
개요
본 블로그 포스팅은 수도권 ICT 이노베이션 스퀘어에서 진행하는 AI 핵심 기술 집중 클래스의 자연어처리(NLP) 강좌 내용을 필자가 다시 복기한 내용에 관한 것입니다.
1. Seq2Seq 검증/추론 분석

이전 포스트 NLP- Seq to Seq (4-1) : Techer forcing의 결과를 분석한다면 Techer forcing(교사강요) 적용을 통해 훈련 성능은 하락했지만 생성모델(Generative Models)의 취지에 맞게 나름 단어 생성(번역)을 어느정도 수행하고 있다.
그러나, 이전 포스트에서도 표기했듯이
모델의 검증, 그리고 추론과정에서는
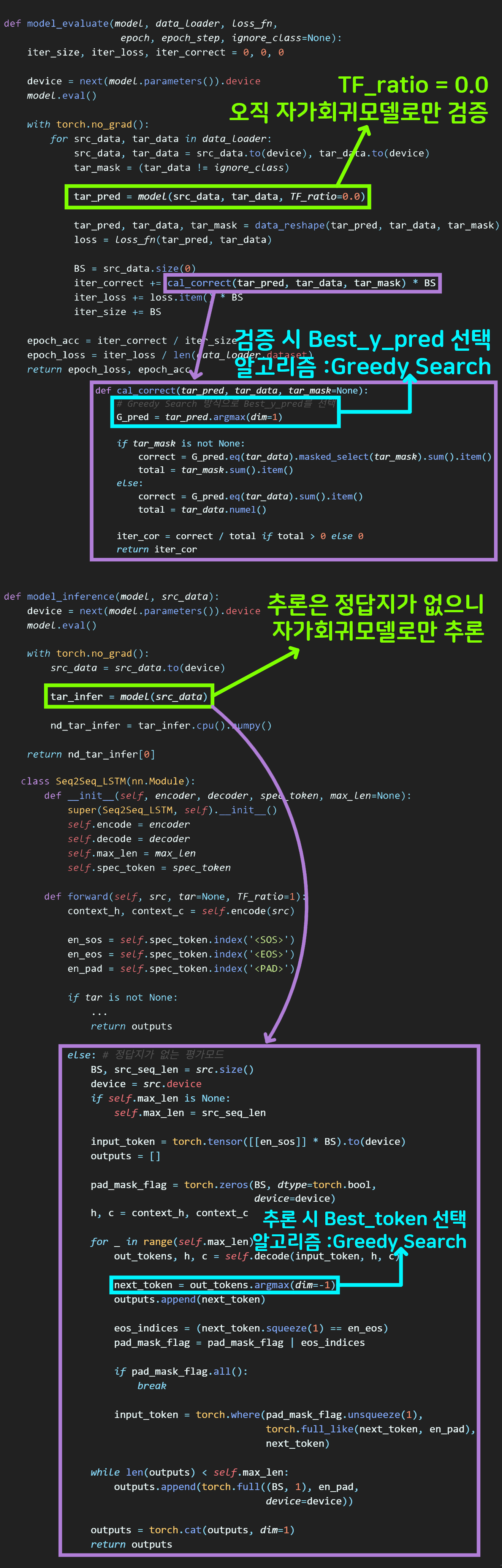
위 사진처럼 model_evaluate, model_inference 함수 모두
Auto-Regressive model(자가회귀 모델)로만 모델 출력을 생성한다.
이게 검증/추론 과정의 성능이 훈련 모드 대비 너무 낮게나오는 경향이 있고
검증 모드의 로스 함수로 nn.CrossEntropyLoss
검증 및 추론 단어의 생성을 Greedy Search를 사용했는데
이를 생성 모델의 더 적합한 평가지표와, 더 적합한 시퀀스 생성 알고리즘을 적용하려 한다.
2. Beam Search
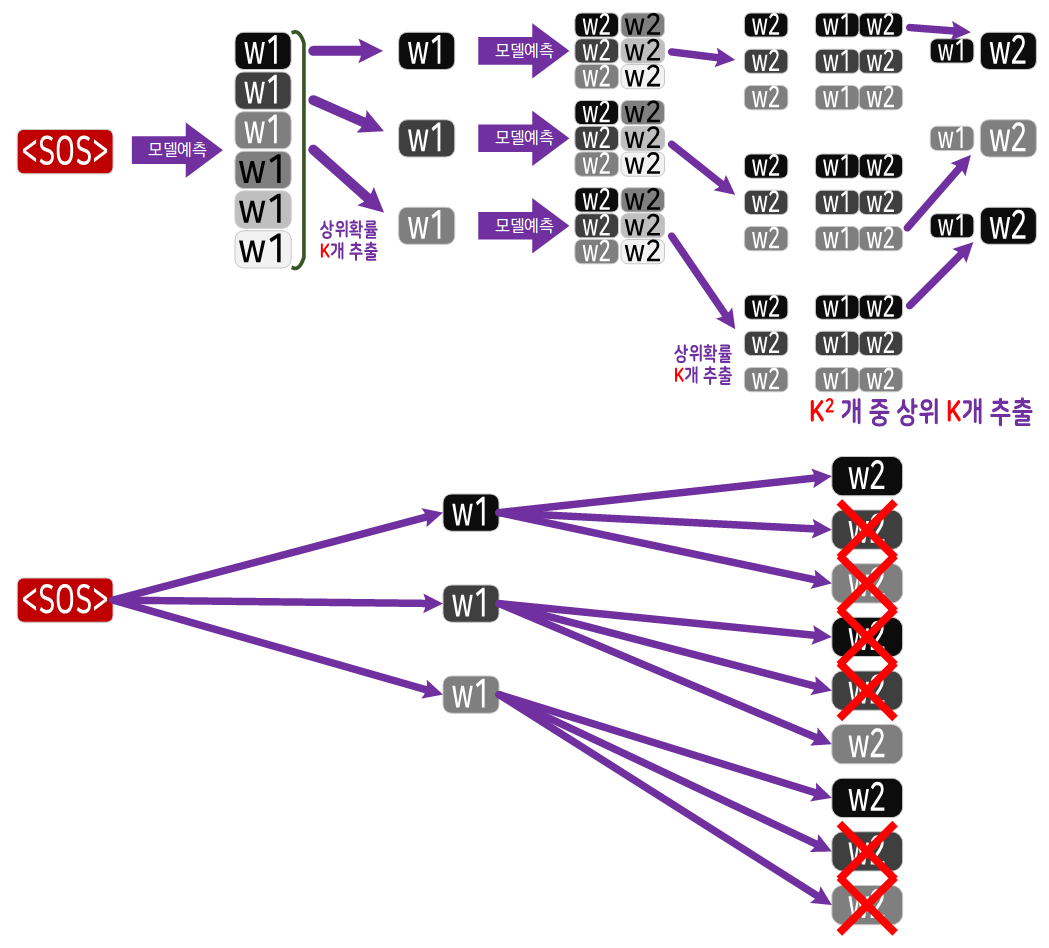
Beam search는 위 그림으로 표현한 탐색 알고리즘 중 하나로 하나의 가장 최적 결과를 찾는
Greedy Search 대비 후보군 몇개를 스페어로 놓고
이전에 찾은 스페어들과 확률값을 합산하여
좀 더 좋은 결과물을 찾기 위해 노력하는 알고리즘 중 하나이다.
간단히 설명하자면 경우의 수를 K 가지 개수만큼 뻗어가면서 K^2개의 가지가 발생하면 이 중 상위 K개의 가지만 살리고 나머지는 계속 솎아내는 것을 반복한다..
위와 같이 모델입력 -> 가지수 확장 -> 상위 K(Beam_width)개만 sorting 을 쳇바퀴처럼 반복하게 코드를 작성해야 하는데
이게 개념은 쉽지만.. 코드화 하기는 상당히 난해한 부분이 있다.
이 Beam search를 Seq2Seq의 추론 부분에 적용하여 코드화를 진행해 보도록 하겠다.

2.1 Beam Search - 초기화
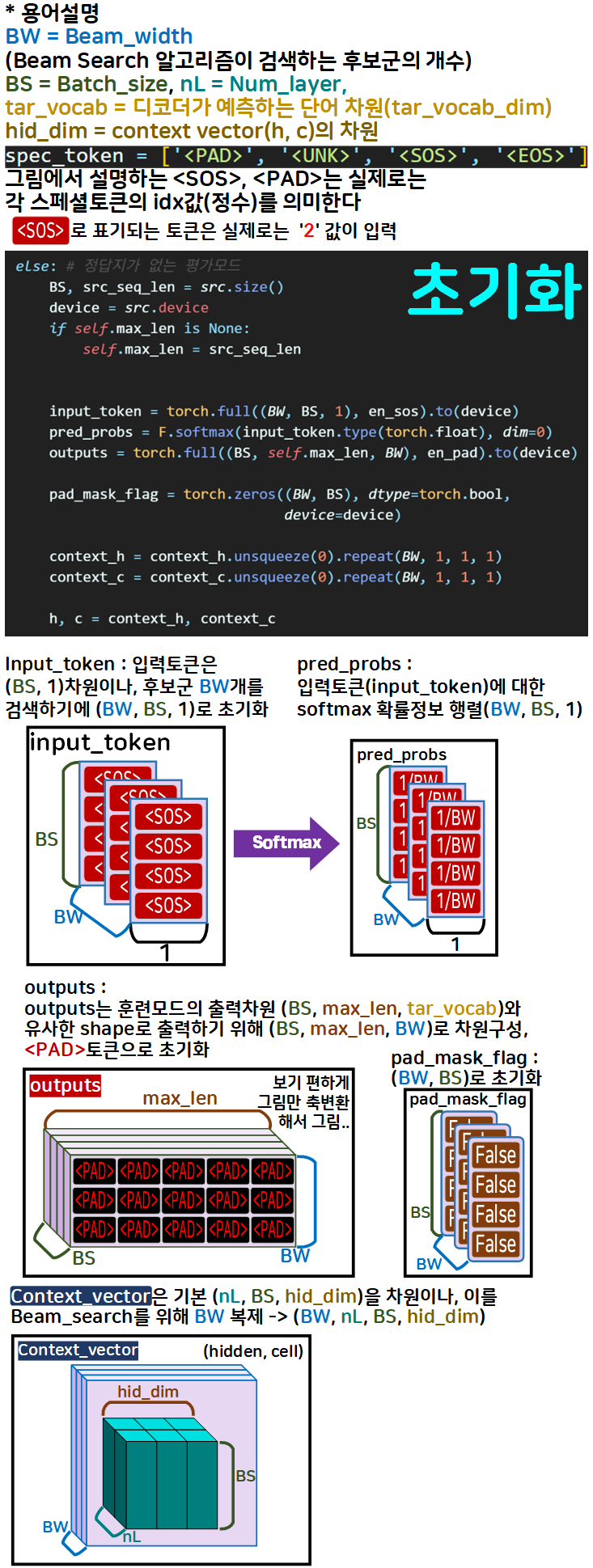
Beam search의 초기화 부분에서는 총 5종의 변수를 Initialize 하며
각각의 변수 초기화 및 기능은 위 그림을 참조하기 바란다.
2.2 Beam Search - 반복문
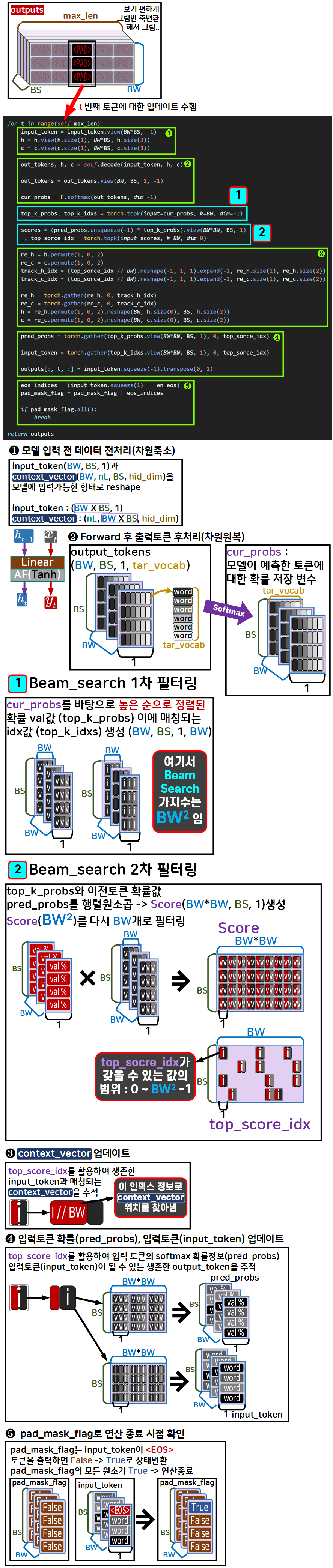
Beam search알고리즘을 활용하여 outputs 출력물을 후보군까지 포함해
(BS, max_len, BW) 차원
으로 출력하기 위한 연산과정을 파트별로 나누고,
각 부분에 대해서는 도식을 첨부했으니 전체적인 흐름이 어떻게 흘러가는지 확인 바란다.
연산과정이 최대한 Tensor 자료형에서 GPU연산이 가능한 방식으로 행렬 변환 및 연산이 진행되게끔 코드를 작성하다 보니 코드를 이해하는데 좀 어려움이 있다...
특히 torch.gather, torch.permute, torch.view, torch.topk, torch.repeat, torch.expand등의 메서드는 기능이 어떻게 동작하는지 필히 숙지해야 한다.

3. Beam Search를 적용한 실습
이전 포스트 NLP- Seq to Seq (4-1) : Techer forcing 에서

방송 컨텐츠 한국어-유럽어 번역 말뭉치 데이터로 기계번역 실습을 진행했다.
동일하게 실습을 진행하며
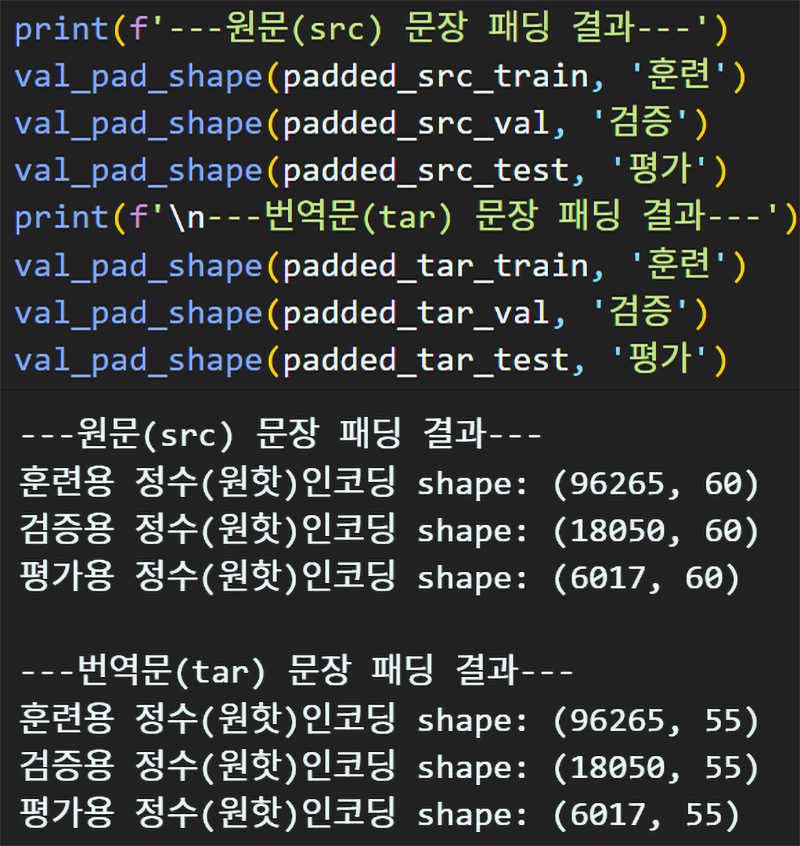
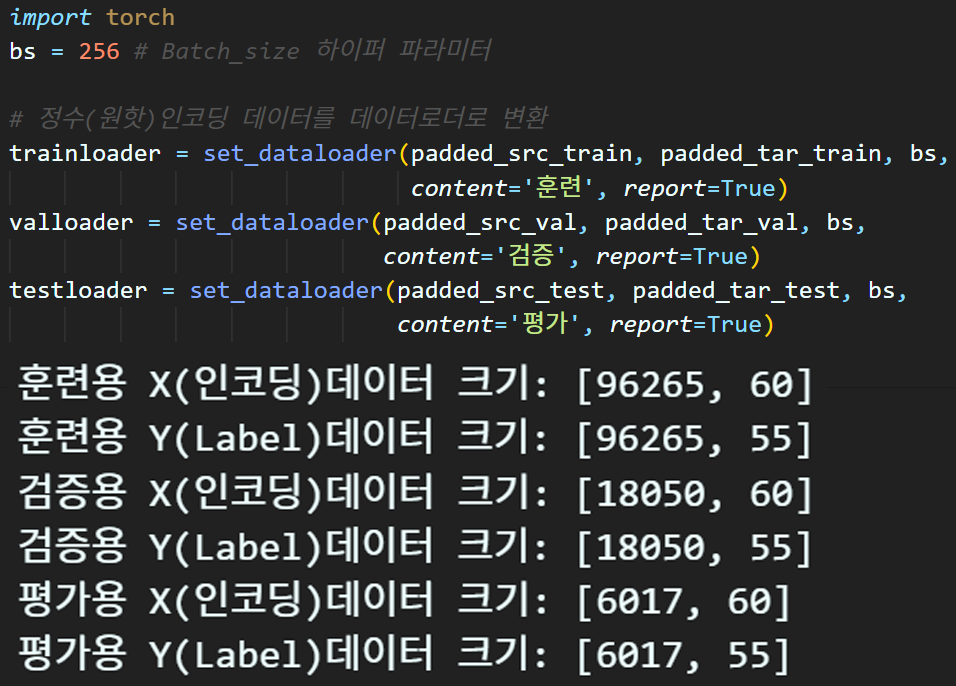
데이터셋 전처리는 문장패딩 데이터로더 생성까지 완료했고
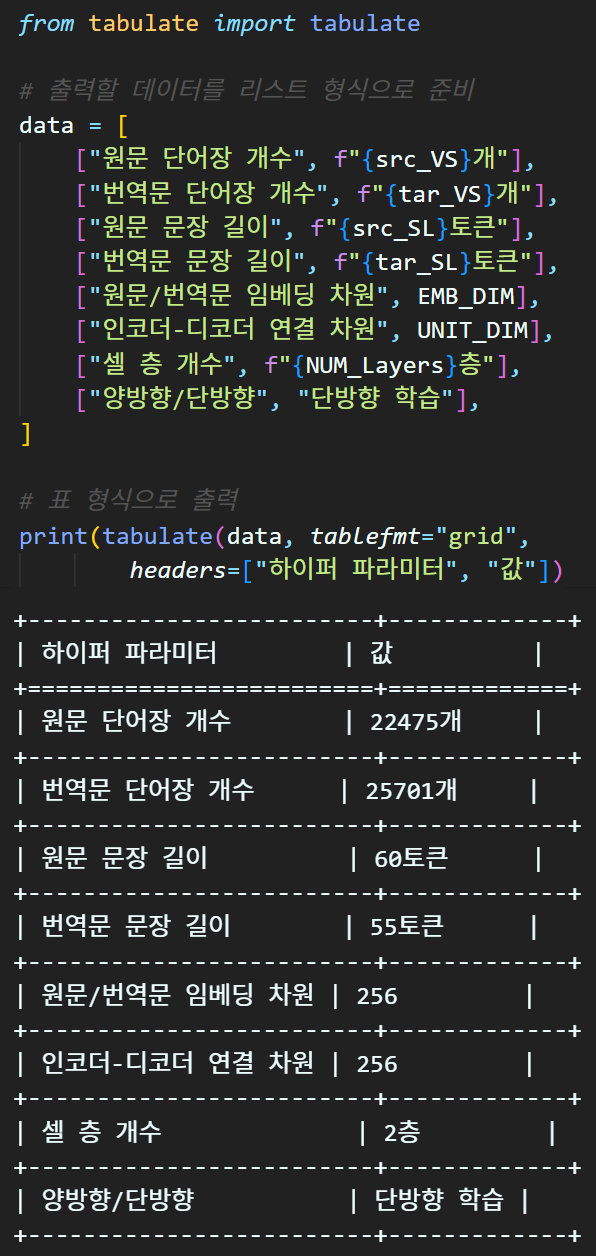
모델 설계를 위한 주요 하이퍼 파리미터 정의
import torch.nn as nn
class Encoder_LSTM(nn.Module):
def __init__(self, src_vocab, src_emb_dim, rnn_dim,
num_layer=1, bi=False):
super(Encoder_LSTM, self).__init__()
# <PAD>토큰의 인덱싱을 지정하면 해당 idx(0)은
# word_vector을 만들 때 모두 0으로 채워지게 만들어준다.
self.embed = nn.Embedding(src_vocab, src_emb_dim,
padding_idx=0)
self.lstm = nn.LSTM(input_size=src_emb_dim,#언어모델 입력차원
hidden_size=rnn_dim, #언어모델 출력차원
num_layers=num_layer, #언어모델 몇층?
bidirectional=bi, #양방향학습 On?
batch_first=True) #왠만하면 True
def forward(self, x): # x의 차원 : (BS, src_seq_len)
emb = self.embed(x) # (BS, src_seq_len, src_emb_dim)
# 인코더에 양방향 학습을 적용한다
# rnn_out : (bs, src_seq_len, hidden_dim * 2)
# hidden : (num_layer * 2, bs, hidden_dim)
rnn_out , (hidden, cell) = self.lstm(emb)
#인코더의 출력은 context_vector
return hidden, cell import torch.nn as nn
class Decoder_LSTM(nn.Module):
def __init__(self, tar_vocab, tar_emb_dim, rnn_dim,
num_layer=1, bi=False):
super(Decoder_LSTM, self).__init__()
# <PAD>토큰의 인덱싱을 지정하면 해당 idx(0)은
# word_vector을 만들 때 모두 0으로 채워지게 만들어준다.
self.embed = nn.Embedding(tar_vocab, tar_emb_dim,
padding_idx=0)
self.lstm = nn.LSTM(input_size=tar_emb_dim,#언어모델 입력차원
hidden_size=rnn_dim, #언어모델 출력차원
num_layers=num_layer, #언어모델 몇층?
bidirectional=bi, #양방향학습 On?
batch_first=True) #왠만하면 True
# 디코더의 출력은 정답(번역문)의 seq_len이 되게 해야함
# 맞춰야 하는 클래스 개수는 정답지의 단어 개수임
if bi : #양방향으로 학습시에는 FC 레이어 입력차원이 두배
self.fc = nn.Linear(rnn_dim*2, tar_vocab)
else:
self.fc = nn.Linear(rnn_dim, tar_vocab)
# 디코더는 인코더의 context_vector을 초기 hidden으로 입력받는다.
def forward(self, x, hidden, cell): # x의 차원 : (BS, tar_seq_len)
emb = self.embed(x) # (BS, tar_seq_len, tar_emb_dim)
# 디코더에 양방향 학습을 적용한다
# rnn_out : (bs, tar_seq_len, hidden_dim * 2)
# hidden : (num_layer * 2, bs, hidden_dim)
rnn_out, (hidden, cell) = self.lstm(emb, (hidden,cell))
output = self.fc(rnn_out)
# 최종 출력은 (bs, seq_len, tar_vocab)
return output, hidden, cellimport torch.nn as nn
class Encoder_GRU(nn.Module):
def __init__(self, src_vocab, src_emb_dim, rnn_dim,
num_layer=1, bi=False):
super(Encoder_GRU, self).__init__()
# <PAD>토큰의 인덱싱을 지정하면 해당 idx(0)은
# word_vector을 만들 때 모두 0으로 채워지게 만들어준다.
self.embed = nn.Embedding(src_vocab, src_emb_dim,
padding_idx=0)
self.gru = nn.GRU(input_size=src_emb_dim,#언어모델 입력차원
hidden_size=rnn_dim, #언어모델 출력차원
num_layers=num_layer, #언어모델 몇층?
bidirectional=bi, #양방향학습 On?
batch_first=True) #왠만하면 True
def forward(self, x): # x의 차원 : (BS, src_seq_len)
emb = self.embed(x) # (BS, src_seq_len, src_emb_dim)
# 인코더에 양방향 학습을 적용한다
# rnn_out : (bs, src_seq_len, hidden_dim * 2)
# hidden : (num_layer * 2, bs, hidden_dim)
rnn_out , hidden = self.gru(emb)
#인코더의 출력은 context_vector
return hiddenimport torch.nn as nn
class Decoder_GRU(nn.Module):
def __init__(self, tar_vocab, tar_emb_dim, rnn_dim,
num_layer=1, bi=False):
super(Decoder_GRU, self).__init__()
# <PAD>토큰의 인덱싱을 지정하면 해당 idx(0)은
# word_vector을 만들 때 모두 0으로 채워지게 만들어준다.
self.embed = nn.Embedding(tar_vocab, tar_emb_dim,
padding_idx=0)
self.gru = nn.GRU(input_size=tar_emb_dim,#언어모델 입력차원
hidden_size=rnn_dim, #언어모델 출력차원
num_layers=num_layer, #언어모델 몇층?
bidirectional=bi, #양방향학습 On?
batch_first=True) #왠만하면 True
# 디코더의 출력은 정답(번역문)의 seq_len이 되게 해야함
# 맞춰야 하는 클래스 개수는 정답지의 단어 개수임
if bi : #양방향으로 학습시에는 FC 레이어 입력차원이 두배
self.fc = nn.Linear(rnn_dim*2, tar_vocab)
else:
self.fc = nn.Linear(rnn_dim, tar_vocab)
# 디코더는 인코더의 context_vector을 초기 hidden으로 입력받는다.
def forward(self, x, hidden): # x의 차원 : (BS, tar_seq_len)
emb = self.embed(x) # (BS, tar_seq_len, tar_emb_dim)
# 디코더에 양방향 학습을 적용한다
# rnn_out : (bs, tar_seq_len, hidden_dim * 2)
# hidden : (num_layer * 2, bs, hidden_dim)
rnn_out, hidden = self.gru(emb, hidden)
output = self.fc(rnn_out)
# 최종 출력은 (bs, seq_len, tar_vocab)
return output, hidden이전 포스트와 동일한 인코더 - 디코더를 선언한다.
Beam search를 적용한 Seq2Seq
import torch
import torch.nn as nn
import torch.nn.functional as F
class Seq2Seq_LSTM(nn.Module):
def __init__(self, encoder, decoder, spec_token, max_len=None):
super(Seq2Seq_LSTM, self).__init__()
self.encode = encoder
self.decode = decoder
# 최대 디코딩 길이 설정
self.max_len = max_len
# 스페셜 토큰을 초기화에 입력하게 변경
self.spec_token = spec_token
def forward(self, src, tar=None, TF_ratio=1, BW=1):
# 인코더의 출력 = context_vector
context_h, context_c = self.encode(src)
# 스페셜 토큰에서 SOS, EOS, PAD의 정수인코딩값 추출
en_sos = self.spec_token.index('<SOS>')
en_eos = self.spec_token.index('<EOS>')
en_pad = self.spec_token.index('<PAD>')
if tar is not None:
# 배치사이즈, 연산위치 정보 추출(tar 기준으로)
BS, tar_seq_len = tar.size()
device = tar.device
# 디코더의 첫번째 토큰을 <SOS>에 (BS, 1)차원으로 생성
# 이때 정답지(tar)의 맨 앞토큰은 <SOS>로 채워져 있으니 이를 이용한다.
input_token = tar[:, 0].unsqueeze(1)
outputs = [] # 출력 디코드 결과를 저장
# 임의 난수를 (BS)차원으로 생성 후 TF_ratio비율정보를 받아서
# 마스크 플래그로 변환, 이때 TF_ratio는 0~1 사이값
# 1에 가까울수록 대부분의 Flag는 True가 되서 지도학습비율이 올라감
TF_flag = torch.rand(BS, device=device) < TF_ratio
# 토큰 단위로 예측이니 자가 회귀 방식임
h, c = context_h, context_c
# tar seq는 맨 처음 토큰을 <SOS>로 채웟으니 1번부터 시작
for t in range(1, tar_seq_len):
# 토큰단위로 입력이니 출력은 (bs, 1, tar_vocab)이다.
out_tokens, h, c = self.decode(input_token, h, c)
outputs.append(out_tokens)
# 마스크 플래그가 True : 지도학습 방식으로 동작
# 마스크 플래그가 False : 비지도학습-자가 회귀방식으로 동작
input_token = torch.where(TF_flag.unsqueeze(1),
tar[:, t].unsqueeze(1),
out_tokens.argmax(dim=-1))
# 최종 출력 모양 조정
outputs = torch.cat(outputs, dim=1) # (BS, tar_seq_len-1, tar_vocab)
# (BS, 1, tar_vocab) 차원의 sos 토큰 인덱스로 채워진 텐서를 만듬
sos_tokens = torch.full((BS, 1, outputs.size(-1)), en_sos, device=device)
# sos_tokens랑 outputs를 합쳐서 (BS, tar_seq_len, tar_vocab)가 되게 함
outputs = torch.cat([sos_tokens, outputs], dim=1)
return outputs # (BS, tar_seq_len, tar_vocab)
else: # 정답지가 없는 평가모드
# 배치사이즈, 연산위치 정보 추출(src 기준으로)
BS, src_seq_len = src.size()
device = src.device
# 최대 디코딩 길이 지정 안했으면 원문 seq_len을 쓰자
if self.max_len is None:
self.max_len = src_seq_len
# 디코더의 첫 토큰을 <SOS>에 (BS,1)로 채우고 맨 앞에 Beam_width적용
input_token = torch.full((BW, BS, 1), en_sos).to(device)
# 디코더 첫 토큰에 대한 확률정보 생성 (BW, BS, 1)
pred_probs = F.softmax(input_token.type(torch.float), dim=0)
# 최종 출력 시퀀스는 Beam_search의 후보군 시퀀스를 다 내보내는 것으로 함
# 후보 시퀀스를 다 내보낸 뒤 나중에 처리하는 것으로
outputs = torch.full((BS, self.max_len, BW), en_pad).to(device)
# <EOS>토큰을 각 beam search, batch_size에서 예측했으면 이를 감지하는 flag
pad_mask_flag = torch.zeros((BW, BS), dtype=torch.bool,
device=device)
# context_vector의 차원은 (num_layers, BS, hid_dim)임
# 이것을 (BW, num_layers, BS, hid_dim) 4차원으로 반복복제로 늘림
context_h = context_h.unsqueeze(0).repeat(BW, 1, 1, 1)
context_c = context_c.unsqueeze(0).repeat(BW, 1, 1, 1)
# 토큰 단위로 예측이니 자가 회귀 방식임
h, c = context_h, context_c
for t in range(self.max_len):
# 디코더에 입력하여 out_tokens를 만들어야 하니 입력 가능하게
# BW * BS를 곱해서 3차원으로 축소
input_token = input_token.view(BW*BS, -1) #(BW*BS, 1)
h = h.view(h.size(1), BW*BS, h.size(3)) # (nL, BW*BS, hid_dim)
c = c.view(c.size(1), BW*BS, c.size(3)) # (nL, BW*BS, hid_dim)
# 출력된 out_tokens의 차원은 (BW*BS, 1, tar_vocab)이다.
out_tokens, h, c = self.decode(input_token, h, c)
# 원래 차원인 (BW, BS ,,)순으로 모두 복원
out_tokens = out_tokens.view(BW, BS, 1, -1) # (BW, BS, 1, tar_vocab)
# h = h.view(BW, h.size(0), BS, -1) # (BW, nL, BS, hid_dim)
# c = c.view(BW, c.size(0), BS, -1) # (BW, nL, BS, hid_dim)
# 모델이 예측한 토큰에 대한 확률정보 생성
cur_probs = F.softmax(out_tokens, dim=-1) # (BW, BS, 1, tar_vocab)
# cur_probs의 가장 높은 확률을 가진 BW(K)개 데이터 val, idx 추출
# val, idx의 BW개를 선택한 차원정보 : (BW, BS, 1, BW)
top_k_probs, top_k_idxs = torch.topk(input=cur_probs, k=BW, dim=-1)
# pred_probs의 차원을 늘려서 (BW, BS, 1, 1)로 만든 다음
# 브로드 캐스팅 방법으로 top_k_probs와 곱한 뒤 (BW, BS, 1, BW)
# reshape를 적용하여 (BW*BW, BS, 1) 차원으로 변환
scores = (pred_probs.unsqueeze(-1) * top_k_probs).view(BW*BW, BS, 1)
# sorces 정보에 대해서 beam search로 BW개만큼의 데이터, idx 추출 (BW, BS, 1)
_, top_sorce_idx = torch.topk(input=scores, k=BW, dim=0)
# context vector 추적 및 추적정보를 바탕으로 갱신하기
re_h = h.permute(1, 0, 2) # (BW * BS, nL, hid_dim)
re_c = c.permute(1, 0, 2) # (BW * BS, nL, hid_dim)
# (BW, BS, 1) -> (BW*BS, 1, 1) -> (BW*BS, nL, hid_dim)
track_h_idx = (top_sorce_idx // BW).reshape(-1, 1, 1).expand(-1, re_h.size(1), re_h.size(2))
track_c_idx = (top_sorce_idx // BW).reshape(-1, 1, 1).expand(-1, re_c.size(1), re_c.size(2))
re_h = torch.gather(re_h, 0, track_h_idx) # (BW*BS, nL, hid_dim)
re_c = torch.gather(re_c, 0, track_c_idx) # (BW*BS, nL, hid_dim)
# (BW*BS, nL, hid_dim) -> (nL, BW*BS, hid_dim) -> (BW, nL, BS, hid_dim)
h = re_h.permute(1, 0, 2).reshape(BW, h.size(0), BS, h.size(2))
c = re_c.permute(1, 0, 2).reshape(BW, c.size(0), BS, c.size(2))
# 이전토큰의 확률정보 pred_probs 업데이트
# cur_probs에서 상위 BW개를 추출한 top_k_probs (BW, BS, 1, BW)를
# (BW*BW, BS, 1)로 차원전환한 뒤 score의 BW개 idx 정보로 값 서치
# 따라서 업데이트 된 pred_probs는 (BW, BS, 1)차원으로 정상적으로 업데이트
pred_probs = torch.gather(top_k_probs.view(BW*BW, BS, 1), 0, top_sorce_idx)
# 입력토큰은 top_sorce_idx 정보를 바탕으로 top_k_idxs의 인덱스 정보를 찾으면 됨
input_token = torch.gather(top_k_idxs.view(BW*BW, BS, 1), 0, top_sorce_idx)
# out_tokes를 최종 출력물을 outputs의 t번째 seq에 덮어쓰기
outputs[:, t, :] = input_token.squeeze(-1).transpose(0, 1) # (BS, max_len, BW)
# 업데이트한 input_token이 <EOS>토큰의 idx를 예측햇는지 검토
eos_indices = (input_token.squeeze(1) == en_eos)
# OR연산을 통해 pad_mask_flag가 <EOS>토큰의 idx를 예측했으면 TRUE로 전환한다
pad_mask_flag = pad_mask_flag | eos_indices
# 모든 샘플이 EOS예측
if pad_mask_flag.all():
break
return outputs # (BS, max_len, BW)import torch
import torch.nn as nn
import torch.nn.functional as F
class Seq2Seq_GRU(nn.Module):
def __init__(self, encoder, decoder, spec_token, max_len=None):
super(Seq2Seq_GRU, self).__init__()
self.encode = encoder
self.decode = decoder
# 최대 디코딩 길이 설정
self.max_len = max_len
# 스페셜 토큰을 초기화에 입력하게 변경
self.spec_token = spec_token
def forward(self, src, tar=None, TF_ratio=1, BW=1):
# 인코더의 출력 = context_vector
context_h = self.encode(src)
# 스페셜 토큰에서 SOS, EOS, PAD의 정수인코딩값 추출
en_sos = self.spec_token.index('<SOS>')
en_eos = self.spec_token.index('<EOS>')
en_pad = self.spec_token.index('<PAD>')
if tar is not None:
# 배치사이즈, 연산위치 정보 추출(tar 기준으로)
BS, tar_seq_len = tar.size()
device = tar.device
# 디코더의 첫번째 토큰을 <SOS>에 (BS, 1)차원으로 생성
# 이때 정답지(tar)의 맨 앞토큰은 <SOS>로 채워져 있으니 이를 이용한다.
input_token = tar[:, 0].unsqueeze(1)
outputs = [] # 출력 디코드 결과를 저장
# 임의 난수를 (BS)차원으로 생성 후 TF_ratio비율정보를 받아서
# 마스크 플래그로 변환, 이때 TF_ratio는 0~1 사이값
# 1에 가까울수록 대부분의 Flag는 True가 되서 지도학습비율이 올라감
TF_flag = torch.rand(BS, device=device) < TF_ratio
# 토큰 단위로 예측이니 자가 회귀 방식임
h = context_h
# tar seq는 맨 처음 토큰을 <SOS>로 채웟으니 1번부터 시작
for t in range(1, tar_seq_len):
# 토큰단위로 입력이니 출력은 (bs, 1, tar_vocab)이다.
out_tokens, h = self.decode(input_token, h)
outputs.append(out_tokens)
# 마스크 플래그가 True : 지도학습 방식으로 동작
# 마스크 플래그가 False : 비지도학습-자가 회귀방식으로 동작
input_token = torch.where(TF_flag.unsqueeze(1),
tar[:, t].unsqueeze(1),
out_tokens.argmax(dim=-1))
# 최종 출력 모양 조정
outputs = torch.cat(outputs, dim=1) # (BS, tar_seq_len-1, tar_vocab)
# (BS, 1, tar_vocab) 차원의 sos 토큰 인덱스로 채워진 텐서를 만듬
sos_tokens = torch.full((BS, 1, outputs.size(-1)), en_sos, device=device)
# sos_tokens랑 outputs를 합쳐서 (BS, tar_seq_len, tar_vocab)가 되게 함
outputs = torch.cat([sos_tokens, outputs], dim=1)
return outputs # (BS, tar_seq_len, tar_vocab)
else: # 정답지가 없는 평가모드
# 배치사이즈, 연산위치 정보 추출(src 기준으로)
BS, src_seq_len = src.size()
device = src.device
# 최대 디코딩 길이 지정 안했으면 원문 seq_len을 쓰자
if self.max_len is None:
self.max_len = src_seq_len
# 디코더의 첫 토큰을 <SOS>에 (BS,1)로 채우고 맨 앞에 Beam_width적용
input_token = torch.full((BW, BS, 1), en_sos).to(device)
# 디코더 첫 토큰에 대한 확률정보 생성 (BW, BS, 1)
pred_probs = F.softmax(input_token.type(torch.float), dim=0)
# 최종 출력 시퀀스는 Beam_search의 후보군 시퀀스를 다 내보내는 것으로 함
# 후보 시퀀스를 다 내보낸 뒤 나중에 처리하는 것으로
outputs = torch.full((BS, self.max_len, BW), en_pad).to(device)
# <EOS>토큰을 각 beam search, batch_size에서 예측했으면 이를 감지하는 flag
pad_mask_flag = torch.zeros((BW, BS), dtype=torch.bool,
device=device)
# context_vector의 차원은 (num_layers, BS, hid_dim)임
# 이것을 (BW, num_layers, BS, hid_dim) 4차원으로 반복복제로 늘림
context_h = context_h.unsqueeze(0).repeat(BW, 1, 1, 1)
# 토큰 단위로 예측이니 자가 회귀 방식임
h = context_h
for t in range(self.max_len):
# 디코더에 입력하여 out_tokens를 만들어야 하니 입력 가능하게
# BW * BS를 곱해서 3차원으로 축소
input_token = input_token.view(BW*BS, -1) #(BW*BS, 1)
h = h.view(h.size(1), BW*BS, h.size(3)) # (nL, BW*BS, hid_dim)
# 출력된 out_tokens의 차원은 (BW*BS, 1, tar_vocab)이다.
out_tokens, h = self.decode(input_token, h)
# h = h.view(BW, h.size(0), BS, -1) # (BW, nL, BS, hid_dim)
# 원래 차원인 (BW, BS ,,)순으로 모두 복원
out_tokens = out_tokens.view(BW, BS, 1, -1) # (BW, BS, 1, tar_vocab)
# 모델이 예측한 토큰에 대한 확률정보 생성
cur_probs = F.softmax(out_tokens, dim=-1) # (BW, BS, 1, tar_vocab)
# cur_probs의 가장 높은 확률을 가진 BW(K)개 데이터 val, idx 추출
# val, idx의 BW개를 선택한 차원정보 : (BW, BS, 1, BW)
top_k_probs, top_k_idxs = torch.topk(input=cur_probs, k=BW, dim=-1)
# pred_probs의 차원을 늘려서 (BW, BS, 1, 1)로 만든 다음
# 브로드 캐스팅 방법으로 top_k_probs와 곱한 뒤 (BW, BS, 1, BW)
# reshape를 적용하여 (BW*BW, BS, 1) 차원으로 변환
scores = (pred_probs.unsqueeze(-1) * top_k_probs).view(BW*BW, BS, 1)
# sorces 정보에 대해서 beam search로 BW개만큼의 데이터, idx 추출 (BW, BS, 1)
_, top_sorce_idx = torch.topk(input=scores, k=BW, dim=0)
# context vector 추적 및 추적정보를 바탕으로 갱신하기
re_h = h.permute(1, 0, 2) # (BW * BS, nL, hid_dim)
# (BW, BS, 1) -> (BW*BS, 1, 1) -> (BW*BS, nL, hid_dim)
track_h_idx = (top_sorce_idx // BW).reshape(-1, 1, 1).expand(-1, re_h.size(1), re_h.size(2))
re_h = torch.gather(re_h, 0, track_h_idx) # (BW*BS, nL, hid_dim)
# (BW*BS, nL, hid_dim) -> (nL, BW*BS, hid_dim) -> (BW, nL, BS, hid_dim)
h = re_h.permute(1, 0, 2).reshape(BW, h.size(0), BS, h.size(2))
# 이전토큰의 확률정보 pred_probs 업데이트
# cur_probs에서 상위 BW개를 추출한 top_k_probs (BW, BS, 1, BW)를
# (BW*BW, BS, 1)로 차원전환한 뒤 score의 BW개 idx 정보로 값 서치
# 따라서 업데이트 된 pred_probs는 (BW, BS, 1)차원으로 정상적으로 업데이트
pred_probs = torch.gather(top_k_probs.view(BW*BW, BS, 1), 0, top_sorce_idx)
# 입력토큰은 top_sorce_idx 정보를 바탕으로 top_k_idxs의 인덱스 정보를 찾으면 됨
input_token = torch.gather(top_k_idxs.view(BW*BW, BS, 1), 0, top_sorce_idx)
# out_tokes를 최종 출력물을 outputs의 t번째 seq에 덮어쓰기
outputs[:, t, :] = input_token.squeeze(-1).transpose(0, 1) # (BS, max_len, BW)
# 업데이트한 input_token이 <EOS>토큰의 idx를 예측햇는지 검토
eos_indices = (input_token.squeeze(1) == en_eos)
# OR연산을 통해 pad_mask_flag가 <EOS>토큰의 idx를 예측했으면 TRUE로 전환한다
pad_mask_flag = pad_mask_flag | eos_indices
# 모든 샘플이 EOS예측
if pad_mask_flag.all():
break
return outputs # (BS, max_len, BW)LSTM버전, GRU버전 둘다 모델 선언은 위와 같이 진행한다.
실습 준비
# 학습 실험 조건을 구분하기 위한 키
model_key = ['LSTM', 'GRU']
metrics_key = ['Loss', '정확도']# Seq2Seq의 LSTM버전 인스턴스화
encoder_lstm = Encoder_LSTM(src_VS, EMB_DIM, UNIT_DIM,
num_layer=NUM_Layers, bi=BI_DIR)
decoder_lstm = Decoder_LSTM(tar_VS, EMB_DIM, UNIT_DIM,
num_layer=NUM_Layers, bi=BI_DIR)
Translater_lstm = Seq2Seq_LSTM(encoder_lstm, decoder_lstm,
spec_token=spec_token, max_len=tar_SL)
# Seq2Seq의 GRU버전 인스턴스화
encoder_gru = Encoder_GRU(src_VS, EMB_DIM, UNIT_DIM,
num_layer=NUM_Layers, bi=BI_DIR)
decoder_gru = Decoder_GRU(tar_VS, EMB_DIM, UNIT_DIM,
num_layer=NUM_Layers, bi=BI_DIR)
Translater_gru = Seq2Seq_GRU(encoder_gru, decoder_gru,
spec_token=spec_token, max_len=tar_SL)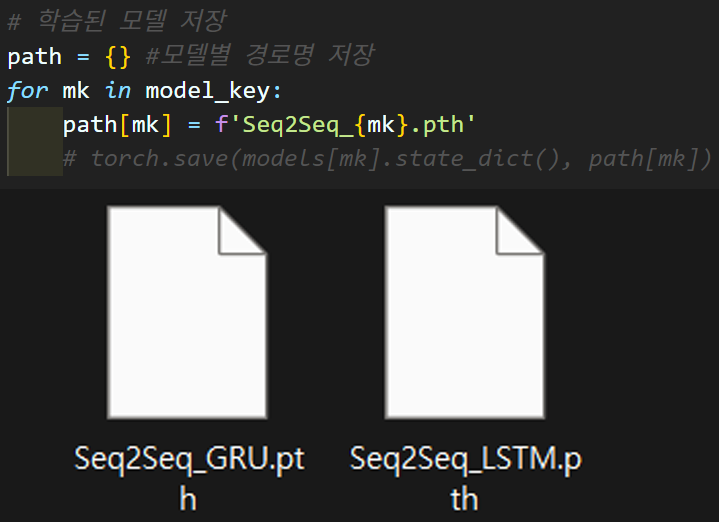
이전 포스트 실습을 충실히 이행했다면
선언한 모델의 학습된 가중치 정보
Seq2Seq_LSTM.pth, Seq2Seq_GRU.pth 두개의 파일을 저장했을 것이다.
# 저장된 모델 불러오기
load_model = {
'LSTM': Translater_lstm, # LSTM 모델 인스턴스 생성
'GRU': Translater_gru # GRU 모델 인스턴스 생성
}
for mk in model_key:
load_model[mk].load_state_dict(torch.load(path[mk], weights_only=True))
#추론기는 CPU에서 돌리자
load_model[mk] = load_model[mk].to('cpu')저장한 모델을 불러오고
import random
# 테스트 데이터셋에서 샘플을 추출
# 전체 테스트 데이터 개수정보를 추출
num_test = padded_src_test.shape[0]
sample_epoch = 5 #추출할 샘플 개수 정의
indices = random.sample(range(num_test), sample_epoch)
# 추출한 샘플번호를 바탕으로 Test 데이터셋에서 무작위 추출
S_src_test = padded_src_test[indices]
S_tar_test = padded_tar_test[indices]
# 원문 데이터만 텐서 자료형으로 변환
TS_src_test = torch.tensor(S_src_test, dtype=torch.long)추론을 위한 데이터셋 추출 데이터로더 생성을 위한 전처리 작업을 수행한다.
모델 추론
from Seq_trainer import *
# 추론 결과를 저장할 딕셔너리
tar_dict = {key: [] for key in model_key}
BW = 1 #Beam Search의 Search Space 계수(Beam_width)값
for key in model_key:
print(f"\n--현재 추론 조건: [Seq2Seq_{key}]--") # 조건에 맞는 실험시작
for idx in tqdm(range(sample_epoch)): #추론 에포크별 추론 시작
# 입력되는 원문 차원을 (1, src_seq_len)으로 만들기 위한 코드
iter_src_data = TS_src_test[idx].unsqueeze(0)
# 모델 추론 -> 추론결과는 (bs, max_len, BW) ndarray타입임
# BW 옵션이 1 -> 사실상 Greedy Search랑 같은 결과
# BW 옵션이 1 이상 -> 제대로된 Beam Search 작업수행
tar_infer_doc = model_inference(load_model[key],
iter_src_data, BW=BW)
tar_dict[key].append(tar_infer_doc)Seq_trainer.py파일에 Beam Search의 인자값인 Search space 계수 : Beam_width(BW)를 인자로 받을 수 있도록
model_inference 함수가 살짝 업데이트 되었다.
# 모델 추론용 함수
def model_inference(model, src_data, BW=1):
device = next(model.parameters()).device # 모델의 연산위치 확인
model.eval() # 모델을 평가 모드로 설정
with torch.no_grad(): #평가모드에서는 그래디언트 계산 중단
src_data = src_data.to(device)
# 추론에서 입력되는 데이터 구조는 (1, src_seq_len)이다.
# 추론 과정이기에 정답지(tar_data)는 입력하지 않는다.
# Beamsearch의 search_space(Beam_width)값 설정
tar_infer = model(src_data, BW=BW)
# 추론결과는 (BS=1, max_len, BW) -> numpy자료형 변환
nd_tar_infer = tar_infer.cpu().numpy()
if nd_tar_infer.size(0) == 1: # BS가 1 인 경우
return nd_tar_infer[0] #BS 차원을 날림
else:
return nd_tar_infer #(BS, max_len, BW)BW의 기본값은 1로 설정했는데 기본값으로 동작하면
기존의 Greedy Search랑 동일한 결과를 도출한다
통상 Beam Search을 적용한다 하면 BW = 3~5사이의 값을 쓰는 듯 하다.
추론 결과 후처리 코드
idx_list = range(1, sample_epoch+1)
for idx, src, pred_lstm, pred_gru, tar in zip(idx_list, S_src_test,
tar_dict['LSTM'],
tar_dict['GRU'],
S_tar_test):
# 원문, 모델번역문_1, 모델번역문_2, 정답번역문 순으로 디코딩
decode_src = Translater_post_processor(src, idx_to_src, spec_token)
de_pred_lstm_list = [] #Beam_search를 수행함으로 인한 후보군 데이터를 저장하는 리스트
de_pred_gru_list = [] #Beam_search를 수행함으로 인한 후보군 데이터를 저장하는 리스트
for BW_i in range(BW):
de_pred_lstm = Translater_post_processor(pred_lstm[:, BW_i], idx_to_tar, spec_token)
de_pred_gru = Translater_post_processor(pred_gru[:, BW_i], idx_to_tar, spec_token)
de_pred_lstm_list.append(de_pred_lstm)
de_pred_gru_list.append(de_pred_gru)
decode_tar = Translater_post_processor(tar, idx_to_tar, spec_token)
print(f"{idx}번째 번역 결과 확인")
print(f"원문(src) : {decode_src}", end='\n\n')
for BW_i in range(BW):
print(f"seqLSTM_{BW_i}_번역 : {de_pred_lstm_list[BW_i]}")
print(f"seq-GRU_{BW_i}_번역 : {de_pred_gru_list[BW_i]}")
print(f"\n번역문(tar) : {decode_tar}")
print("==============================\n")추론 결과 후처리 코드는 위 코드를 활용한다.
추론 결과 - Greedy Search
첫번째로 BW = 1인 기본상태 Greedy Search의 결과물이다.

추론결과 Beam Search (
BW = 3)
다음으로 BW = 3을 적용한 추론결과이다.

왜.. Greedy Search보다 성능이 떨어지는 번역품질이 나오는지.. 음.. 알수가 없다
4. BLEU Score
다음으로 다룰 내용은 BLEU Score(Bilingual Evaluation Understudy Score) 인데
요약을 하자면 번역 성능을 평가하는 지표로
사람이 직접 평가하는 Human Evaluation방법이 가장 많이 쓰이기도 하고 직관적이긴 하지만
Human Evaluation는 정량지표화 하기가 조금 어려운 부분이 있다.
이를 아래의 수식
-
: 모델의 예측(candidate), 정답지(reference)를 비교할 때
n-gram방식으로 비교를 수행하며, 각n-gram별 정밀도를 의미함 -
:
n-gram별로 적용하는 가중치값
통상n-gram은 1~4 gram을 적용하고, 가장 편리하게 균등 가중치(0.25, 0.25, 0.25, 0.25)식으로 적용 -
: n-gram의 최대 차원, 보통 4를 사용
-
: Brevity Penalty로, 번역문의 길이가 정답지 대비 짧으면 짧을수록 패널티를 주는 값
이때, 수식기반으로 패널티를 부여
- : Candidate (모델예측값)의 총 길이(
max_len) - : Reference (참조 번역문)의 총 길이(
tar_seq_len)
으로 정량화 하여 번역품질의 지표로 사용되는 평가지표라 보면 된다.
이걸 좀 더 자세하게 설명하려면 번역품질에 대한 정량지표를 설계하는 과정에 대한 역사를 공부해야 하는데
음.. 재미도 없고 이미 Beam Search에서 마음이 꺾여서 이 부분은 넘어가고
바로 코드를 첨부하도록 하겠다.
import numpy as np
from collections import Counter
from scipy.special import softmax
def BLEU_Score(candidate, reference, p_list=None, ignore_idx=0):
if p_list is None:
p_list = [0.25, 0.25, 0.25, 0.25] # 기본적으로 균등 가중치 설정
def n_gram_precision(candidate, reference, n, ignore_idx):
candidate_n_grams = [tuple(candidate[i:i+n])
for i in range(len(candidate) - n + 1)
if ignore_idx not in candidate[i:i+n]]
reference_n_grams = [tuple(reference[i:i+n])
for i in range(len(reference) - n + 1)
if ignore_idx not in reference[i:i+n]]
candidate_counter = Counter(candidate_n_grams)
reference_counter = Counter(reference_n_grams)
overlap = sum(min(candidate_counter[ng], reference_counter[ng])
for ng in candidate_counter)
total = sum(candidate_counter.values())
if total == 0:
return 0
else:
return overlap / total
best_bleu_score = 0
best_candidate = None
bleu_score_list = []
for i in range(candidate.shape[1]): # BW 개수만큼 후보군을 반복
current_candidate = candidate[:, i]
precisions = []
for n in range(1, 5): # 1-gram, 2-gram, 3-gram, 4-gram
p_n = n_gram_precision(current_candidate, reference, n, ignore_idx)
# Smoothing: precision이 0인 경우 작은 값(예: 1e-9)으로 대체
precisions.append(p_n if p_n > 0 else 1e-9)
log_precisions = [p_list[n-1] * np.log(p) for n, p in
enumerate(precisions, start=1)]
bleu_score = np.exp(sum(log_precisions))
bleu_score_list.append(bleu_score*(10^20))
# bleu_score_result의 값이 원체 작아서 softmax 처리
bleu_score_list = softmax(bleu_score_list)
# 가장 높은 BLEU score를 가진 후보군 선택
best_idx = np.argmax(bleu_score_list)
best_bleu_score = bleu_score_list[best_idx]
best_candidate = candidate[:, best_idx]
bleu_dict = {
'최고BLUE점수': f'{best_bleu_score * 100:.2f}%',
'Best_y예측': best_candidate
}
return bleu_dict먼저 Beam Search 알고리즘을 도입해서 모델의 예측값이 여러개의 후보군을 산출하고 있고
여기에 다시 Greedy Search를 적용해서 가장 좋은 번역이라 생각하는 모델의 예측값 를 연산하는 것은 탐색알고리즘을 중복해서 사용하는 비 효율성이 있기에
번역 품질에 대한 정량지표인BLEU Score를 활용해서
를 산출하는게 목표인 함수라 볼 수 있다.
그러나 막상 결과값을 확인해보면 BLEU Score값이 매우 작은 0에 가까운 값이 나와서
다른 후보군들과 softmax를 구동해야 좀 의미있는 데이터를 확인할 수 있기도 하고
또 BLEU Score가 미분 불가능한 점으로 인해 Loss_fn으로도 활용이 불가능한
정말 번역 품질에 대한 평가지표 외의 기능은 기대하기가 어려운 부분이 있어 살짝 김 새는 내용이긴 하다...
뭐.. BLEU Score를 적용해서 를 산출하고 이를 시각화 하기 좋게 디코딩하면 아래의 추론 결과물을 확인 할 수 있다.
# BLEU score를 적용하여 원문 / 예측구문 / 번역문 결과 확인
idx_list = range(1, sample_epoch+1)
for idx, src, pred_lstm, pred_gru, tar in zip(idx_list, S_src_test,
tar_dict['LSTM'],
tar_dict['GRU'],
S_tar_test):
# 원문, 모델번역문_1, 모델번역문_2, 정답번역문 순으로 디코딩
decode_src = Translater_post_processor(src, idx_to_src, spec_token)
# 모델 예측 결과물에 대하여 BLEU 스코어 및 Best_y_pred 추출
BLEU_LSTM = BLEU_Score(pred_lstm, tar)
BLEU_LSTM_score = BLEU_LSTM['최고BLUE점수']
b_de_pred_lstm = Translater_post_processor(BLEU_LSTM['Best_y예측'], idx_to_tar, spec_token)
BLEU_GRU = BLEU_Score(pred_gru, tar)
BLEU_GRU_score = BLEU_GRU['최고BLUE점수']
b_de_pred_gru = Translater_post_processor(BLEU_GRU['Best_y예측'], idx_to_tar, spec_token)
decode_tar = Translater_post_processor(tar, idx_to_tar, spec_token)
print(f"{idx}번째 번역 결과 확인")
print(f"원문(src) : {decode_src}", end='\n')
print(f"seqLSTM_점수: {BLEU_LSTM_score}\nseqLSTM_번역: {b_de_pred_lstm}")
print(f"seqGRU_점수: {BLEU_GRU_score}\nseqGRU_번역: {b_de_pred_gru}")
print(f"번역문(tar) : {decode_tar}")
print("==============================\n")
음.. 애초에 Beam Search를 적용하면서 기존 Greedy Search 대비 번역품질이 많이 나빠진 느낌이 있기에 BLEU Score를 적용해도 감흥이 그리 있는 편은 아니다.
다음 포스트의 주제가 Seq2Seq with Attention이어서
살짝 쉬어가는 느낌으로 고전적인 번역 품질 향상 방법론을 공부했는데
음.. 코드짜는 노력 대비 성과가 없어서 많이 아쉬운 파트였다.

https://github.com/tbvjvsladla/Seq2Seq
이번 포스트의 실습 내용은
위 깃허브 저장소에 업로드하였습니다
Seq_trainer.py파일이 업데이트 되었으며,
주요 실습내용은 seq2seq실습-03 BLEU Score.ipynb를 참조 바랍니다.
