
개요
본 블로그 포스팅은 수도권 ICT 이노베이션 스퀘어에서 진행하는 AI 핵심 기술 집중 클래스의 자연어처리(NLP) 강좌 내용을 필자가 다시 복기한 내용에 관한 것입니다.
1. 텍스트 분류를 CNN으로

https://aclanthology.org/D14-1181.pdf

자연어 처리(NLP) - 자연어 이해(NLU)는 위 사진처럼 의미분석(감정분석), 개체명 인식, 질문 응답등의 Task가 포함되 있고
그간 포스팅한 NLP-Text 분류기 실습은
자연어 이해(NLU)에 속하는 Task이다.
해당 Task를 수행하는데 RNN, GRU, LSTM등의 언어모델을 사용했지만 동일한 과정을 수행하는 언어모델로
CNN(Convolutional Neural Network)를 사용하는게
이번 포스팅에서 다루는 Convolutional Neural Networks for Sentence Classification논문이다.
해당 논문에서는 Text Clasification을 수행하기 위한 데이터셋에 대하여 기본조건을 설정했는데
1) 데이터셋은 레이블이 라벨링되어 지도 학습(Supervised Learning)이 가능한 형태여야 함
2) 입력된 데이터셋은 적당한 길이의 문장(Sentence)단위어야 함 단어단위의 데이터셋처럼 너무 짧으면 안되고, 여러 문장으로 구성된 긴 문서여도 안됨
3) 고정된 입력 크기 : CNN은 입력되는 데이터가 고정된 크기어야 하기에 모든 문장은 동일한 길이로 변환(문장 패딩과 같은 전처리가 수행된 데이터)이어야 함
이는 이전 포스트 2. NLP-LSTM, GRU (2) : 텍스트 분류기, 2. NLP-RNN (1) : 텍스트 분류기
에서 사용한 데이터셋
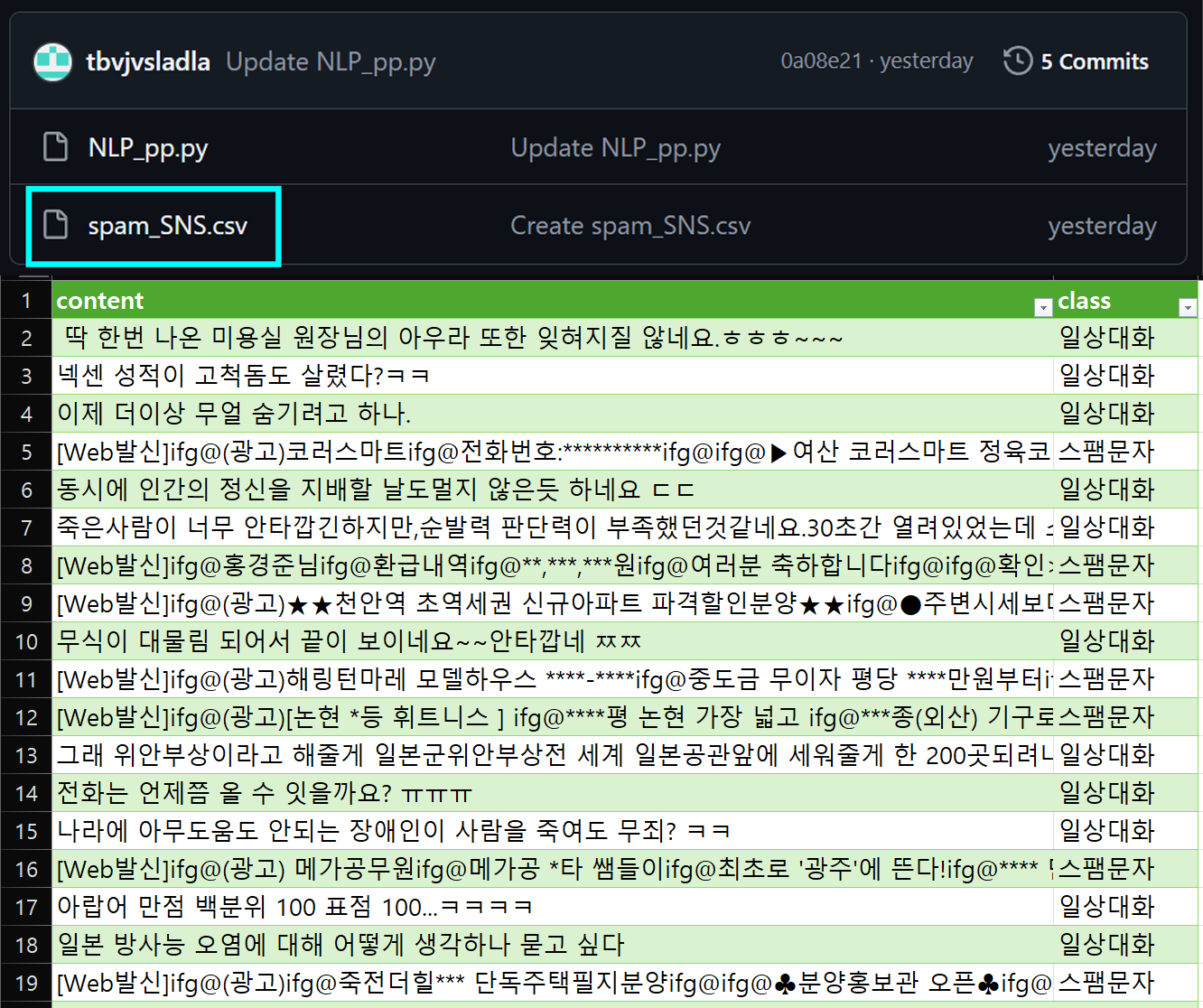
spam_SNS.csv의 데이터셋이라면 Convolutional Neural Networks for Sentence Classification논문에서 언급하는 데이터셋의 기본조건은 거의 모두 충족하는 것이 가능한 데이터셋이다.
따라서 해당 논문에서 CNN을 활용한 Classification 과정을 도식화 한다면 아래와 같아진다.
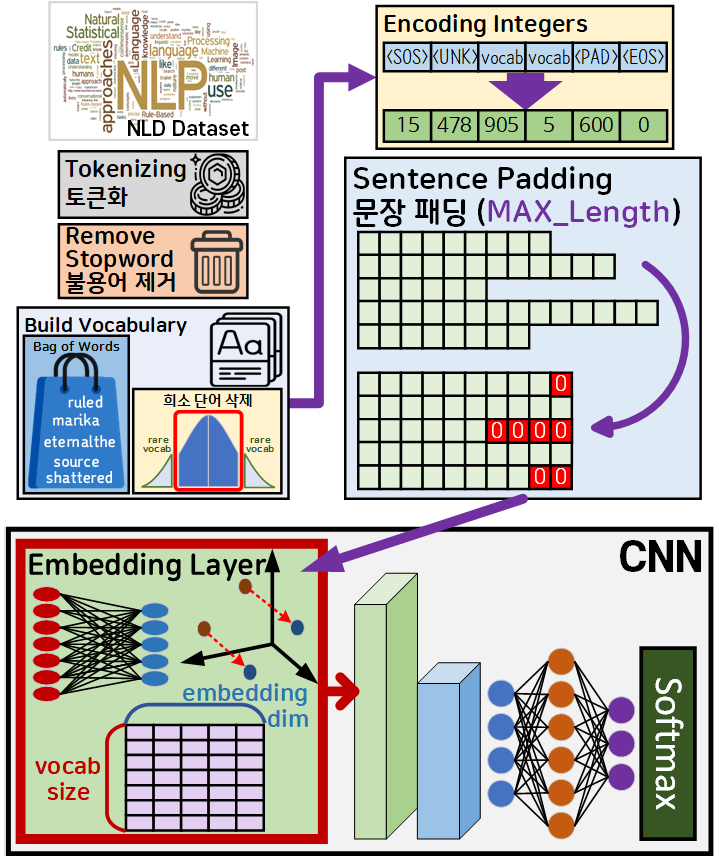
위 도식을 본다면 Convolutional Neural Networks for Sentence Classification을 수행하기 위한 데이터 전처리에는 또다른 주요 조건이 하나 더 붙어있다
바로 CNN모델에 입력되기 직전의 데이터는
nn.Embedding : Embedding layer를 통과시켜서 데이터가 단어의 의미적 유사성 정보가 포함되어야 한다.
즉, CNN이 Kernel을 이용해 이미지의 인접 픽셀 간 특징 유사성을 추출하는 과정을
텍스트(자연어) 분류작업에도 적용하는것 이 본 논문의 핵심 아이디어라 할 수 있다.
이 Embedding layer가 문장 패딩까지 수행하여 전처리된
Sequence matrix를 밀집 벡터(Dense vector)로 차원 축소하면서 동시에 단어의 의미적 유사성 정보가 포함되는 이유는
1. NLP-Text 전처리 : 현대 벡터화(Word Embedding) (2) - AI 핵심기술 강의 복습에 포스팅을 진행했기에 해당 포스트를 참조하기 바란다.
1.1 Conv1d
Convolutional Neural Networks for Sentence Classification에서 사용하는 언어모델인 CNN은 기존 CV계열에서 출창 사용해온 nn.conv2d 메서드를 사용해도 구현이 가능하지만
입력 데이터셋이 임베딩된 시퀀스 데이터이기에 동일하게 순서정보가 포함된 데이터구조인 시계열 데이터의 학습 및 처리에 주로 사용되는 nn.conv1d를 사용하여 언어모델을 구성하고자 한다.
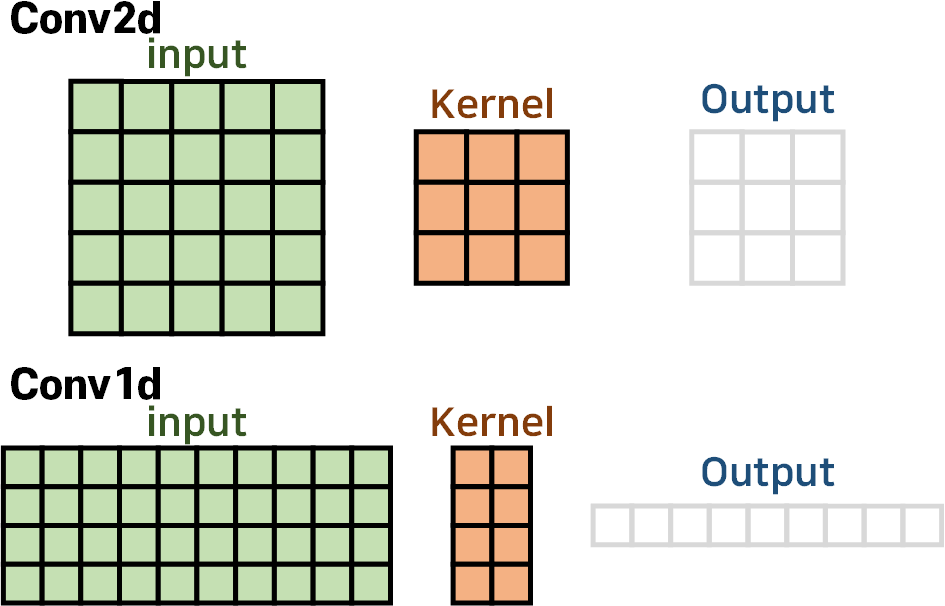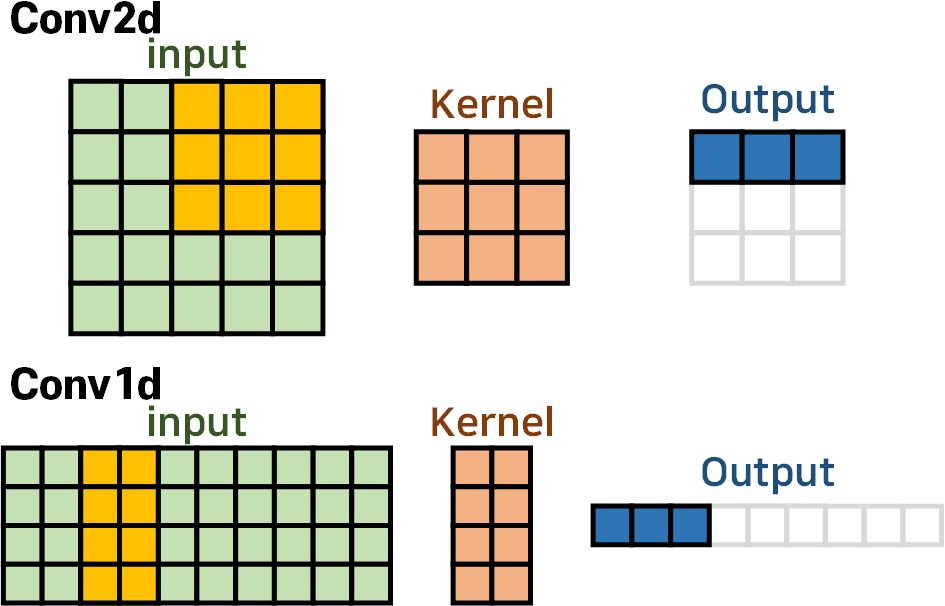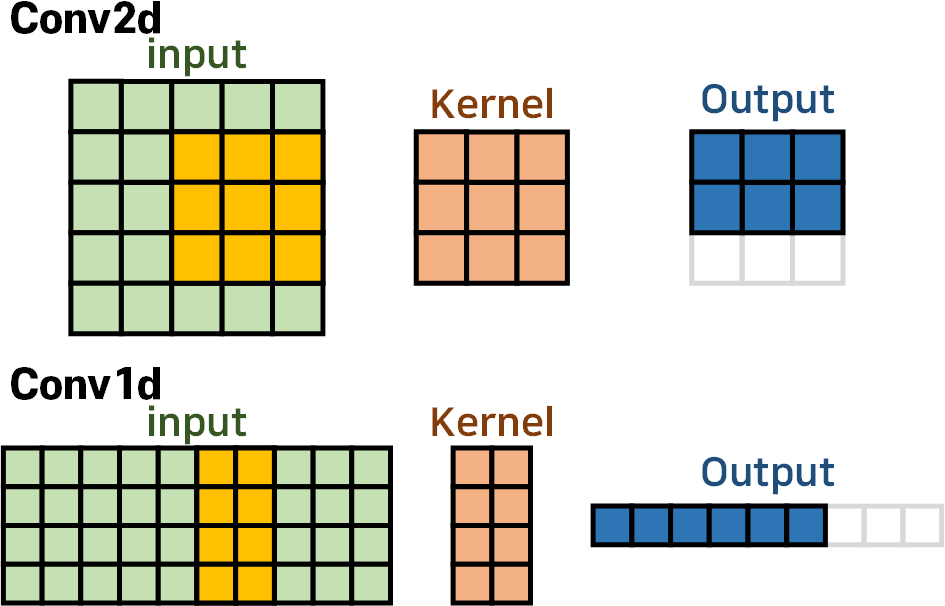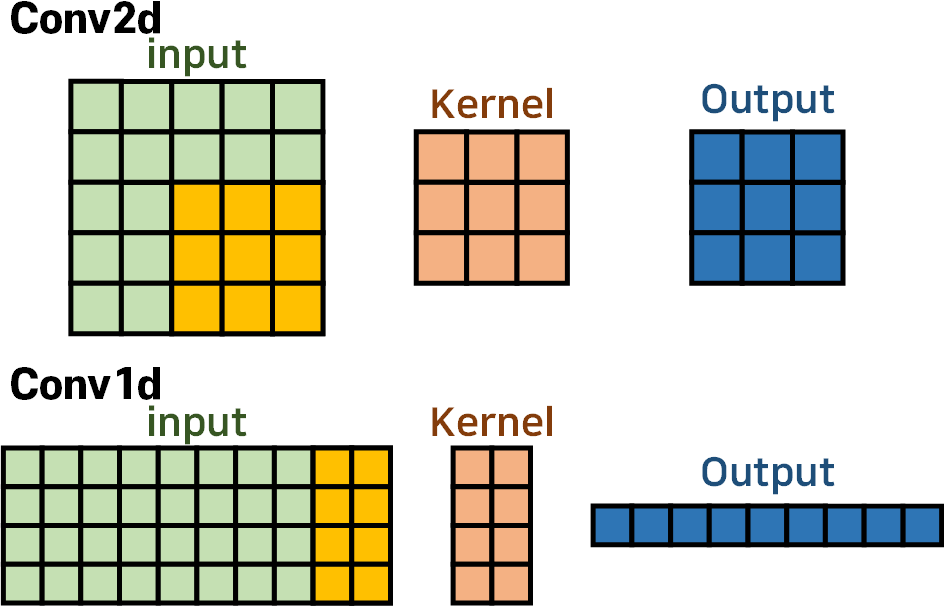
먼저 Conv2d와 Conv1d의 구조를 비교해 본다면
Conv2d에서는 Kernel이 가로, 세로 두가지 방향으로 움직이면서 입력 데이터를 필터링해 Output를 생성하지만
Conv1d는 Kernel이 오직 가로방향으로만 움직이며, 커널의 세로(H) 길이는 무조건 Input의 세로(H)길이와 일치한 값을 갖는다
따라서 Conv1d의 Kernel_size를 조정하는 것은 커널의 가로(W)길이만 조정하는 것이다.
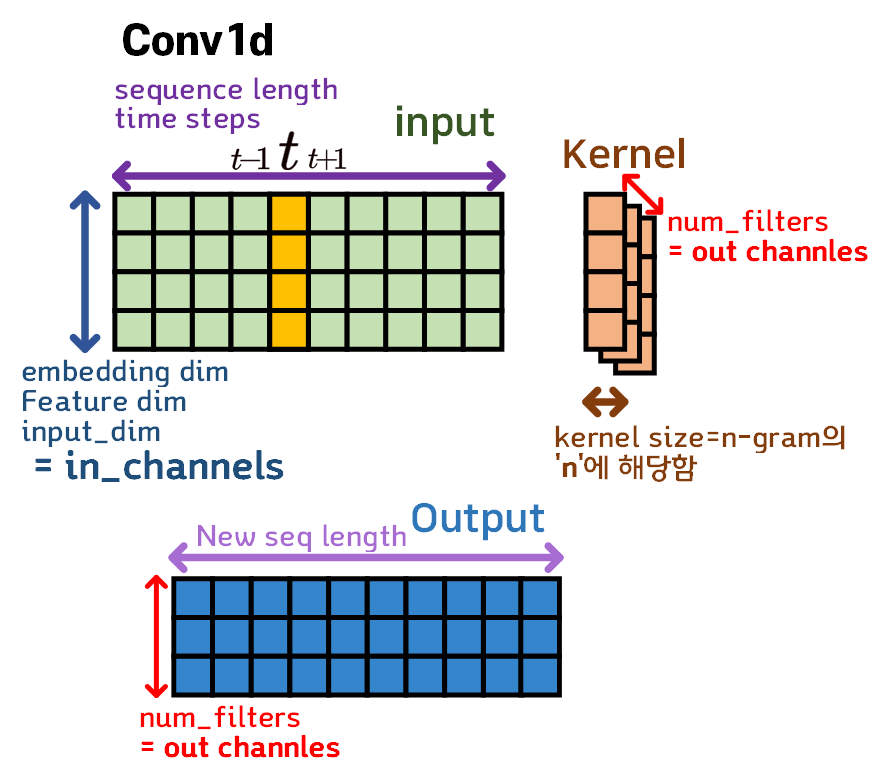
이제 Conv1d의 입력(input), 커널(kernel), 출력(output)의 관계를 그림으로 표현하자면 위와 같으며
Conv1d가 시계열 데이터의 처리에도 사용되는 합성곱 필터이기에 각 Feature의 dimension이 여러 단어로 의미가 중복하여 사용됨을 잘 알아두어야 한다.
먼저 Input Feature는 데이터 입력 형식이
[Batch_size, embdding_dim, Sequence_length]
이고
이때 in_channels = embdding_dim가 된다.
Kernel은 가로방향 즉, time_step 방향으로 데이터를 훑으면서 합성곱을 수행하며, Kernel_size는 시퀀스 데이터를 처리할 때 흔히 언급하는
중심단어-주변단어의 관계인 n_gram의 값이 된다.
만약 중심단어를 기준으로 주변단어를 앞 뒤로 1개씩 보게 된다면 n_gram = 3 = Kernel_size가 되는 것이다.
그리고 여러개의 Kernel을 적용하는 num_filtes인자값은 output_channels랑 같은 값이 된다.
즉, output_channels = num_filtes 이다
마지막으로 Output Feature는 기본적인 출력형식이
[Batch_size, 1 , New_Sequence_length] 이지만
Kernel이 여러개 적용되는 경우(num_filtes이 , 1 이 아님)
[Batch_size, num_filtes, New_Sequence_length]
이렇게 출력된다.
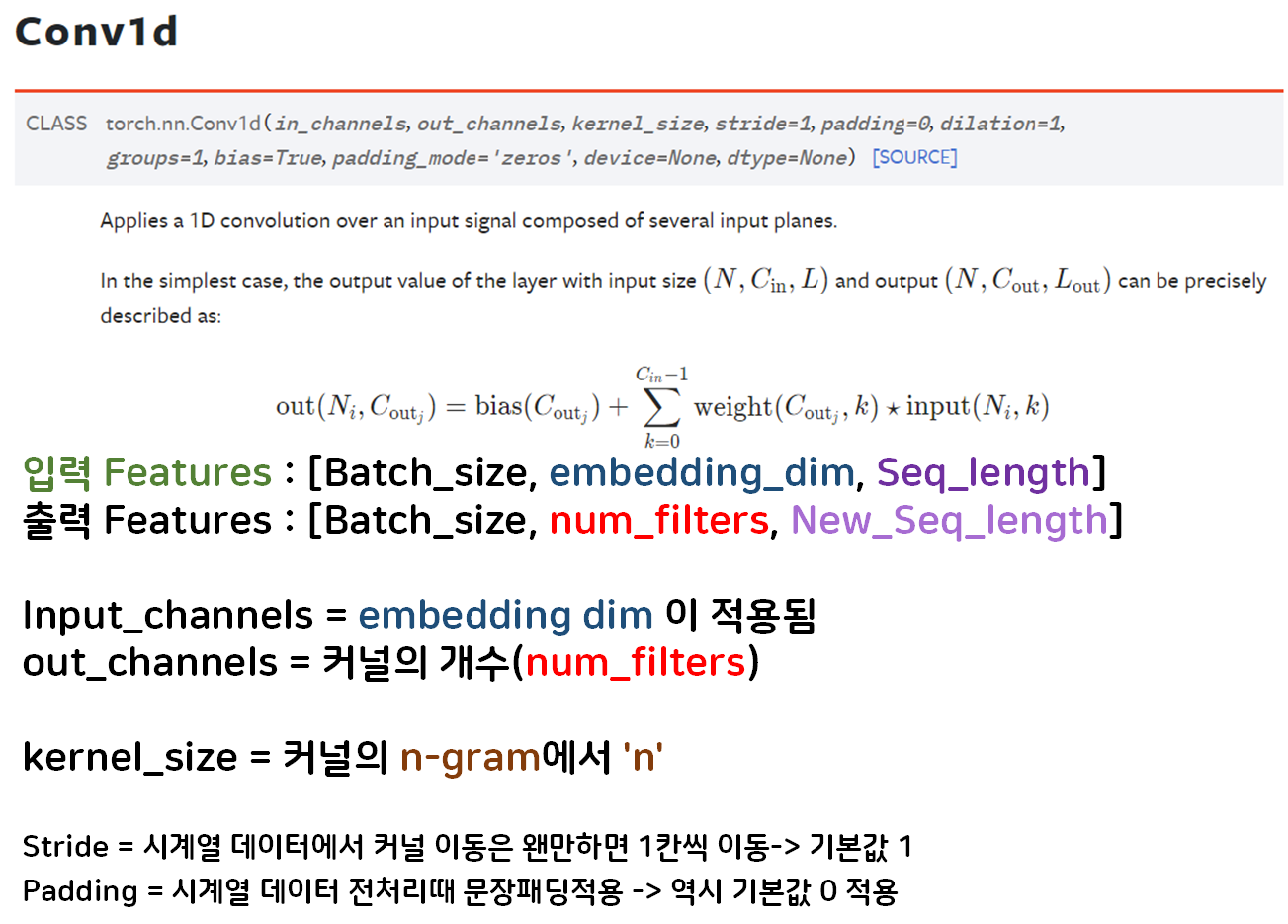
따라서 nn.Conv1d의 주요 인자값 및 입력/출력의 형태는 위와 같이 정리할 수 있다.
이때 stride와 padding은 각각 기본값인 1, 0을 변경하지 않고 그대로 쓰는게 대부분인데
이는 직관적으로 이해하면 당연한 소리이다
stride가 1 이 아니면 time_step를 건너뛰면서 커널을 적용한다는것이니 말이 안되는 이야기고
padding은 어차피 텍스트 전처리 - 문장패딩(Sentence Padding) 과정에서 스페셜 토큰 <PAD> : 0이 달라붙는데 추가로 패딩을 붙일 이유는 없다.
1.2 논문 아키텍쳐 및 실험조건
위 Conv1d의 동작원리를 알았으니
Convolutional Neural Networks for Sentence Classification에서 설명하고 있는 Model 아키텍쳐 및
실험조건에 대해서 혼동되는 부분의 정리 및 비판할 부분을 정리해보자
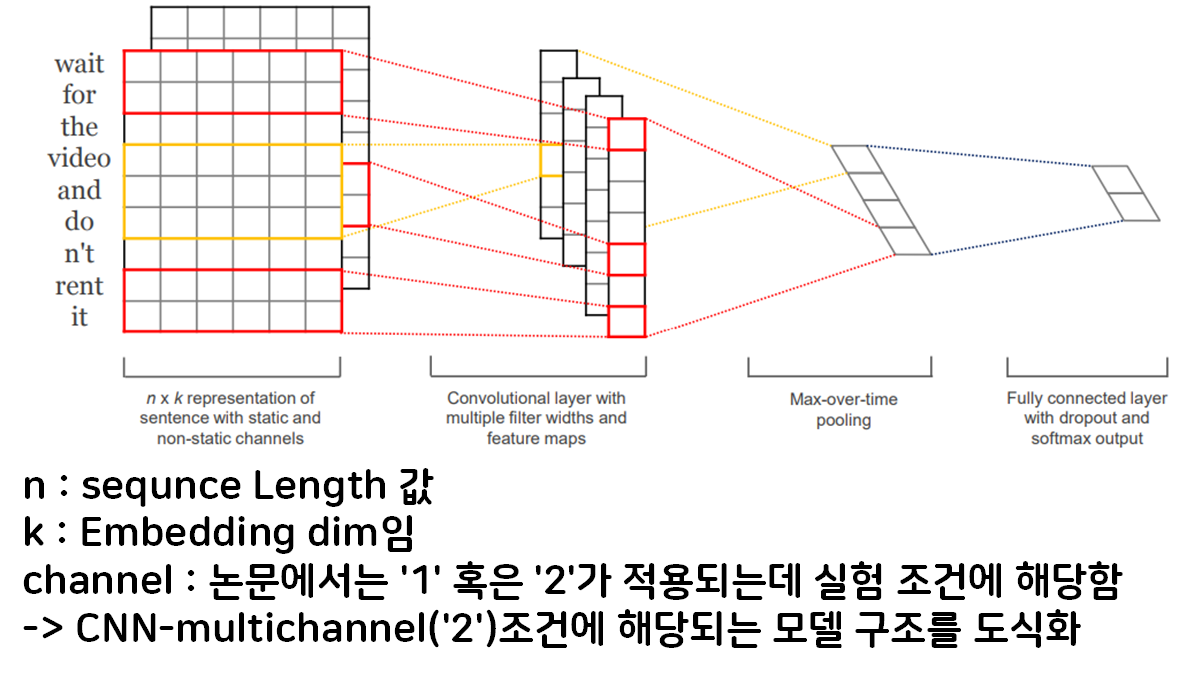
우선 모델 아키텍쳐 도식화를 본다면
Conv1d는 Kernel이 가로방향으로 이동하지만 논문의 그림은 이를 전치하여 세로 방향으로 이동하게끔 그려서
혼동되는 첫번째 항목이 있다.
그리고 n = Sequence_length
k = embdding_dim 인데
Conv1d에서는 embdding_dim = in_channels 이므로
중간에 channel 항목이 또 나와서 혼동되는 항목이 존재한다
논문의 Channel은 실험조건에 따라 대부분 1,
CNN-Multichannel 조건에서만 2인데
CNN-Multichannel로 그림을 그려놔서 이것도 역시 혼동된다
마지막으로 Multiple Filter을 적용하면서 이를
다 채널 Output Feature로 표현했는데
Conv1d에서 num_filtes가 Multiple Filter 조건이면 가로축으로 결과물이 붙는 식이기에
지금처럼 z축으로 Output_Feature가 쌓이는 것처럼 도식화 하면 이것 역시 혼동된다.
그리고 실험조건도 4개 조건으로 상당히 어지럽게 구성되어 있는데
1) CNN-rand : nn.Embedding를 그냥 랜덤초기화
2) CNN-static : nn.Embedding에 사전학습 임베딩 레이어(word2vec)를 적용하고 해당 레이어를 Freeze
3) CNN-non-static : 2)와 과정은 모두 동일하나, nn.Embedding를 Trainable하게 냅둠
4) CNN-Multichannel : 2), 3)과정의 모델을 결합한 앙상블 형태로 사용
그동안 필자가 2. NLP-RNN (1) : 텍스트 분류기,
2. NLP-LSTM, GRU (2) : 텍스트 분류기
에서 실험한 조건은
1) 임베딩 레이어 랜덤 초기화
3) 사전학습 임베딩 레이어 적용 - 해당 레이어는 Trainable
이 조건으로만 실험을 수행했고
2), 4) 조건으로는 실험을 수행하지 않았다.
이거는 실습을 하면서 느낀건데
임베딩 레이어는 사전 학습 임베딩 레이어를 적용하더라도
해당 레이어는 Trainable하게 적용하는게 좋다
Freeze적용하면 경험상 성능이 더 떨어진다...
1.3 모델 설계
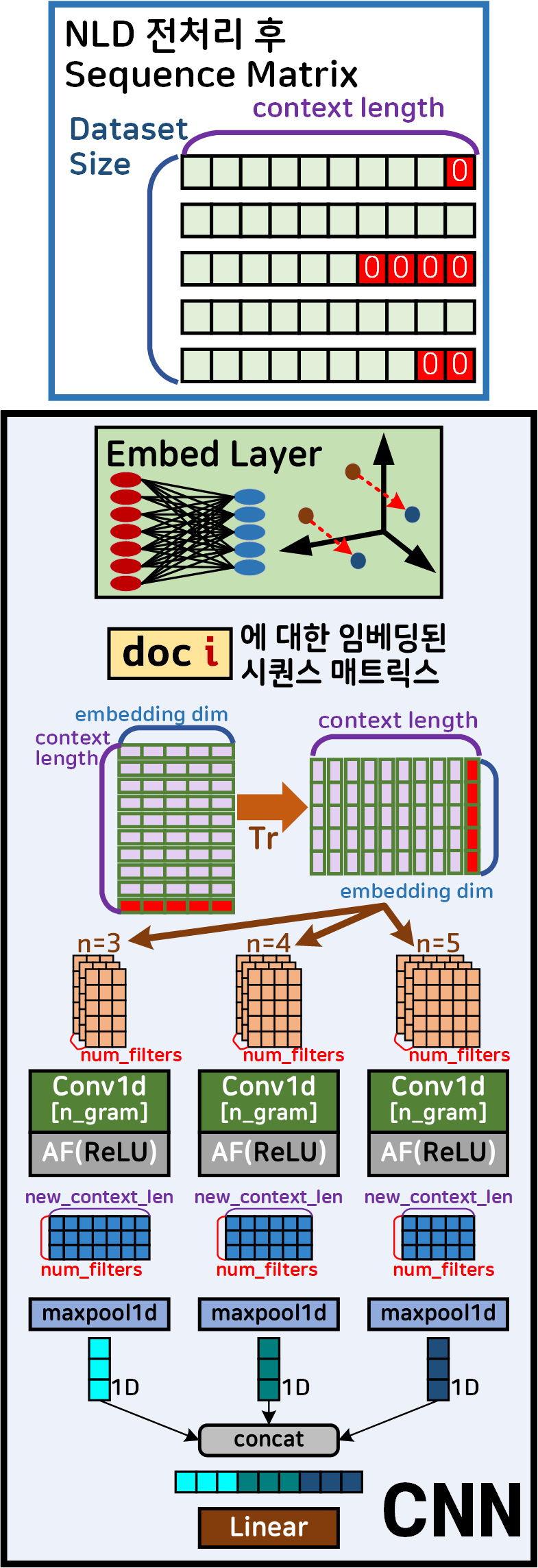
논문 Convolutional Neural Networks for Sentence Classification에서 제안하는
CNN을 언어모델로 활용하여 문장 분류를 수행하는 모델의 설계는 위 그림으로 도식화 할 수 있다.
순서를 살펴보면
1) 자연어 데이터셋(NLD)을 텍스트 전처리까지 수행하여
Sequnece matrix로 변환
2) Sequnece matrix를 Embedding layer를 통과시켜
(context_len, embdding_dim)의 밀집 벡터(Dense vector)로 축소한 뒤 이를 Transpose(전치)하여
Conv1d가 입력받는 데이터 형태인 (embdding_dim, context_len)로 변환
3) 다양한 n-gram 조건에 맞춰 Conv1d + ReLU를 통해
Output Feature 추출 : (num_filtes, New_Sequence_length)
4) 이후 New_Sequence_length를 MaxPool1d로 차원 축소 : (num_filtes)
-> 이때 각 항목의 차원은 batch_size를 제외하면 1D
5) 축소된 Feature를 Concat후 Classifier 수행
논문에서는 word2vec로 임베딩 메트릭스의
embdding_dim를 300, num_filtes(따지고 보면 hidden_dim)을 100을 적용했으나
필자는 FasText : embdding_dim = 100
num_filtes(hidden_dim) = 50
을 적용하여 실험을 수행한다
모델 구현 코드
import torch
import torch.nn as nn
class BasicConv(nn.Module):
def __init__(self, embed_dim, num_filters, n_gram):
super(BasicConv, self).__init__()
# 입력 Feature : (batch_size, embed_dim, seq_length)
self.conv = nn.Conv1d(in_channels=embed_dim,
out_channels=num_filters,
kernel_size=n_gram)
self.relu = nn.ReLU()
def forward(self, x):
x = self.conv(x)
x = self.relu(x)
# 출력 결과는 (batch_size, num_filters, new_seq_length)
return ximport torch.nn.functional as F
class CNNClassifier(nn.Module):
def __init__(self, vocab_size, embed_dim, num_classes,
filter_classes, num_filters, emb_matrix=None,
dropout=0.5):
super(CNNClassifier, self).__init__()
self.embed = nn.Embedding(vocab_size, embed_dim)
if emb_matrix is not None:
# 사전 훈련된 임베딩 매트릭스를 붙여넣음
self.embed.weight = nn.Parameter(
torch.tensor(emb_matrix, dtype=torch.float32))
# 붙여넣은 Pretrained 임베드 레이어만 Freeze하고 싶을때는 False
self.embed.weight.requires_grad = True
# conv의 Kernel_size(n_gram)은 다양한 길이로 적용됨
self.convs = nn.ModuleList([
BasicConv(embed_dim, num_filters, n_gram=fs)
for fs in filter_classes
])
# num_filters는 따지고 보면 hidden_dim이랑 같은값이다.
self.classifier = nn.Sequential(
nn.Dropout(dropout),
nn.Linear(len(filter_classes) * num_filters, num_classes)
)
def forward(self, x):
emb = self.embed(x) # (bs, seq_length, emb_dim)
# 임베딩레이어의 차원순서를 전치해준다.
tr_emb = emb.permute(0, 2, 1) # (bs, emb_dim, seq_length)
conv_outs = [conv(tr_emb) for conv in self.convs]
# 출력 결과가 (batch_size, num_filters, new_seq_length)인데
# new_seq_length가 n_gram을 다양한 길이로 적용하기에 길이가 동적임
# 이 동적인 new_seq_length를 항목별로 max_pool 해서 차원축소
pooled_outs = [F.max_pool1d(co, co.size(2)).squeeze(2) for co in conv_outs]
# co.size(2) -> new_seq_length 를 (1)로
# 그 이후 squeeze(2)를 통해서 (new_seq_length : 1)항목을 차원축소
# 따라서 각 maxpool 결과는 (bs, num_filters)로 이 결과물이 n-gram조건만큼 존재(리스트)
# 리스트형태의 pooled_outs를 concat
out = torch.cat(pooled_outs, 1)
# 결과는 (bs, num_filters * n_gram조건 종류(len(filter_classes)))
logits = self.classifier(out)
return logitsConv1d연산은 병렬로 수행하기에 nn.ModuleList메서드를 활용했으며, nn.Maxpool1d를 적용하고 싶었으나
Conv1d이 n_gram 조건에 따라서 동적으로 변화하는 Output Feature를 출력하기에 forward 함수에서
functional.maxpool1d메서드로 행렬축소
이후 squeeze로 차원축소를 진행한다.
2. CNN 문장분류 실습
모델 설계 원리 및 코드작성까지 완료했으니
실습을 진행하도록 하자
실습 데이터셋은 2. NLP-LSTM, GRU (2) : 텍스트 분류기에서 사용한
span_SNS.csv를 그대로 사용했으며
데이터 전처리 텍스트 전처리 과정은
이전 포스트에 코드를 다 업로드 했으니 생략한다.
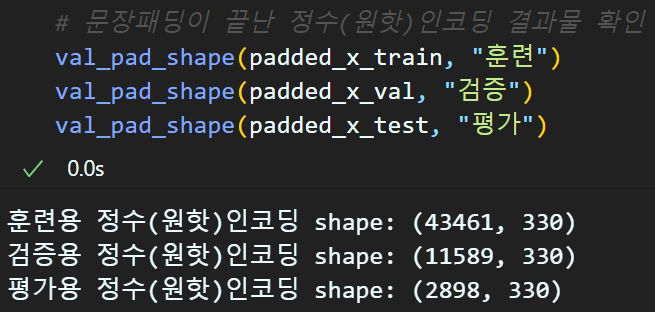
아무튼 문장패딩까지 완료한 전처리 결과물(Sequence matrix)는 위와 같다.
FasText 워드 임베딩 학습 수행
# Word2Vec 및 FastText 학습에 사용할 데이터:
# 원본 데이터셋의 토큰화 후 불용어 제거를 수행한 데이터터
# 에다가 단어 -> 자모 분리를 수행한 데이터
word2vec_doc = jamo_x_datafrom gensim.models import FastText
FT_model = FastText(
sentences=word2vec_doc,
vector_size = 100, # 임베딩 차원은 100으로 설정
window = 5, # 논문의 최대 관심가질 주변단어 사이즈인 5~20
min_count = rare_th, # (3) 단어장에서 배제할 희소단어 빈도 기준
workers= -1, # 학습에 참여할 프로세스 개수 (최대로 설정)
sg = 1, # Skip-gram 방식으로 학습 수행
# FastText의 N-gram 범위 설정(3~6)
min_n=3, max_n=6
)이렇게 FasText로 임베딩 레이어의 사전 훈련 파라미터를 학습시키고
# FastText 방식으로 학습된 임베딩 레이어 조정
my_FT_embedding = build_my_embed(word_to_idx, FT_model.wv)위 함수로 임베딩 레이어 파라미터를 조정한다.
build_my_embed 함수에 대한 설명은 이전 포스트
2. NLP-LSTM, GRU (2) : 텍스트 분류기를 참조하자
2.1 학습 및 분류 실행
먼저 주요 하이퍼 파라미터를 정리하고
# 학습 실험 조건을 구분하기 위한 키
cod_key = ['랜덤초기화', '사전훈련']
metrics_key = ['Loss', '정확도']
N_gram_sizes = [3, 4, 5] # 커널 사이즈는 3~5로 적용CNN_raninit = CNNClassifier(VOCAB_SIZE, EMB_DIM, NUM_CLASS,
N_gram_sizes, HIDE_DIM)
CNN_pre_emb = CNNClassifier(VOCAB_SIZE, EMB_DIM, NUM_CLASS,
N_gram_sizes, HIDE_DIM, my_FT_embedding)# GPU사용 가능 유/무 확인
device = torch.device("cuda" if torch.cuda.is_available() else 'cpu')
models = {}
models[cod_key[0]] = CNN_raninit.to(device)
models[cod_key[1]] = CNN_pre_emb.to(device)import torch.optim as optim
# 로스함수 및 옵티마이저 설계
criterion = nn.CrossEntropyLoss()
LR = 0.001 # 러닝레이트는 통일
optimizers = {}
optimizers[cod_key[0]] = optim.Adam(CNN_raninit.parameters(), lr=LR)
optimizers[cod_key[1]] = optim.Adam(CNN_pre_emb.parameters(), lr=LR)# 사전에 모듈화 한 학습/검증용 라이브러리 import
from C_ModelTrainer import ModelTrainer
num_epoch = 8 #총 훈련/검증 epoch값
ES = 2 # 디스플레이용 에포크 스텝
# BC_mode = True(이진), False(다중)
# aux = 보조분류기 유/무
# wandb = 완디비에 연결 안하면 None
# iter = 훈련시 iteration의 acc및 loss 정보 추출
trainer = ModelTrainer(epoch_step=ES, device=device,
BC_mode=False, aux=False, iter=False)# 학습/검증 정보 저장
history = {ck: {metric: []
for metric in metrics_key}
for ck in cod_key}모델 학습을 위한 여러가지 사전 설정 코드를 작성하자
모델 학습
#실험조건 : 모델 + 임베딩레이어 pretrain 유/무
for ck in cod_key:
# 모델 훈련/검증 코드
for epoch in range(num_epoch):
# 훈련모드의 손실&성과 지표
train_loss, train_acc = trainer.model_train(
models[ck], trainloader,
criterion, optimizers[ck], epoch)
# 검증모드의 손실&성과 지표
val_loss, val_acc = trainer.model_evaluate(
models[ck], valloader,
criterion, epoch)
# 손실 및 성과 지표를 history에 저장
history[ck]['Loss'].append((train_loss, val_loss))
history[ck]['정확도'].append((train_acc, val_acc))
# Epoch_step(ES)일 때마다 print수행
if (epoch+1) % ES == 0 or epoch == 0:
if epoch == 0:
print(f"현재 훈련중인 모델조건: [{[ck]}]")
print(f"epoch {epoch+1:03d}," + "\t" +
f"훈련 [Loss: {train_loss:.3f}, " +
f"Acc: {train_acc*100:.2f}%]")
print(f"epoch {epoch+1:03d}," + "\t" +
f"검증 [Loss: {val_loss:.3f}, " +
f"Acc: {val_acc*100:.2f}%]")
print(f"\n----모델조건[{[ck]}] 훈련 종료----\n")
성능 결과를 보면 알겠지만
둘 다 1 epoch에서 분류성능 100% 달성해서
그래프로 분석하는 의미가 없긴 하다.
LSTM, GRU랑 비교해도
학습 속도나 성능 면에서 더 뛰어난데
애초에 Convolutional Neural Networks for Sentence Classification논문에서도 언급했다 싶이
자연어처리 - 분류 항목에 대해서는 기존 언어모델 대비 성능이 꽤 잘나오는 모델이라고 소개가 되어 있기도 하다.
따라서 실무쪽에서 자연어 데이터셋이라도 분류작업이라면
CNN계열 모델을 적용을 하는데
이때 Conv1d의 사용방법이 개념을 잘 숙지하고 넘어가야 나중에 사용하는데 문제가 없고 또 다른 정리글을 보면
혼란을 야기하게끔 사용방법이 정리된 항목이 많아
이를 정리하기 위한 목적으로 작성되었다 보면 된다.
