
도입
인공지능과 데이터 분야에 대한 관심이 점점 커지고 있는 요즘, 많은 사람이 실제로 어떻게 기술을 활용할 수 있을지 고민하고 있다. 이번 강의는 파이썬과 OpenAI API를 이용해 데이터를 다루고, 의미 있는 결과물을 도출하는 과정을 다룬다. 파이썬을 어느 정도 다룰 줄 안다면 누구나 따라 할 수 있는 실습 프로젝트들로 구성되어 있어, 학습자가 자신의 실력을 자연스럽게 발전시킬 수 있는 기회를 제공한다.
8개의 다양한 프로젝트를 통해, 자연어 처리부터 감정 분석, 데이터 시각화까지 다루며 현업에서 바로 적용할 수 있는 스킬들을 익힐 수 있다. 실제로 데이터 수집부터 분석, 그리고 모델 튜닝까지의 전체 과정을 경험하면서 AI와 데이터 사이언스의 기본기를 확실히 다질 수 있을 것이다.
지금 이 강의를 통해, 데이터의 세계에서 원하는 결과를 보다 쉽게 얻어보라. 어렵게 느껴질 수 있는 AI 기술이 실습과 프로젝트를 통해 친숙해질 것이다.

https://metacodes.co.kr/edu/read2.nx?M2_IDX=31635&EP_IDX=9859&EM_IDX=9683
1. 프로젝트 개요
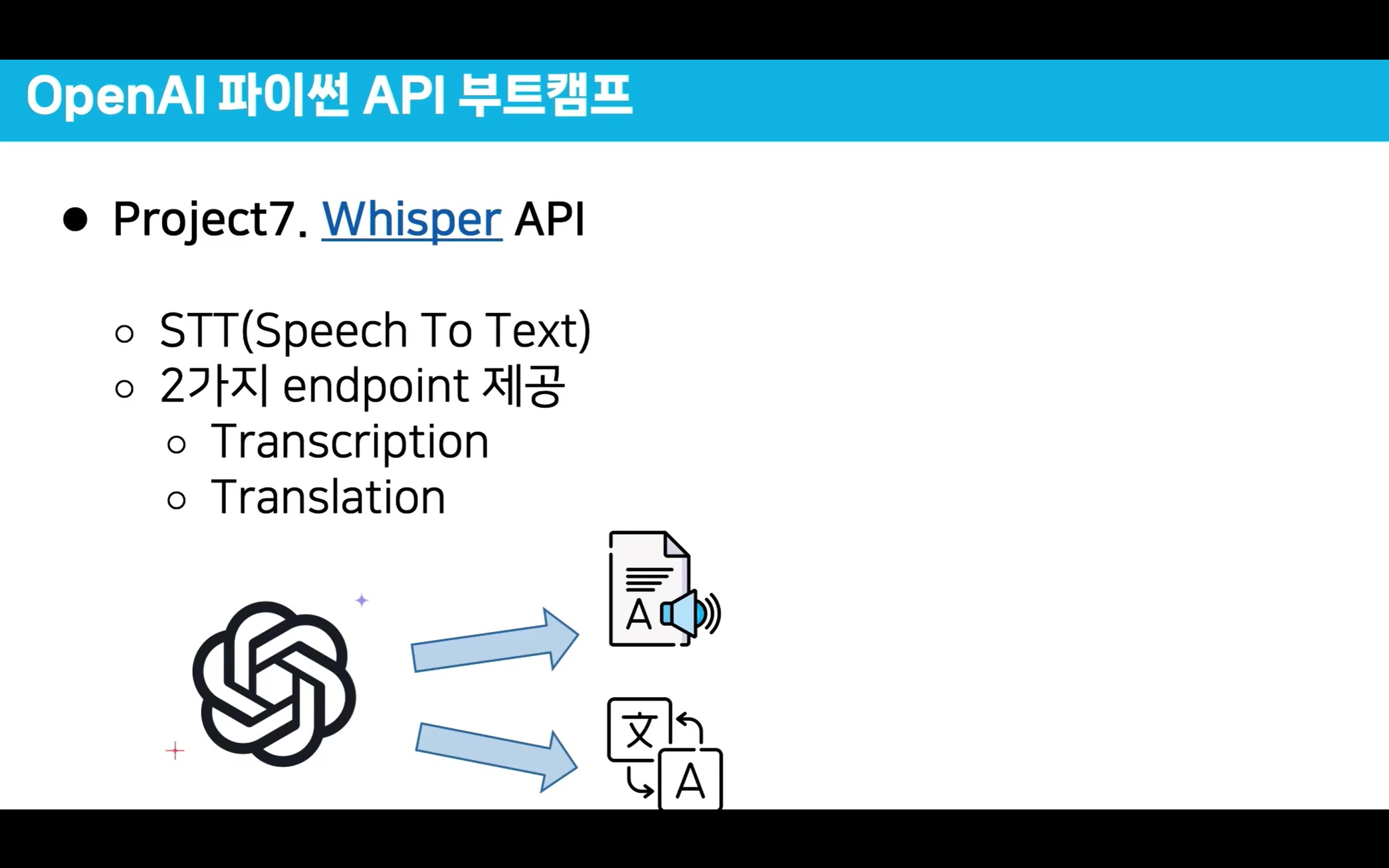
Wisper API는 STT(Speech To Text) 기능을 제공하는 API로
입력된 데이터가 '음성' 일 시 이를 텍스트로 변환해주는 기능이라 보면 된다.
Wisper API는
1) 오디오 파일을 텍스트 파일로 변환
2) 변환된 텍스트 파일을 번역
이 두가지 기능을 제공하며, 이때
2) 텍스트 파일의 번역은
원어 -> 영어 -> 목표 언어 이렇게 중간에 '영어'를 거쳐서 번역해야 하는 문제가 있다.
예를들어 한국어 -> 일본어로 번역을 한다면
한국어 -> 영어 -> 일본어 이렇게 번역이 이뤄진다

https://platform.openai.com/docs/guides/speech-to-text
OpenAI-WisperAPI의 공식문서를 살펴본다면
업로드 가능 파일형식 및 크기는 제한되어 있고
음성 -> 텍스트 변환이 지원되는 언어는
사진에서 보면 알 수 있듯이 한국어도 지원되긴 한다.
여기서 지원되는 언어의 기준은
WER(Word Error Rate) 라는 것으로
음성 -> 텍스트 변환 시 변환된 텍스트가 얼마나 정확한 단어로 변환되었는지의 평가지표라 보면 된다.
이 평가지표가 10% 이하 정도면 상용화가 가능한 지표라 보면 되며, Error 지표이기에 0%에 가까울 수록
음성 -> 텍스트 변환 성능이 높다
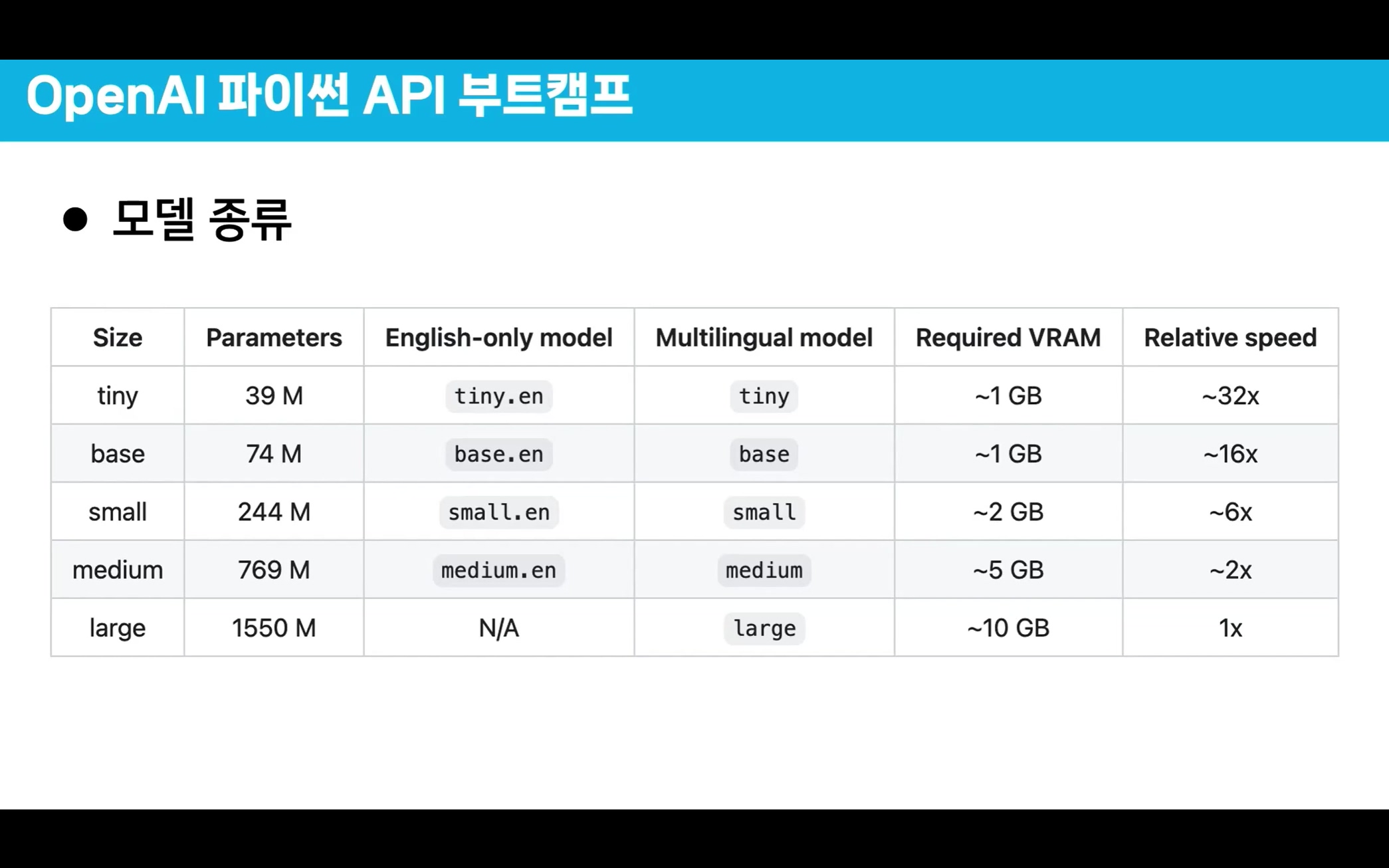
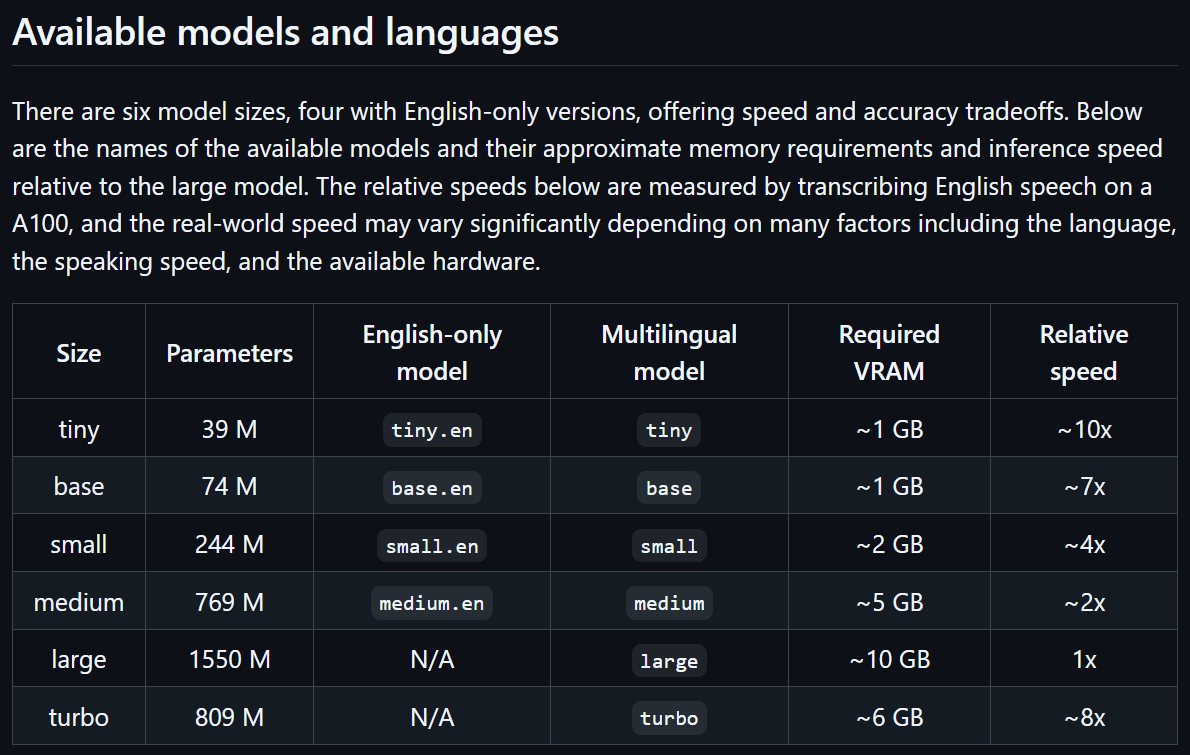
그리고 제공되는 모델도 영어 전용 / 멀티언어
두개의 모델에 모델의 크기도 tiny ~ Large 5개로 분류하고 있으며
당연히 모델이 무거울 수록 정확도는 올라가나, 성능은 하락하는 특성이 있음을 숙지해야 한다.
참고로 OpenAI에서는 whisper-1 1종의 모델만 제공하고 있으며
위 사진에서 언급하는 다양한 모델별 세부 파생모델(tiny, base, small, midium, large)는 Whisper 모델을 직접 다운로드하여 PC에 설치해 사용해야 한다.
https://openai.com/index/whisper/
https://github.com/openai/whisper
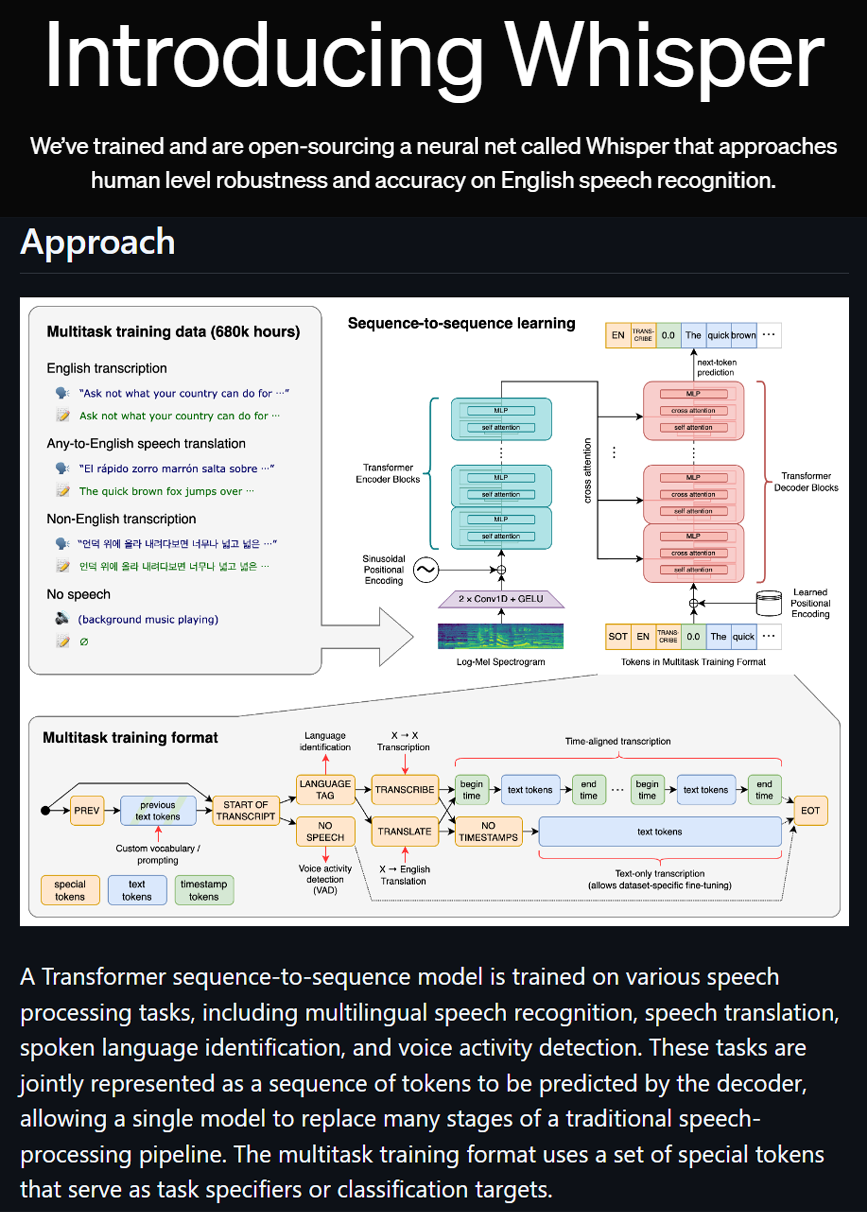
공식 홈페이지 설명 및 설계한 모델 정보 등이 기재되어 있으며, 내용을 확인해보면 Transformer를 기반으로 설계된 모델인 것을 확인할 수 있다.
참고로 OpenAI - WhisperAPI로 사용가능한 whisper-1모델은 위 파생모델 중 'MutliLanguage - Large'모델이다
2. Whisper API
먼저 OpenAI에서 제공하는 Whisper API의 사용방법을 숙지하기 위해 예제 오디오 파일을 생성하고 이를 텍스트 변환 하는 실습을 진행하고자 한다.
예제 오디오 파일은
1분짜리 유투브 영상의 오디오를 추출한 뒤 이를 텍스트 변환하고자 한다.
from pytubefix import YouTube
from pytubefix.cli import on_progress
def down_audio(youtube_url, save_path):
try:
# 유투브 라이브러리를 통해 URL정보 전송
yt = YouTube(youtube_url, on_progress_callback=on_progress)
# 오디오 스트림 정보 추출
audio_stream = yt.streams.filter(only_audio=True).first()
# 오디오 스트림 정보 추출 후 이를 파일로 저장
audio_file = audio_stream.download(output_path=save_path)
except Exception as e:
print(f"오디오 추출 실패 : {e}")url = 'https://www.youtube.com/watch?v=Zm_PauWy_jo'
save_path = './data'
down_audio(url, save_path)원래는 유투브 영상을 다운로드하는데는

pytube라이브러리가 주로 사용되나
HTTP Error 400: Bad Reques와 같은 오류가 계속 발생해서
해당 라이브러리의 오류를 수정한 라이브러리인
pytubefix를 사용하여 영상 내 오디오 정보만 추출하여 다운로드를 진행했다.
다운로드한 파일은 해당 파일의 유투브 영상 제목으로 선정되는 듯 하다.
파일명은 사용이 용이하게 'test_audio.mp4'로 변경한다.
다음으로 Whisper API사용을 위한 사전설정을 해주자
from dotenv import load_dotenv
from openai import OpenAI
import os
load_dotenv() # .env 파일의 환경 변수를 불러옴api_key = os.getenv('OPENAI_API_KEY')
# API 키가 정상적으로 불러와졌는지 확인
#print(f"API Key: {api_key}")
client = OpenAI()다음으로 파일을 불러오자
audio_file_path = './data/test_audio.mp4'# 파일을 바이너리 모드로 열어서 파일 객체를 전달
with open(audio_file_path, "rb") as audio_file:
trans_script = client.audio.transcriptions.create(
model="whisper-1",
file=audio_file
)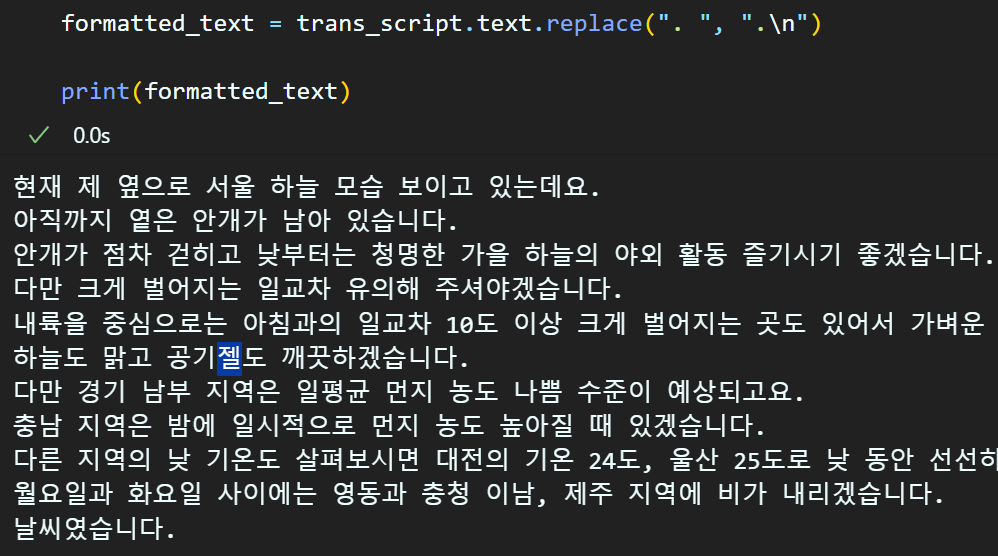
숙련된 발음 및 발성훈련을 받은 기상캐스터가 주변 배경소음이 차단된 스튜디오 환경에서 생성한 음성정보이기에 정보의 순도가 높은 부분도 있지만
전체 음성 데이터의 텍스트 정보 변환 중
단 한글자만 제외하고 성공적으로 텍스트 변환이 수행됨은 꽤 놀라운 성능이라 볼 수 있다.
with open(audio_file_path, "rb") as audio_file:
trans_script = client.audio.transcriptions.create(
model="whisper-1",
file=audio_file,
language= 'ko', # ISO 639 언어국적 코드
temperature=0.0, # 0이면 창의성 없이 수행하라는 뜻
# 즉 음성 듣는 그대로 출력하라는 뜻
# 출력하는 텍스트에 형식을 지정할 수 있음
# 기본 : json -> 타임스탬프가 포함됨
# 텍스트만 추출 : text
# 상세정보(메타데이터)포함 : verbose_json
response_format= 'verbose_json',
# 출력할 때 감지된 단어에 대한 meta_data가 생성되게
timestamp_granularities=["word"]
)추가로 Whisper_API는 좀 더 다양한 파라미터 설정이 가능하고
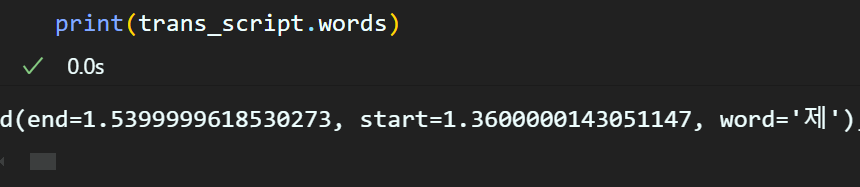
옵션은 다양하게 설정할 수록 변환한 텍스트에 대한 상세분석이 가능해진다.
https://platform.openai.com/docs/api-reference/audio/createTranscription
상세옵션에 대한 지정은 위 document를 좀 더 참조하자
3. Whisper 설치
다음으로는 https://github.com/openai/whisper
OpenAI에서 제공하는 Whisper API의 원본 모델인
Whisper을 직접 PC에 설치하여 사용하고자 한다.
이는 현재 Whisper모델이 v3까지 업데이트가 완료되기도 했고 최신모델인 Turbo는 Large에 준하면서 성능 최적화까지 진행되었기에 여러모로 Speech-to-text task를 수행하는데는 모델을 직접설치하여 사용하는게
API를 활용하는 것보다 효용성이 더 있는 편이다.
해당 모델은 꾸준하게 업데이트가 진행되고 있기에
아래의 명령어로 설치하는것이 더 좋다
! pip install git+https://github.com/openai/whisper.git ## 3.0 사용 전 수행해야 할 내용
Whisper를 제대로 사용하기 위해서는
ffmpeg를 설치해야 하며
ffmpeg를 손쉽게 설치하기 위해서는 Chocolatey를 설치해야 한다(윈도우 환경)
하나하나 설치를 진행하도록 하자
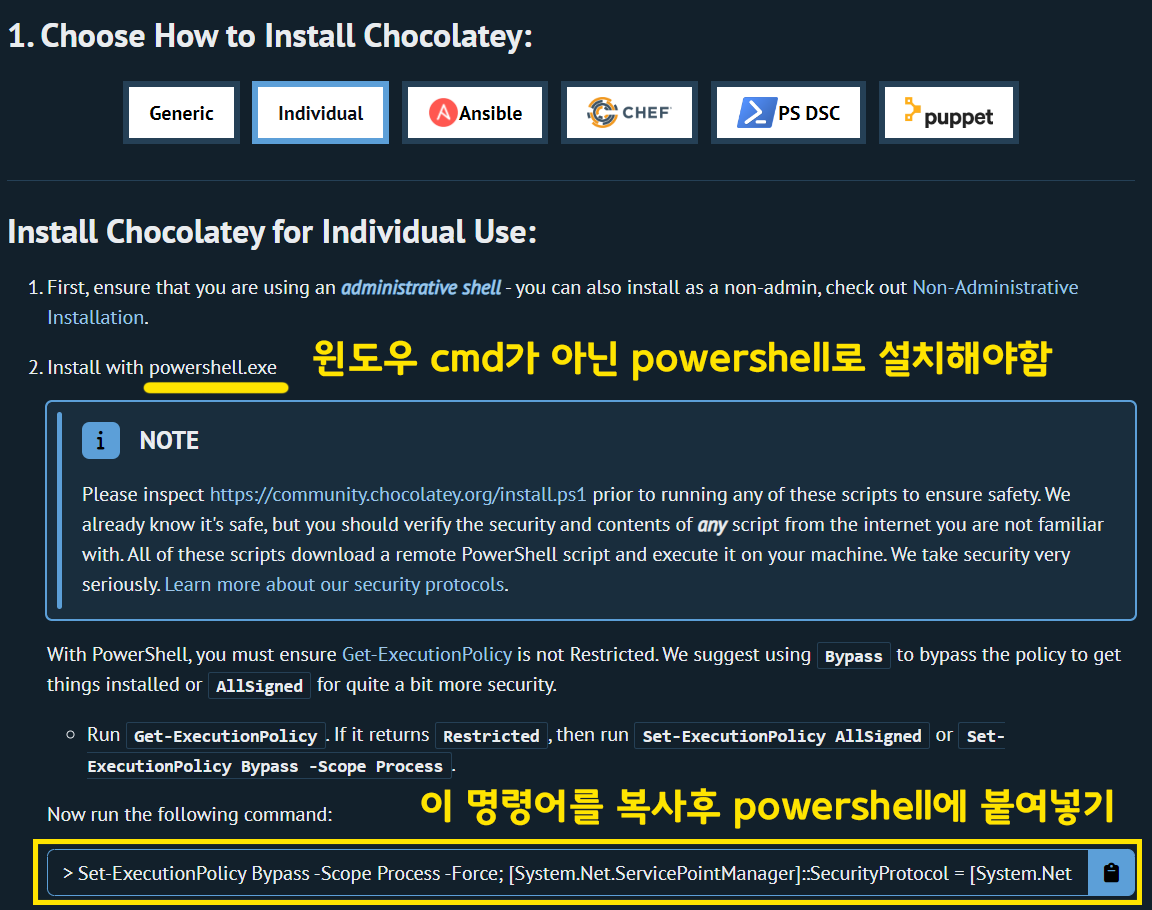
Chocolatey설치
https://chocolatey.org/install#individual
먼저 홈페이지에 접속을 한 뒤
아래의 명령어 부분을 copy한다.
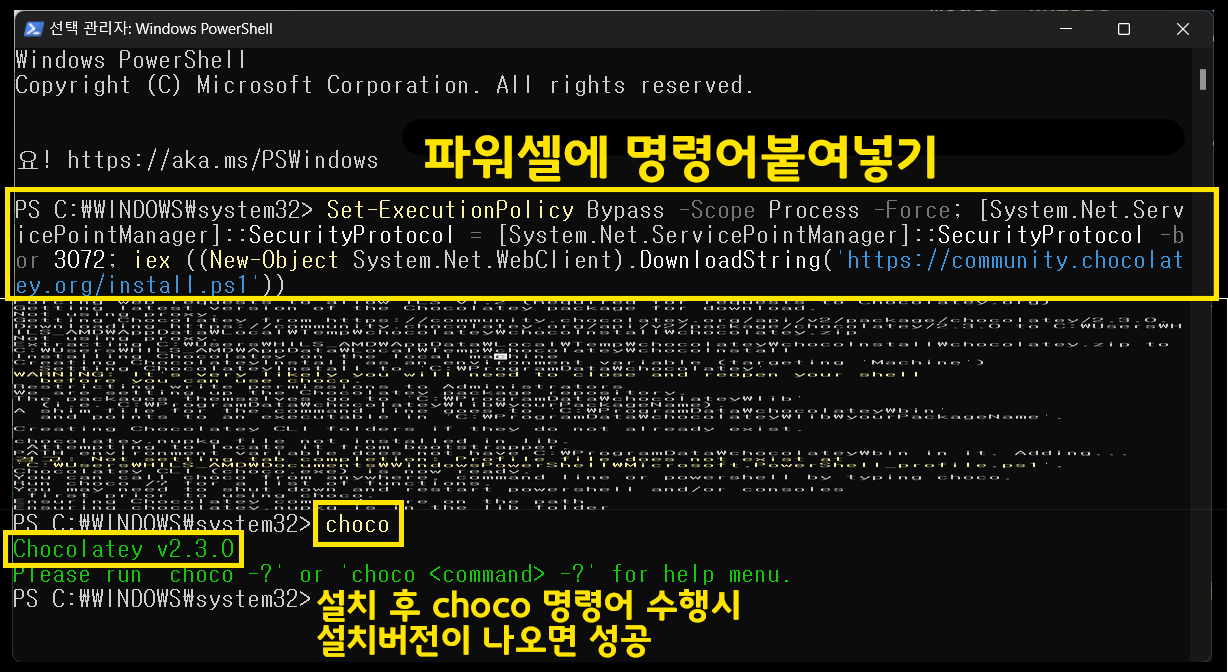
ffmpeg설치
위 Chocolatey 설치를 완료했다면 ffmpeg는 매우 손쉽게 설치하는것이 가능하다
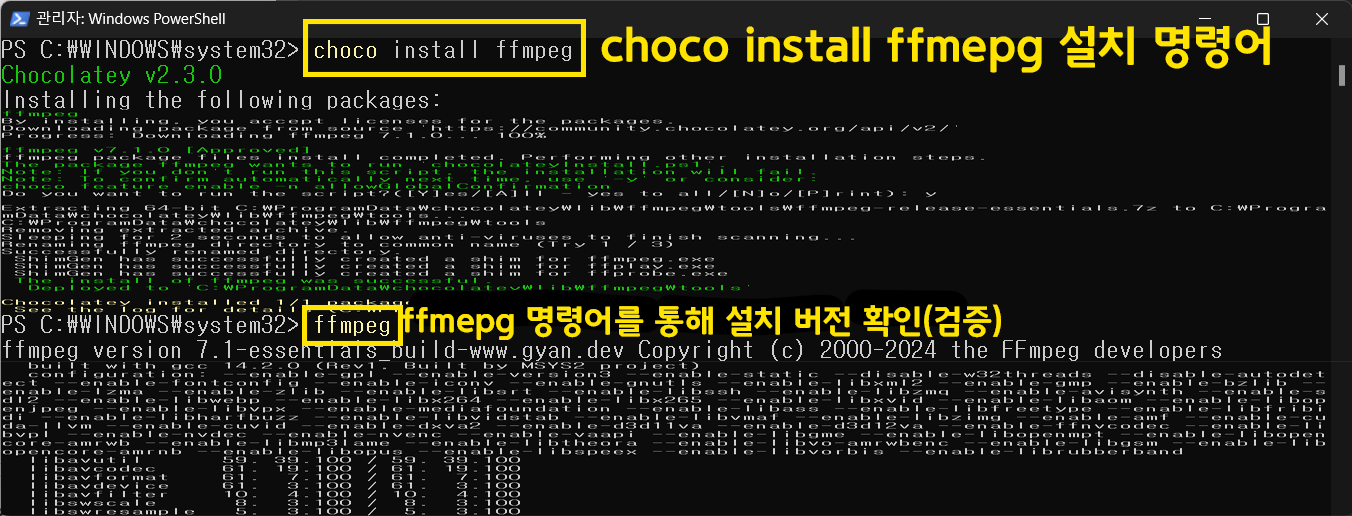
3.1 Whisper로 음성->텍스트 변환
import whisper우선 라이브러리를 로드한 뒤
# whisper 라이브러리의 모델 불러오기
# model = whisper.load_model("large")
model = whisper.load_model("turbo")whisper 객체를 통해 모델을 불러오면 된다.
이때 사용가능한 모델은 available_models 메서드를 참조하자

이때 large모델을 최적화 한 것이 turbo이며,
두개의 성능을 비교하면 아래와 같다.
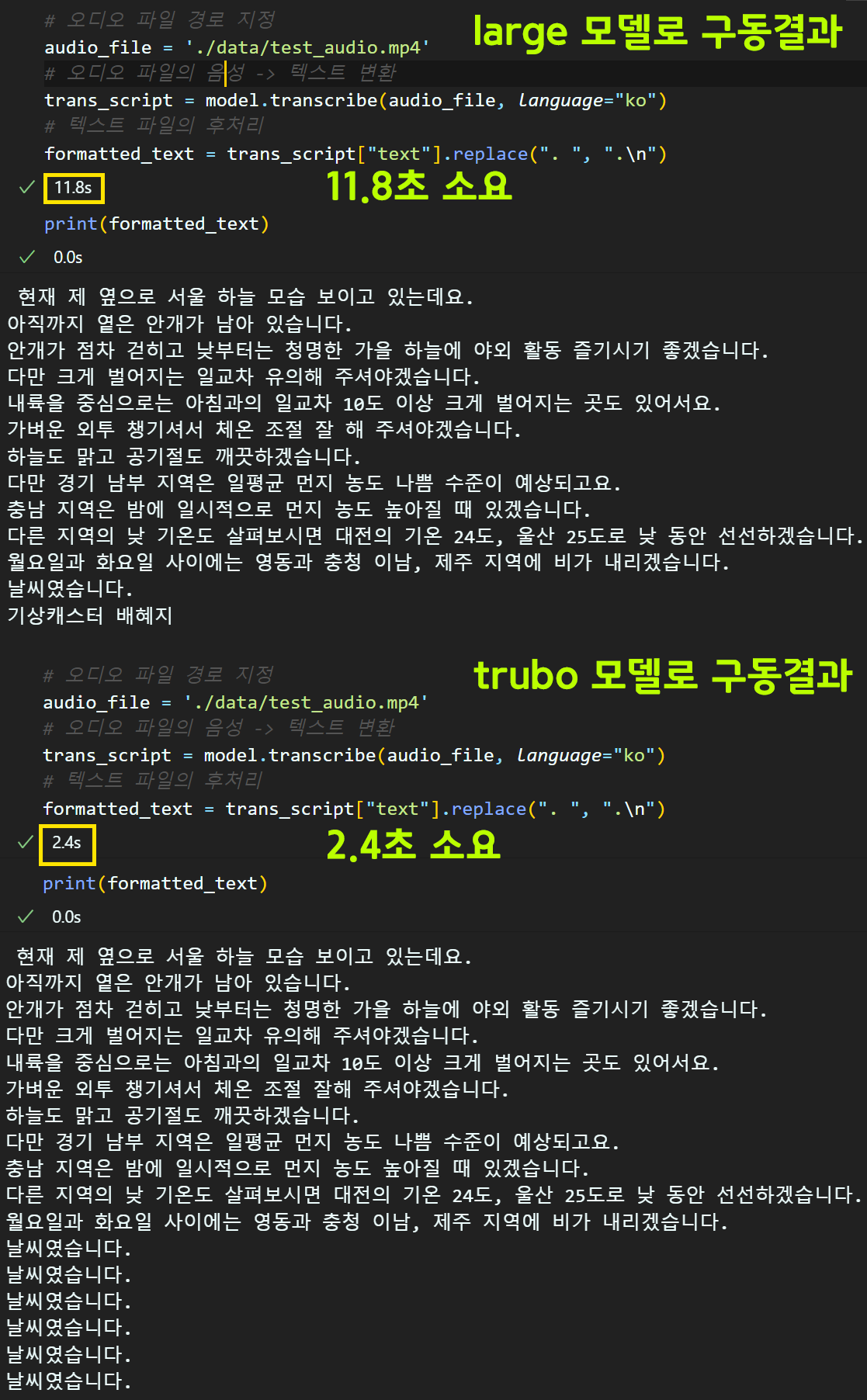

turbo모델은 꽤 최신 릴리즈된 모델이기도 하고
기존 large모델을 최적화 시킨 모델이기에
해당모델로 이후 작업을 수행하도록 하겠다.
4. Whisper로 영상 자막 만들기
위 Whisper 모델을 활용하여 음성 -> 텍스트 변환을 수행하면

변환된 파일은 딕셔너리 형식으로 출력되며,
주요 3가지 하위 원소text, segments, language 3개가 있으며,
segments항목을 응용하면 영상자막을 생성할 수 있다.
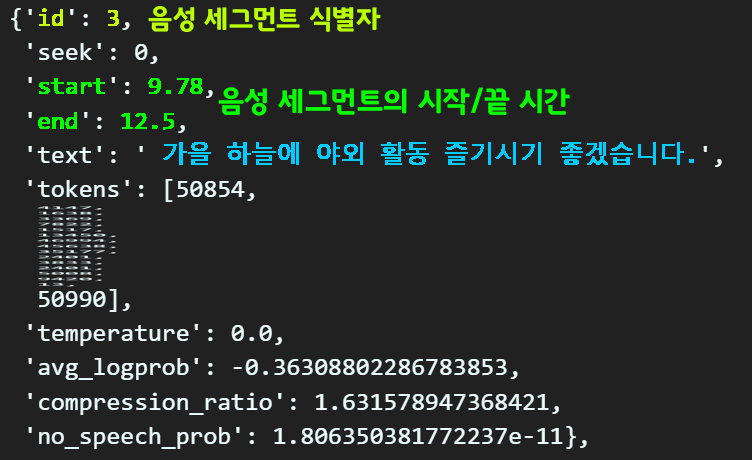
음성 세그먼트는 화자가 speech를 수행할 때
말 하는 것이 쉬는 텀을 단위로 세그먼트가 분리되며
이것이 자막과 다음 자막을 나누는 기준이 된다
그리고 하나의 음성 세그먼트에는 시작 시간 / 종료시간이 존재하니 이를 자막의 시작 / 끝 시간으로 지정하면 된다
이를 구현하기 위한 코드는 아래와 같다.
# SRT(자막) 파일 생성함수
def write_srt(tr_sc_seg, srt_save_path):
with open(srt_save_path, 'w', encoding='utf-8') as srt_file:
for segment in tr_sc_seg:
# 세그먼트에서 시작/종료/텍스트 파일 추출
idx = segment['id']
st_time = segment['start']
ed_time = segment['end']
text = segment['text']
# 시간을 SRT 자막 시간 표기형식으로 변환
def format_time_srt(time):
hr = int(time // 3600)
min = int((time % 3600) // 60)
sec = int(time) % 60
m_sec = int((time - int(time)) * 1000)
f_time = f"{hr:02}:{min:02}:{sec:02},{m_sec:03}"
return f_time
# 자막 인덱스 번호 기입
srt_file.write(f'{idx+1}\n')
# 자막의 시작 및 종료시간을 foramt에 맞춰 기입
st_srt = format_time_srt(st_time)
ed_srt = format_time_srt(ed_time)
srt_file.write(f"{st_srt} --> {ed_srt}\n")
# 자막 내용(텍스트)기입
srt_file.write(f"{text}\n\n")# SRT 파일 생성
srt_file_path = './data/test_sub.srt'
write_srt(trans_script['segments'], srt_file_path)생성한 srt파일을 열람하면
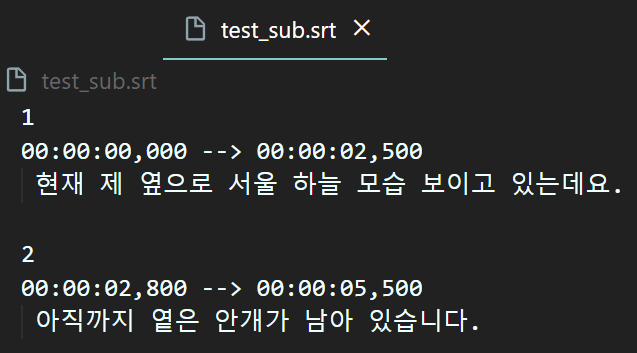
위와 같이 시작시간 / 종료시간 그리고
해당 시간동안 출력될 자막
이 3가지 항목이 srt 자막 파일 format에 맞춰 올바르게 생성됨을 확인할 수 있다.
생성된 자막을 원본 영상과 함께 출력하면 아래와 같다
자막의 경우 싱크가 안맞는 문제가 존재하고
또 일부 자막이 올바르게 텍스트변환이 이뤄지지 않음을 확인할 수 있으니 후처리 작업은 어느정도는 해줘야 한다.
감사의 글

본 포스트는 메타코드 서포터즈로서 작성하였습니다
