
도입
인공지능과 데이터 분야에 대한 관심이 점점 커지고 있는 요즘, 많은 사람이 실제로 어떻게 기술을 활용할 수 있을지 고민하고 있다. 이번 강의는 파이썬과 OpenAI API를 이용해 데이터를 다루고, 의미 있는 결과물을 도출하는 과정을 다룬다. 파이썬을 어느 정도 다룰 줄 안다면 누구나 따라 할 수 있는 실습 프로젝트들로 구성되어 있어, 학습자가 자신의 실력을 자연스럽게 발전시킬 수 있는 기회를 제공한다.
8개의 다양한 프로젝트를 통해, 자연어 처리부터 감정 분석, 데이터 시각화까지 다루며 현업에서 바로 적용할 수 있는 스킬들을 익힐 수 있다. 실제로 데이터 수집부터 분석, 그리고 모델 튜닝까지의 전체 과정을 경험하면서 AI와 데이터 사이언스의 기본기를 확실히 다질 수 있을 것이다.
지금 이 강의를 통해, 데이터의 세계에서 원하는 결과를 보다 쉽게 얻어보라. 어렵게 느껴질 수 있는 AI 기술이 실습과 프로젝트를 통해 친숙해질 것이다.

https://metacodes.co.kr/edu/read2.nx?M2_IDX=31635&EP_IDX=9859&EM_IDX=9683
1. 프로젝트 개요

마지막 프로젝트인 'Fine-Tuning'은 이미 학습이 완료된 모델에 대하여
추가적인 학습을 통해 해당 모델의 성능을 추가적으로 향상시키고자 하는 방안이라 보면 된다.
통상적으로 'Fine-Tuning'을 수행할 때는 여러 목적으로 사용하는 것이 가능한 일반화된 학습 모델을
유저의 특정 작업에 모델의 기능을 조금 더 특화시키는 과정을 수행하는 것이라 보면 된다.
OpenAI - API에서 제공하는 'Fine-Tuning'기능은 코드구현은 어렵지 않게 메서드가 다 정립되어 있지만
'Fine-Tuning'을 수행하려면 이를 위한 전용 훈련 데이터셋이 필요하며
이때 이 훈련 데이터셋이 OpenAI - API에서 요구하는
'Fine-Tuning' 데이터셋 포맷을 따라야 한다.
https://platform.openai.com/docs/guides/fine-tuning
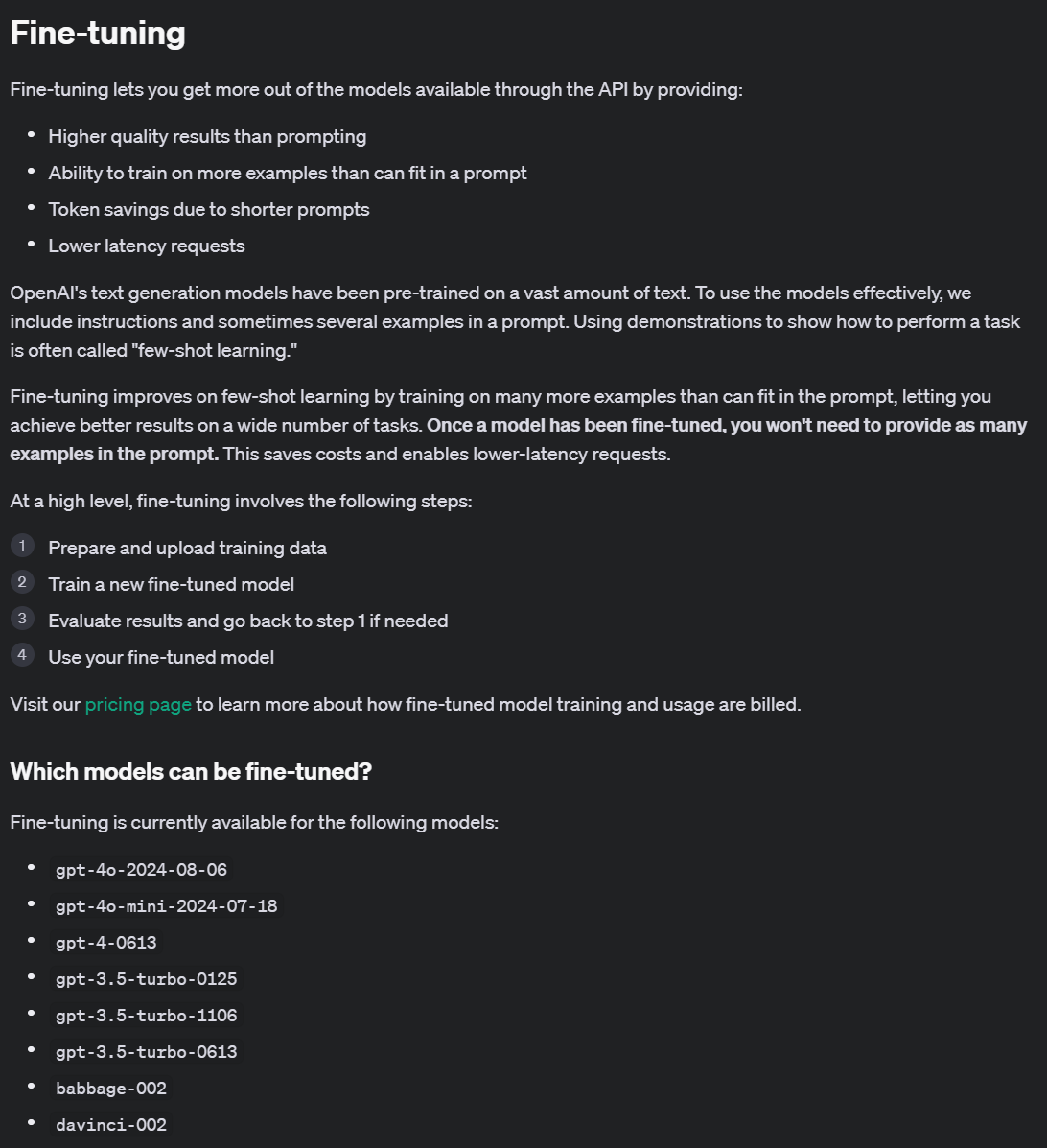
OpenAI의 Fine-tuning 문서를 살펴보면
1) Fine-tuning의 기대효과
2) Fine-tuning의 수행방법
3) Fine-tuning을 적용가능한 모델 리스트
가 기재되어 있으며

어떠한 방식으로 'Fine-tuning'을 수행할 수 있는지에 대한
Fine-tuning용 데이터셋 포맷에 대한 내용도 수록되어 있다.
위 규격에 맞춰 json 확장자 파일을 생성하고 이를 활용하면 된다.
2. Fine-tuning 수행
사전에 설치할 라이브러리
tiktoken 이라는 OpenAI에서 제공하는 토큰 관리 라이브러리를 먼저 설치해야 한다.
이것은 OpenAI용 토크나이저로 훈련 데이터셋은 모델에 입력될 시 토큰화(분절) 처리되어야 하는데
이를 수행하는 라이브러리라 보면 된다.
이 라이브러리를 활용하여 fine-tuning을 할 때 토큰이 ㅁ쳐개 소모되는지를 가늠할 필요성이 있다.
import tiktoken
def cal_token(sent, model):
# 인코딩 규격은 모델마다 다른듯 함
encode = tiktoken.encoding_for_model(model)
num_tokens = len(encode.encode(sent))
return num_tokens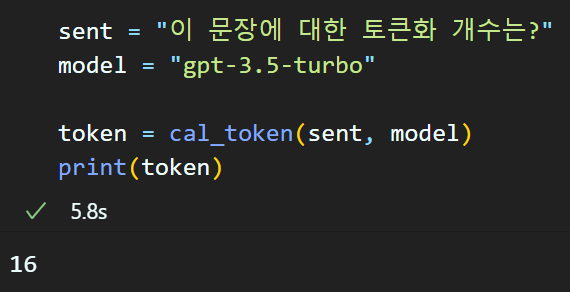
위와 같은 식으로 입력 데이터(문장)에 대한 인코딩 결과의 토큰이 몇개 발생하는지를 확인하여
Fine-tuning용 데이터셋이 총 몇개의 토큰을 소비하는지를 가늠해야 한다.
Fine-tuning용 데이터셋 규격

Fine-tuning용 데이터셋은
데이터 - 데이터 간 구분 : messages
하나의 데이터에 포함시킬 항목 : system, user, assistnat
위 포맷 규격을 준수해야 하며, 각 세부 항목별로 contnet에 훈련시킬 내용에 대한 정보가 기재되면 된다.
그리고 Fine-tuning용 데이터셋은 데이터가 최소 10개 이상 되어야 한다.
위 규격을 준수하는 데이터셋 파일을 *.jsonl
확장자로 저장한 후 해당파일을 불러와서 Fine-tuning을 수행하면 된다.
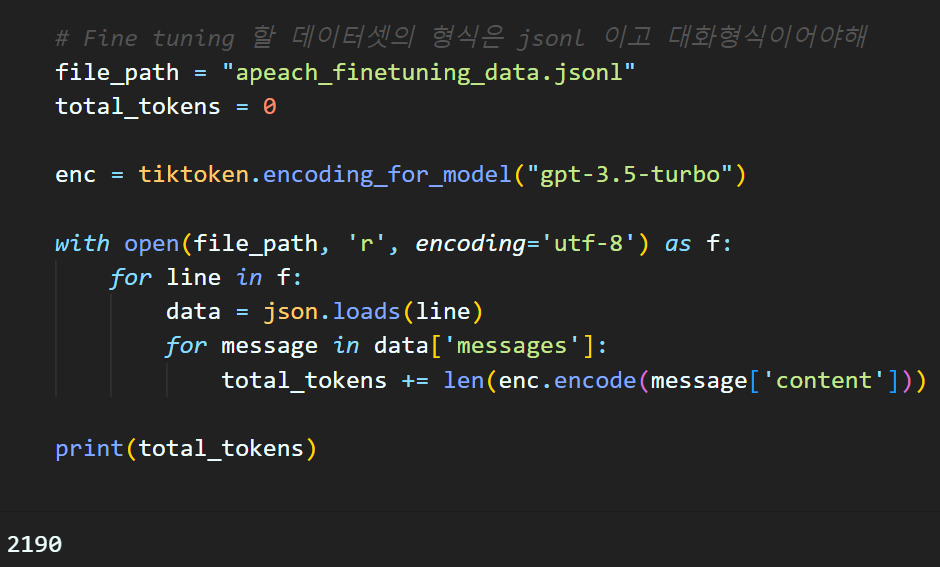
이제 생성한 jsonl 파일을 메세지 단위로 불러와서 해당 데이터셋이 갖고 있는 모든 토큰 개수를 계산한 후
해당 토큰 개수 당 가격을 연산하여 내가 Fine-tuning을 수행하는데 총 비용이 어느정도 소비될 지 가늠할 필요성이 있다.
file_path = "apeach_finetuning_data.jsonl"
total_tokens = 0
enc = tiktoken.encoding_for_model("gpt-3.5-turbo")
with open(file_path, 'r', encoding='utf-8') as f:
for line in f:
data = json.loads(line)
for message in data['messages']:
total_tokens += len(enc.encode(message['content']))
print(total_tokens)
예를 들어 GPT-3.5-turbo는 백만 토큰당 가격으로 정보가 기재되어 있고
현재 사용하는 예제는 그 비용이 그렇게 큰 편은 아니긴 하나
실제 Fine-tuning에 사용하는 데이터셋은 실습용 예제보다는 당연히 데이터량이 많을 것이니 비용소모를 필히 계산해야 한다.
Fine-tuning 수행
from dotenv import load_dotenv
from openai import OpenAI
import os
load_dotenv() # .env 파일의 환경 변수를 불러옴
api_key = os.getenv('OPENAI_API_KEY')
# API 키가 정상적으로 불러와졌는지 확인
#print(f"API Key: {api_key}")
client = OpenAI()client.files.create(
file=open("apeach_finetuning_data.jsonl", "rb"),
purpose="fine-tune"
)client.fine_tuning.jobs.create(
training_file = "[위 client.files.create메서드에서 나온 ID정보를 여기에 기입]",
model="gpt-3.5-turbo")Fine-tuning 작업은 위 두개의 메서드
client.files.create
client.fine_tuning.jobs.create만을 수행하면 된다.
수행된 결과물은 https://platform.openai.com/finetune/
페이지에 Fine-tuning 결과물이 업로드 되기에
Finetuning 결과물의 id정보를 홈페이지에서 확인하자
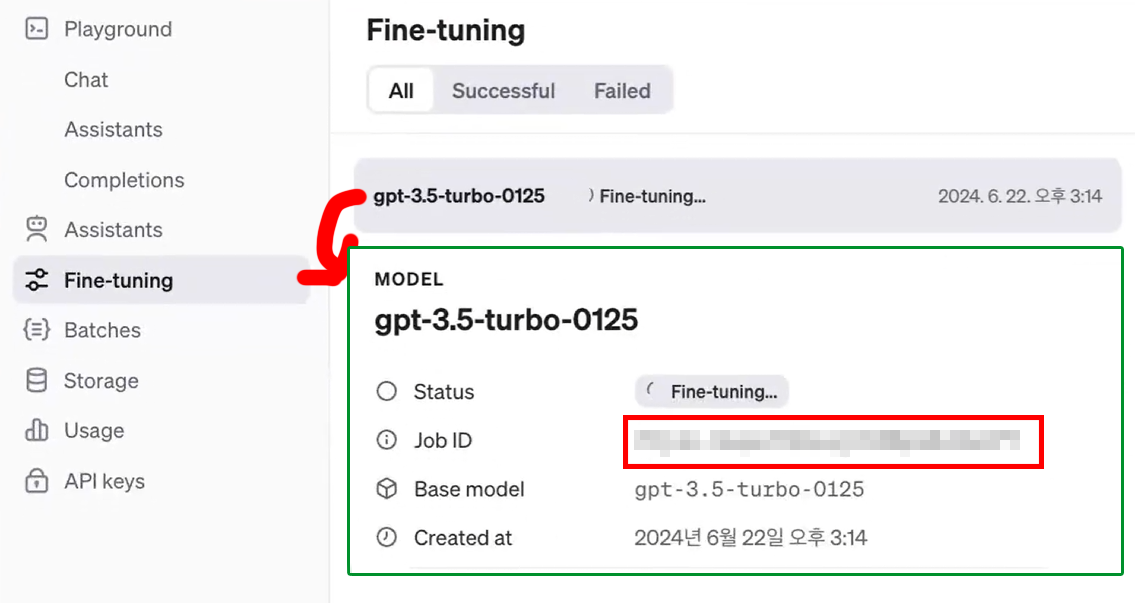
위 사진처럼 Fine-tuning이 완료된 모델이 OpenAI홈페이지에 등록되며, 이 모델의 ID정보를 불러와서 사용하면 된다.
# fine tuned model 불러오기
client.fine_tuning.jobs.retrieve('[https://platform.openai.com/finetune/ 에서 확인한 jobID를 여기에 기입]')위 코드가 Fine-tuning된 모델을 불러오는 코드라 보면 된다.
해당 모델을 불러온 뒤에 사용하는 방법은
completion = client.chat.completions.create(
model='ft:gpt-3.5-turbo-0125:personal::9cnQFnML',
messages=[
{"role": "system", "content": "You are an except assistant"},
{"role": "user", "content": "어피치가 누구인지 어디서 탄생했는지에 대한 배경을 3줄로 소개해줘."}
]
)일반 OpenAI의 여타 다른 메서드를 사용하는 것과 다르지 않다
Client객체에 Fine-tuning 된 모델이 등록되었기에
해당 모델을 기반으로 OpenAI-API의 여러 메서드가 구동된다
감사의 글

본 포스트는 메타코드 서포터즈로서 작성하였습니다
