
개요
본 블로그 포스팅은 수도권 ICT 이노베이션 스퀘어에서 진행하는 AI 핵심 기술 집중 클래스의 자연어처리(NLP) 강좌 내용을 필자가 다시 복기한 내용에 관한 것입니다.
1. 실습 개요
이전 포스트 NLP-LSTM, GRU (3) : 개체명 인식(NER : Named Entity Recognition)
의 실습 workflow를 하나의 도식으로 표현한다면 아래와 같다.
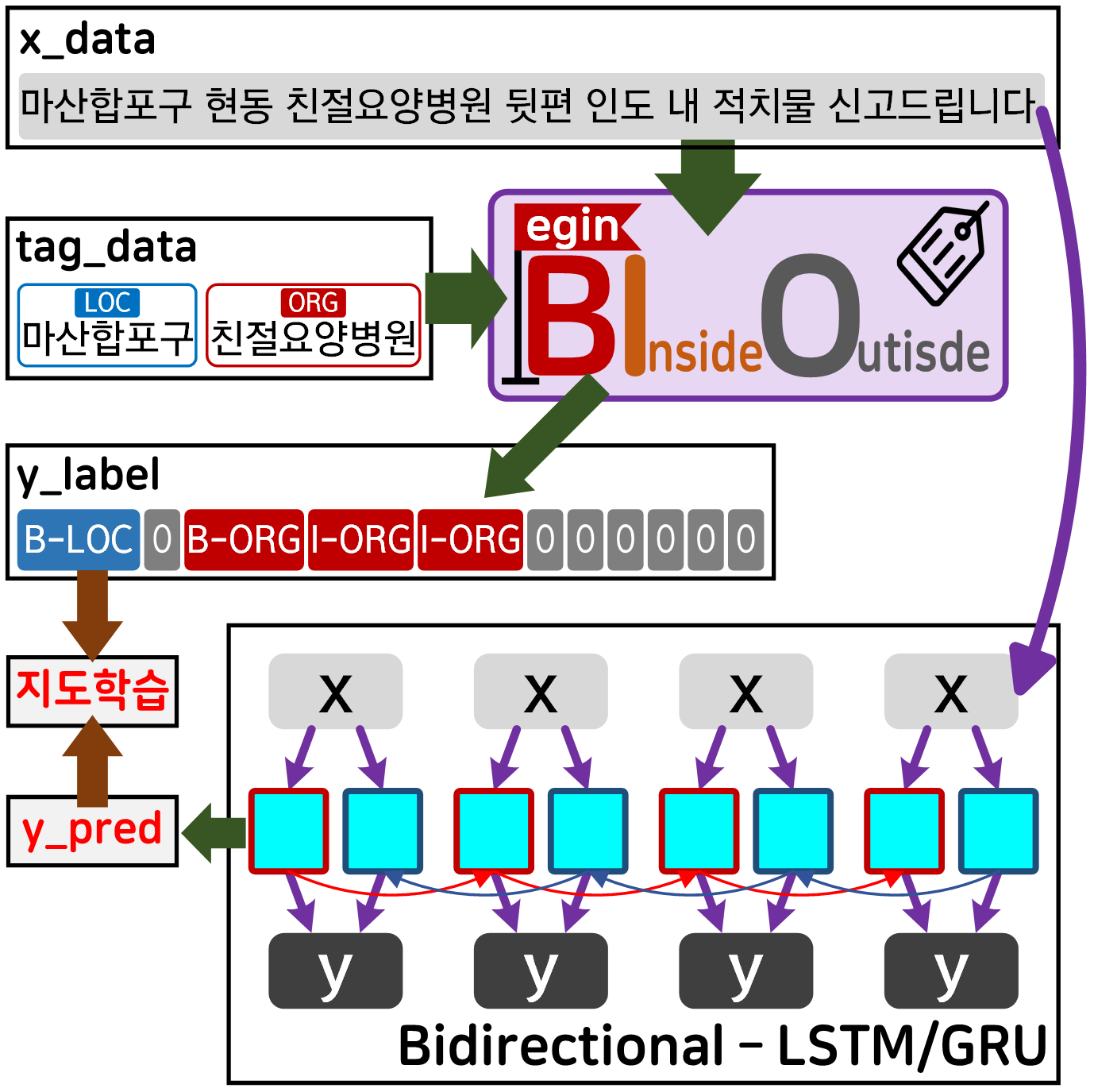
원문 데이터를 BIO Tagging을 통해서
정답지를 만들고
Bidirectinal - LSTM/GRU 언어모델로 학습기를 돌려서
태깅(tagging)작업의 자동화
이를 수행한 것이다.
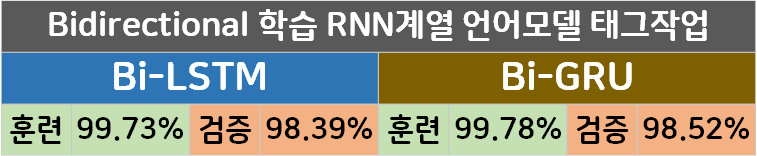
결과물을 보면 둘다 95% 이상의 높은 정확도를 보여주고는 있으나, 여기서 2~3% 정도 더 성능을 향상시킬 수 있는 방법이 하나 존재한다.

이는 Bi-LSTM/GRU에 CRF : Conditional Random Field 방법론을 결합하는 방법으로
CRF의 사용법은 아래의 라이브러리 설치 및 코드로 간단하게 적용이 가능하다.

!pip install TorchCRF #CRF 설치명령어
# CRF 라이브러리 사용방법
from TorchCRF import CRF포스팅에서는 CRF에 대한 개념 설명 + 코드화(로우 레벨 프로그래밍)
그 이후 코드화한 CRF를 기존 Bi-LSTM/GRU에 추가하여
학습/검증/평가를 어떻게 수행하고 결과물이 얼마나 향상되는지를 확인하려 한다.
그러나 포스트에서는 개념 설명만 진행하고
코드화(로우 레벨 프로그래밍)는 skip하도록 한다.
음.. 이게 Pytorch-crf 라이브러리랑 동일하게 작동하도록 코드짜는게 시간을 많이 잡아먹는다..
그리고 개념 설명하는 것도 잘 할수 있을지... 자신이 없고 어차피 코드구현을 해봤자 CRF를 이번 포스트 이후 다시 만날지는 미지수이다.

1.1 BIO Tagging 방법론과 CRF
CRF를 적용하는 이유에 대해 알려면 먼저 BIO Tagging 방법론을 다시 복습해야 한다.
BIO Tagging 방법론은.. 요약을 하자면 Rule : 규칙이다

즉, 위 BIO Tagging 방법론을 준수하지 않으면 태깅(tagging)자체가 의미가 없는 행동이 된다.

따라서 BIO Tagging 방법론의 규칙을 준수하지 않는
모델의 출력값(: output)는 필터를 통해 걸러내는 것이 가능하다.
그렇다면 모델의 학습과정에 BIO Tagging rule을
Rule-Based Learning 방법론을 통해 성능을 향상시키는 것이 가능하다.
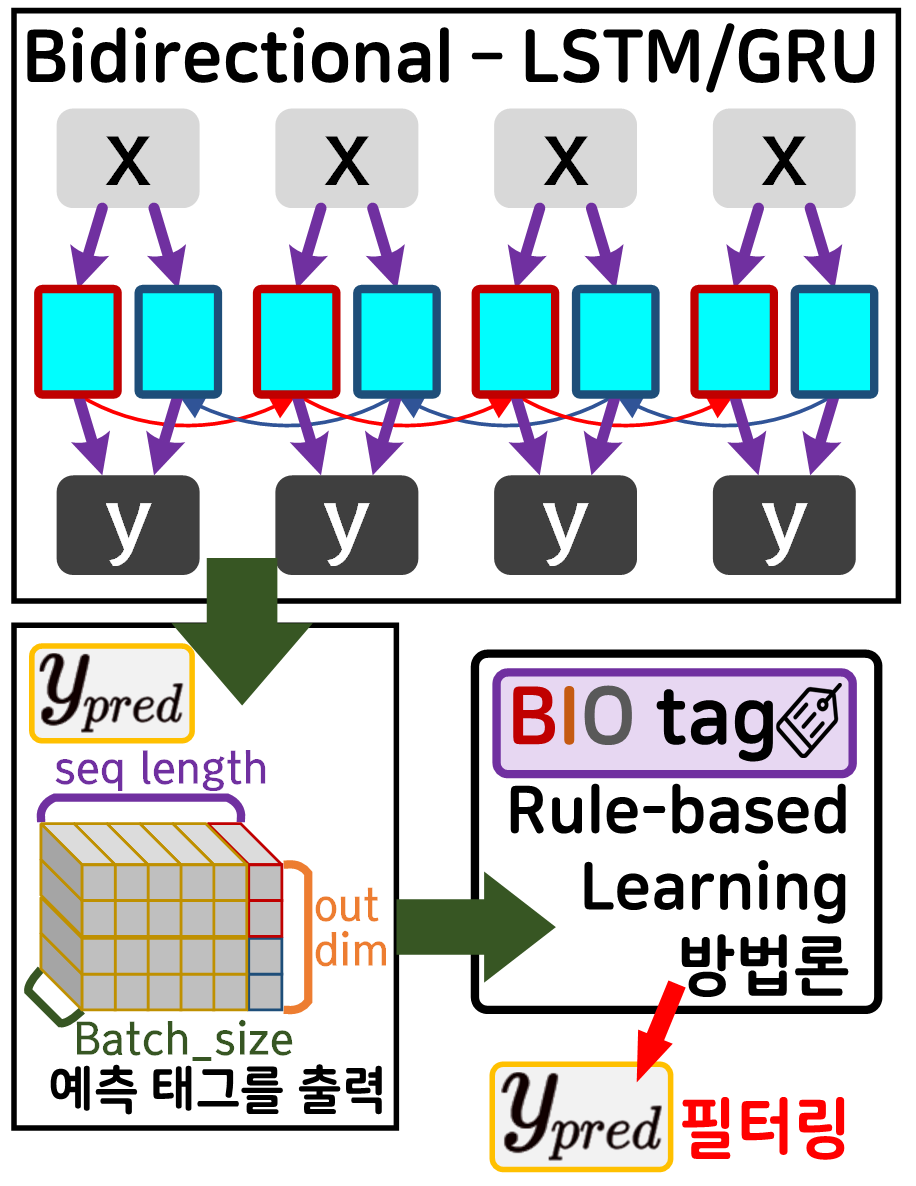
대략 Rule-Based Learning 방법론을 사용하여 성능 개선을 수행한다면 위 도식과 같아지며
Rule-Based Learning 방법론의 Rule : BIO Tagging이 되는 것이다.
그렇다면 이 Rule-Based Learning 방법론을 쓰면 되는걸
왜 알아먹기 힘들게 CRF : Conditional Random Field를 공부를 해야 하는가?
말이 거창해서 그렇지 Rule-Based Learning 방법론는 사실 if, for, case, while 구문을 섞어섞어 만드는 코드이다.
따라서 조건이 추가되고 복잡해지면 그만큼 if조건이 추가되는 것고 결국

위 사진처럼 arrow code가 될 가능성이 높아진다.
좀더 정확하게 표현하자면
확장성, 일반화에 성능이 떨어지고
유지보수는 어려우며, 조건이 복잡할수록 효율이 떨어지는 문제가 있다.
물론 거의 대다수의 문제를 풀이하는건 Rule-Based Learning 방법론이다 (NLP 전처리과정에서 상당한 부분이 Rule-Based로 처리된다.)
그러나 Bidirectinal - LSTM/GRU 가 NER에서 주 모델로 사용되는 조건임을 간안하여
좀더 효율적인 학습 방법론 도입이 가능,
이 방법론이 Data-driven learning이다.
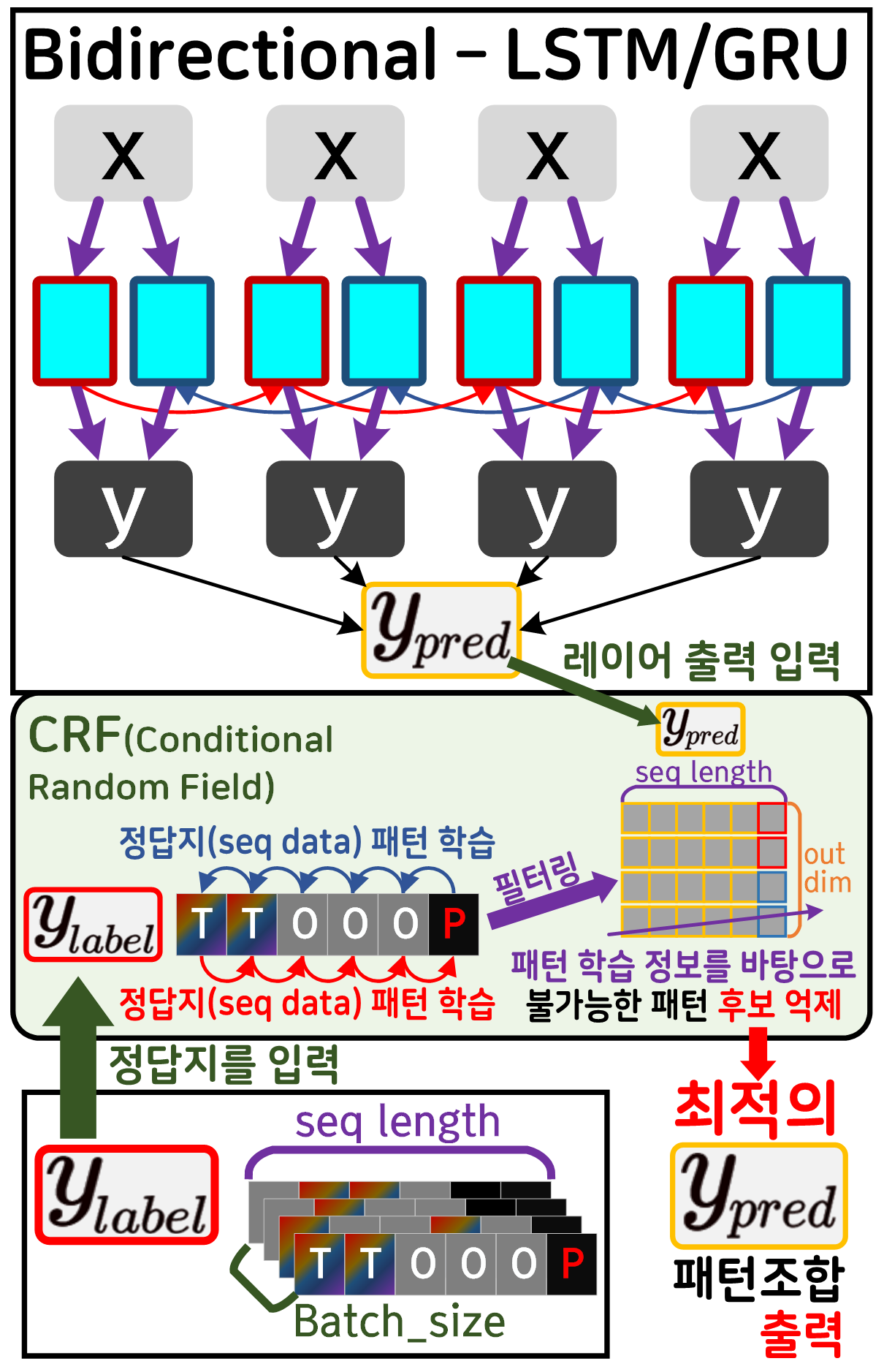
CRF가 포함된 Bidirectinal - LSTM/GRU 모델의 도식은 위 사진과 같으며 과정과 조건을 설명하고자 한다.
1) 정답지()는 전제조건으로 BIO Tagging 방법론을 온전히 준수하는 Sequence Date이다.
즉, 정답지()는 BIO TaggingRule을 모두 포함하고 있다.
2) 이를 CRF가 학습하면 BIO Tagging의 원리는 모르지만
어떤 패턴은 가능한 패턴이고
어떤 패턴은 불가능한 패턴임은 알 수 있다.
마치 수학공식은 모르지만 답안지를 계속 외우다 보면
수학 문제를 찍어서 풀 수 있는 상태가 되는 것이다.
3) 위 학습된 정보를 바탕으로 예측치, 레이어 출력정보()로 조합 가능한 태깅 패턴 조합(tagging sequence data)를
만들어 낼 수 있는데 그 중 학습된 패턴정보로는
절대로 불가능한 패턴조합이 발생할 것이다.
4) 이렇게 불가능한 패턴 정보를 소거해 나가면
최적의 패턴조합을 생성할 수 있다
이것이 CRF를 도입하여 얻는 최적의 패턴조합이다.
1.3 CRF 수식 정리
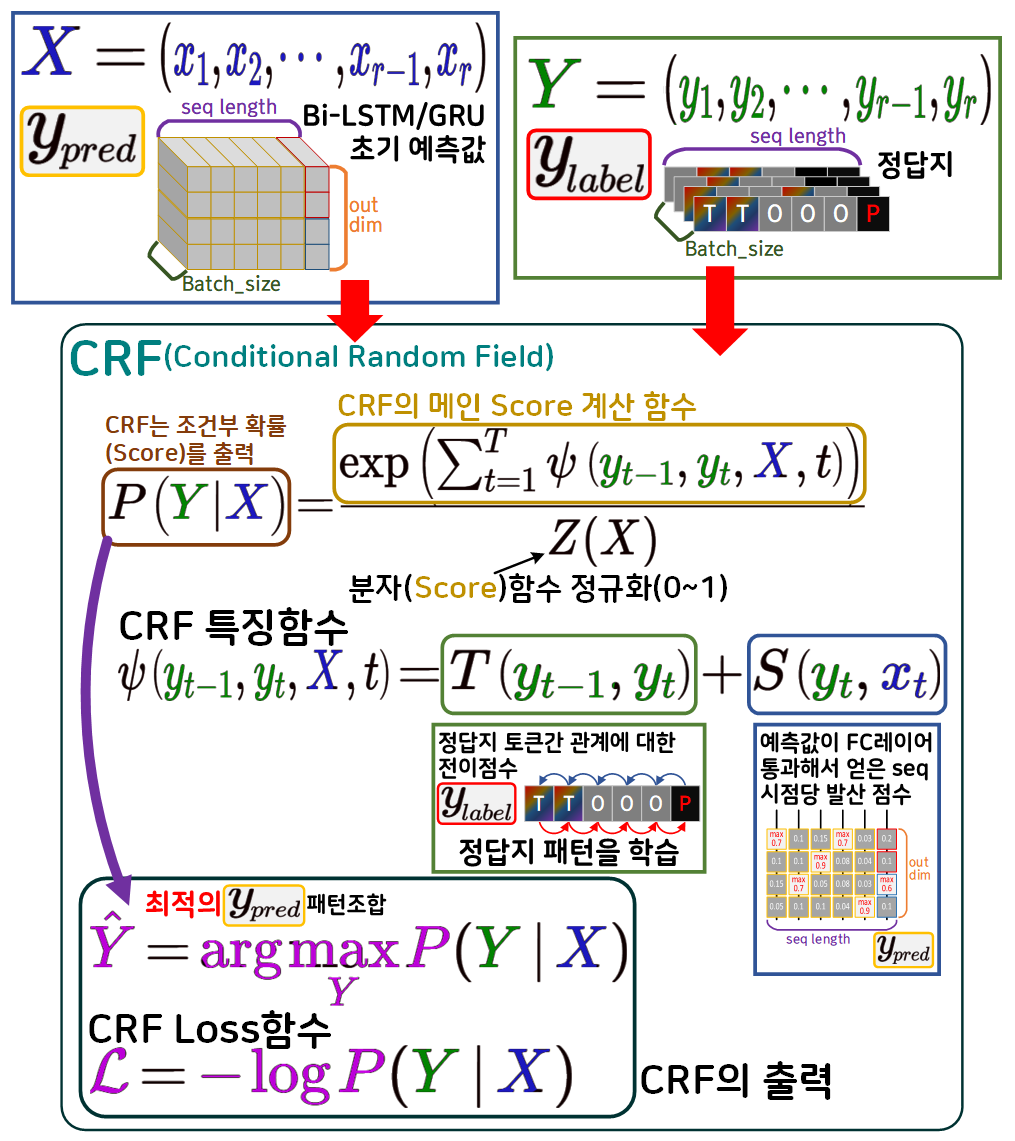
CRF는 머신러닝 계열의 확률 그래픽 모델(조건부 모델)에 속하며
수식을 정리하면
1) 정답지의 패턴간 관계를 학습(점수)화 하는 전이함수
2) 예측값(모델출력)를 발산점수로 활용
두가지 값을 바탕으로 조건부 확률을 계산해
두개의 출력
최적의 패턴조합, CRF Loss 점수
두가지 결과를 출력한다.
2. TorchCRF 코드화
https://pytorch-crf.readthedocs.io/en/stable/
위 홈페이지에 접속하면 지금까지 열심히 설명한
CRF를 진철하게 코드로 구현 + 라이브러리로 배포하고 있다.
물론 배포되는 코드를 그대로 갖다 쓰는것도 살작 머리가 아파오는건 피할 수 없다.

먼저 torch.CRF를 살펴보면 CRF 클래스인 것을 확인할 수 있다.
따라서 해당 클래스를 레이어처럼 기존 Bidirectinal - LSTM/GRU의 가장 마지막 레이어 뒤에 쌓아주기만 하면 된다.
여기서 입력받는 값이 2개인데 중요한 것은 num_tags이다.
이건 Bidirectinal - LSTM/GRU의 Classifier 층을 통과한 최종 출력물인 를 입력받는 것이다.

다음으로 CRF.forwad를 수행할 때 인자값/결과값이 어떻게 나오는지에 대한 문서이다.
CRF 클래스는 기본출력이 loss연산 결과이며
음수로 출력되게 수식이 구성되어 있으니
통상적으로 사용할때는 음수를 다시 -를 붙여서 양수로 반전시켜줘야 한다.
입력 인자값은 정답지 , 정답지에 예측할 필요가 없는 태그를 필터링 하기 위한 mask 두가지가 필요하다

다음으로 CRF.decode는 CRF를 통해 최적화한 패턴조합을 출력하나
데이터 타입이 2중 리스트이다.
마스크가 적용된 태그 토큰은 아에 날려버리게끔 출력값이 나오고 있으니
이를 주의해서 사용해야 한다.
2.1 CRF를 포함한 Bi-LSTM/GRU 설계
코드는 길지만 코드보다 포스트 설명을 위해 주석을 더 많이 달았음을 감안하고 보자
import torch.nn as nn
class NERTagger_BiLSTM_CRF(nn.Module):
def __init__(self, vocab_size, embed_dim, tag_dim,
hid_dim, num_layers, emb_matirx=None):
super(NERTagger_BiLSTM_CRF, self).__init__()
self.embed = nn.Embedding(vocab_size, embed_dim)
# 사전훈련 임베딩 사용 유/무 함수
if emb_matirx is not None:
self.embed.weight = nn.Parameter(
torch.tensor(emb_matirx, dtype=torch.float32))
self.embed.weight.requires_grad = True
self.lstm = nn.LSTM(input_size=embed_dim, # LSTM에 입력차원
hidden_size=hid_dim, # LSTM의 출력차원
num_layers=num_layers, # 내부 Cell 몇층?
bidirectional=True, #양방향 학습 옵션 On
batch_first=True) # 입력텐서 -> batch가 맨처음
# 최종적으로 tag 종류를 맟추는 FC layer
# 양방향 연산이기에 FC_layer에 입력되는 feature는 2배로 늘어난다
self.classifier = nn.Sequential(
nn.Linear(hid_dim*2, tag_dim),
)
# CRF 레이어 추가, 입력은 classifier 통과 결과물을 받아야 함
self.crf = CRF(tag_dim, batch_first=True)
def forward(self, x, tags=None, mask=None):
# 입력 x : batch_size, seq_length
emb = self.embed(x) # (batch_size, seq_length, embedding_dim)
# 양방향 학습 On이기에
# lstm_out : (bs, seq_len, hidden_dim * 2)
# hidden = (num_layer * 2, bs, hidden_dim)
lstm_out, (hidden, cell) = self.lstm(emb)
# many-to-many 방식이니까 lstm_out을 사용한다.
logits = self.classifier(lstm_out)
# logits 출력 : (bs, seq_len, tag_dim)
# CRF는 훈련모드/평가모드로 나눠서 출력을 달리하자
# 평가모드 작성이 더 쉬우니 평가, 훈련모드 순으로 작성한다
if tags is None : # y_label이 없는 '평가 모드'
# CRF의 최적화한 예측값은 2중 리스트 이며
# [[마스크 적용된 가변 seq], [마스크 적용된 가변 seq]] 형태
optim_pred = self.crf.decode(logits, mask=mask)
# 참고로 mask는 Tensor자료형에 Tag = 1, Pad=0 으로
# 처리된 데이터임을 명심하자
return optim_pred
else: #y_label이 존재하는 '훈련 모드'
# CRF의 출력은 Loss가 기본출력이고
# decode 메서드를 써야 CRF로 최적화한 y_pred를 출력한다.
crf_loss = -self.crf(logits, tags, mask=mask)
# 통상적인 로스함수처럼 스칼라값이 출력된다.
optim_pred = self.crf.decode(logits, mask=mask)
# optim_pred 가 이중 리스트 형식이기에 텐서 자료형으로 변환
# 변환되는 형태는 'logits'과 동일하게 변경되게 하며
# 이때 (bs, seq_len, tag_dim=1) 이 된다.
bs, seq_len, _ = logits.size() # 먼저 logit 차원 정보 추출
# 먼저 tensor 자료형을 logis의 구조와 타입과 동일하게 초기화
optim_logits = torch.zeros(bs, seq_len, 1,
dtype=logits.dtype,
device=logits.device)
# 이중리스트 형식의 optim_pred를 추출해
# 텐서 자료형인 optim_logits로 전달
for i, seq in enumerate(optim_pred):
optim_logits[i, :len(seq), 0] = torch.tensor(seq,
dtype=logits.dtype,
device=logits.device)
# 최적화된 CRF_y_pred는 텐서 자료형 (bs, seq_len, 1)
return optim_logits, crf_lossimport torch.nn as nn
class NERTagger_BiGRU_CRF(nn.Module):
def __init__(self, vocab_size, embed_dim, tag_dim,
hid_dim, num_layers, emb_matirx=None):
super(NERTagger_BiGRU_CRF, self).__init__()
self.embed = nn.Embedding(vocab_size, embed_dim)
# 사전훈련 임베딩 사용 유/무 함수
if emb_matirx is not None:
self.embed.weight = nn.Parameter(
torch.tensor(emb_matirx, dtype=torch.float32))
self.embed.weight.requires_grad = True
self.gru = nn.GRU(input_size=embed_dim, # GRU에 입력차원
hidden_size=hid_dim, # GRU의 출력차원
num_layers=num_layers, # 내부 Cell 몇층?
bidirectional=True, #양방향 학습 옵션 On
batch_first=True) # 입력텐서 -> batch가 맨처음
# 최종적으로 tag 종류를 맟추는 FC layer
# 양방향 연산이기에 FC_layer에 입력되는 feature는 2배로 늘어난다
self.classifier = nn.Sequential(
nn.Linear(hid_dim*2, tag_dim),
)
# CRF 레이어 추가, 입력은 classifier 통과 결과물을 받아야 함
self.crf = CRF(tag_dim, batch_first=True)
def forward(self, x, tags=None, mask=None):
# 입력 x : batch_size, seq_length
emb = self.embed(x) # (batch_size, seq_length, embedding_dim)
# 양방향 학습 On이기에
# gru_out : (bs, seq_len, hidden_dim * 2)
# hidden = (num_layer * 2, bs, hidden_dim)
gru_out, hidden = self.gru(emb)
# many-to-many 방식이니까 gru_out을 사용한다.
logits = self.classifier(gru_out)
# logits 출력 : (bs, seq_len, tag_dim)
# CRF는 훈련모드/평가모드로 나눠서 출력을 달리하자
# 평가모드 작성이 더 쉬우니 평가, 훈련모드 순으로 작성한다
if tags is None : # y_label이 없는 '평가 모드'
# CRF의 최적화한 예측값은 2중 리스트 이며
# [[마스크 적용된 가변 seq], [마스크 적용된 가변 seq]] 형태
optim_pred = self.crf.decode(logits, mask=mask)
# 참고로 mask는 Tensor자료형에 Tag = 1, Pad=0 으로
# 처리된 데이터임을 명심하자
return optim_pred
else: #y_label이 존재하는 '훈련 모드'
# CRF의 출력은 Loss가 기본출력이고
# decode 메서드를 써야 CRF로 최적화한 y_pred를 출력한다.
crf_loss = -self.crf(logits, tags, mask=mask)
# 통상적인 로스함수처럼 스칼라값이 출력된다.
optim_pred = self.crf.decode(logits, mask=mask)
# optim_pred 가 이중 리스트 형식이기에 텐서 자료형으로 변환
# 변환되는 형태는 'logits'과 동일하게 변경되게 하며
# 이때 (bs, seq_len, tag_dim=1) 이 된다.
bs, seq_len, _ = logits.size() # 먼저 logit 차원 정보 추출
# 먼저 tensor 자료형을 logis의 구조와 타입과 동일하게 초기화
optim_logits = torch.zeros(bs, seq_len, 1,
dtype=logits.dtype,
device=logits.device)
# 이중리스트 형식의 optim_pred를 추출해
# 텐서 자료형인 optim_logits로 전달
for i, seq in enumerate(optim_pred):
optim_logits[i, :len(seq), 0] = torch.tensor(seq,
dtype=logits.dtype,
device=logits.device)
# 최적화된 CRF_y_pred는 텐서 자료형 (bs, seq_len, 1)
return optim_logits, crf_loss주요 변경사항이

생성자 부분에서 CRF클래스의 초기화 하는 부분
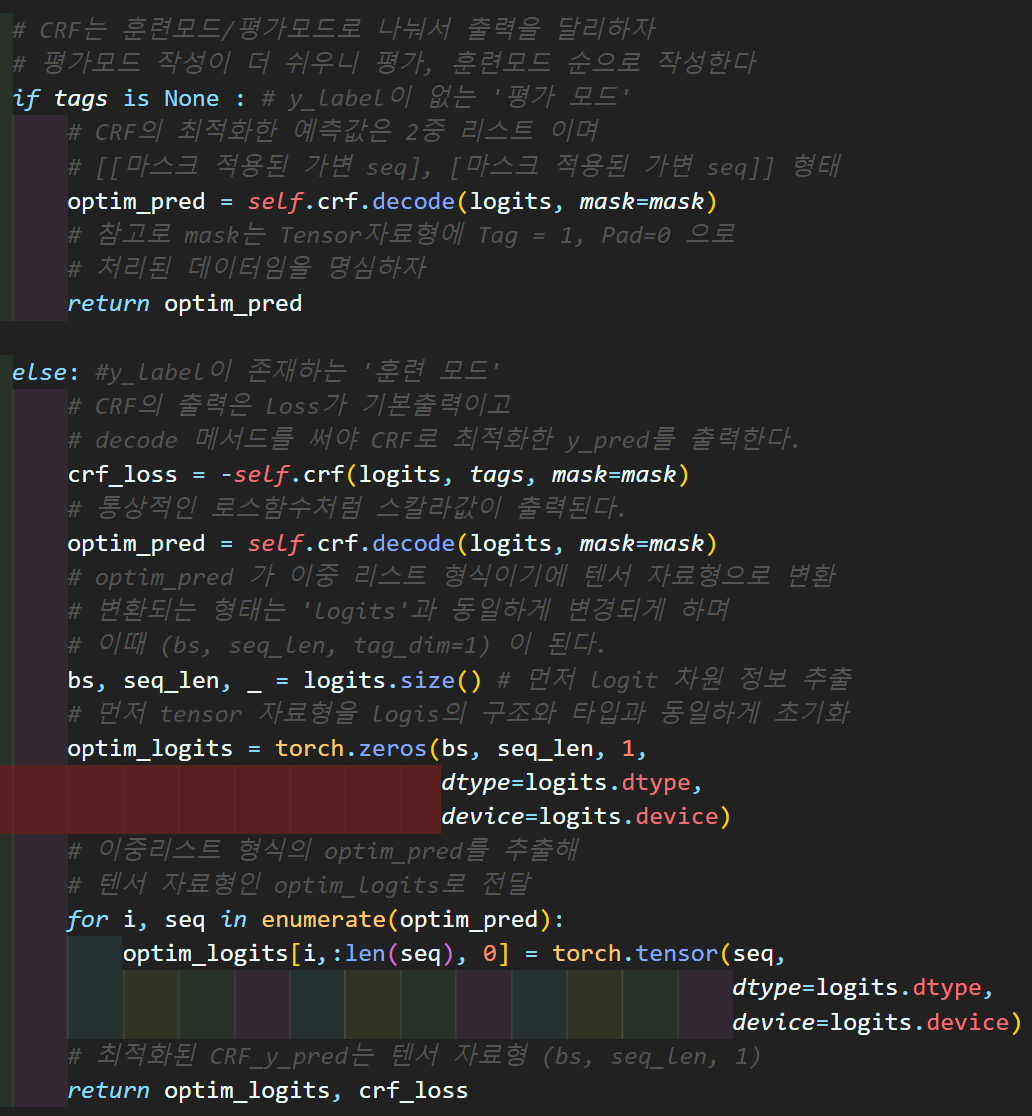
CRF 클래스가 이 존재하는 훈련 모드시의 출력과
이 없는 평가 모드시의 출력
각각의 경우별 retrun이 달라지게끔 설계한 부분이다.
이때 훈련 모드에서는
최종 출력이 최적화한 패턴조합, CRF Loss 점수 두개를 다 출력하는데
최적화한 패턴조합는 기존의 Bidirectinal - LSTM/GRU 최종 출력값인 logits와 동일한 자료형, 차원구조를 갖게끔
형변환이 이뤄지게 코드를 설계했다.
3. 코드 실습
역시 NER 태그 실습을 진행하고
https://www.aihub.or.kr/ AI Hub에서 제공하는
민원 업무화 인공지능 언어 데이터를 사용한다.
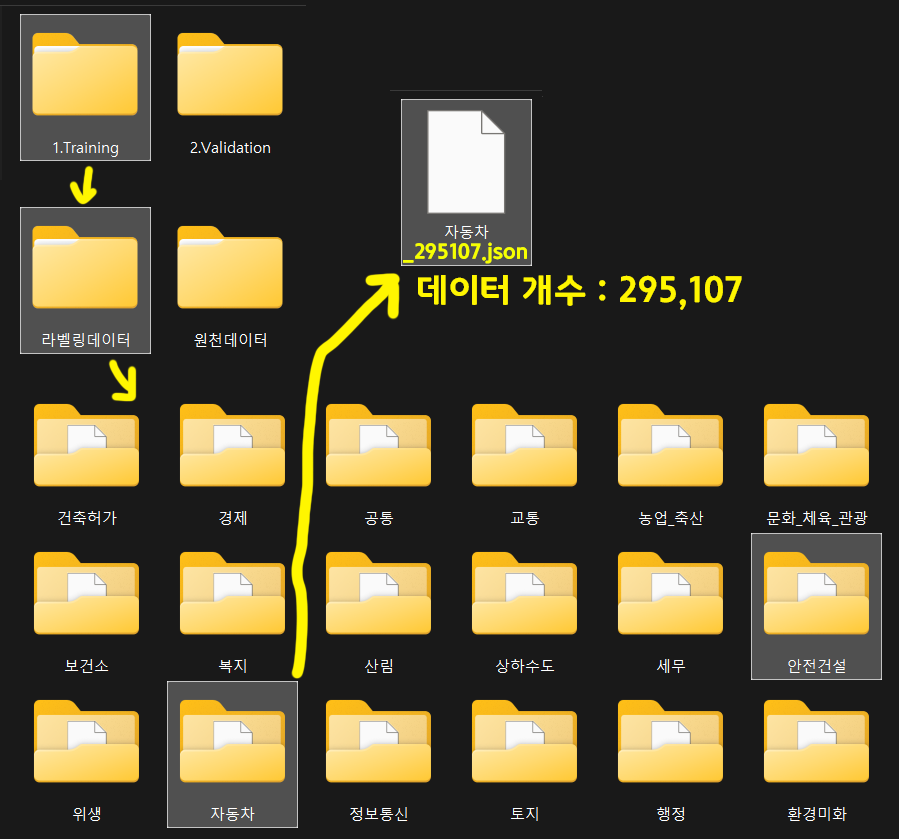
여러개의 카테고리 항목 중 이전 포스트 NLP-LSTM, GRU (3) : 개체명 인식(NER : Named Entity Recognition)에서 사용한 데이터보다는 좀 더 많은 양이 포함된 데이터를 사용하고자 한다.
3.0 NLP 전처리
데이터 전처리
import json
file_path = './1.Training/라벨링데이터/자동차/자동차_295107.json'
#json파일 불러오기
with open(file_path, 'r', encoding='utf-8') as f:
data = json.load(f)
parsed_data =[] # 파싱 데이터를 저장할 변수
for docu in data['documents']:
# 문서 내 id, Q_refined 추출
doc_id = docu['id']
q_refiled = docu['Q_refined']
# endity는 여러개 존재하니 [개채명 : 개체 분류] 형식으로 파싱
entities = [[eneity['form'], eneity['label']]
for eneity in docu["labeling"]["entities"]]
# 현재 document의 정보를 딕셔너리에 담고, 리스트에 추가
raw_dict = {
"문서ID": doc_id,
"컨텐츠": q_refiled,
"개체": entities
}
parsed_data.append(raw_dict)import pandas as pd
# 파싱이 완료된 데이터를 Dataframe 형식으로 변환
raw_data = pd.DataFrame(parsed_data)
display(raw_data)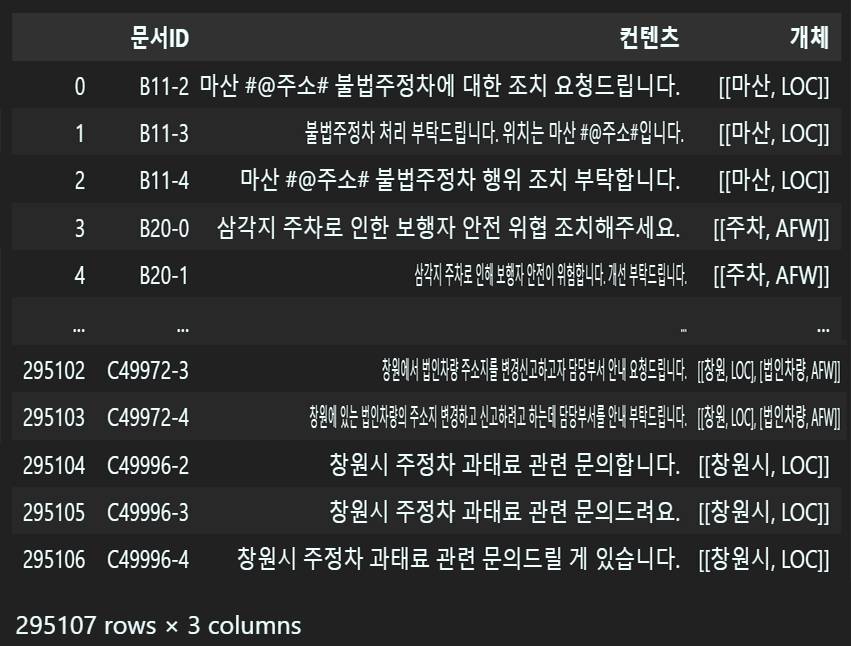
다음으로 결측치&중복치 제거 및 데이터 클리닝 작업을 이전 포스트와 동일하게 수행한다.
# 데이터 및 텍스트 전처리 함수를 모듈화 시킨 파일
from NLP_pp import *# 데이터셋읜 결측치 & 중복치 제거 함수 실행
raw_data = df_cleaning(raw_data, '컨텐츠')import re
# 한글, 영어(소문자, 대문자), 숫자
p1 = re.compile(r'[^가-힣a-zA-Z0-9\s]')
# 개행문자 + 하나 이상의 공백문자
p2 = re.compile(r'\n|\s+')
# 영어 대문자만 있는 경우를 감지하는 정규표현식 패턴
p999 = re.compile(r'^[A-Z]+$')
def regex_sub(origin_sent):
clean_text = p1.sub(repl=" ", string=origin_sent)
clean_text = p2.sub(" ", clean_text)
return clean_text
# [개체:태그]데이터는 리스트 형식이라서 위 함수를 콜백으로 사용함
def list_regex_sub(origin_list):
return [[regex_sub(entity), label] for entity, label in origin_list]
# 태그 항목을 클리닝하는 함수
def clean_tags(entity_list):
# 각 [개체명, 태그] 쌍을 검사하여 태그가 영어 대문자 외 단어가 포함된 경우
# 이 태그는 오염된 태그이니 [개체명, 오염된 태그] 리스트 자체를 제거
cleaned_list = [[entity, tag] for entity, tag in entity_list if p999.match(tag)]
return cleaned_list# 설계한 정규표현식기반 특수문자 삭제 함수 적용
# apply함수는 inplace=True(덮어쓰기) 기능이 없음
raw_data['컨텐츠'] = raw_data['컨텐츠'].apply(regex_sub)
raw_data['개체'] = raw_data['개체'].apply(list_regex_sub)
# 태그 항목에서 오염된 태그 항목을 제거하는 함수 구동
raw_data['개체'] = raw_data['개체'].apply(clean_tags)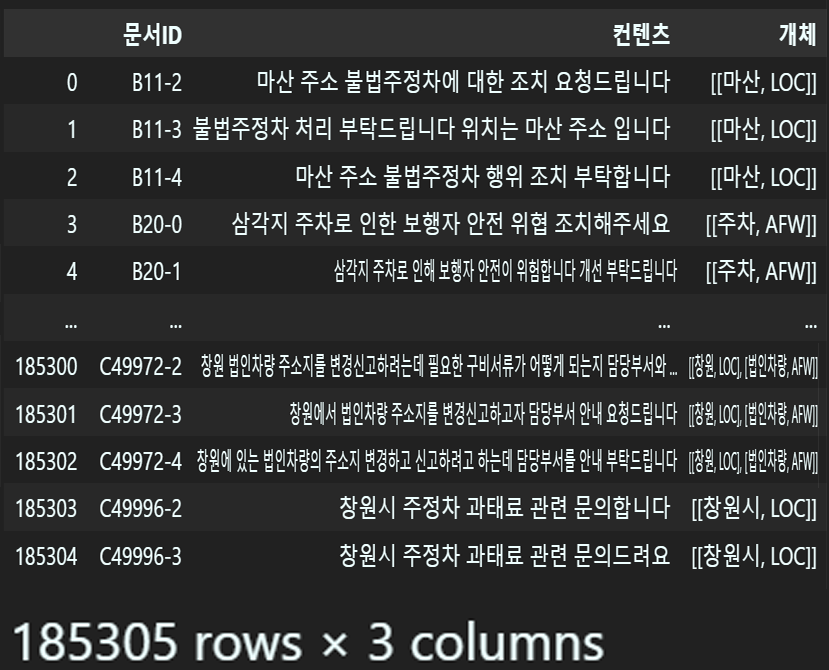
음.. 데이터가 29만개여서 괜찮을 줄 알았더니만
결측치가 10만개 가까이 일줄은 몰랏는데...
텍스트 전처리
# 데이터프레임의 항목을 분리 후 리스트 타입으로 변경
raw_x_data = raw_data['컨텐츠'].values.tolist()
# 개체 : 개체 라벨링 의 태그 정보는 따로 추출한다.
tag_data = raw_data['개체'].values.tolist()from mecab import MeCab #한글 단어 토크나이저
from tqdm import tqdm
#mecab 형태소 분석기 인스턴스화
word_tokenizer = MeCab()# 토큰화 수행
tokenized_x_data = tokenize(raw_x_data, word_tokenizer)
# BIO 태깅 방법론으로 태깅처리된 y데이터와 태깅 검증을 위한 데이터(token_tag) 두개 반환
tagged_y_label, token_tag_data = BIO_tagging(tokenized_x_data, tag_data, word_tokenizer)

다음으로 데이터 분할은 이전 포스트와 동일하게
훈련 : 80%, 검증 : 15%, 평가 : 5%로 분할한다.
from sklearn.model_selection import train_test_split
# 훈련/검증/평가를 80%, 15%, 5%로 분할을 수행
# random_state -> 데이터셋을 내누는데 '재현성' 유지를 위해 넣음 -> 안넣어도 됨
# stratify -> y 클래스 비율을 알기 어렵기에 해당 항목은 없앰
x_train, x_etc, y_train, y_etc = train_test_split(
tokenized_x_data, tagged_y_label, test_size=0.20
)
# 그 외 데이터셋을 반반으로 Val, Test로 나눔
x_val, x_test, y_val, y_test = train_test_split(
x_etc, y_etc, test_size=0.25
)
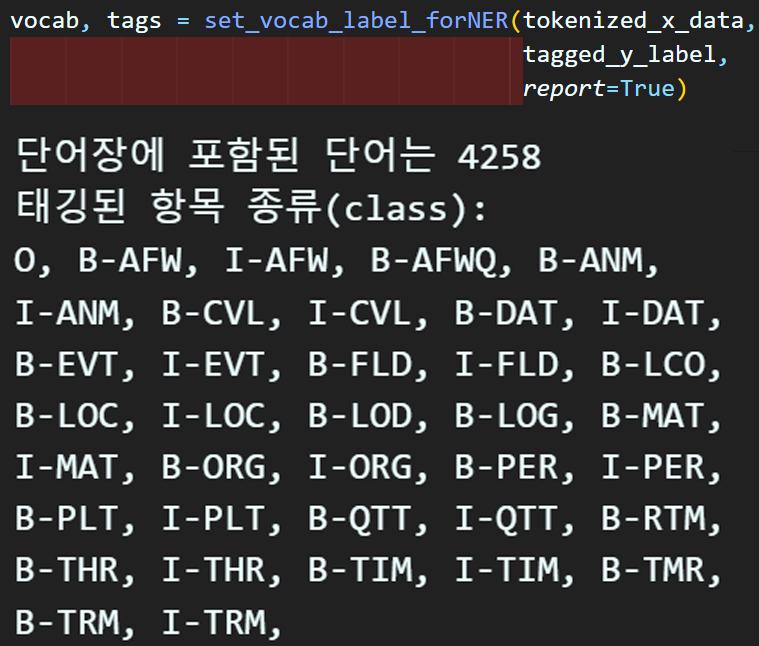
전체 데이터의 태깅 종류 및 총 단어 개수를 가늠했으니
훈련, 검증 데이터만을 사용하여 단어장생성을 수행하자
# 훈련/검증 데이터셋만 단어장 생성 및 클래스 종류 식별에 사용
vocab_1, tag_1 = set_vocab_label_forNER(x_train, y_train)
vocab_2, tag_2 = set_vocab_label_forNER(x_val, y_val)
vocab = list(set(vocab_1 + vocab_2))
tags = list(set(tag_1 + tag_2))
# 훈련 검증 데이터셋만 포함시킨 단어장
print(f"단어장에 포함된 단어는 : {len(vocab)}")
# 태깅된 항목 종류 출력
s_tags = sort_tags([tags])
print(s_tags)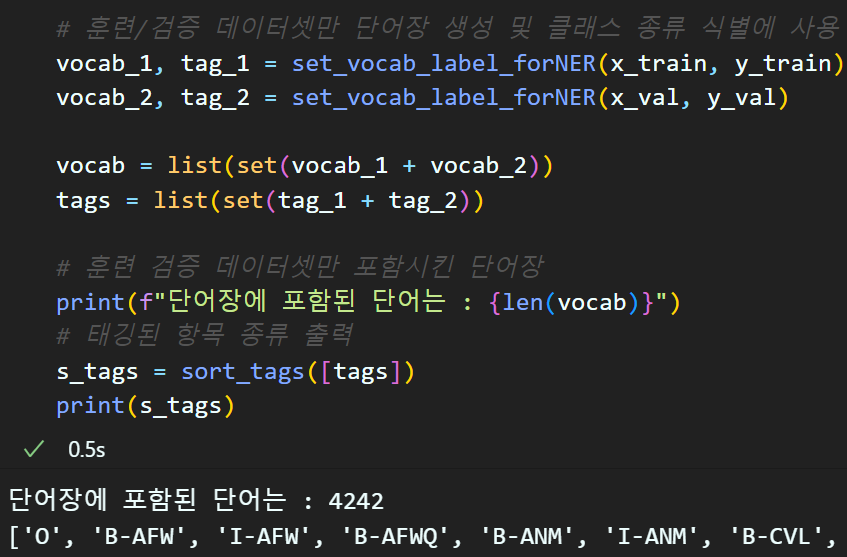
spec_x_token = ['<PAD>', '<UNK>'] # 스페셜 토큰(x)용 선언
spec_y_tag = ['<PAD>'] # 스페셜 태깅토큰(y) 선언
word_to_idx, idx_to_word = set_word_to_idx(spec_x_token, vocab,
report=True)
print()
tag_to_idx, idx_to_tag = set_word_to_idx(spec_y_tag, s_tags,
report=True,
content='태그')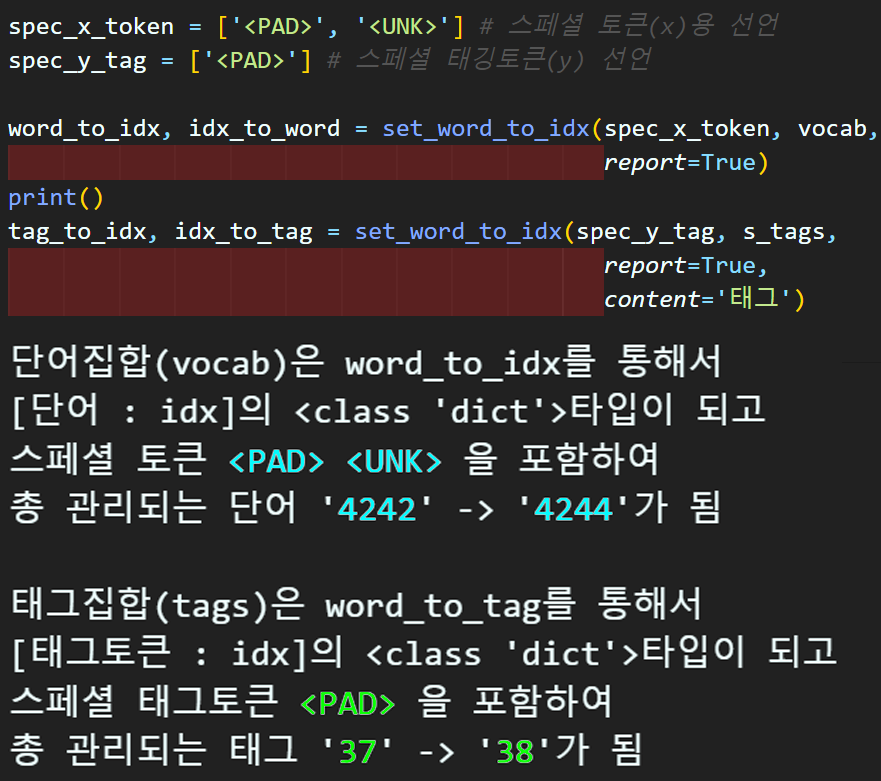
단어장 생성에 대한 인덱싱을 완료했으니
이제 정수인코딩을 수행하자
# x_data(원문)의 정수 인코딩 수행
e_x_train = text_to_sequences(x_train, word_to_idx)
e_x_val = text_to_sequences(x_val, word_to_idx)
e_x_test = text_to_sequences(x_test, word_to_idx)
# y_label(태그)의 정수 인코딩 수행
e_y_train = text_to_sequences(y_train, tag_to_idx, spec_token='O')
e_y_val = text_to_sequences(y_val, tag_to_idx, spec_token='O')
e_y_test = text_to_sequences(y_test, tag_to_idx, spec_token='O')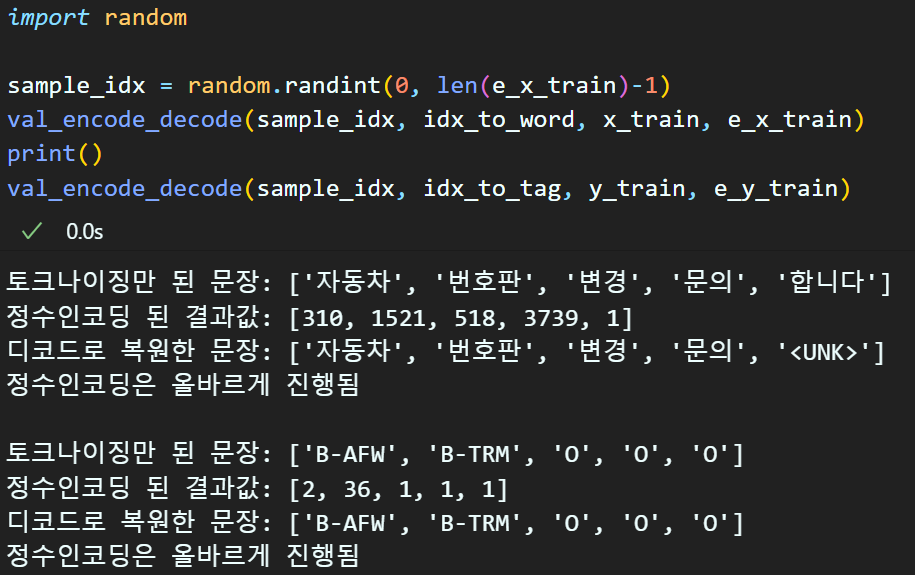
# 문서 당 시퀀스 길이를 정하는 하이퍼 파라미터
context_length = 40
set_sent_pad(e_x_train, context_length, report=True)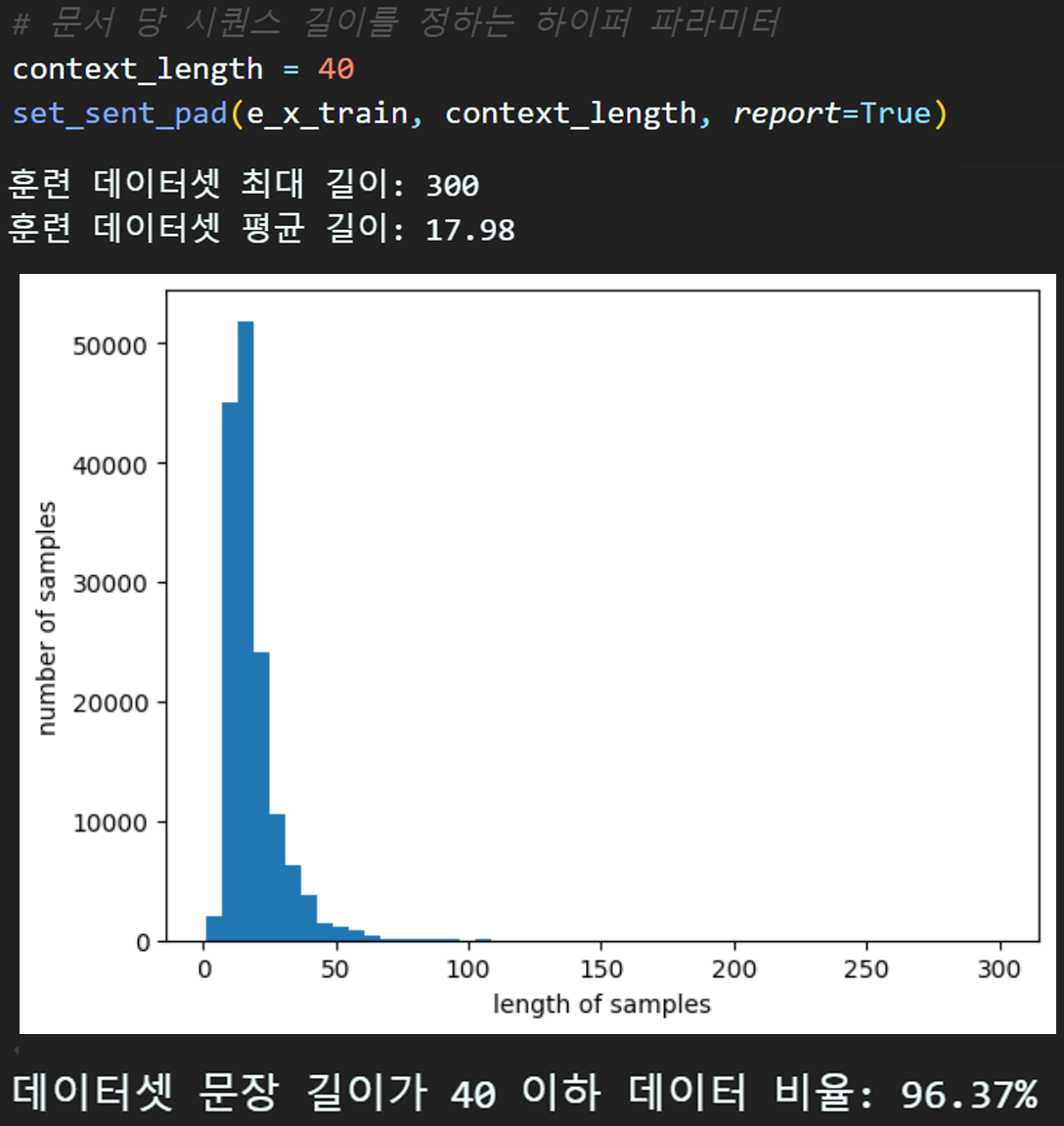
# x_data(원문)의 문장 패딩(정수인코딩의 완료)
padded_x_train = pad_seq_x(e_x_train, context_length)
padded_x_val = pad_seq_x(e_x_val, context_length)
padded_x_test = pad_seq_x(e_x_test, context_length)
# y_label(태그)의 문장 패딩(정수인코딩의 완료)
padded_y_train = pad_seq_x(e_y_train, context_length)
padded_y_val = pad_seq_x(e_y_val, context_length)
padded_y_test = pad_seq_x(e_y_test, context_length)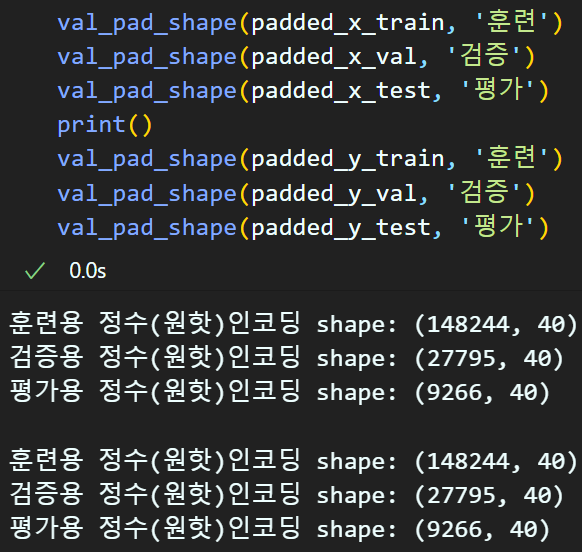
import torch
bs = 256 # Batch_size 하이퍼 파라미터
# 정수(원핫)인코딩 데이터를 데이터로더로 변환
trainloader = set_dataloader(padded_x_train, padded_y_train, bs,
content='훈련', report=True)
valloader = set_dataloader(padded_x_val, padded_y_val, bs,
content='검증', report=True)
testloader = set_dataloader(padded_x_test, padded_y_test, bs,
content='평가', report=True)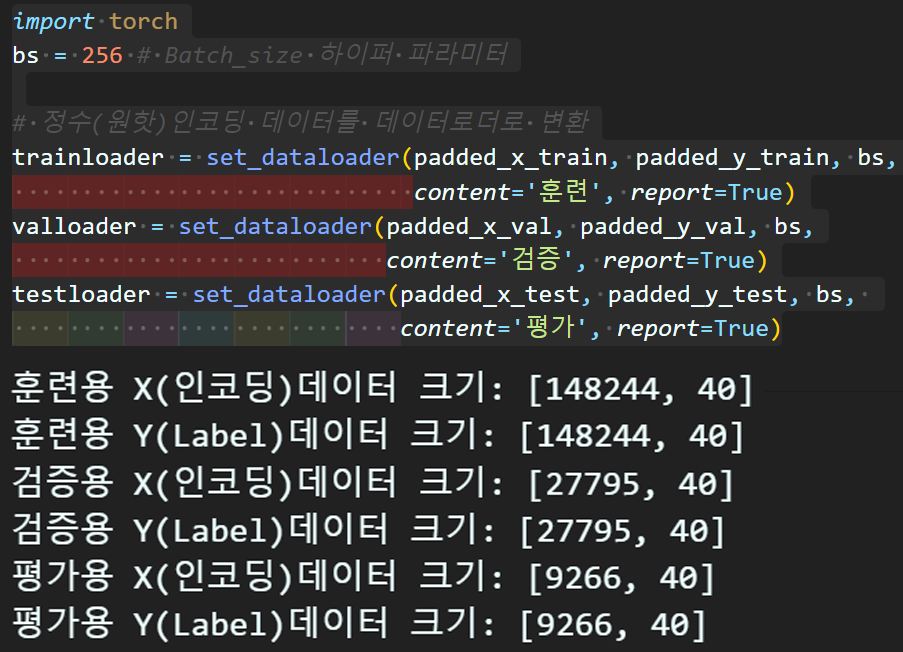
여기까지 수행했다면 데이터 + 텍스트 전처리는 이전 포스트와 동일하게 수행을 완료한것이다.
3.1 모델 학습
주요 하이퍼 파라미터 선정
주요 하이퍼 파라미터를 알아보기 쉽게 정리하자
# 주요 하이퍼 파라미터 정리
VOCAB_SIZE = len(word_to_idx)
CONTEXT_LEN = context_length
EMB_DIM = 100 # 임베딩 차원은 100으로
NUM_Tags = len(tag_to_idx)
NUM_Layers = 2 #셀의 레이어는 1층이 아니라 2층으로
HIDE_DIM = 500
from tabulate import tabulate
# 출력할 데이터를 리스트 형식으로 준비
data = [
["태그 처리된 단어", f"{VOCAB_SIZE}개"],
["문장 최대 길이", CONTEXT_LEN],
["임베딩 차원", EMB_DIM],
["총 태그 종류", f"{NUM_Tags}종"],
["언어 모델 층수", f"{NUM_Layers}층"],
["히든 레이어 너비", HIDE_DIM]
]
# 표 형식으로 출력
print(tabulate(data, headers=["하이퍼 파라미터", "값"],
tablefmt="grid"))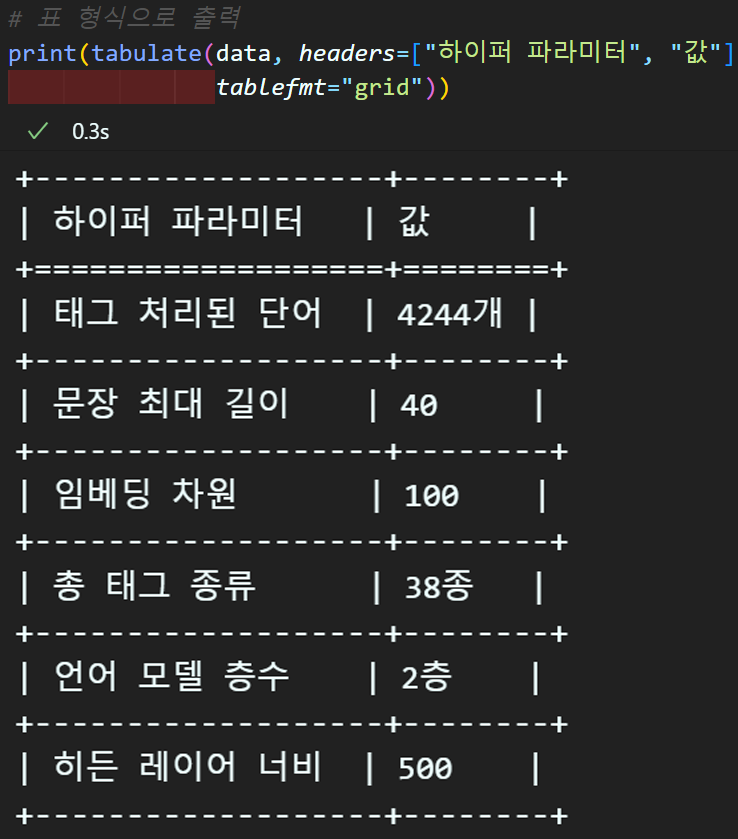
항상 느끼는거지만 버그를 방지하려면
예의가 바르게 코딩을 해야한다.
고로 예의바르게 Bi-LSTM/GRU + CRF모델 설계 코드를 다시 업로드하고자 한다.
여기서 주의사항이 있다
pytorch-crf는 두개의 라이브러리가 존재해서 설치를 잘 해야한다;;;
https://github.com/kmkurn/pytorch-crf
https://github.com/rikeda71/TorchCRF
두가지 버전이 코드는 동일한테 상세 함수 설명이랑 인자값이 살짝.. 아주 사알짝 다르다...
필자는 https://github.com/rikeda71/TorchCRF에서 제공하는 TorchCRF버전으로 진행하고자 한다
주요 차이점은
1) CRF 인스턴스화 할 시 Batch_first=True옵션 없어도 됨
crf = CRF(num_labels)2) 최적화된 를 출력하는 함수명이 viterbi_decode임
crf.viterbi_decode(hidden, mask)이 두 부분이 다르고 그 외 나머지 항목은 모두 동일하다
import torch.nn as nn
from TorchCRF import CRF
class NERTagger_BiLSTM_CRF(nn.Module):
def __init__(self, vocab_size, embed_dim, tag_dim,
hid_dim, num_layers, emb_matirx=None):
super(NERTagger_BiLSTM_CRF, self).__init__()
self.embed = nn.Embedding(vocab_size, embed_dim)
# 사전훈련 임베딩 사용 유/무 함수
if emb_matirx is not None:
self.embed.weight = nn.Parameter(
torch.tensor(emb_matirx, dtype=torch.float32))
self.embed.weight.requires_grad = True
self.lstm = nn.LSTM(input_size=embed_dim, # LSTM에 입력차원
hidden_size=hid_dim, # LSTM의 출력차원
num_layers=num_layers, # 내부 Cell 몇층?
bidirectional=True, #양방향 학습 옵션 On
batch_first=True) # 입력텐서 -> batch가 맨처음
# 최종적으로 tag 종류를 맟추는 FC layer
# 양방향 연산이기에 FC_layer에 입력되는 feature는 2배로 늘어난다
self.classifier = nn.Sequential(
nn.Linear(hid_dim*2, tag_dim),
)
# CRF 레이어 추가, 입력은 classifier 통과 결과물을 받아야 함
self.crf = CRF(tag_dim)
def forward(self, x, tags=None, mask=None):
# 입력 x : batch_size, seq_length
emb = self.embed(x) # (batch_size, seq_length, embedding_dim)
# 양방향 학습 On이기에
# lstm_out : (bs, seq_len, hidden_dim * 2)
# hidden = (num_layer * 2, bs, hidden_dim)
lstm_out, (hidden, cell) = self.lstm(emb)
# many-to-many 방식이니까 lstm_out을 사용한다.
logits = self.classifier(lstm_out)
# logits 출력 : (bs, seq_len, tag_dim)
# CRF는 훈련모드/평가모드로 나눠서 출력을 달리하자
# 평가모드 작성이 더 쉬우니 평가, 훈련모드 순으로 작성한다
if tags is None : # y_label이 없는 '평가 모드'
# tag가 없으니 마스크도 없다 치고 항상 True마스크를 넣어주자
# 이러면 출력되는 2중 리스트 길이가 [[seq_len], [seq_len]]으로 고정됨
one_mask = torch.ones(logits.size(0), logits.size(1),
dtype=torch.bool,
device=logits.device)
# CRF의 최적화한 예측값은 2중 리스트 이며
# [[마스크 적용된 가변 seq], [마스크 적용된 가변 seq]] 형태
optim_pred = self.crf.viterbi_decode(logits, mask=one_mask)
# 참고로 mask는 Tensor자료형에 Tag = 1, Pad=0 으로
# 처리된 데이터임을 명심하자
return optim_pred
else: #y_label이 존재하는 '훈련 모드'
# CRF의 출력은 Loss가 기본출력이고
# decode 메서드를 써야 CRF로 최적화한 y_pred를 출력한다.
crf_loss = -self.crf(logits, tags, mask=mask)
# 통상적인 로스함수처럼 스칼라값이 출력된다.
optim_pred = self.crf.viterbi_decode(logits, mask=mask)
# optim_pred 가 이중 리스트 형식이기에 텐서 자료형으로 변환
# 변환되는 형태는 'logits'과 동일하게 변경되게 하며
# 이때 (bs, seq_len, tag_dim=1) 이 된다.
bs, seq_len, _ = logits.size() # 먼저 logit 차원 정보 추출
# 먼저 tensor 자료형을 logis의 구조와 타입과 동일하게 초기화
optim_logits = torch.zeros(bs, seq_len, 1,
dtype=logits.dtype,
device=logits.device)
# 이중리스트 형식의 optim_pred를 추출해
# 텐서 자료형인 optim_logits로 전달
for i, seq in enumerate(optim_pred):
optim_logits[i, :len(seq), 0] = torch.tensor(seq,
dtype=logits.dtype,
device=logits.device)
# 최적화된 CRF_y_pred는 텐서 자료형 (bs, seq_len, 1)
return optim_logits, crf_lossimport torch.nn as nn
from TorchCRF import CRF
class NERTagger_BiGRU_CRF(nn.Module):
def __init__(self, vocab_size, embed_dim, tag_dim,
hid_dim, num_layers, emb_matirx=None):
super(NERTagger_BiGRU_CRF, self).__init__()
self.embed = nn.Embedding(vocab_size, embed_dim)
# 사전훈련 임베딩 사용 유/무 함수
if emb_matirx is not None:
self.embed.weight = nn.Parameter(
torch.tensor(emb_matirx, dtype=torch.float32))
self.embed.weight.requires_grad = True
self.gru = nn.GRU(input_size=embed_dim, # GRU에 입력차원
hidden_size=hid_dim, # GRU의 출력차원
num_layers=num_layers, # 내부 Cell 몇층?
bidirectional=True, #양방향 학습 옵션 On
batch_first=True) # 입력텐서 -> batch가 맨처음
# 최종적으로 tag 종류를 맟추는 FC layer
# 양방향 연산이기에 FC_layer에 입력되는 feature는 2배로 늘어난다
self.classifier = nn.Sequential(
nn.Linear(hid_dim*2, tag_dim),
)
# CRF 레이어 추가, 입력은 classifier 통과 결과물을 받아야 함
self.crf = CRF(tag_dim)
def forward(self, x, tags=None, mask=None):
# 입력 x : batch_size, seq_length
emb = self.embed(x) # (batch_size, seq_length, embedding_dim)
# 양방향 학습 On이기에
# gru_out : (bs, seq_len, hidden_dim * 2)
# hidden = (num_layer * 2, bs, hidden_dim)
gru_out, hidden = self.gru(emb)
# many-to-many 방식이니까 gru_out을 사용한다.
logits = self.classifier(gru_out)
# logits 출력 : (bs, seq_len, tag_dim)
# CRF는 훈련모드/평가모드로 나눠서 출력을 달리하자
# 평가모드 작성이 더 쉬우니 평가, 훈련모드 순으로 작성한다
if tags is None : # y_label이 없는 '평가 모드'
# tag가 없으니 마스크도 없다 치고 항상 True마스크를 넣어주자
# 이러면 출력되는 2중 리스트 길이가 [[seq_len], [seq_len]]으로 고정됨
one_mask = torch.ones(logits.size(0), logits.size(1),
dtype=torch.bool,
device=logits.device)
# CRF의 최적화한 예측값은 2중 리스트 이며
# [[마스크 적용된 가변 seq], [마스크 적용된 가변 seq]] 형태
optim_pred = self.crf.viterbi_decode(logits, mask=one_mask)
# 참고로 mask는 Tensor자료형에 Tag = 1, Pad=0 으로
# 처리된 데이터임을 명심하자
return optim_pred
else: #y_label이 존재하는 '훈련 모드'
# CRF의 출력은 Loss가 기본출력이고
# decode 메서드를 써야 CRF로 최적화한 y_pred를 출력한다.
crf_loss = -self.crf(logits, tags, mask=mask)
# 통상적인 로스함수처럼 스칼라값이 출력된다.
optim_pred = self.crf.viterbi_decode(logits, mask=mask)
# optim_pred 가 이중 리스트 형식이기에 텐서 자료형으로 변환
# 변환되는 형태는 'logits'과 동일하게 변경되게 하며
# 이때 (bs, seq_len, tag_dim=1) 이 된다.
bs, seq_len, _ = logits.size() # 먼저 logit 차원 정보 추출
# 먼저 tensor 자료형을 logis의 구조와 타입과 동일하게 초기화
optim_logits = torch.zeros(bs, seq_len, 1,
dtype=logits.dtype,
device=logits.device)
# 이중리스트 형식의 optim_pred를 추출해
# 텐서 자료형인 optim_logits로 전달
for i, seq in enumerate(optim_pred):
optim_logits[i, :len(seq), 0] = torch.tensor(seq,
dtype=logits.dtype,
device=logits.device)
# 최적화된 CRF_y_pred는 텐서 자료형 (bs, seq_len, 1)
return optim_logits, crf_loss이렇게 비슷할꺼면 하나로 합쳐..
실험준비
# 학습 실험 조건을 구분하기 위한 키
model_key = ['BiLSTM+CRF', 'BiGRU+CRF']
metrics_key = ['Loss', '정확도']# 모델 선언
Lstm_tagger = NERTagger_BiLSTM_CRF(VOCAB_SIZE, EMB_DIM, NUM_Tags,
HIDE_DIM, NUM_Layers)
Gru_tagger = NERTagger_BiGRU_CRF(VOCAB_SIZE, EMB_DIM, NUM_Tags,
HIDE_DIM, NUM_Layers)# GPU사용 가능 유/무 확인
device = torch.device("cuda" if torch.cuda.is_available() else 'cpu')
models = {} # 딕셔너리
models[model_key[0]] = Lstm_tagger.to(device)
models[model_key[1]] = Gru_tagger.to(device)import torch.optim as optim
# 로스함수 및 옵티마이저 설계
# 로스함수에서 <PAD> 토큰의 정수인덱스 번호 -> 0번에 대해서는
# 틀리건 맞건 무시하겠다 : ignore_index에 해당 정수 인덱스 번호 기입
ignore_class_idx = 0 #무시할 클래스 정보는 살려두자
# criterion = nn.CrossEntropyLoss(ignore_index=ignore_class_idx)
LR = 0.001 # 러닝레이트는 통일
optimizers = {}
optimizers[model_key[0]] = optim.Adam(Lstm_tagger.parameters(), lr=LR)
optimizers[model_key[1]] = optim.Adam(Gru_tagger.parameters(), lr=LR)참고로 CRF의 출력물은 Loss값이니
기존의 CrossEntropyLoss메서드는 더이상 사용안해도 된다.
# 학습/검증 정보 저장
history = {key: {metric: []
for metric in metrics_key}
for key in model_key}학습준비
모델의 구조가 변경되었기에
학습을 실행하는데 필요한
model_train, model_evaluate 두 함수도 변경을 진행해야 한다.
def data_reshape(y_pred, y_label, y_mask, loss): #예측값 차원은 변동됬지만 전반적으로 비슷
# 입력되는 y_pred : (Batch_size, seq_len, output_dim = 1)
# 입력되는 y_label : (Batch_size, seq_len)
batch_size, seq_len, output_dim = y_pred.size()
re_y_pred = y_pred.view(-1, output_dim) # (bs*seq, out)
re_y_label = y_label.view(-1) #(bs*seq)
re_y_mask = y_mask.view(-1) #마스크는 라벨이랑 차원변환과정이 동일하게 수행됨
re_loss = loss.mean() #loss는 (bs)여서 -> 1 스칼라로 바꿔줘야함
return re_y_pred, re_y_label, re_y_mask, re_loss먼저 예측값, 정답지, 정답지로 만드는 마스크
이 3개는 이전 포스트 3개는 이전 포스트
NLP-LSTM, GRU (3) : 개체명 인식(NER : Named Entity Recognition) 에서 수행하는 함수와
거의 유사하게 동작하게끔 작성했다
마스크만 (batch_size, seq_len)차원 (batch_size * seq_len) 하는 항목이 추가됬을 뿐이다.
문제는 loss인데

필자가 사용중에 있는 TorchCRF 라이브러리는
loss 연산결과가 (batch_size) 형식으로
각 배치 내 iter(샘플)단위로 샘플당 loss를 출력한다
이를 스칼라 값으로 변환하는 과정을 거쳐야 하는데
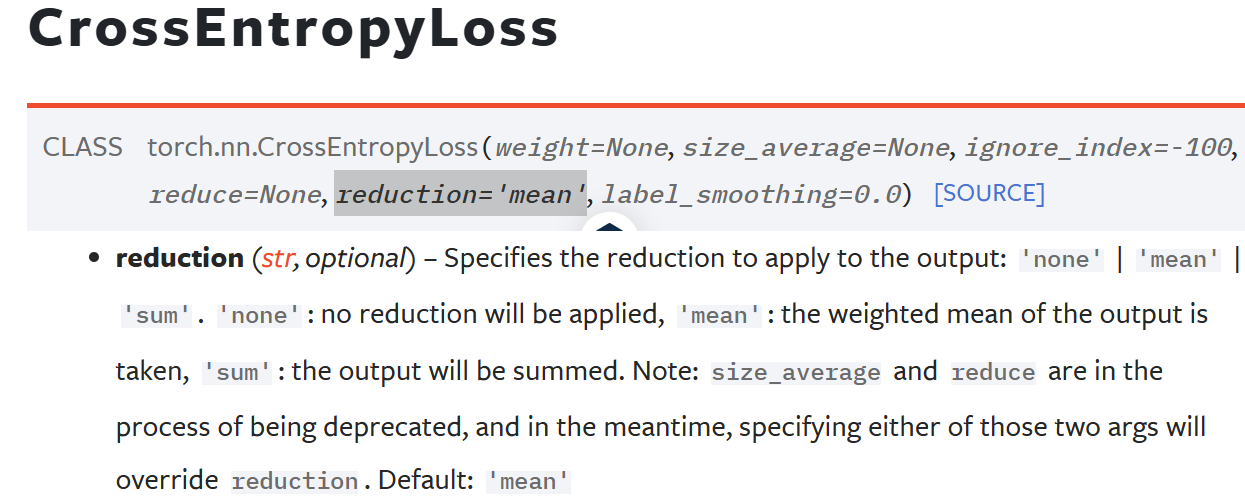
이게 흔히 로스 함수의 대표함수 CrossEntropyLoss
함수의 reduction 옵션이다.
샘플당 loss를 합산(sum)을 할지? 평균(mean)을 낼지? 를 선택하여 스칼라로 변환해야 하는데
필자는 자주 사용되는 mean을 적용했다.
# 정답을 맞출 때 '무시'해야 할 클래스가 있을때 동작하는 함수
def cal_correct(y_pred, y_label, mask=None):
# y_pred는 차원이(bs*seq, out_dim=1)이라서 argmax보다는 squeeze적용이 더 낫다.
pred = y_pred.squeeze(dim=1) #가장 높은 예측값 하나 추출
#그리고 mask는 이 함수에서 계산하지 말고 상위단에서 계산하는게 적합하다.
if mask is not None: #마스크된 항목이 존재할 때
correct = pred.eq(y_label).masked_select(mask).sum().item()
total = mask.sum().item() # 전체 원소 개수중 마스크처리된것만
else:
correct = pred.eq(y_label).sum().item()
total = y_label.numel() # 전체 원소 수 출력
# 수치적 안정성을 보장하면서 연산을 수행하자
iter_cor = correct / total if total > 0 else 0
return iter_cor정답 개수를 세는 함수인 cal_correct 부분에서도 변동사항이 있는데
원래대로라면
pred = y_pred.argmax(dim=1) 이어야 할 부분을
pred = y_pred.squeeze(dim=1) 이렇게 바꿧다
CRF의 출력정보가 최적화한 패턴조합 이고
이것의 차원이 (batch_size, seq_len, out_dim=1)로 변경했고
이걸 (batch_size X seq_len, out_dim=1)으로 reshape 한 값이 전달되어
정답 개수를 세는 것인데
out_dim항목이 사실상 argmax가 적용된 값이 나오는 것이라서 차원만 (batch_size X seq_len, 1) (batch_size X seq_len) 으로 변경되게끔
차원축소 함수인 squeeze함수 사용으로 최적화를 했다.
위 두개의 콜백함수를 바탕으로 model_train, model_evaluate 함수를 개선한다
def model_train(model, data_loader, optimizer_fn,
epoch, epoch_step, ignore_class=None):
# 1개의 epoch내 batch단위(iter)로 연산되는 값이 저장되는 변수들
iter_size, iter_loss, iter_correct = 0, 0, 0
device = next(model.parameters()).device # 모델의 연산위치 확인
model.train() # 모델을 훈련모드로 설정
#특정 epoch_step 단위마다 tqdm 진행바가 생성되게 설정
if (epoch+1) % epoch_step == 0 or epoch == 0:
tqdm_loader = tqdm(data_loader)
else:
tqdm_loader = data_loader
for x_data, y_label in tqdm_loader:
x_data, y_label = x_data.to(device), y_label.to(device)
# y_label을 바탕으로 mask를 생성하기
y_mask = (y_label != ignore_class)
# 모델이 훈련모드일 때 정답지랑 마스크를 더 필요로함
# 그리고 loss도 출력함을 잊지말자
y_pred, loss = model(x_data, y_label, y_mask)
# 데이터셋의 구조 변형이 필요할 때 아래 함수 구동
# loss값이랑 mask도 구조 변형이 필요함
y_pred, y_label, y_mask, loss = data_reshape(y_pred, y_label, y_mask, loss)
#backward 과정 수행
optimizer_fn.zero_grad()
loss.backward()
optimizer_fn.step() # 마지막에 스케줄러 있으면 업뎃코드넣기
# 현재 batch 내 샘플 개수당 correct, loss, 수행 샘플 개수 구하기
iter_correct += cal_correct(y_pred, y_label, y_mask) * x_data.size(0)
iter_loss += loss.item() * x_data.size(0)
iter_size += x_data.size(0)
# tqdm에 현재 진행상태를 출력하기 위한 코드
if (epoch+1) % epoch_step == 0 or epoch == 0:
prograss_loss = iter_loss / iter_size
prograss_acc = iter_correct / iter_size
desc = (f"[훈련중]로스: {prograss_loss:.3f}, "
f"정확도: {prograss_acc:.3f}")
tqdm_loader.set_description(desc)
#현재 epoch에 대한 종합적인 정확도/로스 계산
epoch_acc = iter_correct / iter_size
epoch_loss = iter_loss / len(data_loader.dataset)
return epoch_loss, epoch_acc주요 변경사항은
y_pred, loss = model(x_data, y_label, y_mask)
CRF가 적용된 모델의 출력 및 입력에 맞춰서 코드변경을 진행했다.
def model_evaluate(model, data_loader,
epoch, epoch_step, ignore_class=None):
# 1개의 epoch내 batch단위(iter)로 연산되는 값이 저장되는 변수들
iter_size, iter_loss, iter_correct = 0, 0, 0
device = next(model.parameters()).device # 모델의 연산위치 확인
model.eval() # 모델을 평가 모드로 설정
#특정 epoch_step 단위마다 tqdm 진행바가 생성되게 설정
if (epoch+1) % epoch_step == 0 or epoch == 0:
tqdm_loader = tqdm(data_loader)
else:
tqdm_loader = data_loader
with torch.no_grad(): #평가모드에서는 그래디언트 계산 중단
for x_data, y_label in tqdm_loader:
x_data, y_label = x_data.to(device), y_label.to(device)
# y_label을 바탕으로 mask를 생성하기
y_mask = (y_label != ignore_class)
# 검증과정은 y_label이 필요한 것이니
# 전체적으로 출력결과는 훈련모드랑 비슷함
y_pred, loss = model(x_data, y_label, y_mask)
# 데이터셋의 구조 변형이 필요할 때 아래 함수 구동
# loss값이랑 mask도 구조 변형이 필요함
y_pred, y_label, y_mask, loss = data_reshape(y_pred, y_label, y_mask, loss)
# 현재 batch 내 샘플 개수당 correct, loss, 수행 샘플 개수 구하기
iter_correct += cal_correct(y_pred, y_label, y_mask) * x_data.size(0)
iter_loss += loss.item() * x_data.size(0)
iter_size += x_data.size(0)
#현재 epoch에 대한 종합적인 정확도/로스 계산
epoch_acc = iter_correct / iter_size
epoch_loss = iter_loss / len(data_loader.dataset)
return epoch_loss, epoch_acc모델 평가코드도 동일하게
y_pred, loss = model(x_data, y_label, y_mask)를 적용했다.
학습
num_epoch = 8 #총 훈련/검증 epoch값
ES = 2 # 디스플레이용 에포크 스텝for key in model_key:
print(f"\n--현재 훈련중인 조건: [{[key]}]--") # 조건에 맞는 실험시작
for epoch in range(num_epoch): #에포크별 모델 훈련/검증
# 모델 훈련
train_loss, train_acc = model_train(
models[key], trainloader,
optimizers[key], epoch, ES,
ignore_class=ignore_class_idx #무시할 클래스 인덱스
) #모델 검증
val_loss, val_acc = model_evaluate(
models[key], valloader,
epoch, ES, ignore_class=ignore_class_idx #무시할 클래스 인덱스
)
# 손실 및 성과 지표를 history에 저장
history[key]['Loss'].append((train_loss, val_loss))
history[key]['정확도'].append((train_acc, val_acc))
# Epoch_step(ES)일 때마다 print수행
if (epoch+1) % ES == 0 or epoch == 0:
print(f"epoch {epoch+1:03d}," + "\t" +
f"훈련 [Loss: {train_loss:.3f}, " +
f"Acc: {train_acc*100:.2f}%]")
print(f"epoch {epoch+1:03d}," + "\t" +
f"검증 [Loss: {val_loss:.3f}, " +
f"Acc: {val_acc*100:.2f}%]")
print(f"--조건[{[key]}] 훈련 종료--\n") # 조건에 맞는 실험종료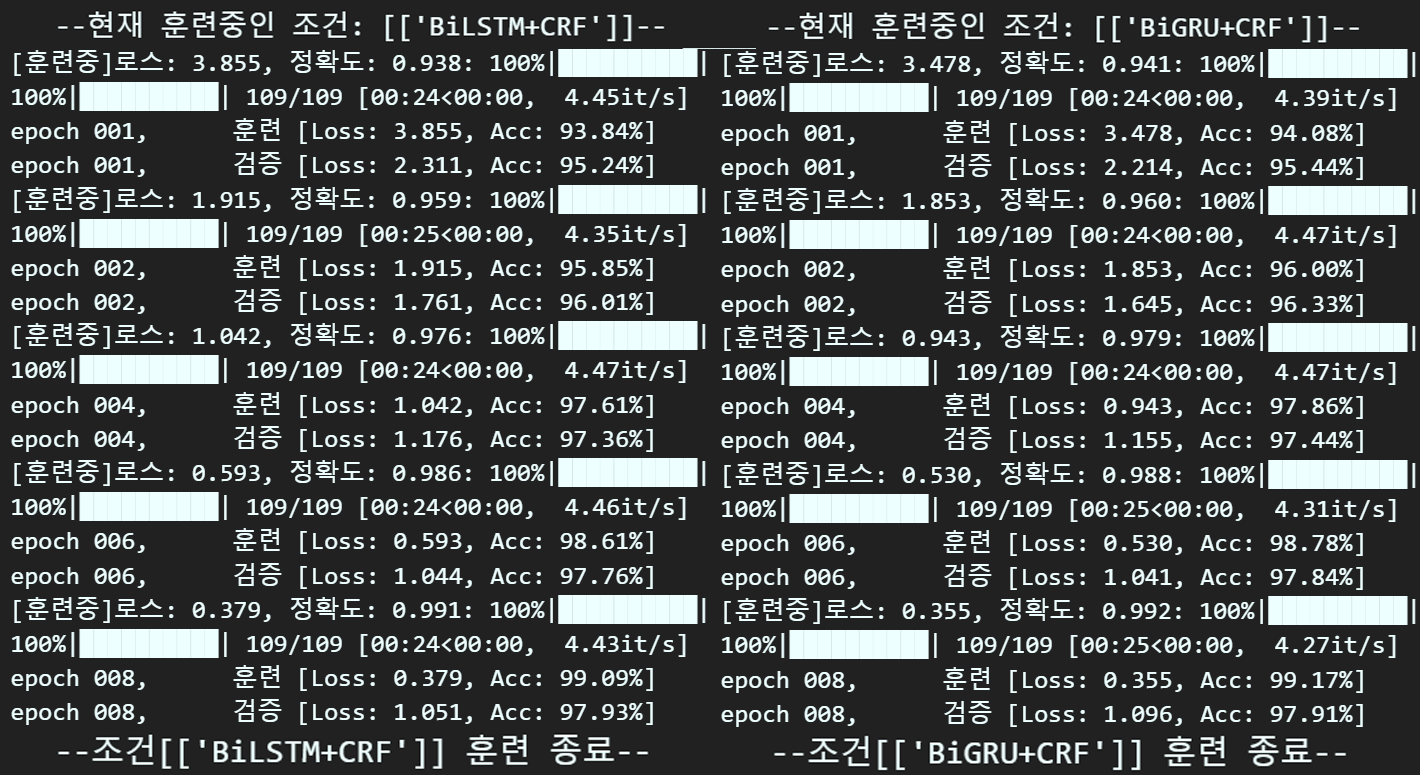
이전 포스트의 결과와 비교하면 아래의 그림으로 정리할 수 있다.
※주의 : 이전 포스트 대비 데이터셋의 크기가 두배 더 큼을 유의하자
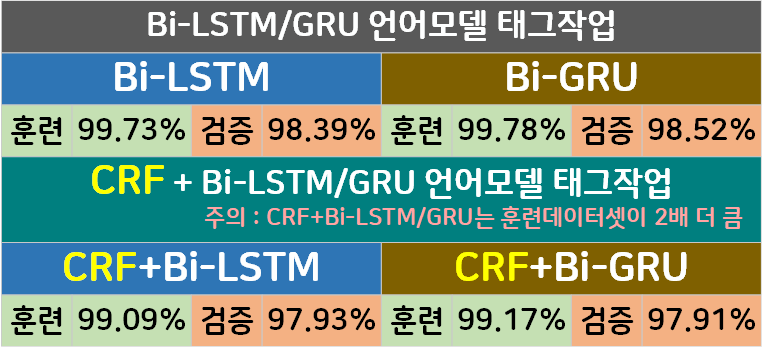
음.. 데이터셋 크기가 두배 늘어난거 감안하면
뭐 적당히 좋은 성능을 내는 것 같은데
문제가 있다.
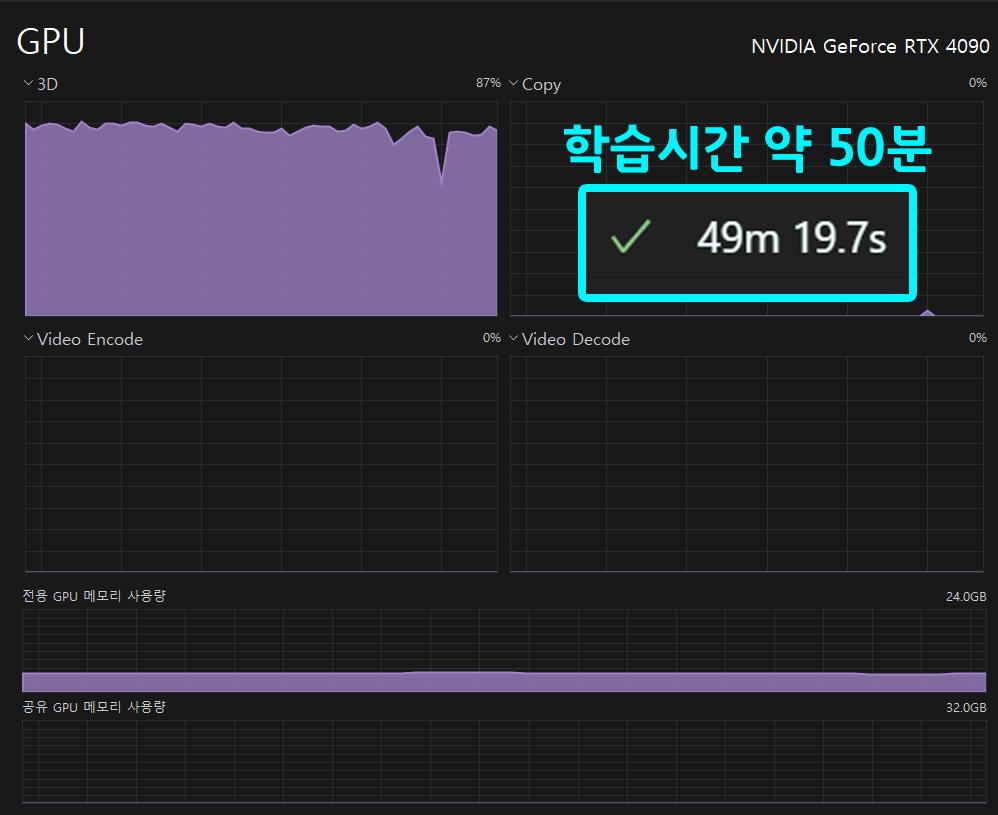
CRF 방법론이 도입되면서 행렬연산이 많아진 탓인지
3D 연산량이 상당이 늘었고 학습 시간도 3배 이상 늘어난 문제점이 있다.
그러니까 간단하게 정리하자면
단가가 안맞는다

CRF는 역시 로우 레벨 프로그래밍을 안하길 잘했다.
이거저거 따져봣을 때 만들어진 라이브러리 한번 찍먹이 낫네;;
