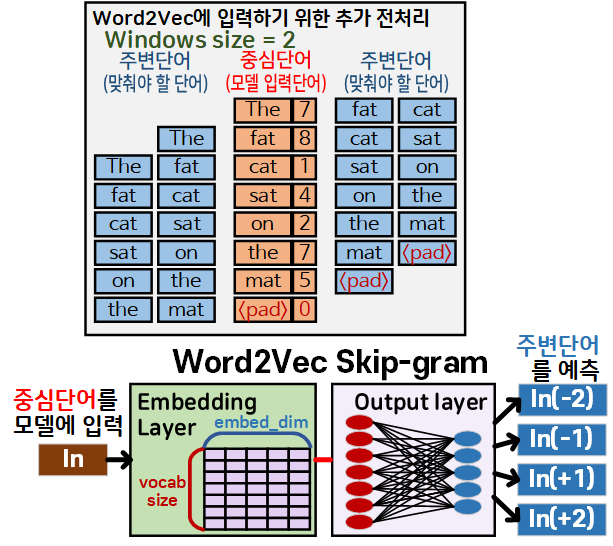
2) Word2Vec에 입력하기 위한 추가 전처리 : Word2Vec는 목적이 중심 단어을 맞추는 것이 목적이다.
이를 위해서 필요 단어(입력 단어)로 주변단어를 설정하고, 이 주변단어의 범위가 Windows_size이다.
모델에 입력될 때에는 하나의 문서에 대하여
{중심 단어 : 주변단어} 쌍을 만들어서 모델에 입력하기에 데이터셋의 크기가 늘어나지는 않으나
데이터셋의 용량이 Windows_size * 2만큼 증강되는 효과가 발생한다.
따라서 Windows_size을 늘리면 중심 단어의 예측 정확도는 높아질 수 있으나, 그만큼 훈련시간 및 모델이 무거워 지기에 적합한 값으로 설정해야 한다.
3) Word2Vec : CBoW에 주변단어를 입력하면, 임베딩 레이어를 통해 Lookup Table인 임베딩 벡터를 산출한다.
이 주변단어별로 산출된 임베딩 결과값을 행 단위로 평균을 낸 Projection 임베딩 벡터를 생성한다.
4) Projection 임베딩 벡터를 Word2Vec - CBoW의 주 작업 언어모델이라 볼 수 있는 Output Layer을 통과시켜 모델이 예측한 중심 단어를 산출한다
이제 정답지 중심단어 / 모델이 예측한 중심단어가 있으니 오차를 줄이는 학습을 수행한다.
아무튼 위 과정을 수행하면 학습이 잘 된 임베딩 레이어의 훈련된 파라미터를 얻을 수 있다
여기서 2) 데이터셋의 추가 전처리,
3~4)Word2Vec : CBoW모델 설계
와 같은 귀찮은 작업은 일일이 작업하는 것은 비 효율적이니 라이브러리를 활용하도록 하자
https://radimrehurek.com/gensim/models/word2vec.html
Gensim 라이브러리를 통해 Word2Vec를 불러올 수 있으며 C언어 기반으로 모델이 설계된 후 Python 환경에서도 구동이 원활하게 되게끔 여러번의 업데이트 및 최적화가 수행되었다니
궂이 어렵게 모델을 구현할 필요는 없다
2.2 Word2Vec : Skip-gram
CBoW에 대해 정리를 했으니 Skip-gram은 딱 그 반대되는 개념이라 보면 된다.
중심 단어를 입력하면 그와 관련된주변단어를 Windows_size 에 맞춰서 앞, 뒤 단어를 예측하는 것으로
Skip-gram는 마인드맵 방식으로 문제를 풀어나간다 이렇게 볼 수 있다.
Skip-gram은 통상적으로 CBoW보다 성능이 더 좋은 임베딩 레이어를 만들어 내는 경향이 있는데 이는 Embedding matrix가 단어 벡터간 유의미한 유사도를 만들어내는 것이 중요하기에 Skip-gram이 이 개념을 잘 반영한다 볼 수 있다.
CBoW에서는 입력된 단어의 임베딩 정보를
행 단위로 평균을 내버리기에
이 뜻은 여러 단어가 좌표공간에 있으면 그냥 좌표 공간 내 중간지점이 중심 단어라고 강제로 정의하기에 유사한 정도(거리) 정보가 뭉게지는 문제가 있다.
Skip-gram의 학습과정도 뜯어보면 CBoW보다 살짝 더 쉬운 편이다.
embedded = embedded.mean(dim=1) 이렇게 임베딩 벡터에 대한 행 기준 평균을 내지 않고 독립적으로 주변단어를 Windows_size * 2번 반복해서 예측하기만 하면 된다.
참고로 CBoW, Skip-gram용 추가 전처리는 동일한 과정을 밟는다.
3. Word2Vec 실습 준비
이번 실습의 주제는 아래와 같다.
1) 고전 TF-IDF 인코딩 방식으로 기사 분류
2) 랜덤 초기화 임베딩으로 기사 분류
3,4) Word2Vec : CBoW, Word2Vec : Skip-gram 방식으로 임베딩 레이어를 학습 각각 훈련된 임베딩 레이어를 2) 언어모델의 임베딩 레이어에 전이
3.1 데이터 전처리
자연어 데이터셋
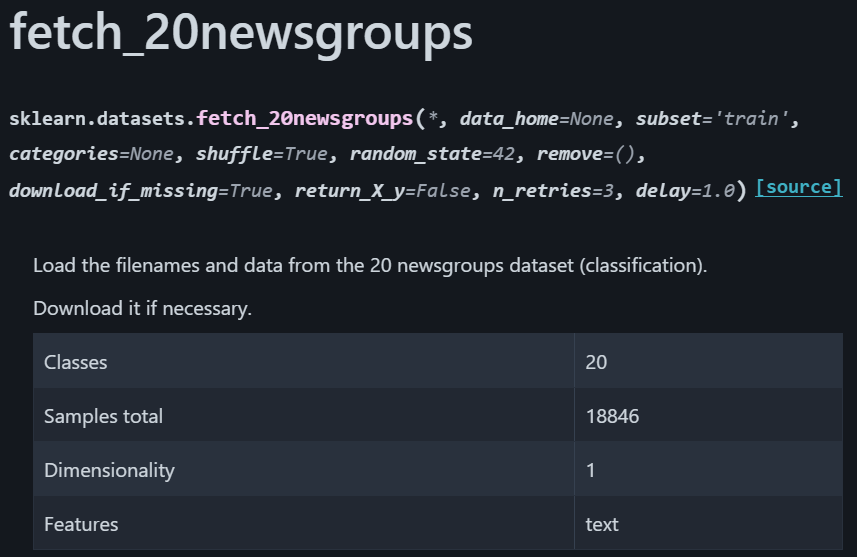
https://scikit-learn.org/stable/modules/generated/sklearn.datasets.fetch_20newsgroups.html
이번에 사용할 데이터셋은 sklearn 라이브러리에서 제공하는 자연어 데이터셋인 서로 다른 20개의 뉴스 그룹으로부터 수집한 약 18,000개의 뉴스기사 데이터 셋이다.
from sklearn.datasets import fetch_20newsgroups# 자연어 데이터셋 전체 가져오기
data = fetch_20newsgroups(subset='all', shuffle=True)
데이터를 다운로드 받은 뒤 구조를 살펴보면
data = x_data, target = y_label 로 놓고 나머지 데이터는 그렇게 필요한 정보는 아니다.
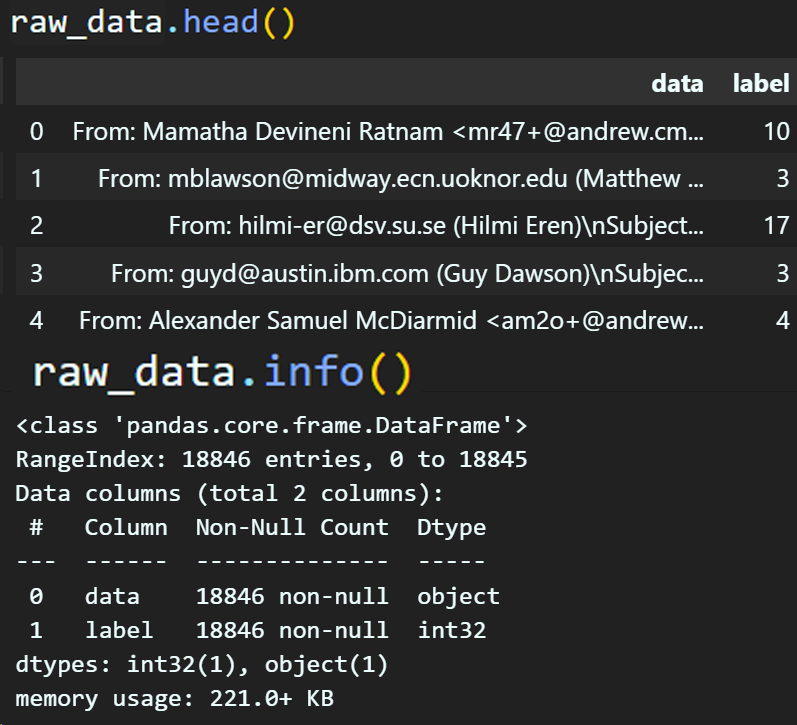
위 정보는 딕셔너리 데이터이니 이를 DataFrame으로 변환한다.
import numpy as np
import pandas as pd
import matplotlib.pyplot as pltraw_data = pd.DataFrame(
{'data' : data['data'],
'label': data['target']}
)
데이터셋 전처리 - 결측치&중복치 제거
# 컬럼별 결측치 cnt값을 모두 더한 값 (정수형 데이터)
missing_data = raw_data.isna().sum().values.sum()
# 결측치 정보가 0이면 결측치가 없으니 아래 함수가 실행안됨
if missing_data != 0:
raw_data.dropna(how='any', inplace=True)
# 중복치 제거
raw_data.drop_duplicates(subset='data',
keep='first',
inplace=True)데이터 전처리 - 정규표현식
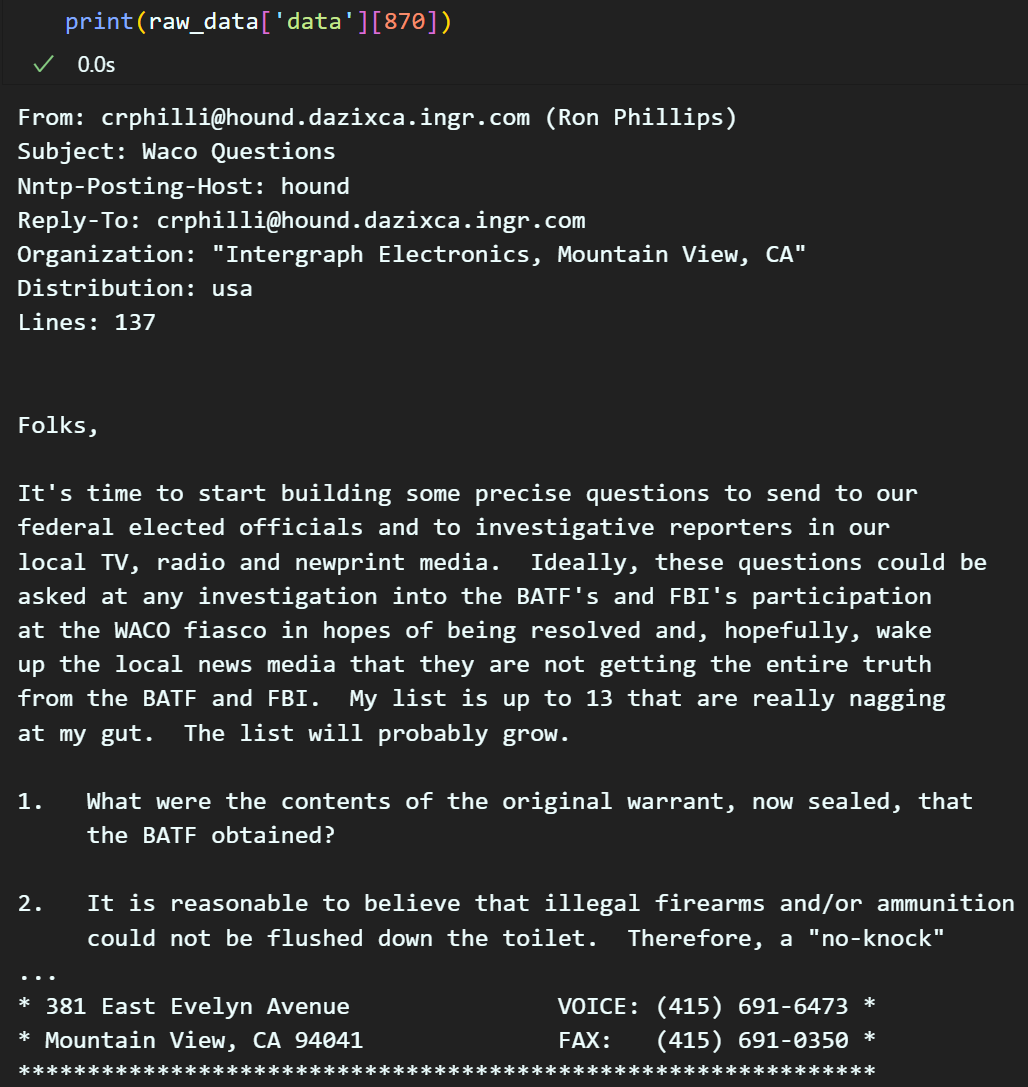
데이터셋을 보면 대충 메일 + 본문 + 주석
구조의 데이터인데
특수문자, 전화번호, 메일주소는 제거하는 식으로 진행하겠다.
import re# 감지할 문자열을 정규표현식 패턴으로 표현
p1 = re.compile(r'\(\d{3}\)\s?\d{3}-\d{4}') # (000) 000-0000 찾음
p2 = re.compile(r'\d{3}-\d{3}-\d{4}') # 000-000-000 찾음
# 이메일 주소 감지 정규표현식 패턴
p3 = re.compile(r'[a-zA-Z0-9._%+-]+@[a-zA-Z0-9.-]+\.[a-z-Z]{2,}')
p4 = re.compile(r'[^a-zA-Z0-9\s]') # 영어, 숫자, 공백외 특수문자
def regex_sub(origin_doc):
clean_doc = p1.sub(repl="", string=origin_doc)
clean_doc = p2.sub(repl="", string=clean_doc)
clean_doc = p3.sub(repl="", string=clean_doc)
clean_doc = p4.sub(repl=" ", string=clean_doc)
return clean_docraw_data['data'] = raw_data['data'].apply(regex_sub)
결과물을 살펴보면 예상한 대로 전화번호, 이메일주소는 삭제되고 자잘한 특수기호들은 다 처리된 것을 확인할 수 있다.
데이터 전처리 - 정규화
def doc_normalize(origin_doc):
# 대문자+소문자 --> 모두 소문자로 정규화
return origin_doc.lower()raw_data['data'] = raw_data['data'].apply(doc_normalize)여기까지 수행했으면 데이터 전처리는 훌륭하게 수행했다 볼 수 있다.
3.2 텍스트 전처리 1차
문서 토큰화
raw_x_data = raw_data['data'].values.tolist()
raw_y_label = raw_data['label'].values.tolist()
import nltk
# punkt 코퍼스 기반
from nltk.tokenize import WordPunctTokenizer
from tqdm import tqdmword_tokenizer = WordPunctTokenizer()
def tokenize(x_data, tokenizer):
tokenized_doc = list()
for sent in tqdm(x_data):
temp = tokenizer.tokenize(sent)
tokenized_doc.append(temp)
return tokenized_doctokenized_x_data = tokenize(raw_x_data, word_tokenizer)불용어 제거
from nltk.corpus import stopwords
# nltk라이브러리의 불용어 리스트 로드
stopwords_list = stopwords.words('english')
# 리스트 컴프리헨션 기반 불용어 제거
def remove_stopword(tokenized_data, stopword):
return [[word for word in sent if word not in stopword]
for sent in tokenized_data]r_t_x_data = remove_stopword(tokenized_x_data, stopwords_list)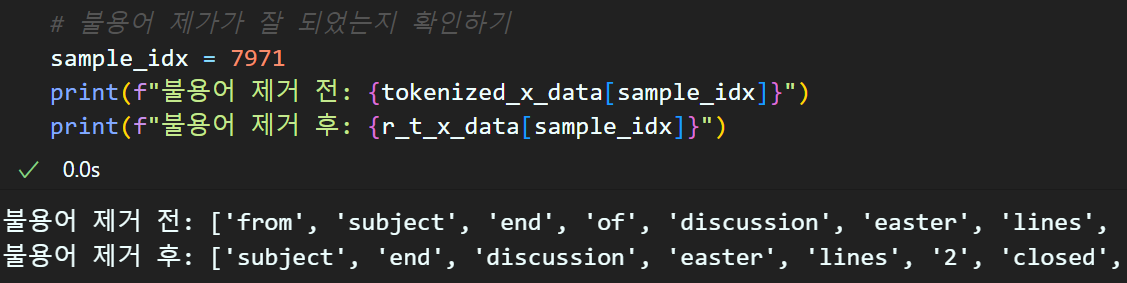
3.3 데이터 분할하기
from sklearn.model_selection import train_test_split
# 훈련데이터셋(60%) 그 외 데이터셋(40)로 나누는 작업 수행
# random_state -> 데이터셋을 내누는데 '재현성' 유지를 위해 넣음 -> 안넣어도 됨
# stratify -> Y_label의 클래스 비율을 유지하면서 데이터 나눌때 옵션
x_train, x_etc, y_train, y_etc = train_test_split(
r_t_x_data, raw_y_label, test_size=0.4, random_state=42, stratify=raw_y_label
)
# 그 외 데이터셋을 반반으로 Val, Test로 나눔
x_val, x_test, y_val, y_test = train_test_split(
x_etc, y_etc, test_size=0.5, random_state=42, stratify=y_etc
)from collections import Counter
# 클래스 비율 계산하는 함수
def class_ratio(label):
lable_counts = Counter(label)
ratio = list(lable_counts.values())[0] / sum(list(lable_counts.values()))
return f"{ratio*100:.2f}%"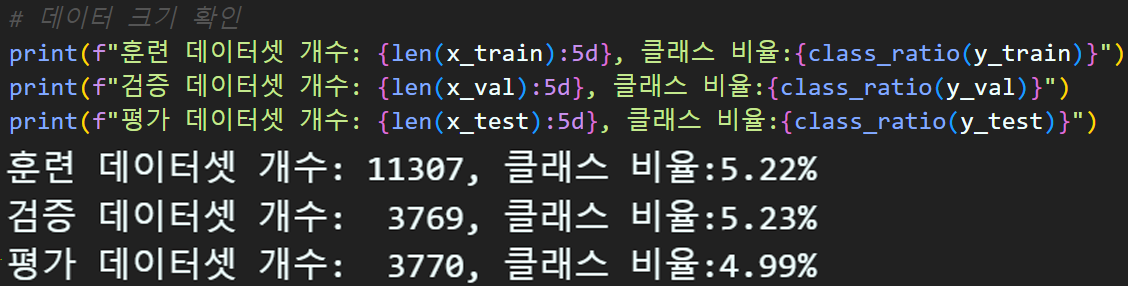
3.5 텍스트 전처리 2차
희소단어 분석하기
from collections import Counter
word_list = []
# train항목을 워드 리스트에 입력
for sent in x_train:
for word in sent:
word_list.append(word)
# val항목을 워드 리스트에 입력
for sent in x_val:
for word in sent:
word_list.append(word)
# 단어와 해당 단어의 출몰 빈도를 함께 저장하는
# Counter 타입의 변수 생성
word_counts = Counter(word_list)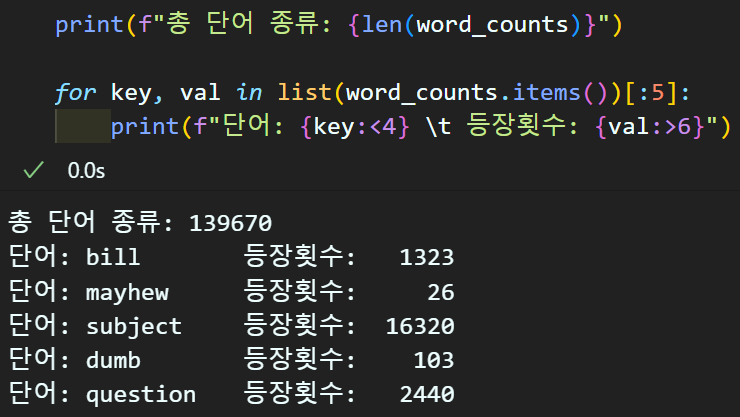
total_vocab_cnt = len(word_counts) #전체 단어 종류
rare_vocab_cnt = 0 #등장빈도수가 적은 단어는 몇 종?
total_freq, rare_freq = 0, 0
# 희소단어를 결정하는 하이퍼 파라미터
threshold = 3
for key, value in word_counts.items():
# 전체 단어의 등장빈도를 모두 가산하여 더함
total_freq = total_freq + value
if (value < threshold):
rare_vocab_cnt += 1
rare_freq += value
# 단어집합 내 희소 단어 비율
rare_ratio = rare_vocab_cnt / total_vocab_cnt
# 희소단어 등장 비율
freq_ratio = rare_freq / total_freq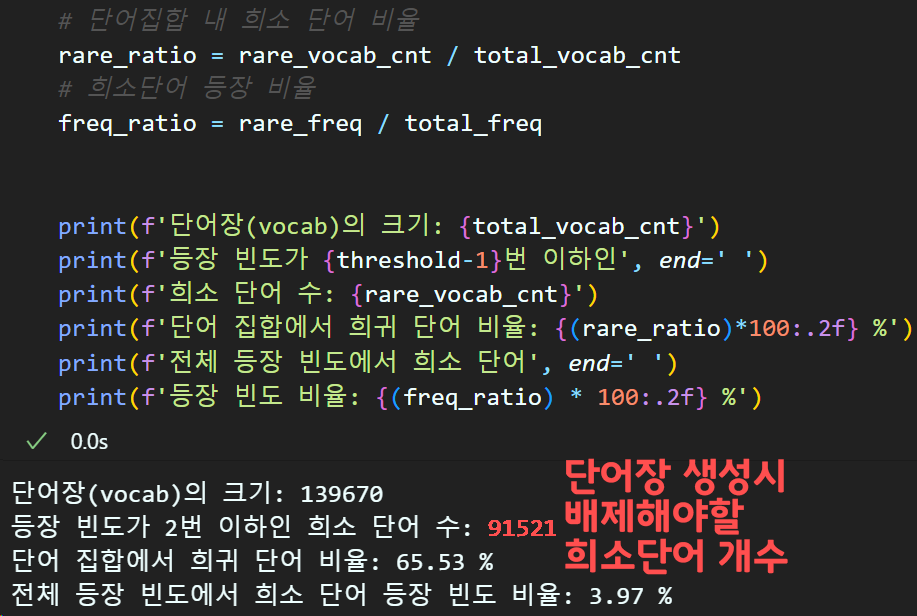
단어장 생성 + 스페셜 토큰 추가
#등장 빈도가 높은 단어 순으로 정렬하기
vocab = sorted(word_counts, key=word_counts.get, reverse=True)
#등장 빈도가 높은 단어만 인덱싱 하기
vocab_size = total_vocab_cnt - rare_vocab_cnt
vocab = vocab[:vocab_size]# 특수단어를 포함시켜 {단어:인덱스} 딕셔너리 생성하기
# 포함시킬 특수단어는 `<PAD>`, `<UNK>`으로
# <PAD> : 0, <UNK> : 1 순으로 특수단어는 맨 앞에 위치하기
word_to_idx = {'<PAD>' : 0, '<UNK>' : 1}
for idx, word in enumerate(vocab):
word_to_idx[word] = idx + 2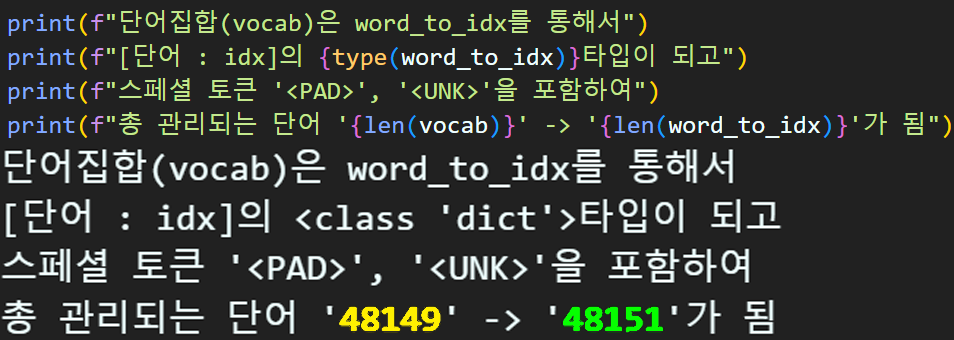
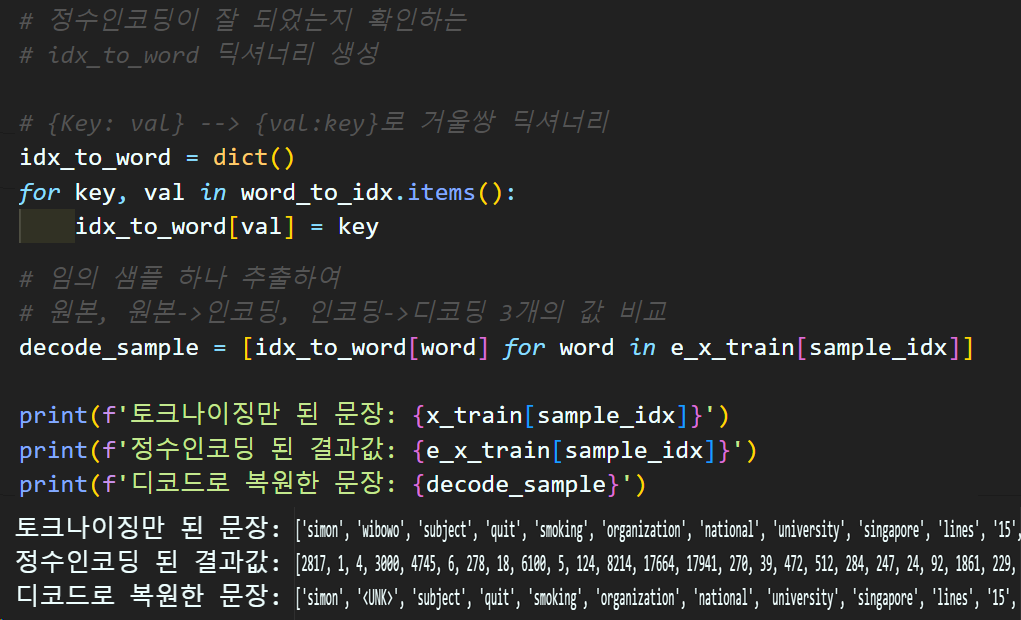
3.6 정수(원핫) 인코딩
단어 정수 인코딩
# 단어를 정수 인덱싱 규칙으로 정수 인덱싱 수행하기
def text_to_sequences(tokenized_data, word_to_idx):
encoded_data = [] #리턴해야할 정수 인코딩 결과값
for sent in tokenized_data:
idx_sequence = [] #단어장 리스트에서 idx를 찾아서 여기에 입력
for word in sent:
try: #word_to_idx에서 단어를 찾은 뒤 해당 단어의 인덱스(숫자)를 입력
idx_sequence.append(word_to_idx[word])
except KeyError: # word_to_idx 딕셔너리에 없는 키(단어)등장시 UNK로 인덱싱
idx_sequence.append(word_to_idx['<UNK>'])
#문장 내 단어를 모두 정수로 변환한 후에 이를 리턴값(리스트)에 입력
encoded_data.append(idx_sequence)
return encoded_data# 데이터셋의 정수 인코딩 수행
e_x_train = text_to_sequences(x_train, word_to_idx)
e_x_val = text_to_sequences(x_val, word_to_idx)
e_x_test = text_to_sequences(x_test, word_to_idx)정수 인코딩 검증
문장 패딩을 위한 문서 길이 분석
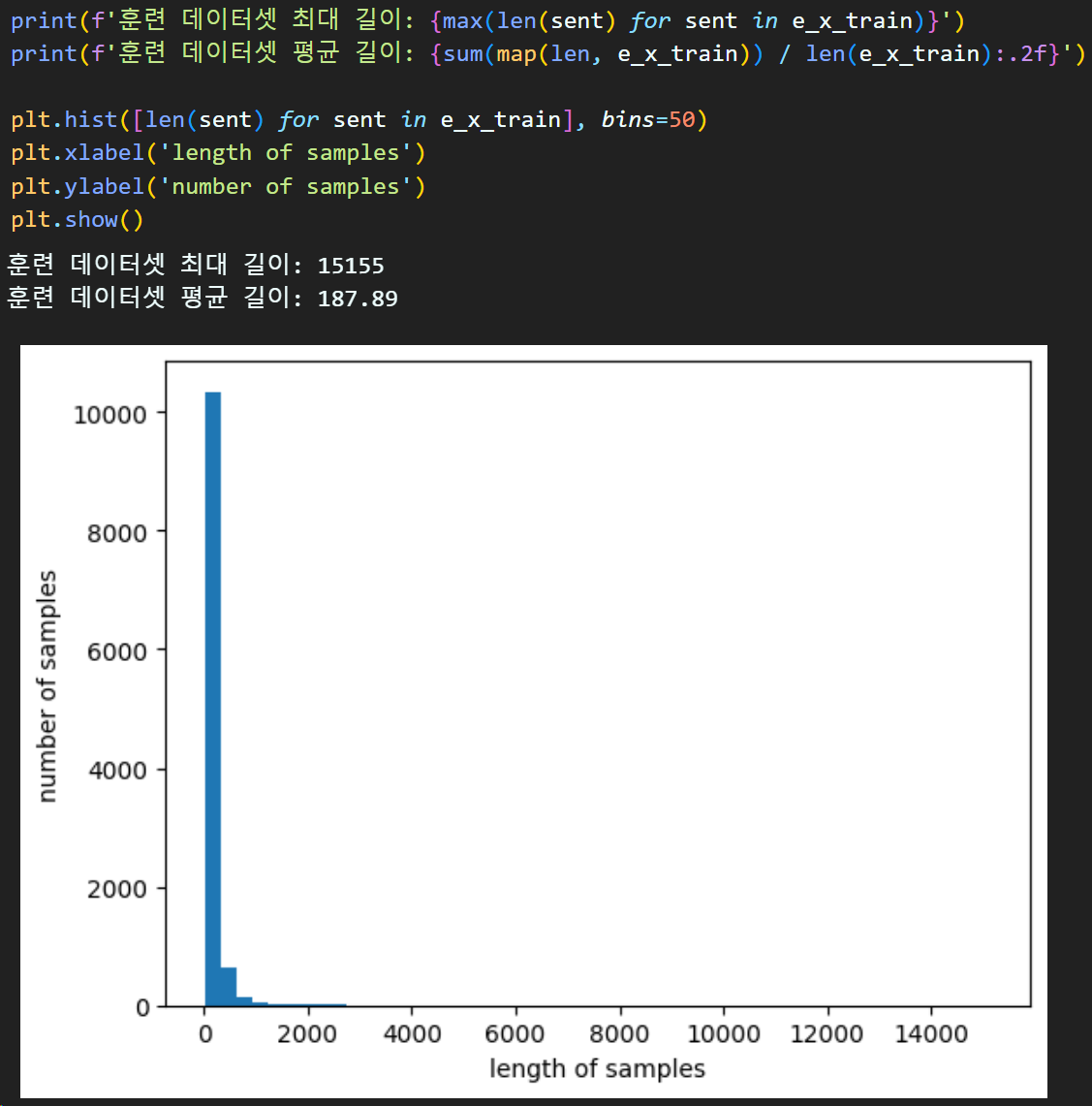
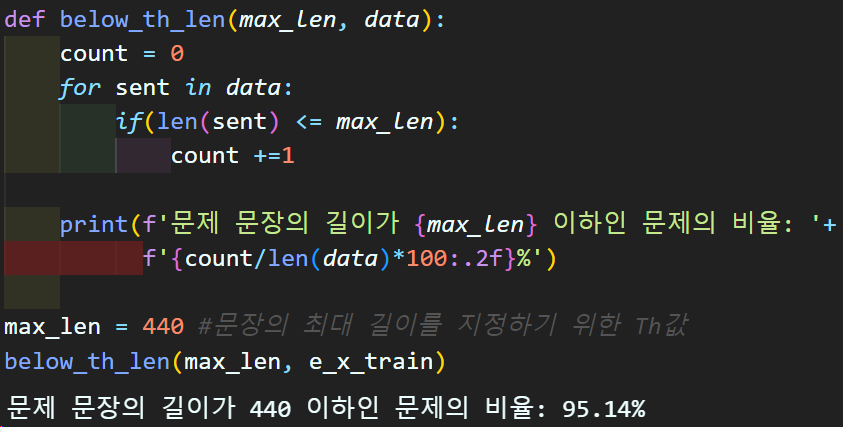
문장 패딩 수행 : 정수(원핫)인코딩 완성
max_len = 440 #문장의 최대 길이를 지정하기 위한 Th값
# x_data 항목을 문장패딩하기 위한 코드
def pad_seq_x(x_data, max_len):
features = np.zeros((len(x_data), max_len), dtype=int)
for idx, sent in enumerate(x_data):
if len(sent) != 0: #예외처리구문
features[idx, :len(sent)] = np.array(sent)[:max_len]
return features# 문장패딩 처리한 x_data (인코딩 완료)
padded_x_train = pad_seq_x(e_x_train, max_len)
padded_x_val = pad_seq_x(e_x_val, max_len)
padded_x_test = pad_seq_x(e_x_test, max_len)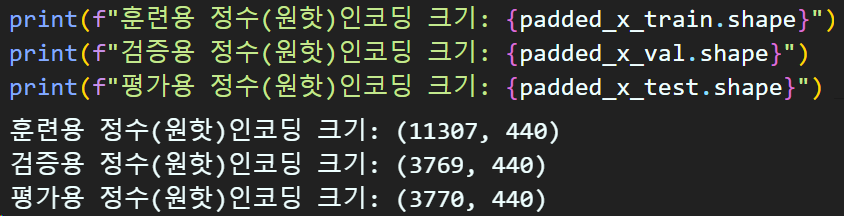
3.7 TF-IDF 인코딩
DTM 매트릭스 생성
# {단어 : 빈도}가 함께 포함되는 DTM 생성하기
def create_dtm(x_data, word_to_idx):
# row = x_data의 개수(문서 개수), col = 생성한 단어장 내 단어 개수
dtm = np.zeros((len(x_data), len(word_to_idx)), dtype=int)
for i, sent in enumerate(x_data):
for word in sent:
#word_to_idx에서 단어를 찾은 뒤 해당 단어의 인덱스(숫자)를 입력
try:
word_idx = word_to_idx[word]
# word_to_idx 딕셔너리에 없는 키(단어)등장시 UNK로 인덱싱
except KeyError:
word_idx = word_to_idx['<UNK>']
#(문서 인덱스, 찾은 단어 인덱스) 항목에 +1 가산
dtm[i, word_idx] +=1
return dtm# 설계된 DTM함수를 기반으로 train, val, test의 인코딩
dtm_train = create_dtm(x_train, word_to_idx)
dtm_val = create_dtm(x_val, word_to_idx)
dtm_test = create_dtm(x_test, word_to_idx)TF-IDF 인코딩 수행
# DTM 매트릭스를 기반으로 TF-IDF 매트릭스 생성
def create_tf_idf(dtm):
# TF 계산 : 문서(d)에서 단어(t)가 등장횟수 / 문서(d)에서 모든 단어 개수
# keepdims=True는 축 별로 더한 sum의 결과 차원정보 유지
row_sums = dtm.sum(axis=1, keepdims=True)
# row_sums, 분모가 0이 되는 경우가 있음 -> 이때 NaN이 발생하니
# 이를 방지하기 위한 코드로 개선하자.
tf = np.divide(dtm, np.where(row_sums == 0, 1, row_sums))
# 문서의 총 개수
num_docs = dtm.shape[0] #row열의 개수
# IDF 계산 : log(총 문서 개수 / 단어(t)를 포함하는 문서(d)의 개수)
df = np.sum(dtm > 0, axis=0) #단어 별 문서 등장 횟수
# 기존 수식의 분자, 분모, 그리고 총 결과값에 +1을 더해서
# 안정적인 idf를 산출 (smoothing)
idf = np.log((num_docs + 1) / (df + 1)) + 1
tf_idf = tf * idf
return tf_idfTF-IDF 인코딩 검증
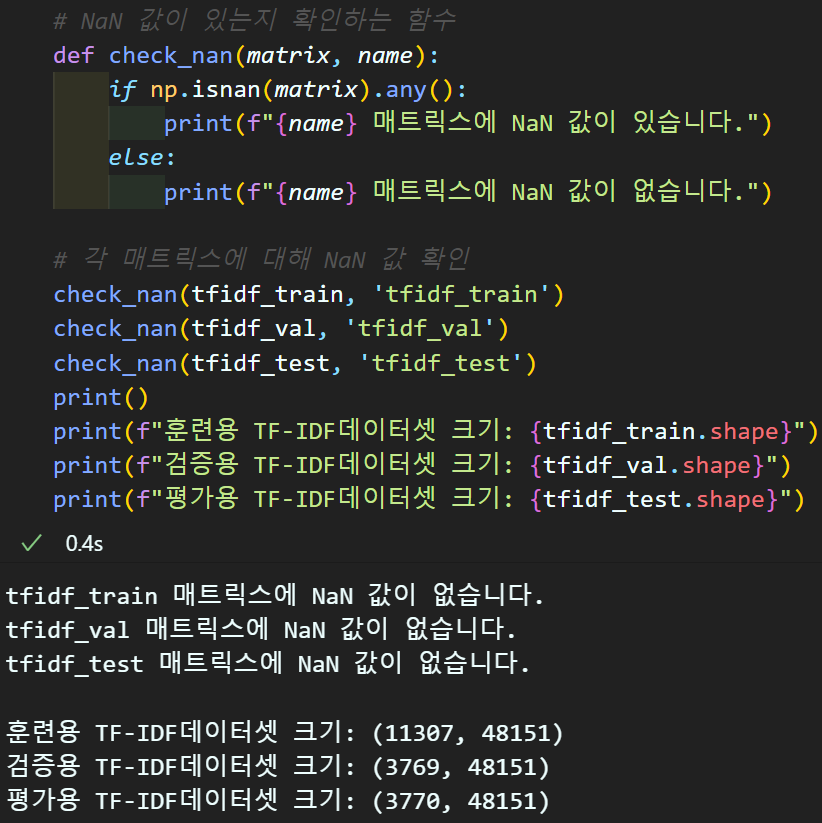
4. Word2Vec 실습
앞서 Word2Vec를 로우 프로그래밍으로 구현하는 것은 비효율적이다 언급했다.
이유는 아래와 같은데
1) 포스트의 목적은 '기사 분류'이다.
임베딩 레이어는 '기사 분류'의 성능을 향상시키기 위한 보조 방법론이다.
2) 보조 방법론은 pandas처럼 잘 지원되는 라이브러리를 응용해서 사용하는게 적합하다. 이것까지 다 구현하면 머리터진다.
https://radimrehurek.com/gensim/models/word2vec.html
따라서 Gensim에서 제공하는 Word2Vec라이브러리를 최대한 활용하도록 하자.
 우선 공식문서에서
우선 공식문서에서 Word2Vec를 사용하려면 참 고맙게도 지정가능한 인자를 어지럽게 많이도 만들어놨다.
이 파라미터를 정리하면 아래와 같다.
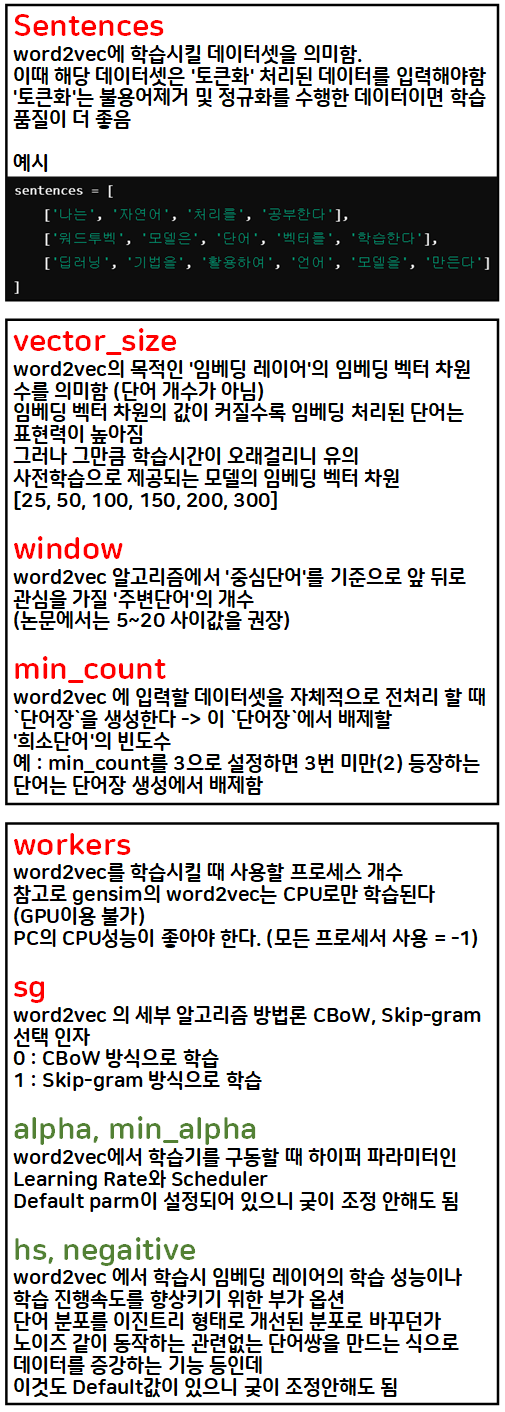
필요 및 알아둘만한 인자값 정리를 완료했으니
이제 본격적으로 CBoW기반 Skip-gram기반으로
학습을 시킨 뒤 임베딩 레이어를 추출해보자
CBoW, Skip-gram 모델 학습
from gensim.models import Word2Vec
# Word2Vec 학습에 사용할 데이터:
# 원본 데이터셋의 토큰화 후 불용어 제거를 수행한 데이터터
word2vec_doc = r_t_x_data# word2Vec : CBow 모델 학습
cbow_model = Word2Vec(
sentences=word2vec_doc,
vector_size = 100, # 임베딩 차원은 100으로 설정
window = 5, # 논문의 최대 관심가질 주변단어 사이즈인 5~20
min_count = threshold, # (3) 단어장에서 배제할 희소단어 빈도 기준
workers= -1, # 학습에 참여할 프로세스 개수 (최대로 설정)
sg = 0 # CBoW 방식으로 학습 수행
)# word2Vec : skip-gram 모델 학습
cbow_model = Word2Vec(
sentences=word2vec_doc,
vector_size = 100, # 임베딩 차원은 100으로 설정
window = 5, # 논문의 최대 관심가질 주변단어 사이즈인 5~20
min_count = threshold, # (3) 단어장에서 배제할 희소단어 빈도 기준
workers= -1, # 학습에 참여할 프로세스 개수 (최대로 설정)
sg = 1 # Skip-gram 방식으로 학습 수행
)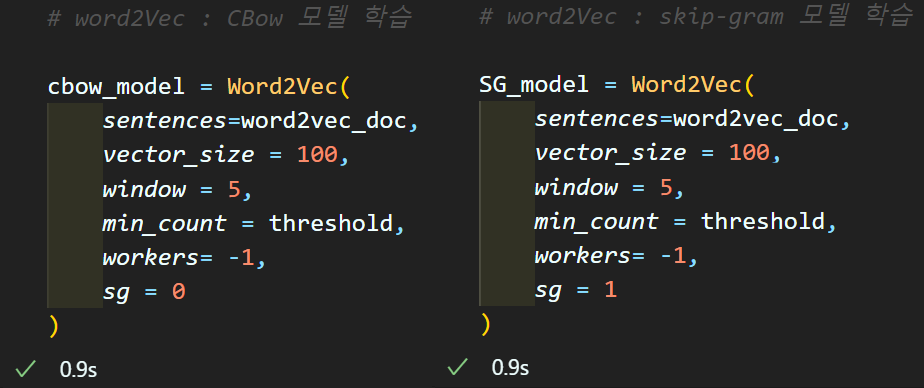
어쨋든 딥러닝 모델이라서 학습시간이 오래걸릴줄 알았는데
의외로 CPU에서 작업을 했는데도 학습이 빠릿빠릿하게 된 것을 확인할 수 있다.
wv : 임베딩 레이어 파라미터 관리 메서드
학습이 완료됬으니 임베딩 레이어를 추출해야 한다.
여기서부터 머리가 아파올 것이라 생각이 들지만
다행이도 gensim에서는 임베딩 레이어에 쉽게 접근가능한 메서드 wv를 지원한다.

생성한 임베딩 레이어의 정보 및 지원 가능한 클래스 함수로 몇가지 검증 작업을 수행해 보도록 하자
1) 생성한 임베딩 레이어의 기본정보

학습이 완료된 임베딩 레이어는 wv.vector 메서드를 통해 접근이 가능하다.
이때 필자가 수행한 정수(원핫)인코딩에서 사용된 단어장과 개수 및 순서의 차이가 있음을 인지해야 한다.
아무튼 임베딩 레이어 파라미터는 ndarray자료형으로 저장됨을 확인할 수 있다.
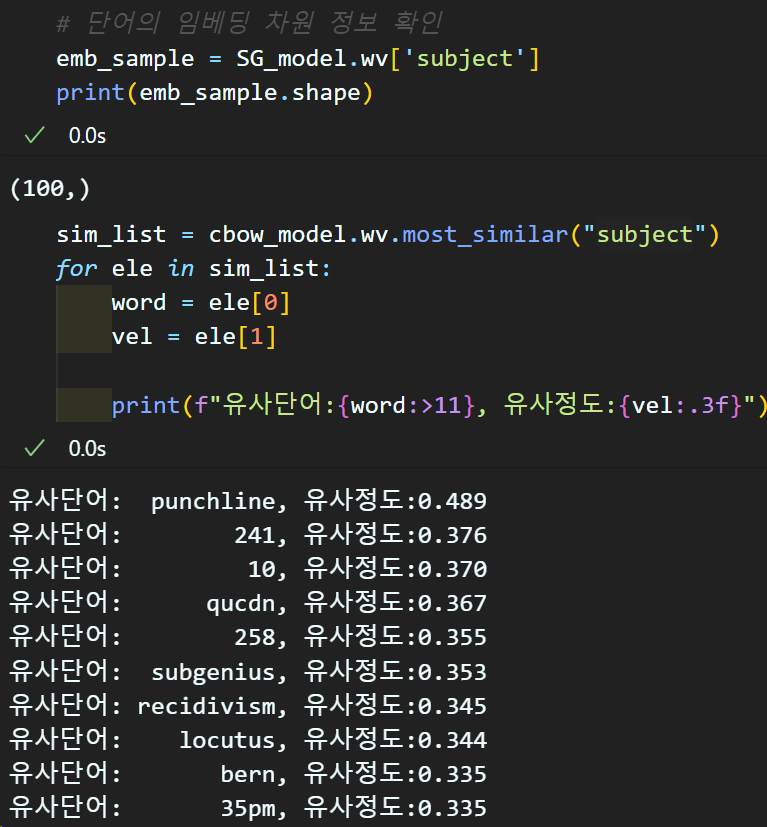
다음으로 most_similar 메서드를 사용하면
단어장 내 포함된 A라는 단어와 가장 유사한 의미를 내포하고 있는 단어군 B를 출력할 수 있다.
학습된 임베딩 레이어는
{단어 : 해당 단어를 임베드 처리한 벡터}의 쌍인
단어벡터 형식으로 저장하는 것이 가능하다
from gensim.models import KeyedVectors
# 훈련이 완료된 단어 벡터를 저장
# 여기서 단어 벡터는 {단어 : 단어의 임베딩된 벡터}를 의미함
cbow_model.wv.save_word2vec_format('news_w2v_CB') # 모델 저장
SG_model.wv.save_word2vec_format('news_w2v_SG') # 모델 저장 저장한 단어벡터 정보는 임베딩레이어 파라미터와 각 파라미터에 매칭된 단어정보를
저장한 단어벡터 정보는 임베딩레이어 파라미터와 각 파라미터에 매칭된 단어정보를 binary 포맷으로 저장한다.
마지막으로 학습된 단어 벡터를 시각화 하는것도 가능하다.
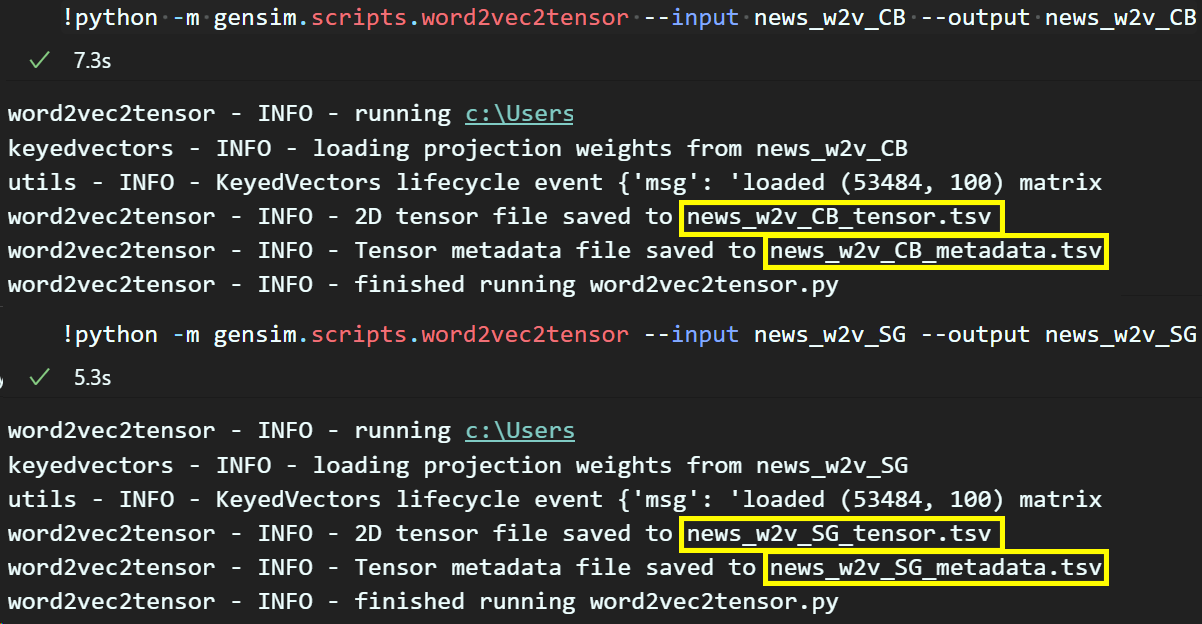
!python -m gensim.scripts.word2vec2tensor --input [저장한 단어벡터] --output [출력할 파일명]이렇게 위 사진처럼 디스플레이를 위한 *.tsv파일을 생성하는 코드를 실행한다.
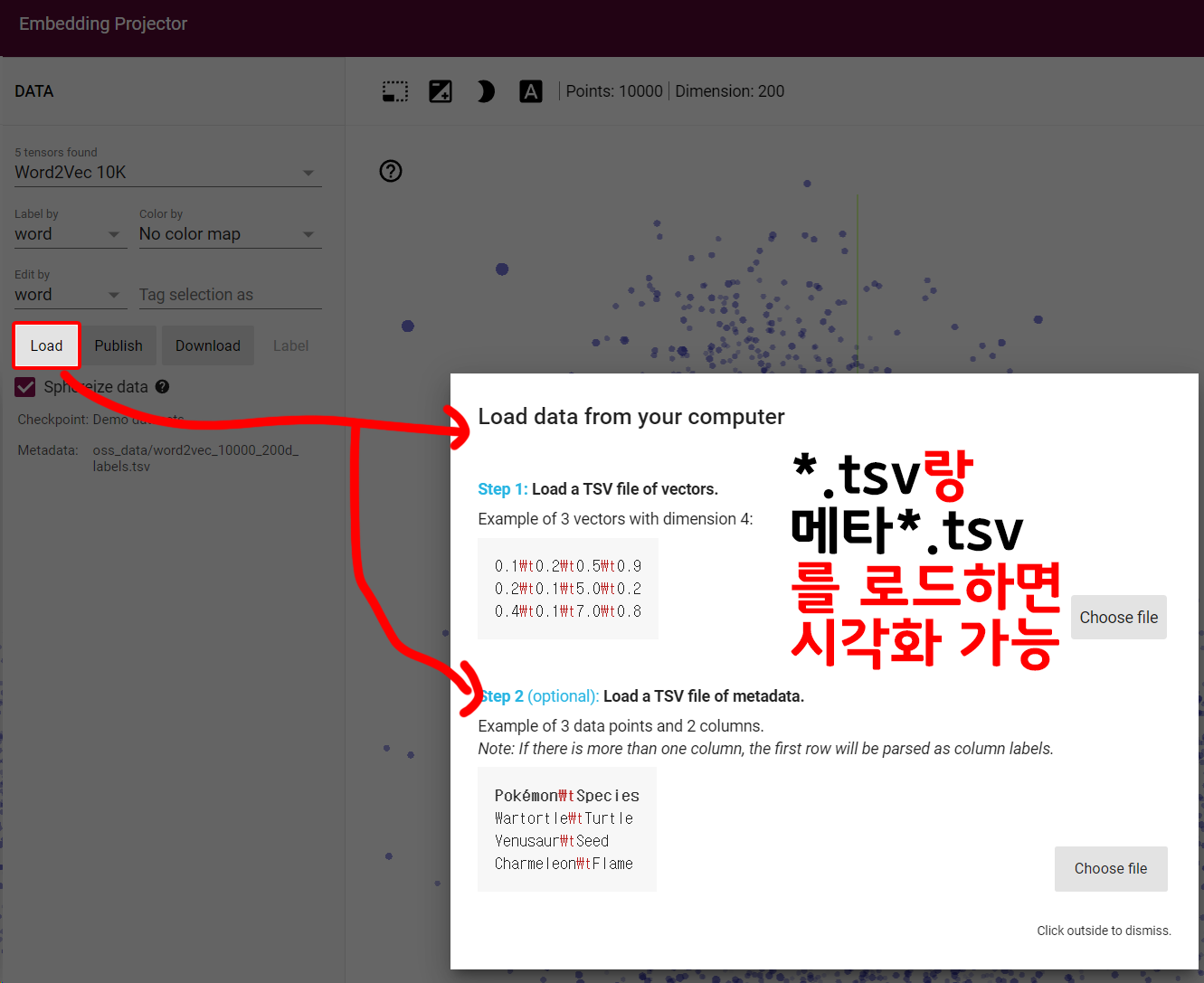

생성한 *.tsv는 https://projector.tensorflow.org/ 에 접속하여
Load 버튼을 클릭 후 파일을 업로드 하면
위 사진처럼 word2vec로 훈련된 임베딩 레이어 정보를 시각화할 수 있다.
학습된 임베딩 레이어 재조정하기
word2vec에서 임베딩 레이어를 학습시킬 때는
입력된 데이터셋을 정리하여
index_to_key : 단어장의 순번
을 생성한다.
이것은 텍스트 처리 과정에서 생성하는 word_to_idx와 동일한 과정으로 제작되는데
필자가 생성한 word_to_idx과 index_to_key를 비교하자면 아래와 같다.
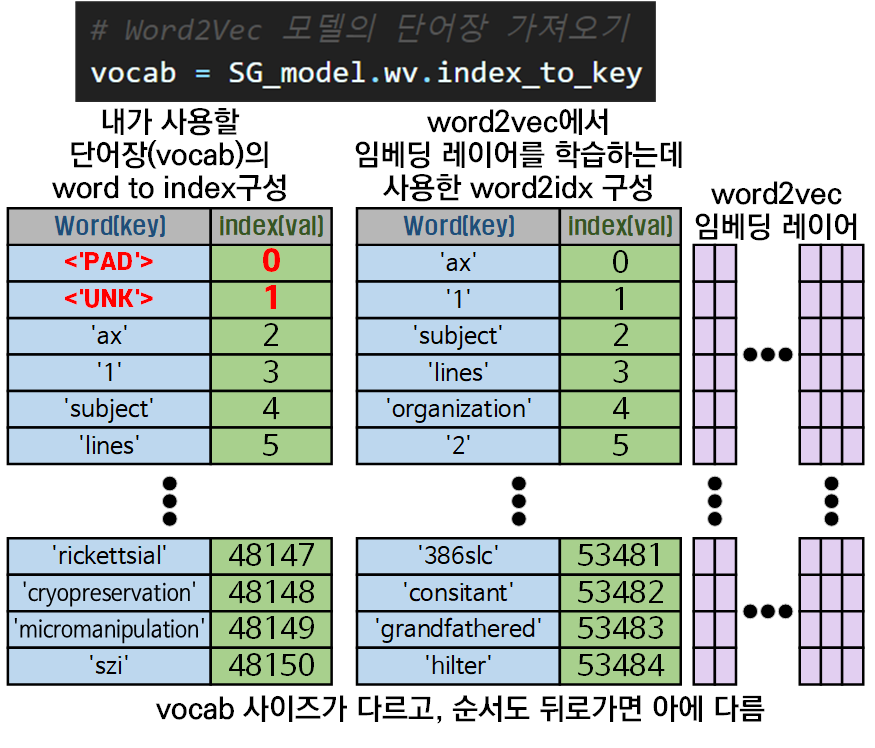
word2vec - index_to_key를 생성하는 메커니즘은 필자의 word_to_idx와 거의 동일하지만
맨 앞단에 스페셜 토큰인 <'UNK'>, <'PAD'>도 없고, 추출한 vocab의 크기도 다르기에
처음만 idx가 비슷하지 후반으로 가면 순번이 꼬이기 시작한다.
따라서 필자가 사용할 word_to_idx 단어 순서 규칙에 맞춰서 학습된 임베딩 레이어의 row 순서도 조정하는 작업을 진행해야 한다.
이에 대한 코드는 정수인코딩에서 사용한 코드를 살짝 응용하면 쉬이 조정할 수 있다.
def build_my_embed(word2idx, vocab_vector):
vocab_size = len(word2idx)
emb_dim = vocab_vector.vector_size
embedding_matrix = np.zeros((vocab_size, emb_dim))
for word, idx in word2idx.items():
# word2idx의 단어를 학습된 임베딩레이어가
# 포함된 단어벡터에서 찾아냄
if word in vocab_vector:
embedding_vector = vocab_vector[word]
embedding_matrix[idx] = embedding_vector
# 스페셜 토큰별로 처리하기
elif word == '<PAD>':
# '<PAD>' 토큰의 임베딩 벡터는 0으로 유지
embedding_matrix[idx] = np.zeros(emb_dim)
else: # 단어벡터에 없는 단어 발생 -> '<UNK>' 처리
# '<UNK>'는 랜덤 초기화 해버린다
embedding_matrix[idx] = np.random.normal(size=(emb_dim,))
return embedding_matrix# CBoW 방식으로 학습된 임베딩 레이어의 조정
my_CB_embedding = build_my_embed(word_to_idx, cbow_model.wv)
# Skip-gram 방식으로 학습된 임베딩 레이어의 조정
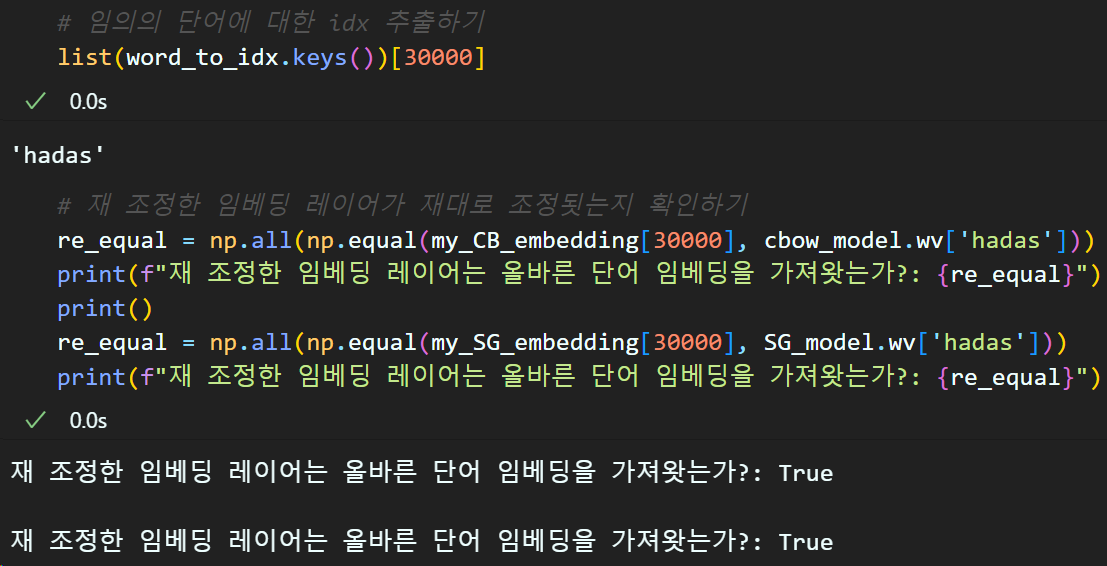
my_SG_embedding = build_my_embed(word_to_idx, SG_model.wv)재 조정이 잘 수행되었는지도 검증하자.
5. 사전 훈련 임베딩
이제
본 포스트의 목적인
뉴스기사를 클래스 분류작업을 해보자...
진짜 자연어 처리(NLP)는 준비가 90%인거 같다...
5.1 데이터셋 정리
주요 하이퍼 파라미터 정리
데이터 전처리, 텍스트 전처리 과정을 수행하면서 다양한 하이퍼 파라미터가 발생했다.
이를 한번 모아서 정리할 필요성이 있다.
# 주요 하이퍼 파라미터 정리
VOCAB_SIZE = len(word_to_idx)
CONTEXT_LENGTH = max_len
EMB_DIM = cbow_model.wv.vector_size
NUM_CLASS = len(data['target_names'])
텐서 자료형으로 변환
import torch
import torch.nn.functional as F# 정수(원핫)인코딩된 x_data를 텐서 자료형으로 변환
t_x_train = torch.tensor(padded_x_train, dtype=torch.int64)
t_x_val = torch.tensor(padded_x_val, dtype=torch.int64)
t_x_test = torch.tensor(padded_x_test, dtype=torch.int64)
# TF-IDF 인코딩된 x_data의 텐서 자료형 변환환
t_tfidf_x_train = torch.tensor(tfidf_train, dtype=torch.float32)
t_tfidf_x_val = torch.tensor(tfidf_val, dtype=torch.float32)
t_tfidf_x_test = torch.tensor(tfidf_test, dtype=torch.float32)
# Y_label 데이터를 텐서 자료형으로 변환 (list -> tensor)
t_y_train = torch.tensor(y_train, dtype=torch.int64)
t_y_val = torch.tensor(y_val, dtype=torch.int64)
t_y_test = torch.tensor(y_test, dtype=torch.int64)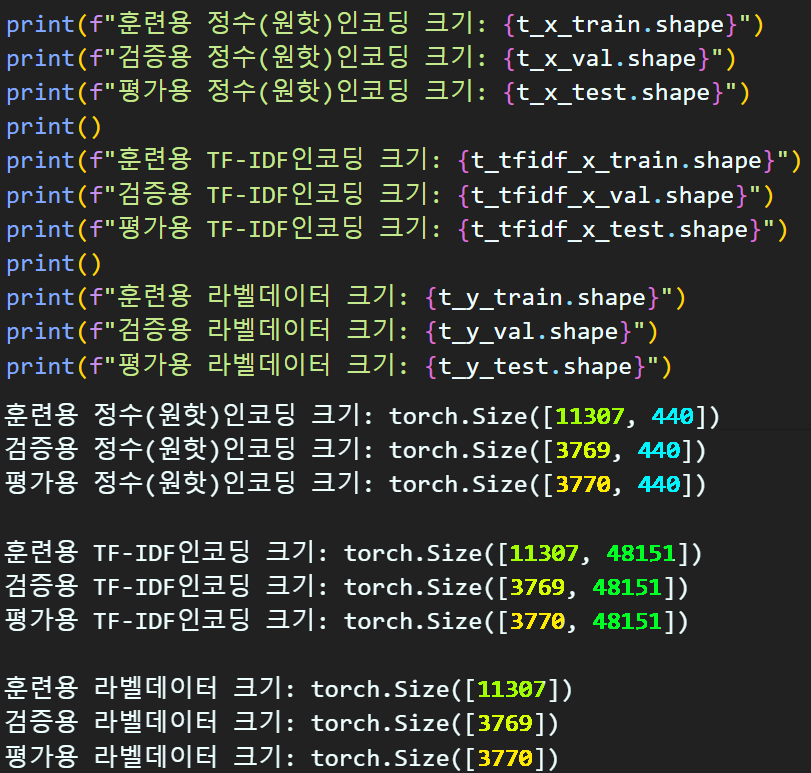
텐서 데이터셋 + 데이터로더 생성
from torch.utils.data import TensorDataset, DataLoader
BS = 256 # Batch_size는 통일# TF-IDF 인코딩용 데이터셋 + 데이터로더
TI_trainset = TensorDataset(t_tfidf_x_train, t_y_train)
TI_trainloader = DataLoader(TI_trainset, shuffle=True, batch_size=BS)
TI_valset = TensorDataset(t_tfidf_x_val, t_y_val)
TI_valloader = DataLoader(TI_valset, shuffle=False, batch_size=BS)
TI_testset = TensorDataset(t_tfidf_x_test, t_y_test)
TI_testloader = DataLoader(TI_testset, shuffle=False, batch_size=BS)
# 임베딩 레이어가 있는 언어모델에 입력할 데이터셋 + 데이터로더
oh_trainset = TensorDataset(t_x_train, t_y_train)
oh_trainloader = DataLoader(oh_trainset, shuffle=True, batch_size=BS)
oh_valset = TensorDataset(t_x_val, t_y_val)
oh_valloader = DataLoader(oh_valset, shuffle=False, batch_size=BS)
oh_testset = TensorDataset(t_x_test, t_y_test)
oh_testloader = DataLoader(oh_testset, shuffle=False, batch_size=BS)5.2 모델 설계
모델 설계 및 객체화
TF-IDF인코딩 데이터로더
임베딩 레이어 적용을 고려한 정수 인코딩 데이터로더
2 종의 데이터로더를 만들었고
임베딩 레이어는
1) 랜덤 초기화
2) CBoW 레이어 파라미터로 Transfer
3) Skip-gram 레이어 파라미터로 Transfer
이니 모델을 설계하고 각 실험군에 맞춰 모델을 객체화한다.
import torch.nn as nn
HIDE_DIM = 1400class simpleNet(nn.Module):
def __init__(self, vocab_size, hidden_dim, num_label):
super(simpleNet, self).__init__()
self.fcn1 = nn.Linear(vocab_size, hidden_dim)
self.relu = nn.ReLU()
self.fcn2 = nn.Linear(hidden_dim, num_label)
def forward(self, x):
x = self.fcn1(x)
x = self.relu(x)
x = self.fcn2(x)
return xclass emb_simpleNet(nn.Module):
def __init__(self, vocab_size, embed_dim, hidden_dim, num_label):
super(emb_simpleNet, self).__init__()
self.embed = nn.Embedding(vocab_size, embed_dim)
self.fcn1 = nn.Linear(embed_dim, hidden_dim)
self.relu = nn.ReLU()
self.fcn2 = nn.Linear(hidden_dim, num_label)
def forward(self, x):
x = self.embed(x)
# 단어의 유사성 의미정보는 뭉게버린다.
x = torch.mean(x, dim=1)
x = self.fcn1(x)
x = self.relu(x)
x = self.fcn2(x)
return x# 0. TF-IDF 인코딩으로 기사분류를 위한 모델 객체화
tfidf_model = simpleNet(VOCAB_SIZE, HIDE_DIM, NUM_CLASS)
# 1. 랜덤 초기화한 임베딩 레이어를 사용하는 모델 객체화
normal_model = emb_simpleNet(VOCAB_SIZE, EMB_DIM, HIDE_DIM, NUM_CLASS)
# 2. CBoW으로 훈련된 임베딩 레이어를 붙인 모델 객체화
cb_model = emb_simpleNet(VOCAB_SIZE, EMB_DIM, HIDE_DIM, NUM_CLASS)
# 레이어 붙이기
cb_model.embed.weight.data.copy_(torch.from_numpy(my_CB_embedding))
# 옵션 : 붙인 임베딩 레이어를 Freeze하고싶을때
# cb_model.embed.weight.requires_grad = False
# 3. Skip-gram으로 훈련된 임베딩 레이어를 붙인 모델 객체화
sg_model = emb_simpleNet(VOCAB_SIZE, EMB_DIM, HIDE_DIM, NUM_CLASS)
# 레이어 붙이기
sg_model.embed.weight.data.copy_(torch.from_numpy(my_SG_embedding))
# 옵션 : 붙인 임베딩 레이어를 Freeze하고싶을때
# sg_model.embed.weight.requires_grad = False
print()5.3 학습 준비
학습 하이퍼 파라미터 설정
# GPU사용 가능 유/무 확인
device = torch.device("cuda" if torch.cuda.is_available() else 'cpu')
# GPU로 모델 전이
tfidf_model.to(device)
normal_model.to(device)
cb_model.to(device)
sg_model.to(device)import torch.optim as optim
# 로스함수 및 옵티마이저 설계
criterion = nn.CrossEntropyLoss()
LR = 0.001 # 러닝레이트는 통일
optimizer_0 = optim.Adam(tfidf_model.parameters(), lr=LR)
optimizer_1 = optim.Adam(normal_model.parameters(), lr=LR)
optimizer_2 = optim.Adam(cb_model.parameters(), lr=LR)
optimizer_3 = optim.Adam(sg_model.parameters(), lr=LR)훈련/검증 라이브러리 불러오기
# 사전에 모듈화 한 학습/검증용 라이브러리 import
from C_ModelTrainer import ModelTrainer
num_epoch = 15 #총 훈련/검증 epoch값
ES = 3 # 디스플레이용 에포크 스텝
# BC_mode = True(이진), False(다중)
# aux = 보조분류기 유/무
# wandb = 완디비에 연결 안하면 None
trainer = ModelTrainer(epoch_step=ES, device=device, BC_mode=False, aux=False)위 라이브러리는 필자가 훈련/검증을 위해 설계한 별도의 라이브러리 이다.
해당 코드는 https://github.com/tbvjvsladla/ResNext_wandb/blob/main/C_ModelTrainer.py 에서 다운로드가 가능하다.
실험군별 딕셔너리화
#학습/검증 중간 정보 저장
keys = [['tfidf', 'random_init', 'CBoW', 'Skip-gram'], ['loss', 'acc']]
history = {key: {'loss': [], 'acc': []} for key in keys[0]}models = {'tfidf' : tfidf_model,
'random_init' : normal_model,
'CBoW' : cb_model,
'Skip-gram' : sg_model}
train_loaders = {'tfidf' : TI_trainloader,
'random_init' : oh_trainloader,
'CBoW' : oh_trainloader,
'Skip-gram' : oh_trainloader}
val_loaders = {'tfidf' : TI_valloader,
'random_init' : oh_valloader,
'CBoW' : oh_valloader,
'Skip-gram' : oh_valloader}
optimizers = {'tfidf' : optimizer_0,
'random_init' : optimizer_1,
'CBoW' : optimizer_2,
'Skip-gram' : optimizer_3}5.4 학습
모델 학습 루프 구동
for step in range(len(keys[0])):
epoch = 0 #에포크 초기화
for epoch in range(num_epoch):
#훈련 손실&성능지표 반환
train_loss, train_acc = trainer.model_train(
models[keys[0][step]], train_loaders[keys[0][step]],
criterion, optimizers[keys[0][step]], epoch
)
#검증 손실&성능지표 반환
val_loss, val_acc = trainer.model_evaluate(
models[keys[0][step]], val_loaders[keys[0][step]],
criterion, epoch
)
#손실&성능지표를 history에 저장
history[keys[0][step]][keys[1][0]].append((train_loss, val_loss))
history[keys[0][step]][keys[1][1]].append((train_acc, val_acc))
# Epoch_Step(ES)일때 print하기
if (epoch+1) % ES == 0 or epoch == 0:
print(f"현재 훈련중인 모델: {keys[0][step]}")
print(f"epoch {epoch+1:03d}," + "\t" +
f"훈련 [Loss: {train_loss:.3f}, " +
f"Acc: {train_acc*100:.2f}%]")
print(f"epoch {epoch+1:03d}," + "\t" +
f"검증 [Loss: {val_loss:.3f}, " +
f"Acc: {val_acc*100:.2f}%]")
print(f"\n----모델{keys[0][step]} 훈련 종료----\n")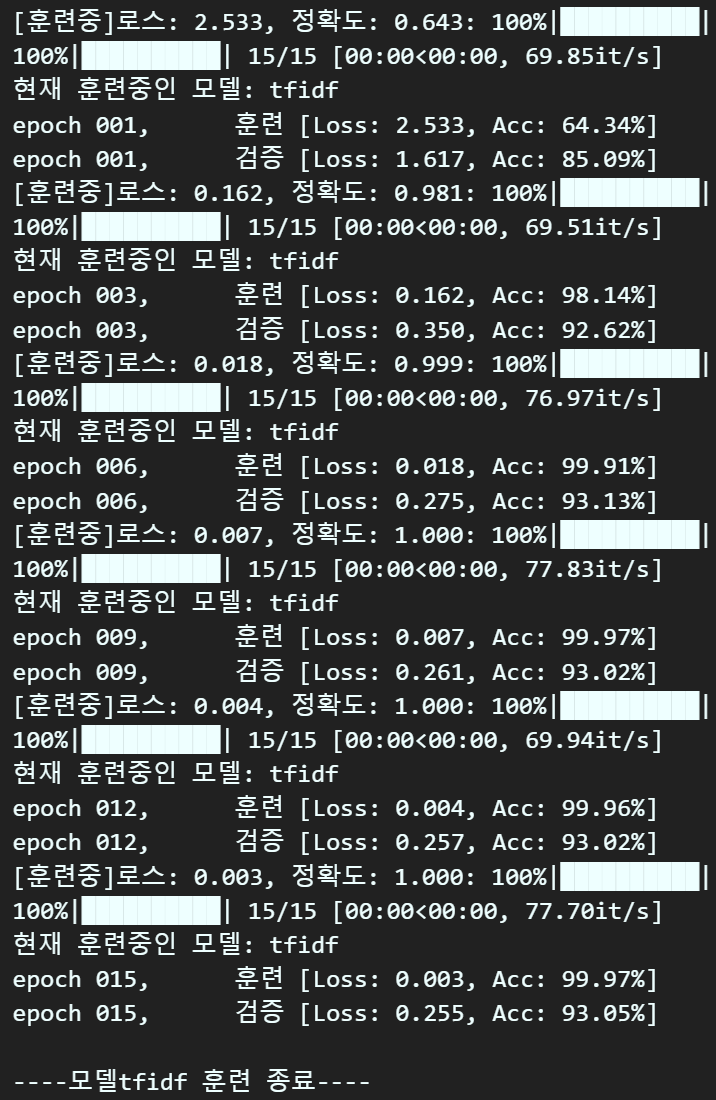
대략 위와 같게 학습이 진행되면서 중간 결과물이 출력되면 문제가 없는 것이다.
5.5 학습 결과 분석
학습 결과 분석 준비
import matplotlib.pyplot as plt
# 모델 목록과 메트릭 목록
models = keys[0]
metrics = keys[1]
# 데이터 추출을 위한 딕셔너리 초기화
extracted_data = {}
for model in models:
extracted_data[model] = {}
for metric in metrics:
# 각 모델의 메트릭 데이터 추출
metric_data = history[model][metric]
# 훈련 및 검증 값 분리
train_values = [tup[0] for tup in metric_data]
val_values = [tup[1] for tup in metric_data]
extracted_data[model][f'train_{metric}'] = train_values
extracted_data[model][f'val_{metric}'] = val_values4개의 모델에 대한 학습/검증 루프를 돌리면서 다중 중첩 딕셔너리에 데이터를 저장했으니
이를 그래프화 하기 전에 인덱싱이 잘 이뤄지도록 준비 코드를 작성한다
손실 그래프
# 손실 그래프 생성
fig, axes = plt.subplots(2, 2, figsize=(12, 10))
axes = axes.flatten() # 2차원 배열을 1차원으로 변환하여 인덱싱 쉽게 함
for idx, model in enumerate(models):
ax = axes[idx]
ax.plot(extracted_data[model]['train_loss'], label='Train Loss')
ax.plot(extracted_data[model]['val_loss'], label='Validation Loss')
ax.set_title(f'{model} Loss')
ax.set_xlabel('Epoch')
ax.set_ylabel('Loss')
ax.legend()
plt.tight_layout()
plt.show()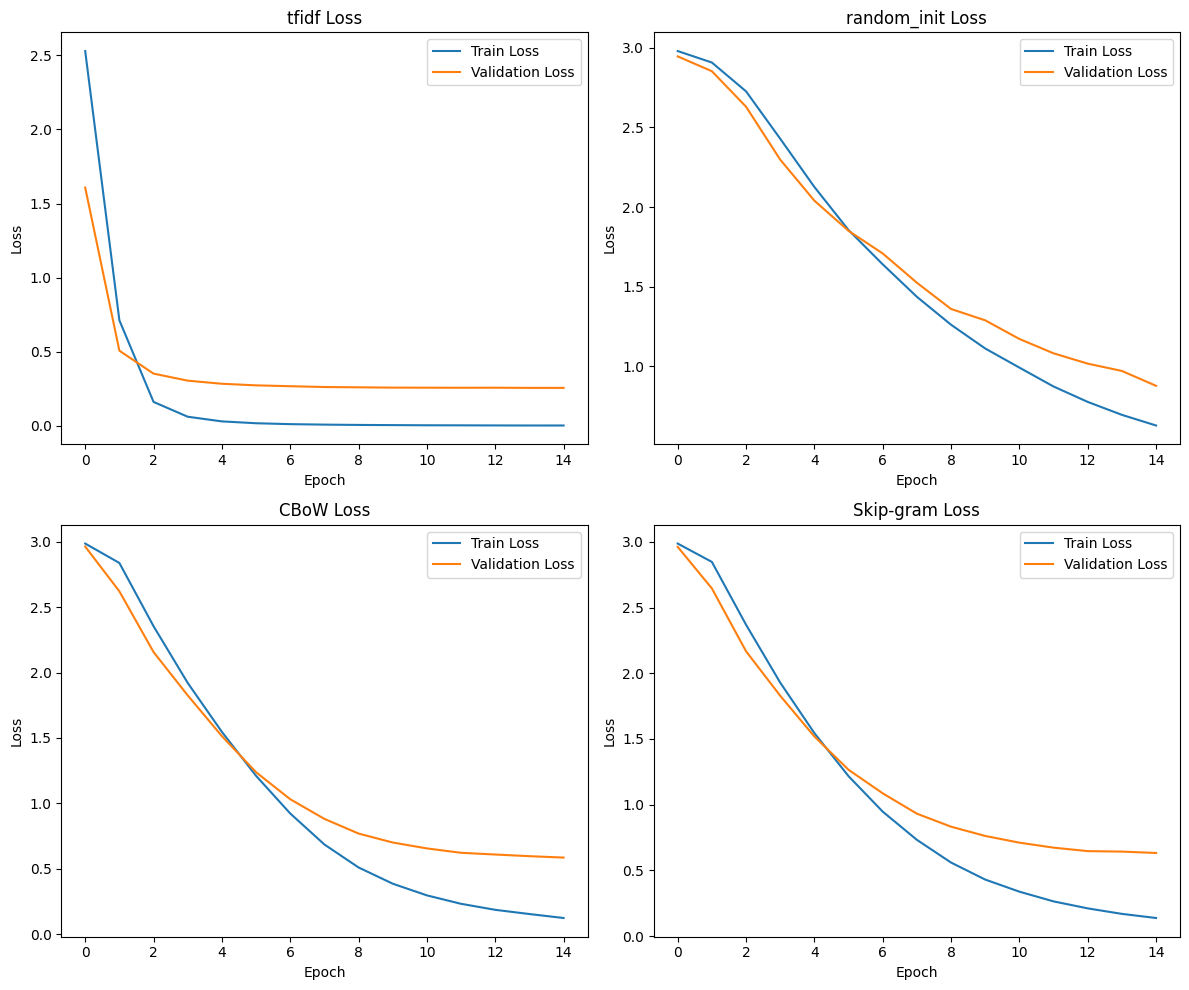
정확도 그래프
# 정확도 그래프 생성
fig, axes = plt.subplots(2, 2, figsize=(12, 10))
axes = axes.flatten()
for idx, model in enumerate(models):
ax = axes[idx]
ax.plot(extracted_data[model]['train_acc'], label='Train Accuracy')
ax.plot(extracted_data[model]['val_acc'], label='Validation Accuracy')
ax.set_title(f'{model} Accuracy')
ax.set_xlabel('Epoch')
ax.set_ylabel('Accuracy')
ax.legend()
plt.tight_layout()
plt.show()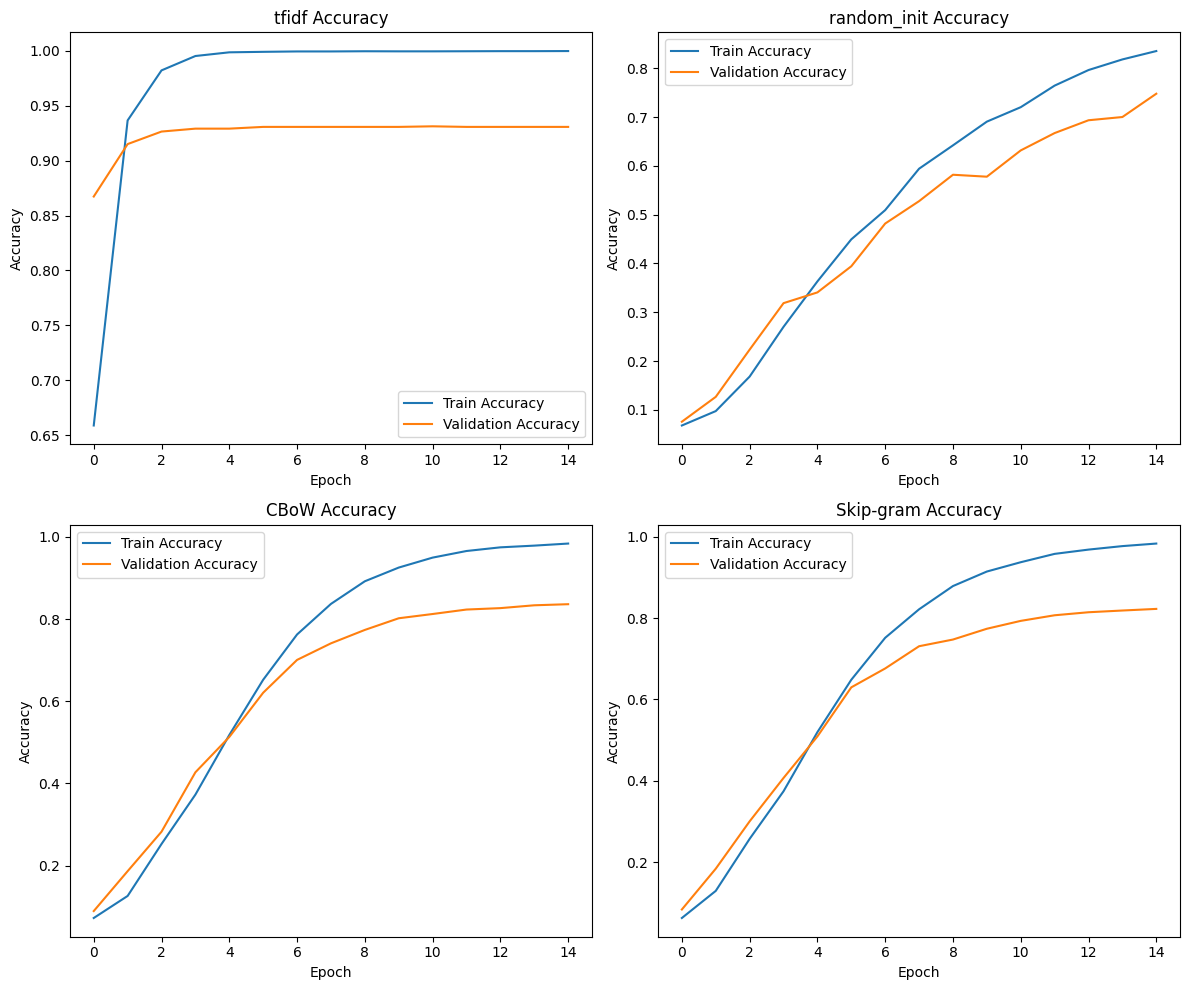
종합 분석
# 모든 모델의 손실과 정확도를 비교하는 그래프 생성
fig, axes = plt.subplots(2, 1, figsize=(10, 18))
# 모든 모델의 손실 그래프
ax = axes[0]
for model in models:
ax.plot(extracted_data[model]['train_loss'], label=f'{model} Train Loss')
ax.plot(extracted_data[model]['val_loss'], label=f'{model} Val Loss', linestyle='--')
ax.set_title('Training and Validation Loss for All Models')
ax.set_xlabel('Epoch')
ax.set_ylabel('Loss')
ax.legend()
# 모든 모델의 정확도 그래프
ax = axes[1]
for model in models:
ax.plot(extracted_data[model]['train_acc'], label=f'{model} Train Acc')
ax.plot(extracted_data[model]['val_acc'], label=f'{model} Val Acc', linestyle='--')
ax.set_title('Training and Validation Accuracy for All Models')
ax.set_xlabel('Epoch')
ax.set_ylabel('Accuracy')
ax.legend()
plt.tight_layout()
plt.show()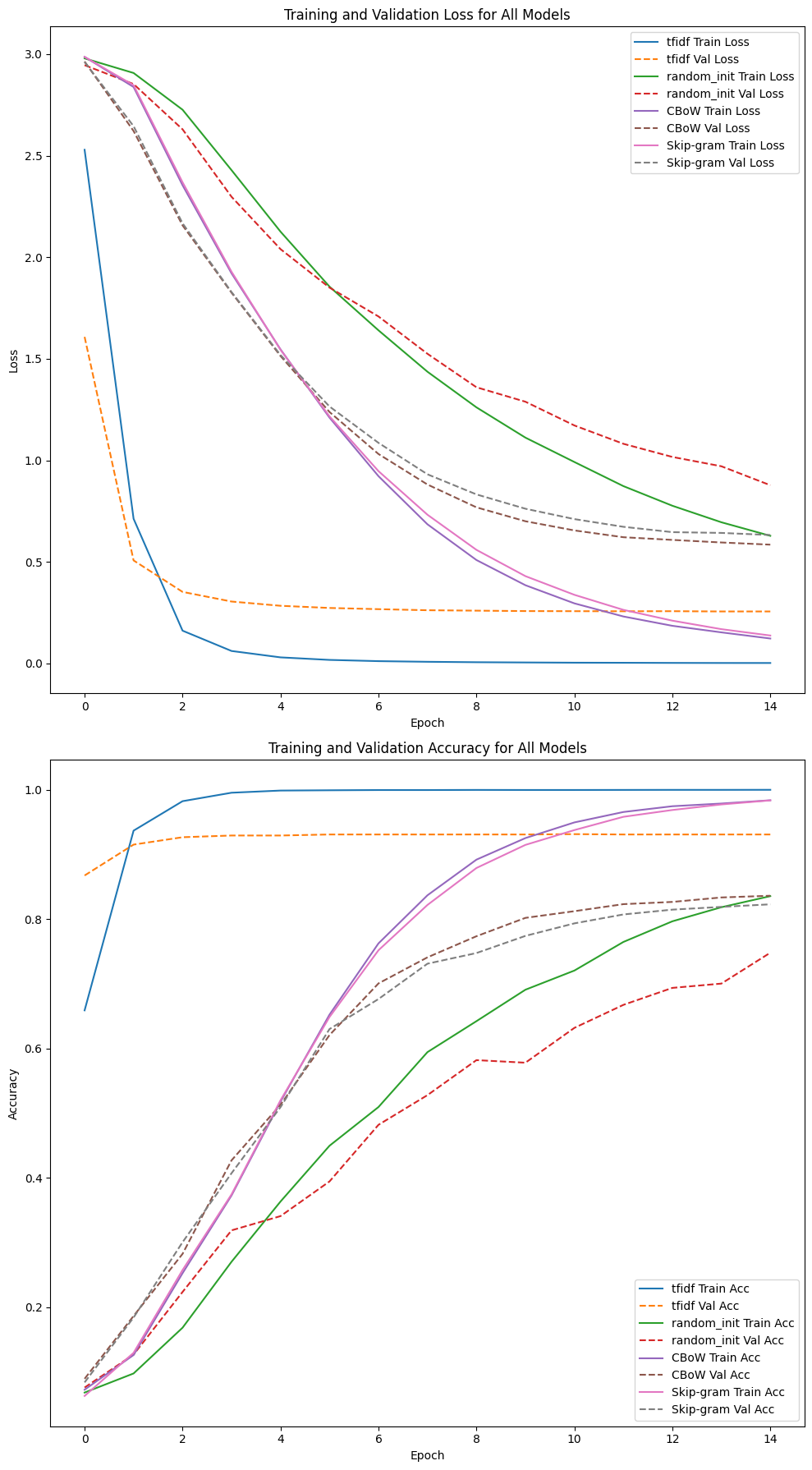
TF-IDF는 데이터가 뭉게지는 과정이 없이 온전히 인코딩 된 정보가 모두 반영되기에 학습성능이 가장좋게 나오는 것을 알 수 있다.
그러면 데이터가 뭉게지는 패널티를 앉고 간
임베딩 레이어 별로 성능을 비교하자면
랜덤 초기화 << CBoW < Skip-gram
순으로 Pre-trained Embedding 을 적용했을 때
뉴스 기사 분석의 정확도가 높아지는 것을 확인할 수 있다.
포스트를 작성하면서
데이터 전처리 -> 텍스트 전처리 부분은
하나의 클래스로 만든 뒤 외부 모듈화 처리를 해서 내용을 줄여도 볼까 고민하고 있지만
하.. 이 자연어 데이터셋은 진짜 일반화 하기가 어렵기에
데이터 전처리, 텍스트 전처리 뭐 모듈화 하기가 참 난감하다

진짜 이미지 처리가 선녀다 선녀;;;
자연어 처리 진짜 드럽게 자잘하게 할거 많네
