
개요
본 블로그 포스팅은 수도권 ICT 이노베이션 스퀘어에서 진행하는 AI 핵심 기술 집중 클래스의 자연어처리(NLP) 강좌 내용을 필자가 다시 복기한 내용에 관한 것입니다.
1. Seq2Seq 개선사항
1.1 Reversing the Source Sentences

NLP- Seq to Seq (4) : 번역에서 소개한 논문 : Sequence to Sequence Learning with NN에서 수행하지 않은 성능 개선사항이 하나 존재하는데 Reversing the Source Sentences
원문(src)시퀀스를 반전하여 입력하는 것이다.

이렇게 시퀀스을 반전(역방향)으로 입력하는 이유는 순환 신경망 계열의 모델은 모두 장기 의존성 문제 (Long-Term Dependency Problem)문제가 존재하기에 중요한 정보가 시퀀스 내에서 맨 앞에 위치하고 있는 경우라면 정보 희석이 많이 되어서 이를 대응하기 위한 방안이라 보면 된다.
물론 이것은 언어가 SVO구조로 중요 키워드가 맨 앞에 위치하는 영어, 중국어, 프랑스어 한정으로 성능 향상을 꾀할 수 있는 것이지
언어 구조가 SOV 형태를 따라서 중요 키워드가 맨 뒤에 위치하는 한국어, 일본어, 터키어에는 오히려 성능 하락이 발생할 수 있다.

한국어에는 Reversing the Source Sentences을 적용하면 오히려 성능하락이 되는것이 당연하다..
따라서 위와 같은 개선사항은 SVO언어 SVO언어 간 기계번역에서만 적용가능하기에 강인하지 않다.
그러면 위 아이디어를 차용하면서 동시에 범용성을 확보하려면 어떻게 해야하는가?
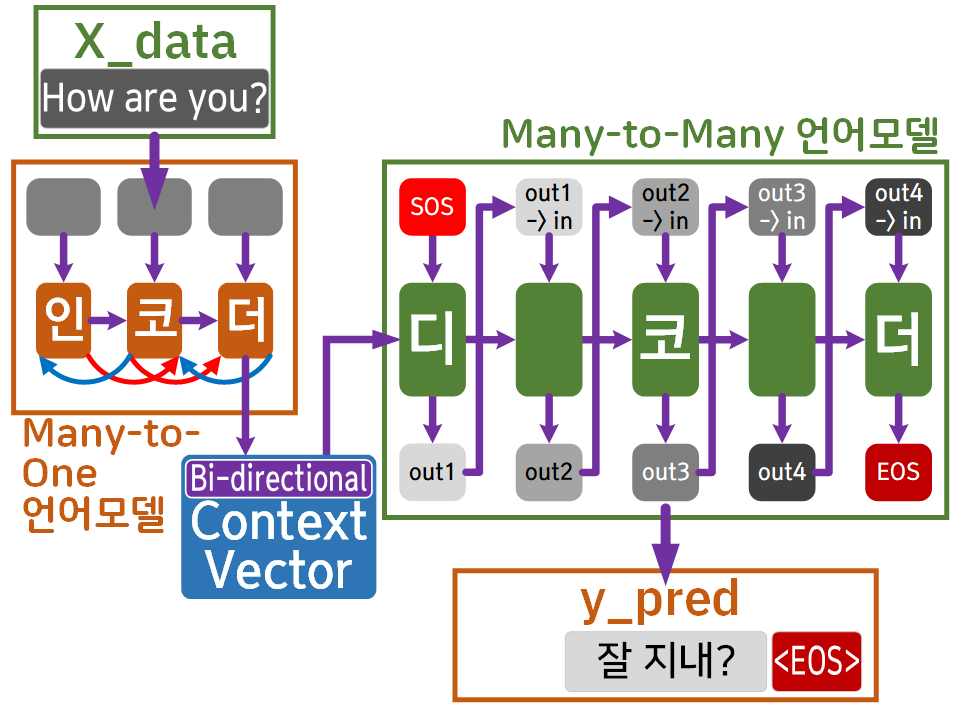
위 사진처럼 인코더 항목에서 Bi-directional을 적용한
Context Vector을 만든 뒤 이를 디코더에 전달하는 식으로 모델의 구조를 변형한다.
이렇게 하면 단순하게 생각해도 Context Vector의 정보가 늘어나기에 좀 더 풍부한 표현력을 갖출 수 있으며, 양방향으로 문맥 정보를 인코딩하기에 앞서 언급한 장기 의존성 문제에도 자유로워진다.
1.2 Peeky Seq2Seq
Peeky(엿보기) 방법을 적용한 Seq2Seq모델은
Learning Phrase Representations using RNN Encoder–Decoder for Statistical Machine Translation 논문에서 적용한 방법론이며,
이게 조금 애매한게 논문에서는 Peeky이란 단어는 전혀 등장하지 않고 Seq2Seq 모델에 대한 설명도 RNN Encoder–Decoder라는 이름으로 부르고 있고
Backbone도 Seq2Seq는 통상적으로 LSTM을 사용하는데
논문에서는 GRU를 백본으로 사용하고 있다.
또 Peeky(엿보기) 기능을 적용하여 RNN Encoder–Decoder를 설계했다는 내용도
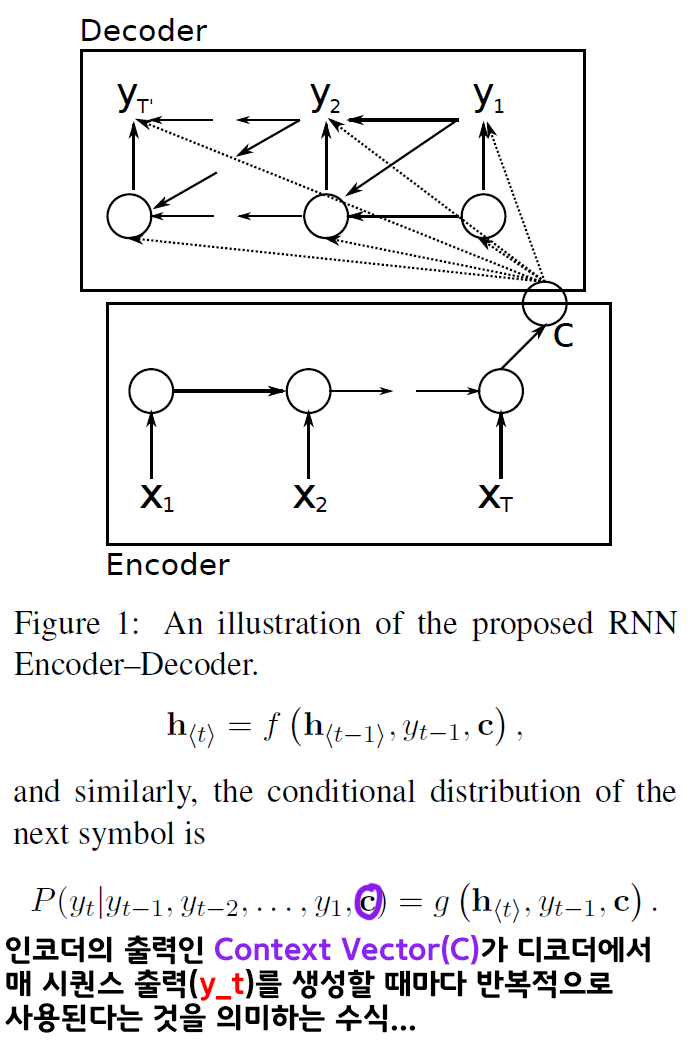
위 그림과 수식으로 간접적으로 확인이 가능하다.
아무튼 인코더의 최종출력 Context Vector이 매 디코더의 시퀀스 생성시 마치 Residual connection처럼 반복입력이 되는 것을 논문에서 확인할 수 있고
이를 도식화 하면 아래와 같아진다.
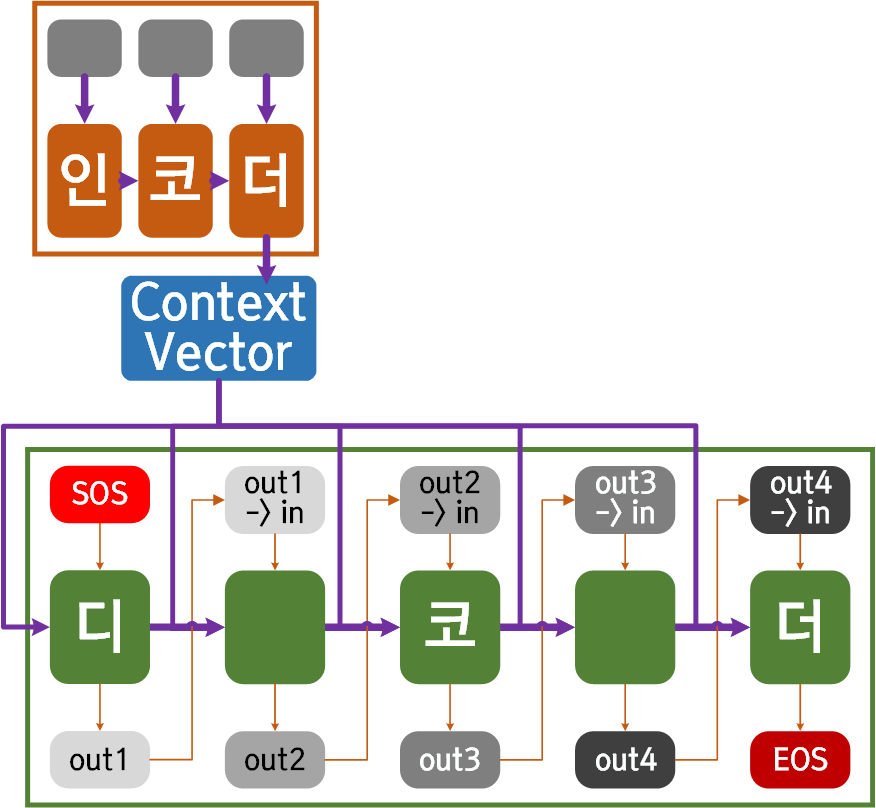
여기서 문제가 되는 부분이 매 디코더 연산마다 인코더의 출력정보인 Context Vector를 합산해서 넣어줘야 하니 이 부분을 어떻게 코드화 할지가 살짝 난감해지는데
이는 해당 논문의 부록에 첨부되어 있다.
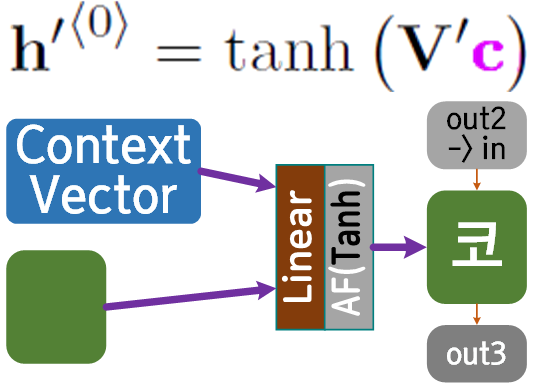
논문의 뒤편에는 점화식 형식으로 수식이 더 기재되어 있지만
요약을 하자면
인코더의 Context Vector와 디코더의 hidden state를 concat한 뒤 nn.Linear AF(tanh)를 차례로 통과시키면 된다.
이렇게 Seq2Seq의 개선사항으로
1) 인코더에는 Bi-directional옵션 활성화
2) Peeky 방법론 적용
두가지를 코드화 하고자 한다
2. 개선사항 코드화
인코더 :
Bi-directional옵션 활성화

먼저 기존 인코더에서 bidirectional옵션 인자값 bi = True를 입력하면 자동으로 양방향 시퀀스 학습 옵션이 활성화 된다.
이때 출력되는 Context Vector의 shape가
(num_layers x 2, Batch_size, hid_dim)
으로 차원정보가 구성됨을 숙지해둬야 한다.
이 차원정보를 (num_layers, Batch_size, hid_dim x 2)으로 reshape를 수행해야 한다.
이 부분에 대한 코드는 향후 기술하도록 하겠다.
디코더 : 인코더의 양방향 학습 옵션을 확인

디코더는 크게 바뀌는 부분은 없으나, 인코더가 양방향 학습 모드이고,
향후 차원 변환을 통해 인코더의 Context Vector차원이
num_layers, Batch_size, hid_dim x 2)으로 바뀌게 되는것에 대비를 해야 한다.
따라서 맨 앞 구문
self.rnn_dim = rnn_dim * 2 if bi else rnn_dim구문으로 이에 대응한다.
참고로 인코더의 Context Vector는 향후 디코더의 hidden_state과 같은 차원이고
hidden_size == rnn_dim == hid_dim == UNIT_DIM
== 인코더-디코더 연결차원 이다.
이게 코드를 작성하다 보니 내용은 중복인데 단어가 다르게 작성된게 꽤 된다..
Peeky Seq2Seq
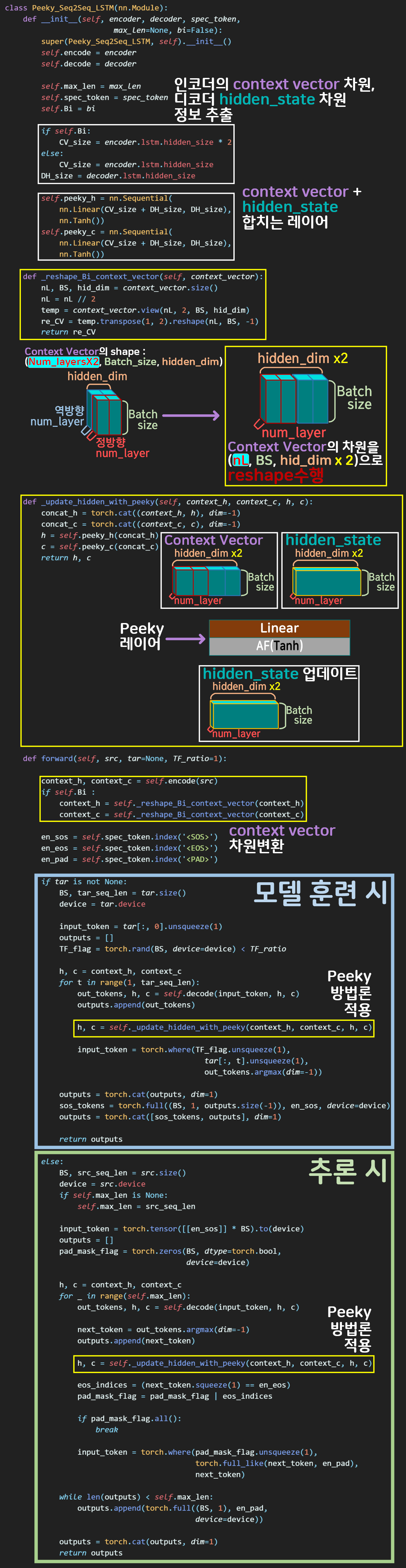
마지막으로 Peeky 방법론을 적용한 Seq2Seq 설계 구문이다.
인코더의 Context Vector을 설계 목적에 맞게 차원변환을 수행하는 함수와
Context Vector + hidden_state 를 수행한 뒤 이를 Peeky_layer에 넘겨
최종적으로 디코더에서 사용하는 hidden_state 를 업데이트 하는 함수가 구동되면서
단어생성(기계번역)을 수행하게끔 코드를 작성했다
이전 포스트 NLP- Seq to Seq (4-2) : Beam Search에서 사용한 추론작업 - Beam Search 방법론은 성능이 Greedy Search 대비 성능향상이 제대로 된 것 같지가 않아서 추론작업은 원래의 Greedy Search 방법론으로 진행한다.
3. 코드실습
코드 실습은 이전 포스트 NLP- Seq to Seq (4-1) : Techer forcing에서 수행한

방송 컨텐츠 한국어-유럽어 번역 말뭉치 데이터로 기계번역 실습을 진행한다.
동일하게 실습을 진행하며
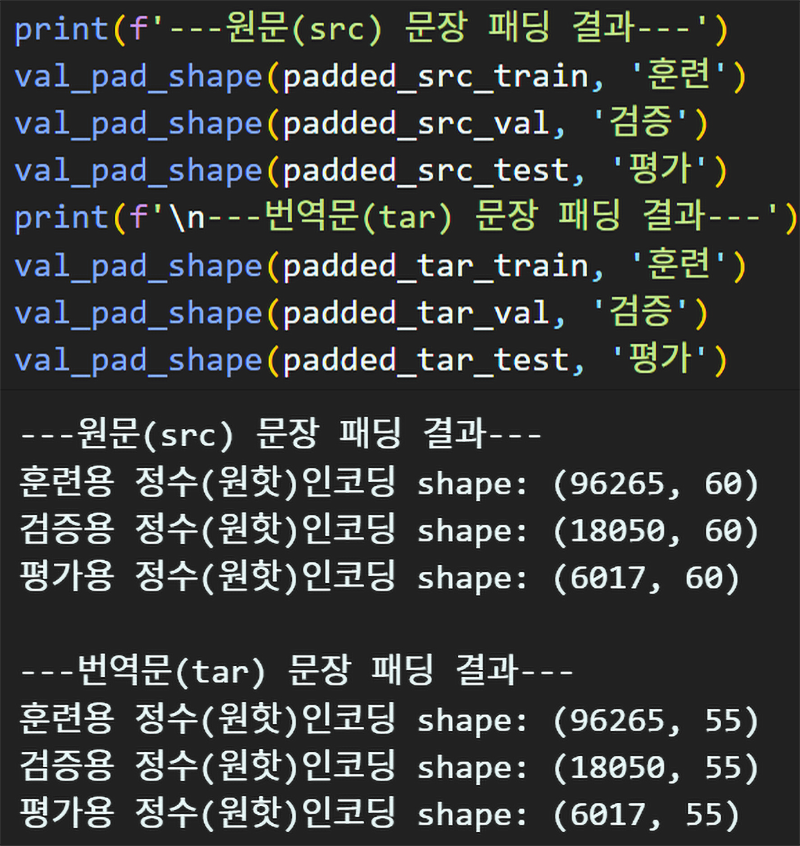
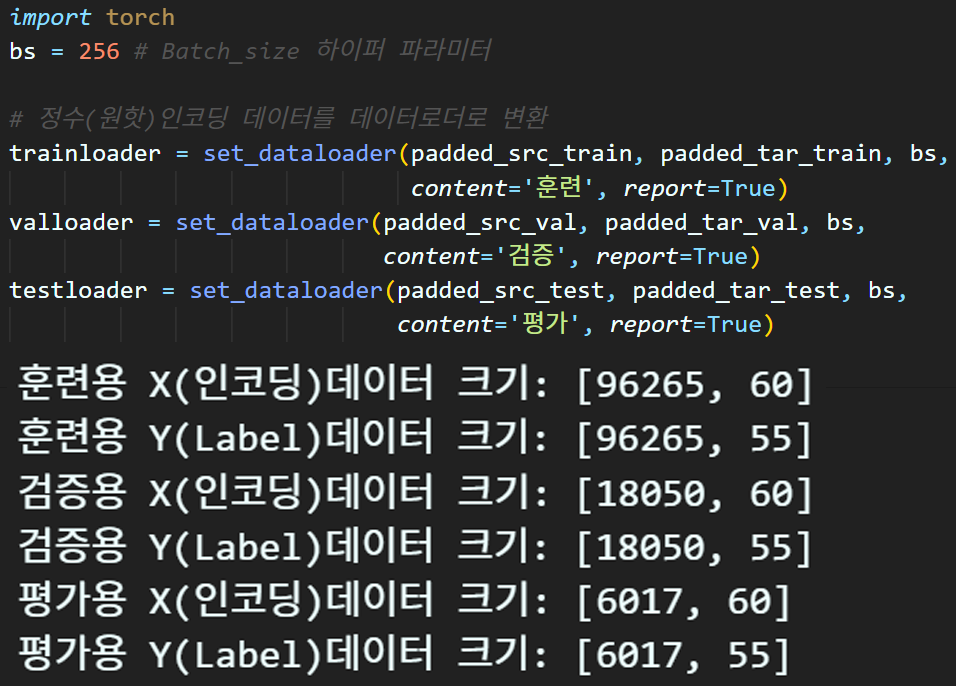
데이터셋 전처리는 문장패딩 → 데이터로더 생성까지 동일하게 수행
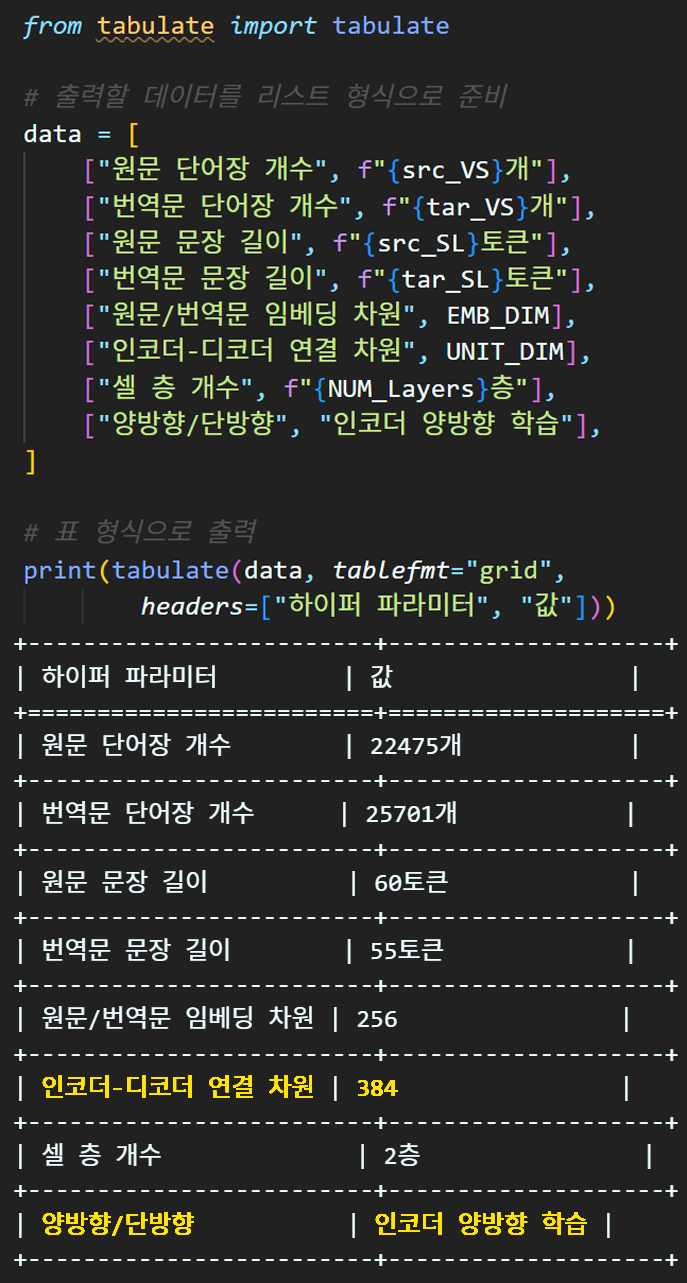
하이퍼 파라미터의 UNIT_DIM 값을 살짝 변경했는데
이유는 코드 디버깅하면서 EMB_DIM과 같은 값으로 디버깅을 수행하다보니 엉키는 부분이 있어 차원을 늘렸다.
그 외로 인코더의 양방향 학습이 진행되기에 이를 명시적으로 표현한다.
모델 설계
Peeky Seq2Seq를 적용한 LSTM버전과 GRU버전의 모델 설계 및 인스턴스화는 아래와 같다.
import torch.nn as nn
class Encoder_LSTM(nn.Module):
def __init__(self, src_vocab, src_emb_dim, rnn_dim,
num_layer=1, bi=False):
super(Encoder_LSTM, self).__init__()
# <PAD>토큰의 인덱싱을 지정하면 해당 idx(0)은
# word_vector을 만들 때 모두 0으로 채워지게 만들어준다.
self.embed = nn.Embedding(src_vocab, src_emb_dim,
padding_idx=0)
self.lstm = nn.LSTM(input_size=src_emb_dim,#언어모델 입력차원
hidden_size=rnn_dim, #언어모델 출력차원
num_layers=num_layer, #언어모델 몇층?
bidirectional=bi, #양방향학습 On?
batch_first=True) #왠만하면 True
def forward(self, x): # x의 차원 : (BS, src_seq_len)
emb = self.embed(x) # (BS, src_seq_len, src_emb_dim)
# 인코더에 양방향 학습을 적용한다
# rnn_out : (bs, src_seq_len, hidden_dim * 2)
# hidden : (num_layer * 2, bs, hidden_dim)
rnn_out , (hidden, cell) = self.lstm(emb)
#인코더의 출력은 context_vector
return hidden, cell import torch.nn as nn
class Decoder_LSTM(nn.Module):
def __init__(self, tar_vocab, tar_emb_dim, rnn_dim,
num_layer=1, bi=False):
super(Decoder_LSTM, self).__init__()
# 양방향으로 인코더가 학습되었으면 hidden_size를 2배로 하기
self.rnn_dim = rnn_dim * 2 if bi else rnn_dim
# <PAD>토큰의 인덱싱을 지정하면 해당 idx(0)은
# word_vector을 만들 때 모두 0으로 채워지게 만들어준다.
self.embed = nn.Embedding(tar_vocab, tar_emb_dim,
padding_idx=0)
self.lstm = nn.LSTM(input_size=tar_emb_dim, #언어모델 입력차원
hidden_size=self.rnn_dim, #언어모델 출력차원
num_layers=num_layer, #언어모델 몇층?
bidirectional=False, #디코더는 항상 단방향
batch_first=True) #왠만하면 True
# 디코더는 인코더가 양방향이면 2배 늘어난 hidden_size가 적용됨
self.fc = nn.Linear(self.rnn_dim, tar_vocab)
# 디코더는 인코더의 context_vector을 초기 hidden으로 입력받는다.
def forward(self, x, hidden, cell): # x의 차원 : (BS, tar_seq_len)
emb = self.embed(x) # (BS, tar_seq_len, tar_emb_dim)
# 인코더의 양방향 학습이 적용되면 디코더는 아래 차원이 된다.
# rnn_out : (bs, tar_seq_len, hidden_dim * 2)
# hidden : (num_layer, bs, hidden_dim * 2)
rnn_out, (hidden, cell) = self.lstm(emb, (hidden,cell))
output = self.fc(rnn_out)
# 최종 출력은 (bs, seq_len, tar_vocab)
return output, hidden, cellimport torch.nn as nn
class Encoder_GRU(nn.Module):
def __init__(self, src_vocab, src_emb_dim, rnn_dim,
num_layer=1, bi=False):
super(Encoder_GRU, self).__init__()
# <PAD>토큰의 인덱싱을 지정하면 해당 idx(0)은
# word_vector을 만들 때 모두 0으로 채워지게 만들어준다.
self.embed = nn.Embedding(src_vocab, src_emb_dim,
padding_idx=0)
self.gru = nn.GRU(input_size=src_emb_dim,#언어모델 입력차원
hidden_size=rnn_dim, #언어모델 출력차원
num_layers=num_layer, #언어모델 몇층?
bidirectional=bi, #양방향학습 On?
batch_first=True) #왠만하면 True
def forward(self, x): # x의 차원 : (BS, src_seq_len)
emb = self.embed(x) # (BS, src_seq_len, src_emb_dim)
# 인코더에 양방향 학습을 적용한다
# rnn_out : (bs, src_seq_len, hidden_dim * 2)
# hidden : (num_layer * 2, bs, hidden_dim)
rnn_out , hidden = self.gru(emb)
#인코더의 출력은 context_vector
return hiddenimport torch.nn as nn
class Decoder_GRU(nn.Module):
def __init__(self, tar_vocab, tar_emb_dim, rnn_dim,
num_layer=1, bi=False):
super(Decoder_GRU, self).__init__()
# 양방향으로 인코더가 학습되었으면 hidden_size를 2배로 하기
self.rnn_dim = rnn_dim * 2 if bi else rnn_dim
# <PAD>토큰의 인덱싱을 지정하면 해당 idx(0)은
# word_vector을 만들 때 모두 0으로 채워지게 만들어준다.
self.embed = nn.Embedding(tar_vocab, tar_emb_dim,
padding_idx=0)
self.gru = nn.GRU(input_size=tar_emb_dim, #언어모델 입력차원
hidden_size=self.rnn_dim, #언어모델 출력차원
num_layers=num_layer, #언어모델 몇층?
bidirectional=False, #디코더는 항상 단방향
batch_first=True) #왠만하면 True
# 디코더는 인코더가 양방향이면 2배 늘어난 hidden_size가 적용됨
self.fc = nn.Linear(self.rnn_dim, tar_vocab)
# 디코더는 인코더의 context_vector을 초기 hidden으로 입력받는다.
def forward(self, x, hidden): # x의 차원 : (BS, tar_seq_len)
emb = self.embed(x) # (BS, tar_seq_len, tar_emb_dim)
# 인코더의 양방향 학습이 적용되면 디코더는 아래 차원이 된다.
# rnn_out : (bs, tar_seq_len, hidden_dim * 2)
# hidden : (num_layer, bs, hidden_dim * 2)
rnn_out, hidden = self.gru(emb, hidden)
output = self.fc(rnn_out)
# 최종 출력은 (bs, seq_len, tar_vocab)
return output, hiddenimport torch
import torch.nn as nn
class Peeky_Seq2Seq_LSTM(nn.Module):
def __init__(self, encoder, decoder, spec_token,
max_len=None, bi=False):
super(Peeky_Seq2Seq_LSTM, self).__init__()
self.encode = encoder
self.decode = decoder
self.max_len = max_len # 최대 디코딩 길이 설정
self.spec_token = spec_token # 스페셜 토큰 정보 입력
self.Bi = bi # 인코더가 양방향/단방향 학습인지 확인
if self.Bi: #인코더가 양방향인경우
# 인코더의 context vector 사이즈는 hidden_size의 2배가 됨
CV_size = encoder.lstm.hidden_size * 2
else: #인코더가 단방향인경우
CV_size = encoder.lstm.hidden_size
# 디코더의 hid_dim 사이즈 정보 추출
DH_size = decoder.lstm.hidden_size
self.peeky_h = nn.Sequential(
nn.Linear(CV_size + DH_size, DH_size),
nn.Tanh())
self.peeky_c = nn.Sequential(
nn.Linear(CV_size + DH_size, DH_size),
nn.Tanh())
def _reshape_Bi_context_vector(self, context_vector):
# 인코더가 양방향 학습이면 차원이 (nL*2, BS, hid_dim)이다.
# 이를 (nl, BS, hid_dim*2)로 변경해줘야한다.
nL, BS, hid_dim = context_vector.size()
nL = nL // 2 #현재 num_layers는 nl*2이니 반갈죽
# 코드 가독성을 위해 차원변환이 되는 과정을 두개로 나눔
temp = context_vector.view(nL, 2, BS, hid_dim)
re_CV = temp.transpose(1, 2).reshape(nL, BS, -1)
# 최종차원은 (nl, BS, hid_dim*2)
return re_CV
def _update_hidden_with_peeky(self, context_h, context_c, h, c):
# 디코더의 hidden_state에 인코더 context_vector을 Peeky하기
concat_h = torch.cat((context_h, h), dim=-1) # 입력 전 합치기
concat_c = torch.cat((context_c, c), dim=-1) # 입력 전 합치기
h = self.peeky_h(concat_h) # 합친 정보로 업데이트하기
c = self.peeky_c(concat_c)
return h, c
def forward(self, src, tar=None, TF_ratio=1):
# 인코더의 출력 = context_vector
context_h, context_c = self.encode(src)
if self.Bi : #양방향 학습인 경우 -> 차원변환이 필요함
context_h = self._reshape_Bi_context_vector(context_h)
context_c = self._reshape_Bi_context_vector(context_c)
# 스페셜 토큰에서 SOS, EOS, PAD의 정수인코딩값 추출
en_sos = self.spec_token.index('<SOS>')
en_eos = self.spec_token.index('<EOS>')
en_pad = self.spec_token.index('<PAD>')
if tar is not None:
# 배치사이즈, 연산위치 정보 추출(tar 기준으로)
BS, tar_seq_len = tar.size()
device = tar.device
# 디코더의 첫번째 토큰을 <SOS>에 (BS, 1)차원으로 생성
# 이때 정답지(tar)의 맨 앞토큰은 <SOS>로 채워져 있으니 이를 이용한다.
input_token = tar[:, 0].unsqueeze(1)
outputs = [] # 출력 디코드 결과를 저장
# 임의 난수를 (BS)차원으로 생성 후 TF_ratio비율정보를 받아서
# 마스크 플래그로 변환, 이때 TF_ratio는 0~1 사이값
# 1에 가까울수록 대부분의 Flag는 True가 되서 지도학습비율이 올라감
TF_flag = torch.rand(BS, device=device) < TF_ratio
# 초기 은닉상태 설정
h, c = context_h, context_c
# tar seq는 맨 처음 토큰을 <SOS>로 채웟으니 1번부터 시작
for t in range(1, tar_seq_len):
# 토큰단위로 입력이니 출력은 (bs, 1, tar_vocab)이다.
out_tokens, h, c = self.decode(input_token, h, c)
outputs.append(out_tokens)
# 디코더의 hidden_state에 인코더 context_vector을 Peeky하기
h, c = self._update_hidden_with_peeky(context_h, context_c, h, c)
# 마스크 플래그가 True : 지도학습 방식으로 동작
# 마스크 플래그가 False : 비지도학습-자가 회귀방식으로 동작
input_token = torch.where(TF_flag.unsqueeze(1),
tar[:, t].unsqueeze(1),
out_tokens.argmax(dim=-1))
# 최종 출력 모양 조정
outputs = torch.cat(outputs, dim=1) # (BS, tar_seq_len-1, tar_vocab)
# (BS, 1, tar_vocab) 차원의 sos 토큰 인덱스로 채워진 텐서를 만듬
sos_tokens = torch.full((BS, 1, outputs.size(-1)), en_sos, device=device)
# sos_tokens랑 outputs를 합쳐서 (BS, tar_seq_len, tar_vocab)가 되게 함
outputs = torch.cat([sos_tokens, outputs], dim=1)
return outputs # (BS, tar_seq_len, tar_vocab)
else: # 정답지가 없는 평가모드
# 배치사이즈, 연산위치 정보 추출(src 기준으로)
BS, src_seq_len = src.size()
device = src.device
# 최대 디코딩 길이 지정 안했으면 원문 seq_len을 쓰자
if self.max_len is None:
self.max_len = src_seq_len
# 디코더의 첫번째 토큰을 <SOS>에 (BS, 1)차원으로 생성
input_token = torch.tensor([[en_sos]] * BS).to(device)
outputs = [] # 출력 디코드 결과를 저장
# EOS를 샘플별로 예측하면 그 뒷단을 PAD로 채우는 flag 텐서
pad_mask_flag = torch.zeros(BS, dtype=torch.bool,
device=device)
# 만약에 Batch내 샘플이 <EOS>예측했다면 해당 샘플의 flag가 올라간다.
# 토큰 단위로 예측이니 자가 회귀 방식임
h, c = context_h, context_c
for _ in range(self.max_len):
# 토큰단위로 입력이니 출력은 (bs, 1, tar_vocab)이다.
out_tokens, h, c = self.decode(input_token, h, c)
# 추론 과정이니 next_token은
# Greedy Search-> (bs, 1)결과가 됨
next_token = out_tokens.argmax(dim=-1)
outputs.append(next_token)
# 디코더의 hidden_state에 인코더 context_vector을 Peeky하기
h, c = self._update_hidden_with_peeky(context_h, context_c, h, c)
# 배치 내 샘플이 <EOS>토큰을 예측한다면 해당샘플의 flag를 True로 올린다.
# 이때 next_token = (bs, 1) -> (bs)로 차원 축소 후 인디케이터 연산해야함
eos_indices = (next_token.squeeze(1) == en_eos)
# OR연산이니까 EOS예측된 마스크는 계속 True로 남는다.
pad_mask_flag = pad_mask_flag | eos_indices
# 모든 샘플에서 EOS를 예측한 경우, 더이상 수행하지 않고 탈출
if pad_mask_flag.all():
break
# 자가 회귀방식이니 다음 입력을 갱신한다.
input_token = torch.where(pad_mask_flag.unsqueeze(1),
torch.full_like(next_token, en_pad),
next_token)
# 예측된 단어들을 모아서 최종 출력으로 반환
# 이때 최종 출력은 # (BS, max_len) 규격을 맞추기 위해
# PAD토큰을 채우는 과정을 수행한다.
while len(outputs) < self.max_len:
outputs.append(torch.full((BS, 1), en_pad,
device=device))
outputs = torch.cat(outputs, dim=1) # (BS, max_len)
return outputsimport torch
import torch.nn as nn
class Peeky_Seq2Seq_GRU(nn.Module):
def __init__(self, encoder, decoder, spec_token,
max_len=None, bi=False):
super(Peeky_Seq2Seq_GRU, self).__init__()
self.encode = encoder
self.decode = decoder
self.max_len = max_len # 최대 디코딩 길이 설정
self.spec_token = spec_token # 스페셜 토큰 정보 입력
self.Bi = bi # 인코더가 양방향/단방향 학습인지 확인
if self.Bi: #인코더가 양방향인경우
# 인코더의 context vector 사이즈는 hidden_size의 2배가 됨
CV_size = encoder.gru.hidden_size * 2
else: #인코더가 단방향인경우
CV_size = encoder.gru.hidden_size
# 디코더의 hid_dim 사이즈 정보 추출
DH_size = decoder.gru.hidden_size
self.peeky_h = nn.Sequential(
nn.Linear(CV_size + DH_size, DH_size),
nn.Tanh())
def _reshape_Bi_context_vector(self, context_vector):
# 인코더가 양방향 학습이면 차원이 (nL*2, BS, hid_dim)이다.
# 이를 (nl, BS, hid_dim*2)로 변경해줘야한다.
nL, BS, hid_dim = context_vector.size()
nL = nL // 2 #현재 num_layers는 nl*2이니 반갈죽
# 코드 가독성을 위해 차원변환이 되는 과정을 두개로 나눔
temp = context_vector.view(nL, 2, BS, hid_dim)
re_CV = temp.transpose(1, 2).reshape(nL, BS, -1)
# 최종차원은 (nl, BS, hid_dim*2)
return re_CV
def _update_hidden_with_peeky(self, context_h, h):
# 디코더의 hidden_state에 인코더 context_vector을 Peeky하기
concat_h = torch.cat((context_h, h), dim=-1) # 입력 전 합치기
h = self.peeky_h(concat_h) # 합친 정보로 업데이트하기
return h
def forward(self, src, tar=None, TF_ratio=1):
# 인코더의 출력 = context_vector
context_h = self.encode(src)
if self.Bi : #양방향 학습인 경우 -> 차원변환이 필요함
context_h = self._reshape_Bi_context_vector(context_h)
# 스페셜 토큰에서 SOS, EOS, PAD의 정수인코딩값 추출
en_sos = self.spec_token.index('<SOS>')
en_eos = self.spec_token.index('<EOS>')
en_pad = self.spec_token.index('<PAD>')
if tar is not None:
# 배치사이즈, 연산위치 정보 추출(tar 기준으로)
BS, tar_seq_len = tar.size()
device = tar.device
# 디코더의 첫번째 토큰을 <SOS>에 (BS, 1)차원으로 생성
# 이때 정답지(tar)의 맨 앞토큰은 <SOS>로 채워져 있으니 이를 이용한다.
input_token = tar[:, 0].unsqueeze(1)
outputs = [] # 출력 디코드 결과를 저장
# 임의 난수를 (BS)차원으로 생성 후 TF_ratio비율정보를 받아서
# 마스크 플래그로 변환, 이때 TF_ratio는 0~1 사이값
# 1에 가까울수록 대부분의 Flag는 True가 되서 지도학습비율이 올라감
TF_flag = torch.rand(BS, device=device) < TF_ratio
# 초기 은닉상태 설정
h = context_h
# tar seq는 맨 처음 토큰을 <SOS>로 채웟으니 1번부터 시작
for t in range(1, tar_seq_len):
# 토큰단위로 입력이니 출력은 (bs, 1, tar_vocab)이다.
out_tokens, h = self.decode(input_token, h)
outputs.append(out_tokens)
# 디코더의 hidden_state에 인코더 context_vector을 Peeky하기
h = self._update_hidden_with_peeky(context_h, h)
# 마스크 플래그가 True : 지도학습 방식으로 동작
# 마스크 플래그가 False : 비지도학습-자가 회귀방식으로 동작
input_token = torch.where(TF_flag.unsqueeze(1),
tar[:, t].unsqueeze(1),
out_tokens.argmax(dim=-1))
# 최종 출력 모양 조정
outputs = torch.cat(outputs, dim=1) # (BS, tar_seq_len-1, tar_vocab)
# (BS, 1, tar_vocab) 차원의 sos 토큰 인덱스로 채워진 텐서를 만듬
sos_tokens = torch.full((BS, 1, outputs.size(-1)), en_sos, device=device)
# sos_tokens랑 outputs를 합쳐서 (BS, tar_seq_len, tar_vocab)가 되게 함
outputs = torch.cat([sos_tokens, outputs], dim=1)
return outputs # (BS, tar_seq_len, tar_vocab)
else: # 정답지가 없는 평가모드
# 배치사이즈, 연산위치 정보 추출(src 기준으로)
BS, src_seq_len = src.size()
device = src.device
# 최대 디코딩 길이 지정 안했으면 원문 seq_len을 쓰자
if self.max_len is None:
self.max_len = src_seq_len
# 디코더의 첫번째 토큰을 <SOS>에 (BS, 1)차원으로 생성
input_token = torch.tensor([[en_sos]] * BS).to(device)
outputs = [] # 출력 디코드 결과를 저장
# EOS를 샘플별로 예측하면 그 뒷단을 PAD로 채우는 flag 텐서
pad_mask_flag = torch.zeros(BS, dtype=torch.bool,
device=device)
# 만약에 Batch내 샘플이 <EOS>예측했다면 해당 샘플의 flag가 올라간다.
# 토큰 단위로 예측이니 자가 회귀 방식임
h = context_h
for _ in range(self.max_len):
# 토큰단위로 입력이니 출력은 (bs, 1, tar_vocab)이다.
out_tokens, h = self.decode(input_token, h)
# 추론 과정이니 next_token은
# Greedy Search-> (bs, 1)결과가 됨
next_token = out_tokens.argmax(dim=-1)
outputs.append(next_token)
# 디코더의 hidden_state에 인코더 context_vector을 Peeky하기
h = self._update_hidden_with_peeky(context_h, h)
# 배치 내 샘플이 <EOS>토큰을 예측한다면 해당샘플의 flag를 True로 올린다.
# 이때 next_token = (bs, 1) -> (bs)로 차원 축소 후 인디케이터 연산해야함
eos_indices = (next_token.squeeze(1) == en_eos)
# OR연산이니까 EOS예측된 마스크는 계속 True로 남는다.
pad_mask_flag = pad_mask_flag | eos_indices
# 모든 샘플에서 EOS를 예측한 경우, 더이상 수행하지 않고 탈출
if pad_mask_flag.all():
break
# 자가 회귀방식이니 다음 입력을 갱신한다.
input_token = torch.where(pad_mask_flag.unsqueeze(1),
torch.full_like(next_token, en_pad),
next_token)
# 예측된 단어들을 모아서 최종 출력으로 반환
# 이때 최종 출력은 # (BS, max_len) 규격을 맞추기 위해
# PAD토큰을 채우는 과정을 수행한다.
while len(outputs) < self.max_len:
outputs.append(torch.full((BS, 1), en_pad,
device=device))
outputs = torch.cat(outputs, dim=1) # (BS, max_len)
return outputs선언한 모델의 인스턴스화는 아래의 코드로 진행한다
# Seq2Seq의 LSTM버전 인스턴스화
encoder_lstm = Encoder_LSTM(src_VS, EMB_DIM, UNIT_DIM,
num_layer=NUM_Layers, bi=BI_DIR)
decoder_lstm = Decoder_LSTM(tar_VS, EMB_DIM, UNIT_DIM,
num_layer=NUM_Layers, bi=BI_DIR)
Translater_lstm = Peeky_Seq2Seq_LSTM(encoder_lstm, decoder_lstm,
spec_token=spec_token, max_len=tar_SL, bi=BI_DIR)
# Seq2Seq의 GRU버전 인스턴스화
encoder_gru = Encoder_GRU(src_VS, EMB_DIM, UNIT_DIM,
num_layer=NUM_Layers, bi=BI_DIR)
decoder_gru = Decoder_GRU(tar_VS, EMB_DIM, UNIT_DIM,
num_layer=NUM_Layers, bi=BI_DIR)
Translater_gru = Peeky_Seq2Seq_GRU(encoder_gru, decoder_gru,
spec_token=spec_token, max_len=tar_SL, bi=BI_DIR)실험준비
기계번역 실습을 위한 실험준비는 아래와 같다.
# 학습 실험 조건을 구분하기 위한 키
model_key = ['LSTM', 'GRU']
metrics_key = ['Loss', '정확도']# GPU사용 가능 유/무 확인
device = torch.device("cuda" if torch.cuda.is_available() else 'cpu')
models = {} # 딕셔너리
models[model_key[0]] = Translater_lstm.to(device)
models[model_key[1]] = Translater_gru.to(device)import torch.optim as optim
# 로스함수 및 옵티마이저 설계
# 로스함수에서 <PAD> 토큰의 정수인덱스 번호 -> 0번에 대해서는
# 틀리건 맞건 무시하겠다 : ignore_index에 해당 정수 인덱스 번호 기입
ignore_class_idx = spec_token.index('<PAD>')
criterion = nn.CrossEntropyLoss(ignore_index=ignore_class_idx)
LR = 0.001 # 러닝레이트는 통일
optimizers = {}
optimizers[model_key[0]] = optim.Adam(Translater_lstm.parameters(), lr=LR)
optimizers[model_key[1]] = optim.Adam(Translater_gru.parameters(), lr=LR)Techer forcing 인자값 조정
from Seq_trainer import *
num_epoch = 35 #총 훈련/검증 epoch값
ES = 7 # 디스플레이용 에포크 스텝
# Techer forcing 비율을 스케줄러 형식으로 조정하기 위한 클래스 객체화
TF_ratio = 1.0
TF_schedular = TeacherForcingScheduler(TF_ratio,
Damping_Factor=0.95,
min_TF= 0.35)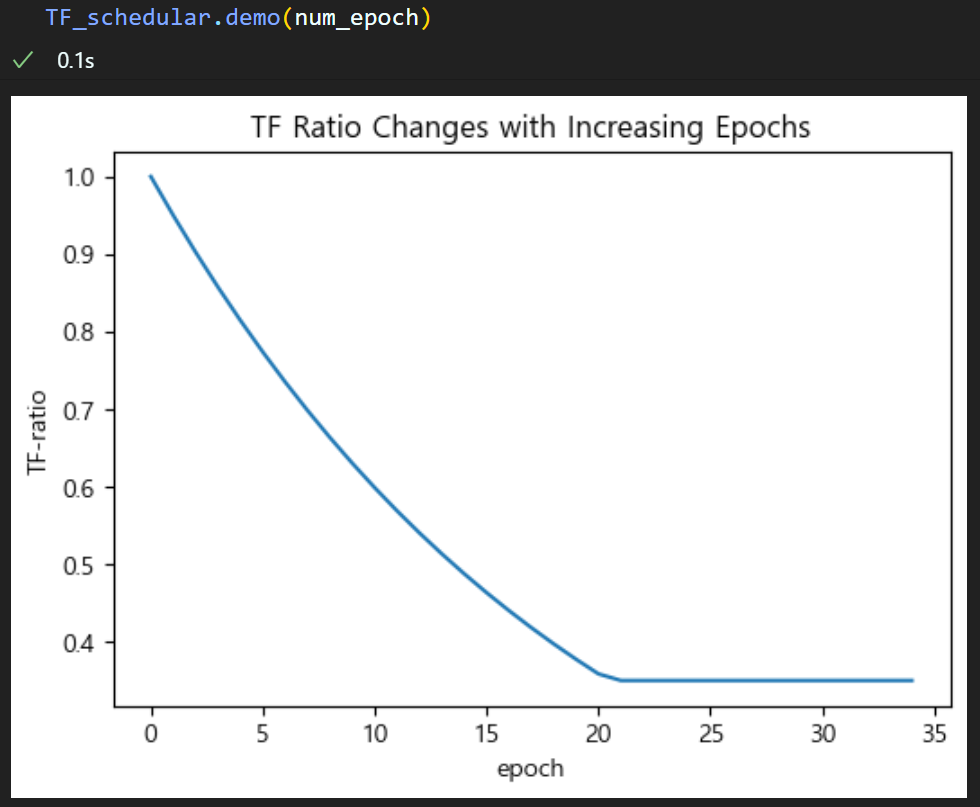
이전포스트와 다르게 Techer Forcing의 하한값을 살짝 조정했다
Peeky + Bi-direction 옵션을 둘다 적용하면서
학습 성능이 대폭 향상됬는데 문제는 과적합이 일어나면서 오히려 성능하락이 떨어지는 문제가 생겼다.
따라서 좀 더 단어 생성능력 향상을 위해 Techer Forcing옵션이 조정을 진행했다 보면 된다.
학습 진행
# 학습/검증 정보 저장
history = {key: {metric: []
for metric in metrics_key}
for key in model_key}for key in model_key:
print(f"\n--현재 훈련중인 조건: [Peeky_Seq2Seq_{key}]--") # 조건에 맞는 실험시작
for epoch in range(num_epoch): #에포크별 모델 훈련/검증
# 모델 훈련
train_loss, train_acc = model_train(
models[key], trainloader, criterion,
optimizers[key], epoch, ES,
ignore_class=ignore_class_idx, #무시할 클래스 인덱스
TF_schedular=None #Techer forcing비율 조정 함수
)
#모델 검증
val_loss, val_acc = model_evaluate(
models[key], valloader, criterion,
epoch, ES,
ignore_class=ignore_class_idx, #무시할 클래스 인덱스
)
# 손실 및 성과 지표를 history에 저장
history[key]['Loss'].append((train_loss, val_loss))
history[key]['정확도'].append((train_acc, val_acc))
# Epoch_step(ES)일 때마다 print수행
if (epoch+1) % ES == 0 or epoch == 0:
print(f"epoch {epoch+1:03d}," + "\t" +
f"훈련 [Loss: {train_loss:.3f}, " +
f"Acc: {train_acc*100:.2f}%]")
print(f"epoch {epoch+1:03d}," + "\t" +
f"검증 [Loss: {val_loss:.3f}, " +
f"Acc: {val_acc*100:.2f}%]")
print(f"--[Peeky_Seq2Seq_{key}] 훈련 종료--\n") # 조건에 맞는 실험종료학습/검증 결과 분석
import matplotlib.pyplot as plt
# 한글 사용을 위한 폰트 포함
plt.rcParams['font.family'] = 'Malgun Gothic'
plt.rcParams['axes.unicode_minus'] = False# 학습/검증 결과 데이터를 재배치
res_data = {}
for key in model_key:
res_data[key] = {}
for metric in metrics_key:
# 각 모델의 메트릭 데이터 추출
metric_data = history[key][metric]
# 훈련 및 검증 값 분리
train_values = [tup[0] for tup in metric_data]
val_values = [tup[1] for tup in metric_data]
res_data[key][f'훈련_{metric}'] = train_values
res_data[key][f'검증_{metric}'] = val_values# 손실 및 정확도 그래프 그리기 그래프 생성
fig, axes = plt.subplots(2, 2, figsize=(12, 12))
axes = axes.flatten() # 2차원 배열을 1차원으로 변환하여 인덱싱 쉽게 함
# 손실 그래프 그리기
for idx, key in enumerate(model_key):
ax = axes[idx*2] #손실 그래프는 0, 2번째에 위치
ax.plot(res_data[key]['훈련_Loss'], label='훈련 로스')
ax.plot(res_data[key]['검증_Loss'], label='검증 로스')
ax.set_title(f'Peeky+Bi-적용 Seq2Seq_{key} 번역 Loss', fontsize=15)
ax.set_xlabel('Epoch')
ax.set_ylabel('Loss')
ax.legend()
# 정확도 그래프 그리기
for idx, key in enumerate(model_key):
ax = axes[idx*2 + 1] #정확도 그래프는 1, 3번째에 위치
ax.plot(res_data[key]['훈련_정확도'], label='훈련 정확도')
ax.plot(res_data[key]['검증_정확도'], label='검증 정확도')
ax.set_title(f'Peeky+Bi-적용 Seq2Seq_{key} 번역 정확도', fontsize=15)
ax.set_xlabel('Epoch')
ax.set_ylabel('정확도')
ax.legend()
plt.tight_layout()
plt.show()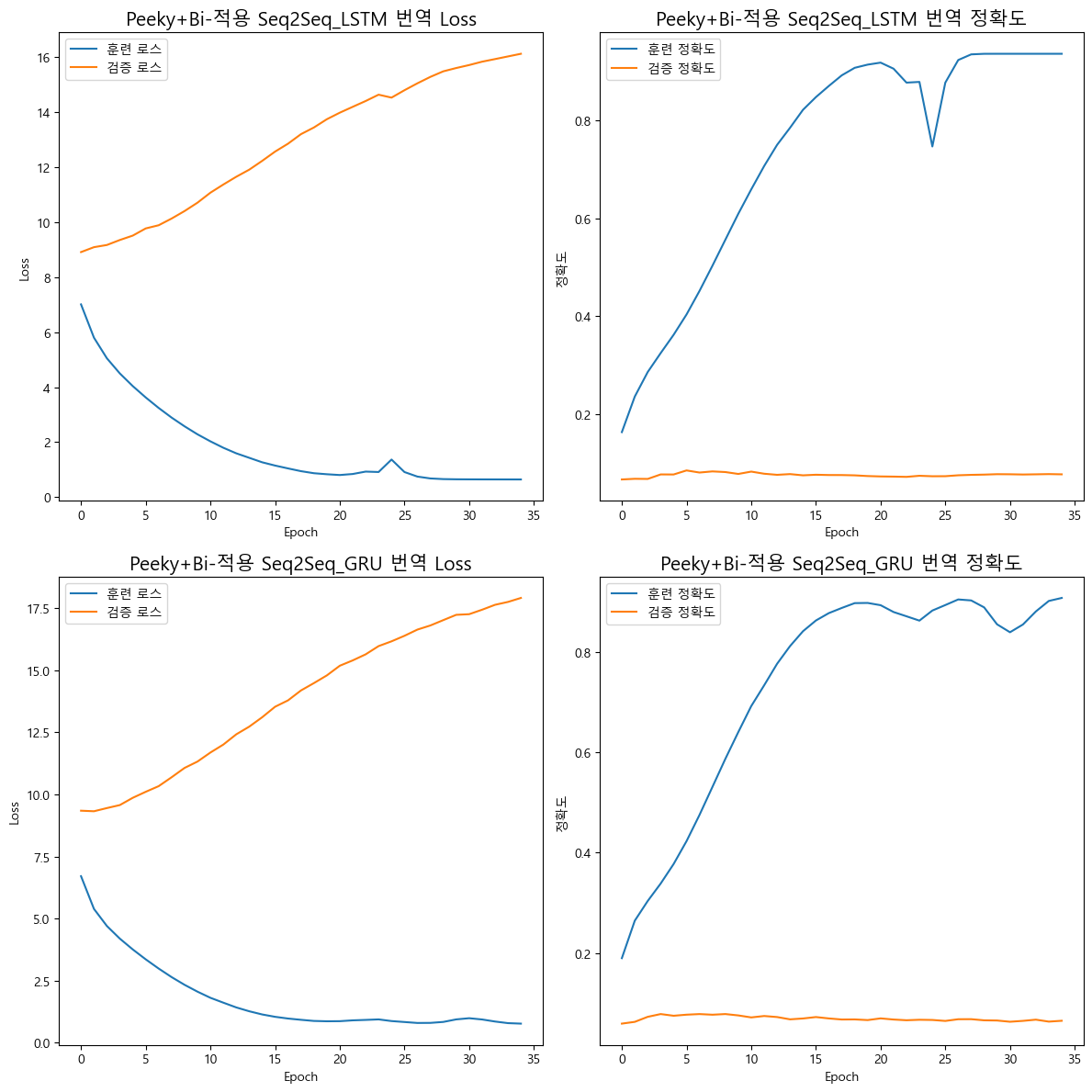
# 모든 모델의 손실과 정확도를 비교하는 그래프 생성
fig, axes = plt.subplots(1, 2, figsize=(16, 8))
# 모든 모델의 손실 그래프
ax = axes[0]
for key in model_key:
ax.plot(res_data[key]['훈련_Loss'], label=f'Seq2Se2_{key} 훈련 로스')
ax.plot(res_data[key]['검증_Loss'], label=f'Seq2Se2_{key} 검증 로스', linestyle='--')
ax.set_title('모든 조건별 모델의 훈련/검증 Loss', fontsize=16)
ax.set_xlabel('Epoch')
ax.set_ylabel('Loss')
ax.legend(fontsize=16) # 범례의 폰트 크기 설정
# 모든 모델의 정확도 그래프
ax = axes[1]
for key in model_key:
ax.plot(res_data[key]['훈련_정확도'], label=f'Seq2Se2_{key} 훈련 정확도')
ax.plot(res_data[key]['검증_정확도'], label=f'Seq2Se2_{key} 검증 정확도', linestyle='--')
ax.set_title('모든 조건별 모델의 훈련/검증 정확도', fontsize=16)
ax.set_xlabel('Epoch')
ax.set_ylabel('정확도')
ax.legend(fontsize=16) # 범례의 폰트 크기 설정
plt.tight_layout()
plt.show()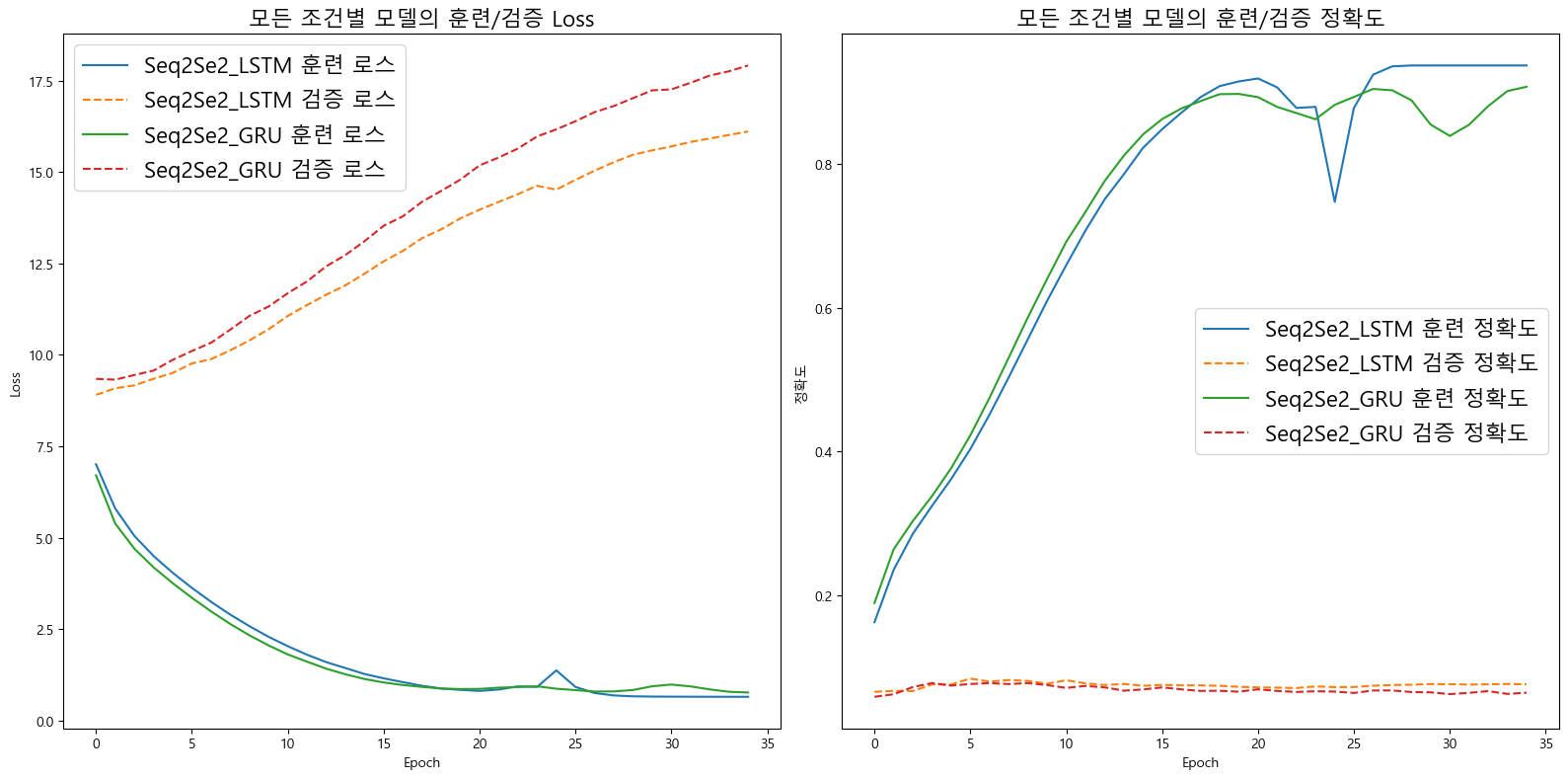
이전 포스트에서는 40epoch만 돌렸을 때 약 70~80% 정확도가 나온것이랑 비교하면
35epoch만 돌렸는데도 90% 이상의 정확도가 나왔다.
문제는 90% 이후로 계속 불안정한 상태로 진행되다가 정확도가 확 떨어지는 구간이 발생하는 등..
과적합도 빠르게 다가오는 듯 하다..
모델 추론
# 학습된 모델 저장
path = {} #모델별 경로명 저장
for mk in model_key:
path[mk] = f'Peeky_Seq2Seq_{mk}.pth'
torch.save(models[mk].state_dict(), path[mk])# 저장된 모델 불러오기
load_model = {
'LSTM': Translater_lstm, # LSTM 모델 인스턴스 생성
'GRU': Translater_gru # GRU 모델 인스턴스 생성
}
for mk in model_key:
load_model[mk].load_state_dict(torch.load(path[mk], weights_only=True))
#추론기는 CPU에서 돌리자
load_model[mk] = load_model[mk].to('cpu')import random
# 테스트 데이터셋에서 샘플을 추출
# 전체 테스트 데이터 개수정보를 추출
num_test = padded_src_test.shape[0]
sample_epoch = 10 #추출할 샘플 개수 정의
indices = random.sample(range(num_test), sample_epoch)
# 추출한 샘플번호를 바탕으로 Test 데이터셋에서 무작위 추출
S_src_test = padded_src_test[indices]
S_tar_test = padded_tar_test[indices]
# 원문 데이터만 텐서 자료형으로 변환
TS_src_test = torch.tensor(S_src_test, dtype=torch.long)모델의 추론(번역) 성능을 평가하기 위한 방법은 Test데이터셋에서 임의 추출을 진행한다
from Seq_trainer import *
# 추론 결과를 저장할 딕셔너리
tar_dict = {key: [] for key in model_key}
for key in model_key:
print(f"\n--현재 추론 조건: [Seq2Seq_{key}]--") # 조건에 맞는 실험시작
for idx in tqdm(range(sample_epoch)): #추론 에포크별 추론 시작
# 입력되는 원문 차원을 (1, src_seq_len)으로 만들기 위한 코드
iter_src_data = TS_src_test[idx].unsqueeze(0)
# 모델 추론 -> 추론결과는 (bs, max_len) ndarray타입임
tar_infer_doc = model_inference(load_model[key], iter_src_data)
tar_dict[key].append(tar_infer_doc)모델 추론 결과는 디코딩을 해야 정보 확인이 가능하니
아래의 코드를 수행하자
idx_list = range(1, sample_epoch+1)
for idx, src, pred_lstm, pred_gru, tar in zip(idx_list, S_src_test,
tar_dict['LSTM'],
tar_dict['GRU'],
S_tar_test):
# 원문, 모델번역문_1, 모델번역문_2, 정답번역문 순으로 디코딩
decode_src = Translater_post_processor(src, idx_to_src, spec_token)
de_pred_lstm = Translater_post_processor(pred_lstm, idx_to_tar, spec_token)
de_pred_gru = Translater_post_processor(pred_gru, idx_to_tar, spec_token)
decode_tar = Translater_post_processor(tar, idx_to_tar, spec_token)
print(f"{idx}번째 번역 결과 확인")
print(f"원문(src) : {decode_src}")
print(f"seqLSTM번역 : {de_pred_lstm}")
print(f"seq-GRU번역 : {de_pred_gru}")
print(f"번역문(tar) : {decode_tar}")
print("==============================\n")
BLEU Score까지 확인을 해보지는 않았지만
번역품질이 조금은 향상된 부분이 있다.
이렇게 Attention Mechanism방법론이 발생하기 이전에
여러가지 성능 향상을 위한 연구가 진행됬다.
지금은 사장된 기술도 있고
애초에 번역 Task를 수행하는데 Seq2Seq을 사용하는 것보다는
Transformer을 사용하는게 이제는 일반적인 상황이지만
코드학습 차원에서 그간 연구된 방법론들을 학습했다.
이번 포스트에 진행한 실습파일은 https://github.com/tbvjvsladla/Seq2Seq 에 업로드 하였습니다.
Seq2Seq의 그간 포스트 했던 내용도 차례대로 업로드가 진행되었으니
확인 부탁드립니다
감사합니다.
