
도입
인공지능과 데이터 분야에 대한 관심이 점점 커지고 있는 요즘, 많은 사람이 실제로 어떻게 기술을 활용할 수 있을지 고민하고 있다. 이번 강의는 파이썬과 OpenAI API를 이용해 데이터를 다루고, 의미 있는 결과물을 도출하는 과정을 다룬다. 파이썬을 어느 정도 다룰 줄 안다면 누구나 따라 할 수 있는 실습 프로젝트들로 구성되어 있어, 학습자가 자신의 실력을 자연스럽게 발전시킬 수 있는 기회를 제공한다.
8개의 다양한 프로젝트를 통해, 자연어 처리부터 감정 분석, 데이터 시각화까지 다루며 현업에서 바로 적용할 수 있는 스킬들을 익힐 수 있다. 실제로 데이터 수집부터 분석, 그리고 모델 튜닝까지의 전체 과정을 경험하면서 AI와 데이터 사이언스의 기본기를 확실히 다질 수 있을 것이다.
지금 이 강의를 통해, 데이터의 세계에서 원하는 결과를 보다 쉽게 얻어보라. 어렵게 느껴질 수 있는 AI 기술이 실습과 프로젝트를 통해 친숙해질 것이다.

https://metacodes.co.kr/edu/read2.nx?M2_IDX=31635&EP_IDX=9859&EM_IDX=9683
1. 프로젝트 개요

이번 프로젝트의 개요는 특정 커뮤니티(Raddit)에 게시글이 업로드 되어 있으면 해당 게시글에 댓글이 달려 토론이 진행된다.
이 때 해당 댓글에 대한 감정분석을 진행하고자 한다.
물론 이때 사용하는 OpenAI-API는 범용 LLM인 GTP를 사용하여 감정분석을 진행하기에
해당 감성분석에 특화된 전용 LM대비 성능이 하락할 수 있음을 유의해야 한다.
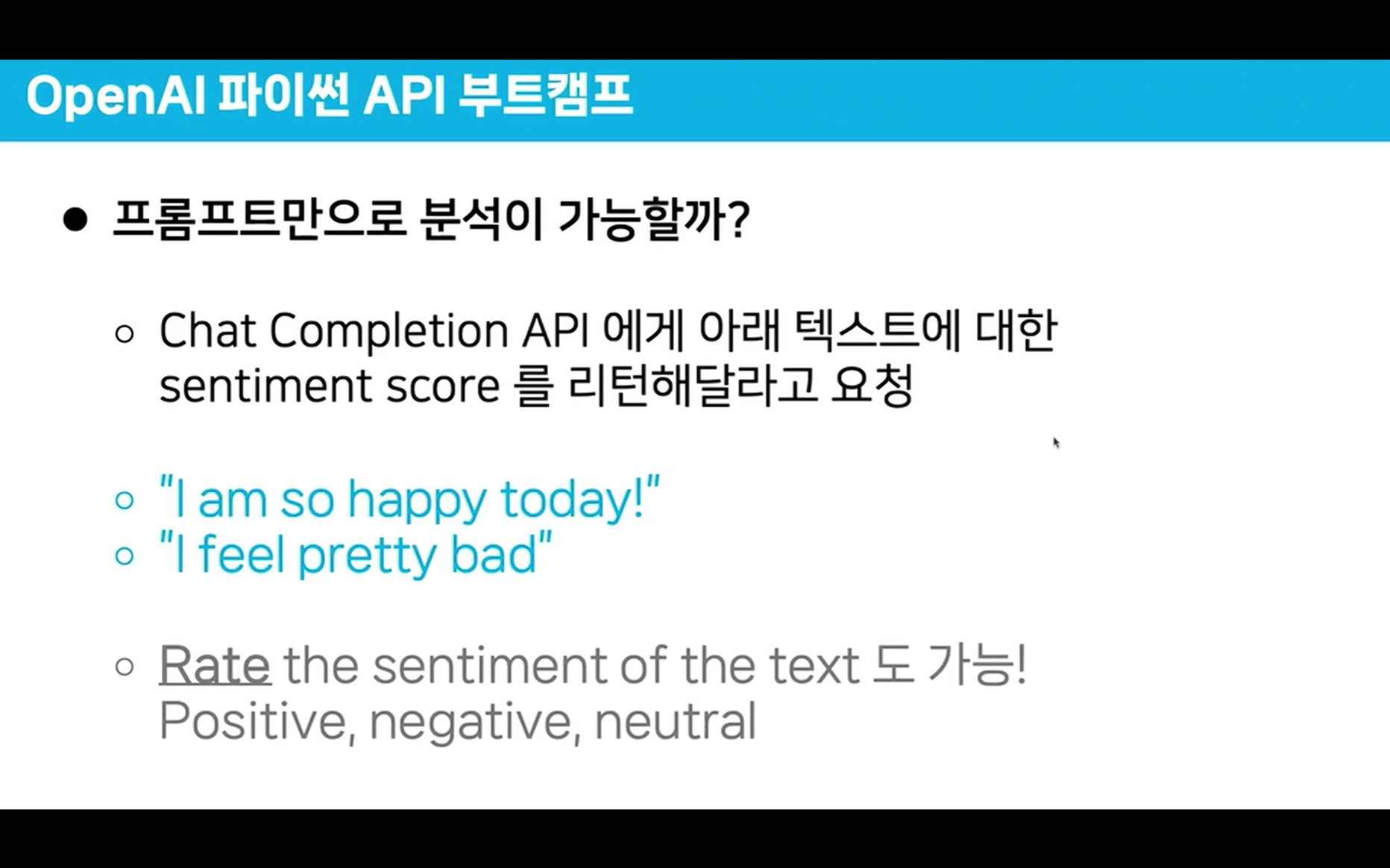
사용하는 API는 OpenAI-Chat Completion API이고
입력한 텍스트(댓글)에 대한
긍정(Positive)
중립(Netural)
부정(Negative) 3가지로 각각 score를 매기는 방식으로 수행한다.
2. Raddit API 세팅하기
Raddit에서는 Raddit App를 통하여 계정을 생성하면 개발자용 앱 페이지에서
Raddit API를 사용할 수 잇도록 API Key를 발급해준다
이후 해당 API를 Python에서 사용할 수 있도록
Praw(Python Raddit API Wrapper)를 사용하여 특정 개시글의 정보를 연동하는 과정을 수행한다.
이렇게 API를 통하여 게시글의 정보를 크롤링하는 이유는
일반적인 웹 크롤링 방식으로 게시글 정보를 수집 할 시
일부 웹페이지의 경우 접근 차단이 발생할 수도 있기에
공식 API를통하여 수집하는것을 권장한다.
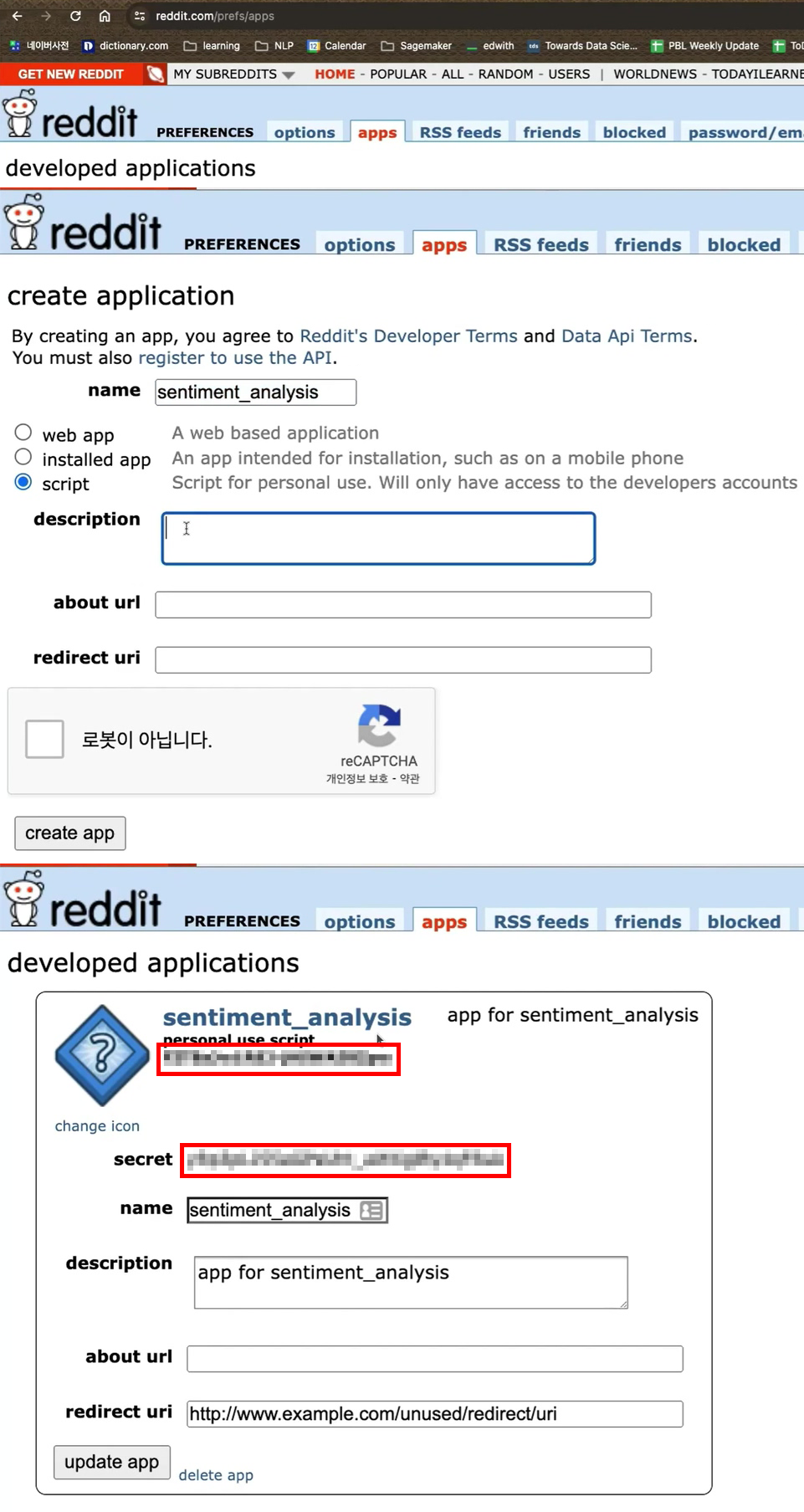
API의 생성은 Raddit 커뮤니티에 접속 후 로그인 한 후에
https://www.reddit.com/prefs/apps
위 사이트의 개발자 플랫폼에 접속하여
apps 옵션에서 어플생성을 수행하면 된다.
어플 생성을 수행하면 ID API, Secret API 두개의 키가 발급되는데 해당 키를 등록하면 OpenAI-API처럼 게시글 크롤링이 가능해진다.
이때 Raddit-API를 파이썬 개발환경에서 사용하기 위해서는
praw(python raddit api wrapper)패기지를 설치해야한다
! pip install prawhttps://praw.readthedocs.io/en/stable/

해당 API의 사용은 위 document를 참고하여 코드작성을 수행한다.
3. 유투브 API로 따라하기
위 Raddit 커뮤니티에서 게시글 크롤링 하고 해당 게시글에 담긴 댓글의 감정분석을 하는 것은 좋은 실습 예제일 수 있으나
필자는 유투브 영상에 담긴 댓글을 가져와서 감정분석을 진행하고자 한다.
https://developers.google.com/youtube/v3?hl=ko
Youtube Data API는 프로젝트에서 사용하고 있는
Raddit-API와 유사한 기능을 제공하는 API로
특정 유투브 영상에 대한 댓글(comment)크롤링을 지원하고 있다.
! pip install --upgrade google-api-python-client
! pip install --upgrade google-auth-oauthlib google-auth-httplib2Python 환경에서 사용하기 위해서는 먼저 위 라이브러리를 설치해야 하고

위와 같이 Youtube Data API 및 다른 API도 통합하여 관리하는 Google Cloud Platform에 접속하여
Youtube Data API 검색 및 API-Key를 생성한다.
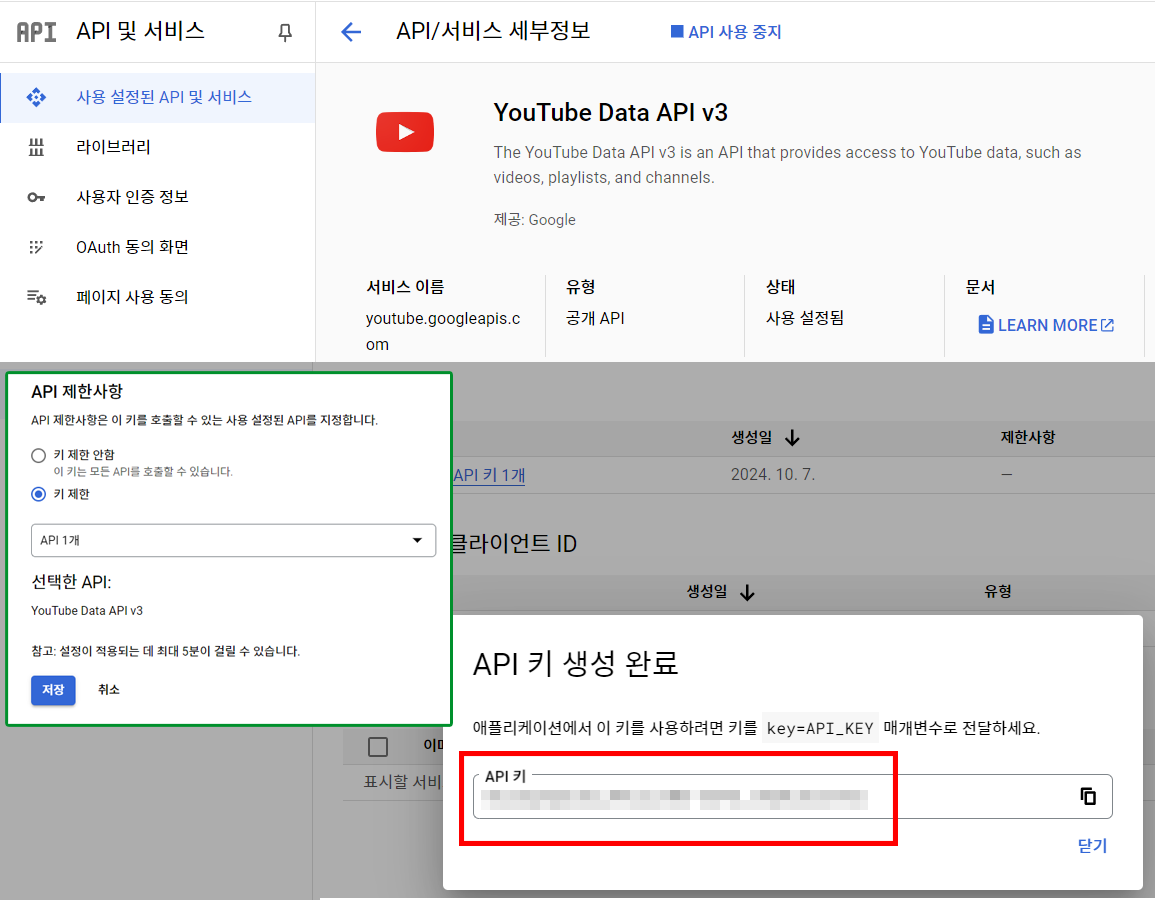
API-Key를 생성한 뒤에는 해당 API-Key의 제한사항을 지정할 수 있는데 Youtube Data API에만 사용제한을 지정하거나 그 외 제한사항을 설정할 수 있다.
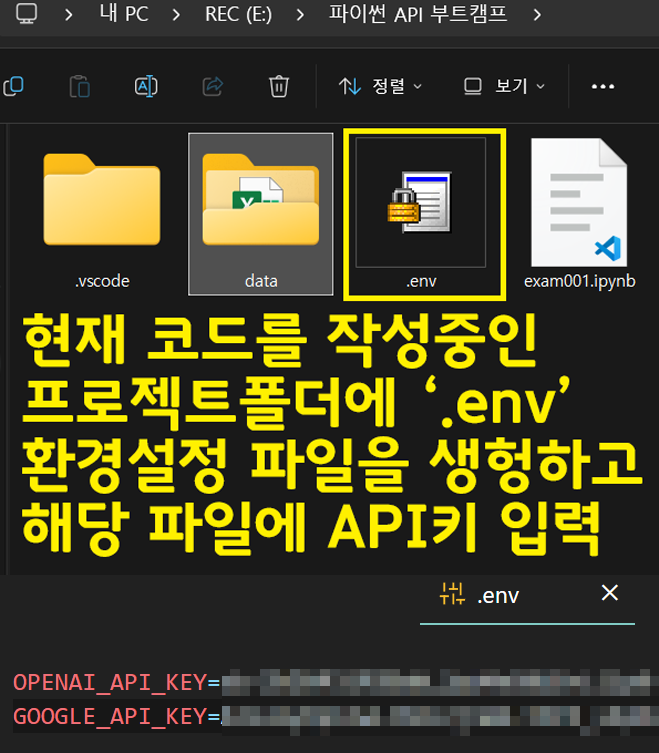
다음으로 이전 포스트 에서 작성한 .env API-Key 관리 파일에 새로이 발급받은 Youtube Data API Key를 등록한다.
등록한 키를 바탕으로 댓글(comment)를 가져오는 코드의 작성은 아래와 같다.
from googleapiclient.discovery import buildGoogle_api_key = os.getenv('GOOGLE_API_KEY')
# openAI처럼 API서비스 활성화는 아래의 build 함수로 실행
youtube_client = build(serviceName='youtube',
version='v3',
developerKey=Google_api_key)위 코드로 API 서비스를 사용할 수 있는 객체를 활성화 한다.
이때 Youtube Data API는 서비스 이름명이
youtube, 해당 서비스의 버전은 v3이기에
이를 순차로 인자에 입력한다.
다음으로 크롤링할 댓글의 영상을 선정하자
댓글을 크롤링할 영상은 위 영상으로 선정했으며
해당 페이지의 주소를 본다면

위 video_id 인자값을 기록하여 API-request(서비스 신청)을 수행한다.
# 댓글을 크롤링할 유투브 영상 ID
video_id = 'LyV_H8bLPB8'
request = youtube_client.commentThreads().list(
part='snippet', #댓글만 가져올지? 대댓글도 가져올지 설정(snippet,replies)
videoId=video_id,
maxResults=100, #최대 가져올 수 있는 댓글
textFormat='plainText', #일반 텍스트 형태로 댓글을 가져옴
order='relevance' # 'relevance'로 인기 댓글 순으로 가져오기
)# API 서비스 요청에 대한 응답(response)객체 저장
youtube_response = request.execute()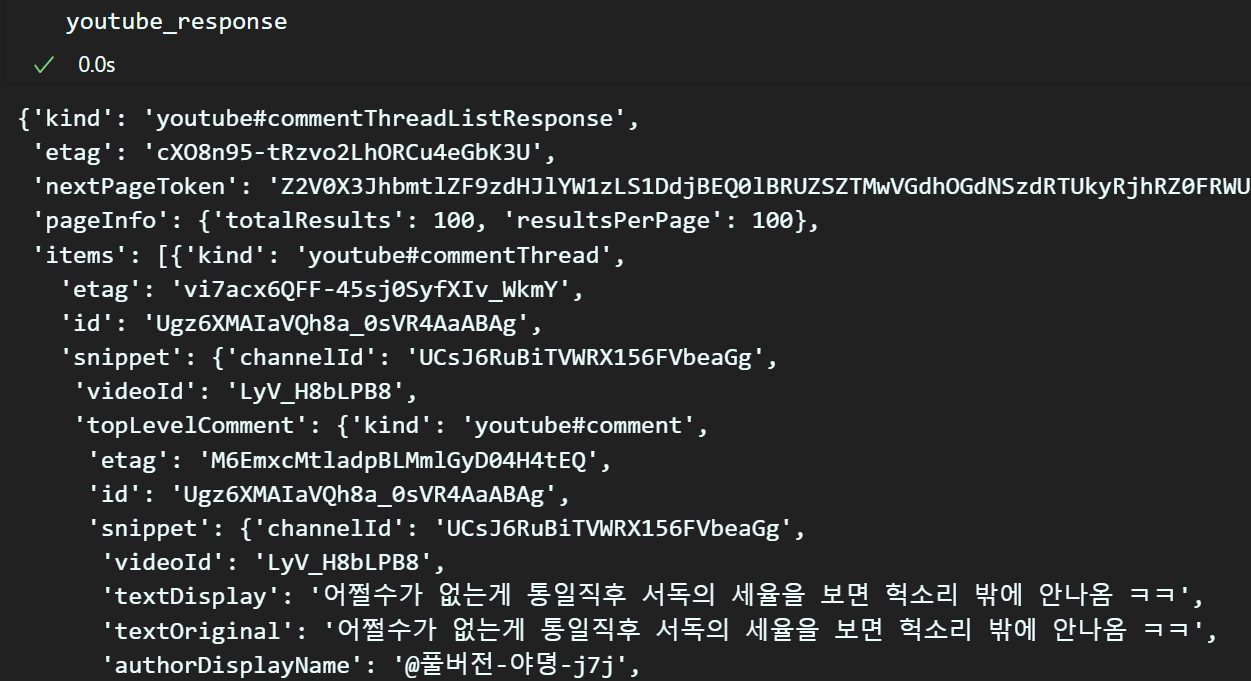
서비스 요청(request)에 대한 응답(response)를 확인하면 여러 정보가 함께 저장되는데
이 중 의미있는 데이터인 textDisplay를 추출하여 이를 저장해야 한다.
comment_list = [] # 추출한 댓글을 저장할 리스트
for item in youtube_response['items']:
comment = item['snippet']['topLevelComment']['snippet']['textDisplay']
comment_list.append(comment)
이때 Youtube Data API의 크롤링 구성을 살펴보면
추출할 수 있는 댓글의 최대 개수가 100개이기에
이를 초과하여 댓글을 크롤링 하려면
pageToken=next_page_token 옵션을 추가하여 아래와 같이 코드를 개선한다.
total_comments = 500 # 가져올 댓글의 총 개수
comments_list = [] # 추출한 댓글을 저장할 리스트
next_page_token = None # 페이지 토큰 초기화
video_id = 'LyV_H8bLPB8' # 유튜브 영상 IDwhile len(comments_list) < total_comments:
# 댓글 목록 요청
request = youtube_client.commentThreads().list(
part='snippet', # 댓글 정보
videoId=video_id,
maxResults=100, # 한 번의 요청으로 가져올 댓글 수 (최대 100)
textFormat='plainText', # 일반 텍스트 형태로 댓글 가져오기
order='relevance', # 인기 댓글 순으로 정렬
pageToken=next_page_token # 다음 페이지의 댓글을 가져오기 위한 토큰
)
response = request.execute()
# 댓글 추출
for item in response['items']:
comment = item['snippet']['topLevelComment']['snippet']['textDisplay']
comments_list.append(comment)
# 다음 페이지 토큰 업데이트
next_page_token = response.get('nextPageToken')
# 더 이상 다음 페이지가 없으면 종료
if not next_page_token:
break
결과물을 확인하면 가져올 댓글의 개수를 500으로 설정하였고 그만큼 API를 반복 요청하는 식으로 댓글을 가져오게 코드를 작성했다.
4. 댓글 감정 분석하기
이제 OpenAI-API를 활용하여 수집한 댓글에 대한 감정분석을 수행하고자 한다.
from dotenv import load_dotenv
from openai import OpenAI
import os
load_dotenv() # .env 파일의 환경 변수를 불러옴
api_key = os.getenv('OPENAI_API_KEY')
# API 키가 정상적으로 불러와졌는지 확인
#print(f"API Key: {api_key}")
client = OpenAI()시스템 프롬포트와 유저프롬포트, 그리고 출력형식을 아래와 같이 지정한다.
def system_prompt():
return '''입력한 댓글에 대해
댓글이 다루고 있는 주요 주제
주제에 관한 감정 분석 수행'''
def user_prompt(comment, format_template):
return f'''입력한 댓글 : {comment}이 다루고 있는
주요 주제는 한 단어로 한정한다.
주제 단어에 대해 {comment}가 갖는 감정을
긍정, 중립, 부정 3개의 클래스로 softmax 값을 출력한다
결과물의 출력형식은 {format_template}형식으로만 출력한다.'''
format_template = '[주제, 긍정확률, 중립확률, 부정확률]'위 프롬포트로 댓글 당 API서비스를 수행하는 코드를 작성한다
import re
from tqdm import tqdm
p1 = re.compile(r'\[|\]') # 대괄호를 찾는 정규표현식
p2 = re.compile(r'\s*,\s*') # 쉼표를 기준으로 분절하고, 공백 제거
def sentiment_analysis(comments):
SA_results = []
for comment in tqdm(comments):
response = client.chat.completions.create(
model = "gpt-4-turbo",
messages=[
{"role": "system", "content": system_prompt()},
{"role": "user", "content":
user_prompt(comment, format_template)},
],
max_tokens = 40
)
# 하나의 코멘트에 대하여 감정분석결과 출력
SA_comment = response.choices[0].message.content
# 감정 분석결과를 후처리
temp = p1.sub(repl="", string=SA_comment)
SA_list = p2.split(string=temp)
SA_results.append(SA_list)
return SA_results
이제 댓글 전체 항목을 설계한 함수 sentiment_analysis에 입력하면 댓글 별로
해당 댓글의 주제
댓글의 긍정, 중립, 부정에 대한 softmax 확률값을 산출한다.
3.1. 데이터 후처리
마지막으로 입력받은 데이터를 후처리하자
import pandas as pd
columns=['주제', '긍정', '중립', '부정']
# 감정분석 결과를 pandas - dataframe 객체로 변환
df = pd.DataFrame(SA_result_list, columns=columns)
# 댓글 원본을 pandas - series객체로 변환
ser = pd.Series(comments_list)
df['comment'] = ser
# 컬럼 순서 재정렬
df = df[['comment', '주제', '긍정', '중립', '부정']]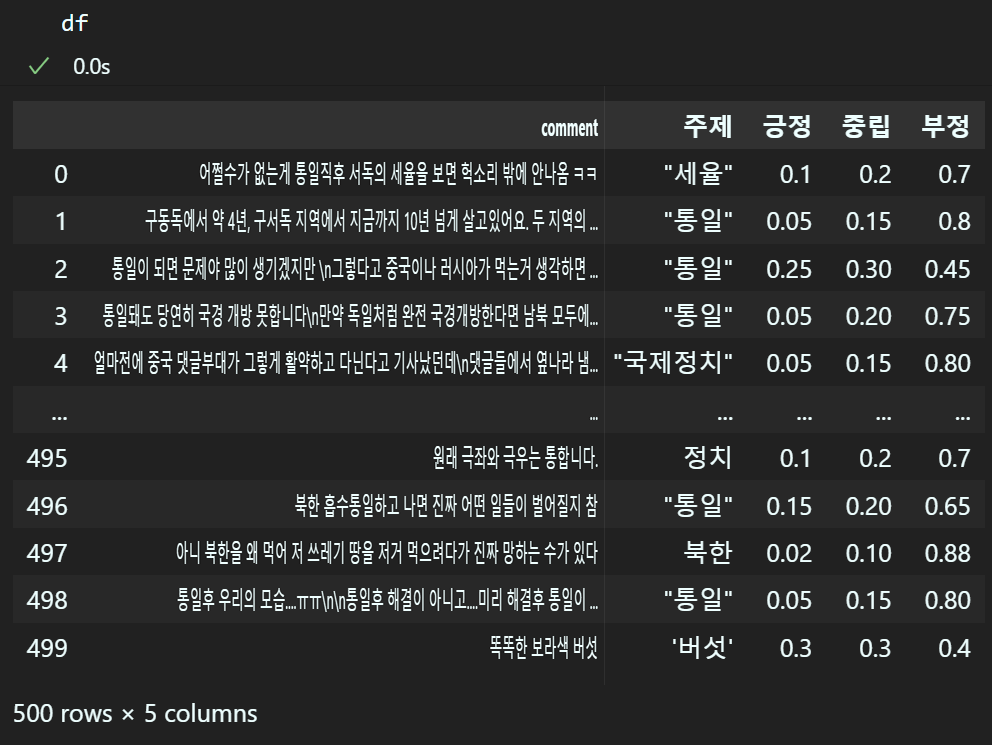
결과물은 500개의 댓글이 출력되지만
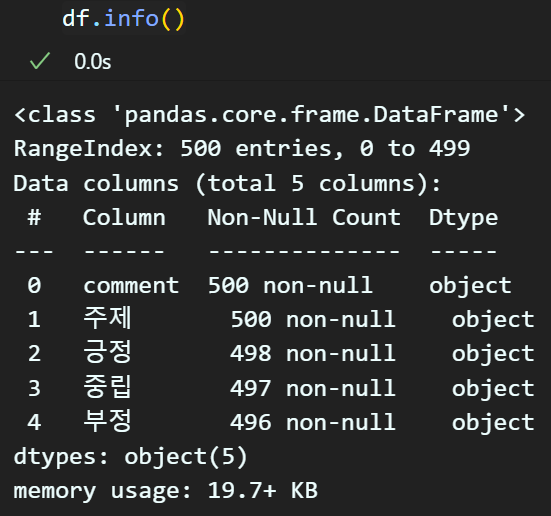
댓글 중 감정분석에 오류가 발생한 항목이 존재하니
# 오류 발생항목(결측치) 제거수행
df = df.dropna(how='any')위 코드로 결측치 제거를 수행한다.
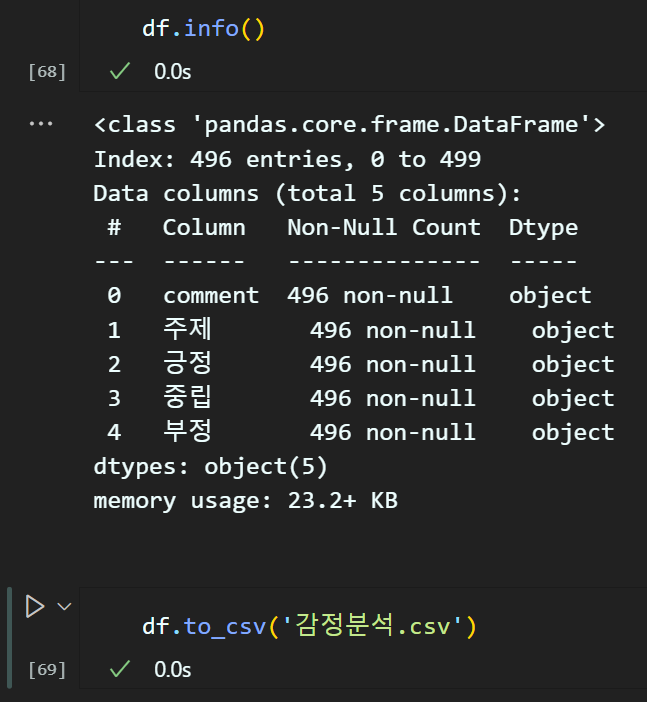
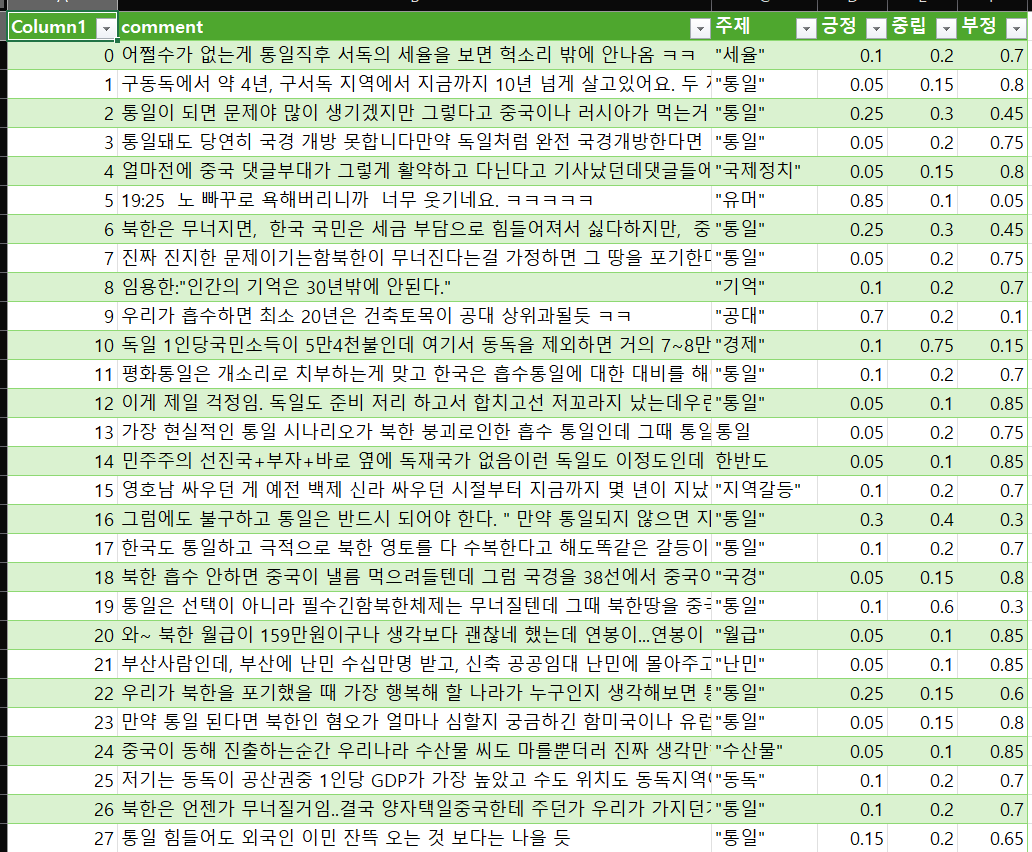
수행 결과물을 최종적으로 *.csv 형태로 저장하면
위 엑셀 프로그램을 통해 열람할 시
댓글원본, 해당 댓글이 다루는 주제, 주제에 대한 댓글이 가진 감정 (긍정, 중립, 부정) 3가지 값이 각각
올바르게 기입된 것을 확인할 수 있다.
감사의 글

본 포스트는 메타코드 서포터즈로서 작성하였습니다
