
서론
Agent를 설계하는데는 당연히 코어로 LLM을 사용해야 하고 LLM을 온라인 서빙 LLM인 Chat-GPT, Claude, Gemini를 사용하다 보면
점점 온-프레미스 LLM (내 PC에 LLM을 설치해서 사용해보기)에 관심이 생기게 된다.
이때 사용하는 것이 Inference Engine (추론 엔진)이다.
이 LLM 추론엔진은 워낙 종류가 많기에 A Survey on Inference Engines for Large Language Models: Perspectives on Optimization and Efficiency 와 같이 논문으로 정리가 되기도 하지만
필자가 느끼기에 주로 접근이 가능한 추론 엔진이
llama.cpp, ollama, 허깅페이스 TGI, vLLM 정도가 있다.
이 중 vLLM이 paged attention 방식을 통해 다른 추론 엔진 대비 토큰 생성 속도(TPS : Token Per Second)가 빠르다는 장점이 있다.
그러나 paged attention기능은 항시적으로 VRAM을 점유해야 하고, 이 VRAM의 점유량을 조절하는 인자값인 gpu_memory_utilization이 자유롭게 조정이 되는 편이 아니다.
(이정도면 KV cache에 충분한 vram을 할당했다 생각해도 메모리 용량 부족으로 로딩 실패가 심심찮게 발생함)
그러나 다른 나머지 3개의 추론 엔진은 그렇게 빠른 TPS를 보장하는 편은 아니기에
Nvidia에서 개발한 오픈소스 라이브러리 기반 추론엔진인
TensorRT-LLM을 사용해보고자 한다.
TensorRT-LLM 개요 및 감상평
TensorRT-LLM도 vLLM과 동일하게 paged attention방법론을 통하여 추론속도 향상을 꾀하고 있으며, 그 외의 TPS속도를 향상시키기 위한 In-flight Batching기술도 적용하고 있다.
내부적으로 LLM의 서빙에 최적화된 기술은 vLLM이나 TensorRT-LLM이 비슷비슷한 내용이 많긴 하지만
vllm은 다양한 병렬 연산처리 환경에서도 해당 추론 엔진이 동작 할 수 있게끔 Python 생태계 기반으로 코드개발이 이뤄졌다면
TensorRT-LLM은 애초에 Nvidia GPU에서 특화되어 구동되게끔 설계한 오픈소스 라이브러리여서 C++기반으로 메모리 관리가 수행되고, Nvidia의 CUDA Kernel을 적극적으로 활용하는 측면이 있다.
이게 최적화 효율은 더 좋긴 하지만 Nvidia특유의 알아보기 힘든 Document 관리체계랑 시너지를 이루면서
사용자 풀이 정말 좁아지는 참사가 발생한다.
https://docs.nvidia.com/tensorrt-llm/index.html
Tensor-RT LLM의 소개 홈페이지를 보면

설명구문에는 easy-to-use Python API라고 하지만
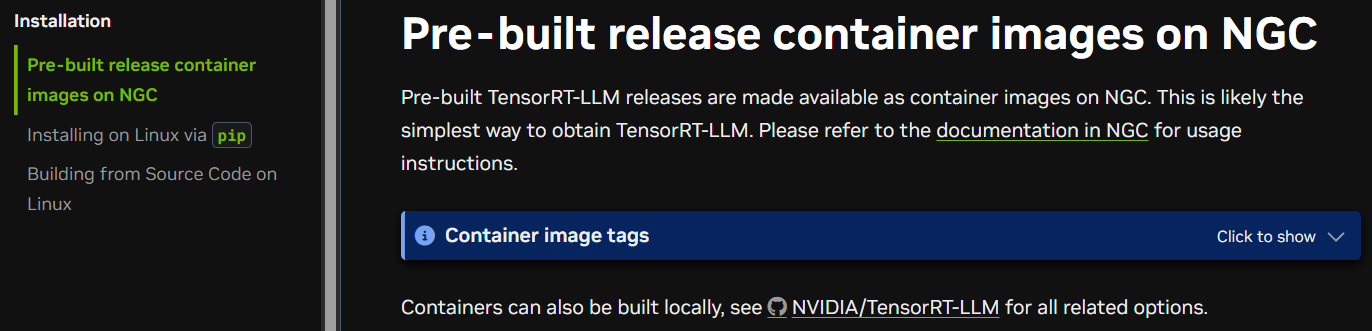
실제 Docu를 보면 TensorRT-LLM 라이브러리만 딱 설치된 NGC 컨테이너 사용을 먼저 소개하고 있다.
이게 참 문제인게 고작 추론 엔진 하나 구동하는데 docker 사용을 먼저 권장하고 있다.
https://docs.vllm.ai/en/latest/getting_started/installation/gpu.html
대조군에 속하는 vllm은 최대한 설치과정을 먼저 다 소개한 뒤 한참을 내려가서야 Docker기반으로 vllm구동 과정을 소개하고 있어서
이 부분은 문제가 있다.
그리고 https://nvidia.github.io/TensorRT-LLM/installation/linux.html
여기서도 보면 알 수 있지만 의외로 Ubuntu도 24.04버전에서만 테스트 했다 하고 있고 CUDA 커널도 현재 Nvidia에서 판매중인 GPU사용자만을 상정해서 12.8버전으로 설명하고 있다.
아무튼.. pip방식으로 설치하는건 많이 어려움이 있다.
WSL-Ubuntu 24.04설치하기
https://nvidia.github.io/TensorRT-LLM/installation/linux.html
첨부한 웹페이지에서 설치 내용을 살펴본다면
먼저 CUDA Installation Guide for Linux 문서를 바탕으로 환경변수 CUDA_HOME까지 설정을 완료하라는데
문서를 보고 따라하면 머리에 쥐 나온다
TensorRT-LLM보다 더 많은 양의 문서로 되어 있는게
CUDA Installation Guide for Linux이다.
즉, 쓸데없는 내용이 너무많다.
이를 WSL-Ubuntu기반 / CUDA 12.8설치로 한정하면 아래와 같이 요약할 수 있다.
CUDA Toolkit 12.8 설치
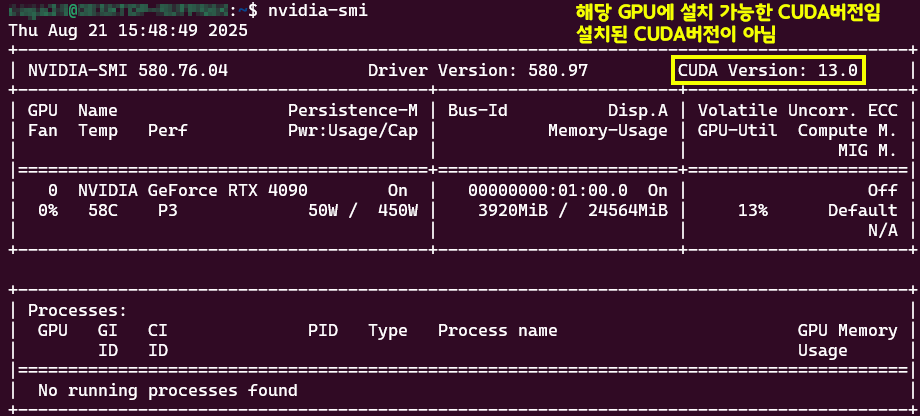
먼저 WSL-Ubuntu 24.04를 설치하면 기본적으로 GPU드라이버는 탑재된 상태로 설치된다.
따라서 nvidia-smi는 기본적으로 사용 가능하다.
다음으로 CUDA Toolkit Archive 페이지에 접속해서 CUDA 12.8.1을 다운로드 받는 방법을 찾는다.
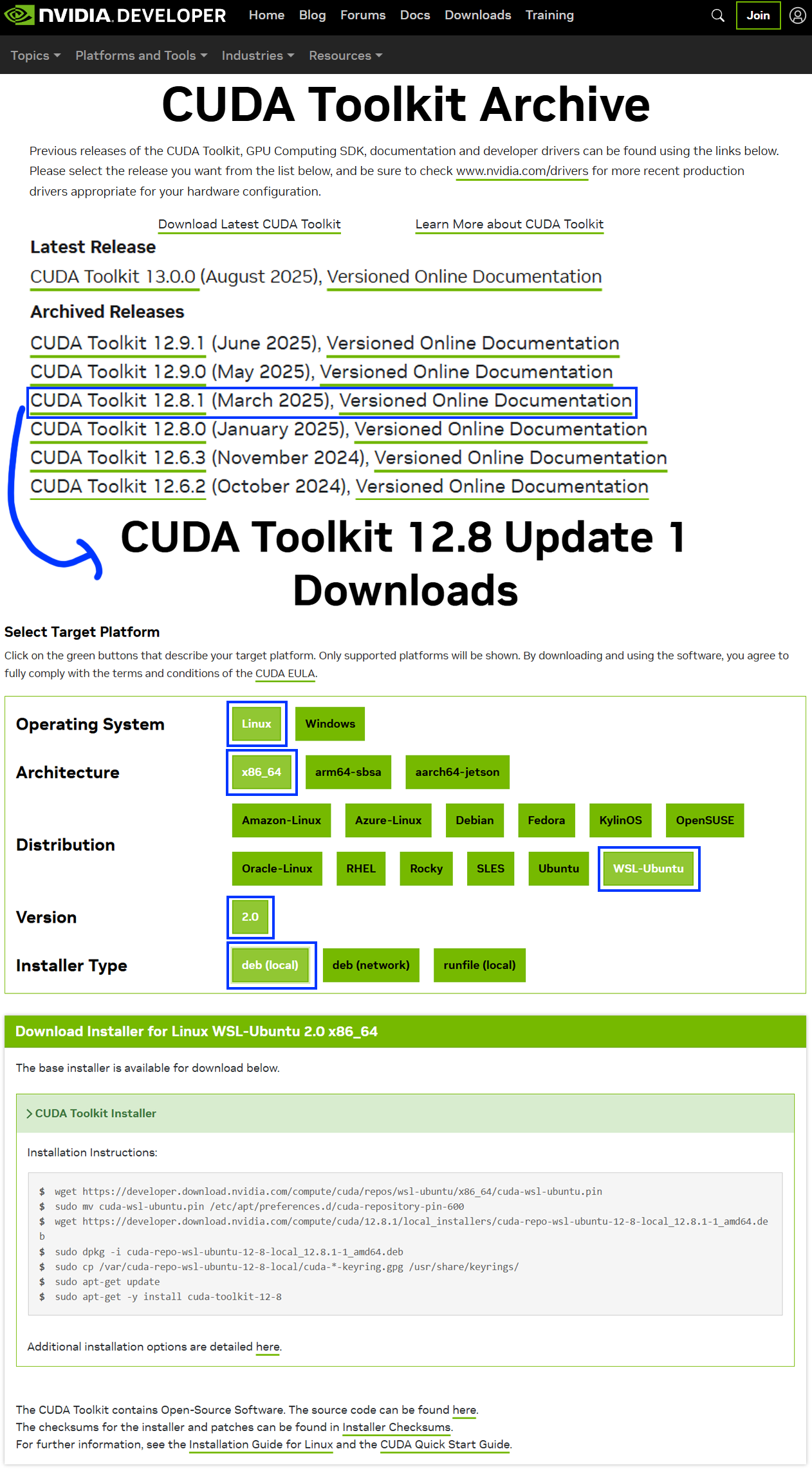
wget https://developer.download.nvidia.com/compute/cuda/repos/wsl-ubuntu/x86_64/cuda-wsl-ubuntu.pin
sudo mv cuda-wsl-ubuntu.pin /etc/apt/preferences.d/cuda-repository-pin-600
wget https://developer.download.nvidia.com/compute/cuda/12.8.1/local_installers/cuda-repo-wsl-ubuntu-12-8-local_12.8.1-1_amd64.deb
sudo dpkg -i cuda-repo-wsl-ubuntu-12-8-local_12.8.1-1_amd64.deb
sudo cp /var/cuda-repo-wsl-ubuntu-12-8-local/cuda-*-keyring.gpg /usr/share/keyrings/
sudo apt-get update
sudo apt-get -y install cuda-toolkit-12-8위 과정을 충실하게 이행한 후에는 cuda 툴킷버전을 환경변수에 등록해준다. .bashrc에 아래의 코드를 환경변수로 등록해주면 된다.
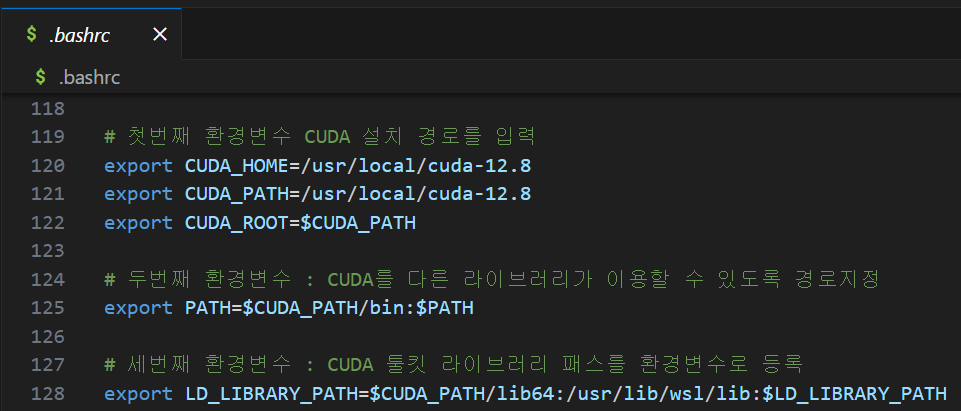
# 첫번째 환경변수 CUDA 설치 경로를 입력
export CUDA_HOME=/usr/local/cuda-12.8
export CUDA_PATH=/usr/local/cuda-12.8
export CUDA_ROOT=$CUDA_PATH
# 두번째 환경변수 : CUDA를 다른 라이브러리가 이용할 수 있도록 경로지정
export PATH=$CUDA_PATH/bin:$PATH
# 세번째 환경변수 : CUDA 툴킷 라이브러리 패스를 환경변수로 등록
export LD_LIBRARY_PATH=$CUDA_PATH/lib64:/usr/lib/wsl/lib:$LD_LIBRARY_PATH만약 wsl 우분투 환경이 아닌 메인 OS를 우분투로 사용하는 경우라면
세번째 환경변수만 아래 경로로 바꾸면 된다
# 세번째 환경변수 : CUDA 툴킷 라이브러리 패스를 환경변수로 등록
export LD_LIBRARY_PATH=$CUDA_PATH/lib64:$LD_LIBRARY_PATH여기서 추가로 pip로 설치한 라이브러리들이 CLI환경에서 구동가능하도록 PATH를 추가로 환경변수로 등록한다
# 영번째 환경변수 : 리얼 우분투에서는 pip 설치경로로 지정해야함
export PATH=$PATH:~/.local.bin환경변수 등록 후 source ~/.bashrc로 환경변수 변경사항을 업데이트 해준 뒤
아래 명령어가 실제로 동작하는지 확인해보자
nvcc --version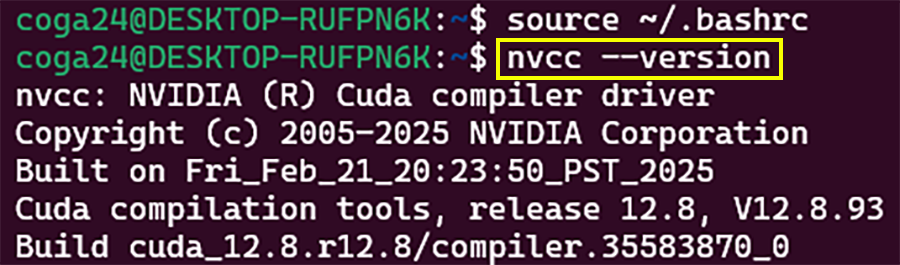
여기까지 완료를 해줘야 이제 본격적으로 TensorRT-LLM설치 진입이 가능해진다..
pip로 TensorRT-LLM 설치
WSL-ubuntu 24.04에는 기본적으로 Python3.12가 설치되어 있다
이제 아래 사전 설치 라이브러리를 순차로 설치를 진행한다.
# 시스템 패키지 및 라이브러리 업데이트 & 업그레이드
sudo apt update && sudo apt upgrade -y
# pip3 설치
sudo apt install -y python3-pip
# pip와 setuptools 업그레이드
pip3 install --upgrade pip setuptools
# OpenMPI 및 추가 필수 시스템 패키지 설치
sudo apt-get -y install libopenmpi-dev build-essential만약 위 설치과정 중 PEP668 에러이 나온나면 .bashrc에 아래구문을 하나 더 추가하자

# PEP 668 에러 우회 방법
export PIP_BREAK_SYSTEM_PACKAGES=1여기까지 진행한 뒤에 파이토치 라이브러리를 설치하자
여기서 공식 문서에서는
pip3 install torch==2.7.1 torchvision torchaudio --index-url https://download.pytorch.org/whl/cu128이렇게 되어있으니 그대로 따라서 설치하자
괜히 최신버전 설치하면 문제가 생긴다.
설치를 완료한 후애는 아래 명령으로 설치가 잘 되었는지 확인하자
python3 -c "import torch; print(f'PyTorch: {torch.__version__}')"
이제 TensorRT-LLM을 설치하자
pip3 install tensorrt_llm설치 후 오류수정
위 과정까지 수행한 후 아래 명령어를 실행하면 오류가 발생한다.
python3 -c "from tensorrt_llm import LLM, SamplingParams"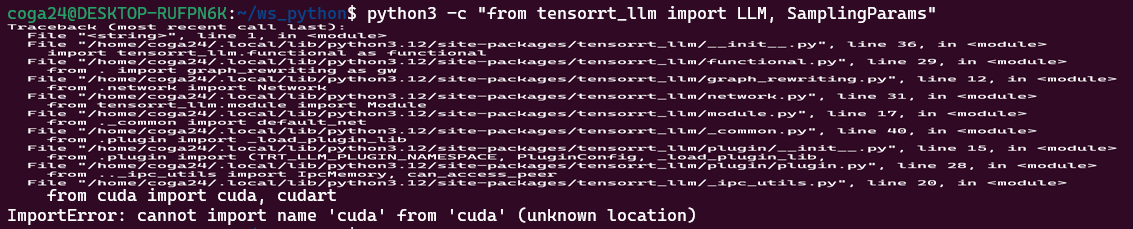
이렇게 위 사진처럼 cuda 버전을 모른다는 오류가 발생하는데
이것은 파이썬 라이브러리 중 cuda-python이 버전 미스매칭으로 발생한 오류이다.
# 설치된 파이썬 라이브러리 정보 확인
pip list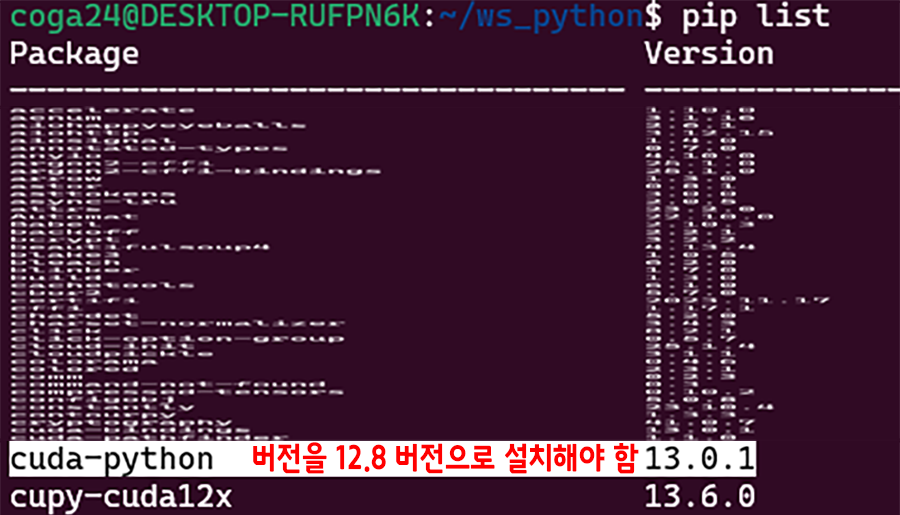
pip3 uninstall cuda-python # 기존의 cuda-python 삭제
pip3 install cuda-python==12.8.* # cuda toolkit과 호환되는 버전으로 설치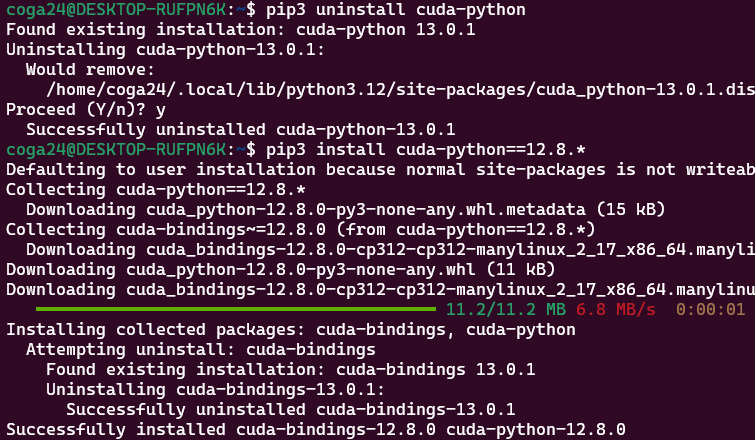
이러고 다시 TensorRT-LLM 검증코드를 돌리면 잘 동작할것이다.
python3 -c "from tensorrt_llm import LLM, SamplingParams"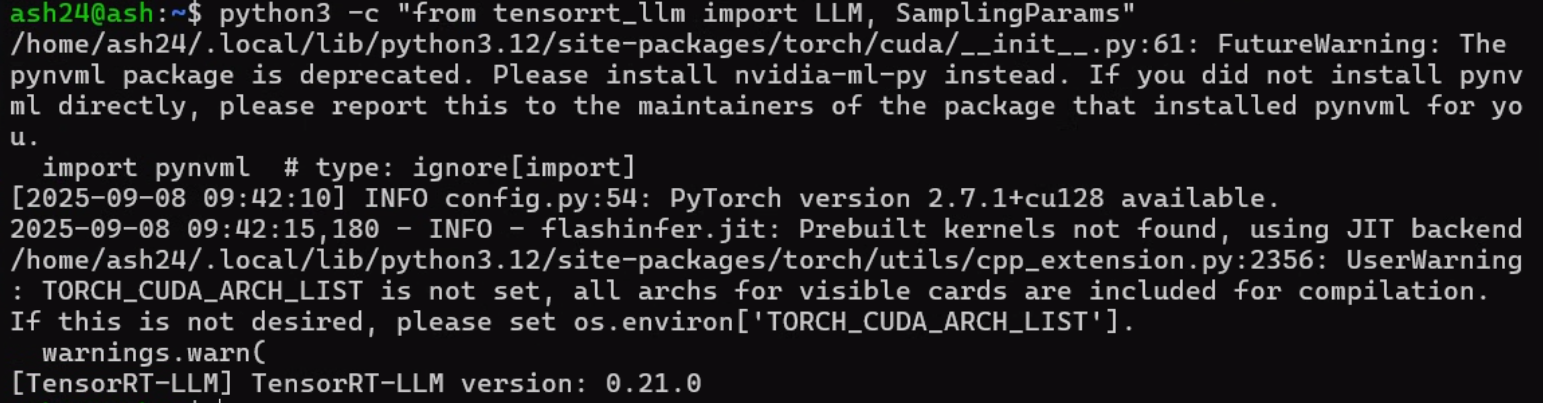
설치 이후 경구문구 해제방법
1) pynvml 패키지 문제
FutureWarning: The pynvml package is deprecated.
Please install nvidia-ml-py instead.
If you did not install pynvml directly,
please report this to the maintainers
of the package that installed pynvml for you.위 warning 구문에 대한 내용은 pynvml패키지는 더이상 유지보수가 진행되는 라이브러리가 아니며, nvidia-ml-py로 변경하라는 뜻이다
이는 아래와 같이 수행하면 된다.
pip uninstall -y pynvml # pynvml 패키지 삭제
pip install -U nvidia-ml-py # 대체 패키지 설치2) flashinfer.jit: Prebuilt kernels not found, using JIT backend
위 경고문구는 flashinfer (Tensort LLM이 하위 GPU커널 연산에 사용하는 커널 라이브러리)가 사전에 빌드된 커널을 찾지 못해 JIT 백앤드로 대체하여 실행한다는 뜻이다.
위 문제를 해결하려면 아래와 같이
https://github.com/flashinfer-ai/flashinfer
해당 깃 저장소를 클론한 뒤 직접 설치하는 방안을 추천한다
(pip로 설치하니까 의외로 잘 해결이 안됨...)

git clone https://github.com/flashinfer-ai/flashinfer.git --recursive
pip install ninja
cd flashinfer
python3 -m pip install --no-build-isolation --verbose .3) UserWarning: TORCH_CUDA_ARCH_LIST is not set
이 경고문구는 현재 설치된 GPU를 Pytorch가 인식하는 모든 CUDA 아키텍쳐로 컴파일/JIT를 하려 한다는 경고문구이다.
불필요한 빌드 시도가 있으니 사용자의 GPU에 타게팅된 SM 아키텍쳐를 지정하라는 뜻인데
https://developer.nvidia.com/cuda-gpus
기재되어 있는 엔비디아 그래픽카드 모델명과 GPU아키텍쳐를 매칭하여 사용하면 된다.
필자는 RTX 5000시리즈 그래픽 카드에서 실습을 진행하기에
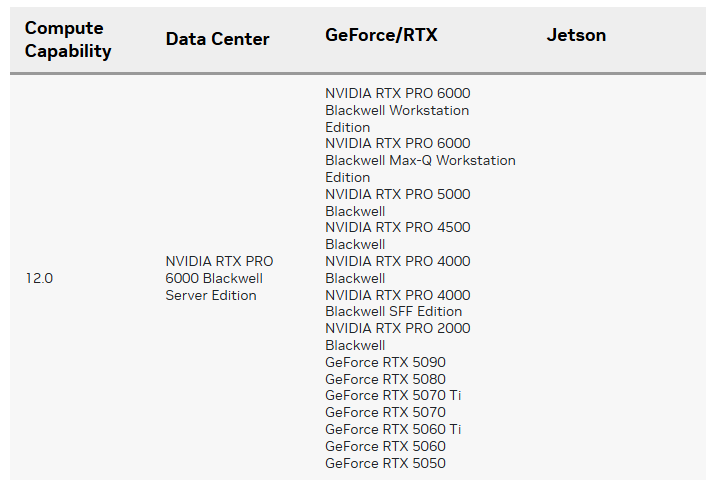
export TORCH_CUDA_ARCH_LIST="12.0"위 구문을 .bashrc에 적용하거나 커맨트창에서 기입 후 Tensort-LLM을 기동하면 된다.
GPU의 경우 특정 아키텍쳐 군으로 타게팅하면 나중에 CI/CD에 문제가 생길 수 있으니 3번 경고는 궂이 해결에 목메달 필요는 없다.

