
이전 포스트에서 TensorRT-LLM에 대한 소개와 설치까지 마쳣으니 이제 실행 및 LLM모델의 최적화 팁에 대해 소개하고자 한다.
TensorRT-LLM으로 LLM모델 로드 방법
TensorRT-LLM으로 모델 구동을 위한 사전설정
https://nvidia.github.io/TensorRT-LLM/installation/linux.html
먼저 공식 홈페이지에 나와있는데로 LLM불러오기 및 추론 테스트를 수행해보자
테스트에 사용할 모델은 Qwen3-4B, kanana-nano-2.1B를 사용하고자 한다.
우선 필자는 vscode에서 *.ipynb 파일을 통해 주피터 노트북 방식으로 파이썬 코드를 수행하려 하기에 미리 사전에 패키지 몇개를 설치하고자 한다
pip3 install ipykernel ipywidgets
pip3 install --upgrade ipywidgets jupyter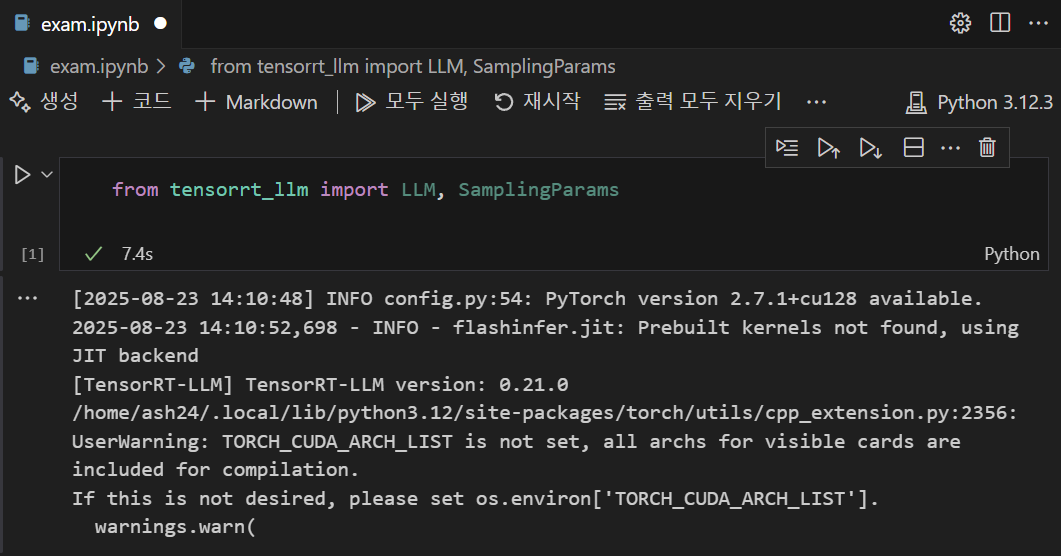
설치를 완료하고 라이브러리 import 코드만 실행하면 위와 같은 결과물을 얻을 수 있는데 여기서 Prebuilt kernels 경고문구가 거슬린다면 아래와 같이 코드 수행을 진행하자
# 기존 Prebuilt와 관련된 파이썬 라이브러리 삭제
pip3 uninstall flashinfer flashinfer-python -y
# 깃허브로 flashinfer 클론
git clone https://github.com/flashinfer-ai/flashinfer.git --recursive
cd flashinfer
pip3 install -v . # 현재 클론한 버전으로 Prebuilt와 관련된 파이썬 라이브러리 설치그 다음 TORCH_CUDA_ARCH_LIST 이 내용은 실행하는 TensorRT-LLM 라이브러리를 사용하는 GPU에 최적화 시켜서 구동하지 않고 있다는 경고문구인데
https://developer.nvidia.com/cuda-gpus#compute
여기에 나와있는 본인의 GPU의 아키텍처 버전을 미리 알려주면 경고문구가 사라진다.
import os
# RTX 5090용 CUDA 아키텍처 설정
os.environ['TORCH_CUDA_ARCH_LIST'] = '12.0'필자는 RTX 5090을 사용하기에 이에 맞는 쿠다 아키텍처 버전인 12.0으로 먼저 설정한다.
여기까지 설정했으면 TensorRT-LLM으로 LLM로드하기 위한 사전설정은 어느정도 완료한 것이다.
모델로드 테스트
1. Qwen3-4B 모델 추론 테스트
모델 추론 전에 해당 모델을 허깅페이스에서 다운로드 받으려면
먼저 git-lfs를 설치해야한다
sudo apt-get install git-lfs
git lfs installgit clone https://huggingface.co/Qwen/Qwen3-4BMODEL_PATH = 'Qwen3-4B'
# 모델 로드 코드
llm = LLM(
model=MODEL_PATH,
)
# 테스트 프롬포트 입력
prompts = [
"안녕, 너는 누구야?",
"대한민국의 수도는?",
"너가 수행할 수 있는 기능에 대해 알려줘",
]
# LLM의 응답 출력을 위한 Output Parm 설정
sampling_params = SamplingParams(
temperature=0.8,
top_p=0.95
)
# LLM의 텍스트 생성 테스트
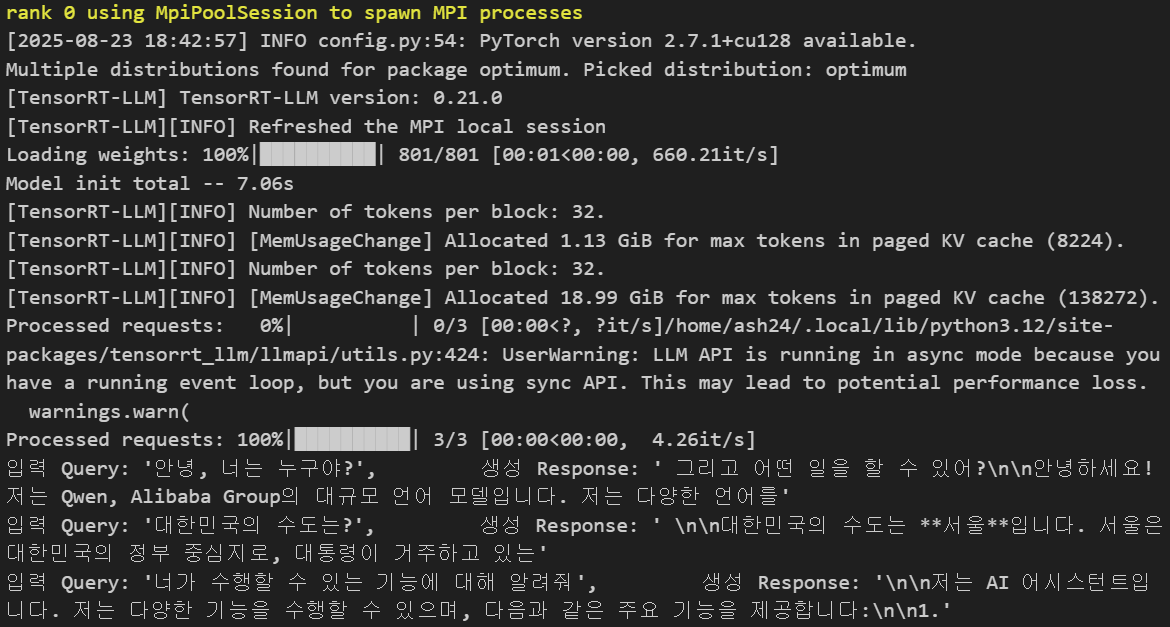
for output in llm.generate(prompts, sampling_params):
print(
f"입력 Query: {output.prompt!r}, \
생성 Response: {output.outputs[0].text!r}"
)위 코드로 모델 로드 및 추론 테스트를 실행한다면 아래와 같은 오류가 발생한다.
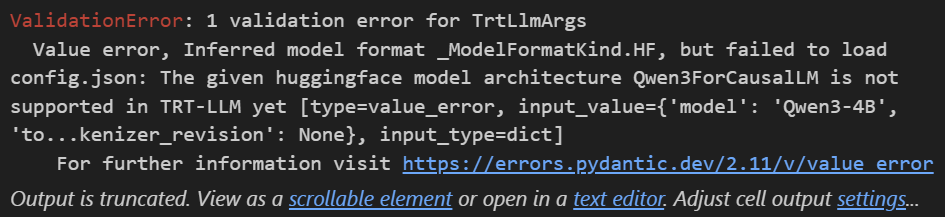
번역을 하자면 Qwen3계열의 아키텍처인 Qwen3ForCausalLM모델은 현재 TensorRT LLM으로 모델로드가 안된다는 것인데
모델 로드 인자값에 backend="pytorch"라고 백앤드엔진을 pytorch로 명시해야 로드가 가능해진다.
여기서 LLM클래스를 사용하는 문서 인자값 문제가 좀 발생하는데
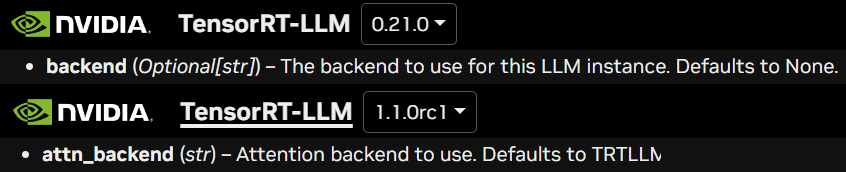
첨부한 https://nvidia.github.io/TensorRT-LLM/latest/llm-api/reference.html TensorRT-LLM의 라이브러리 API 레퍼런스를 보면
버전별로 인자값에 차이가 있다.
문제는 pip로 설치되는 TensorRT-LLM은 0.21.0 버전이 설치되는데 공식문서는 1.1.0rc1까지 9개 버전 정도 차이가 나기에 많이 열받는 상황이 발생한다.
아무튼 Qwen3-4B 모델을 구동하려면
MODEL_PATH = 'Qwen3-4B'
# 모델 로드 코드
llm = LLM(
model=MODEL_PATH,
backend='pytorch'
)이렇게 인자값을 넣어야 제대로 추론테스트가 가능하다.
2. LLM모델 VRAM 최적화 전략
다음으로 vllm도 그렇고 TensorRT-LLM도 모델 로드 및 운용에서 항상 머리아파오는 문제점인
LLM로드시 VRAM 할당과 관련된 설정을 진행해보자
우선 위에 모델 로드한 정보를 분석해 본다면

kv cahce로 VRAM 19GB정도를 빨아먹고 있는데 이 KV cache로 너무 과도하게 VRAM이 점유되고 있다. 이 부분을 해결해야 한다.
우선 상세하게 LLM실행로그를 확인하기 위해 아래 구문을 파이썬 코드셀에 추가한다.
import os
# RTX 5090용 CUDA 아키텍처 설정
os.environ['TORCH_CUDA_ARCH_LIST'] = '12.0'
# 로그 정보를 좀더 자세하게 출력
os.environ['TLLM_LOG_LEVEL']= 'INFO'이렇게 설정해놓고 LLM 로딩 시 VRAM 소비정보를 좀 더 자세하게 살펴볼 필요성이 있다.
여기에 기재되어 있는 KvCacheConfig 라이브러리를 추가로 import 한다.
from tensorrt_llm import LLM, SamplingParams
from tensorrt_llm.llmapi import KvCacheConfigMODEL_PATH = 'Qwen3-4B'
kv_cache_config = KvCacheConfig(
free_gpu_memory_fraction=0.35, # 남은 VRAM의 35% 를 KV캐시에 할당
# max_tokens = 8192 # KV 캐시 용량을 “토큰 절대값”으로 계산함
)
# 모델 로드 코드
llm = LLM(
model=MODEL_PATH,
backend='pytorch',
kv_cache_config=kv_cache_config
)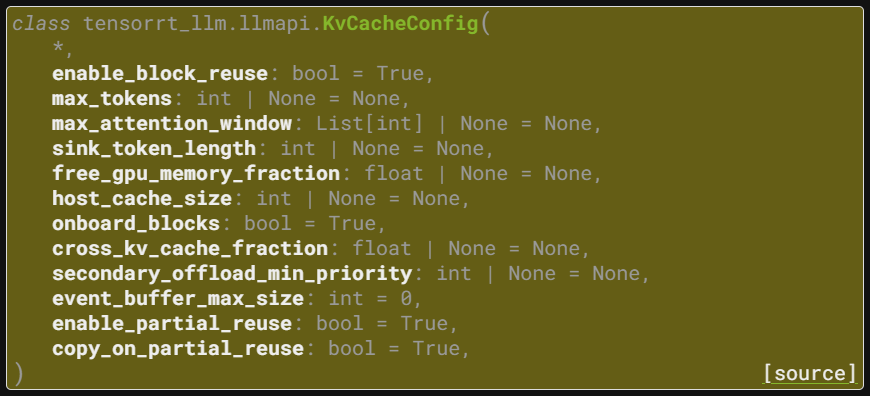
첨부한 사진처럼 VRAM에 KV cache 캐시를 할당하는 용량이랑 방법론 등을 조정하는 파라미터인데
free_gpu_memory_fraction만 기억하면 되긴 한다.
이게 VLLM 추론엔진의 gpu_memory_utilization 파라미터랑 거의 동일한 기능을 하는 인자라 보면 된다.
하지만 VLLM 의 gpu_memory_utilization 파라미터는 조정하기가 좀 더러운 인자라고 볼 수 있는데
TensorRT-LLM의 free_gpu_memory_fraction은 꽤 상세하게 인자값 조정이 가능하고, 그에 따라 KV Cache조정도 깔끔하게 할당되서 전반적으로 사용하기 편한 부분이 있었다.
위 설정대로 LLM을 로드하면 아래와 같은 실행결과를 얻을 수 있었다.
# 허깅페이스 모델 로드에 사용된 VRAM관련 내용 -> 대략 7.5GB ~ 8.2GB 사이로 사용된다 보면 됨
[TRT-LLM] [I] Use 8.22 GB for model weights.
[TRT-LLM] [I] Prefetching 7.49GB checkpoint files.
# 허깅페이스 모델의 config 정보(max_token=8224)에 맞춰서 1.13GB의 VRAM을 KV cache로 임시 할당
[MemUsageChange] Allocated 1.13 GiB for max tokens in paged KV cache (8224)
# KV 캐시 컨피그 정보를 바탕으로 최종 할당된 KV cache용량 = 7.38GB
[I] Peak memory during memory usage profiling (torch + non-torch): 11.88 GiB, available KV cache memory when calculating max tokens: 7.38 GiB
# 추론에 사용된 동적 메모리 0.61GB
[I] Memory dynamically allocated during inference (inside torch) in memory usage profiling: 0.61 GiB
# LLM구동 외의 프로그램(윈도우 같은거...)에서 이미 쓰고 있는 VRAM용량 = 3.69GB
[I] Memory used after loading model weights (outside torch) in memory usage profiling: 3.69 GiB
이렇게 상세하게 vram 점유 항목 및 용량정보를 알 수 있으며, 이를 바탕으로 LLM구동에 사용되는 VRAM 최적화 전략을 수립할 수 있다.
3. kanana-nano-2.1B 추론 테스트
이번에는 TensorRT-LLM에서 Backend = TensorRTLLM으로 구동이 가능한 LLM모델인 kanaan-nano-2.1B 모델로 추론테스트를 진행하고자 한다.
MODEL_PATH = 'kanana-nano-2.1B-instruct'
kv_cache_config = KvCacheConfig(
free_gpu_memory_fraction=0.35, # 남은 VRAM의 35% 를 KV캐시에 할당
# max_tokens = 8192 # KV 캐시 용량을 “토큰 절대값”으로 계산함
)
# 모델 로드 코드
llm = LLM(
model=MODEL_PATH,
backend=None, # 아에 이 인자값을 날려도 됨
kv_cache_config=kv_cache_config
)
# 테스트 프롬포트 입력
prompts = [
"안녕, 너는 누구야?",
"대한민국의 수도는?",
"너가 수행할 수 있는 기능에 대해 알려줘",
]
# LLM의 응답 출력을 위한 Output Parm 설정
sampling_params = SamplingParams(
temperature=0.8,
top_p=0.95
)
# LLM의 텍스트 생성 테스트
for output in llm.generate(prompts, sampling_params):
print(
f"입력 Query: {output.prompt!r}, \
생성 Response: {output.outputs[0].text!r}"
)위와 같이 백앤드 엔진을 Pytorch에서 기본 엔진인 Tensorrt로 변경하면(기본값이 None임을 숙지하자..)
허깅페이스 모델 -> TensorRT engine로 빌드하는 과정을 먼저 수행한다
Loading Model: [1/2] Loading HF model to memory
Loading Model: [2/2] Building TRT-LLM engine당연히 모델이 바뀌기도 했고 TRT-LLM엔진으로 빌드하는 과정도 거치기에 VRAM점유량이 좀 많이 변경되는데
Loaded engine size: 4012 MiB # LLM 모델 로드 vram(4.21GB)
# 실행 컨텍스트 메모리 = 0.74GB
[MemUsageChange] Allocated 702.01 MiB for execution context memory.
# 런타임 및 디코더 메모리 = 5.58GB
[MemUsageChange] Allocated 1.29 GB GPU memory for runtime buffers.
[MemUsageChange] Allocated 4.29 GB GPU memory for decoder.
# 허용된 KV캐시용량 = 7.45GB
[MemUsageChange] Allocated 6.94 GiB for max tokens in paged KV cache (56864)여기에 윈도우OS가 점유중인 vram등 기타 여러개를 계산하면 대략 20.6GB 정도의 VRAM이 소비된다
이제 이것을 Backend=pytorch로 파이토치 백엔드로 돌리면 이상한 문제가 하나 발생한다
MODEL_PATH = 'kanana-nano-2.1B-instruct'
kv_cache_config = KvCacheConfig(
free_gpu_memory_fraction=0.35, # 남은 VRAM의 35% 를 KV캐시에 할당
# max_tokens = 8192 # KV 캐시 용량을 “토큰 절대값”으로 계산함
)
# 모델 로드 코드
llm = LLM(
model=MODEL_PATH,
backend='pytorch', # 백앤드 파이토치로 다시 조정
kv_cache_config=kv_cache_config
)
[TRT-LLM] [I] Use 4.32 GB for model weights.
[TRT-LLM] [I] Prefetching 3.89GB checkpoint files.
# 최종 모델 로드에 사용된 vram = 3.32GB
[TRT-LLM] [I] Memory used after loading model weights (outside torch) in memory usage profiling: 3.32 GiB
[MemUsageChange] Allocated 1.00 GiB for max tokens in paged KV cache (8224).
# 추론에 사용된 버퍼 메모리 = 0.49GB
[TRT-LLM] [I] Memory dynamically allocated during inference (inside torch) in memory usage profiling: 0.49 GiB
# 윈도우에서 쓰고잇는 메모리 = 3.32GB
[TRT-LLM] [I] Memory used outside torch (e.g., NCCL and CUDA graphs) in memory usage profiling: 3.32 GiB
# kv캐시에 최종 할당된 메모리 = 9.43GB
[MemUsageChange] Allocated 8.78 GiB for max tokens in paged KV cache (71936)총 VRAM 점유되는 용량도 21GB에서 17GB로 줄어들 뿐더러, kv캐시로 할당된 메모리도
1) Backend - tensorrt 일때는 7.45GB
2) Backend - pytorch 일때는 9.43GB
더 효율적이다.
위와 같은 문제가 발생하는 이유는 Backend=tensorrt 일때
허깅페이스 모델 -> TensorRT engine로 모델변환 을 수행하고 이때 수행과정에서 VRAM이 소비되기에 VRAM소비 비 효율성이 발생하는 것이다.
이같은 문제를 해결하려면
사전에 허깅페이스 모델 -> TensorRT Engine으로 모델 변환을 수행해야 한다.
허깅페이스 모델 TensorRT engine으로 변환하기
이 허깅페이스 모델을 TensorRT-LLM에 최적화된 파일로 변경하기 위해서는 첨부한 링크에서 볼 수 있듯이 3가지 단계를 거쳐야 하는데
https://nvidia.github.io/TensorRT-LLM/architecture/checkpoint.html
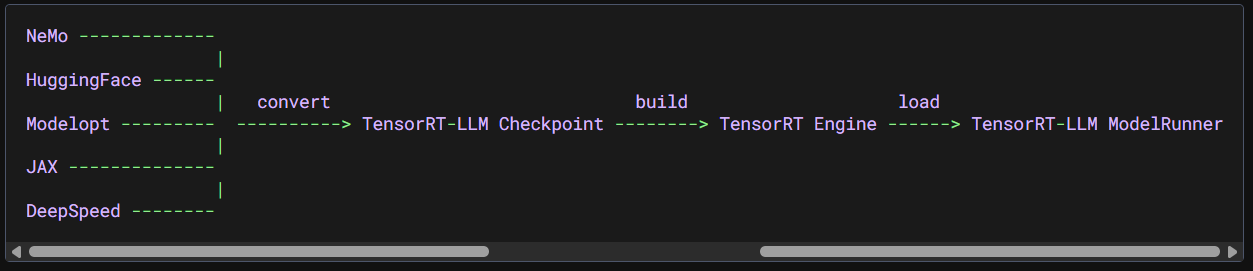
허깅페이스 체크포인트 모델 -> Tensor-RT LLM 체크포인트 -> Tensor-RT 엔진
이렇게 3가지 단계를 거쳐야 한다
뭐 이리 복잡하게 변경이 되는지는 알기가 어렵지만
이게 또 문제가 아닌게 체크포인트 모델 만드는것도 아키텍쳐 별로 다 나뉘어져 있다
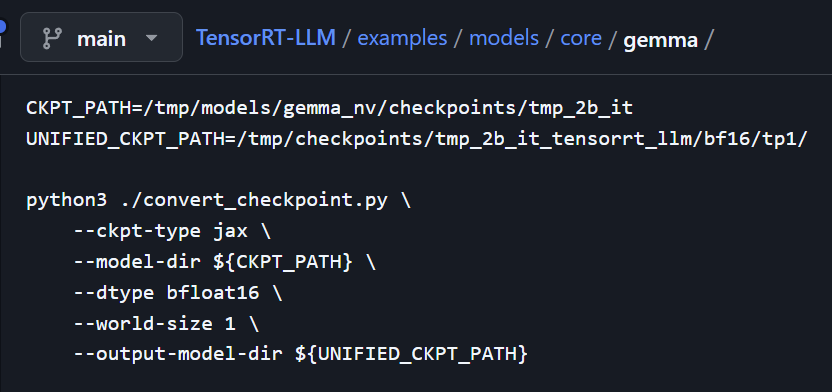
뭐 이런식으로 각 모델별로 따로 변환을 수행하는 convert_checkpoint.py이란 변환에 필요한 라이브러리 설치용 requirements.txt가 각각 배치되어 있어
변환이 안된다면 관련 라이브러리 설치도 진행을 해야 한다.
이때 변환이 가능한 모델도 있고 아닌 모델도 있는데
현재 시점에서 Qwen3-4B 모델은 변환이 불가능하고
kanana-nano-2.1B 모델은 변환이 되지만
llama계열 모델의 convert_checkpoint.py파일을 이용해야 한다.
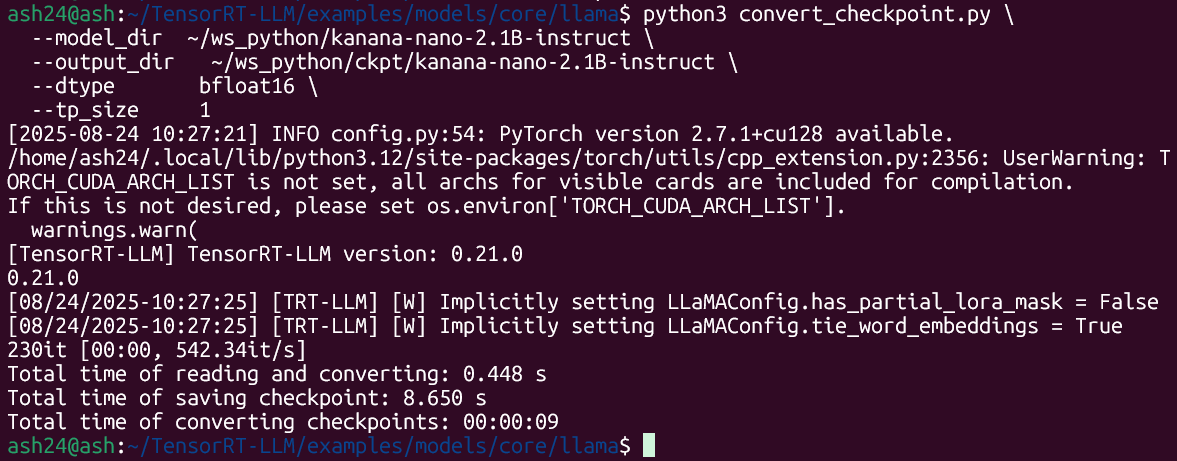
python3 convert_checkpoint.py \
--model_dir ~/ws_python/kanana-nano-2.1B-instruct \
--output_dir ~/ws_python/ckpt/kanana-nano-2.1B-instruct \
--dtype bfloat16 \
--tp_size 1대략 위 첨부한 사진처럼 convert_checkpoint.py 를 이용해서 체크포인트 형식으로 변환을 수행한 뒤

trtllm-build \
--checkpoint_dir ~/ws_python/ckpt/kanana-nano-2.1B-instruct \
--output_dir ~/ws_python/trtengine/kanana-nano-2.1B-instruct위와 같이 변환 명령어를 순차로 기입하면 된다.
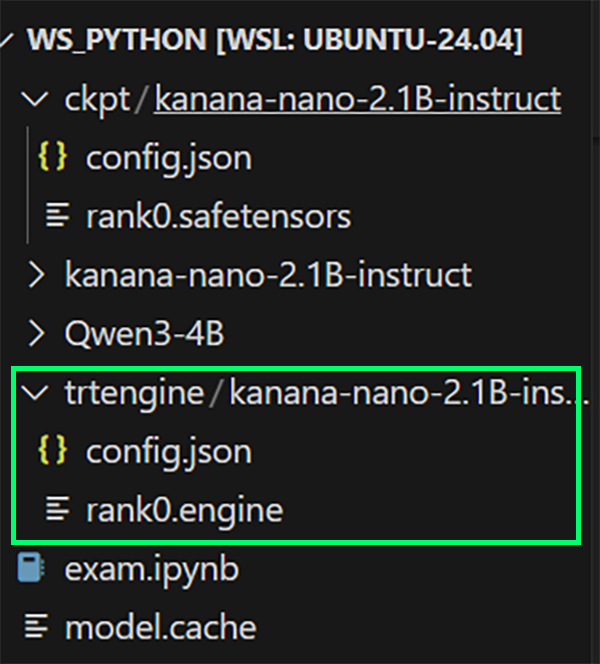
이제 첨부한 사진처럼 ckpt폴더랑 trtengine폴더에 변환된 파일들이 저장되었을 텐데
ckpt에 저장된 파일은 이제는 필요없으니 지우면 된다.
그럼 이제 변환된 trtengine 파일을 구동하면 성공하는가?
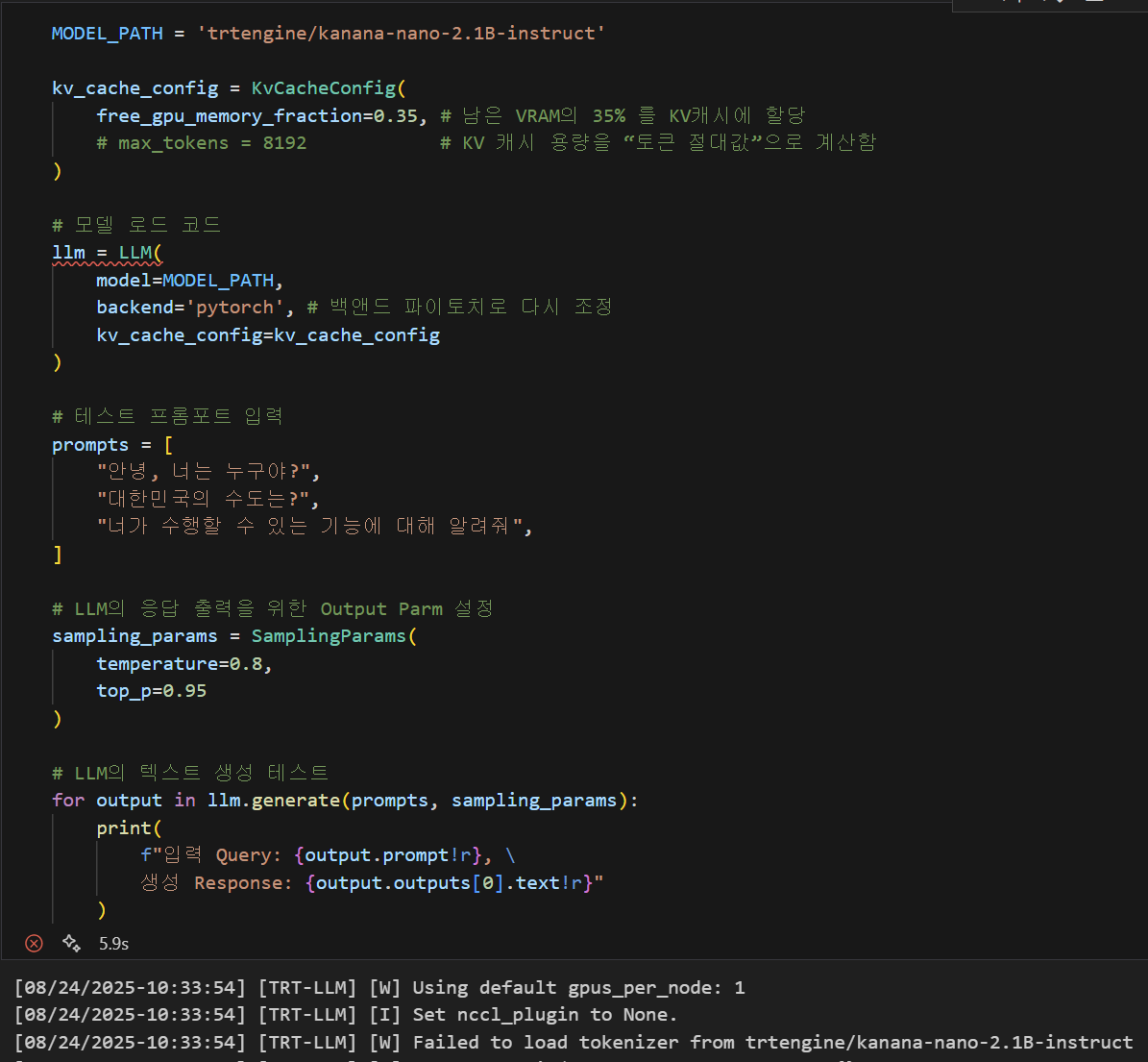
성공하지 못하는 것을 알 수 있다.
이유는
Failed to load tokenizer from trtengine/kanana-nano-2.1B-instruct이렇게 토크나이저가 없다는 메세지가 뜨는데
해결방법은 아래와 같다.
MODEL_PATH = 'trtengine/kanana-nano-2.1B-instruct'
kv_cache_config = KvCacheConfig(
free_gpu_memory_fraction=0.35, # 남은 VRAM의 35% 를 KV캐시에 할당
# max_tokens = 8192 # KV 캐시 용량을 “토큰 절대값”으로 계산함
)
# 모델 로드 코드
llm = LLM(
model=MODEL_PATH,
# backend='pytorch', # 백앤드 파이토치로 다시 조정
kv_cache_config=kv_cache_config,
tokenizer='kanana-nano-2.1B-instruct',
)이렇게 tokenizer 인자를 추가한 뒤 여기에 허깅페이스 모델이 저장된 폴더에서 토크나이저 정보를 불러오면 된다.
아니면
허깅페이스 모델에 담겨있는 위 3개 파일
special_tokens_map.json, tokenizer_config.json, tokenizer.json파일 3개를 trtengine으로 변환한 폴더에 넣어도 된다.
이렇게 복붙하면 알아서 tokenizer인자가 폴더 내에 있는 토크나이저 파일을 찾아서 추론에 사용한다.
이렇게
허깅페이스 체크포인트 모델 -> Tensor-RT LLM 체크포인트 -> Tensor-RT 엔진
변환 실습까지 시행했는데
backend='pytorch' 이 백앤드 옵션을 파이토치로 해서 그냥 허깅페이스 모델을 구동하는게 제일 속편하다.
